人工知能(AI)、ビッグデータ法務 未分類
Midjourney、Stable Diffusion、mimicなどの画像自動生成AIと著作権

Contents
はじめに
Midjourney、Stable Diffusion、mimicなど、コンテンツ(画像)自動生成AIに関する話題で持ちきりですね。それぞれのサービスの内容については今更言うまでもないのですがMidjourney、Stable Diffusionは「文章(呪文)を入力するとAIが自動で画像を生成してくれる画像自動生成AI」、mimicは「特定の描き手のイラストを学習させることで、描き手の個性が反映されたイラストを自動生成できるAIを作成できるサービス」です(サービスリリース後すぐ盛大に炎上してサービス停止しちゃいましたが)。
で、この手の画像自動生成AIのようなコンテンツ自動生成AIですが、著作権法的に問題になる論点は大体決まっていまして、画像自動生成AIを例にとると以下の3つです1正確に言うと論点1はコンテンツ自動生成系AIだけではなく、AI一般に関して問題となる論点です。コンテンツ自動生成AI特有の論点は論点2と論点3ですね。。
▼ AIソフトウェア2ここでは統計的機械学習の技術を利用して開発したソフトウェアのことを指しています。本記事では単に「AI」と言うこともあります。を生成するために他人の画像や文章などの著作物を勝手に収集して利用することができるか(論点1)
▼ 自動生成された画像に著作権が発生するか(論点2)
▼ 学習に用いられた画像と同一の画像が『偶然』自動生成された場合、著作権侵害に該当するか(論点3)
Twitterで「自動生成された画像に著作権が発生するか」についてツイートしたところ、沢山の方々に反響を頂いたので、本記事では、この3つの論点について詳細に解説をしたいと思います。
第1 論点の全体像
仕事柄、AIソフトウェアの開発(学習・訓練)や、AIソフトウェアの利用に関する相談を受けたり人前でお話をしたりすることが多いのですが、その際に、この図を用いて説明をします。
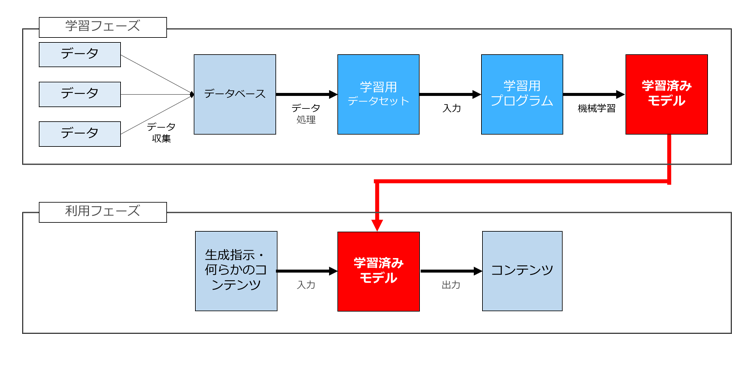
先ほど紹介した3つの論点のうち「AIソフトウェアを生成するために他人の画像や文章などの著作物を勝手に収集して利用することができるか」(論点1)は学習(訓練)フェーズに関する論点でして、主としてAIソフトウェアを開発・提供するサービサーに関連するポイントです。
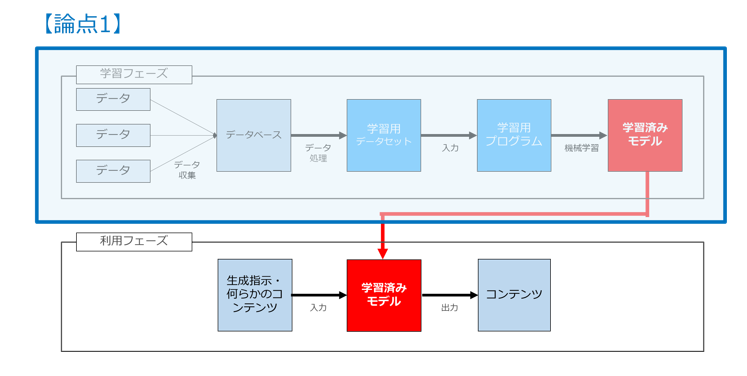
次に2つ目の「自動生成された画像に著作権が発生するか」(論点2)は利用フェーズに関する論点でして、専らAIソフトウェアを利用して画像を自動生成するユーザに関係するポイントです。
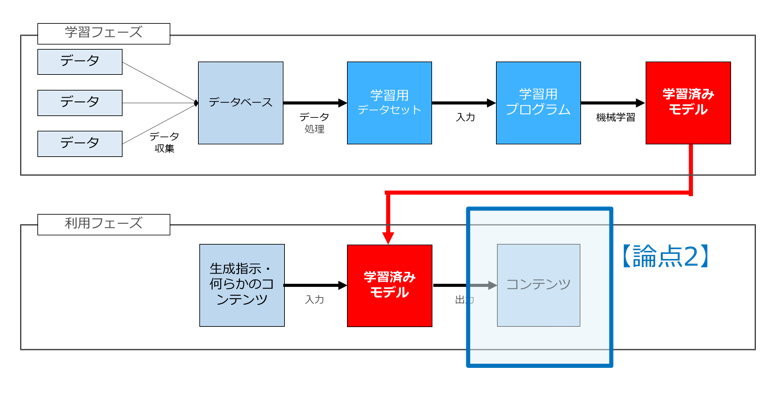
最後の「学習に用いられた画像と同一の画像が『偶然』自動生成された場合、著作権侵害に該当するか」(論点3)も利用フェーズに関する論点ですが、これはサービサーとユーザ双方に関わる論点です。
というのは、サービサーは画像自動生成AIというツールを提供し、ユーザは同ツールを利用して画像を自動生成します。そのため、ユーザが画像自動生成AIを利用して自動生成した画像の利用が著作権侵害に該当するか(論点3②)と、仮にユーザが著作権侵害をしてしまった場合、ユーザのみならず、当該画像自動生成AIを提供したサービサーも責任を負うか(論点3①)の双方が問題となるのです。
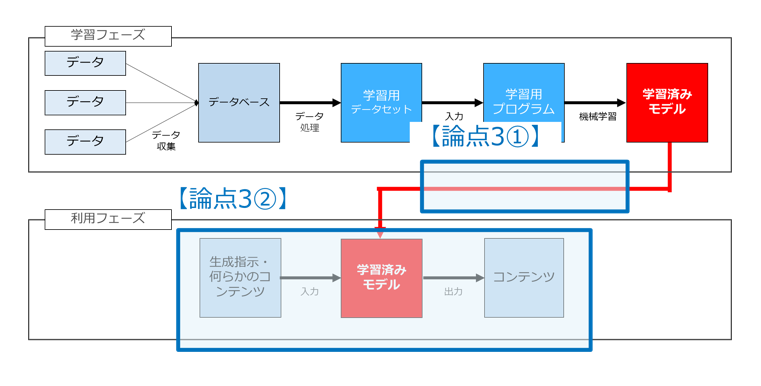
論点3だけちょっとイメージしずらいので別の図で示したのが以下の図です。
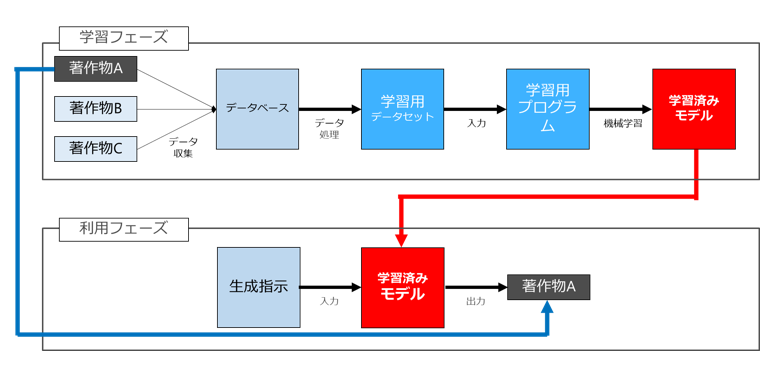
学習に用いた既存画像Aと「偶然」同一の画像Aが自動生成された場合に著作権侵害になるのかという問題ですね。
第2 AIソフトウェア を生成するために他人の画像や文章などの著作物を勝手に収集して利用することができるか(論点1)
他人の著作物を勝手に収集して機械学習技術を用いてAIソフトウェアを生成する場合、その『材料』となる著作物の収集方法にはいくつかのパターンがありますが、ここではネット上のデータを収集する場合に絞って説明します。
実はこの場合、論点は2つあります。
「著作権法上問題ないか(著作権侵害にならないか)」という問題と「契約(利用規約)違反とならないか」です。
後者の論点はmimicに関して「私が描いたイラストをAI学習に使うのは禁止にします」と表明することで、実際にイラストが学習に利用されることを禁止できるのか、というような形で問題となります。
両者は別の問題なので、以下分けて説明をします。
1 AIソフトウェア を生成するために他人の画像や文章などの著作物を勝手に収集して利用することは著作権法上問題ないか
(1) 日本著作権法30条の4第2号
たとえば、ウェブ上に存在している大量の写真やイラストを収集し 、学習用データセットを生成したうえで画像自動生成AIを作る場合を考えてみます。
この場合、それらの写真やイラストの著作権は、通常当該写真・イラストの生成者が保有していますが、AIソフトウェアを生成するために、そのような写真をダウンロードし(複製)、学習に適した形に加工し(翻案)、学習に用いるためには、原則としてそれらの写真の著作権者の許諾が必要です。
しかし、日本著作権法においては、AIソフトウェアの生成に必要な著作物の利用行為(データの複製や翻案)については、原則として著作権者の承諾を行わなくても可能であるという権利制限規定が存在します。
それが、平成30年改正著作権法によって導入された著作権法30条の4第2号です。
(著作物に表現された思想又は感情の享受を目的としない利用)
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 略
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 略
条文は上記のとおりですが、要するに「『情報解析』に必要な限度においては原則として著作物を自由に利用できる」という内容の権利制限規定です。
そして、AIソフトウェアの開発は、当該「情報解析」に該当するため、結果として「AIソフトウェアの生成に必要な限度においては原則として著作物を自由に利用できる」ということになります。
具体的には、30条の4の柱書には「その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる」と規定されているため、「自らがAIソフトウェアの開発を行うために、著作物を収集・複製・改変等する行為」「AIソフトウェアの開発を行う他社のために、著作物を収集・改変して学習用データセットを生成し提供する行為」などが可能です。
(2) 日本著作権法30条の4の特殊性
以上説明したように、「情報解析」のためであれば、かなり広い範囲で著作物の利用を認める日本国著作権法30条の4ですが、この条文は世界的に見るとかなり特殊であると言われています。
他国にも「情報解析」のためであれば自由に著作物を利用できるとの規定はあるのですが、たとえば、英国の場合、「非商業的調査のためのテキストおよびデータの解析のための複製」のみが権利制限の対象となっています(著作権・意匠・特許法29A条、2014年改正)3その他米国・ドイツ、中国の状況については「(海外におけるデザイン・ブランド保護等新たな知財制度上の課題に関する実態調査)https://www.meti.go.jp/policy/economy/chizai/chiteki/pdf/reiwa3_itaku_designbrand.pdfの別紙2(「新たな知財制度上の課題に関する研究会報告書」)のP55~を参照。 。
一方、日本の著作権法については、そのような目的の限定がないため、営利企業が営利目的で情報解析を行う場合にも著作権法30条の4の適用があります。
この点が日本著作権法30条の4の特殊性です。
それに関連してよく相談を受ける問題について書いておきます。
(3) どのような行為に日本著作権法が適用されるのか
日本著作権法が素晴らしい、という話をすると当然のことながら「どうやったら日本著作権法が適用されるんですか」という話になるわけですが、この「ある行為についてどこの国の法律が適用されるか」の問題を「準拠法」の問題といいます。著作権法に関しては一般的に「当該著作物が利用される地」(利用行為地国)の法律を適用すべきとされています 。
したがって、AIソフトウェア開発目的で著作物の利用行為を行う場合でも、当該利用に関する利用行為地が日本であれば日本著作権法が適用され、米国であれば米国著作権法が適用されることになります。
では、日本国内にいる作業者が米国内に所在するサーバにおいてAIソフトウェアの開発に必要な著作物の利用行為(データのダウンロードや機械学習行為など)を行った場合など、国境をまたいだ利用行為が行われる場合に「利用行為地」とはどこを指すのでしょうか。
「利用主体(作業者)がいる場所」と「利用行為が行われるサーバの所在地」のいずれもが日本国内である場合には日本国が「利用行為地」であり、日本著作権法が適用されます。
一方、「利用主体(作業者)がいる場所」と「複製等の利用行為が行われるサーバの所在地」のいずれかが外国である場合(たとえば、日本にいる作業者が外国のリージョンを選択して作業をする場合)に、日本国著作権法30条の4が適用されるかについての結論ははっきりしておらず日本著作権法が適用されないリスクがあります。
(4) 利用対象の著作物の著作権者や、著作物の利用者が外国企業(あるいは外国の個人)の場合でも、当該著作物の利用行為は著作権法30条の4が適用され適法になるのか
準拠法の問題は、あくまで「利用行為地」が日本国内か否かの問題であって、当該著作物の著作権者が日本の企業なのか外国の企業なのか、あるいは著作物の利用者が日本の企業なのか外国の企業なのかは無関係です。
外国の企業(あるいは個人)が著作権を有する著作物 についても、あるいは著作物の利用者が外国の企業であっても、当該著作物の利用行為地が日本国内であれば日本国著作権法30条の4は適用され、適法となります4上野達弘「情報解析と著作権~「機械学習パラダイス」としての日本」(人工知能36巻6号748頁) 。
(5)日本国内で適法に生成したAIソフトウェアを、外国に所在するサーバ上にデプロイしてSaaS形式で全世界に向けて提供する、あるいは当該ソフトウェアを外国所在の企業にライセンスする行為は適法なのか
適法です。
この点、仮に「当該AIソフトウェアが、学習に利用したデータ(著作物)の二次的著作物である」とすると、当該ソフトウェアについては原則として当該データ(著作物)の著作権者の承諾なく利用することはできません(著作権法28条)。
しかし、あるデータを元に生成されたAIソフトウェアの内部においては、通常、当該データは学習の過程においてパラメータ化されており、データそのものがそのまま知覚できる形式では残存していません。したがって、当該AIソフトウェアはそもそも当該ソフトウェアの二次的著作物ではありません。
平たく言うと「あるデータを元に生成されたAIソフトウェア」は、当該データとは全く別の著作物(プログラム著作物)であり、当該ソフトウェアの公開・提供に際して当該データが利用されているわけではないから、当該データに関する権利処理は不要、ということになります。
したがって、日本国内で適法に生成したAIソフトウェアを、外国に所在するサーバ上にデプロイしてSaaS形式で全世界に向けて提供する、あるいは当該ソフトウェアを外国所在の企業にライセンスする行為は適法です。
(6) 日本著作権法30条の4の限界
もっとも、日本著作権法30条の4も「情報解析」のためであれば無限定に他人の著作物の利用を認めているわけではなく、「当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合」には著作物を利用することはできません(日本著作権法30条の4但書)。
問題は、どのような場合が「当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合」に該当するかです。
具体的に議論されているのは、「特定の作者の画像のみを学習させることで、当該作者の作風を表現できるAIソフトウェアを生成する行為」がこの「当該著作物の・・・著作権者の利益を不当に害する」場合に該当するかです。
この点、愛知靖之「AI生成物・機械学習と著作権法」(パテント73巻8号142頁)は、30条の4但書の「著作権者の利益を不当に害することとなる」の意味について、同じ文言が用いられている35 条1 項と同様「将来における著作物の潜在的販路を阻害するかどうかで判断する」とした上で、「ディズニー映画風の新しい映画を作るAI を開発するために、ディズニー映画(但書にいう『当該著作物』)全てをコンピュータに入力して機械学習させる行為は、将来において、ディズニー映画という『当該著作物』と潜在的に競合する映画を作成するという用途で、(既存のディズニー映画という)著作物をデータとして入力していることになる。それゆえ、将来における著作物の潜在的販路を阻害する可能性があり、『著作権者の利益を不当に害することとなる』ようにも思われる。」としています。
しかし、私は個人的にはこの見解には疑問を持っています。
もちろん、そのような手法で学習を行った学習済みモデルを利用して既存ディズニー映画と同一・類似の表現を生成して利用(販売・頒布等)する行為が著作権侵害に該当することは疑いがありません(この点については論点3で述べます)。
しかし、問題は、未だそのような著作権侵害が行われてない段階で、あくまで著作権侵害を起こす可能性があるに過ぎないAIソフトウェアを生成する行為としてどのような行為が許容されるか、です。
「将来における著作物の潜在的販路を阻害する(か否か)」という基準で30条の4ただし書の該当性を判断した場合、「AIソフトウェアが既存著作物と同一・類似の著作物を生成する可能性がわずかでもある」というだけで、ただし書に該当してしまうことになります。
しかし、「AIソフトウェアが既存著作物と同一・類似の著作物を生成する可能性がない」ということは誰にも証明できないのですから、このような解釈を採用すると、結局AIソフトウェアを生成する行為が全て著作権侵害に該当してしまうことになります。これでは、既存著作物の本来的利用行為(視聴等)が存在しない「非享受利用」の場合に著作物の利用を認めた規定である30条の4の趣旨(2017年4月文化審議会著作権分科会報告書41頁参照)を大きく損なうのではないでしょうか。
また、ディズニー映画の例で言うと、ディズニー映画を情報解析に利用する者がいるからといって、「ディズニー映画を視聴用に利用する潜在的販路」に悪影響を及ぼすとは考えにくいのではないかと思います。
したがって、私見では特定の作者の画像のみを学習させることで、当該作者の作風を表現できるAIソフトウェアを生成する行為は30条の4但書の「著作権者の利益を不当に害する」場合に該当しないと考えます。
しかし、注意しなければならないのは、あくまでここで適法としているのは「AIソフトウェアの生成行為」(論点1)であって、当該ソフトウェアを提供した結果、当該ソフトウェアを利用したユーザが既存著作物と同一・類似の著作物を生成して著作権侵害を起こした場合に、当該ソフトウェア提供者がどのような責任を負うか(論点3①)は別問題であるということです。
すなわち論点1は、「ユーザによる著作権侵害行為が実際に発生したか否かを問わず、侵害行為の危険性が高いツールを生成・提供する行為自体を単体で違法とするか」の問題であり、論点3①は、「実際にユーザによる著作権侵害行為が発生した場合において、当該著作権侵害行為に利用されたツールの提供行為を違法とするか」の問題です。
2 「私が描いたイラストをAI学習に使うのは禁止にします」と表明することで、実際にイラストが学習に利用されることを禁止できるのか
この点については、以下の2点が問題となります。
① そもそも著作権法上「著作権者の承諾なく行える」とされている行為を契約で制限することはできるのか
② ①が可能だとしてどのような場合に「契約が成立した」といえるのか
(1)そもそも著作権法上「著作権者の承諾なく行える」とされている行為を契約で制限することはできるのか
先ほど解説したように、日本国著作権法には「AIソフトウェアの開発のためであれば著作物は原則として著作権者の承諾なく利用することが出来る」という規定(30条の4第2号)が存在し、当該30条の4の下では、営利・非営利問わず著作物の利用行為が可能です。
しかし、「私が描いたイラストをAI学習に使うのは禁止にします」という表明がされた場合、30条の4と矛盾する内容となっているため、そもそもそのような合意をすることができるのか、という問題が生じるのです。
この点については著作権法の構造を理解するとわかりやすいです。
著作権法上、「著作物については著作権者の承諾なく利用行為を行うことが出来ない」のが原則なのですが、例外的に「著作物についても権利制限規定に該当すれば著作権者の承諾がなくとも利用行為を行うことが出来る」という建て付けになっています。
イメージで言うとこんな感じです。
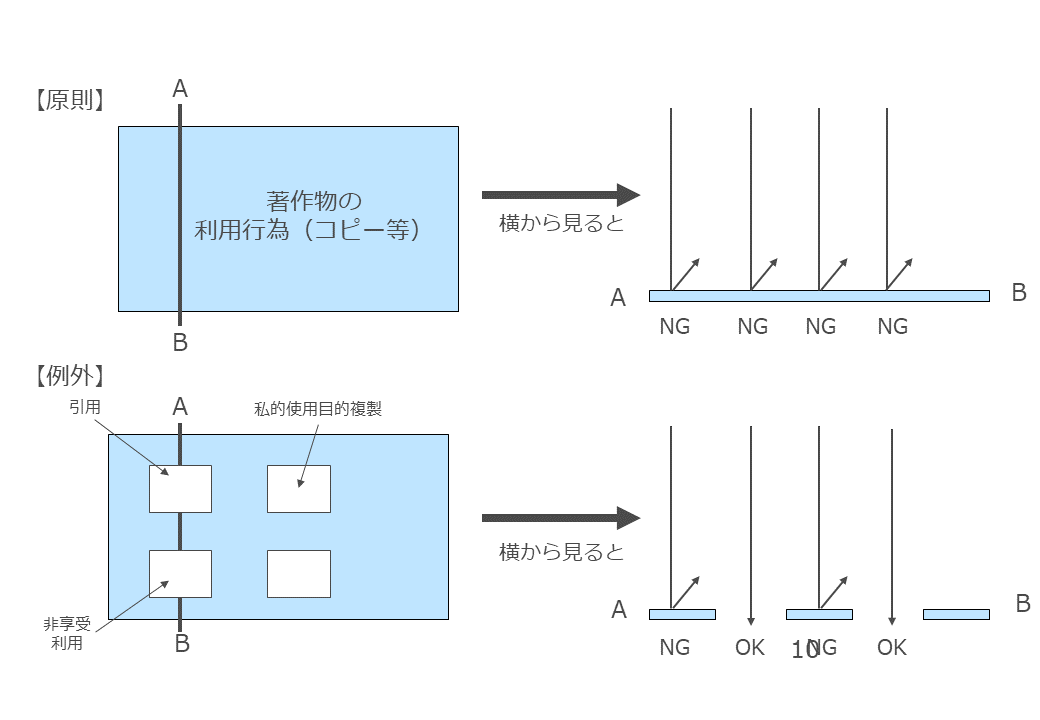
そして、先程来説明している著作権法30条の4は、この権利制限規定の一種ですので、要するに穴が空いている部分と言うことになります。
一方、「私が描いたイラストをAI学習に使うのは禁止にします」というような表明がされた場合、比喩的に言えば「権利制限規定によって空けられた穴を、『契約』という蓋を被せることで塞ぐことが出来るのか」という問題が発生します(この問題を「著作権法のオーバーライドの問題」といいます)。
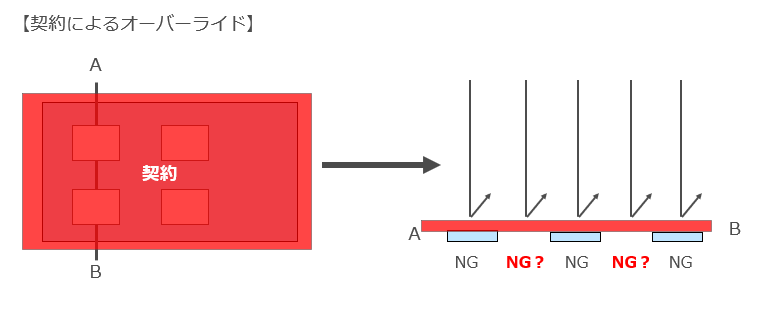
従前の議論においては、オーバーライド条項の有効性について検討するに当たり、権利制限規定を強行規定と考えこれに反する契約を一律に無効とする考えは取られていません。
権利制限規定の趣旨等諸要素を総合的に勘案して、個別的に当該契約の有効性を判断する必要があると整理されていることが多いのではないかと思われます(「文化審議会著作権分科会法制問題小委員会契約・利用ワーキングチーム検討結果報告」(平成17年7月) 、「文化審議会著作権分科会報告書 」(平成19年1月)18頁 、「権利制限一般規定ワーキングチーム 報告書 」(平成22年1月)47頁 )。
それを前提とした上で、著作権法30条の4の立法目的を重視し、同条を強行規定と整理した上で、同条に反する契約を一律に無効とする見解もあります5 松田政行「柔軟な権利制限規定によるパラダイムの転換・実務検討・書籍検索サービスの著作物の利用ガイドライン」(コピライトNo.718/Vol60)22頁。
一方、先ほどの報告書別紙2(「新たな知財制度上の課題に関する研究会報告書」)のP55~においては、著作権法30条の4を強行規定と解釈するのではなく、著作権法30条の4により権利制限が認められる利用行為のうち、特にAI学習のための利用行為に着目し、「個別の事情における諸般の事情を考慮する必要があるものの、AI学習等のための著作物の利用行為を制限するオーバーライド条項は、その範囲において、公序良俗に反し、無効とされる可能性が相当程度あると考えられる。」と結論づけています。
結構踏み込んだ記載です。
この解釈を前提とすれば、少なくともAI開発のための著作物の利用行為を制約する契約条項は無効であると考えられることになります。
こんな感じです。
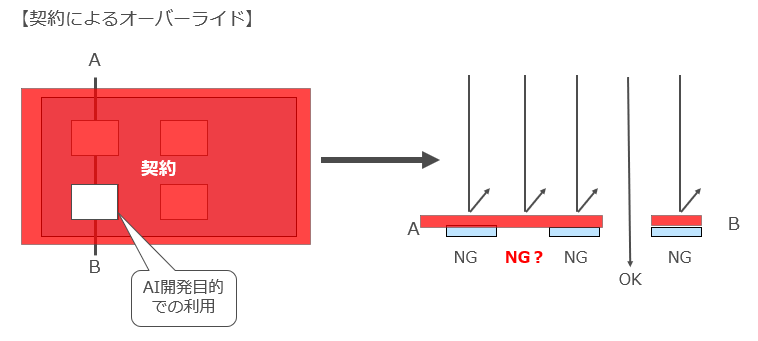
(2)(1)が可能だとしてどのような場合に「契約が成立した」といえるのか
この点は、「私が描いたイラストをAI学習に使うのは禁止にします」と表明するだけでそもそも「契約」が成立したか、という問題です。
結論からいうと、そのような一方的な表明がなされただけでは「契約」が成立したことにはならないと思われます。「契約」が成立するためには契約当事者双方の意思が合致することが必要とされているためです。
したがって「この画像をAI学習のために利用することを禁止する」という内容の契約が成立するためには単なる「表明」だけでは足りず、そのような内容を含んだ利用規約に明確に同意する必要があります(たとえば、利用規約に同意した後に初めて画像にアクセスできるなど)。
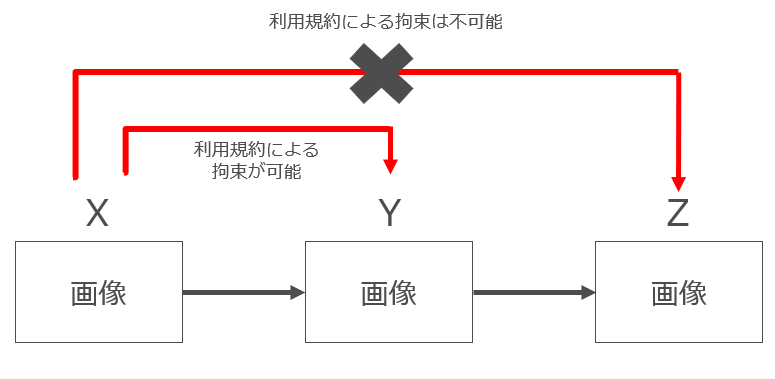
もっとも、実は、仮に利用規約を踏ませるなどして有効に「契約」が成立したとしても、その効果は限定的です。なぜなら「契約」はあくまで「契約」を締結した当事者間でしか効力を持たないからです。
たとえば画像作成者Xが「この画像をAI学習のために利用することを禁止する」という利用規約の下で画像を公開したとします。
この場合、Yが当該利用規約に同意して当該画像を取得した場合にはYは当該利用規約に拘束されます。
したがって、Yが利用規約に違反して画像をAI学習のために利用した場合に、Yは債務不履行による損害賠償責任をXに対して負うことになります。
一方、Yが利用規約に違反して当該画像をZ(Xとの間で利用規約は締結していないものとします)に提供し、Zが当該画像をAI学習のために利用することは利用規約上禁止されません。
Zは利用規約に同意しておらず利用規約に拘束されないからです。
(3) まとめ
このように「私が描いたイラストをAI学習に使うのは禁止にします」と表明したとしても、そもそもそのような表明は著作権法30条の4に違反して無効の可能性がありますし、仮に著作権法30条の4に違反しないとしても、一方的な表明が契約として成立することはないため、結論的にはそのような表明は少なくとも法律的には意味がないということになると思います。
第3 画像生成AIにより自動生成された画像に著作権が発生するか(論点2)
この点については、以下の論点が問題となります。
1 画像自動生成AIを利用して画像を生成した場合、当該画像に著作権が発生するか。
2 著作権が発生するとした場合、誰に著作権が発生するか。
1 画像自動生成AIを利用して画像を生成した場合、当該画像に著作権が発生するか。
この論点は以下のような場合に問題となります。
・ ある人(以下「作成者」)がAIで画像を自動生成し、当該画像をWEBにアップしたところ、第三者が当該画像を勝手に利用したとします。その場合。作成者が当該利用者に対して「それは私が制作した画像の著作権を侵害する行為だから止めて欲しい。止めてくれないのなら損害賠償請求しますけど。」と言えるか
・ 作成者が作成した自動生成画像を第三者にライセンスしたが、全く無関係な人が当該自動生成画像を勝手に利用した場合に、著作権侵害を理由にその利用を止められるか。もし止められないのであればライセンス料を支払っている人は何のためにお金を払っているのか、という話になります。
自動生成画像に著作権が発生していれば、作成者はこれらの事例において「契約関係にない全くの第三者」に対しても権利行使(差止請求や損害賠償請求)ができますが、もし著作権が発生してなければ、このような請求はできません。
原則として使われ放題です。
(1) どのような場合に著作権が発生するか
日本を含むほとんどの国の著作権法の下では、著作権が発生するのは人間の創作物に限られ、人間が創作に関与せずAIの利用により完全自律的に作成されたコンテンツには著作権が発生しない扱いとなっています6 ちなみに、イギリス法(CDPA)は、コンピューター生成物(computer-generated work)に著作権保護を与えている。すなわち、人間の著作者が存在しない状況でコンピューターにより生成されたコンピューター生成物について生成後50年間の著作権保護を与えており、コンピューター生成物の創作に「必要な手筈(the arrangements necessary)」を引き受ける者を著作者としている。。
で、すぐに判ると思うのですが「人間が創作した」と「人間が創作に関与せずAIの利用により完全自律的に作成された」の線引きをどこに置くかが大きな問題です。
要するに、人間がAIを道具として利用したにすぎないのか、AIが完全自律的に生成したと言えるのかどうかですが、日本での議論では、この点は人間に「創作意図」と「創作的寄与」があったかによって判断されるとされています7新たな情報財検討委員会報告書(2017年3月・知的財産戦略本部検証・評価・企画委員会・新たな情報財検討委員会)35頁 。
「創作意図」は通常はあるので、「創作的寄与」、乱暴に言い切ると「人間がAIの利用に際して具体的かつ詳細な指示をしたか」によって著作物性は判断されることになると思われます。
これ、逆に言うと、人間が簡単な指示しかしていなければ、生成された画像がいかに独創的で素晴らしいものだったとしても、著作権は発生しない、ということです。
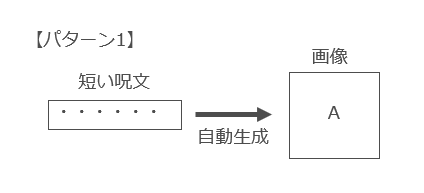
MidjourneyやStable Diffusionなどの「文章→画像」AIの場合は、文章(呪文)を入力して画像を生成するので、入力文章がポイントとなります。
まず短い呪文を入力したら一発で素晴らしい画像が出てきた、というパターンでは「創作的寄与」がなく、著作権が発生しない可能性が高いです(パターン1)。
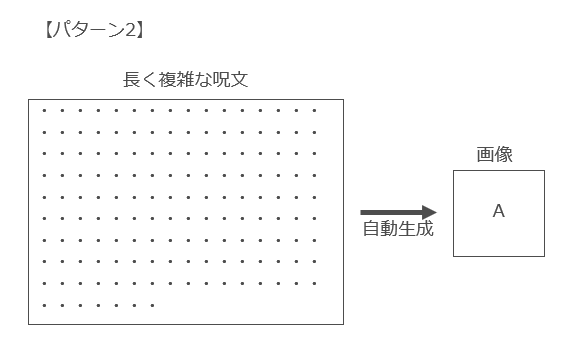
一方、いろいろな方がおっしゃっていますし、私も少し試してみましたが、「Midjourneyで良い画像を生成できる入力文章のコツ」というものが確かにあり、良い入力文章はまさに「秘密の呪文」ですね。
したがって、詳細かつ長い呪文を唱えて画像を生成した場合には「創作的寄与」があり、当該画像について著作権が発生する可能性が高くなると思われます(パターン2)。
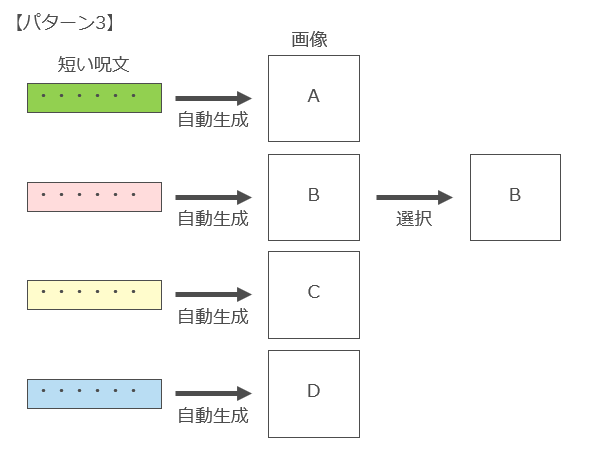
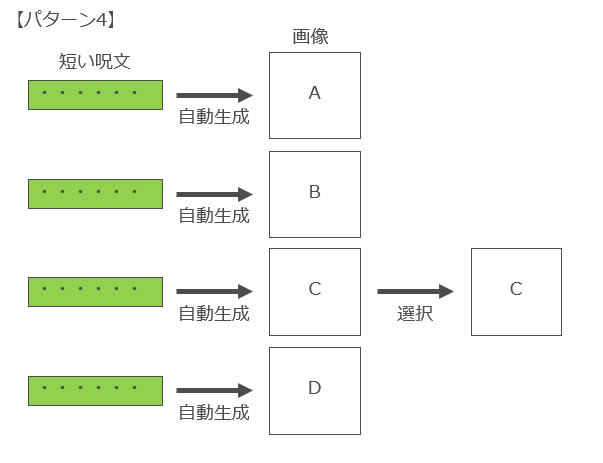
また、通常はパターン1のように「最初の呪文一発で望みの画像を生成できた」ということはほとんどなく、呪文自体の長さや構成要素を複数回試行錯誤したり(パターン3)、同じ呪文を何度も唱えて複数の画像を生成し、その中から好みの画像をピックアップするという行為(パターン4)も行われています。
このように「AIにより自動生成される複数の生成物から、人間が好みのものを選択する行為」についても「創作的寄与」に該当する可能性は十分にあるのではないかと考えています8奥邨弘司「人工知能生成コンテンツは著作権で保護されるか」(電子情報通信学会誌102巻3号)256頁は、AI搭載ワープロにおいて作家が記した1行の文章に対していくつかのバリエーションの文章が示された場合において、それらの文章を漫然と選択するのではなく、人間が自身の考えや思いを踏まえて個性を発揮するような形で取捨選択するのであれば、人間に創作的寄与が認められるとする。 。
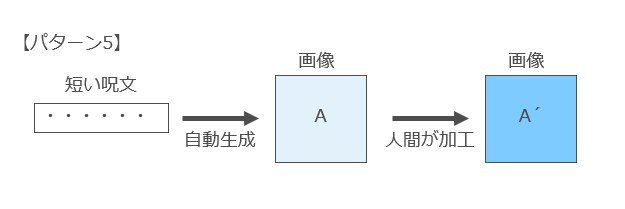
また、当然のことですが、AIが自動生成した画像に人間がさらに加工をし、当該加工に創作的な表現が含まれていれば、できあがった完成物には著作権が発生します(パターン5)。
このように考えてみると、少なくともプロのイラストレーターが画像生成AIを利用して試行錯誤して画像を生成・加工する場合、通常は「創作的寄与」が認められ、当該画像には著作権が発生することが多いのではないかと思われます。
「AI生成物には著作権が発生しない」という結論は、インパクトがあるためセンセーショナルに語られることも多いですが、実は著作権が発生しないAI生成物の方が少数なのかもしれません。
とはいえ、パターン1のような場合や、パターン2,3で「人間によって選ばれなかった画像」については著作権は発生しないため、やはりAI生成物に著作権があるかという問題は残ると思われます。
ちなみに商標については創作性は要求されていませんので、人間の創作的寄与がない商標でも商標出願はできますし、登録を受けることもできると思われます。AIを利用して生成された商標について大量の出願がなされるとすると。。。新たな火種の予感です。
(2) 呪文を法的に保護する方法
良い画像を生成できる呪文は非常に価値が高いため、当然「呪文を法的に保護する方法」も問題となります。
① 呪文自体が著作物として保護される場合
まず、呪文自体が著作物として保護される場合があります。
著作物とは「思想又は感情を創作的に表現したものであつて、文芸、学術、美術又は音楽の範囲に属するもの」ですが(著作権法2条1項1号)、典型的には呪文が「人間が読んで意味をとることができる、一定の長さをもった文章」の場合です。
この場合は、特に呪文が著作物であることについて特に問題はないと思います。
難しいのは、呪文が、文章とは言えない、多数の単語の羅列の場合です。
これは難しい。
私の知る限り論じられたことのない論点であり、私の中でも結論は出ていませんが、まず、全く無関係の単語を羅列した呪文は「思想又は感情を創作的に表現」したとは言えず、著作物には該当しないと考えます。
一方、ある特定のテイストを持った対象物を思ったように生成するためには、呪文生成にかなり特殊なコツが必要のようです。
AIに命令するコツだけど… たとえば「ガンダム」というルーンを呪文詠唱に組み込んだ時、直接的にガンダムが出るわけではない。「AIはガンダムという解説のついた画像群」を学習してるので、「ガンダム」のルーンには、「ザク」「歴代のガンダム」「ゲームのキャプチャ」とかの成分も含まれている pic.twitter.com/AxtNPCe8Bo
— 深津 貴之 / THE GUILD / note.com (@fladdict) August 6, 2022
このような「コツ」の下に作成された、一定の長さの呪文は、仮に文章の形式でないとしても、人間の「思想又は感情を創作的に表現」したものに該当する可能性があると思われます。
② ただし呪文が著作物に該当しても意味は薄いのではないか。
もっとも、呪文自体が著作物に該当するとしても、その意味はかなり限定的ではないかと思います。
これは「ある呪文」と「その呪文から生成された画像」の関係に由来します。
もし「特定の呪文から生成された画像」が当該「特定の呪文」の二次的著作物であるとすると、大変なことになります。
つまり、ある特定の呪文(著作物に該当するとします)を創作した人がいた場合、その呪文から自動生成されるあらゆる画像について、当該呪文創作者に原作者の権利(著作権法28条)が発生してしまうことになり、それら画像全てについて当該呪文創作者がコントロール可能になってしまいます。
しかし、実際にはそのようなことはないのではないかと思います。
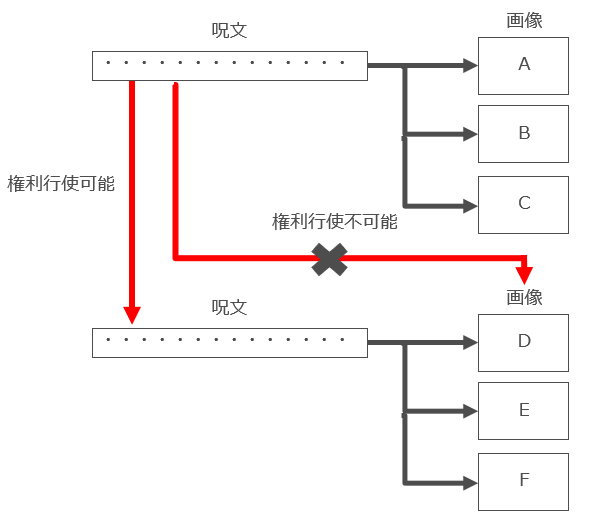
すなわち、「二次的著作物」とは「著作物を翻訳し、編曲し、若しくは変形し、又は脚色し、映画化し、その他翻案することにより創作した著作物」(著作権法2条1項11号)と定義されていますが、判例上はざっくり言うと「原著作物の表現上の本質的な特徴を直接感得できる」場合が二次的著作物に該当するとされています。
画像自動生成AIの場合で言うと「原著作物」は「呪文」ですが、「特定の呪文によって自動生成された画像」には、通常は当該呪文の表現上の本質的な特徴が残っているとはいえず(アイデアレベルであれば特徴が残っていることはあり得ますが)、当該呪文の二次的著作物には該当しないことが多いのではないかと思われます。
これを前提とすると、仮にある呪文が著作物に該当するとしても、当該呪文の著作権者が禁止できる行為は「当該呪文をコピーしたりWEBで無断でアップロードする行為」に限られ、「当該呪文から生成された画像」の利用を禁止したり制限することはできません。
で、まあ他人が作成した呪文を勝手に利用して画像を生成した人が、そのことを正直に告白するとは思えませんし、画像から当該画像を生成した呪文をリバースエンジニアリングすることも(おそらく)技術的には難しいでしょうから、「当該呪文をコピーしたりWEBで無断でアップロードする行為」が禁止できたとしてもほとんど意味がないのではないかと思います。
③ じゃあどうしたらよいのか
このように、呪文が著作物に該当しても意味が薄いとすると、良い呪文を法的に保護する方法は不正競争防止法上の「営業秘密」しかないことになります。
具体的には、良い呪文が見つかったら「秘匿」したうえで秘密管理をし、第三者に販売・提供するのであれば、秘密保持契約(NDA)を締結した上で提供することになります。
このように呪文を「営業秘密」として管理しておけば、呪文を購入した者が当該呪文を勝手に転売したり、事情を知って当該呪文を買い受けた人がいた場合には、それらの者に対して不正競争行為であるとして差止請求や損害賠償請求を行うことが可能になります。
一方、たとえばオープンなマーケットプレイスにおいて呪文を売りに出し、だれでも当該呪文を見ることができる場合には非公知性が失われ、「営業秘密」として保護することはできなくなってしまうのではないかと思われます。
2 自動生成された画像に著作権が発生する場合、誰が著作権を有するのか
では、自動生成された画像に著作権が発生する場合、誰が著作権を有するのでしょうか。著作権法上「著作者」とは「著作物を創作する者をいう」とされています(著作権法2条1項2号)。
ちなみに、あるコンテンツに著作権が発生するか、及びだれが著作者かは著作権法上決まることであって、私人が勝手に著作権発生の有無や著作者性(原始的な著作権の発生源)を決定することはできません。
したがって、画像生成AIソフトウェアの利用規約で「このソフトウェアで作成された画像には著作権が発生します」とか「このソフトウェアで作成された画像の著作者はサービス提供者です」と記載されていても無意味です(「ユーザの下で発生した著作権がサービス提供者に無償で移転する」という建て付けは可能です)。
まず画像生成AIソフトウェアの制作者については、画像生成AIソフトウェア自体(これはプログラムの著作物です)の著作者に該当することは間違いありませんが、当該AIソフトウェアを利用して自動生成された画像についての創作行為は行っていませんので、自動生成画像についての著作権を取得することはありません。
また、同じ理由で、自動生成AIソフトウェア制作のための画像を生成・提供した者、データセットを生成・提供した者についても自動生成画像についての著作権を取得することはありません。
一方、先ほど説明したように、「詳細かつ長い呪文を作成した上で唱えて画像を生成した者」「呪文自体の長さや構成要素を複数回試行錯誤して好みの画像をピックアップした者」「同じ呪文を何度も唱えて複数の画像を生成して好みの画像をピックアップした者」「AIが自動生成した画像に創作的な加工をした者」についてはそれぞれ著作権が発生すると思われます。
「詳細かつ長い呪文を作成した人」と、「当該呪文を使って画像生成をした人」が別人の場合はややこしいことになります。
「詳細かつ長い呪文Xを作成した人」をA、「呪文Xを使って画像生成をした人」をB、Bが呪文Xを使って一発で自動生成した画像をYとします。
この場合、画像Yは呪文Xの二次的著作物ではありませんから、画像YについてAが著作権を持つことはないように思います。一方でBは他人であるAが作成した呪文Xを使って一発で画像Yを自動生成していますので「創作的寄与」はないことになります。したがってBも著作者にはなりません。
とすると、画像Yについては誰も著作権を持つことはない、ということになります。ただ、「呪文Xを作成したこと」自体が「Yの創作に関しての創作的寄与」だとすると、画像YについてAが著作権を持つとしても良いように思います。ただそうすると、画像Yが呪文Xの二次的著作物ではないとしたことと矛盾するようにも思うんですよね。。。。もう少し考えてみます。
ちなみに、立法論としては、「AI自身」に人格を認めて、「AI自身」が著作者ということでよいのではないか、あるいは著作権法上の職務著作(著作権法15条)や映画の著作物に関する著作権(同29条1項)類似の考え方をとって、当該AIを生成した者を著作者としても良いのではないかという議論もあります。
第4 学習に用いられた画像と同一の画像が『偶然』自動生成された場合、著作権侵害に該当するか(論点3
1 そもそも著作権侵害に該当するのか
たとえば、既存画像Aが存在する場合において、当該既存著作物Aが学習用データとして用いられ、その後既存画像Aと同一・類似の画像Aが自動生成された場合を考えてみましょう。
著作権侵害(複製権・翻案権侵害)が成立するためには、① 当該著作物が既存著作物と同一・類似であること(類似性)及び② 依拠性が必要です。
(1) 作風の類似に過ぎない場合
まず、①の「類似性」との関係で問題となるのは、出力された画像Aが既存画像Aの「作風」「スタイル」レベルでしか類似していない場合です。
「類似性」が肯定されるためには「既存著作物の表現上の本質的な特徴を直接感得できること」が必要であるとされており、「作風」「スタイル」レベルでしか類似していない場合、には類似性を満たさず、著作権侵害には該当しません。
これは、著作権はあくまで具体的な「表現」を保護する権利であり、ある作家の「作風」「スタイル」といったものは抽象的な「アイデア」に属し、著作権保護をうけないからです(アイデア/表現二分論)9 上野達弘「人工知能と機械学習をめぐる著作権法上の課題~日本とヨーロッパにおける金治の動向」(法律時報91巻8号38頁)。
もっとも、「表現」レベルで類似しているのか、「作風」「スタイル」レベルで類似しているのかの区別は、必ずしもはっきりしたものではないため、AI生成物に限らず、争いになることが多い困難なポイントです。
(2) 依拠性の有無
依拠性とは「他人の著作物に接しそれを自己の作品の中に用いること」を指すとされています10中山信弘・著作権法(第3版)709頁 。要するに、ある創作物がたまたま他人の著作物に似ていても、当該他人の著作物に依拠することなく独自に創作されたものであれば、依拠性が否定されて非侵害となる、ということです。
したがって、このケースの場合、著作権侵害の要件の1つである「依拠性」が存在するかが問題となります11 実際には、本文に記載したケースと異なり、「学習用データとして用いられていない既存著作物Aと同一・類似の著作物Aが自動生成された場合」もありえる。この場合は、当該既存著作物Aに利用者・サービス提供者がアクセスしたことがあるか否かが問題になり、アクセスしたことがなければ依拠性は否定されるであろう。 。
この点については、既存著作物Aが学習用データセットに含まれている等の既存著作物へのアクセスがあれば依拠性を認めるべきであるとする考え方(肯定説)12 横山久芳「AIに関する著作権法・特許法上の問題」法律時報91巻8号53~54頁。同論考は「元の著作物が一群のパラメータの生成に寄与し、かつ、その一群のパラメータに基づいて生成物が制作されている場合には、表現形式が変換されているとはいえ、元の著作物を利用してAI生成物が制作されたといえるから、依拠を肯定すべきである」とする。愛知靖之「AI生成物・機械学習と著作権法」パテント73巻8号143頁。 と、パラメータ(機械学習により生成された係数)自体はアイデアであるから、既存著作物がパラメータ化されている場合には依拠性を認めるべきではないという考え方(否定説)13奥邨弘司「技術革新と著作権法性のメビウスの輪」コピライトNO.702/Vol.5910頁。 があり結論が出ていません。
2 著作権侵害に該当する場合に誰が責任を負うのか
次に、仮にAI自動生成物について既存著作物との「類似性」及び「依拠性」が肯定され、著作権侵害の要件を満たす場合、誰がその責任を負うかが問題となります。
(1) ユーザ
まず、ユーザが画像生成指示を行って、当該指示により既存画像と同一・類似の著作物が生成された場合には、当該ユーザ自身が既存著作物の「複製」行為を行っていることになります。
したがって、当該「複製」行為が私的領域内で行われる場合には著作権法30条により適法となりますが、仮にサービス利用者が当該自動生成物を販売したり配信したりした場合には著作権侵害に該当することになります。
このような場合には、既存画像Aの著作権者は当該販売・配信行為に対する差止請求権を行使することはできますが、ユーザが既存著作物の存在を知らなかった場合は、ユーザに故意・過失がないため損害賠償請求はできないと思われます。
(2) ツール提供者
ユーザが自動生成AIを利用して既存著作物と同一・類似の著作物を生成して利用し、当該利用行為が著作権侵害に該当する場合、当該違法著作物生成に関わるツール(学習用データセットや自動生成AIソフトウェア)を提供した者の責任についてどのように考えるべきでしょうか。
Winny事件14 最決平成23年12月19日・刑集第65巻9号1380頁=判示2141号135頁=判タ1366号103頁 や、ときめきメモリアル事件15最判平成13年2月13日民集55巻1号87号 を思い出しますが、この点は今後の日本の自動生成系AIの発展のために極めて重要な法的論点だと思われます。
結論から言うと、この点については「著作権侵害発生の実質的危険性を有する物品を、侵害発生を知り、又は知るべきでありながら、侵害発生防止のための合理的措置を採ることなく、当該侵害のために提供する行為」か否かで判断すべきと考えます。
この判断基準は、著作権侵害における間接侵害について整理した「『間接侵害』等に関する考え方の整理」(平成24年1月12日・文化審議会著作権分科会司法救済ワーキングチーム)が整理した第2類型とほぼ同一であり、「侵害発生の実質的危険性を有する物品」という客観的要件及び「侵害発生を知り、又は知るべきでありながら、侵害発生防止のための合理的措置を採ることなく」という主観的要件で構成されています16 ここでいう「ツール提供者の法的責任」は厳密には、侵害主体としての法的責任と、教唆・幇助者としての法的責任があり、両者は責任内容(差止請求を受けるか)や主観的要件が異なる。ただし本稿では紙幅の関係上、両者を区別していない。 。
このような客観的要件と主観的要件を組み合わせることで、比較的明確な基準となりますし、これから説明するように結論の妥当性も確保できると考えています。
この基準を採用した場合、ツール提供行為の違法性については以下のような結論となります。
① 学習用データセットの生成・提供行為
データセットは、それ自体では著作物を生成する能力はないこと、データセットが利用される用途は学習済みモデル生成以外もありうること、学習済みモデル生成のために用いられる場合であっても当該データセット単体ではなく、他のデータセットと合わせて学習に用いられる場合も容易に想定されることからすると、当該データセットの生成・提供行為が著作権侵害につながる危険性は相当に低いといえます。
したがって、データセットは「著作権侵害発生の実質的危険性を有する物品」に該当しないことから、データセットの生成・提供行為については上記基準を満たさず、仮にユーザの行為が著作権侵害に該当する場合でも、データセットの生成・提供行為を行った者が法的責任を問われることはないと考えます。
② 画像自動生成AIソフトウェアの生成・提供行為
一方、画像自動生成AIソフトウェアは学習用データセットと異なり、画像を自動生成する能力を有しているため、「著作権侵害発生の実質的危険性を有する物品」に該当する可能性があります。
もっとも、一般的に言って、AIソフトウェアは、学習に用いられるデータセットの内容や学習方法によって大きく異なる性能・機能を持つため、より細かい検討が必要でしょう。
この点、ときめきメモリアル事件において問題となったパラメータ編集ツールのような、「当該ツールを利用するとユーザが望むようにゲーム内容の改変行為が必ず行われ、かつ改変行為が行われれば、即時に著作権(同一性保持権)の侵害が生じる」 ツールについては「権利侵害発生の実質的危険性を有する物品」に該当すると考えても特に不合理性はありません。
一方、著作権侵害における画像自動生成AIソフトウェアには、このようなパラメータ編集ツールとは大きく異なる点があります。
すなわち、十分な量のデータセットを元データとして生成された画像自動生成ソフトウェアの場合、当該画像自動生成AIソフトウェアを利用したとしても、必ずしも既存著作物と同一・類似の著作物が生成されるとは限らず、むしろ既存著作物と同一・類似の著作物は極めて「偶然」にしか生成されません。
そのような著作物が生成されなければそもそも著作権侵害は問題にならないことから、この点は画像自動生成ソフトウェアと、ときメモ事件におけるパラメータ編集ツールとの大きな相違点です。
したがって、十分な量のデータセットを元データとして生成された画像自動生成ソフトウェアについては、「著作権侵害発生の実質的危険性を有する物品」に該当しないことから、そのようなAIソフトウェアの生成・提供行為については上記基準を満たさず、仮にユーザの行為が著作権侵害に該当する場合でも、そのようなソフトウェアの生成・提供を行った者には法的責任はないと考えます。
次に、「十分な量のデータセットを元データとして生成された学習済みモデル」ではなく「当該学習済みモデルを利用すると、既存著作物と同一・類似の著作物が非常に高い確率で生成される学習済みモデル」であればどうでしょうか。
具体的には、「ある特定のイラストレーターの既存作品を自動生成することを目的として、当該イラストレーターの既存作品のみを収集してデータセットを作成し、同データセットを用いて学習させた画像自動生成ソフトウェア」です。
このようなソフトウェアは既存作品と同一・類似の作品を自動生成する能力が非常に高く、著作権侵害をもたらす危険性が高いため、客観的要件である「著作権侵害発生の実質的危険性を有する物品」に該当すると思われます。
そして、そのようなソフトウェアを提供する者は、主観的要件である「侵害発生を知り、又は知るべきでありながら、侵害発生防止のための合理的措置を採ることがなかった」という要件を通常は満たすでしょうから、ユーザの行為が著作権侵害に該当する場合は、ソフトウェア提供者も法的責任を問われることになるでしょう。
③ 画像自動生成AIソフトウェア生成ツールの提供行為
最後に、Mimicのような画像自動生成AIソフトウェア生成ツールの提供行為についてはどうでしょうか。
これまでと同じく「著作権侵害発生の実質的危険性を有する物品」に該当するか否かを検討することになりますが、どのようなデータを学習させるかによって画像自動生成AIソフトウェア生成ツールの危険性は異なること、利用許諾を得ている適法なデータを学習させることも十分考えられることからすると、「著作権侵害発生の実質的危険性を有する物品」には該当しないと考えます。
したがって、仮に同ツールを利用して生成された画像自動生成AIソフトウェアを利用したユーザの行為が著作権侵害に該当する場合でも、同ツールの提供行為を行った者が法的責任を問われることはないと考えます。
3 著作権以外の権利の侵害
なお、先ほどは著作権侵害について検討しましたが、画像自動生成AIでは著作権以外の権利の侵害が生じることもあります。
具体的にはパブリシティ権侵害(有名人の肖像が自動生成された場合)や名誉権侵害(実在の人物の顔に裸体を合成した画像が出力された場合)などです。
この場合においても、ユーザの行為の違法性とツール提供者の行為の違法性が問題となりますが、ちょっと力尽きたので、また機会があれば。
【文中脚注】
- 1正確に言うと論点1はコンテンツ自動生成系AIだけではなく、AI一般に関して問題となる論点です。コンテンツ自動生成AI特有の論点は論点2と論点3ですね。
- 2ここでは統計的機械学習の技術を利用して開発したソフトウェアのことを指しています。本記事では単に「AI」と言うこともあります。
- 3その他米国・ドイツ、中国の状況については「(海外におけるデザイン・ブランド保護等新たな知財制度上の課題に関する実態調査)https://www.meti.go.jp/policy/economy/chizai/chiteki/pdf/reiwa3_itaku_designbrand.pdfの別紙2(「新たな知財制度上の課題に関する研究会報告書」)のP55~を参照。
- 4上野達弘「情報解析と著作権~「機械学習パラダイス」としての日本」(人工知能36巻6号748頁)
- 5松田政行「柔軟な権利制限規定によるパラダイムの転換・実務検討・書籍検索サービスの著作物の利用ガイドライン」(コピライトNo.718/Vol60)22頁
- 6ちなみに、イギリス法(CDPA)は、コンピューター生成物(computer-generated work)に著作権保護を与えている。すなわち、人間の著作者が存在しない状況でコンピューターにより生成されたコンピューター生成物について生成後50年間の著作権保護を与えており、コンピューター生成物の創作に「必要な手筈(the arrangements necessary)」を引き受ける者を著作者としている。
- 7
- 8奥邨弘司「人工知能生成コンテンツは著作権で保護されるか」(電子情報通信学会誌102巻3号)256頁は、AI搭載ワープロにおいて作家が記した1行の文章に対していくつかのバリエーションの文章が示された場合において、それらの文章を漫然と選択するのではなく、人間が自身の考えや思いを踏まえて個性を発揮するような形で取捨選択するのであれば、人間に創作的寄与が認められるとする。
- 9上野達弘「人工知能と機械学習をめぐる著作権法上の課題~日本とヨーロッパにおける金治の動向」(法律時報91巻8号38頁)
- 10中山信弘・著作権法(第3版)709頁
- 11実際には、本文に記載したケースと異なり、「学習用データとして用いられていない既存著作物Aと同一・類似の著作物Aが自動生成された場合」もありえる。この場合は、当該既存著作物Aに利用者・サービス提供者がアクセスしたことがあるか否かが問題になり、アクセスしたことがなければ依拠性は否定されるであろう。
- 12横山久芳「AIに関する著作権法・特許法上の問題」法律時報91巻8号53~54頁。同論考は「元の著作物が一群のパラメータの生成に寄与し、かつ、その一群のパラメータに基づいて生成物が制作されている場合には、表現形式が変換されているとはいえ、元の著作物を利用してAI生成物が制作されたといえるから、依拠を肯定すべきである」とする。愛知靖之「AI生成物・機械学習と著作権法」パテント73巻8号143頁。
- 13奥邨弘司「技術革新と著作権法性のメビウスの輪」コピライトNO.702/Vol.5910頁。
- 14最決平成23年12月19日・刑集第65巻9号1380頁=判示2141号135頁=判タ1366号103頁
- 15最判平成13年2月13日民集55巻1号87号
- 16ここでいう「ツール提供者の法的責任」は厳密には、侵害主体としての法的責任と、教唆・幇助者としての法的責任があり、両者は責任内容(差止請求を受けるか)や主観的要件が異なる。ただし本稿では紙幅の関係上、両者を区別していない。












