人工知能(AI)、ビッグデータ法務
生成AIの猛烈な進化と著作権制度~技術発展と著作権者の利益のバランスをとるには~

Contents
1 はじめに
日本著作権法30条の4は、AI開発という観点では日本にとっての大きなアドバンテージになるということは何度かお伝えしていますが、最近の生成AIの猛烈な進化に伴って「2018年の30条の4制定段階で生成AIがこれほどまで発展することは想定されていなかった(だから30条の4は見直すべきだ)」という議論を見るようになりました。
この点についての論点を整理し、私の意見をお伝えしようと思います。
2 30条の4と、AI創作物による著作権侵害は無関係
まずはっきりさせておきたいのは、30条の4はあくまで学習段階の著作物の利用を適法化するものであって、AI創作物による著作権侵害を適法化するものではない、ということです。
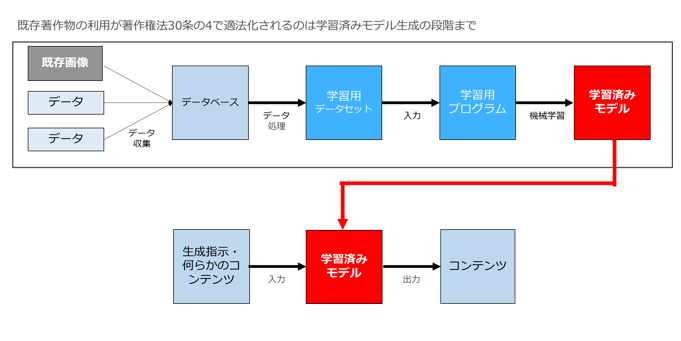
つまりAI創作物による著作権侵害(学習用データと同一・類似の生成物が出力された場合の著作権侵害)については、著作権侵害の要件である「類似性」「依拠性」があるかどうかの問題であって、30条の4は無関係なのです。
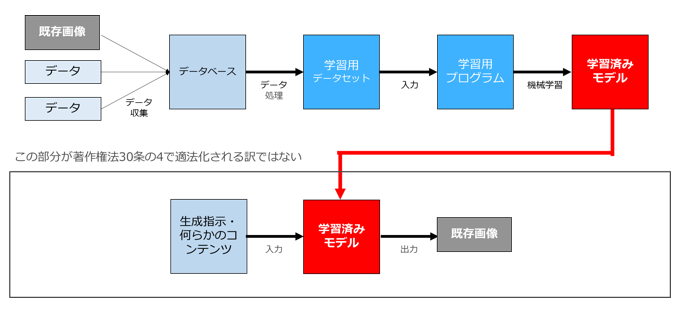
生成AIと著作権法について議論をする際には、「学習」と「利用(生成)」を明確に区別して議論することが非常に重要です。
ここを区別して議論しないと、AIに関する技術革新と著作権者の利益のバランスを大きく欠く結論になります。
ちなみに、海外で行われている画像生成AIに関する著作権侵害訴訟はいくつか存在していますが、集団訴訟の方は、「学習」と「利用(生成)」のいずれも著作権侵害と主張しているようです(はっきりとはしませんが)。
一方Getty ImagesがStability AIに対して提起した訴訟は、明確に「学習」段階のみを著作権侵害と主張しているようです。
3 「2018年の30条の4制定段階で生成AIがこれほどまで発展することは想定されていなかった」のか?
次に、「2018年の30条の4制定段階で生成AIがこれほどまで発展することは想定されていなかった(だから30条の4は見直すべきだ)」という論調がありますが、やはり「学習」と「生成」がごっちゃになった議論になっており、2つの点で違和感があります1ちなみに、山田太郎参議院議員の「【第530回】#AI 画像生成とその課題。権利保護?技術革新?日本の文化を守るには?(2023/03/29)」を拝見しましたが、論点の整理は非常に的確になされています(例:39:25)(ただし、具体的に当該論点でどのように対応すべきかは私は山田議員とは違う意見を持っています。詳細は後述。)。
1つは先ほど言ったように、30条の4は「学習」段階に関する規定であり、生成AIの「利用」段階の著作権侵害(学習用データと同一・類似の生成物が出力された場合の著作権侵害)とは無関係であること。
もう1つは、2018年の30条の4制定段階でも、すでにAI創作物による著作権侵害が発生することは十分想定されていた、という点です。
たとえば2016年4月に公表された「次世代知財システム検討委員会報告書」(知的財産戦略本部 検証・評価・企画委員会・次世代知財システム検討委員会 」のP28には「(4)論点3:AI創作物による知財制度への影響① AI創作物の類似・侵害への対応 」として以下の記載があります(強調部筆者)。
▼創作物間の類似・侵害に関する紛争は両方向から起こりうるが、AI創作物に法的保護は及ばない、あるいは一部のAI創作物のみが保護される、との仮定に立てば、権利を有さない(あるいは権利の弱い)AI創作物側から訴えるというよりは、著作権を有するC(人間の創作者)が、AI創作物の提供者に対し、著作権侵害で訴えていくケースがより一般的に生じると考えられる。
このようなケースにおいては、AI創作物の創作過程における「依拠性」をどのように捉えるかが一つ大きな問題になってくると考えられる。
二つの著作物が類似しており、侵害が問題となるケースにおいて、侵害に該当するか否かは、「その著作物に依拠し結果的に同一あるいは類似のものを作成したかどうか(依拠と類似性)」によって判断されるが、依拠の立証については、人間の創作物同士の争いであっても困難な場合が多いと言われている。
被告(被疑侵害者)の作品が原告の作品に依拠して作成されたという立証責任を負う原告において、通常、被疑侵害者の創作過程において何がなされているかについて知り得ないためである。
被疑侵害作品がAI創作物である場合に、人工知能の内部でどのような処理がなされて当該作品が生成されたのか、原告が探知することは一層難しくなると考えられる。他方で、人工知能が参照あるいは学習したビッグデータの中に原告作品が入っていれば直ちに「依拠」と言えるかについては議論の余地がある。 AI創作物の実用化の動向や具体的な紛争事例なども踏まえつつ、AI創作物の「依拠性」のあり方について検討が必要になると考えられる。
また、2017年3月に公表された「新たな情報財検討委員会報告書」(知的財産戦略本部 検証・評価・企画委員会・新たな情報財検討委員会 」のP37には「課題④-3)AI生成物が問題となる(悪用される等)可能性」「・学習済みモデルから学習用データ(著作物)類似物が出力される問題」として以下の記載があります(強調部筆者)。
▼(注:改正前)著作権法第 47 条の7に基づき著作物を含む学習用データを作成し、当該学習用データを「AIのプログラム」に機械学習させて「学習済みモデル」を作成した後、当該学習済みモデルに何らかの入力を与えて出力した結果の一部又は全部が、元の学習用データの一部又は全部と同一又は類似する場合をどのように考えるかという問題がある。
この場合、出力された生成物が著作権侵害と判断されるためには、依拠と類似性が必要とされると考えられるが、単に学習用データに元となった著作物が含まれているからといって依拠が肯定されるのか、仮に肯定されるとしても学習済みモデルの作成者とAI生成物を出力した者が異なる場合にまで依拠を認めて良いのか等の問題が指摘されている。
これについては、学習用データに含まれる著作物の全部又は一部と同一又は類似するものが学習済みモデルから出力された場合に、仮に依拠を一律に否定するとAIを利用すれば著作権侵害を否定できるようになり、その結果、著作権侵害を目的としてAIを利用することや実際にはAIを利用しない場合でも侵害逃れのためにAIを利用したと僭称することが想定されるのではないかとの指摘がある。こうした指摘を背景に、著作物が学習済みモデル内に創作的な表現の形でデータとしてそのまま保持されている場合は依拠を認めるべきとの指摘や、そのまま保持されていなくとも学習用データに含まれている等の元の著作物へのアクセスがあれば依拠を認めても良く、侵害の成否については類似性のみで判断すれば良いとの指摘があった。
一方で、著作物が創作的表現としてではなくパラメータとして抽象化・断片化されている場合等は、アイデアを利用しているにすぎず依拠を認めるべきではないのではないかとの指摘があった。また、人間の創作における依拠とパラレルに考えた場合、仮に著作物へのアクセスがあれば依拠があると認めてしまうと、著作権法上の独自創作の抗弁が機能しなくなり、表現の自由空間が狭まるおそれもあるとの指摘もあった。
この問題についても、AIの技術の変化は非常に激しく、問題となった具体的な事例が多くない状況では、人間の創作を前提とした従来の依拠の考え方をAIの創作の場合に当てはめて良いのか更に検討を進めることが必要であり、現時点で、具体的な方向性を決めることは難しいと考えられる。
さらに、仮に依拠及び類似性が認められ、著作物の権利を侵害するとした場合、権利侵害の責任は誰が負うのか、利用者か学習済みモデルの作成者なのかという問題が生ずる可能性がある 77。現在の状況においては、利用者・学習済みモデル作成者それぞれが責任を負うとも考えられるが 78、今後、AI生成物の出力に対する利用者(人間)の関与が減少していった場合に利用者に責任を負わせて良いのかという問題が生じる可能性もあるが、現時点でAIの技術の可能性について必ずしも予断することはできず、同様に具体的な方向性を決めることは困難と考えられる。以上から、AIを利用した場合の依拠や責任の考え方について、問題となった具体的な事例に即して引き続き検討することが適当と考えられる。
このように、2018年の30条の4制定段階でも、すでにAI創作物による著作権侵害が発生することは十分想定されていました。
もっとも、先ほど紹介した2つの報告書の内容からおわかりのように、AI創作物による著作権侵害が発生することは十分想定されていましたが「だからどうする」ということまでは具体的には検討されていません。
また、AI創作物による著作権侵害の問題と、学習段階における著作物の利用(つまり30条の4)を結びつけた議論もなされていません(この点は山田議員が整理するとおりです。私の知る限り政府や学者の間ではそのような議論は今も昔もありません。)
なぜなら先ほど言ったように「両者は関係ない」からです。
ちなみに、ここ勘違いしている人が多いのですが、「30条の4があるからAIが絡めばなんでも著作権フリー!」ではありません。
たとえば、最近ちょっとずつ出てきている以下のような論文AIサービスを考えてみましょう。
著作権が存在する論文を無断で集積してデータベース化し、検索語を入力すると、AIが良い感じで検索し、検索結果として書誌情報だけでなく関連する論文の全文・相当部分が表示されるようなサービス
このようなサービスは、出力対象となる著作物を事業者が収集・蓄積した上で、ユーザーからの指示に応じて当該著作物の出力行為(ユーザーへの送信行為)を行っているのは事業者ですので、当該著作物の利用主体は事業者です。
そして、当該出力行為(ユーザーへの送信行為)は、著作物の公衆送信行為に該当しますので、当該著作物の著作権者の許諾を得なければ、事業者の行為は著作権侵害に該当します。
つまり、たとえ情報処理(蓄積含む)の段階でAIのような情報解析技術を使っていたとしても、事業者が予め収集・蓄積していた著作物をそのままユーザーに出力(送信)する場合、当該出力(=複製・公衆送信)行為は事業者の行為となり、かつ当該出力行為は「情報解析」等(30条の4)にも該当しません。
これは、検索語から適切な出力対象を選択する部分にAI技術が使われていたとしても同様です。
したがって、このようなサービスにおいて事業者によるユーザーへの著作物の出力(送信)が無許諾の行為であれば、普通に著作権侵害に該当します。【参考】
自然言語系AIサービスと著作権侵害
4 生成AIにおける「利用(生成)」と著作権侵害についてどう考えるべきか
この問題については、主として「類似性」「依拠性」の問題となりますが、従前の著作権侵害訴訟において依拠性・類似性についてはこれまで蓄積された司法判断がありますし、ある程度の予測可能性はあります。
したがって、この点については立法による解決ではなく基本的には司法判断に委ねるべきと考えます。
もっとも、AI特有の論点として、学習用データと同一・類似の生成物が生成された場合の「依拠性」についてどのように考えるかという大きな論点があります。
この点について、私の立場は以下の通りです。
①大量の偏りのないデータを利用し、機械学習技術を用いて生成された汎用的なAIを利用して、かつ② 他人の著作物を入力していない、あるいは他人の著作物を入力している場合でもその翻案物が出力されていない場合には依拠性はない
ちょっと判りにくいので表にしてみました。
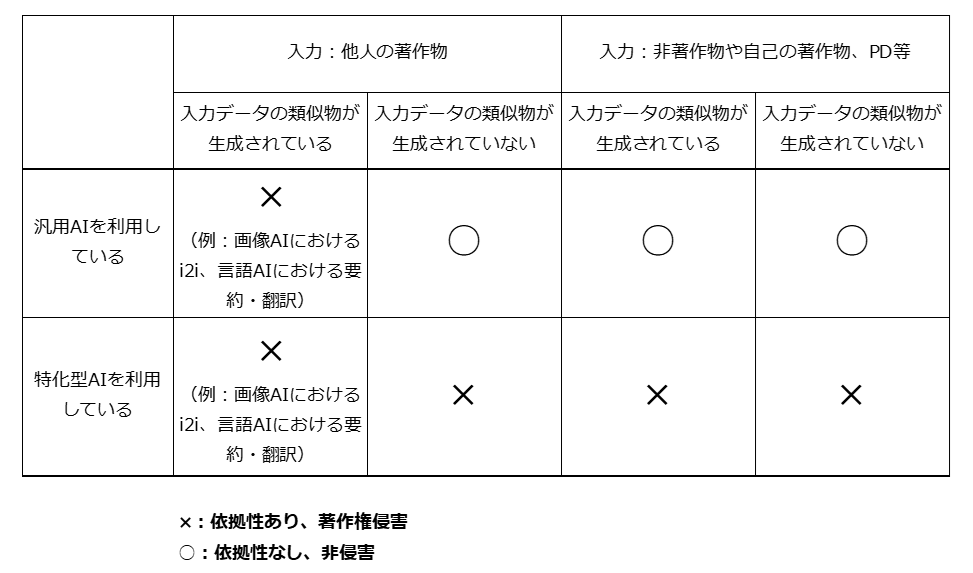
したがって、以下の場合は依拠性があり著作権侵害になります。
▼ ①の要件の関係
・ AIを利用したと言いつつ実は利用していない
・ AIと言いつつ実は単なる学習用作品のデータベースである
・ 特定の作者や作家の作品のみを学習させた特化型AIを使っている(●●風AI)
▼ ②の要件の関係
・ 画像AIの場合i2iである
・ 言語AIの場合、他人の著作物を入力してその二次的著作物を生成させている
この立場を前提とすると「汎用的AIを利用したか」や「どのような入力を行って生成をしたか」が論点になりますが、この点については、著作権侵害訴訟においては権利者側ではなく利用者側(被疑侵害者側)が立証すべきでしょう。
そうなると、利用者は制作ログ(どのようなAIを利用したかや、利用したプロンプト、入力内容、出力内容)を保管しておき、訴訟になった場合には提出しなければならないことになりますが、自己の能力を拡張するツールとしてAIツールを利用するのであれば、著作権者の権利とのバランス上、そのような負担を課しても不合理ではないと考えます。
そして、「生成AIにおける「利用(生成)」と著作権侵害」の論点について立法で手当てするのであれば、そのあたりの訴訟上のルールとしての立証責任の明確化を行うことが適切だと思います。
それを超えた強力な立法(たとえば「AIツールの利用者は出力が学習用データに含まれているかを調査する義務がある」や「学習用データに含まれていれば依拠性があり著作権侵害とみなす」等)には筆者は明確に反対します。
そのような立法がなされると、怖くて誰もAIツールを利用することができなくなってしまうからです。
5 生成AIにおける「学習」と著作権侵害についてどう考えるべきか
(1) 司法判断(条文の解釈問題)か立法問題か
この点は4と異なり、生成AI特有の問題ではなく、あらゆるAIに共通する問題です。
学習段階における著作物の利用が著作権侵害に該当するかについては、司法判断においては、30条の4の但書(「ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。」)の解釈問題です。
この点については、いろいろな論稿が出ているところですので詳細は割愛します。
ただ、著作権法30条の4の立法趣旨からすると、30条の4の但書の解釈は相当謙抑的に考えなければ筋が通りませんので、もし学習段階における著作物の利用に関し、著作権者の利益を守る方向性で考えるということであれば、条文の解釈でなんとかする問題ではなく立法しかないというのが私の意見です。
(2) 仮に立法をするとするとどのような方向性が考えられるか
仮に「学習」と著作権侵害に関する立法をするのであればどのような観点を考慮すべきでしょうか。
もともと著作物については、(1)まず著作者による創作が行われ、(2)それが流通して受領者の手元に届き、(3)受領者の手元で様々な目的で利用される、という構造になっています。
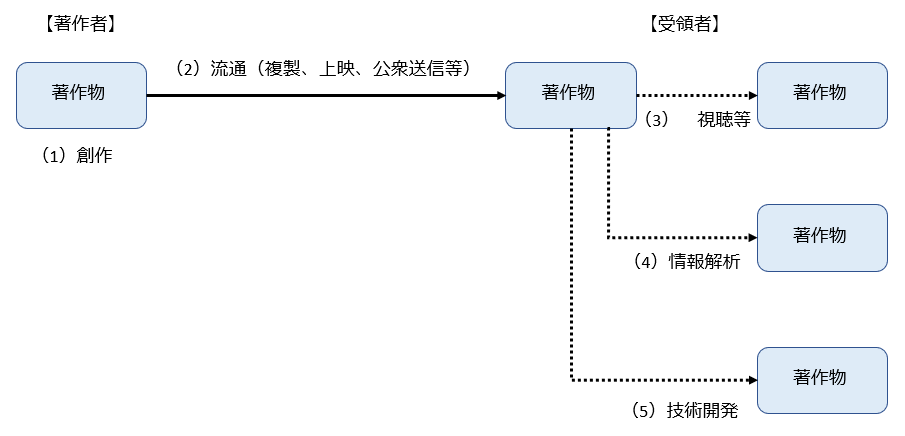
もっとも、著作物については「視聴する」(=享受する)というのが本来的用途であり、その本来的用途に向けての流通(視聴、上映、公衆送信等)について著作権者に著作権を付与し、著作権者がコントロールできるようにする」というのが著作権法の基本的な考え方です。
この「本来的用途」とそれに向けられた流通が下記の図の赤枠分です。
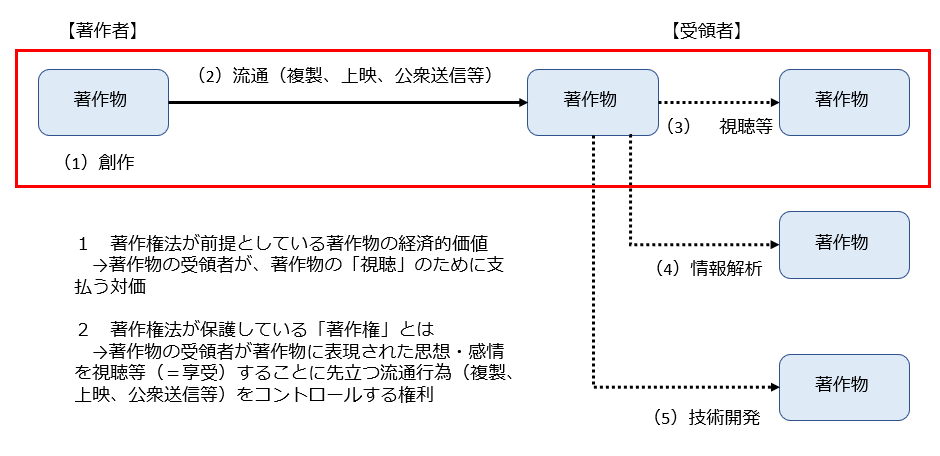
そのため、この「本来的用途」ではない利用(=非享受利用、赤枠部分以外の「情報解析」や「技術開発」の用途での利用)については、著作権者がコントロールできるようにする必要はなく、自由に利用可能(著作権の範囲に含まれない)とすればよいのであって、それが30条の4の趣旨です。
もっとも、今後更なるAI技術の発展に伴い、将来のどこかの段階で、この著作物の「本来的用途」に「視聴(=享受利用)」だけではなく「AI開発等の技術開発(=非享受利用)」も含まれるようになってくる可能性があります。
そうなると、「AI開発等の技術開発」用途の著作物の利用についても著作権の対象とすべきという議論にいつかはなってくるかもしれません。
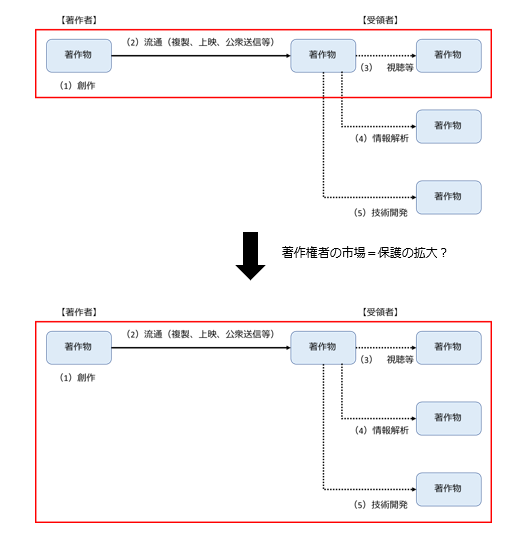
ただし、仮にこのような議論をするのであれば、先ほどお伝えしたように30条の4但書の解釈の場面ではなく「立法」でやるべきです。
現行の30条の4の制定時には著作物の「本来的用途」に「視聴」だけではなく「AI開発のような技術開発」も含まれるのか、というような著作権法の存在意義を問うような議論はなされていないからです。
仮に著作物の「本来的用途」に「視聴」だけではなく「AI開発のような技術開発」も含まれるとすると、著作権法の目的(著作物を保護することにより文化の発展に寄与する)と果たして整合するのかという議論も必要でしょう。
また、著作物の「本来的用途」に「視聴等」に加えて「AI開発用のような技術開発」も含まれるとしても、両者の用途は需要者層や、人の知覚が伴うか、著作物が利用される量や形式などの点において相当異なります。
したがって、仮に立法をするにしても、どのように制度設計するかについては、著作権者の利益と技術開発とのバランスをとるべく、極めて慎重な検討が必要だと思います。
私自身は現状では立法的な措置をとる必要性があるとは考えていませんが、以下は、もし立法的な措置をとるとしたら、という前提での試論です
まず、1つの極端な方向性としては、30条の4を廃止あるいは制限するという方向があります。
この方向を採用すると、「AI開発等の技術開発」用途の著作物の利用についても一部又は全部が権利制限の対象外(=著作権の対象)となり、当該利用が無断でなされた場合に著作権者は差止請求ができることになります。
しかし、こうなると学習用データに1つでも無許諾の著作物が含まれていれば学習自体(あるいは学習に先立つ著作物の収集)を差し止めることができることになりますが、それは技術進展をあまりに阻害しすぎるのではないかと考えています。
そこで、異なる方向性を考えてみます。
ざっと思いつく範囲ですと「学習用データの著作権者に対する補償金制度の創設」と「権利者による事前の機械的に読み取り可能な方法でのオプトアウト」が考えつきます。
① 学習用データの著作権者に対する補償金制度の創設
学習用データの著作権者に差止請求権は付与しないが、補償金請求権を付与するという制度です。
類似の制度としては2018年5月の法改正で創設された授業目的公衆送信補償金制度が参考になると思います。この制度は、2018年の法改正で、ICTを活用した教育での著作物利用可能範囲が拡大されたことに伴い導入された制度です。簡単にいうと「教育目的という一定の目的のためであれば原則として無許諾で著作物を利用できるが、その代わり補償金を支払わなければならない」という制度でして、AI開発のための著作物の利用にも応用できる方法のように思います。
ただし、教育目的のための著作物の利用とAI開発のための著作物の利用は、その利用規模が全く異なる(関係する著作権者の数が段違いです)ことと、教育目的のための著作物の利用の場合はまさに「視聴等」のために利用されているのに対し、AI開発のための著作物の利用は「視聴等以外」のために利用されていることから、補償金制度の制度設計は非常に難しそうです。
② 権利者による事前の機械的に読み取り可能な方法でのオプトアウト
事前に権利者が学習に使われることを拒絶するのであれば、その意思は尊重すべきという意見は十分に理解できます。そこで「権利者による事前の機械的に読み取り可能な方法でのオプトアウト」が考えられます。
実は、同じ発想の類似制度はすでに日本の現行著作権法の中にもあります。
それは、著作権法47条の5(軽微利用)です。
この条文は、簡単に言うと「検索や情報解析を行い、その結果を提供するに際して著作物を一部利用すること」(たとえば、検索結果表示におけるスニペット表示など)を許容する条文です。
これらの「軽微利用」を行うためには、「当該行為を政令で定める基準に従つて行う」ことが必要とされているのですが(法47条の5第1項)、この「軽微利用」のうちインターネット情報検索サービスについては(同1号)、「robots.txtや対象Web頁のHTMLのページヘッダ内にメタタグにより「情報収集禁止」と記述がされているWeb情報」については収集することができません(著作権法施行令7条の4第1項、同施行規則4条の4)。
この規定はあくまで著作権法47条の5に基づいて「インターネット情報検索サービスを提供するに際して検索対象ページの一部を表示する場合」に限って適用されるものであり、30条の4に定める「情報解析等の非享受利用」をする場合に適用されるものではありません。
将来的には、30条の4に定める「情報解析等の非享受利用」をする場合にも同様の条文を適用し、権利者による事前の機械的に読み取り可能な方法でのオプトアウトを認める余地はあるかもしれません。
6 まとめ
▼ 生成AIが急激に発展しているが著作権との関係では「学習」と「利用(生成)」を明確に区別すべき。
▼ 著作権法30条の4と、AI創作物による著作権侵害は無関係。
▼ 生成AIにおける「利用(生成)」と著作権侵害については、依拠性が問題となるが、「①大量の偏りのないデータを利用し、機械学習技術を用いて生成された汎用的なAIを利用して、かつ② 他人の著作物を入力していない、あるいは他人の著作物を入力している場合でもその翻案物が出力されていない場合には依拠性はない」というのが筆者の意見。立法措置とをとるのであればその点についての立証責任の転換にとどめるべきであり、それ以上の強力な「規制」には明確に反対。
▼ 生成AIにおける「学習」と著作権侵害については、条文解釈の問題ではなく立法を検討すべき。仮に立法をするのであれば、具体的には「学習用データの著作権者に対する補償金制度の創設」と「権利者による事前の機械的に読み取り可能な方法でのオプトアウト」の2つが考えられる。
- 1ちなみに、山田太郎参議院議員の「【第530回】#AI 画像生成とその課題。権利保護?技術革新?日本の文化を守るには?(2023/03/29)」を拝見しましたが、論点の整理は非常に的確になされています(例:39:25)(ただし、具体的に当該論点でどのように対応すべきかは私は山田議員とは違う意見を持っています。詳細は後述。)
・STORIA法律事務所へのお問い合わせはこちらのお問い合わせフォームからお願いします。












