人工知能(AI)、ビッグデータ法務
大規模言語モデル(LLM)に関するビジネスと法律~LLMやデータセットの構築と提供(レイヤー1)~

第1 はじめに
前回の記事で大規模言語モデル(LLM)に関するビジネスは3つのレイヤーに分けると理解しやすいというお話をしました。
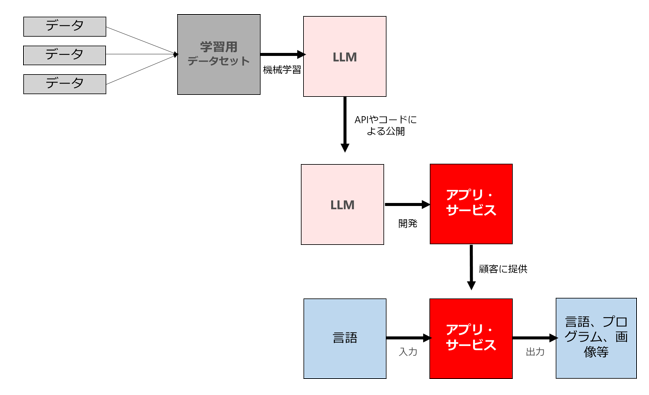
このうち、レイヤー1は「大規模データセットや大規模言語モデルを自ら開発して公開・提供するレイヤー」です。
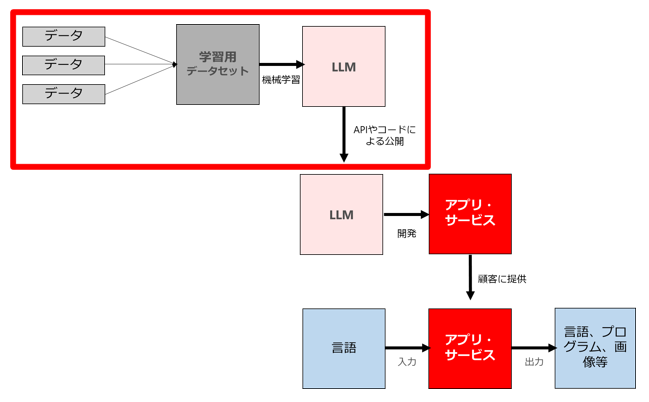
このレイヤーに関する最近の話題としては、自民党が公表したホワイトペーパー(案)や、OpenAIのサム・アルトマンCEO来日+日本への7つの提言などがありますね。
【関連リンク】
▼ 自民党AIの進化と実装に関するプロジェクトチーム
▼ 来日したOpenAIのアルトマンCEO、日本へ7つの提案–自民党の塩崎議員が明かす
今回の記事は、このレイヤー1に取り組む際の法的な留意点について解説をしたいと思います。
レイヤー1に関する論点の全体構造は以下のとおりですが、全部を解説するとボリュームが大きくなりすぎるため、とりあえず最も良く問題となる①に絞ります。
① データの収集・利用についての著作権法・個人情報保護法制のクリア
大規模言語モデルを生成するためには、まず大量の言語データを収集する必要がありますが、当該データを収集するためには法規制のクリアや知的財産権の権利処理が必要となります。
実務上、よく問題となるのは「個人情報保護法制のクリア」「著作権の権利処理」です(それ以外にも、一定の利用規約の下公開されているデータセットを利用する場合、当該利用規約の遵守が必要となりますが、あまり大きな問題ではないので割愛します)です。
ここでは、WEB上からデータを収集することを前提に検討します。② データセット・モデルの知的財産権
生成したデータセットやモデルに知的財産権(特に著作権)が発生するかの問題です。データセットやモデルのライセンス違反が生じた場合に著作権侵害の責任を追及できるかという形で問題となります。③ データセットやモデルを公開・提供する場合の利用条件
生成したデータセットやモデルをコードやAPI等の様々な形式で公開・提供する場合にはその利用条件・ライセンスを適切に設定する必要があります。④ データセットやモデルのユーザーによる違法行為
データセットやモデルを公開した場合、当該モデルを用いて様々なアプリやサービスが開発されることが予想されますが、当該アプリやサービスの利用ユーザにより何らかの違法行為が行われる可能性もあります。その場合、データセットやモデルの提供者が責任を負うか、が問題となりますが、大規模なデータセットや当該データセットで学習を行った大規模言語モデルの提供の場合、モデルやデータセット提供者が責任を負う可能性は極めて低いと思われます。
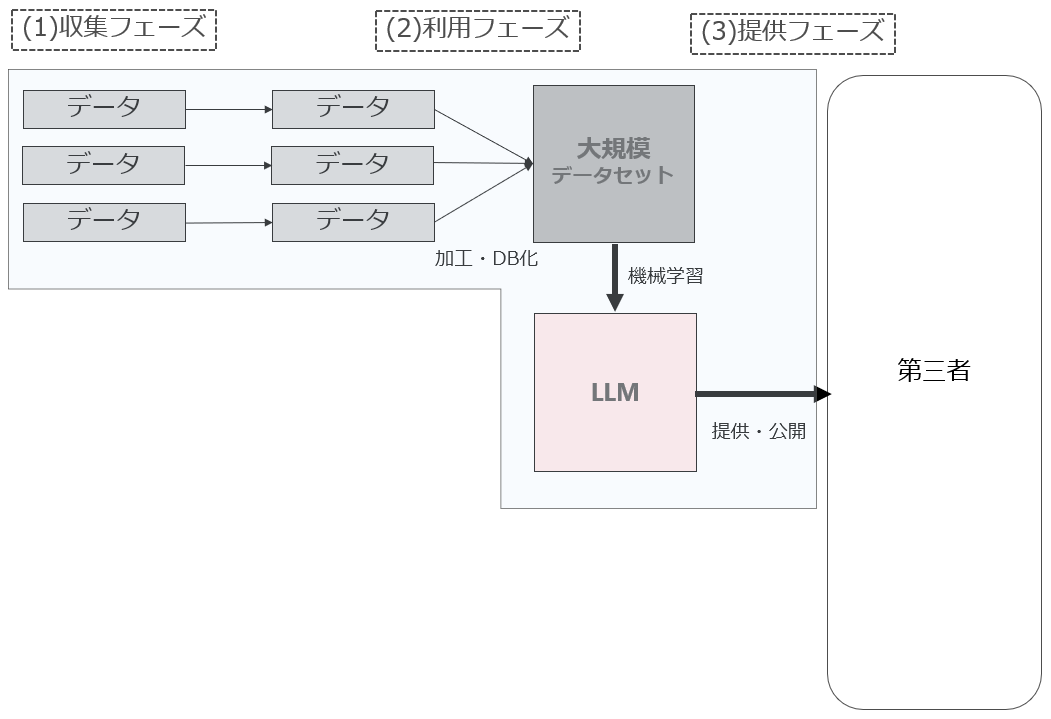
レイヤー1は、時系列的には「データの収集→データの利用による成果物(データセットやモデル)の生成→成果物の提供・公開」となります。
仮に日本(あるいは日本の事業者)が大規模言語データセットを構築した上で、自ら同データセットを利用してLLMを構築するのであれば下図の様なイメージになります。
一方、日本(あるいは日本の事業者)が大規模言語データセットを構築した上で、同データセットをOpenAIなどの第三者に提供し、当該第三者がLLMを構築・追加学習・ファインチューニング等する場合には下図のようなイメージになります。
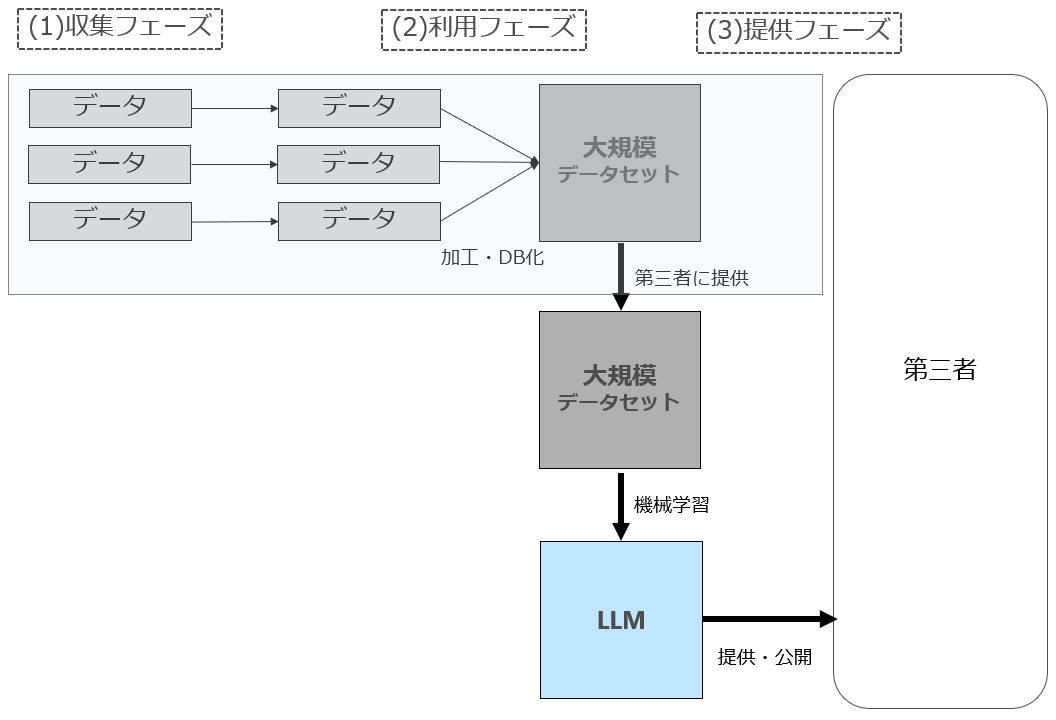
したがって日本がいずれの戦略を採るにしても「データセットの構築・提供」と「LLMの構築・提供」は分けて(作業としてはもちろん一部重複しているのですが)検討をする必要があります。
以下、「データの収集→データの利用による成果物(データセットやモデル)の生成→成果物の提供・公開」の各ステップごとに著作権法上の問題と個人情報保護法制上の問題を解説します1なお、収集の対象となるデータは多くはWEB上のデータですので、今回の記事もそれを前提とします。
第2 著作権法
1 データの収集
(1) 日本著作権法30条の4
LLMやデータセットを作成するためにはWEB上から大量の自然言語データを収集する必要がありますが、それらの自然言語データは通常は著作権法上の「著作物」であるため、データの収集(複製)に関しては著作権法のクリアが必要となります。
もっとも、過去の記事でもご説明しているとおり、LLMの構築のために日本国内において収集行為を行う場合には、日本国著作権法30条の4第2号(「情報解析の用に供する場合」)が適用されますので、原則として著作権者の承諾なくWEB上の自然言語データを収集(複製)することができます。
(著作物に表現された思想又は感情の享受を目的としない利用)
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
以下、ポイントをいくつか紹介いたします。
(2) 例外がある
著作権法30条の4は、情報解析等のためであれば無限定に著作物の利用行為を許すという内容にはなっていません。
条文の但書に記載されているように「当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合」には、たとえ「情報解析」のためであっても著作物を著作権者の承諾なしに利用することはできません。
どのような行為がこの但書に該当する行為かについては、狭く解釈する見解から広く解釈する見解まで様々な意見があります。
もっとも、様々な論者の間で一致しているのは「情報解析を行う者の用に供するために作成されたデータベースの著作物の利用行為」 2改正前著作権法47条の7但書に該当する行為ですについては但書に該当し、著作権者に無許諾で行えば著作権侵害に該当する、という点です。
ただし、あらゆるデータベース(以下「DB」ということがあります)の利用が但書に該当するわけではなく、① 情報解析を行う者の用に供するために作成された②データベースの著作物に該当するDBの利用のみが但書に該当します。
すなわち、「データベースの著作物」に該当しないDBの利用行為は但書に該当しません。たとえば、悉皆的・網羅的にデータを収集したに過ぎないDBについては「データベースの著作物」には該当しません。
また、データベース著作物であっても「情報解析を行う者の用に供するために作成され」ていなければ但書には該当しません(たとえばコンテンツ提供サイトやユーザー投稿サイトなど)。
さらに、データベース著作物のDBとしての創作的な部分を利用する行為が但書に該当するので、当該DBから個々のデータを抽出して一部分のみ利用する行為や、別のデータと合わせて別のDBにして利用する行為についても但書に該当しません。
(3) データ収集や学習に利用するサーバの所在地によって適用される法律が異なる
以上説明したように、「情報解析」のためであれば、かなり広い範囲で著作物の利用を認める著作権法30条の4ですが、この条文は世界的に見るとかなり特殊であると言われています。
他国にも「情報解析」のためであれば自由に著作物を利用できるとの規定はあるのですが、たとえば、英国の場合、「非商業的調査のためのテキストおよびデータの解析のための複製」のみが権利制限の対象となっています(著作権・意匠・特許法29A条、2014年改正) 。
なお、各国の法令の比較については、「新たな知財制度上の課題に関する研究会報告書」(令和4年2月・新たな知財制度上の課題に関する研究会)の別紙2が日本、米国、ドイツ、英国、中国の法制度について比較しており大変参考になります。以下の比較一覧表はこの報告書のp57の引用です。
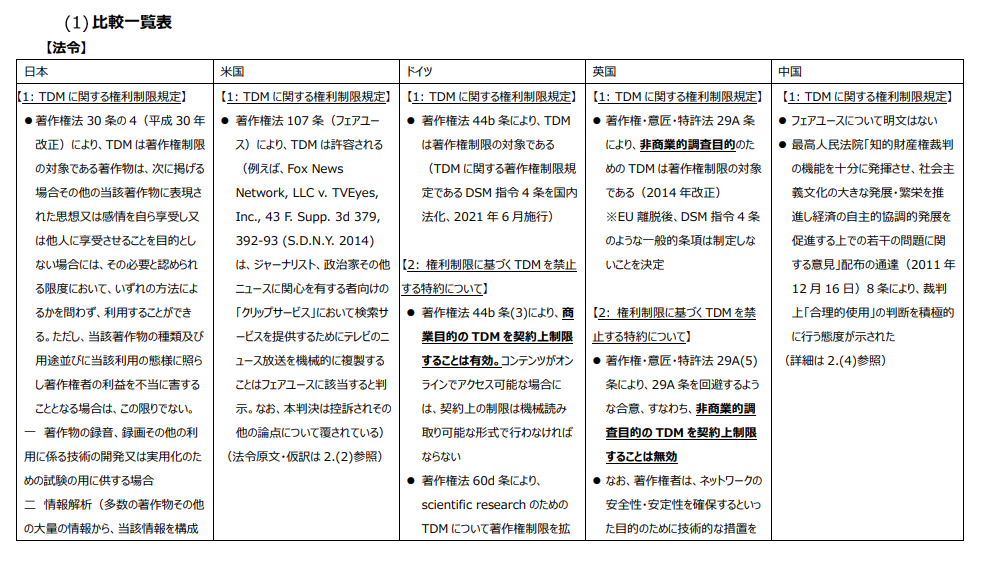
一方、日本の著作権法については、そのような目的の限定がないため、営利企業が営利目的で情報解析を行う場合にも著作権法30条の4の適用があります。
そのため、LLM開発目的で著作物の利用行為を行う者にとっては、「当該利用行為に日本の著作権法30条の4が適用されるのか」が重要な問題となります。
この「ある行為についてどこの国の法律が適用されるか」の問題を「準拠法」の問題といいますが、著作権法に関しては一般的に「当該著作物が利用される地」(利用行為地国)の法律を適用すべきとされています 。
したがって、LLM開発目的で著作物の利用行為を行う場合でも、当該利用に関する利用行為地が日本であれば日本著作権法が適用され、米国であれば米国著作権法が適用されることになります。
では、日本国内にいる作業者が米国内に所在するサーバにおいてLLMの開発に必要な著作物の利用行為(データのダウンロードや機械学習行為など)を行った場合など、国境をまたいだ利用行為が行われる場合に「利用行為地」とはどこを指すのでしょうか。
「利用主体(作業者)がいる場所」と「利用行為が行われるサーバの所在地」のいずれかのみが日本国外である場合に、日本国著作権法の適用があるかについて確たる結論は現時点では出されていません。
したがって、確実に日本国著作権法30条の4の適用を受けるためには、「利用主体(作業者)がいる場所」と「複製等の利用行為が行われるサーバの所在地」のいずれもが日本国内である必要があると思われます。
(4) 著作権者が誰かは無関係
また「利用対象の著作物の著作権者が外国企業(あるいは外国の個人)の場合でも、当該著作物の利用行為は著作権法30条の4が適用され適法になるのか」という質問もよく受けます。
準拠法の問題は、あくまで「利用行為地」が日本国内か否かの問題であって、当該著作物の著作権者が日本の企業なのか外国の企業なのかは無関係です。
外国の企業(あるいは個人)が著作権を有する著作物 についても、当該著作物の利用行為地が日本国内であれば著作権法30条の4は適用され、適法となります。また、同様の理由により、利用するコンテンツが提供されているサイトのサーバー所在地は利用行為地の判断にあたり考慮されません。
2 データセットの作成・モデルの作成
データセットやモデルの作成に際しては、収集したデータ(著作物)を加工することになりますが、それらの加工行為は、著作権法上は著作物の複製や翻案に該当します。
そして、先ほどの著作権法30条の4は「その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる」と定めていますので(強調部筆者)、データセット・モデルの作成に際しての複製や翻案も問題なく行うことができます。
3 データセット・モデルの公開
(1) データセットの公開
まず、データセットの公開ですが、データセットの中には、収集対象になったデータ(著作物)が含まれています。
したがって、当該データセットの公開や提供は、元データの公衆送信行為や譲渡行為に該当しますが、これも著作権法30条の4が「情報解析(略)の用に供する場合」には「その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる」と定めていますので、同条が適用される限り適法です。
あたりまえじゃん、と思うかもしれませんが、実は著作権法30条の4の前身である改正前著作権法47条の7は「著作物は、電子計算機による情報解析(略)を行うことを目的とする場合には、必要と認められる限度において、記録媒体への記録又は翻案(これにより創作した二次的著作物の記録を含む。)を行うことができる。(以下略)」 と定めていました。
つまり、著作権法30条の4が施行されるまでは、「情報解析を行うことを目的とする場合」に「記録または翻案」を行うことしかできなかったのです。
言い換えると他人による情報解析のための著作物の利用や、作成したデータセットの公衆送信や譲渡は認められておらず、モデルを生成する主体自身がデータセットを生成してモデルを作るしかありませんでした。
しかし、著作権法30条の4が「情報解析(略)の用に供する場合」には「その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる」と定めたことにより、「自らのために作成したデータセットの共有」及び「他人のために作成したデータセットの共有」も合法的に可能になりました。
この点は、著作権法30条の4の施行によって大きく変わった部分です。
以下は文化庁の「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方(著作権法第30条の4,第47条の4及び第47条の5関係)」の該当部分です。
問 11 人工知能の開発に関し,人工知能が学習するためのデータの収集行為,人工知能の開発を行う第三者への学習用データの提供行為は,それぞれ権利制限の対象となるか。
(前略)
また,収集した学習用データを第三者に提供する行為についても,当該学習用データの利用が人工知能の開発という目的に限定されている限りは,「著作物に表現された思想又は感情を享受」することを目的としない著作物の利用に該当し,法第30条の4による権利制限の対象となるものと考えられる。
(2) モデルの公開・提供
次に、モデルの公開・提供については、著作権法上、何の問題もありません。
もちろん、仮に「当該モデルが、学習に利用したデータ(著作物)の二次的著作物である」とすると、当該モデルについては原則として当該データ(著作物)の著作権者の承諾なく利用することはできません(著作権法28条)。
しかし、あるデータを元に生成されたモデルの内部においては、通常、当該データは学習の過程においてパラメータ化されており、データそのものがそのまま知覚できる形式では残存していません。したがって、当該モデルはそもそも当該データの二次的著作物ではありません。
平たく言うと「あるデータを元に生成されたモデル」は、当該データとは全く別の著作物であり、当該モデルの公開・提供に際して当該データが利用されているわけではないため、当該データに関する権利処理は不要となります。
したがって、たとえば、日本国内で30条の4を使って適法に生成したLLMを、外国に所在するサーバ上にデプロイしてSaaS形式で全世界に向けて提供する、あるいは当該モデルを外国所在の企業にライセンスする行為も適法となります。
第3 個人情報保護法制
1 データの収集
大規模データセットやLLMを構築するためにWEB上からデータを収集する場合、当該データに氏名や生年月日等の個人情報が含まれていることがあります。
そのような個人情報を、本人に無断で収集・取得することはできるのでしょうか。
(1) 個人情報の取得に関する日本の法規制
日本の個人情報保護法では、個人情報の取得に際しては大きく分けて以下の3つの規制がかかっています。
① 偽りその他不正の手段による個人情報の取得の禁止(法20条1項)、
② 要配慮個人情報の取得に際しての本人の同意取得(法20条2項)
③ 個人情報の取得に際しての利用目的の通知・公表等(法21条1項、同2項)
(2) ① 偽りその他不正の手段による個人情報の取得の禁止(法20条1項)、
①については、データセットやLLMの構築のためにWEB上から大量にデータを収集する際に「偽りその他不正の手段」がとられることは考えがたいので問題となりません。
(3) ② 要配慮個人情報の取得に際しての本人の同意取得(法20条2項)
②については、まず「要配慮個人情報」とは「本人の人種、信条、社会的身分、病歴、犯罪の経歴等」をいいます。この「要配慮個人情報」については、その扱いに慎重さが必要であることから、通常の個人情報とは異なる扱いがされており、原則として「取得に際して本人の同意が必要」とされています。
もっとも、WEB上に公開されている要配慮個人情報は、取得及び提供に関する本人の同意を得て公開されたものも多いと思われますが、その場合は、当該要配慮個人情報の取得に際して再度の同意取得は必要とされていません(個人情報の保護に関する法律についてのガイドライン(通則編)3-3-2)。
また、WEB上に公開されている要配慮個人情報は、本人や学術研究機関、あるいは報道機関により報道として公開されていることも多いと思われますが、それらの要配慮個人情報の取得に際しては同意が必要とされていません(法20条2項7号)。
要するに、「本人から同意を得ずに違法に取得された要配慮個人情報がWEBに公開された場合」や「本人・学術研究機関・報道機関以外の主体がWEBに公開した場合」において、当該要配慮個人情報を取得する行為のみが法20条2項違反となります。このようなケースが多いのか少ないのか、あるいはほとんど考えられないのかは、なんとも言えませんが。。
(適正な取得)
第二十条 個人情報取扱事業者は、偽りその他不正の手段により個人情報を取得してはならない。
2 個人情報取扱事業者は、次に掲げる場合を除くほか、あらかじめ本人の同意を得ないで、要配慮個人情報を取得してはならない。
一~六 略
七 当該要配慮個人情報が、本人、国の機関、地方公共団体、学術研究機関等、第五十七条第一項各号に掲げる者その他個人情報保護委員会規則で定める者により公開されている場合
八 略
(3) 個人情報の取得に際しての利用目的の通知・公表等(法21条1項、同2項)
最後に個人情報の取得に際しての利用目的の通知・公表等(法21条1項、同2項)が必要です。
そもそも個人情報取扱事業者は「利用目的」をできる限り特定しなければならないとされています(法17条)。
この、利用目的を「できる限り」特定するとは、個人情報取扱事業者において、個人情報をどのような目的で利用するかについて明確な認識を持つことができ、また、本人において、自らの個人情報がどのような事業の用に供され、どのような目的で利用されるのかについて一般的かつ合理的に予測・想定できる程度に、利用目的を特定することをいいます(QA2-1)。
しかし、逆に言えばそのように利用目的をきちんと特定したうえで、公表していさえすれば、個人情報の取得に際しての利用目的の通知・公表等(法21条1項、同2項)の規制はクリアしていることになります。
(4) GDPRについて
なお、GDPRについては、先ほど説明した日本の個人情報保護法制よりも個人情報の取得について強い規制が存在します。
すなわち、個人データの取得を含む「処理」(processing)が許されるのは、GDPR第6条1項が定める適法化根拠(「本人の同意」「契約履行に必要」「正当な利益」など)がある場合に限られ、そのような根拠がなければ違法になり、高額な制裁金の対象となります(詳細については弊所の杉浦弁護士の記事「ChatGPTにとって日本は”機械学習パラダイス”なのか ~LLM(大規模言語モデル)にとっての個人情報保護法とGDPR~」参照)。
しかし、GDPRが日本の企業に適用されるのは、以下の場合に限られます(GDPR第3条)。
① 日本企業がEU域内に拠点を持ち、その拠点の活動の過程で個人データを処理する場合
② EU域内に拠点がなくても、EU域内にいる者に対して商品やサービスを提供している場合や、EU域内の本人の行動をモニタリングに関して個人データを処理する場合
そして、日本の企業が、ウェブ上に公開されているEU域内の個人に関する情報を収集する行為は上記①②のいずれにも該当しませんので、GDPRは適用されません。
この点において、日本でのLLMの開発には、著作権法だけではなく個人情報との関係でもアドバンテージがあると言えるのかもしれません。
2 データセットの作成・モデルの作成
個人情報が含まれているデータセットを利用してモデルを生成する行為は個人情報の利用行為に該当します。
当初特定・公表している利用目的に、そのような利用行為が含まれていれば、当該目的内で利用することについては特に問題ありません。
一方、GDPRの下では、このような個人情報の利用行為も個人データの「処理」(processing)に該当しますので、GDPR第6条1項が定める適法化根拠(「本人の同意」「契約履行に必要」「正当な利益」など)がなければ行うことができません。
この点についても、GDPRより日本の個人情報保護法制の方が規制が緩やかということになります。
3 データセット・モデルの公開
(1) データセットの公開
個人情報が含まれているデータセットを公開することには、個人情報保護法制上どのような規制があるのでしょうか。
仮に、当該データセットが「個人情報データベース等」(法第16条1項)に該当する場合、当該データセットに含まれる個人情報は「個人データ」(法第16条3項)に該当します。そして、個人データを第三者に提供する場合には原則として本人の同意が必要とされています(法27条1項)。
つまり、データセットが「個人情報データベース等」(法第16条1項)に該当する場合、当該データセットを公開する際には、当該データセットに含まれている個人情報により識別される本人の同意を取得しなければならないということになり、事実上公開が不可能になります。
その点についてはどのように考えるべきでしょうか。
「個人情報データベース等」(法第16条1項)の定義は以下のとおりです。
個人情報を含む情報の集合物であって、次に掲げるもの(利用方法からみて個人の権利利益を害するおそれが少ないものとして政令で定めるものを除く。)をいう。
一 特定の個人情報を電子計算機を用いて検索することができるように体系的に構成したもの
二 略
つまり、仮にある特定のデータの集合体について、特定の個人情報をコンピューターを用いて検索できるようになっていたとしても、それだけでは「個人情報データベース等」には該当しません。「特定の個人情報を電子計算機を用いて検索することができるように体系的に構成したもの」とは、個人情報としてのそれぞれの属性に着目して検索できるように構成されている必要があり、文字列検索でたまたま検索できるというだけでは、「個人情報データベース等」に該当しません3(園部逸夫・藤原静雄編集「個人情報保護法の解説(第3次改訂版)・ぎょうせい・85頁参照。また、QA1-40、同41,、42等も参照) そして、データセットについては、個人情報は通常含まれているでしょうが、個人情報としてのそれぞれの属性に着目して検索できるように構成されている訳ではありませんので、「個人情報データベース」等には該当せず、当該データセットを公開・提供するに際して本人の同意は必要ないと思われます。
(2) モデルの公開
モデルの中には個人情報は通常含まれていませんので、モデルの公開について個人情報保護法上の規制がかかることはありません。
第4 まとめ
以上、「大規模データセットや大規模言語モデルを自ら開発して公開・提供するレイヤー」について、各ステップ(「データの収集→データの利用による成果物(データセットやモデル)の生成→成果物の提供・公開」)ごとに著作権法上の問題点と個人情報保護法制上の問題点を解説しました。
読んでいただければ判るように、大規模データセットや大規模言語モデルを自ら開発して公開・提供するに際して、著作権法上も個人情報保護法制上も、日本には大きなアドバンテージがあると言えるでしょう。
- 1なお、収集の対象となるデータは多くはWEB上のデータですので、今回の記事もそれを前提とします
- 2改正前著作権法47条の7但書に該当する行為です
- 3(園部逸夫・藤原静雄編集「個人情報保護法の解説(第3次改訂版)・ぎょうせい・85頁参照。また、QA1-40、同41,、42等も参照)
・STORIA法律事務所へのお問い合わせはこちらのお問い合わせフォームからお願いします。












