人工知能(AI)、ビッグデータ法務 著作権
AIと著作権【第3回】学習用データとして“何を使ってはいけないか”を見極める~学習対象の観点からの検討~

2025年7月にSTORIA法律事務所の柿沼・杉浦の共著で日本加除出版から書籍「AIと法 実務大全」を出版します。
本書は650頁超というボリュームでありながらも、AI開発や利活用に問題となる点を「網羅的」に解説するものではありません。あくまで、現場の方がAI開発や利活用を行う際に、法律的によく問題となる論点とその解決手法に照準を絞っています。その分個々の論点については、最先端の議論を下敷きにしつつ実務的に相当深掘りした記述となっています。
書籍の出版に先立ち、その一部である「第2章 生成AI開発・提供・利用と著作権」について日本加除出版からご了解を得て、ブログで連載記事として先行公開することとしました。
「一部」といっても記事合計13万字を越えるボリューム(ほぼ新書1冊分!)であり、ブログ公開を快諾いただいた日本加除出版には感謝しかありません。
この連載記事を読んで興味が湧いた方は是非書籍をお買い求めください!
連載「AIと著作権」全18回の目次を表示
- 第1回 プレイヤー・フェーズ・提供形態による法的整理
- 第2回 AI学習段階での著作物利用はどこまで許されるか?──著作権法第30条の4の射程
- 第3回 学習用データとして“何を使ってはいけないか”を見極める~学習対象の観点からの検討~
- 第4回 海賊版や学習禁止表示がされている著作物をAI学習に利用することができるか
- 第5回 開発・学習段階での著作権侵害行為が発生した場合、侵害者はどのような責任を負うか
- 第6回 生成・利用段階では何が問題になるのか?
- 第7回 類似AI生成物の「生成」における依拠性をどのように考えるか~複雑な論点を解きほぐす~
- 第8回 類似AI生成物の「生成」における行為主体性~ロクラクⅡ事件判決をベースに徹底的に考える~
- 第9回 生成された類似AI生成物を利用すると著作権侵害?
- 第10回 類似AI生成物の「送信」は誰の責任?──クラウド提供型AIにおける著作権侵害リスクを検証する
- 第11回 生成・利用段階で著作権侵害行為が認められた場合、権利者は何を請求できるのか
- 第12回 RAG・ロングコンテクストLLMと著作権侵害(前編)
- 第13回 RAG・ロングコンテクストLLMと著作権侵害(後編)
- 第14回 RAGシステムのための既存著作物の蓄積・入力などは著作権侵害になるのか
- 第15回 RAGとAI利用者の責任~入力・送信・出力のそれぞれで何が問われるか?~
- 第16回 AI生成物に著作権はあるのか?~著作物性と“創作的寄与”の最新実務論~
- 第17回 その行為に日本著作権法は適用されるか~準拠法の問題~
- 第18回 で、結局何に気をつければよいのか~AI開発者・AI提供者・AI利用者それぞれの注意事項~
🔊 音声で内容を復習する
この記事の内容を、対話形式の音声で聞くことができます。
▶ 対話形式で聞く
※ 対話形式の音声はNotebookLMを利用して自動的に作成したものです。正確な内容は記事本文をご参照ください。
ウ 学習対象による制限
「学習対象による制限」が問題となる著作物は「情報解析に活用できる形で整理したデータベースの著作物」「海賊版等の権利侵害複製物」「学習禁止意思が付されている著作物」「学習を防止するための機械可読方法による技術的な措置が付されている著作物」等です。
これらの対象物をAIモデルの学習に利用することが30条の4柱書但書に該当するかが問題となりますが、同但書の該当性を検討するに際しては、著作権者の著作物の利用市場と衝突するか、あるいは将来における著作物の潜在的販路を阻害するかという観点から、技術の進展や、著作物の利用態様の変化といった諸般の事情を総合的に考慮して検討することが必要とされています124)「考え方」23 頁、文化庁著作権課「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する本的な考え方(著作権法第30 条の4、第47 条の4及び第47 条の5関係)」令和元年10 月24 日・問9(9頁)。
(ア) 情報解析に活用できる形で整理したデータベースの著作物(情報解析用DB著作物)
この「(ア) 情報解析に活用できる形で整理したデータベースの著作物(情報解析用DB著作物)」の利用が法30条の4柱書但書に該当するかの論点は、かなり複雑であり、かつよく議論されている部分なので詳しく説明します。
(ⅰ)データベース、データベース著作物(DB著作物)、情報解析用DB著作物とは
① データベース(DB)
データベース(DB)とは、単体データを集めて構造化したり、組み合わせたりして作られたものであり、学習用データセットもDBに該当します。
著作権法には「データベース」の定義が置かれており、同定義によるとデータベースとは「論文、数値、図形その他の情報の集合物であつて、それらの情報を電子計算機を用いて検索することができるように体系的に構成したもの」(著作権法2条1項10の3)です。
② データベース著作物
もっとも、著作権法上は上記定義に該当する全てのDBが著作物に該当するのではなく、上記定義に該当するDBのうち「その情報の選択又は体系的な構成によって創作性を有するもの」のみが著作物(データベースの著作物)に該当します(同法12条の2第1項)。
③ 情報解析用DB著作物
著作権法上は、データベースは「著作物に該当しないデータベース」と「著作物に該当するデータベース(DB著作物)」しかありませんが、著作権法30条の4柱書但書の解釈においては「情報解析用DB著作物」という概念が出てきます。
「情報解析用DB著作物」とは、データベース著作物のうち「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物」2「考え方」24頁をいいます。
そして30条の4柱書但書に該当する(=30条の4が適用されない)例として、同条制定当時から、「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物(情報解析用DB著作物)が販売されている場合に,当該データベースを情報解析目的で複製等する行為」が示されています3前掲注24)「基本的な考え方」問9(9頁)。ただし、「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に、当該データベースを情報解析目的で複製等する行為」については、30 条の4柱書但書の問題ではなく、当該データベース著作物の本来的利用であるとして享受目的併存により30 条の4が適用されない、という説もある(前田健「生成AI の利用が著作権侵害となる場合」法学教室523 号(2024)30 頁、『AI と著作権』231 頁〔前田発言〕)。
したがって、情報解析用DB著作物が販売されている場合において、それを学習(情報解析)目的で利用したり、生成・利用段階で、AIによる解析(情報解析)目的で入力したりする行為は、30条の4柱書但書に該当し、他の権利制限規定の適用がなければ著作権侵害に該当します。
一方、写真やイラストのDBなど、享受目的を本来的目的として作成されたデータにより構成されているデータベースは、DB著作物に該当することはあっても、「情報解析用DB著作物」には該当しません427)『AI と著作権』231 頁〔奥邨発言〕「一方で、例えば、一般的な印刷用とかウェブサイトの挿絵用とかでライセンスされているフォトストックのデータベースだと、著作物の種類はデータベースでも、用途は観賞用、利用態様は、情報解析用機器で全部複製する、という当てはめになります。これは、元々、柱書本文がやってもいいよと書いてあることをやっているだけなので、不当に害する余地はない、大丈夫じゃないかなと私は思います。」。
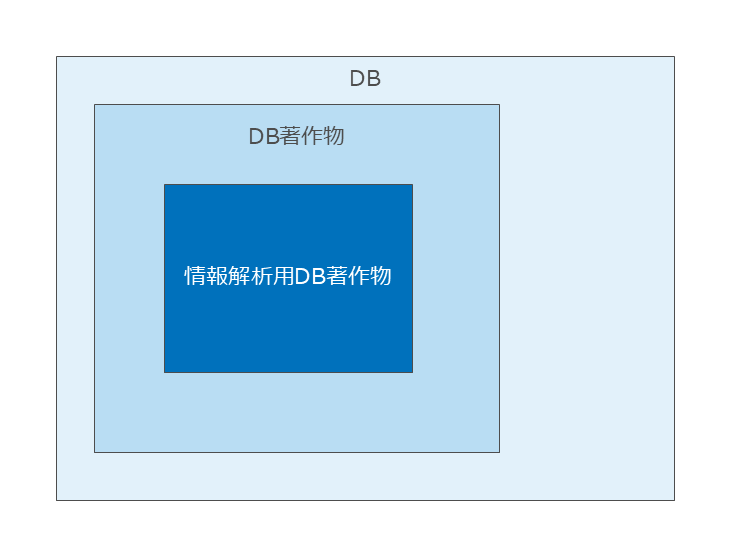
図26
学習用データセットは、個々のデータを一定の方針のもと収集してタグ付けやアノテーションなどの処理を施したデータベースですが、全ての学習用データセットが、DB著作物や情報解析用DB著作物に該当するわけではありません。
学習用データセットが情報解析用DB著作物に該当するためには、まずDB著作物に該当すること、すなわち「情報の選択」か「体系的な構成」に創作性がなければなりません。
たとえば散在したデータを悉皆的・網羅的に収集・集積して前処理を行っただけの学習用データセットはデータベース著作物に該当しません(当然、情報解析用DB著作物にも該当しません)。あくまで、収集・蓄積の過程における「情報の選択」や、「体系的な構成」によって創作性を有する学習用データセットのみがDB著作物や情報解析用DB著作物に該当しうるということです(図 27)。
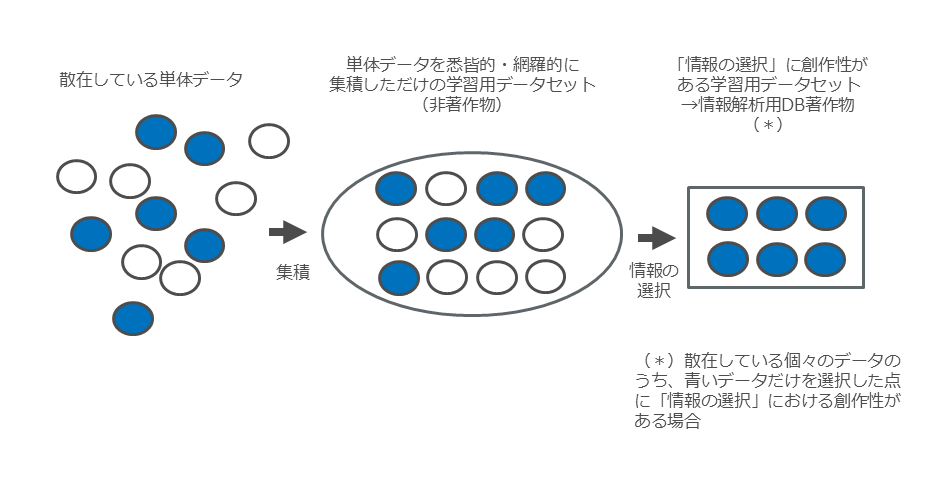
図27
もっとも、データの選択にどの程度の工夫があれば「情報の選択」や「体系的な構成」に創作性があるといえるかは難問です。
判断基準としては「当該情報の選択や体系的な構成が通常なされるべき選択・体系的構成であって、当該データベースに特有のものと言えない」場合や「他にも同様の選択行為や体系的構成を有するデータベースが存在する」場合には「情報の選択」や「体系的な構成」による創作性が否定されることになるでしょう。
たとえば、アメリカ国内で利用される顔認識用のAIを開発するために、人物肖像写真で構成される学習用データセットを生成することを考えてみます。
このような学習用データセットの生成に際して、たとえば「WEB上で『アメリカ人 顔写真』というキーワードで画像検索を行い、検索結果として表示された顔写真画像からランダムに1万枚選択する」という選択行為が行われたとします。
この場合、当該選択行為においては単純な(誰でも思いつく)キーワード検索を行った上でのランダム選択しか行われていませんから、「情報の選択」に創作性があるとは言えず、当該手法で生成された学習用データセットはDB著作物には該当しないでしょう。
では、次にたとえば「アメリカの総人口における人種の割合と同じ割合で、各人種に属する人物の顔写真を収集して構成する」という選択行為をなした場合はどうでしょうか。
この選択は、先ほどの単純なキーワード検索の例よりも創作性はあるように思えますが、「データ全体における個々のデータの割合と同じ割合で構成されたデータセット」という基準で情報を選択した場合は、通常なされるべき選択に該当し、この場合でも「情報の選択」に創作性はないように思われます。
(ⅱ) 「考え方」の内容
先述のように、30条の4柱書但書に該当する(30条の4が適用されない)例として、同条制定当時から、「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物(情報解析用DB著作物)が販売されている場合に,当該データベースを情報解析目的で複製等する行為」が示され、考え方についてもその点について詳細に述べています。
「考え方」24頁~27頁で示されている、「情報解析用DB著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為」の具体例は以下の3つです。
▼ 具体例1
情報解析用DB著作物がDVD等の記録媒体に記録して提供されている場合に、当該記録媒体から同DB著作物全体を情報解析目的で複製する行為(考え方P24)
▼ 具体例2
インターネット上のウェブサイトで、ユーザの閲覧に供するため記事等が提供されているのに加え、情報解析用DB著作物がAPI を通じて有償で提供されている場合において、当該 API を有償で利用することなく、当該ウェブサイトに閲覧用に掲載された記事等のデータから、当該データベースの著作物の創作的表現が認められる一定の情報のまとまりを情報解析目的で複製する行為(考え方P25)
▼ 具体例3
AI 学習のための著作物の複製等を防止する技術的な措置が講じられており、かつ、このような措置が講じられていることや、過去の実績(情報解析に活用できる形で整理したデータベースの著作物の作成実績や、そのライセンス取引に関する実績等)といった事実から、当該ウェブサイト内のデータを含み、情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることが推認される場合に、この措置を回避して、クローラにより当該ウェブサイト内に掲載されている多数のデータを収集することにより、AI学習のために当該データベースの著作物の複製等をする行為(考え方P26)5なお「考え方」25 頁脚注28 には「この点に関して、インターネット上のウェブサイトに掲載されたデータについては、AI 学習のための複製を行うクローラによるウェブサイト内へのアクセスが、後述するウェブサイト内のファイル“robots.txt” への記述により制限されていない場合、「(大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が)販売されている場合」に該当しないことを推認させる要素となるものと考えられる」との記載がある。この記載内容は合理的であるが、このような技術的制限が講じられていない事実は、パターン3における「情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があること」に該
当しないことを推認させる要素にもなると思われる(パブコメ191 参照)。
① 基本的な考え方
ここでは、直接的には「情報解析用DB著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為が30条の4柱書但書に該当するか」が問題となっているのですが、問題が複雑なので、少し基本的なことから説明していきます。
著作権侵害の要件は、①被侵害著作物との類似性、②被侵害著作物への依拠性、③利用者の著作物利用行為が権利制限規定(私的利用目的複製や情報解析目的複製等)に該当しないことの3つと考えると分かり易いです(図28)。
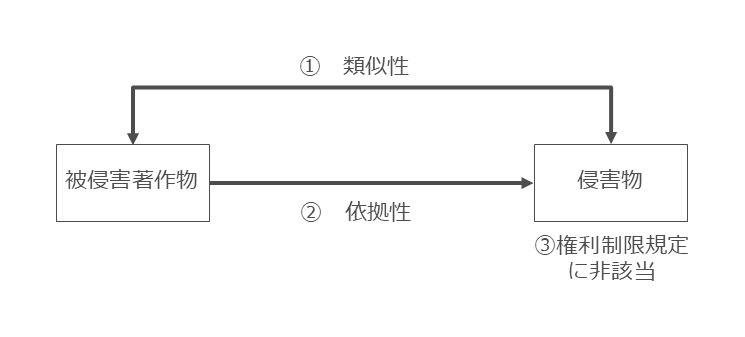
図28
①を満たさないケース(非類似)、②を満たさないケース(依拠性がなく独自創作)、③を満たさないケース(権利制限規定の適用あり)のいずれかに該当すると著作権侵害には該当しません(図29)。
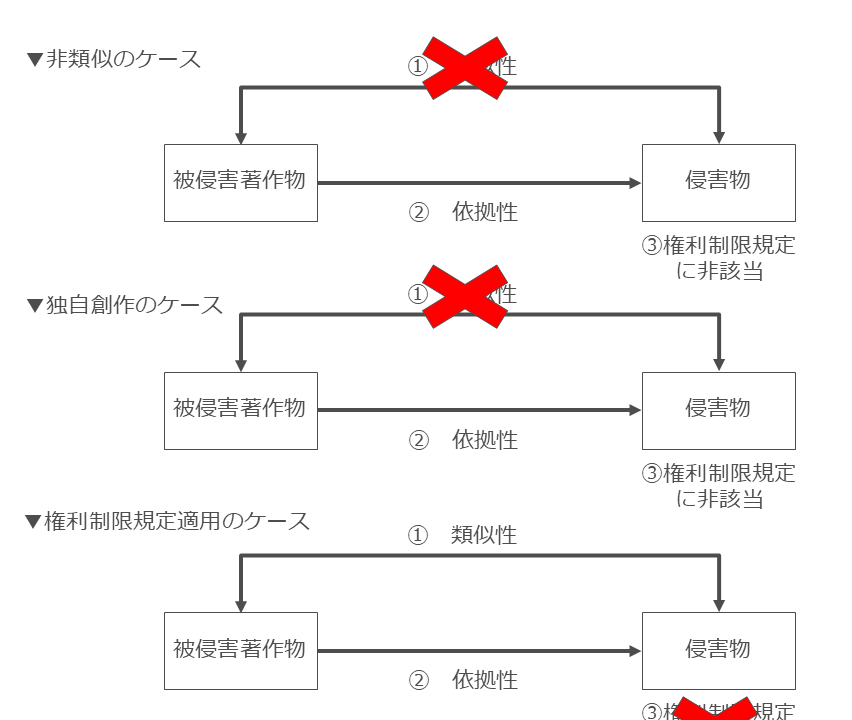
図29
たとえば、ウェブ上に掲載されている個々の新聞記事(著作物)をクローリングして複製し、AI学習のための学習用データセットを作成する行為は、当該個々の新聞記事との関係では、類似性・依拠性を満たしますが、そのような複製行為は情報解析のために必要な行為であるため、権利制限規定である30条の4が適用されて著作権侵害には該当しないことになります(図30、③を満たさないケース)。
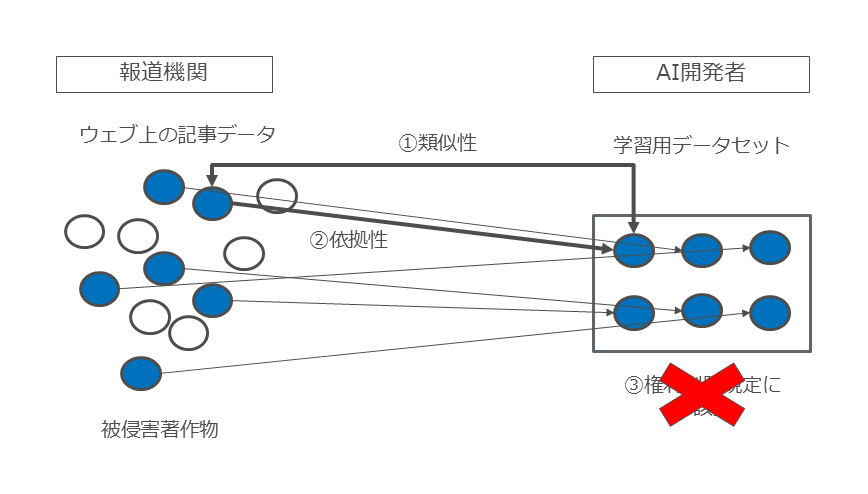
図30
後述のようにそのようなアクセス制限されているという事実が、将来的な情報解析用DB著作物の販売予定があることを推認させる一事情にはなりますが、そのようなアクセス制限の存在自体によって30条の4柱書但書該当性が肯定されるわけではありません(図31)。
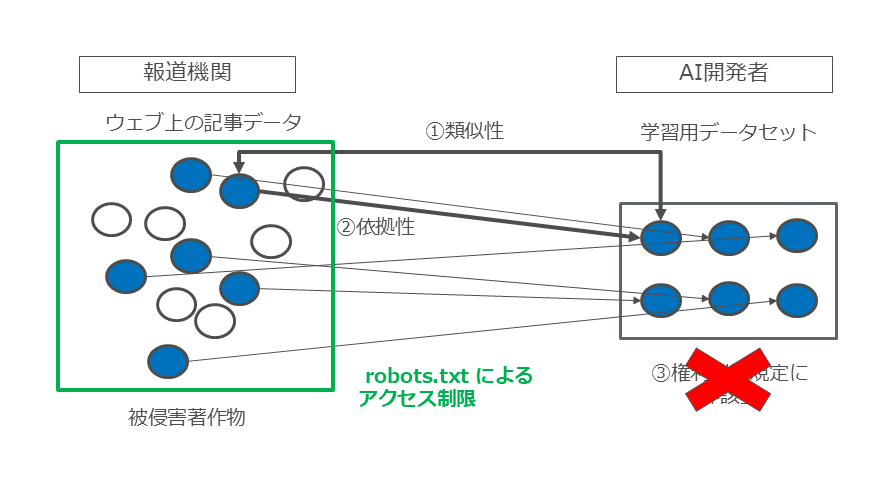
図31
以上を前提に具体例1~3までを見ていきましょう。
② 具体例1
具体例1は、図32のような行為ですが、類似性・依拠性は当然満たしますし、かつ改正前47条の7の但書に該当する行為であって現行法30条の4柱書但書に該当する(その結果権利制限規定に非該当)ことは明らかです。
したがって、他の権利制限規定が適用されなければ著作権侵害に該当します。
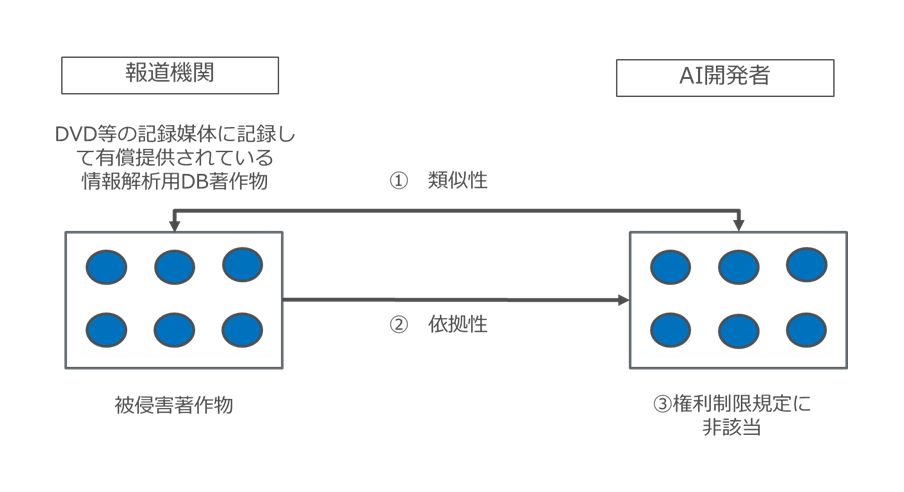
図32
ただし、DB著作物の著作権侵害における類似性とは、被侵害著作物であるDB著作物における創作性(情報の選択・体系的構成における創作性)が利用されることを意味しています。
したがってDVD等の記録媒体に記録して有償提供されている情報解析用DB著作物に含まれているデータの一部のみを抽出して、他のデータと混ぜてデータセットを作成した場合、被侵害著作物であるDB著作物の「創作性」が利用されていないため類似性はなく著作権侵害は否定されることになります(図 33)6中山信弘『著作権法 第4版』(有斐閣、2023)179 頁は「著作権侵害は、基本的には創作性のある部分が侵害された場合に生ずるが、データベースの創作性は情報の選択または体系的構成にあるので、抽象的にいえば、他の者が無断利用した部分が、情報の選択または体系的構成という観点から創作性があると認められる場合に著作権侵害となるが、具体的には個別的な事例ごとに判断され、その事例の集積を待って基準が明らかとなろう。他人のデータベースから、体系的な構成を模倣することはせず、相当量のデータだけを抽出し、自己の体系を構築したような場合には、利用した情報のひとかたまりには「情報の選択」という観点から、データベース作成者の創作性がないであろう」とする。。
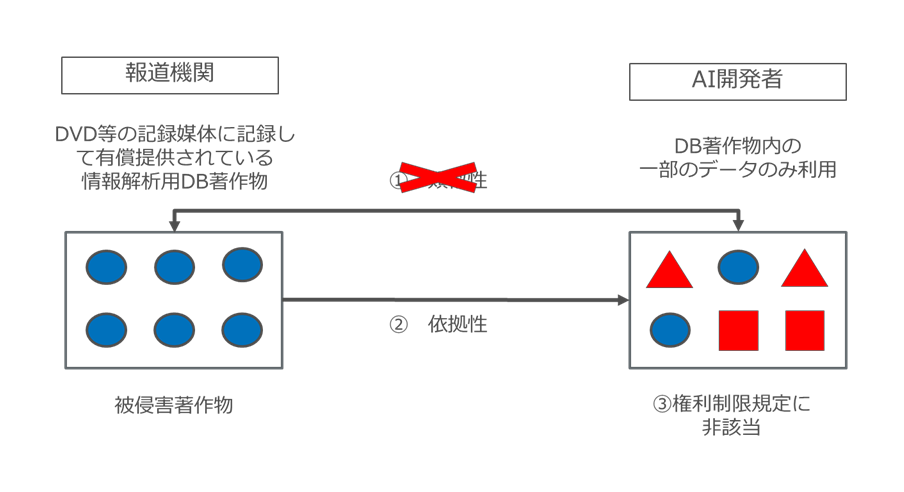
図33
具体例2は、かなりわかりにくいケースだと思います。
ここでのポイントは「被侵害著作物は何か」つまり、どの著作物の著作権侵害が問題になっているのか、ということです。
具体例2を図解すると以下のとおりとなります(図 34)。
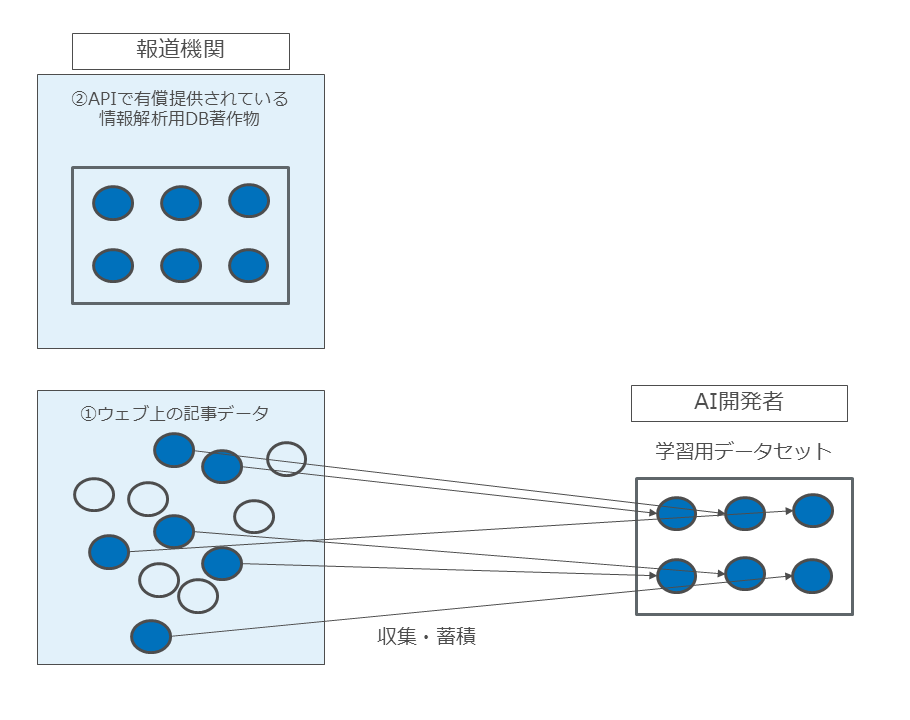
図34
まず、具体例2においては、権利者が、①インターネット上のウェブサイトで、ユーザの閲覧に供するため記事等を提供しているのに加えて、②情報解析用DB著作物をAPI等 を通じて有償で提供していることが前提となっています。
つまり、著作権侵害が問題となる(被侵害著作物になり得る)著作物は、①ウェブサイト上の記事と、②情報解析用DB著作物の2つがあることになります。
そして、具体例2,3で被侵害著作物として検討対象となっているのは、①の「ウェブサイト上の記事」ではなく②の「情報解析用DB著作物」の方です。
この点は特に誤解しやすい点なので注意してください。
これは「考え方」P26の「○ そのため、AI 学習のための著作物の複製等を防止する技術的な措置が講じられて・・・・・」の部分において、「この措置(筆者注:複製防止のための技術的措置)を回避して、クローラにより当該ウェブサイト内に掲載されている多数のデータを収集することにより、AI学習のために当該データベースの著作物の複製等をする行為」とされていることからも明らかです(強調部筆者)。
また、小委員会での議論で上野委員ら複数の委員からこの点について指摘があり、事務局から明確に以下のような回答があったところです(第6回小委員会議事録。強調部筆者)。
【三輪著作権課調査官】事務局でございます。ただいま委員の先生方からいただきました意見を踏まえまして少し補足させていただきますと、今おっしゃっていただきましたように、この点、記載の趣旨としては、先ほど事務局から御説明申し上げたとおり、対象の著作物として考えておりますのは、情報解析用のデータベースの著作物であり、問題にする行為としても、情報解析用のデータベースの著作物の複製と言えるような行為については、30条の4ただし書に該当し、権利制限の対象とはならない場合があると、そういう趣旨の記載をしているというところでございます。
以上をまとめると、具体例2は、API を有償で利用することなく(②のAPIを利用することなく)、①のウェブサイトに閲覧用に掲載された記事等をクローリングすることで、「結果的に」②の情報解析用DB著作物を複製することについて述べているということになります。
被侵害著作物は②の「APIで提供されている情報解析用DB著作物」ですから、著作権侵害に該当するのは、当該DB著作物と、クローリングした結果としての学習用データセットとの間に「類似性」「依拠性」「権利制限規定に非該当」という要件がある場合のみ、ということになります(図35)。
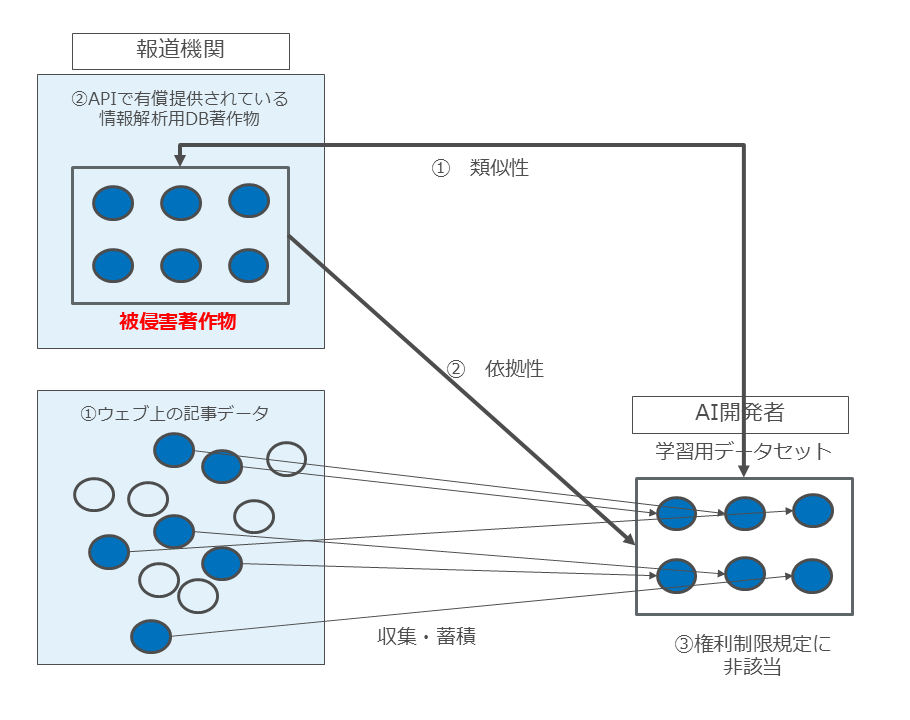
図35
まず前提として、報道機関がAPIで有償提供している記事DBが「情報解析用DB著作物」に該当することが必要です。
この点については、記事DBがDB著作物に該当しない場合はもちろん、記事DBが単なるDB著作物(単なる縮刷版記事DBなど享受目的を本来的目的として作成されたDB著作物)がAPI提供されていても、著作権侵害には該当しません。
記事DBが「情報解析用DB著作物」でなければ、30条の4柱書但書の趣旨である情報解析目的利用による「著作権者の著作物の利用市場との衝突」や「将来における著作物の潜在的販路の阻害」が起こらないためです。
そして、報道機関の提供している記事DBが情報解析用DB著作物に該当する可能性があるとすると、「取材により得た事実の中から、記事化に値する事実を選択した」という点に「情報の選択」における創作性が認められる場合ではないかと思われます7AI 開発のための学習用データセットのDB 著作物性について検討したものとして、新たな知財制度上の課題に
関する研究会編「新たな知財制度上の課題に関する研究会報告書」9頁〜16 頁。。
ただし、本当にそのような点に「情報の選択」における創作性が認められる場合があるかと考えると、かなり疑問です。
まず、他の新聞社も同様の事実を報道していれば、当該事実を記事化するための選択について「情報の選択」における創作性はないでしょう。
また、記事の掲載は「①世の中のありとあらゆる事実の中からの取材すべき事実の選択→②取材による多数の事実の収集→③取材により収集した多数の事実の中から記事として掲載するかの選択→④記事化」という流れによって行われるところ、記事DBにDB著作物としての著作物性が認められるのは、「③ 取材により収集した事実の中から記事として掲載するかの選択」に創作性がある場合のみであると考えます。
これは、①の「世の中のありとあらゆる事実の中から取材すべき事実の選択」における創作性は、そもそも「選択」が行われていないとも言えますし、仮にそのような「選択」における創作性があるとしても、当該創作性は侵害が問題となっている著作物としてのDB著作物の著作物性(情報選択の創作性)と直接結びついていないからです。
そして、「③ 取材により収集した事実の中から記事として掲載するかの選択」に創作性がある場合はかなり限定的でしょう。これは「取材された多数の事実を前提として、ニュースバリューのある記事を選択して記事化する」場合、ほとんどの報道機関において同様の選択が行われるだろうからです。
c 類似性
AI開発者が、Web上の個別の記事を集積して学習用データセットを作成したとしても、当該データセットにおいて、権利者がAPIを通じて有償で提供している情報解析用DB著作物の創作的表現部分を利用していなければ、類似性は否定されることになります831)「考え方」25 頁の具体例2についての説明においても「これを踏まえると、例えば、インターネット上のウェブサイトで、ユーザの閲覧に供するため記事等が提供されているのに加え、データベースの著作物から容易に情報解析に活用できる形で整理されたデータを取得できるAPI が有償で提供されている場合において、当該API を有償で利用することなく、当該ウェブサイトに閲覧用に掲載された記事等のデータから、当該データベースの著作物の創作的表現が認められる一定の情報のまとまりを情報解析目的で複製する行為は、本ただし書に該当し、同条による権利制限の対象とはならない場合があり得ると考えられる」と記載されている(下線部筆者)。。
たとえば、学習用データセットと情報解析用DB著作物との間で、一部しか記事の重複がない場合には、類似性が否定されます(図36)。
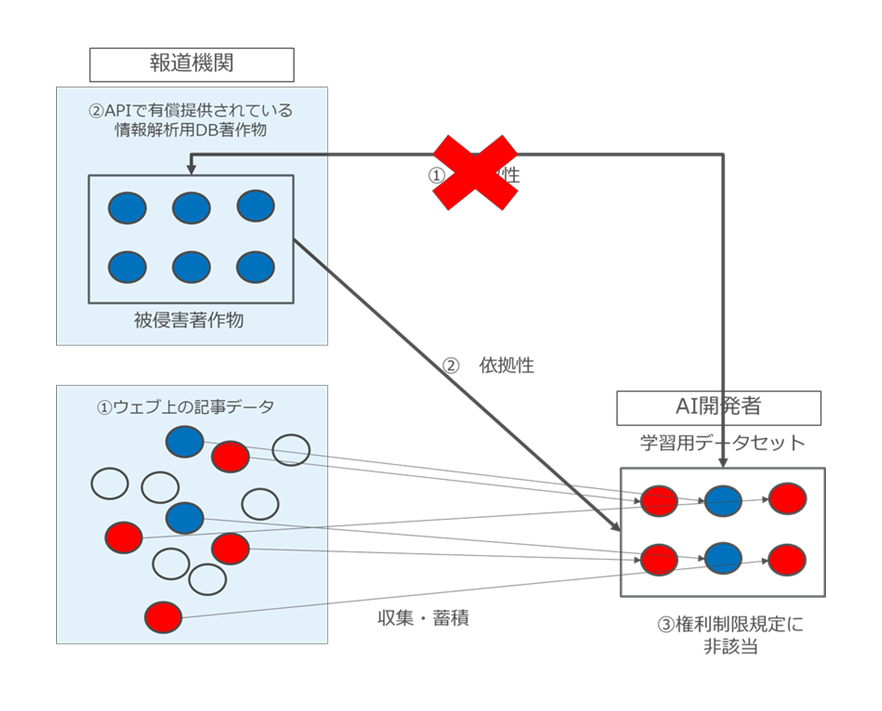
図36
AI開発者は、AI開発のために複数の報道機関のニュース記事や他のWEB上の文章をまとめて大規模に収集するのが通常ですから、1つの報道機関だけの、かつ当該報道機関のみが報道しているニュースのみをあえて対象にして収集して学習に用いることは非常に考えにくいでしょう。
そして、AI開発者が、複数の報道機関のニュース記事や他のWEB上の文章をまとめて大規模に収集して学習用データセットを作成して学習に用いた場合、当該報道機関の一部が公開している情報解析用DB著作物において、記事の選択に創作性が認められるとしても、当該創作的表現は利用されていない(類似性がない)ことになるのではないかと考えます。
d 依拠性
著作権侵害の要件として当然「依拠性」が必要となりますが、この場合の依拠性とは、被侵害対象著作物である情報解析用DB著作物への依拠性のことを指します。
しかし、具体例2においては、AI開発者は、情報解析用DB著作物には一切アクセスしておらず、被侵害対象著作物である情報解析用DB著作物とは異なる著作物であるウェブ上の個別記事を集積し、結果的に情報解析用DB著作物と同一・類似のDB著作物を作成しているに過ぎません。
また、この場合、AI開発者は、被侵害対象著作物である情報解析用DB著作物の内容(どのような点に「情報の選択における創作性があるか」)を知らないのが通常ではないかと思われます10個別記事のクローラーによる収集がrobots.txt で制限されている場合、当該個別記事を収集しようとする者は、当該制限の存在から、原告が情報解析用DB 著作物を販売している可能性があることや、記事内容を調査して知ろうと思えば知ることは可能である。したがって、当該調査を怠ること(過失)が「依拠性」につながるのかが問題となるが、判例(最一小判昭53・9・7民集32 巻6号1145 頁―ワン・レイニー・ナイト・イン・トーキョー事件)上は、「(前略)既存の著作物と同一性のある作品が作成されても、それが既存の著作物に依拠して再製されたものでないときは、その複製をしたことにはあたらず、著作権侵害の問題を生ずる余地はないところ、既存の著作物に接する機会がなく、従って、その存在、内容を知らなかった者は、これを知らなかったことにつき過失があると否とにかかわらず、既存の著作物に依拠した作品を再製するに由ないものであるから、既存の著作物と同一性のある作品を作成しても、これにより著作権侵害の責に任じなければならないものではない」としてその点を否定している。。
したがって、客観的にも主観的にも、被侵害著作物である情報解析用DB著作物への依拠性は認められないのではないかと考えます(図37)。
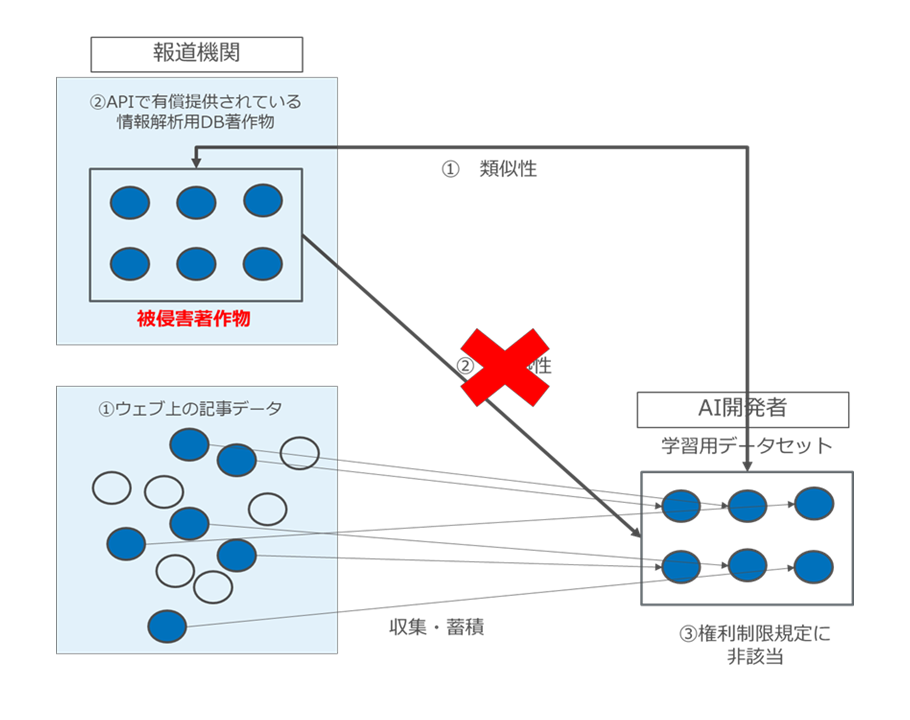
図37
以上をまとめると、具体例2において著作権侵害が生じるのは、①権利者がAPIを通じて有償で提供しているDBが情報解析用DB著作物に該当すること、及び②ウェブ上の記事データを収集することで、情報解析用DB著作物と創作的部分において同一・類似している学習用データセットを作成することが前提となっていますが、そのような「偶然」が生じる可能性は極めて低いでしょう。また、仮にそのような「偶然」が生じたとしても、情報解析用DB著作物への依拠性が認められがたいことから、具体例2が著作権侵害に該当する可能性は非常に低いのではないかと考えます。「考え方」では、具体例2は、30条の4柱書但書に該当する例として紹介されていますが、そもそも30条の4柱書但書の問題(権利制限規定適用可否の問題)に行く前の、被侵害著作物の著作物性、類似性、依拠性が認められないことがほとんどではないかというのが筆者の意見です。
③ 具体例3
具体例3を図示すると以下のとおりとなります(図38)。
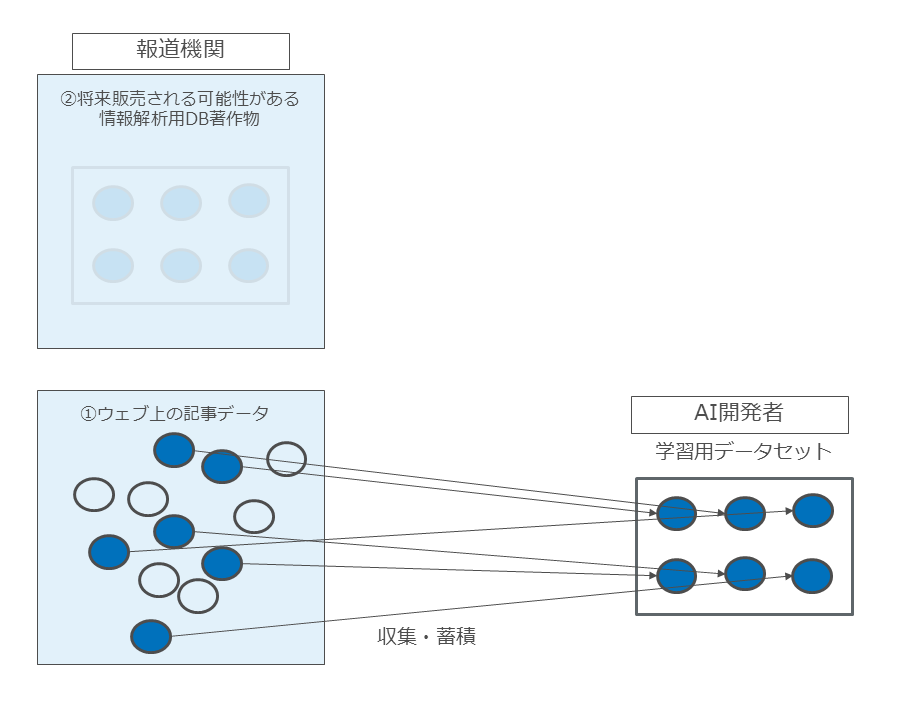
図38
具体例3についても、具体例2と同様、著作権侵害に該当するのは、被侵害著作物である「将来販売される予定がある情報解析用DB著作物」と、クローリングした結果としての学習用データセットとの間に「類似性」「依拠性」「権利制限規定に非該当」という要件がある場合のみ、ということになります(図39)。
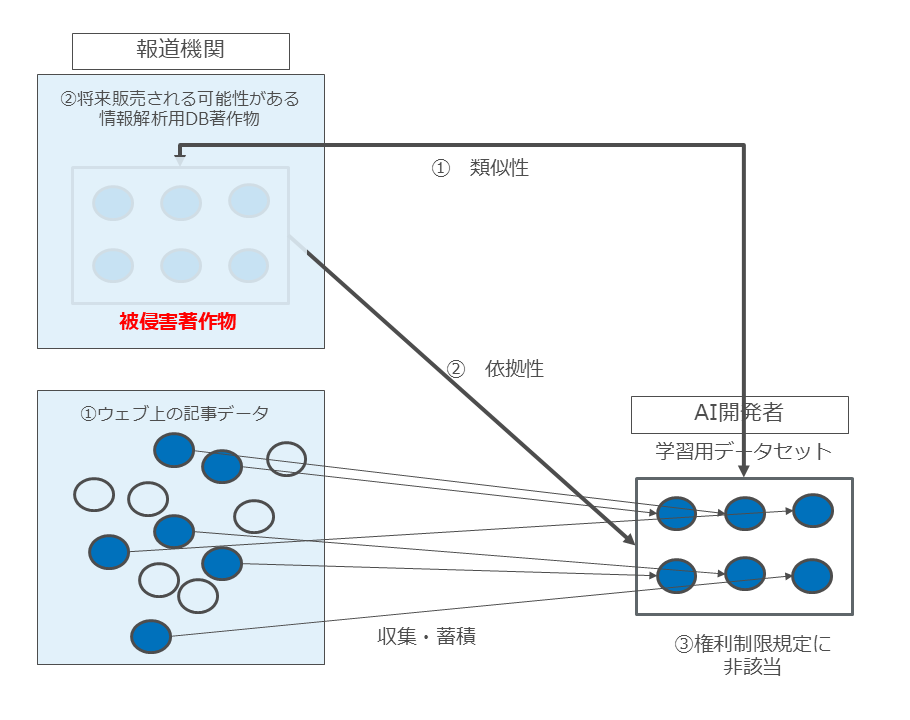
図39
更に具体例3については、「被侵害対象著作物としての情報解析用DB著作物が、まだこの世に存在していない」という点が、権利者がクリアすべき高いハードルとして立ちはだかります。
a 「考え方」の記載
「考え方」26頁は、この点について「当該ウェブサイト内のデータを含み、情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることが推認される場合」であれば、当該「将来販売される予定がある情報解析用DB著作物」との関係で著作権侵害の要件を満たす(30条の4柱書但書に該当する)としています。
b 「将来販売される予定の被侵害著作物」に関する著作権侵害がありうるのか
しかし、まず素朴な疑問として、AI開発者による個々のWeb記事の収集によって、当該収集時点においては未だ存在していない「将来販売される予定の情報解析用DB著作物」の著作権侵害(類似性・依拠性)が認められるのかという点があります。
このように「将来販売される可能性がある情報解析用DB著作物」の将来販路が阻害されることを理由に個々のウェブ記事の収集行為が30条の4柱書但書に該当するという「考え方」の解釈は、実質的には、現時点では存在しない、将来発生する可能性のある被侵害著作物についての著作権侵害を認める解釈です。
まだ存在していない被侵害著作物ですから、著作権侵害の有無を判断しようにも、そもそも、当該被侵害著作物が「情報解析用DB著作物」に該当するかや、著作権侵害の要件である「類似性」や「依拠性」を満たすかを判断しようがないのではないでしょうか。
確かに、著作物自体が未だに発生しておらず、かつ侵害行為も行われていない段階での侵害行為の予防的な差止請求を認めた裁判例は存在します(東京地判平5・8・30知的裁集25巻2号380頁(ウォール・ストリート・ジャーナル事件)。
この決定は、米国において日刊新聞 The Wall Street Journal(「本件新聞」)を継続して発行する X(債権者・被控訴人)が、わが国において本件新聞の記事を抄訳して紙面構成に対応して配列した文書(以下「本件文書」という)を募集した会員に作成・頒布する Y(債務者・控訴人)に対し、本件文書の作成・頒布は、債権者の本件新聞について有する編集著作権を侵害するとして申し立てた本件文書の作成・頒布の差止仮処分が認められた事案です。
この事件では、申立時点ではまだ存在していない、将来作成される著作物(=本件新聞)の編集著作権に基づく差止めの可否等が問題となりましたが、裁判所は差し止めを認めました。
しかし、この事件は、過去に具体的な編集著作権侵害行為が継続して行われていたことを根拠として、将来的に同様の著作権侵害が発生する可能性が相当高度であることを認め、その結果差止請求を認めたものにすぎず、一般化することはできません。
現に同裁判例については、「被侵害著作物が未だ存在しない場合の差止請求は極めて例外的であり,同判決は一般化できないであろう」と評価されています11中山信弘『著作権法 第4版』(有斐閣、2023)756 頁。
したがって、同裁判例を根拠として、将来販売される可能性がある情報解析用DB著作物についての著作権侵害が認められることはないと考えます。
c どのような場合に「将来販売される予定」が推認されるのか
次の問題は、「どのような場合に「将来販売される予定」が推認されるのか」です。当然のことですが、単に権利者が「自分はこのウェブ上の記事を将来情報解析用DB著作物として販売する予定である」と宣言すればそのような推認が得られるわけではありません。
この点について、考え方26頁は「当該ウェブサイト内のデータを含み、情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることを推認させる事実」として、「AI 学習のための著作物の複製等を防止する技術的な措置(”robots.txt”への記述など)が講じられており、かつ、このような措置が講じられていることや、過去の実績(情報解析に活用できる形で整理したデータベースの著作物の作成実績や、そのライセンス取引に関する実績等)といった事実」があるとしています。
すなわち、robots.txtによるアクセス制限がなされているという事実そのものによって30条の4柱書但書に該当するとしているのではなく、あくまでそのような事実によって「情報解析用DB著作物が将来販売されることが推認される」というだけの話です。
しかし、これらの事実のうち「「AI 学習のための著作物の複製等を防止する技術的な措置が講じられていること」は、単に「学習を防止したいという意思が著作権者にある」ことを推認させるだけであり12そして著作権者がそのような学習防止意思を示していることをもって権利制限規定の対象から除外されることにはならないことは「考え方」26 頁に明記されている。、「情報解析用DB著作物の販売予定があること」を推認させる事実にはならないと考えます。
また、過去の販売実績が仮にあるケースであっても、どの程度直近の「実績」があれば「情報解析用DB著作物の販売予定があること」が推認されるのか、その「推認」はどの程度の期間続くのかが全く明らかではありません。
ある行為が30条の4柱書但書に該当する(権利制限規定の対象から除外される)ということは、当該行為が刑事罰もある著作権侵害行為に該当する可能性があることを意味しているため、その解釈が曖昧であってはなりません。
そのような観点からすると「考え方」26頁に記載されているような「推認」を安易に認めるべきではないと考えます。
脚注一覧
- 124)「考え方」23 頁、文化庁著作権課「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する本的な考え方(著作権法第30 条の4、第47 条の4及び第47 条の5関係)」令和元年10 月24 日・問9(9頁)
- 2「考え方」24頁
- 3前掲注24)「基本的な考え方」問9(9頁)。ただし、「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に、当該データベースを情報解析目的で複製等する行為」については、30 条の4柱書但書の問題ではなく、当該データベース著作物の本来的利用であるとして享受目的併存により30 条の4が適用されない、という説もある(前田健「生成AI の利用が著作権侵害となる場合」法学教室523 号(2024)30 頁、『AI と著作権』231 頁〔前田発言〕)
- 427)『AI と著作権』231 頁〔奥邨発言〕「一方で、例えば、一般的な印刷用とかウェブサイトの挿絵用とかでライセンスされているフォトストックのデータベースだと、著作物の種類はデータベースでも、用途は観賞用、利用態様は、情報解析用機器で全部複製する、という当てはめになります。これは、元々、柱書本文がやってもいいよと書いてあることをやっているだけなので、不当に害する余地はない、大丈夫じゃないかなと私は思います。」
- 5なお「考え方」25 頁脚注28 には「この点に関して、インターネット上のウェブサイトに掲載されたデータについては、AI 学習のための複製を行うクローラによるウェブサイト内へのアクセスが、後述するウェブサイト内のファイル“robots.txt” への記述により制限されていない場合、「(大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が)販売されている場合」に該当しないことを推認させる要素となるものと考えられる」との記載がある。この記載内容は合理的であるが、このような技術的制限が講じられていない事実は、パターン3における「情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があること」に該
当しないことを推認させる要素にもなると思われる(パブコメ191 参照)。 - 6中山信弘『著作権法 第4版』(有斐閣、2023)179 頁は「著作権侵害は、基本的には創作性のある部分が侵害された場合に生ずるが、データベースの創作性は情報の選択または体系的構成にあるので、抽象的にいえば、他の者が無断利用した部分が、情報の選択または体系的構成という観点から創作性があると認められる場合に著作権侵害となるが、具体的には個別的な事例ごとに判断され、その事例の集積を待って基準が明らかとなろう。他人のデータベースから、体系的な構成を模倣することはせず、相当量のデータだけを抽出し、自己の体系を構築したような場合には、利用した情報のひとかたまりには「情報の選択」という観点から、データベース作成者の創作性がないであろう」とする。
- 7AI 開発のための学習用データセットのDB 著作物性について検討したものとして、新たな知財制度上の課題に
関する研究会編「新たな知財制度上の課題に関する研究会報告書」9頁〜16 頁。 - 831)「考え方」25 頁の具体例2についての説明においても「これを踏まえると、例えば、インターネット上のウェブサイトで、ユーザの閲覧に供するため記事等が提供されているのに加え、データベースの著作物から容易に情報解析に活用できる形で整理されたデータを取得できるAPI が有償で提供されている場合において、当該API を有償で利用することなく、当該ウェブサイトに閲覧用に掲載された記事等のデータから、当該データベースの著作物の創作的表現が認められる一定の情報のまとまりを情報解析目的で複製する行為は、本ただし書に該当し、同条による権利制限の対象とはならない場合があり得ると考えられる」と記載されている(下線部筆者)。
- 9中山信弘『著作権法 第4版』(有斐閣、2023)174 頁は「データベースの場合、ある方針が決まればある程度の情報の重複は必然であって、その重複をもって侵害であるとすると、「情報収集の方針」自体が保護されるに等しいことになり、それは著作権法では保護されないアイディアを保護することに繋がる。従って、データベースにおける情報の選択とは、小説・音楽等の著作物とは異なり、他人のデータベースのかなりの部分が同一であっても、それだけで侵害を認めると、より良い後発のデータベースの参入障壁となり、却ってデータベースの発展を妨げることになりかねない。技術の場合と同様に、データベースには積み上げ的要素があるという点を忘れてはならない。どの程度の重複まで許されるのか、という点は一概には決定できないが、小説や音楽の場合と比して、重複が許される範囲は各段に広いということは言えよう。その結果、多くの情報が同一であるとしても、誰が行っても類似のものにならざるを得ないのか、あるいは類似のものが既に存在しているのか、という点を注意深く検討する必要がある。」とする。
- 10個別記事のクローラーによる収集がrobots.txt で制限されている場合、当該個別記事を収集しようとする者は、当該制限の存在から、原告が情報解析用DB 著作物を販売している可能性があることや、記事内容を調査して知ろうと思えば知ることは可能である。したがって、当該調査を怠ること(過失)が「依拠性」につながるのかが問題となるが、判例(最一小判昭53・9・7民集32 巻6号1145 頁―ワン・レイニー・ナイト・イン・トーキョー事件)上は、「(前略)既存の著作物と同一性のある作品が作成されても、それが既存の著作物に依拠して再製されたものでないときは、その複製をしたことにはあたらず、著作権侵害の問題を生ずる余地はないところ、既存の著作物に接する機会がなく、従って、その存在、内容を知らなかった者は、これを知らなかったことにつき過失があると否とにかかわらず、既存の著作物に依拠した作品を再製するに由ないものであるから、既存の著作物と同一性のある作品を作成しても、これにより著作権侵害の責に任じなければならないものではない」としてその点を否定している。
- 11中山信弘『著作権法 第4版』(有斐閣、2023)756 頁
- 12そして著作権者がそのような学習防止意思を示していることをもって権利制限規定の対象から除外されることにはならないことは「考え方」26 頁に明記されている。
この記事の内容を、対話形式の音声で聞くことができます。
▶ 対話形式で聞く
※ 対話形式の音声はNotebookLMを利用して自動的に作成したものです。正確な内容は記事本文をご参照ください。












