人工知能(AI)、ビッグデータ法務 著作権
AIと著作権【第12回】RAG・ロングコンテクストLLMと著作権侵害(前編)

2025年7月にSTORIA法律事務所の柿沼・杉浦の共著で日本加除出版から書籍「AIと法 実務大全」を出版します。
本書は650頁超というボリュームでありながらも、AI開発や利活用に問題となる点を「網羅的」に解説するものではありません。あくまで、現場の方がAI開発や利活用を行う際に、法律的によく問題となる論点とその解決手法に照準を絞っています。その分個々の論点については、最先端の議論を下敷きにしつつ実務的に相当深掘りした記述となっています。
書籍の出版に先立ち、その一部である「第2章 生成AI開発・提供・利用と著作権」について日本加除出版からご了解を得て、ブログで連載記事として先行公開することとしました。
「一部」といっても記事合計13万字を越えるボリューム(ほぼ新書1冊分!)であり、ブログ公開を快諾いただいた日本加除出版には感謝しかありません。
この連載記事を読んで興味が湧いた方は是非書籍をお買い求めください!
連載「AIと著作権」全18回の目次を表示
- 第1回 プレイヤー・フェーズ・提供形態による法的整理
- 第2回 AI学習段階での著作物利用はどこまで許されるか?──著作権法第30条の4の射程
- 第3回 学習用データとして“何を使ってはいけないか”を見極める~学習対象の観点からの検討~
- 第4回 海賊版や学習禁止表示がされている著作物をAI学習に利用することができるか
- 第5回 開発・学習段階での著作権侵害行為が発生した場合、侵害者はどのような責任を負うか
- 第6回 生成・利用段階では何が問題になるのか?
- 第7回 類似AI生成物の「生成」における依拠性をどのように考えるか~複雑な論点を解きほぐす~
- 第8回 類似AI生成物の「生成」における行為主体性~ロクラクⅡ事件判決をベースに徹底的に考える~
- 第9回 生成された類似AI生成物を利用すると著作権侵害?
- 第10回 類似AI生成物の「送信」は誰の責任?──クラウド提供型AIにおける著作権侵害リスクを検証する
- 第11回 生成・利用段階で著作権侵害行為が認められた場合、権利者は何を請求できるのか
- 第12回 RAG・ロングコンテクストLLMと著作権侵害(前編)
- 第13回 RAG・ロングコンテクストLLMと著作権侵害(後編)
- 第14回 RAGシステムのための既存著作物の蓄積・入力などは著作権侵害になるのか
- 第15回 RAGとAI利用者の責任~入力・送信・出力のそれぞれで何が問われるか?~
- 第16回 AI生成物に著作権はあるのか?~著作物性と“創作的寄与”の最新実務論~
- 第17回 その行為に日本著作権法は適用されるか~準拠法の問題~
- 第18回 で、結局何に気をつければよいのか~AI開発者・AI提供者・AI利用者それぞれの注意事項~
🔊 音声で内容を復習する
この記事の内容を、対話形式の音声で聞くことができます。
▶ 対話形式で聞く
※ 対話形式の音声はNotebookLMを利用して自動的に作成したものです。正確な内容は記事本文をご参照ください。
4 RAG・ロングコンテクストLLMと著作権侵害1ここで述べている内容は、RAG だけではなく、ロングコンテクストLLM にも同じく当てはまる。ロングコンテクストLLM とは、数千から数万語、あるいはそれ以上のテキストをAI(LLM)に入力して処理をする仕組みである。従前の技術ではそれほど大量のテキストデータをAI に入力することはできなかったが(それゆえに「関連する情報のみを検索・抽出して入力する」というRAG が考案された)、技術発展により可能となった。そのため、RAG とロングコンテクストLLM の相違は「AI(LLM)に入力される著作物の量の違い」でしかなく、著作権法という観点から見ると差分はない。したがって、「4 RAG・ロングコンテクストLLM と著作権侵害」で述べている内容はRAG だけではなくロングコンテクストLLM にも等しく当てはまる。
(1) RAG(Retrieval Augmented Generation、検索拡張生成)とは
顧客向けチャットボットや、社内 FAQ 等で生成 AI を利用する場合、大規模言語モデル(LLM)をそのまま利用すると回答精度が十分でなかったり、回答の根拠が明示できないという問題があります。その場合に利用される手法の1つが RAG(Retrieval Augmented Generation、検索拡張生成)です。
RAGとは、LLMによる回答を生成する際に参照したい外部情報2ここでは、「外部情報」を、LLM の外部にある情報という意味で用いている。 をベクトルデータベースとして蓄積しておいて、ユーザが質問文を入力すると、同質問文と関連性が高い外部情報を検索した上で、質問文と外部情報をLLMに入力して回答を生成するという仕組みです。これにより、精度が高い、かつ実際の外部情報に紐付いた回答を生成することができるとされています(図 66)。
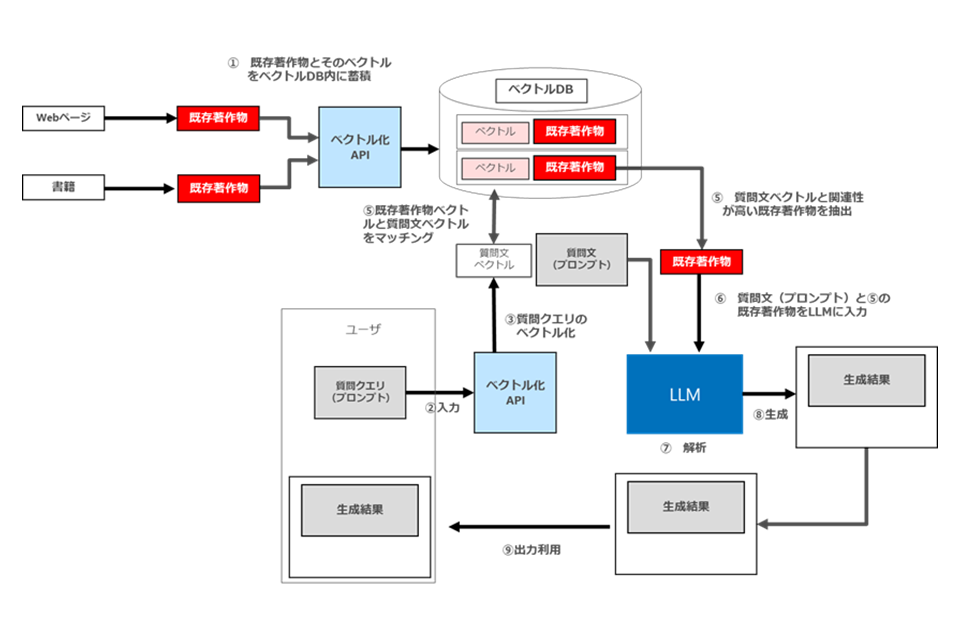
図66
(2) RAGにおいて著作権侵害が問題となる著作物の利用行為
RAGを非常にシンプルに言うと、「既存の著作物を蓄積したうえで、AI利用者の質問と関連性が高い著作物を検索・抽出し、当該抽出著作物をLLMに入力して回答を生成する仕組み」です
したがって、RAGにおいて著作権侵害が問題となる著作物の利用行為は2つありますが、いずれも生成・利用段階で行われる行為です。
1つは、既存著作物の蓄積・入力行為です。これは、RAGにおいて検索対象となる既存著作物を蓄積し、指示に応じてAIモデルに入力する行為です(図67)。
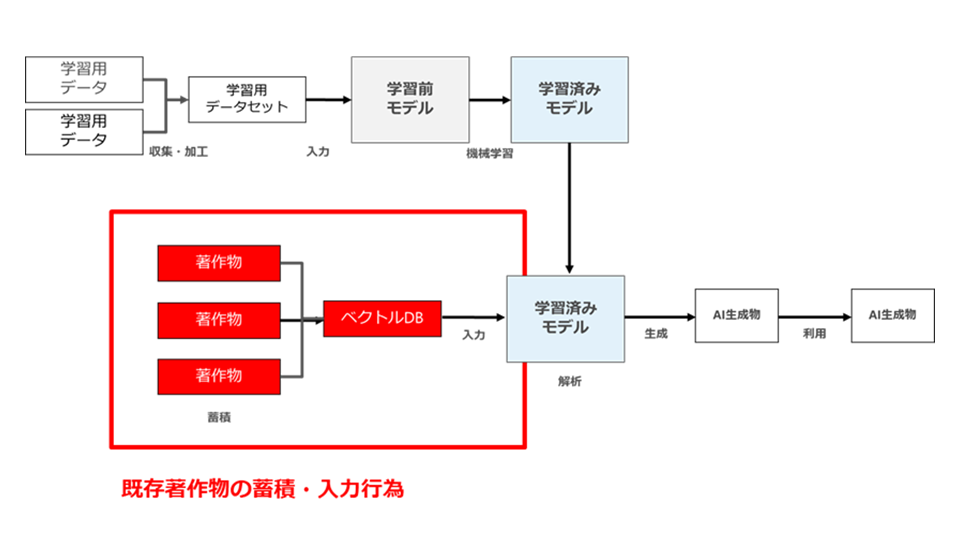
図67
もう1つは、入力された既存著作物と同一・類似のAI生成物の生成・利用行為です。
RAGにおいては、生成結果として、入力された既存著作物と同一・類似物が出力されることがあります。これは、先ほどの「既存著作物の蓄積・入力行為」とは別の、当該既存著作物の利用行為です(図68)。
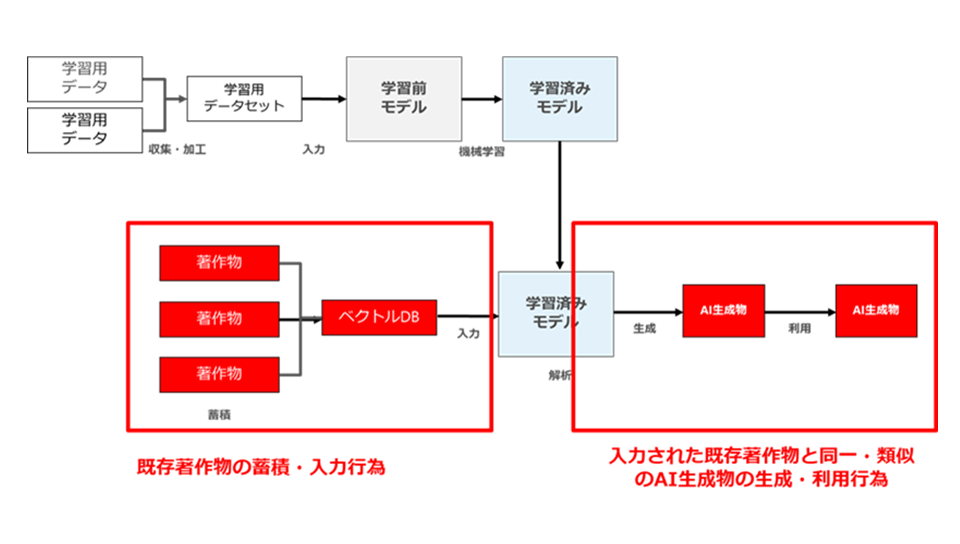
図68
■コラム RAGとライセンス・契約違反
この後詳細に説明をしますが、RAGにおいては、入力された既存著作物の同一・類似物の出力目的がなければ、基本的に既存著作物の蓄積・入力は著作権法上は適法です。もっとも、契約やライセンス違反には注意する必要があります。
たとえば、有料のジャーナルの場合、当該ジャーナルの利用規約やライセンス上は、RAGのような形式でジャーナル内の論文データを利用することが禁止されているのが通常です。
そのような論文データを利用してRAGを構築した場合、著作権法上は適法でも契約違反・ライセンス違反に該当することになりますので、注意して下さい。
また、誰がRAGの構築・提供をしているかという面から見ると、そのバリエーションは様々です。
たとえば、AI提供者自身がRAGの対象著作物を収集・蓄積し、SaaS形式でAI利用者にRAGをサービスとして提供している場合を簡略化して示すと以下のような構成になります(図69)。
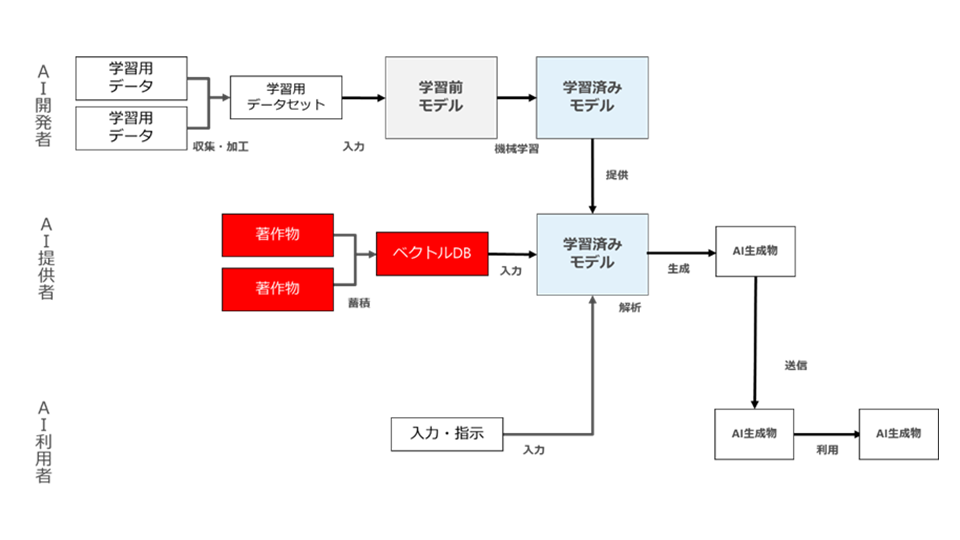
図69
この場合は、AI提供者が、生成・利用段階において、物理的に対象著作物の利用行為(具体的には対象著作物の収集・蓄積及びAIへの入力行為)を行っていることになります。
一方、AI提供者は、RAGのオンプレミスのシステム(いわば「ガワ」)だけを提供し、AI利用者自身がRAGにおける入力対象著作物の収集・蓄積等を行う場合もあります。
この場合は以下のような構成になります(図70)。
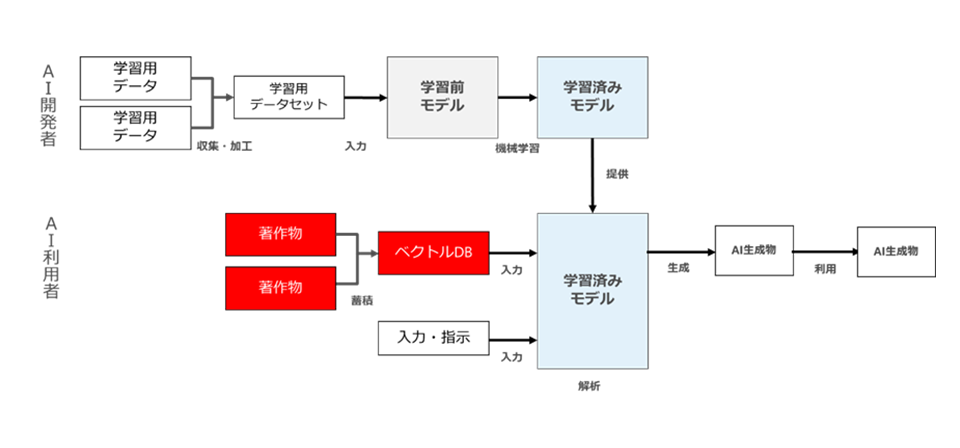
図70
(3) RAGの分類
上述のように RAGにおいて著作権侵害が問題となる著作物の利用行為は2つ(①蓄積・入力行為と②同一・類似AI生成物の生成・利用)あるのですが、著作権侵害に該当するか、及び誰が著作権侵害の責任を負うかを検討するに際して、RAGを3つの視点から8つのタイプに分類します(表12)。
3つの視点とは、①入力対象著作物と同一・類似物の出力目的があるか②入力対象著作物をAI提供者とAI利用者のどちらが収集・蓄積しているか③ローカルかSaaSか、です。
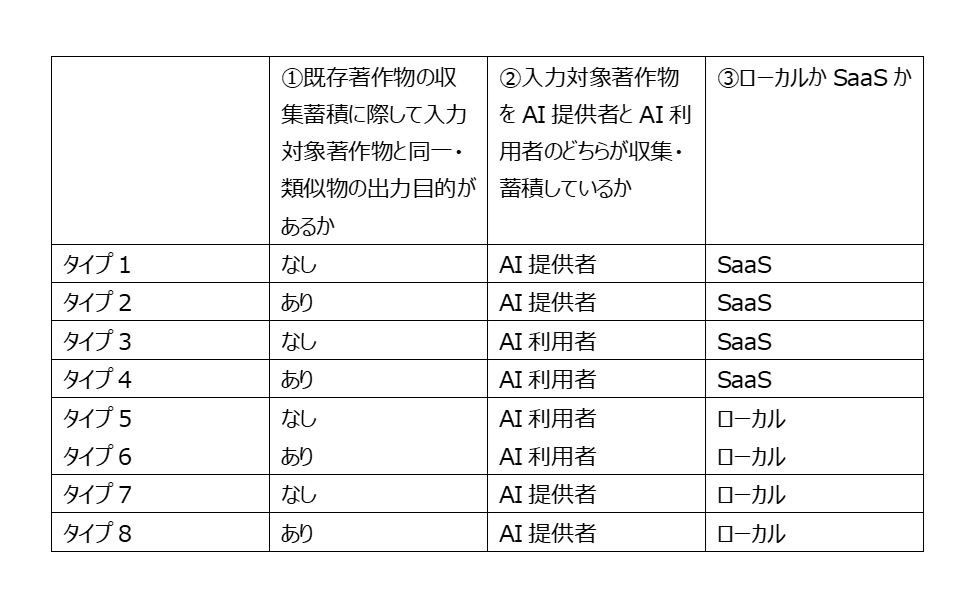
表12
RAGにおいては、出力の中に出力生成の根拠となった入力対象著作物の同一・類似物が含まれていた方が利便性が高いため、後者のタイプが採用されることもあります。このタイプの場合でも、RAGの提供者・利用者自身が著作権を持っている、あるいは利用許諾を受けている既存著作物を利用する際には問題は生じません。
一方、詳細は後述しますが、入力対象著作物と同一・類似物の出力目的がある場合は、既存著作物の蓄積・入力行為に著作権法30条の4の適用がありません。そのため、RAGの提供者・利用者自身が著作権を持っている、あるいは利用許諾を受けている著作物「以外の」著作物を利用する際には、その点をどうクリアするかが問題となります。
②の「入力対象著作物をAI提供者とAI利用者のどちらが収集・蓄積しているか」には、AI提供者とAI利用者がそれぞれどのような著作物利用行為を行っているか、及び仮に著作権侵害が生じた場合にAI提供者とAI利用者のどちらが行為主体に該当するかに影響します。
③の「ローカルかSaaSか」は、AI提供者が入力対象著作物DBやAIをAI利用者に提供し、AI利用者の手元で検索・生成行為が行われている(ローカル)と、AI提供者がAI利用者にクラウドサービスとしてRAGを提供している(SaaS)を区別します。この点も、AI提供者とAI利用者がそれぞれどのような著作物利用行為を行っているか、及び仮に著作権侵害が生じた場合にAI提供者とAI利用者のどちらが著作権侵害の責任を負うかに影響します。
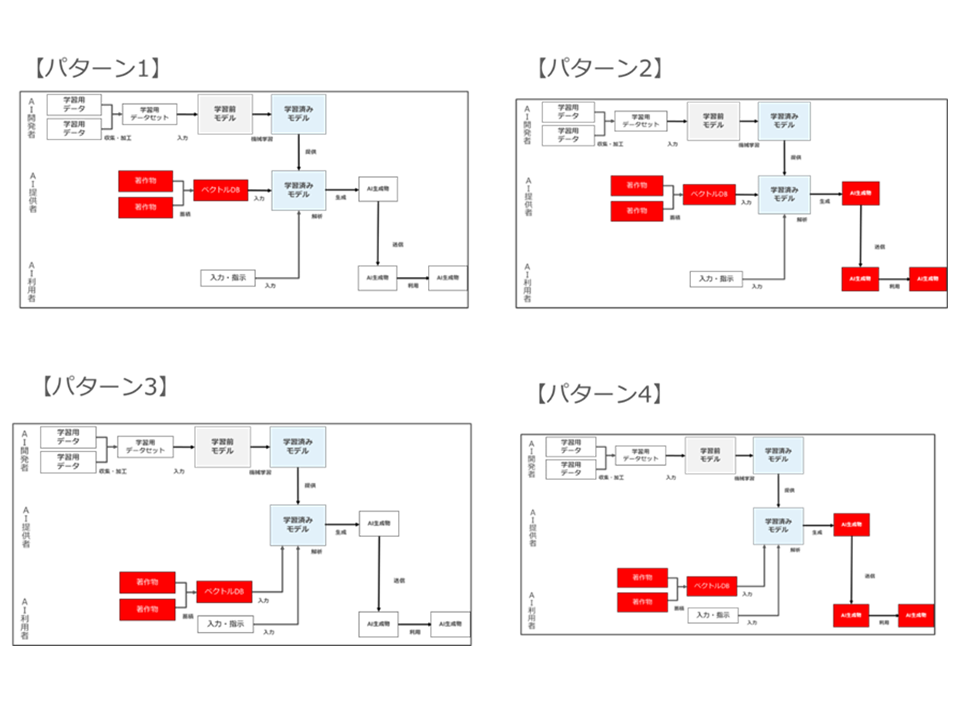
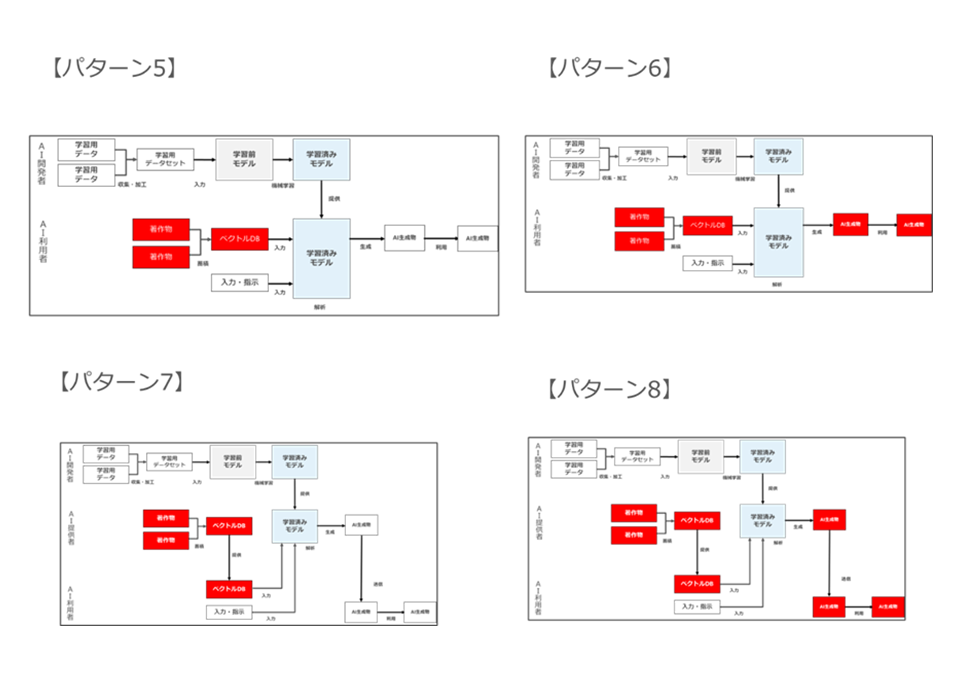
以下、これらのタイプ1~タイプ8のRAGについて、① 既存著作物の蓄積・入力行為が著作権侵害に該当しないか、② 入力された既存著作物と同一・類似のAI生成物の生成・利用行為が著作権侵害に該当しないかについて検討します。
脚注一覧
- 1ここで述べている内容は、RAG だけではなく、ロングコンテクストLLM にも同じく当てはまる。ロングコンテクストLLM とは、数千から数万語、あるいはそれ以上のテキストをAI(LLM)に入力して処理をする仕組みである。従前の技術ではそれほど大量のテキストデータをAI に入力することはできなかったが(それゆえに「関連する情報のみを検索・抽出して入力する」というRAG が考案された)、技術発展により可能となった。そのため、RAG とロングコンテクストLLM の相違は「AI(LLM)に入力される著作物の量の違い」でしかなく、著作権法という観点から見ると差分はない。したがって、「4 RAG・ロングコンテクストLLM と著作権侵害」で述べている内容はRAG だけではなくロングコンテクストLLM にも等しく当てはまる。
- 2ここでは、「外部情報」を、LLM の外部にある情報という意味で用いている。
この記事の内容を、対話形式の音声で聞くことができます。
▶ 対話形式で聞く
※ 対話形式の音声はNotebookLMを利用して自動的に作成したものです。正確な内容は記事本文をご参照ください。












