人工知能(AI)、ビッグデータ法務 著作権
LLMを利用したRAG(Retrieval Augmented Generation)と著作権侵害

Contents
1 はじめに
近時、LLMを利用し、社内外の文書データを用いた精度の高いチャットボットを構築するために、RAG(Retrieval Augmented Generation)という手法が注目されています。
LLMをそのまま利用してチャットボットの構築を行うと、通常、LLMが学習したときのデータに含まれている内容以外に関する質問には回答ができないか、あるいは正しくない回答を返してしまいます。
この問題を解決する手法として注目されているのがRAGです。
この手法は、あらかじめ社内外の文書データをデータベース(DB)として準備しておき、ユーザからの質問がなされた場合には、当該質問と関連性が高い文書データを検索し、その文章データを質問文に付加してLLMに入力することで、精度が高い、かつ実際の文書データに紐付いた回答を生成することができるというものです。
ここで、プロンプトに入力するためにDBとして用意する社内外の文書データとしては、当該ユーザー自身が著作権を有する著作物(例:社内で蓄積された既存FAQなど)や、第三者が著作権を有する著作物(WEBページや書籍等)が考えられます。
今回は、このRAGと著作権法の問題について検討をします。
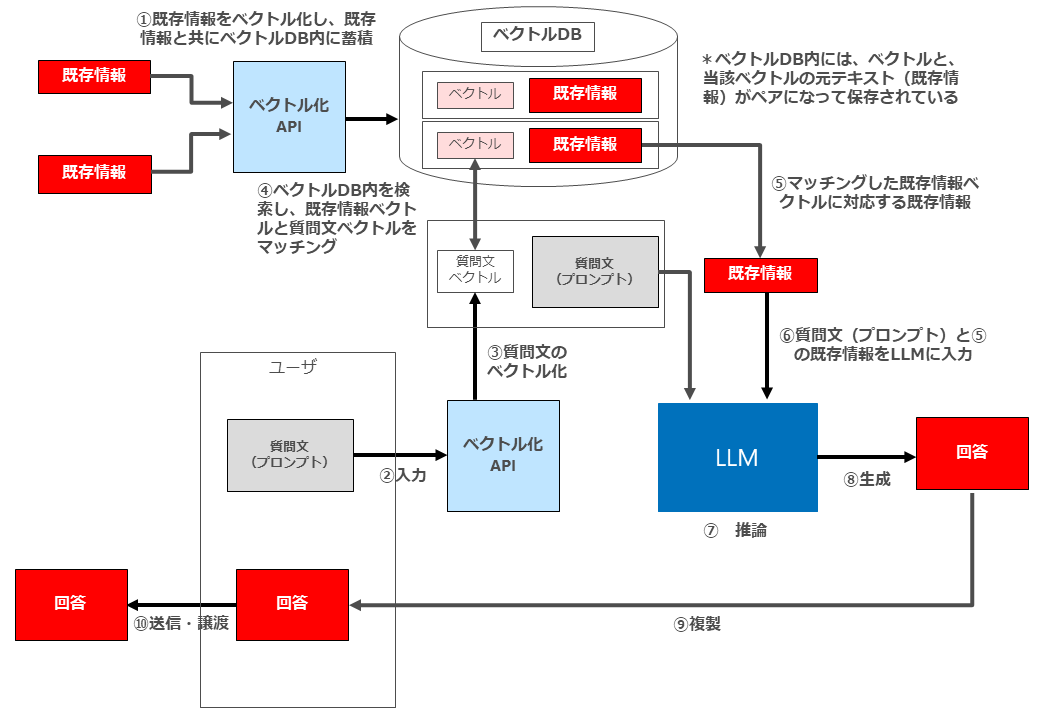
まず、RAGのシステム構成例は以下のとおりです。
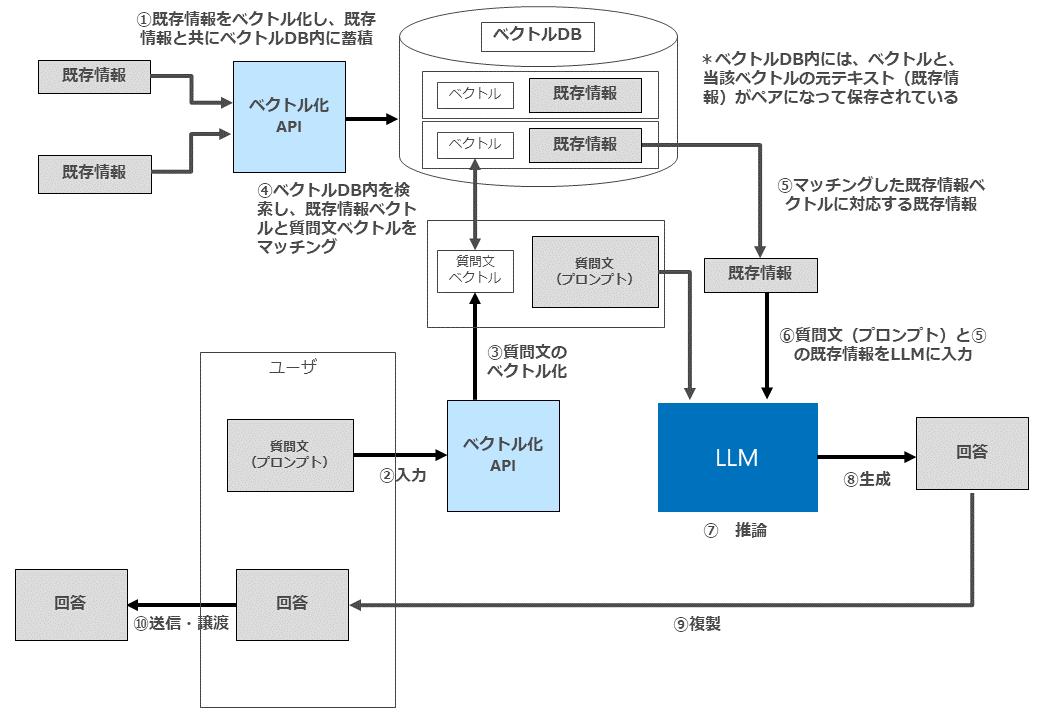
① 既存情報をベクトル化し、既存情報と共にベクトルDB内に蓄積
② ユーザーがプロンプトとして質問文を入力
③ ②で入力された質問文をベクトル化
④ ベクトルDB内を検索し、既存情報ベクトルと質問文ベクトルをマッチング
⑤⑥ マッチングした既存情報ベクトルに対応する既存情報を質問文と共にLLMに入力
⑦⑧ 回答生成・出力
ここで、「既存情報」として当該ユーザー自身が著作権を有する著作物を利用する場合は特に著作権法上の問題は起こりません。
2 RAGと著作権侵害
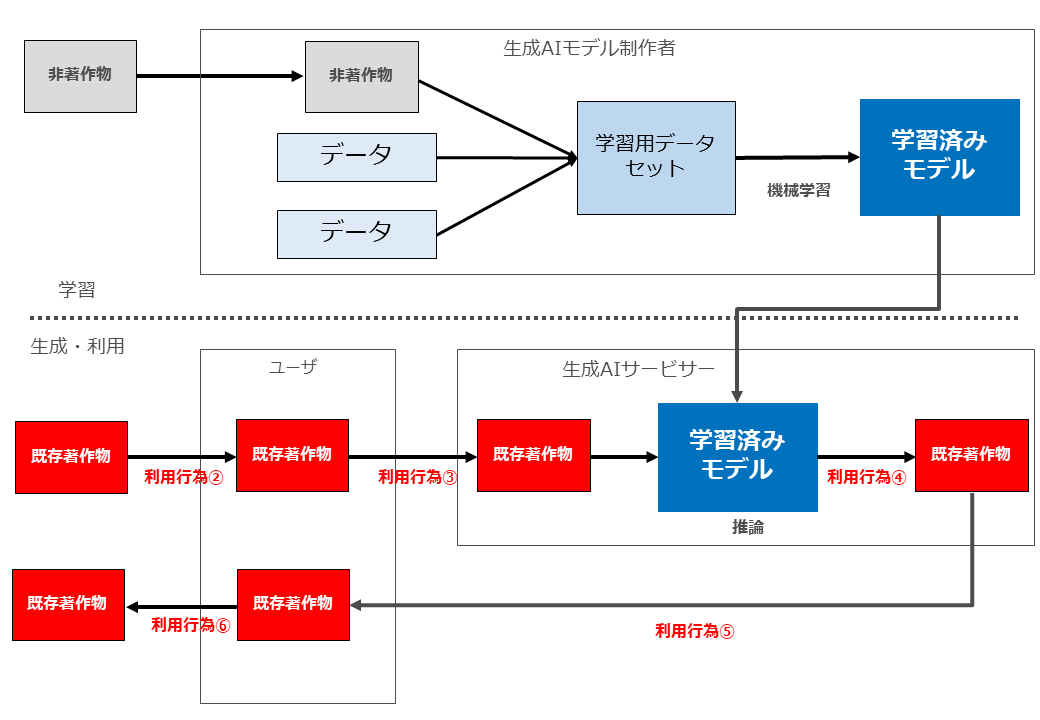
問題は、「既存情報」として第三者の著作物を利用する場合です。
この場合、「既存情報」をベクトルデーターベースとして蓄積したり(下図①)、マッチングした既存情報をLLMへプロンプトとして入力する行為(下図⑤⑥)が行われます。
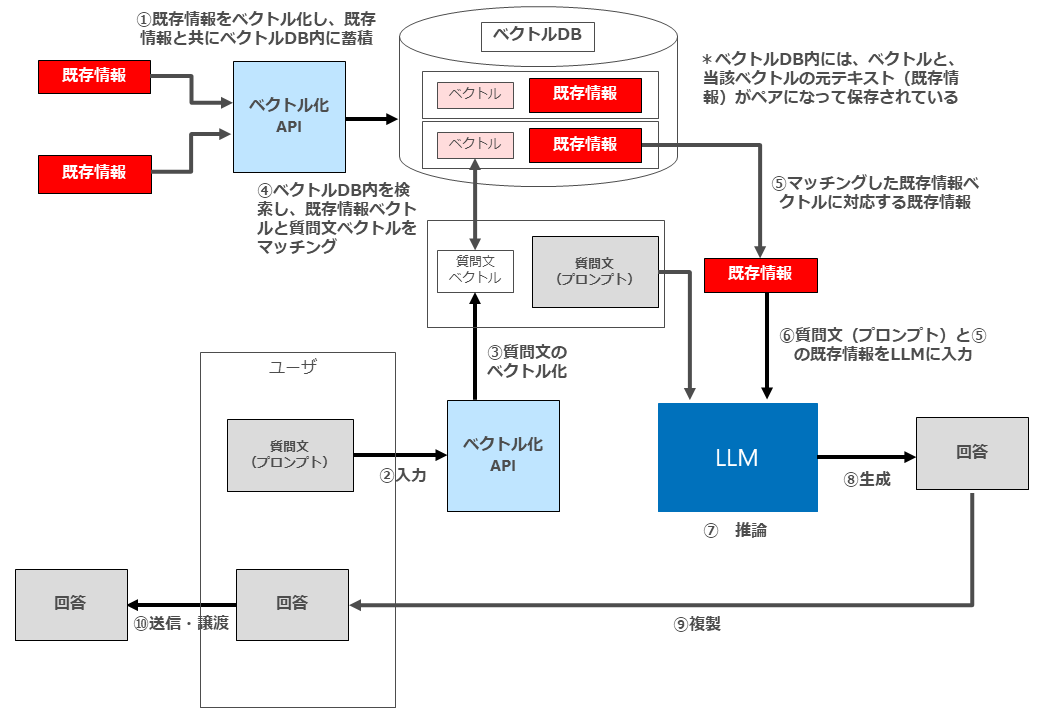
これらの行為は、いずれも既存情報という第三者の著作物を複製等する行為ですので、原則として著作権者の許諾がなければ行うことができません。
では、既存情報(入力情報)として第三者の著作物を利用したRAGは一切行うことができないのでしょうか。
この点については、まだほとんど議論されていませんが、私は以下のとおり考えています。
① 第三者の著作物をLLMへの入力情報としてのみ利用し、出力として、入力対象著作物の表現上の本質的特徴を有する回答(AI生成物)が生成されていないケースは著作権法30条の4第2号・第3号により適法だが
② 出力(LLMによる回答)として、入力対象著作物の表現上の本質的特徴を有するAI生成物を生成・利用する行為は著作権侵害に該当する
(1) 既存著作物のLLMへの入力行為は著作権法30条の4により原則として適法
ここで行われている著作物の利用行為は、「LLMによる回答生成のために、第三者の著作物をベクトルデーターベースとして蓄積したり(上記図①)、マッチングした著作物をLLMへプロンプトとして入力する(上記図⑤⑥)」行為です。
まず「LLMによる回答生成」のための、LLM内部での入力プロンプトの解析行為(上記図⑦)は、「情報解析」(著作権法30条の4第2号)に該当します。
そして、著作権法30条の4は「(情報解析に)必要と認められる」著作物の利用行為を行うことは、原則として著作権侵害に該当しないとしています。
したがって、第三者の著作物をベクトルデーターベースとして蓄積したり(上記図①)、マッチングした著作物をLLMへプロンプトとして入力する行為(上記図⑤⑥)は、いずれも「LLMによる回答生成」のための、入力プロンプトの解析行為(上記図⑦=情報解析)に必要と認められる行為ですから著作権法30条の4により原則として適法であるということになります。
もっとも、2つの例外があります。
1つは「入力行為に享受目的が併存している場合」、もう1つは「30条の4但書」に該当する場合です。
これらの場合はいずれも30条の4の本文が適用されず、入力行為は著作権侵害に該当することになります。このうち、LLMに既存著作物を入力する行為が30条の4但書に該当することは通常考えられませんので、その点に関する説明は割愛し、以下「入力行為に享受目的が併存している場合」について検討します。
(2) 入力行為に享受目的が併存している場合はNGだが・・
まず、著作権法30条の4は、著作物の非享受目的の利用行為に関する権利制限規定ですから、利用行為に、対象著作物の享受目的が併存している場合は適用されません(なお、この論点は、入力行為(推論行為)だけでなく学習行為においても問題になりますが、ここでは入力行為(推論行為)に絞って検討します)。
したがって、RAGにおける第三者著作物の入力行為に、入力する第三者著作物の享受目的がある場合は、30条の4が適用されず著作権侵害に該当することになります。
もっとも、以下に述べるとおり、私は、LLMを利用したRAGの場合は、第三者著作物の入力行為に、この「享受目的」が認められるケースはほぼないのではないかと考えています。
ア LLMを含む生成AIにおける「享受目的」とは
まず、LLMを含む生成AIにおける「入力対象著作物の享受目的」とは、具体的に言うと「入力対象著作物の「表現上の本質的な特徴を感じ取れるような」AI生成物の作成目的」を指しています。
これは、文化庁の下記資料の下記赤く囲った部分(赤く囲ったのは私の加筆です)で「※1例えば、3DCG映像作成のため風景写真から必要な情報を抽出する場合であって、元の風景写真の「表現上の本質的な特徴」を感じ取れるような映像の作成を目的として行う場合は、元の風景写真を享受することも目的に含まれていると考えられることから、このような情報抽出のために著作物を利用する行為は、本条の対象とならないと考えられる」ということからも裏付けられます。

そして、ここでの「AI生成物」とは、RAGの場合「LLMによる回答結果」ですから、結局のところ「入力対象著作物の享受目的」とは、「入力対象著作物の「表現上の本質的な特徴を感じ取れるような」回答の作成目的」ということになります。
ポイントは「表現上の本質的な特徴を感じ取れるような」という部分です。
つまり、単に、「入力対象著作物を参考にした回答の作成目的」はこの「享受目的」に含まれませんし、「入力対象著作物が一部でも含まれている回答を生成する目的」があったとしても、それが「入力対象著作物の表現上の本質的な特徴を含んだ回答を生成する目的」でなければ「享受目的」はないことになります。
イ LLMを利用したRAGの場合には、この「入力対象著作物の表現上の本質的な特徴を含んだ回答を生成する目的」があることはほとんどないのではないか
逆に言うと「入力対象著作物の表現上の本質的な特徴を含んだ回答を生成する目的」があれば、入力時点において享受目的があることになりますが、私はLLMを利用したRAGの場合には、この「入力対象著作物の表現上の本質的な特徴を含んだ回答を生成する目的」があることはほとんどないと考えています。
理由は2つあります。
まず「享受目的」が認められるには、入力対象著作物の「表現上の本質的な特徴」を感じ取れるAI生成物の生成目的が必要ですが、LLMを利用したRAGの場合、入力対象著作物の中に含まれている「事実」「ノウハウ」「アイデア」「知識」を利用することが目的であり、入力対象著作物の「表現上の本質的な特徴」を有するAI生成物(回答)の生成目的は通常は存在しないためです1なお、文章生成AIと比較して、画像生成AIの場合であれば、既存著作物の入力行為(例:i2i)において享受目的が認められるケースは多いと思います。
さらに、LLMに入力された入力対象著作物の「表現」部分は、対象著作物のデータベース化の過程でのチャンク処理や、LLM内の処理により、その表現上の特徴がそぎ落とされ、より一般的な表現になることが多いことも享受目的を否定する根拠となります。
1点目について、もう少し詳しく説明します。
なぜ、「享受目的」として単に「入力対象著作物と似ているAI生成物の生成目的」だけでは足りず、入力対象著作物の「表現上の本質的な特徴」を感じ取れるAI生成物の生成目的が必要なのか、です。
まず、著作権はあくまで「表現」を保護するものであり、「表現」の元になっている「事実」「アイデア」「ノウハウ」「知識」を保護するものではありません。
つまり、 2つの著作物を対比した場合に、「事実」「アイデア」「ノウハウ」「知識」が類似しているだけでは、類似性が否定され、著作権侵害にはなりません。
こんなイメージですね。
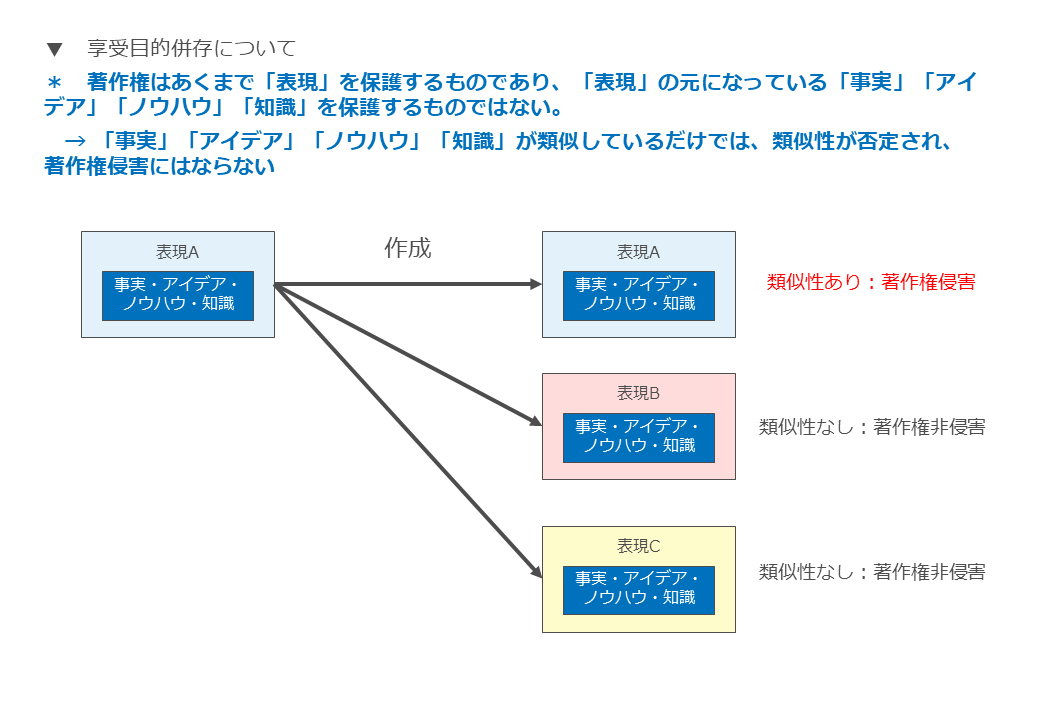
つまり、著作権侵害の要件としての「類似性」を満たすためには、単に似ているだけでは足りず「他人の著作物の表現上の本質的な特徴を直接感得できること」が必要となるのです。
日常用語としての「類似性」より、かなり狭い概念であることが判りますね。
文化庁の資料でもこの点が分かり易く説明されています。
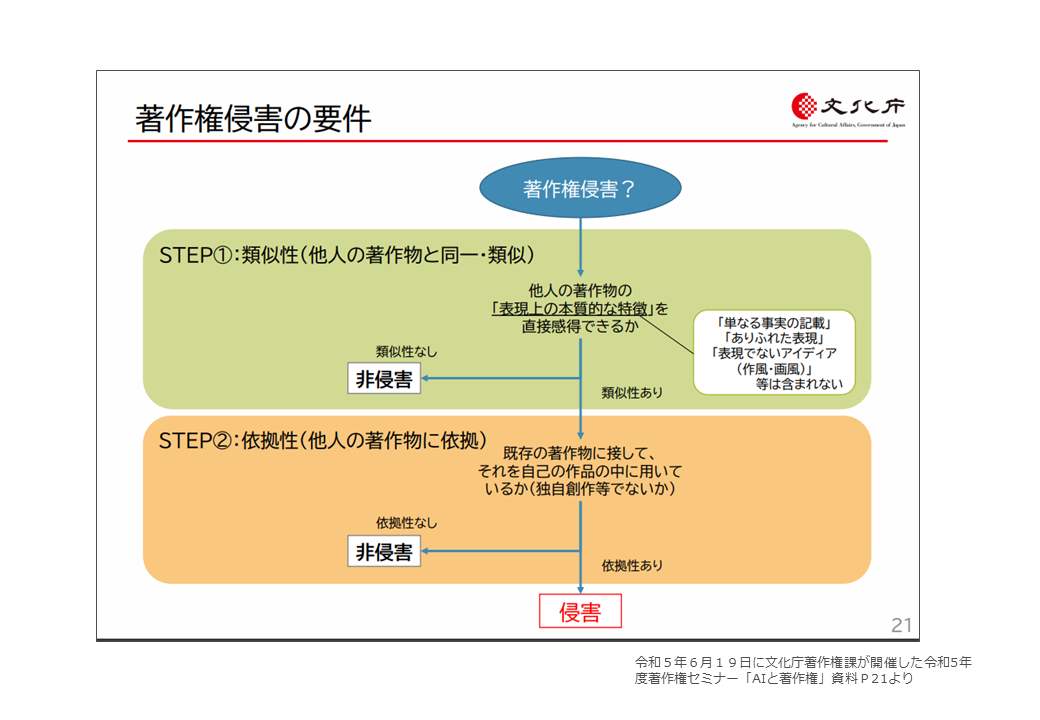
このように、著作権侵害の要件としての類似性の判断基準が「他人の著作物の表現上の本質的な特徴を直接感得できること」であるからこそ、「享受目的」は、単に「対象著作物と似ているAI生成物の作成目的」ではなく「対象著作物の「表現上の本質的な特徴を感じ取れるような」AI生成物の作成目的」とされているのです。
そして、「享受目的」をこのように限定的に理解する以上、LLMを利用したRAGの場合には、この「享受目的」があることはほとんどないと考えています。
3 著作権侵害になるケース
ただし、以上の議論は、あくまでLLMによる回答(AI生成物)に、入力対象著作物の表現上の本質的特徴が含まれていない場合にのみ当てはまります。
LLMによる回答(AI生成物)に入力対象著作物の表現上の本質的特徴が含まれている場合、対象著作物の入力行為、当該AI生成物の生成や利用(社内での共有や配信等)は著作権侵害に該当するのでしょうか。
このパターンは、シンプルに言うと、前回記事における「(5) 既存著作物を入力し、同既存著作物と類似するAI生成物を生成して配信等を行うパターン(パターン3)」です。
そして、前回記事で説明をしたとおり、このパターンは、① 入力行為については、AI生成物を実際に生成し、かつ配信等していることから、享受目的が認められて30条の4が適用されず著作権侵害となる可能性が高い、②AI生成物の生成行為については、権利制限規定(30条等)に該当しなければ著作権侵害、③ 配信行為は該当する権利制限規定がなく著作権侵害、ということになります。
つまり、LLMによる回答(AI生成物)に入力対象著作物の表現上の本質的特徴が含まれている場合には、対象著作物の入力行為、当該AI生成物の生成や利用(社内での共有や配信等)は著作権侵害になる、ということになります。
4 違法と適法の境目
以上の通り、LLMを用いたRAGについては、適法なパターンと違法なパターンがあることになります。
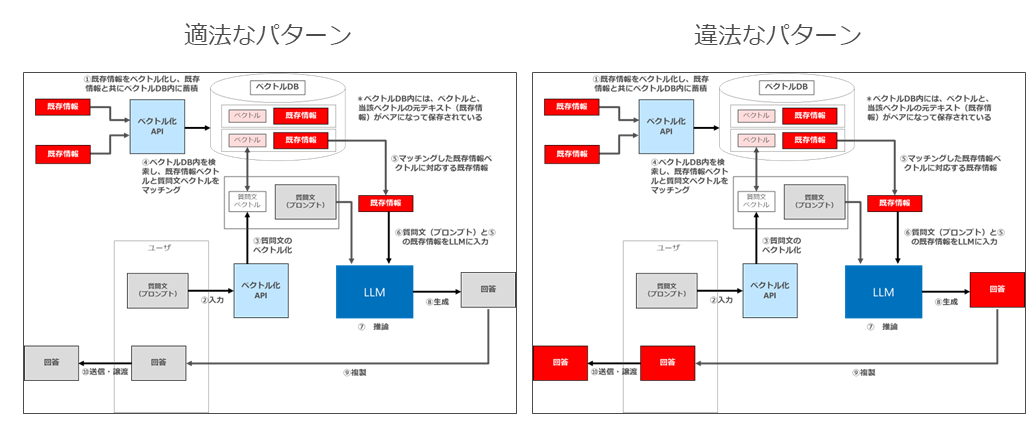
両者の境目は何なのでしょうか。
この点については、繰り返しになりますが、「LLMによる回答(AI生成物)に入力対象著作物の表現上の本質的特徴が含まれているか否か」が境目となります。
そして、私はLLMを利用したRAGの場合には、LLMによる回答が入力対象著作物の表現上の本質的な特徴を含んだ回答になるケースは少ないのではないかと考えています。
理由は先ほど、第三者著作物を入力する際の享受目的併存の部分で詳細に述べたことがそのまま当てはまります。
つまり、LLMに入力された対象著作物については、対象著作物のデータベース化の過程でのチャンク処理やLLM内の処理により、結果として回答(AI生成物)の内容としては、入力対象著作物の「表現上の本質的特徴」部分がそぎ落とされ、より一般的な表現になるためです。
また、検索結果としてプロンプトと共にLLMに入力される入力対象著作物は、複数の著作物(文章)であることが通常で、LLM内では、それら複数の入力対象著作物を解析し、意味が通るような回答結果をLLM内で生成するため、その過程でも、個々の入力対象著作物(文章)の「表現」部分はそぎ落とされることになります。
そのため、LLMを利用したRAGの場合、入力対象著作物の中に含まれている「事実」「ノウハウ」「アイデア」「知識」しか利用されていない回答(AI生成物)が生成される可能性が高く、入力対象著作物の「表現上の本質的な特徴」を有する回答(AI生成物)が生成される可能性は低いということになります。
もちろん、可能性は低いとは言え、入力対象著作物の「表現上の本質的な特徴」を有する回答が生成される可能性は0ではありません。
そのため、システム上の工夫(入力対象著作物と生成回答を対比して、一定以上の類似度がある場合には、生成回答を更に一般的な内容に修正する等)や、ユーザー自身がAI生成物と入力対象著作物を比較して、一定以上の類似度がないかを確認し、類似している場合にはユーザー自身で出力結果を修正する等の措置が必要でしょう2厳密に言うと入力対象著作物の「表現上の本質的な特徴」を有するAI生成物が生成された時点で「複製」がなされていることになるので、その後チェックしても遅いということにはなりますが、実務的な対応としては、上記措置で対応するしかないと思われます。
5 その他適法なケース
なお、「LLMによる回答(AI生成物)に入力対象著作物の表現上の本質的特徴が含まれている場合」がNGなのであって、そもそもでそのようなものが含まれていない場合は適法です。
たとえば、「入力対象著作物がウェブページ上の著作物の場合に、当該ウェブページのリンクだけを出力・回答する」「入力対象著作物が書籍の場合に、当該書籍の書誌情報及び頁番号だけ出力する」ような行為は適法です。
また、「LLMによる回答(AI生成物)に入力対象著作物の本質的特徴が含まれている場合」であっても、その利用が「軽微利用」にとどまれば適法です(著作権法47条の5第1項)。
たとえば、入力対象著作物の冒頭数行だけを出力する場合などが該当します。具体的には、検索エンジンの検索結果表示画面で表示されるスニペットをイメージしてください。この「軽微利用」としてどこまで利用が認められるかについては、ケースバイケースですが、条文上は「当該公衆提供等著作物のうちその利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なもの」と定義されています。
さらに、「LLMによる回答(AI生成物)に入力対象著作物の本質的特徴が含まれている場合」であっても、その利用が「引用」(著作権法32条)に該当すれば適法です。もちろん、「引用」の要件(明瞭区分性や主従関係、出所表示など)を満たす必要がありますが、不可能ではないと考えています。
6 まとめ
(1) LLMを利用したRAG(Retrieval Augmented Generation)において、第三者の著作物をベクトルデーターベースとして蓄積したり、マッチングした既存情報をLLMへプロンプトとして入力する行為は原則として適法。
(2) ただし、LLMによる回答(AI生成物)に入力対象著作物の表現上の本質的特徴が含まれている場合は著作権侵害に該当。
(3) 違法と適法の境目は「LLMによる回答(AI生成物)に入力対象著作物の表現上の本質的特徴が含まれているか否か」。もっとも、LLMを利用したRAGの場合には、LLMによる回答が入力対象著作物の表現上の本質的な特徴を含んだ回答になるケースは少ないのではないか。
(4) また、「入力対象著作物がウェブページ上の著作物の場合に、当該ウェブページのリンクだけを出力・回答する」「入力対象著作物が書籍の場合に、当該書籍の書誌情報及び頁番号だけ出力する」「LLMによる回答(AI生成物)に入力対象著作物の本質的特徴が含まれている場合」であっても、その利用が「軽微利用」にとどまっている場合」には適法。
- 1なお、文章生成AIと比較して、画像生成AIの場合であれば、既存著作物の入力行為(例:i2i)において享受目的が認められるケースは多いと思います
- 2厳密に言うと入力対象著作物の「表現上の本質的な特徴」を有するAI生成物が生成された時点で「複製」がなされていることになるので、その後チェックしても遅いということにはなりますが、実務的な対応としては、上記措置で対応するしかないと思われます。
・STORIA法律事務所へのお問い合わせはこちらのお問い合わせフォームからお願いします。












