人工知能(AI)、ビッグデータ法務
生成AIの利用ガイドライン作成のための手引き

Contents
- 1 第1 本手引きについて
- 2 第2 利用する生成AIサービスの構造・規約の把握
- 3 第3 そもそも入力して良いデータなのか(入力行為のリスク)
- 4 第4 生成物をどのように取り扱っていいのか(生成物利用のリスク)
- 5 第5 その他生成AIサービスの規約上の制限に違反していないか
- 6 第6 まとめ
第1 本手引きについて
1 本手引きの利用目的
本手引きは以下の目的に利用されることを想定しています。
① 生成AIサービスの導入を検討している企業の経営陣・セキュリティ部門・法務部門が導入に際しての法的リスク評価や、社内独自の生成AI利用ガイドラインを作成する際の参考にする。
② フリーランスの方や、所属する会社・機関に生成AI利用ガイドラインがない方が、生成AIサービス利用の際の注意事項を把握する。
③ 生成AIサービスを開発・提供する事業者がサービス・システム設計の参考にする。
2 本手引きが対象とする生成AIサービス
ChatGPTのようなLLM(大規模言語モデル)を利用した文章生成AIサービスを主たる対象としますが、画像生成AIサービスについても必要な限度で触れます。
3 本手引きの構成
生成AIサービスは、いずれのサービスも基本的に「ユーザーが何らかのデータを入力して何らかの処理(保管、解析、生成、学習、再提供等)が行われ、その結果(生成物)を得て利用する」という構造ですので、生成AIサービス導入・利用のリスク判断や利用ガイドライン作成のためには、以下の4つの観点からの検討が必要です。
(1) 利用する生成AIサービスの構造・規約の把握
(2) そもそも入力して良いデータなのか(入力行為のリスク)
(3) 生成物をどのように利用していいのか(生成物利用のリスク)
(4) その他生成AIサービスの規約上の制限に違反していないか
第2 利用する生成AIサービスの構造・規約の把握
1 生成AIサービスの構造について
生成AIサービスには様々なものがありますが、法的なリスク評価という観点からは以下の3つに分類するのが有益です。各パターンによって法的なリスクが異なるためです。
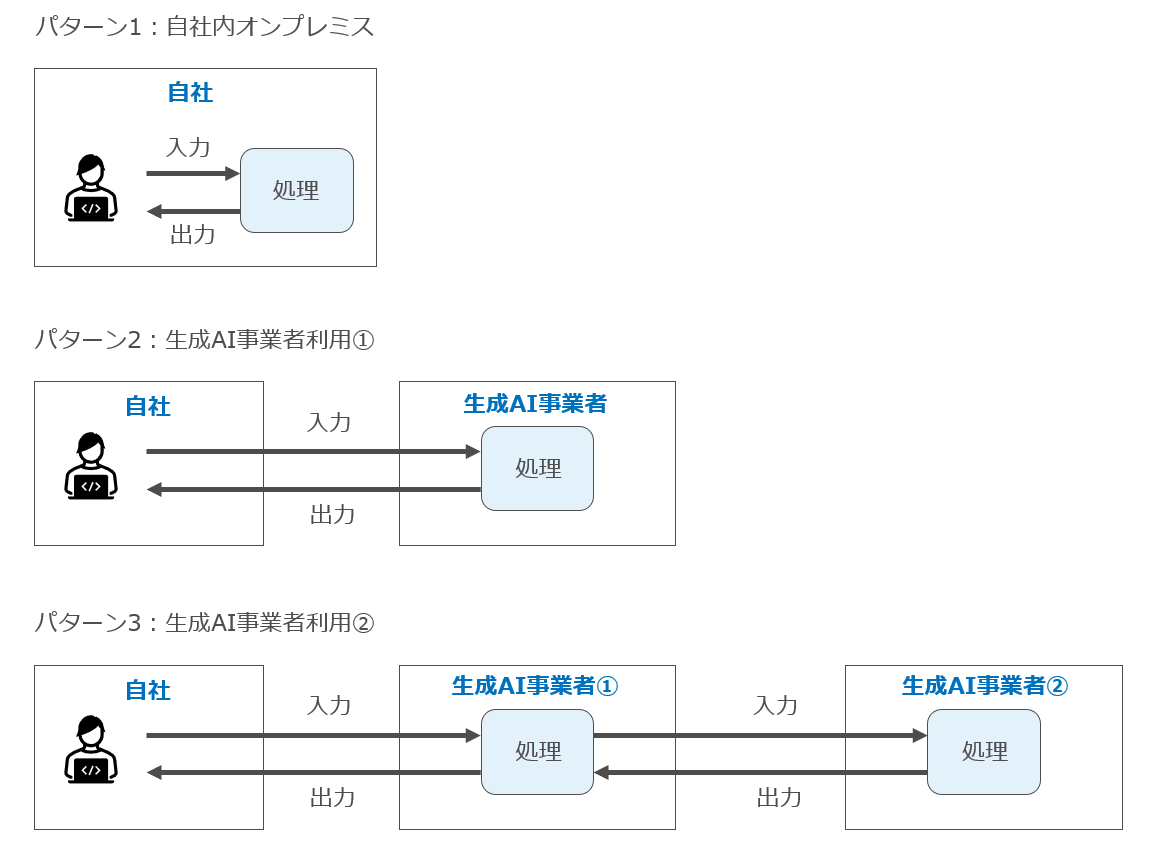
パターン1は自社内にオンプレミスでモデルを構築し自社内で処理が完結しているパターン、パターン2は、OpenAIなど、生成AIサービス機能を提供している事業者から直接サービス提供を受けるパターン(例:ChatGPTのブラウザ版)です。
パターン3は、生成AIサービス機能を提供している事業者(「上図生成AI事業者②」)から当該機能をAPI等を経由して自社サービスに組み込んでサービス提供している事業者(上図「生成AI事業者①」)からサービス提供をうけるパターンです。
このうちパターン1については、入力データが生成AI事業者に提供されないので、生成AIサービス利用のリスクのうち、入力行為のリスクはかなり低いと言えます。ただし生成物をどのように利用していいか(生成物利用のリスク)は他のパターンと同様注意が必要です。
現在、いわゆる生成AIサービスとして提供されている数が最も多いのはパターン3と思われますが、パターン3の場合、ベースになっている生成AIサービス(GPT等)の上に各事業者の独自サービスが構築されている、いわば2階建て構造になっているため、入力行為及び生成物利用リスクの評価にあたっては、ベースとなっている生成AIサービスと当該サービス両方の検討が必要となります。
本手引きは、パターン2を基本とし、必要に応じてパターン1及びパターン3に触れることとします。
2 生成AIサービスの各種規約(利用規約・プライバシーポリシー・データポリシー等)の確認
生成AIサービスのリスクの把握においては、当該サービスの規約のチェックが必須です。特にパターン3のサービスを利用する場合は、ベースになっている生成AIサービスの規約と当該サービス両方の規約をチェックする必要があります。
もっとも各規約はかなり膨大ですので、法的リスクの把握という観点からは、特に① 入力したデータがどのように扱われるのか(特にサービス側の学習に利用されるのか)、② 生成物の利用に制限がないのか(例:商用利用が可能なのか)、③ その他生成AIサービス独自の規約上の禁止事項としてどのようなものがあるのか、についてチェックするようにして下さい。
詳細は後述します。
第3 そもそも入力して良いデータなのか(入力行為のリスク)
入力(送信)するデータは多種多様なものが含まれますが、知的財産権の処理の必要性や法規制の遵守という観点からは、以下の類型のデータを入力する場合、特に注意が必要です。なお、「入力したデータが生成AIサービス内でどのように処理・利用されるのか」が「そもそも入力して良いデータなのか」にも密接に関連しますので、その点についても適宜触れます。
1 著作物、登録商標など第三者が知的財産権を保有しているデータ
生成AIサービスの利用に際して第三者が作成した文章や、他社登録商標等(ロゴやデザイン)を入力する行為です。
(1) 著作物(文章等)
生成AIサービスに入力するプロンプトとして第三者が著作権を保有している文章等を入力する行為です。
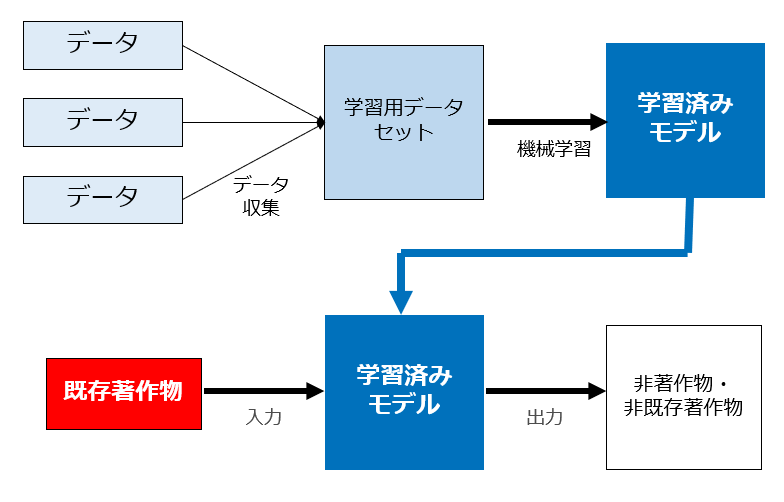
なお、生成物が入力著作物や既存著作物と同一・類似の場合は、当該生成物の利用が当該著作物の著作権侵害になる可能性もあります(後述)ので、ここでは生成物が入力著作物や既存著作物と同一・類似ではない場合を前提とします。
① 当該プロンプトが第三者の著作物か
当然のことですが、入力した当該プロンプトが第三者の著作物ではない場合(例:自分で考えた質問や保護期間が満了した著作物等)や、著作権者により明示的に自由利用が許諾されている著作物であれば、問題ありません。
② 著作権侵害のリスクはかなり低い
また、仮に入力するプロンプトが著作物であるとしても、他人が著作権を保有している文章等をプロンプトとして入力する行為は、結論としては著作権侵害に該当するリスクはかなり低いと思われます。
まず、生成AIサービスのユーザーが第三者の著作物を無許諾でサービスに入力する行為は、著作権法的には当該ユーザーによる「複製」等に該当しますので、原則として著作権侵害に該当します 。
もっとも、日本著作権法30条の4では、「情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うこと)」(同2号)や「著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)」する行為(同3号、いわゆる「非享受利用行為」)については権利制限の対象(著作権侵害にならない)としています。
ある生成AIサービスにユーザーが既存著作物を入力した場合、当該生成AIサービス内で当該入力著作物に関する「情報解析」あるいは「非享受利用行為」が行われていると解釈するのが自然であるように思われます
その解釈にたつと、既存著作物の入力行為は「(情報解析の)用に供する」行為または(非享受利用)に供する」行為に該当しますので、著作権侵害には該当しないということになります。
なお、繰り返しになりますが、この結論はあくまで下図のように「生成物が入力著作物や既存著作物と同一・類似ではない場合」にのみ当てはまるものです。生成物が入力著作物や既存著作物と同一・類似の場合は、当該生成物を利用することが当該著作物の著作権侵害になる可能性もあります(後述)ので注意してください。
③ 生成AI事業者における学習行為
生成AI事業者が、入力データを当該生成AI事業者においてモデルの学習に利用する場合でも、当該生成AI事業者における学習行為に日本の著作権法が適用される場合には、著作権法30条の4により著作権侵害の問題は起こりません(この点は後述する個人情報保護法と異なります)。
④ ファインチューニング・プロンプトエンジニアリング
また、ファインチューニングによる独自モデルの作成や、いわゆるプロンプトエンジニアリングのために他者著作物を利用することもあると思われます。
このうち、ファインチューニングによる独自モデルの作成に際して他者著作物を利用する行為については、当該行為は、著作権法30条の4第2号「情報解析」に該当しますので、当該行為に日本の著作権法が適用される場合には問題がありません。
次に、いわゆるプロンプトエンジニアリングのために、自社サーバ内や事業者のサーバ内に第三者の著作物を蓄積する行為を行うことも考えられます。
プロンプトエンジニアリングとは、具体的には、生成AIサービスにおいてより精度の高い出力を生成させるために、ユーザの入力(プロンプト)を補完したり加工したりする行為ですので、当該行為自体が「情報解析」「非享受利用」に該当する、あるいは生成AIサービスにおける出力の生成(これも「情報解析」「非享受利用」に該当すると思われます)に「必要と認められる限度 」の行為として、著作権法30条の4により適法ではないかと思われます。
ただし「必要と認められる限度 」でしか利用は認められませんので、たとえば「プロンプトエンジニアリングのためにサーバ内に第三者の著作物を蓄積」しつつ、同時に「当該著作物をデータベース化して人間が参照したり読んだりすることができる」のであれば「必要と認められる限度」を超えていますので、30条の4は適用されず著作権侵害に該当すると思われます。
⑤ 特定の作者名や作品名を入力する行為
特に画像生成AIにおいて、プロンプトに特定の作者名や作品名を入力する行為についても、それらの作者名等は著作物ではありませんので、著作権侵害にはなりません。
もっとも、それらの情報を入力した結果、当該特定の作者や作品に同一・類似の著作物が生成物された場合、当該生成物を利用することは著作権侵害に該当する可能性が高いと思われます(後述)。そのため、生成AI利用ガイドラインを作成する際には、プロンプトに特定の作者名や作品名を入力する行為を禁止することも考えられます。
(2) 他社登録商標(ロゴやデザイン)
ロゴ・デザイン等については、著作権により保護されている場合もありますが、登録商標として登録されている場合もあります。それら登録商標を生成AIサービスに入力することは適法なのでしょうか。
商標権者が保有している権利は、指定商品または指定役務について当該商標を独占的に「使用」する行為です(商標法25条)。
もっとも、この「使用」というのは、対象商標のあらゆる使用行為を意味しているわけではありません。
具体的には、商標法2条3項で「使用」の用語が定義されているのですが、たとえば対象商標を商品やパッケージに付する行為や、商品の広告に対象商標を付す行為などに限定されています。
要するに、商標権というのはブランドを保護するための制度なので、ブランド価値を毀損・ただ乗りするような態様での利用だけを制限している、ということです。
したがって、対象商標についても、この「使用」に該当しない行為は、誰でも自由に行うことができます。
生成AIサービスへの入力行為や、生成AIサービス内での学習に利用する行為については、この「使用」(法2条3項)あるいは商標的使用に該当しない(法26条1項6号)ため商標権侵害に該当しません。
もっとも、この点はあくまで「入力行為」に関するものである点に注意が必要です。
著作権と同様、「故意に、あるいは偶然生成物された、他者登録商標と同一・類似の商標を『使用』する行為が商標権侵害になるか」については別途問題になります。詳細は後述しますが、このような行為は商標権侵害になります。
この点を言い換えると、生成AIサービスにロゴやデザインを入力する際には登録商標の調査は不要ですが、生成物を利用する場合には調査が必要ということになります。
(3) 他社登録意匠(ロゴやデザイン)
商標権と異なり、意匠権では基本的に「物品」と結びついたデザインのみが保護されています。したがって、登録意匠について物品と離れたデザインのデータのみを生成AIサービスに入力する行為はそもそも「意匠」(意匠法2条1項)が利用されていないので、意匠権侵害に当たりません。
ただ、「物品」と結びついていない「意匠」としていわゆる「画像意匠」があります。
意匠法上保護される画像意匠として登録が可能なのは、画像のうち、①機器の操作の用に供されるもの(「操作画像」)又は②機器がその機能を発揮した結果として表示されるもの(「表示画像」)のみです。
つまり、機器とは独立した、画像や映像の内容自体を表現の中心として創作される画像(コンテンツ)は、意匠登録ができません。
したがって、生成AIサービスに、「画像意匠」以外の登録意匠(デザイン+物品で登録されているもの)を入力する行為は意匠権侵害になりませんが、「画像意匠」を入力する行為は意匠権侵害になる可能性がある、ということになります。
意匠権侵害に該当するのは、権利者に無断で当該登録意匠の「実施」行為を行った場合ですが、画像意匠における「実施」とは「意匠に係る画像の作成、使用又は電気通信回線を通じた提供若しくはその申出(提供のための展示を含む。以下同じ。)をする行為」を言います(意匠法2条2項3号イ)。
ここでいう「作成」には、複製を含むと理解されていますので、操作画像・表示画像を生成AIサービスに入力する行為は、当該サービス内でいったん複製されているという意味で、形式的には意匠権侵害になるようにも思われます。
もっとも、「意匠」といえるためには「視覚を通じて美感を起こさせる」(視覚性)という要件が必要です(意匠法2条1項)。つまり目に見えなければ「意匠」には該当しません。
生成AIサービスに登録意匠データを入力したり、生成AIサービス内での学習に利用する行為だけでは、当該入力された登録意匠データを誰かが見るわけではありませんので「作成」に該当せず、意匠権侵害に該当しないように思われます。
ただし商標権と同様、この点はあくまで「入力行為」に関するものであること、「故意に、あるいは偶然生成物された、他者が登録している画像意匠と同一・類似の画像意匠を使用する行為が意匠権侵害になります。そのため、生成AIサービスにロゴやデザインを入力する際には登録意匠の調査は不要ですが、生成物を利用する場合には調査が必要という事になります。
(4) 著名人の顔写真や氏名
著名人の顔写真や氏名を生成AIサービスに入力する場合、当該著名人が有しているパブリシティ権を侵害しないかを検討する可能性があります。
日本の判例上、著名人の氏名、肖像等はパブリシティ権で保護されているためです(ピンク・レディー事件(最高裁平成24年2月2日判決))。
ただし、著名人の氏名、肖像等を使えば即パブリシティ権侵害に該当する訳ではなく、「専ら肖像等の有する顧客吸引力の利用を目的とするといえる場合」のみ侵害に該当します。
具体的には以下のいずれかです。
① 肖像等それ自体を独立して鑑賞の対象となる商品等として使用する場合
② 商品等の差別化を図る目的で肖像等を商品等に付す場合
③ 肖像等を商品等の広告として使用する場合
そして、生成AIサービスに著名人の氏名、肖像等を入力する行為は、上記のいずれにも該当しませんので、パブリシティ権侵害に該当することはないと思われます。
また、生成AIサービスを利用して生成物された著名人の氏名、肖像等の利用については、上記3類型のいずれにも該当しない場合(例:画像生成AIの紹介記事の中で生成肖像を利用する等)にはパブリシティ権侵害に該当しませんが、3類型のいずれかに該当する方法で利用した場合には、パブリシティ権侵害に該当します。
2 個人情報(個人データ)
個人情報保護法(以下「個情法」ということがあります)上問題となるのは、ユーザーが自社内で保存している個人情報(顧客氏名、住所等)をプロンプトとして生成AIサービスに入力する行為です。
まず、個人情報保護法は、「個人情報」という概念のうち一定のデータベースを構成する個人情報を「個人データ」として規律します。ユーザーが自社内で保存している個人情報は通常はデータベースとして保存されていると思われますので、当該個人情報は「個人データ」(個情法16条3項)にも該当します。
個人情報取扱事業者に該当する企業においては、個人情報の利用目的の特定(個情法17条1項)をしたうえで、当該利用目的内で個人情報を利用する必要がありますが(同18条)、逆に利用目的の範囲内での個人情報の利用については本人の同意は必要ありません。
したがって、まず、企業が通知公表している個人情報の「利用目的」の範囲内で生成AIサービスを利用し、その範囲内で個人情報を入力する必要があります(ここまではパターン1~パターン3共通です)。
次に、パターン2または3、すなわち「外部の生成AI事業者が提供している生成AIサービスを利用する場合」には、当該サービスに個人情報(個人データ)を入力することが可能かについては慎重な検討が必要です。
「個人データ」については、「第三者」に「提供」する際には原則として本人の同意を得る必要があるためです(個情法27条1項)。
(1) 入力した情報が生成AIサービス内でどのように処理されるのか~①「提供」該当性~
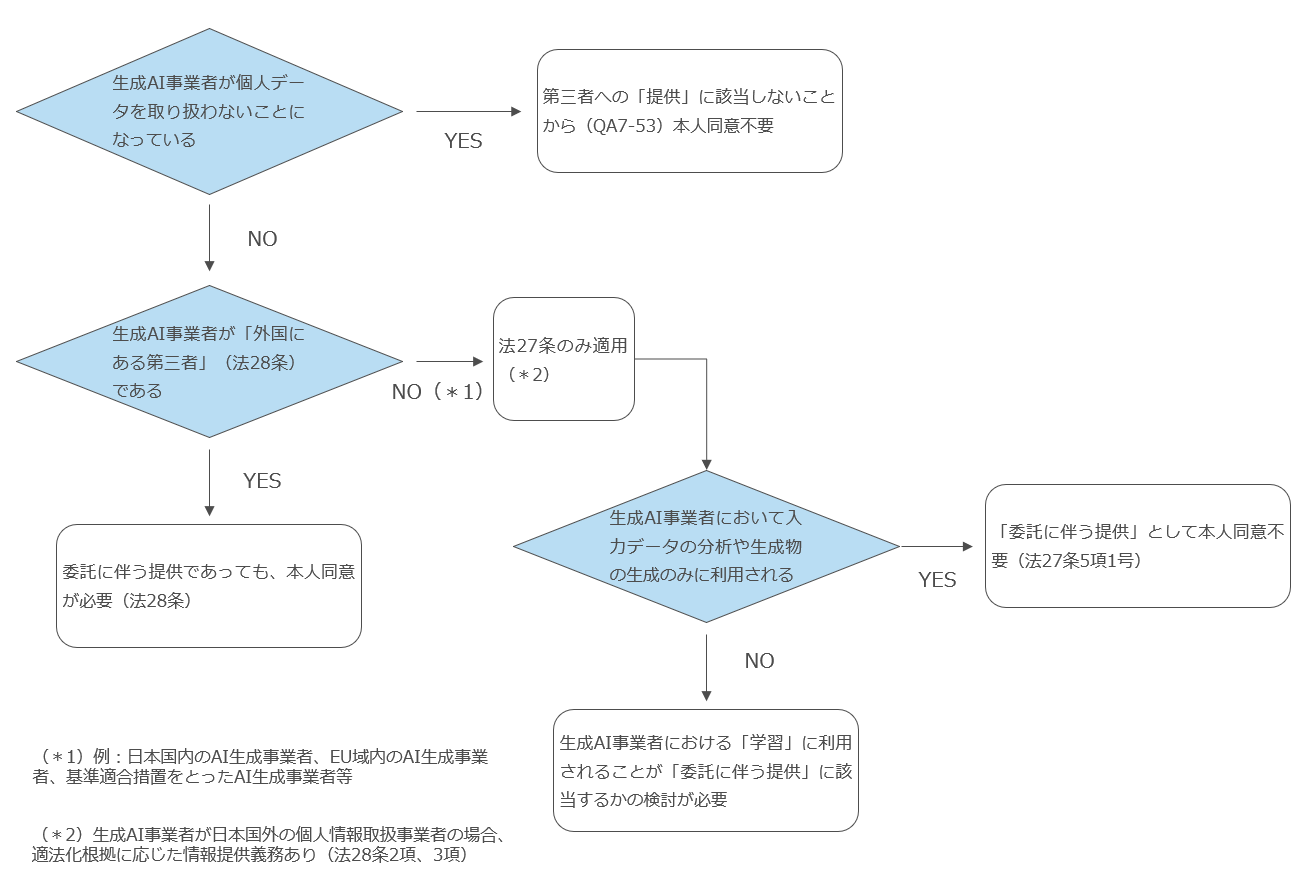
まず、個人データを生成AI事業者が提供している生成AIサービスに入力したとしても当該入力行為がそもそも「提供」に該当しない場合には、第三者「提供」にはあたらないため、本人の同意が不要となります。
「個人情報の保護に関する法律についてのガイドライン」に関するQ&A (令和4年5月26日更新)Q7-53 では、「提供」の解釈について、「当該クラウドサービス提供事業者(筆者注:生成AIサービスをクラウドサービスとして提供している事業者も含みます)が、当該個人データを取り扱わないこととなっている場合には、当該個人情報取扱事業者は個人データを提供したことにはならないため、「本人の同意」を得る必要はありません。」としています。
そして、同QAでは「当該クラウドサービス提供事業者が、当該個人データを取り扱わないこととなっている場合」とは、「①契約条項によって当該生成AI事業者がサーバに保存された個人データを取り扱わない旨が定められており、②適切にアクセス制御を行っている場合等」とされています。
たとえば、OpenAIは、API経由で入力されたデータについては、学習用には利用をしないと明言していますが、API data usage policies(2023年3月1日更新版) によれば、API経由のデータであっても、「不正使用や誤用の監視を目的として、APIデータを30日間保持します。OpenAIの限られた権限のある従業員、および機密保持とセキュリティの義務を負う専門の第三者請負業者は、不正使用の疑いを調査および検証するためだけにこのデータにアクセスできます。」としています。
また、Microsoftが提供しているAzure OpenAI Serviceの「Data, privacy, and security for Azure OpenAI Service」においては「Azure OpenAI Service は、適用される製品規約に違反する可能性のある方法でのサービスの使用を示唆するコンテンツおよび/または動作を監視するために、サービスからのプロンプトおよび生成物を最大 30 日間保存します。マイクロソフトの正規従業員は、自動化されたシステムを起動させたプロンプトおよび生成物データを確認し、潜在的な不正使用を調査および確認することができます。」としています。
このように、監視目的での人間によるアクセスに限定されている場合に、上記で紹介した「①契約条項によって当該生成AI事業者がサーバに保存された個人データを取り扱わない旨が定められており、②適切にアクセス制御を行っている場合等」に該当するのかははっきりしません。
一方、先ほど紹介したMicrosoftが提供しているAzure OpenAI Serviceの「Data, privacy, and security for Azure OpenAI Service」においては、「機密性、高度な機密性、または法的規制のある入力データの処理を伴うが、有害な生成物および/または誤用の可能性が低いユースケース」について、ユーザーが申請した場合は、Microsoftは、不正使用監視機能をオフにし、ユーザーが入力したプロンプトおよび生成物を保存しない扱いにしているようです。
このような扱い(監視目的であっても一切アクセスしない)であれば、個人データの入力が「提供」には該当しないとして、第三者提供規制については考慮しなくてもよい整理できる可能性が高くなります。この点は、生成AI事業者が「外国にある第三者」である場合に特にメリットが大きい部分です。
(2) 入力した情報が生成AIサービス内でどのように処理されるのか②「委託」該当性
上述の通り個人データを「第三者」に提供する際には原則として本人の同意を得る必要があります(個情法27条1項)。
もっとも、例外的に「利用目的の達成に必要な範囲内において個人データの取扱いの全部又は一部を委託することに伴って当該個人データが提供される場合」には、当該委託先は「第三者」に該当せず、本人の同意を得る必要はありません(個情法27条5項1号)。
ここで「委託」とは、「契約の形態・種類を問わず、個人情報取扱事業者が他の者に個人データの取り扱いを行わせること」をいい、これは委託元の「利用目的の達成に必要な範囲内において」行われる必要があります(前記個情法27条5項1号)。
具体的には「個人データの入力(本人からの取得を含む。)、編集、分析、生成物等の処理を行うことを委託すること等が想定」されています(「個人情報の保護に関する法律についてのガイドライン」(通則編)(令和4年9月更新)3-4-4)。
したがって、生成AIAI事業者が入力データをどのように利用しているかが「委託」の範囲内での取扱かを判断するのに重要な要素となります。
具体的には、生成AI事業者において入力データが①「入力データの分析や生成物の生成」のみに利用されているのか、それを超えて②「学習」に利用されているのかです。
① 生成AI事業者において「入力データの分析や生成物の生成」のみに利用され「学習」に利用されない場合
この場合は、自社における「入力データの分析や生成物の生成」という処理のため(プロンプトエンジニアリングのために利用することも含む)に個人データを生成AI事業者に取り扱わせているに過ぎませんので、ユーザーの利用目的の達成に必要な範囲内における取扱いと評価できます。
したがって、日本法上は上記「委託」に該当し、個人データ入力に際して本人の同意を得る必要はありません。
たとえば、OpenAI のAPI利用や、ChatGPTでのオプトアウト処理、Azure OpenAIサービスを利用する場合には、それらのサービスの規約上、入力データは学習に利用されないことになっていますので、「委託」に該当します(ただし、OpenAI等は外国の事業者に該当しますので、追加的な規制がかかります。詳細は後述します)。
② ①に加えて生成AI事業者における「学習」に利用される場合
次に生成AI事業者における「学習」に利用される場合はどうでしょうか。
たとえば、OpenAIのChatGPTやDALL-Eのような非APIのコンシューマー向け製品に入力されたデータについては、学習に利用されることになっています(ただしオプトアウト可能)。
委託者(この場合は個人データを入力する事業者)からの個人データの取り扱いの委託は、あくまで委託者の利用目的達成に必要な範囲での生成物作成に限定されることから、このように生成AI事業者におけるモデルの「学習」に利用される場合には、「委託」に伴う個人データの利用の範囲を超える可能性があります。
もっとも、「個人情報の保護に関する法律についてのガイドライン」 に関するQA7-39には以下の記載があります。
(第三者に該当しない場合)
Q7-39
委託に伴って提供された個人データを、委託業務を処理するための一環として、委託先が自社の分析技術の改善のために利用することはできますか。A7-39
個別の事例ごとに判断することになりますが、委託先は、委託元の利用目的の達成に必要な範囲内である限りにおいて、委託元から提供された個人データを、自社の分析技術の改善のために利用することができます。
(令和3年9月追加)
この記載からすると、少なくとも委託者が自社のためのファインチューニングモデル生成のために個人データを入力する行為は、「委託」に伴う個人データの利用の範囲内の行為に該当するように思われます。
それを超えて、委託先(生成AI事業者)が保有するLLMの性能向上のための学習行為が「委託業務を処理するための一環」としての「自社の分析技術の改善」に該当し、「委託」の範囲内に収まるのかは解釈上明確ではありません。
(3) 生成AI事業者が「外国にある第三者」に該当するか
以上では、便宜上、生成AI事業者が外国にある第三者か日本国内の事業者かを区別せずに議論しました。
もっとも、「委託」に伴う提供により本人の同意が不要となるという例外規定が定められているのは、日本国内の事業者に対する「提供」(個情法27条)のみです。
「外国にある第三者」に対する個人データの提供の場面では「委託」の例外は規定されていません(個情法28条)。
したがって、「外国にある第三者」に対する個人データの提供についてはそれが「委託」の範囲内にとどまるとしても、原則として本人の同意を得る必要があります(個情法28条1項) 。
ただし更にややこしいことに、外国事業者全てに、この規制がかかる訳ではありません。
具体的には、以下の場合は、たとえ外国事業者に対する提供でも、委託に伴う提供に際して本人の同意を得る必要はありません。
① EU及び英国内の事業者に提供する場合(個情法28条1項)
② 当該外国事業者との間で当該提供を受ける者における当該個人データの取扱いについて、適切かつ合理的な方法により、法第4章第2節の規定の趣旨に沿った措置(いわゆる相当措置)の実施が確保されている場合(個情法28条1項、同法施行規則第16条第1号)
③ 当該外国事業者が、個人情報の取扱いに係る国際的な枠組みに基づく認定を受けている場合(個情法28条1項、同法施行規則第16条第2号)
④ 法令上の例外に該当する場合
上記①より、生成AI事業者がEU及び英国内の事業者の場合、本人同意を取得する必要はないことになります。
一方、米国企業である、OpenAIの場合、②の「相当措置の実施を確保する」方法が考えられます。
OpenAIはプライバシーポリシーを公開しており、希望するユーザーは同社との間でデータ処理追加条項(DPA)の締結が可能です(ただし、DPAのフォームに記載されているように、DPAを締結できるのは、API利用者に限られ、ChatGPT、DALL-E Labsのようなコンシューマサービス利用者は締結できないようです)。
そして、当該プライバシーポリシー及びDPAの各項目は、概ね「法第4章第2節の規定」に沿った内容になっていることから、OpenAI のAPI を利用するに当たり、同社との間で同社所定の Privacy Policy の適用の確認をし、かつ同社と DPA の締結をすることにより、「相当措置の実施が確保されている」と評価できるでしょう 。
したがって、OpenAI のAPI を利用する場合には、個人データを入力するに際して本人の同意は必要ないということになります。1なお、上記例外に該当する場合であっても、安全管理措置の一環としての「外的環境の把握」(具体的には①所在する外国の名称・個人データが保存されるサーバの所在国の名称を明らかにし、②当該外国の制度等を把握した上で講じた措置の内容を本人の知り得る状態に置くこと)は必要ですので注意して下さい(個人情報保護法 QA 7-54、10-25)
(4) まとめ
以上の検討をまとめると、以下のチャートになります(法規制の一部を省略している部分があります)。
3 他社に対して秘密保持義務を負う秘密情報
次の検討対象は、他社との間で秘密保持契約(NDA)などを締結して取得した秘密情報を生成AIサービスに入力する行為です。この類型は先の知的財産権や個人情報などの法規制の問題とは異なり、他社との間の契約違反に該当するかどうかがポイントとなります。
NDAでは、通常は秘密情報について「第三者に開示してはならない(開示禁止)」及び「特定の目的以外に利用してはならない(目的外利用の禁止)」という制限がかかっています。
たとえば、経済産業省が公開している秘密保持契約の雛形には以下の条項があります。
第2条(秘密情報等の取扱い)
1.甲又は乙は、相手方から開示を受けた秘密情報及び秘密情報を含む記録媒体若しくは物件(複写物及び複製物を含む。以下「秘密情報等」という。)の取扱いについて、次の各号に定める事項を遵守するものとする。
① 情報取扱管理者を定め、相手方から開示された秘密情報等を、善良なる管理者としての注意義務をもって厳重に保管、管理する。
② 秘密情報等は、本取引の目的以外には使用しないものとする。
③ 以下略
2.甲又は乙は、次項に定める場合を除き、秘密情報等を第三者に開示する場合には、書面により相手方の事前承諾を得なければならない。この場合、甲又は乙は、当該第三者との間で本契約書と同等の義務を負わせ、これを遵守させる義務を負うものとする。
3.甲又は乙は、法令に基づき秘密情報等の開示が義務づけられた場合には、事前に相手方に通知し、開示につき可能な限り相手方の指示に従うものとする。
2条1項2号が目的外利用の禁止、同2項が開示禁止の規定です。
(1) 開示禁止規定
パターン2やパターン3の生成AIサービスに秘密情報を入力する行為は、生成AI事業者という「第三者」に秘密情報を「開示」することになるため、開示禁止規定に違反する可能性があります。
ただし、先ほど紹介したようなOpenAIにおけるAPI経由で入力されたデータやAzure OpenAI Serviceに入力されたデータのように、生成AI事業者によるアクセスが、監視目的での人間によるアクセスに限定されている場合であれば、「開示」をしていないと解釈しうる余地は残りますがはっきりしません。
なお、これも先ほど紹介しましたが、Azure OpenAIサービスにおいて、ユーザーの申請に応じてMicrosoftが、不正使用監視機能をオフにし、ユーザーが入力したプロンプトおよび生成物を保存しない扱いにする場合は、第三者に入力データを「開示」していることにはならないと思われます。
(2) 目的外利用の禁止規定
また、入力データの処理内容によっては、秘密情報の目的外利用の禁止規定にも違反する可能性があります。
まず、OpenAIのChatGPTやDALL-Eのような非APIのコンシューマー向け製品に入力されたデータのように、当該入力データ(秘密情報)が生成AI事業者の「学習」に利用される場合は明らかに「目的外利用」に該当します。
さらに、企業が受領した秘密情報を、自社専用モデルのファインチューニングに利用することが「目的外利用」に該当するかですが、そのような行為も通常、秘密情報の利用目的を超えた、自社のための行為であることから、「目的外利用」に該当するように思われます。
一方で、「学習」には利用されず、秘密情報の利用目的として定められている目的(例:取引開始の検討等)のために生成AIサービスに秘密情報を入力(プロンプトエンジニアリングのために利用することも含む)して分析・生成する行為は「目的外利用」には該当しないでしょう。
(3) まとめ
以上をまとめると、① 生成AI事業者が入力データに監視目的での限定されたアクセスしかしない、あるいは一切アクセス・保存しない場合において、② 企業が秘密情報の利用目的として定められている目的のために生成AIサービスに秘密情報を入力(プロンプトエンジニアリングのために利用することも含む)して分析・生成する行為については、NDAに違反しないでしょう。
それ以外のケースにおいてはNDA違反に該当する可能性があります。
今後はNDAの開示禁止規定や目的外使用の禁止規定の例外に「監視目的を除くアクセスがされないことが利用規約によって担保されている生成AIサービスを利用すること」が含まれるようになるかもしれません。
4 自社の機密情報
自社内の機密情報(ノウハウ等)を生成AIサービスに入力する行為です。
この場合、何らかの法令に違反するということはありませんが、生成AIサービスの処理内容や規約の内容によっては当該機密情報が法律上保護されなくなったり特許出願ができなくなってしまうというリスクがあります。
(1) 営業秘密
企業が保有する機密情報のうち、一定の要件を満たす情報(「営業秘密」)は不正競争防止法という法律で保護されています。
具体的には、秘密管理性、有用性、非公知性という要件を満たす「営業秘密」については、その不正取得や、不正開示が不正競争行為として民事上の差止請求・損害賠償請求の対象となりますし、刑事罰の対象にもなっています(不正競争防止法2条1項4号~10号、3条、4条、21条)。
生成AIサービス利用に際して特に問題となるのは営業秘密の3要件のうち「秘密管理性」です。
ある営業秘密を第三者に提供した場合に、この「秘密管理性」が満たされるためには、自社の「秘密管理意思」を明確に相手に示し、当該秘密管理意思に対する開示先の認識可能性が確保される必要があります。
この「秘密管理意思」を示す方法の一つとして典型的なのが、第三者に「営業秘密」を開示する際にNDAを締結することです。
したがって、生成AI事業者の規約上、入力データに関する当該事業者の秘密保持義務が定められていれば、たとえ営業秘密を入力したとしても「秘密管理性」は失われないことになります。
一方、すでに紹介した、OpenAIにおけるAPI経由で入力されたデータや、Azure OpenAIサービスに入力されたデータについては、データ処理という目的にしか利用されず、かつ監視目的でしか人間のアクセスがされないことが規約上明記されていますが、サービス提供者の秘密保持義務について明記した条文はないように思います。
この規約をもって、秘密管理性を満たすかは解釈上明確ではありませんので、安全サイドで考えるのであれば、自社の営業秘密を入力すべきでないでしょう。
なお、入力データが生成AI事業者において学習に用いられる場合には、当該入力データが他のユーザーとの関係でそのまま出力される問題が指摘されています。そのような状態にある場合「秘密管理性」があるとはいえないと思われます。
(2) 特許出願を考えている場合
自社の機密情報をもとにして特許出願を検討している場合にも注意が必要です。というのは、特許出願前に公然知られた(公知)発明に特許は付与されないからです(特許法29条1項1号)。
生成AIサービスへの機密情報の入力により、当該機密情報が「公知発明」になってしまうとすれば、特許が付与されないという重大な問題が起きます。
判例上の傾向としては、出願前に一部の者に発明を開示したとしても、秘密保持義務の合意があれば「公知性」が失われることはない(逆に言えば、秘密保持義務を課さずに開示した場合には公知に該当する可能性がある)と言えます。
とすると、先ほどの(1)営業秘密で述べたように、生成AI事業者の規約上、事業者の秘密保持義務があるかを確認すべきということになります。
5 まとめ
以上、著作物・登録商標など第三者が知的財産権を保有しているデータ、個人情報(個人データ)、他社に対して秘密保持義務を負う秘密情報、自社の機密情報に分けて、入力行為のリスクについて検討してきました。
特に個人情報(個人データ)に関する規制はかなり複雑ですので注意して下さい。
また、繰り返しになりますが、パターン3の生成AIサービスを利用する場合には、ベースとなるLLMを提供している事業者の利用規約・データの取扱と、当該LLMを用いたサービスの利用規約・データの取扱の双方を検討することを忘れないようにして下さい。
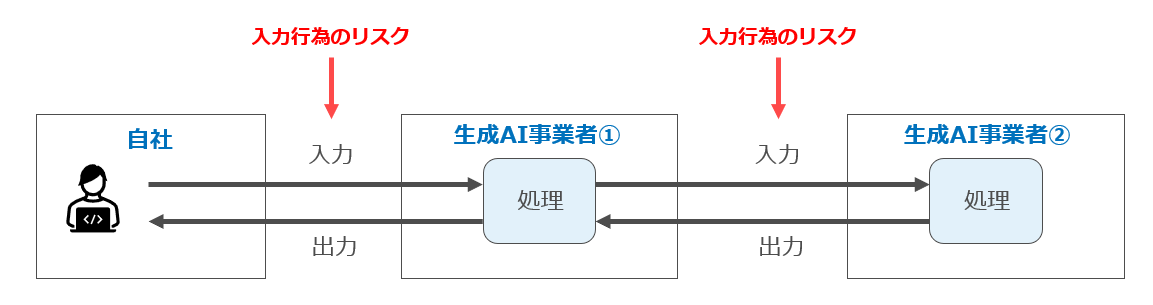
第4 生成物をどのように取り扱っていいのか(生成物利用のリスク)
生成物利用のリスクについては、「生成物を利用する行為が誰かの既存の権利を侵害しないか」「生成物について何らかの知的財産権が発生しているのか」「生成物の利用について制限がないか」の3点が問題となります。
なお、入力行為のリスクにおいては、当該生成AIサービスがパターン1~3のどれに該当するかや、入力データの処理内容が問題となりましたが、生成物利用のリスク評価においては、パターン1~3のいずれに該当するかは影響しません。
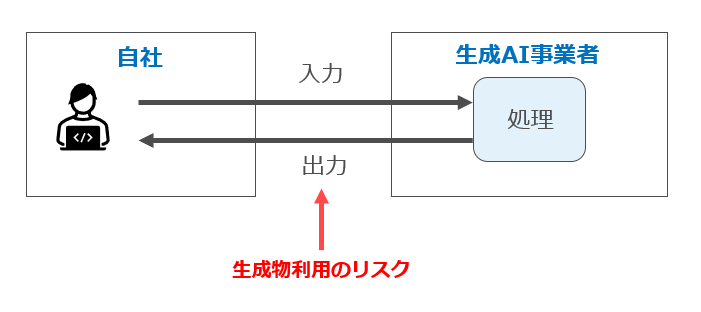
1 生成物を利用する行為が誰かの既存の権利を侵害しないか
(1) 著作権侵害
生成AIサービスからの生成物が、既存の著作物と同一・類似している場合は、当該生成物を利用(複製や配信等)する行為が著作権侵害に該当する可能性があります。
著作権侵害の要件である「依拠性」があるか否かがポイントになるのですが、3つのパターンに分けて検討しましょう。
① 入力データに既存著作物が含まれている場合
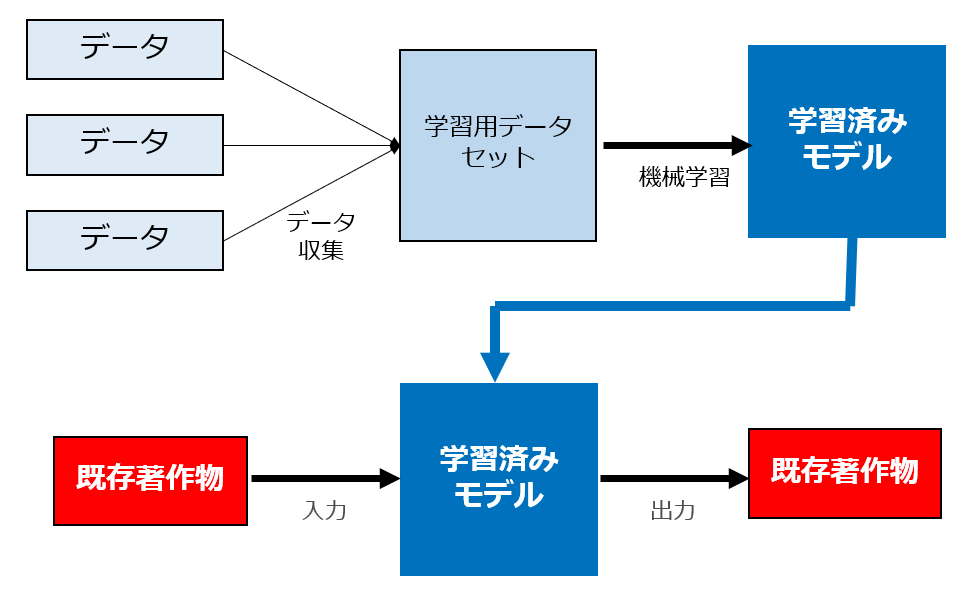
このパターンは画像生成AIにおけるi2iや、言語AIにおける要約・翻訳(文章やコードなど第三者の著作物を入力し、その二次的著作物を生成させる)が該当します。
この場合には依拠性があり、当該生成物は入力データの複製物ないし二次的著作物ですので、その無断利用は当然著作権侵害に該当します。
たとえば、あるライセンスの下で公開されているOSSを入力し、それと類似したコードが出力されたとします。当該類似コードは入力データであるOSSの派生物(二次的著作物)ですので、OSSのライセンスが伝搬し、当該ライセンスの制限下でのみ公開できると思われます。特に当該OSSのライセンスがGPLV3などのコピーレフト系の場合は注意が必要です。
② 学習用データにも入力データにも既存著作物が含まれていない場合
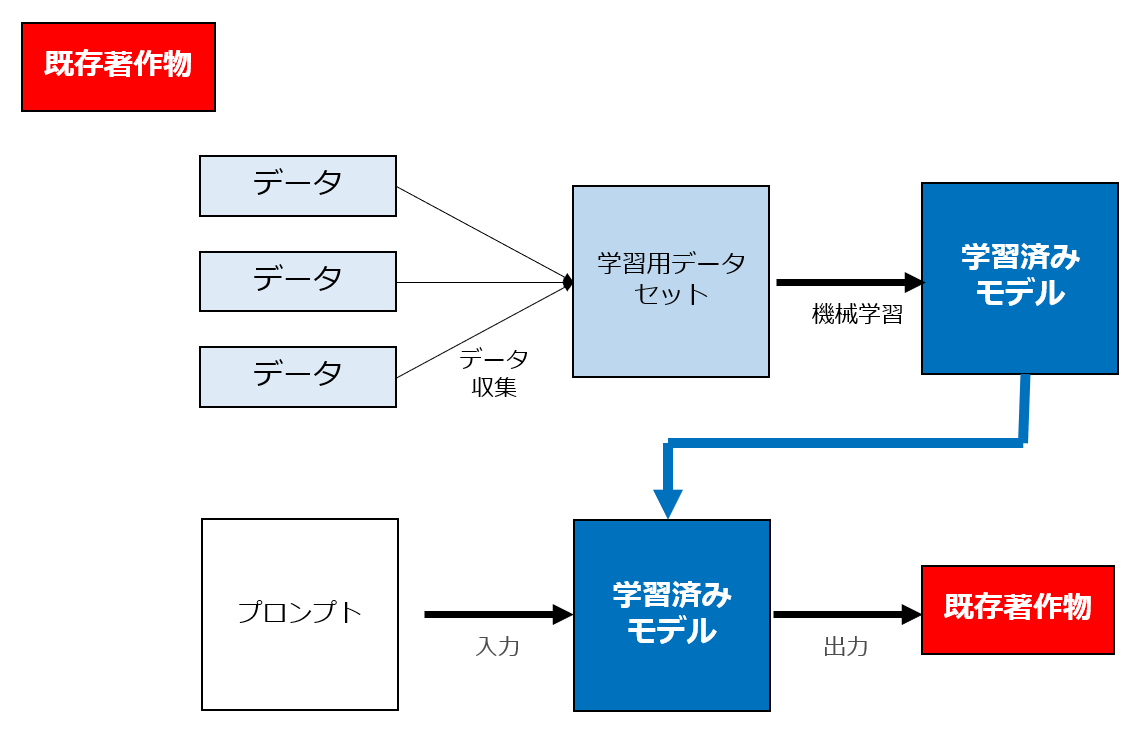
このパターンの場合は、生成AIサービスのユーザーが、当該既存著作物の存在を知っているかどうかにより依拠性の有無が判断されます。
ユーザーが当該既存著作物の存在を知っている場合には、学習用データの内容やプロンプト・入力データの内容に関わらず依拠性が肯定されます。
逆に、ユーザーが、既存著作物の存在を知らず、偶然同一・類似の著作物を生成した場合には独自創作として依拠性がなく著作権侵害に該当しないことになります。
もっとも、既存著作物の出力を意図して① 特定の作者や作家の作品のみを学習させた特化型AIを使っている、あるいは同様の意図を持って② プロンプトに既存の作家名や作品の名称を入力しているという事情がある場合には、依拠性は肯定されると思われます。
③ 学習用データに既存著作物が含まれている場合
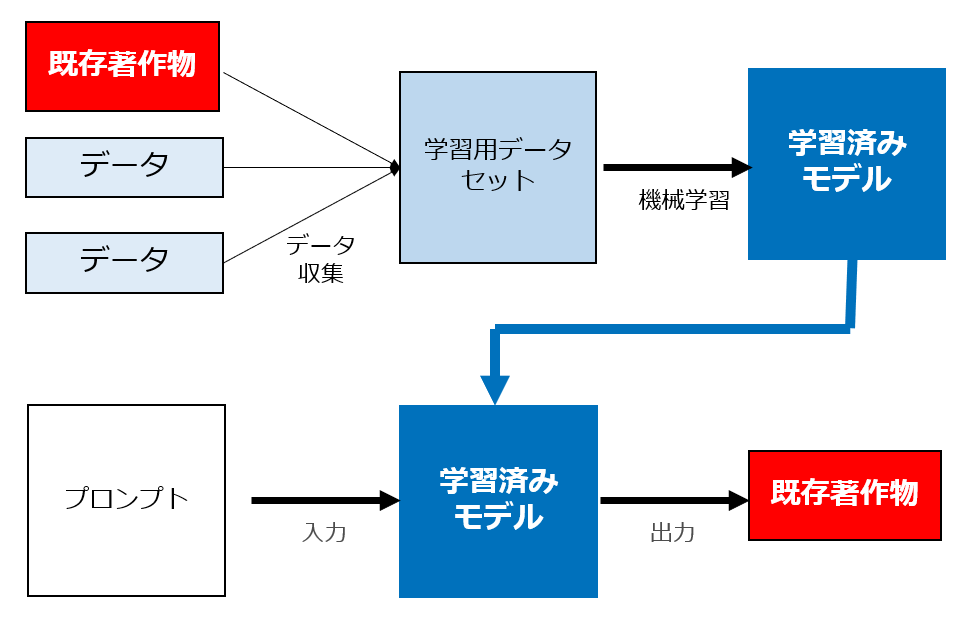
このパターンにおいて、「ユーザーが、出力著作物と同一・類似の既存著作物が学習用データとして利用されていることを知っている場合」には依拠性があることは疑いがありません。
問題は「ユーザーが知らない場合」です。
通常であれば、ユーザーは当該AIの学習用データとして何が利用されているかは知らないことがほとんどなので、このパターンは結構多いと思います。
このパターンで著作権侵害が認められるかは、依拠性が認められるかどうかにかかっているのですが、この点については肯定説と否定説があります(どちらかと言うと肯定説が多い印象です)。
個人的には、大量の偏りのないデータを利用し、機械学習技術を用いて生成された汎用的なAIを利用している場合には、たとえ学習用データと同一・類似の著作物が出力されたとしても(そのようなケースは極めて可能性が低いと思いますが)、同著作物の利用は原則として依拠性がない(著作権侵害には該当しない)と考えています。
ただし、例外的な場合、具体的には、既存著作物の出力を意図して① 特定の作者や作家の作品のみを学習させた特化型AIを使っている、あるいは同様の意図を持って② プロンプトに既存の作家名や作品の名称を入力しているという事情がある場合には、依拠性は肯定されると考えます。
この立場を前提とすると「汎用的AIを利用したか」や「生成AIサービスにどのような入力を行って生成をしたか」が論点になりますが、この点については、著作権侵害訴訟においては権利者側ではなくユーザー側(被疑侵害者側)が立証すべきでしょう。
そうなると、ユーザーは制作ログ(どのようなAIを利用したかや、利用したプロンプト、入力内容、出力内容)を保管しておき、訴訟になった場合には提出しなければならないことになりますが、自己の能力を拡張するツールとして生成AIサービスを利用するのであれば、著作権者の権利とのバランス上、そのような負担を課しても不合理ではないと考えます。
④ 現実的な対応
以上のとおり、解釈上はっきりしない問題が残りますので、企業におけるリスク軽減という観点からは、以下のような対応になるでしょう。
▼ 特定の作者や作家の作品のみを学習させた特化型AIの利用を禁止する
▼ プロンプトに既存著作物、作家名、作品の名称を入力することを禁止する
▼ 利用者に制作ログ保存を義務づける
▼ 特に生成物を配信・公開等する場合には、生成された著作物が既存著作物に類似しないかの調査を行う(画像であればGoogle画像検索等)
(2) 商標権・意匠権侵害
画像生成AIを利用して生成した画像や、文章生成AIを利用して生成したキャッチコピーなどを商品ロゴや広告宣伝などに使う行為は、他者が権利を持っている登録商標権や登録意匠権を侵害する可能性があります。
具体的には「故意に、あるいは偶然出力された、他者登録商標と同一・類似の商標を『使用』(商標法2条3項)」する行為、あるいは、「故意に、あるいは偶然出力された他者登録意匠と同一・類似の意匠を『実施』(意匠法2条2項)する行為は商標権侵害あるいは意匠権侵害になります 。
著作権の場合、著作権侵害に該当するためには、元の著作物に依拠して創作・複製されている必要があり(依拠性)、偶然同一・類似のものを創作・複製しても著作権侵害に該当しません。
しかし、商標権・意匠権については、侵害の要件としてこのような「依拠性」は要求されておらず、「偶然」同一・類似の商標や意匠を生成して「使用」「実施」したとしても商標権侵害・意匠権侵害になります。
しかも、商標権侵害・意匠権侵害の場合、著作権侵害と異なり、侵害者の「過失」が推定されています(商標法39条及び特許法103条、意匠法40条)ので、著作権侵害よりも、より損害賠償請求が認められやすくなっています。
したがって、実務的には、先ほどの著作権侵害の有無のチェックに加えて、登録商標・登録意匠(画像意匠)のチェックが必要となります。
(3) 虚偽の個人情報・名誉毀損等
また、ChatGPTなどは、個人に関する虚偽の情報を生成することがあることが知られています。そのような虚偽の個人情報を生成して利用・提供する行為は、個人情報保護法違反(法19条、20条違反)や、名誉毀損・信用毀損に該当する可能性があります。
2 生成物について何らかの知的財産権が発生しているのか
(1) 著作権
仮に生成物に著作権が発生していないとすると、当該生成物は基本的に第三者にパクられ放題ということになりますので、プロや企業にとっては大きな問題となります。
この論点については、生成AIを利用しての創作活動に人間の「創作的寄与」があるか否かによって結論が分かれます。
① 画像生成AIの場合
画像生成AIの場合であれば、自分の意図通りに高画質の画像を生成するために、詳細かつ長い呪文を唱えて画像を生成した場合、呪文自体の長さや構成要素を複数回試行錯誤する場合、同じ呪文を何度も唱えて複数の画像を生成し、その中から好みの画像をピックアップする場合、自動生成された画像に人間がさらに加筆・修正をした場合などは「創作的寄与」があるとして、それらの行為を行った人間を著作者として著作権が発生することになるでしょう。
なお、生成物に著作権が発生しておりユーザーに著作権が帰属していても、利用した生成AIサービスの利用規約によってはユーザーが権利行使できなくなる可能性がある点に注意が必要です。権利行使できない場合、著作権が発生していても結局パクられ放題ということになるからです。
② 文章生成AIの場合
ChatGPTのような文章生成AIには様々な用途がありますが、そのうち、何らかの文書を入力してその要約や添削後の結果を出力させた場合、当該出力は入力文書の二次的著作物であることが多いと思われるので、出力テキストは著作物であり、入力文書の著作権者=出力文書の著作権者になることが多いでしょう。
一方、文章生成AIのユーザーが何らかの指示をして、何らかのリサーチ結果、アイデアや回答を得た場合、出力テキストにはユーザーの創作意図と創作的寄与は通常はありませんので、文章生成AIによる出力テキストには著作権は発生しないということになると思われます。
文章生成AIから、よりよい出力を引き出すために、質問(入力)の仕方のTIPSが沢山公開されていますが、ユーザーが質問をするにあたってそれらのTIPSを駆使したとしても、出力テキストに対するユーザーの創作意図と創作的寄与が認められることはないでしょう。
したがって、ユーザーが文章生成AI に指示をして、何らかのリサーチ結果、アイデアや回答を得た場合、それらの出力には著作権が発生しない、ということになりそうです。
③ プロンプトの著作権
なお、生成物に著作権が発生しているかとは別の問題として、生成AIに入力するプロンプトを創作した場合、当該プロンプトが著作物かという問題があります。人間が読んで意味が通じるプロンプトでかつ一定の長さがあり、創作性があれば言語の著作物として保護されると思われます。
一方、人間が読んでも意味がわからないプロンプトの場合でも、創作性があれば「プログラムの著作物」(著作権法10条1項9号)として保護されると思われます。著作権法上、プログラムとは「電子計算機を機能させて一の結果を得ることができるようにこれに対する指令を組み合わせたものとして表現したものをいう」と定義されていますが(同法2条1項10の2)プロンプトはまさにこの定義に該当するからです。
(2) 商標登録(商標法)
画像生成AIを利用して生成物した画像や、文章生成AIを利用して生成物したキャッチコピーなどについて商標登録をすることは可能でしょうか。
商標については「自己の業務に係る商品又は役務について使用をする商標」であれば、それ以外の一定の要件を満たせば商標登録を受けることができます(商標法3条)。
そこでは「思想又は感情」や「創作的」であることは要件とされていません。
したがって、生成AIを利用して創作されたロゴ等についても、上記の要件を満たせば商標登録は問題なく可能と思われます。
これは、そもそも商標法が人間の創作を保護する法律ではなく、ブランドやブランドに対する信頼を保護するための法律だからです。
(3) 意匠登録(意匠法)
一方画像生成AIを利用して生成した画像・デザインについて意匠登録をすることは可能でしょうか。
意匠権の場合、「工業上利用することができる意匠の創作をした者は、次に掲げる意匠を除き、その意匠について意匠登録を受けることができる。」(意匠法3条)と規定されていますので、人間による「創作」がなければ意匠登録をすることができません。
したがって、意匠権については著作権と同様、当該意匠の作成に人間の「創作的寄与」があるか否かによって意匠登録できるかどうかの結論が分かれます。
(4) 特許登録(特許法)
生成AIを用いてなされた出力が技術的に価値がある情報だったとしても、特許法上は特許登録が可能な「発明」について「自然法則を利用した技術的思想の創作のうち高度のもの」(特許法2条1項)と定義され、「産業上利用することができる発明をした者は、次に掲げる発明を除き、その発明について特許を受けることができる。」(特許法29条1項)と規定されているので、意匠と同様、人間による「発明」がなされなければ特許登録をすることができません2次世代知財システム検討委員会報告書 22頁脚注33 したがって、特許権については著作権・意匠権と同様、当該発明に人間の「創作的寄与」があるか否かによって特許登録できるかどうかの結論が分かれます。
(5) 営業秘密(不正競争防止法)
生成AIを用いてなされた出力がビジネス上の価値ある情報だった場合、当該情報について営業秘密の3要件(秘密管理性、有用性、非公知性)を満たせば、問題なく不正競争防止法上の営業秘密として保護されます。営業秘密は人による「創作」を要件としていないためです。
3 生成物の利用について制限がないか
生成AIサービスにより生成した生成物をビジネスで利用する場合、当該生成物を商用利用できるかが問題となります。
この論点は、利用する生成AIサービスの利用規約により結論が左右されるので、当該サービスの利用規約をよく読む必要があります。
たとえば、画像生成AIであるMidjourneyの場合、無料会員が生成した画像の著作権はいったん無料会員にAI生成物の著作権が帰属した後、Midjourneyに当該著作権が移転し、その上で、Midjourneyは、当該AI生成物を創作した無料会員に対して、CC4.0NCの下、ライセンスをすることになっています(利用規約)。
つまり、無料会員は当該AI生成物を商用利用することはできません。
一方、OpenAIに関しては、Terms of Use 3(a)で、ChatGPT等への入力データに対する権利がユーザー側に留保され、また生成物に関する権利についても全てOpenAIからユーザに移転する旨が規定されていますので、生成物の利用についての制限はないということになります3 もっとも、これは出力が著作物かどうかについての規定ではありませんし、そもそも出力が著作物かどうかは法令によって定まりますので、利用規約でどのように規定したとしても意味がありません。
そのため、この利用規約は、出力が著作物の場合とそうでない場合に場合分けして理解する必要があります。
(1) 出力が著作物の場合
当該出力の創作行為を行った人(プロンプトを入力した人が多いと思いますが)に出力の著作権が帰属します。そのため、当該出力を無断で複製したり配信したりした人に対して、著作権侵害を根拠として差止請求や損害賠償請求ができます。
(2) 出力が著作物ではない場合
そもそも出力が著作物ではないので、出力行為を行った人を含め、誰にも著作権は発生しません。
そのため、当該出力を無断で複製したり配信したりした人に対しても、出力行為者を含め誰も著作権侵害を主張することはできません。
要するにパクられ放題になります。
この状況を防ごうと思えば、当該出力について、ユーザーとの間で利用許諾契約を締結してコントロールすることが考えられますが、効果は非常に限定的です。というのは、「契約」は契約を締結した人の間でしか効力がないので、契約を締結していない人が出力を無断複製したとしても、契約違反の主張ができないからです。
一方、「著作権」は、あらゆる会社・人に対して著作権侵害を主張することができます。
このように「著作権」は「契約」とは比べものにならないくらい強力であるがゆえに、出力に「著作権」が発生するかが重要なポイントになるのです。 。
なお、パターン2の場合は、生成AI事業者が1社しかいませんので、当該生成AI事業者の利用規約だけを確認すれば良いのですが、パターン3の場合は生成AI事業者が複数いますので、全ての生成AI事業者の利用規約を確認する必要があります。
第5 その他生成AIサービスの規約上の制限に違反していないか
生成AIサービスにおいては、これまで説明してきたリスク(主として法規制)以外にも、サービスの規約上独自の制限を設けていることがあります。
生成AIサービスを利用する場合には、それらサービスの規約上の制限もチェックする必要があります。
たとえば、OpenAIのUsage Policiesでは、「Adult content, adult industries, and dating apps(アダルトコンテンツ、アダルト産業、出会い系アプリ)」「Engaging in the unauthorized practice of law, or offering tailored legal advice without a qualified person reviewing the information(許可なく法律実務を行うこと、または資格のある人が情報をレビューしないままに特定の法的助言を提供すること)」などの具体的禁止項目が定められています。
また、医療、金融、法律業界、ニュース生成、ニュース要約など、消費者向けにコンテンツを作成して提供する場合には、AIが使用されていることとその潜在的な限界を知らせる免責事項をユーザーに提供する必要があることも同規約には明記されています。
さらに、関連規約上は、ChatGPTなどOpenAIのサービスを利用して生成されたコンテンツを公開する際には、AIを利用した生成物であることを明示することなどが定められています。
第6 まとめ
以上、企業が生成AIサービスを導入する際のリスク評価や独自ガイドライン作成、生成AIサービスを利用する際の注意点について説明をしました。
入力行為のリスクについては、著作物、他社登録商標・意匠、個人情報(個人データ)、秘密情報等入力データの種類に応じて検討することが必要です。また、生成AI利用サービスがパターン1、2,3のどれに該当するかで、入力行為のリスクは相当異なりますので、入力するデータの種類によって、どのパターンの生成AIを利用するかを検討すると良いでしょう。
生成物利用のリスクのうち、最も重要なのは「生成物を利用する行為が誰かの権利を侵害しないか」です。また「生成物について何らかの知的財産権が発生しないか」「生成物の利用について制限がないか」は、生成物を業務で利用する場合(特にエンタメ系など生成物を販売/配信等する場合)に重要な事項となります。
■ 本記事の個人情報保護法関連部分については、当事務所の個人情報領域のエキスパートである杉浦健二弁護士と山城尚嵩弁護士から的確な指摘とアドバイスを多数頂きました。お二人に感謝いたします。なお、本記事において指摘されたいかなる誤りについても、筆者自身に責任があります。
【2023/05/01追記】
筆者が有識者委員を務めるJDLA(一般社団法人 日本ディープラーニング協会)から生成AI用ガイドラインのひな形が公開されました。
このひな形を参考に、それぞれの組織内での活用目的等に照らして、適宜、必要な追加や修正を加えて使用して頂ければと思います。
【2023/06/05追記】
個人情報(個人データ)の入力に関する記載を一部修正しました。
- 1なお、上記例外に該当する場合であっても、安全管理措置の一環としての「外的環境の把握」(具体的には①所在する外国の名称・個人データが保存されるサーバの所在国の名称を明らかにし、②当該外国の制度等を把握した上で講じた措置の内容を本人の知り得る状態に置くこと)は必要ですので注意して下さい(個人情報保護法 QA 7-54、10-25)
- 2
- 3もっとも、これは出力が著作物かどうかについての規定ではありませんし、そもそも出力が著作物かどうかは法令によって定まりますので、利用規約でどのように規定したとしても意味がありません。
そのため、この利用規約は、出力が著作物の場合とそうでない場合に場合分けして理解する必要があります。
(1) 出力が著作物の場合
当該出力の創作行為を行った人(プロンプトを入力した人が多いと思いますが)に出力の著作権が帰属します。そのため、当該出力を無断で複製したり配信したりした人に対して、著作権侵害を根拠として差止請求や損害賠償請求ができます。
(2) 出力が著作物ではない場合
そもそも出力が著作物ではないので、出力行為を行った人を含め、誰にも著作権は発生しません。
そのため、当該出力を無断で複製したり配信したりした人に対しても、出力行為者を含め誰も著作権侵害を主張することはできません。
要するにパクられ放題になります。
この状況を防ごうと思えば、当該出力について、ユーザーとの間で利用許諾契約を締結してコントロールすることが考えられますが、効果は非常に限定的です。というのは、「契約」は契約を締結した人の間でしか効力がないので、契約を締結していない人が出力を無断複製したとしても、契約違反の主張ができないからです。
一方、「著作権」は、あらゆる会社・人に対して著作権侵害を主張することができます。
このように「著作権」は「契約」とは比べものにならないくらい強力であるがゆえに、出力に「著作権」が発生するかが重要なポイントになるのです。
・STORIA法律事務所へのお問い合わせはこちらのお問い合わせフォームからお願いします。












