人工知能(AI)、ビッグデータ法務
LLMを利用したRAGと個人データの第三者提供
生成AIを用いた社内情報検索システムなどで、RAGという手法が用いられる例が増えています。前回のSTORIA事務所ブログでは、LLMを利用したRAG(Retrieval Augmented Generation)と著作権侵害について柿沼弁護士が解説しましたが、本稿では、RAGと個人情報保護法の論点(RAGと個人データの第三者提供該当性)について検討します。
Contents
RAGとは「ナレッジベースの外部化」
RAG(Retrieval Augmented Generation)とは
RAGとは、一言でいえば「ナレッジベースの外部化」です1ryohtaka「Azure OpenAI Service On Your Data の仕組みと使う上で気を付けるべきポイント」で用いられていた表現を使わせていただきました。。
LLM(大規模言語モデル)は、主としてWeb上にある膨大なデータを学習用データとして用いているため、ある会社の内部規程について質問したり、Webで公開されていない専門知識について質問したりしても、答えることができないか、的外れな出力がされます。
上記のような通常のLLMでは対応できない、特定領域の専門知識(ドメイン・ナレッジ)について出力できるようにするための手法のひとつとして、ファインチューニングが用いられる場合があります。ファインチューニングとは、学習済みのLLMに専門知識を再学習させてパラメータを調整する手法を指し、画像生成AIでよく用いられるLoRAもファインチューニングの一類型です2LoRA(Low-Rank Adaptation)はすべてのパラメータを更新するフルファインチューニングとは異なり、特定のパラメータのみを更新するPEFT(Parameter efficient FT)のひとつです。。
RAGは、ファインチューニングとは異なり、LLMのパラメータを調整するのではなく、LLMに入力するデータの内容を調整する手法で、いわゆるプロンプト・エンジニアリング(求める出力を得るための技術やスキル)に含まれるものです。
典型的なプロンプト・エンジニアリングとしては、質問文において「あなたはプロのコンサルタントです」といった前提条件(役割)を与えたり、いくつかの例文(Few-shot)を与えたりすることで出力の精度を高める手法が挙げられますが、RAGは質問文の書き方を工夫するのではなく、あらかじめ外部(ナレッジ・ベース)に保存した情報から質問文と関連するデータを抽出して、質問文と一緒にLLMに入力する手法です。
LLMでは、プロンプトとして入力できるトークン(文字数)に制限があるため、プロンプトとして膨大な量の社内規程を全て入力したり、大量の専門知識を入力したりすることが困難です。このような問題を解決してくれる手法のひとつがRAGです。
典型的なRAGの仕組み
RAGは、①まず既存情報(社内規程や特定の専門知識など)を適宜分割した上でベクトル情報と呼ばれる形式に変換(Embedding)し、ベクトル情報と既存情報とをベクトルデータベースに格納します。Embeddingによってベクトル情報に変換する理由は、端的にいうとデータ(既存情報と、プロンプトとして入力された質問文)の類似度を判断しやすくするためです。
次に②プロンプトとして入力された質問文を③ベクトル情報に変換(Embedding)したうえで、④ベクトル化された質問文とベクトル化された既存情報の類似度を測り、類似(マッチング)する既存情報を抽出します。そのうえで⑤マッチングした既存情報を⑥質問文と共にLLMに入力します。
以上の過程を経ることで、あらかじめ準備した既存情報(社内規程や特定の専門情報など)のうち、質問文に関連する情報のみをLLMに入力することができるので、プロンプトのトークン制限に抵触することなく、大量の既存情報をベースとした入力を実現できるのがRAGの利点となります。
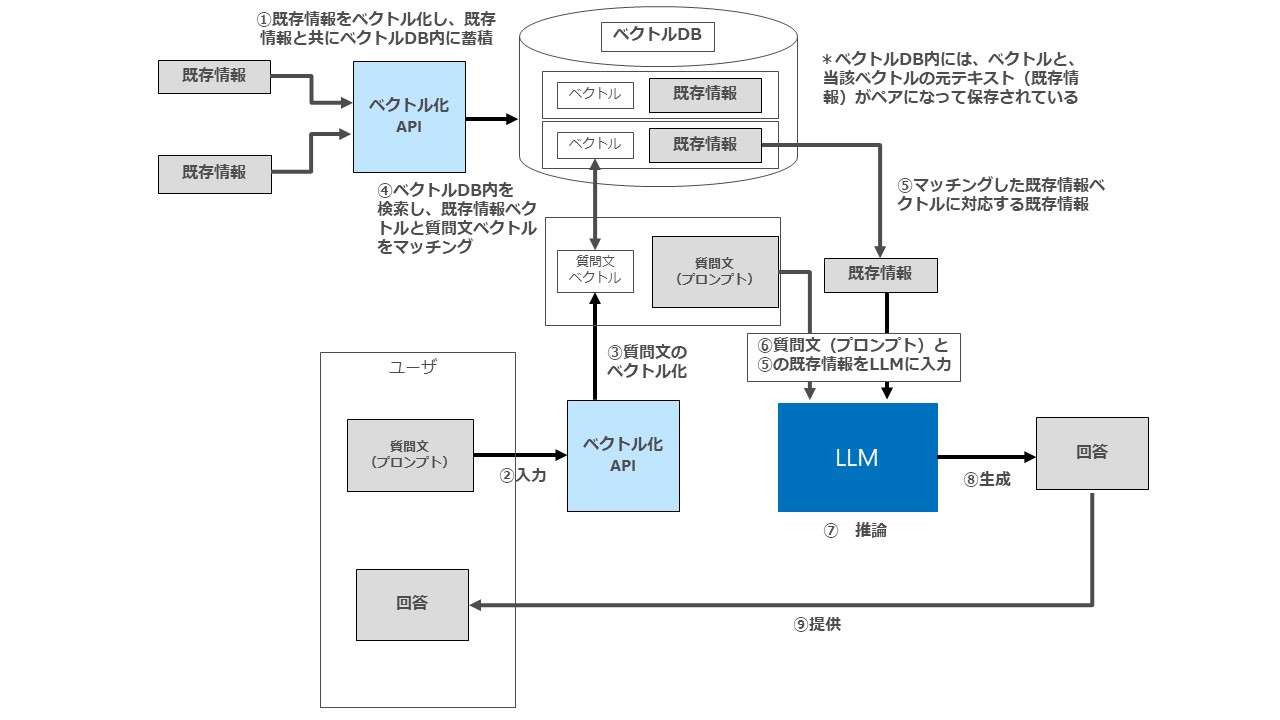
図1・典型的なRAGのフローを簡略化した図
2つの設例
本稿では以下の2つの設例を検討します。いずれの設例も、ベクトルデータベースに個人情報が含まれています。
▼ 設例1(ウェブページや書籍をベクトル化)
既存のウェブページや書籍を既存情報としてベクトル化し、ベクトルDBとして蓄積しているが、それらの既存情報の中には個人情報(氏名等を含む情報)が一部含まれている。このような、個人情報を含んだ既存情報をベクトルDBとして蓄積してRAGに用いることについて、個人情報保護法上の問題はないか。
▼ 設例2(顧客データベースをベクトル化)
自社の顧客DBの分析を行い、顧客セグメントに即したマーケティング施策を立案したい。顧客セグメントを分類する際に、単純な年齢や性別ではなく、自社顧客DB内の「担当者による各顧客に対するコメント」や「顧客の各商品に対する感想コメント」といった自由記述項目を用いた分類を行いたい。そこで、自社顧客DBをベクトルDB化し、既存情報の一部としてRAGに用いることについて、個人情報保護法上の問題はないか。
ベクトルデータベースからLLMへの入力は、個人データの第三者提供にあたるか
上記設例のいずれも、個人情報を含む既存情報をベクトル化したうえでRAGに用いています。
既存情報をRAGに用いるということは、LLMに当該既存情報を入力することを意味します(図1の⑤⑥)。
では個人情報を含む既存情報をLLMへ入力することは、ユーザーのLLMサービス事業者に対する、個人データの第三者提供にあたるでしょうか。あたるとした場合、当該既存情報の入力は、個人情報保護法(以下「法」という場合があります)における個人データ第三者提供規制(法27条、法28条)の対象となる可能性が生じるため、以下で検討します。
個人情報、個人データ、個人情報データベース等
個人データとは、個人情報データベース等を構成する個人情報3「個人情報」の定義は当事務所ブログでも何度も触れているので割愛しますが、端的にいうと、個人情報とは、生存する個人に関する情報であって、①その情報に含まれる記述等によって特定の個人を識別できる情報か②他の情報と容易に照合することによって特定の個人を識別できる情報、または③個人識別符号を含む情報が個人情報です(法2条1項)。をいうところ(法16条3項)、個人情報データベース等とは、個人情報を含む情報の集合物であって、特定の個人情報を電子計算機を用いて検索することができるように体系的に構成したものや、個人情報を含む情報の集合物に含まれる個人情報を一定の規則に従って整理することにより特定の個人情報を容易に検索することができるように体系的に構成したものであって、目次、索引その他検索を容易にするためのものを有するものを指します(法16条1項、政令4条2項4一定の例外あり。政令4条1項。)。
ややこしいので名刺で例えると、あちこちでもらった名刺の束が「個人情報」、それらの名刺の情報を入力・整理した名刺リストが「個人情報データベース等」(名刺管理ソフトやエクセルで作成したリストのみならず、アナログの名刺帳も、五十音順に整理しインデックスを付す等して特定の個人情報を容易に検索できるように体系的に構成したものであれば個人情報データベース等に該当します5GL通則編2-4【個人情報データベース等に該当する事例】事例4)、名刺リストを構成するレコードが「個人データ」にあたります。
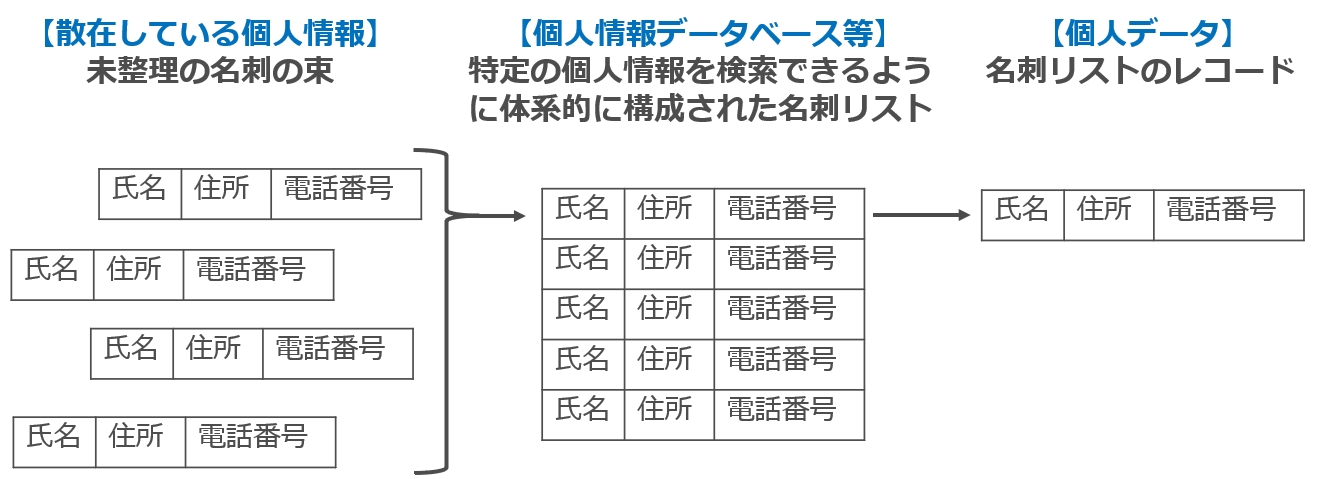
図2・個人情報、個人情報データベース等、個人データ
RAGにおけるベクトルデータベースが個人情報データベース等にあたる場合、ベクトルデータベースを構成する既存情報(個人情報)は個人データにあたることになるため、以下では設例1と設例2について、それぞれベクトルデータベースの個人情報データベース等該当性について検討します。
設例1(ウェブページや書籍をベクトル化)
ベクトルデータベースは、典型的にはチャンク(文章の塊)に分割された既存情報と、これをベクトル形式(数値配列)に変換(Embedding)したベクトルデータを主として構成されています。
設例1はまさにこのケースですが、このようなベクトルデータベースは「特定の個人情報を電子計算機を用いて検索することができるように体系的に構成したもの」には原則としてあたりません。
なぜなら「特定の個人情報を電子計算機を用いて検索することができるように体系的に構成」とは、検索機能等によって特定の個人情報を含む文字列を検索できるような場合は含まれず6個人情報保護委員会「個人情報の保護に関する法律についてのガイドライン」に関するQ&A1-40 、あくまで個人に着目した処理ができるように体系的に構成されている場合を指すところ、ウェブページや書籍を元に構築したベクトルデータベースがこのような構成をとっていることは通常はないためです。
ここで参考になるのが、検索エンジンは原則として個人情報データベース等に該当しないとする政府見解です。すなわち、個人情報保護法の立案担当者が中心になって執筆された書籍7園部逸夫=藤原靜雄 (編)『個人情報保護法の解説 第三次改訂版』(ぎょうせい、2022)86頁では「検索エンジンは、そのデータベース中に蓄積された情報に個人情報としての索引が付されているわけではない(同じ文字列であれば、地名や企業名等の個人情報でない情報も検索される。)場合には、これをもって『特定の個人情報を……検索することができるように体系的に構成したもの』とは言い難く、本条第2項に規定する『個人情報データベース等』には該当しない。ただし当該検索エンジンが個人情報としての索引を付してデータベース化されているような場合、すなわち個人情報に該当する情報だけを選別して検索できる場合には、『個人情報データベース等』に該当すると考えられる。」と記載されており、平成15年改正時における政府答弁でも、検索エンジンの個人情報データベース等該当性は原則として否定されています8第156 回国会国会会議録衆議院個人情報の保護に関する特別委員会第6号(平成15年4月17日)。高木浩光「個人情報保護から個人データ保護へ―民間部門と公的部門の規定統合に向けた検討 ⑶―」82頁参照。。
この立案担当者書籍は、検索エンジンについて「個人情報としての索引を付してデータベース化されているような場合、すなわち個人情報に該当する情報だけを選別して検索できる場合」は例外的に個人情報データベース等に該当するとしていますが、逆に言えば、個人情報としての索引をベクトルデータベースに付しているような場合でない限り、ベクトルデータベースが個人情報データベース等に該当することはないといえます。
よって設例1のようにウェブページや書籍を既存情報としてベクトル化した場合、ベクトルデータベースは個人情報データベース等に該当せず、これを構成する既存情報も個人データにあたりませんので、ベクトルデータベースから既存情報をLLMへ入力すること(図1の⑤⑥)は個人データの第三者提供にはあたらない、その結果、個人データ第三者提供規制(法27条、法28条)の対象とはならない、と整理できます。
設例2(自社の顧客データベースをベクトル化)
では、設例2はどうでしょうか。設例2では自社の顧客DBをベクトル化しています。
設例2は個人データの第三者提供に該当する可能性がある
ベクトルデータベースを構築する基となった既存情報のデータベースが個人情報データベース等に該当する場合、ベクトルデータベースに保存された当該既存情報は個人データにあたる可能性が生じます。
設例2における顧客DBは「特定の個人情報を電子計算機を用いて検索することができるように体系的に構成したもの」として個人情報データベース等に該当します。ベクトルデータベースは、既存情報と既存情報をベクトル化(Embedding)したベクトル情報とで構成されるところ、顧客DB(個人情報データベース等)と顧客DB内のデータをベクトル化した情報とで構成されるベクトルデータベースも個人情報データベース等にあたることになります。この場合、当該ベクトルデータベースに保存された既存情報(顧客データ)は個人データにあたるため、これをLLMへ入力すること(図1の⑤⑥)は、個人データの第三者提供にあたる可能性が生じると考えます。
なお顧客DBが年齢や性別といった属性項目のみで構成される場合、これをベクトル化するメリットは乏しいのですが、設例2のように、顧客DBが「担当者による各顧客に対するコメント」や「顧客の各商品に対する感想コメント」といった自由記述項目を有しており、これらの自由記述項目を生成AIの質問文に応じて抽出したいような場合は、自由記述項目をベクトル化し、ベクトル化した質問文と類似度に応じてマッチングさせることで、質問文と類似する自由記述項目を抽出することができるので、顧客DBをベクトル化してRAGに用いるメリットがあるといえます。
個人データの「提供」該当性については別途検討を要する
もっとも、LLMに入力するデータが「個人データ」にあたる場合であっても、LLMに入力することが「提供」に該当するかどうかは別途検討が必要になります。法27条と法28条は、個人データの第三者「提供」について規律していますが、LLMへの入力が「提供」に当たらない場合、これらの条文は適用されないためです。
提供該当性については個人情報保護委員会が2023年6月2日に公表した「生成AIサービスの利用に関する注意喚起等について」の解釈が重要となるところ、注意喚起の以下の箇所からすれば、入力した個人データが「当該プロンプトに対する応答結果の出力以外の目的で取り扱われる場合」、すなわち機械学習目的で利用される場合や不正検知目的で取り扱われる場合等は、個人データの第三者「提供」に当たるものとして、法27条や法28条が適用される可能性が生じると考えます。この点は後日別ブログでまとめる予定です。
注意喚起 別添1(1)
② 個人情報取扱事業者が、あらかじめ本人の同意を得ることなく生成AIサービスに個人データを含むプロンプトを入力し、当該個人データが当該プロンプトに対する応答結果の出力以外の目的で取り扱われる場合、当該個人情報取扱事業者は個人情報保護法の規定に違反することとなる可能性がある。
そのため、このようなプロンプトの入力を行う場合には、当該生成AIサービスを提供する事業者が、当該個人データを機械学習に利用しないこと等を十分に確認すること。
なお、ベクトルデータベースからの既存情報の入力(図1の⑤)とは別に、質問文として入力したテキスト自体(図1の②)が個人データに該当する場合があることには別途留意が必要です。
また、ベクトルデータベース内の既存情報と、質問文テキストのいずれも個人データに該当しない場合、RAGを利用したLLMへの入力は「個人データ」の第三者提供にはあたらないことになりますが、個人データに該当する否かとは別に、プライバシー侵害等の問題は別途生じ得る可能性がある点にも注意を要します(個人情報保護法上の適法性とプライバシー侵害の有無とは一応別の話です)。
生成AIを社内情報検索に用いる場合を中心として、今後、RAGの利用は増えていくことが予想されます。RAGを用いたLLMへの入力が、個人データの第三者提供に該当するかどうかは生成AIサービスの個人情報保護法上の適法性を検討するうえでも有益と考え、本稿を作成した次第です。(弁護士杉浦健二)
【Special Thanks】本稿における生成AIの技術面に関する記載については、スキルアップAI株式会社 取締役CTO 小縣信也さんより大変貴重なご意見をいただきました。ここに深謝申し上げます。
- 1ryohtaka「Azure OpenAI Service On Your Data の仕組みと使う上で気を付けるべきポイント」で用いられていた表現を使わせていただきました。
- 2LoRA(Low-Rank Adaptation)はすべてのパラメータを更新するフルファインチューニングとは異なり、特定のパラメータのみを更新するPEFT(Parameter efficient FT)のひとつです。
- 3「個人情報」の定義は当事務所ブログでも何度も触れているので割愛しますが、端的にいうと、個人情報とは、生存する個人に関する情報であって、①その情報に含まれる記述等によって特定の個人を識別できる情報か②他の情報と容易に照合することによって特定の個人を識別できる情報、または③個人識別符号を含む情報が個人情報です(法2条1項)。
- 4一定の例外あり。政令4条1項。
- 5GL通則編2-4【個人情報データベース等に該当する事例】事例4
- 6個人情報保護委員会「個人情報の保護に関する法律についてのガイドライン」に関するQ&A1-40
- 7園部逸夫=藤原靜雄 (編)『個人情報保護法の解説 第三次改訂版』(ぎょうせい、2022)86頁
- 8第156 回国会国会会議録衆議院個人情報の保護に関する特別委員会第6号(平成15年4月17日)。高木浩光「個人情報保護から個人データ保護へ―民間部門と公的部門の規定統合に向けた検討 ⑶―」82頁参照。
その他本稿の参考文献:
DAIR.AI「プロンプト・エンジニアリングガイド」
Amazon Web Services ブログ「高精度な生成系 AI アプリケーションを Amazon Kendra、LangChain、大規模言語モデルを使って作る」
Amazon Web Services ブログ「生成系 AI アプリケーションでベクトルデータストアが果たす役割とは」
Hirosato Gamo「ChatGPT – Azure OpenAI 大全」
ryohtaka「Azure OpenAI Service On Your Data の仕組みと使う上で気を付けるべきポイント」
ABEJA Tech Blog「外部データをRetrievalしてLLM活用する上での課題と対策案」
ブレインパッドPlatinum Data Blog「プロンプトエンジニアリング手法 外部データ接続・RAG編」
【告知】2023年8月30日、新社会システム総合研究所(SSK)主催セミナー「生成AIと個人情報保護法制の勘所 〜個人情報保護法とプライバシーをめぐる法的留意点〜」に登壇します。プログラムの詳細及びご参加方法は下記外部サイトをご参照下さい。
https://www.ssk21.co.jp/S0000103.php?gpage=23387
STORIA法律事務所へのお問い合わせはこちらのお問い合わせフォームからお願いします。












