人工知能(AI)、ビッグデータ法務
ChatGPTにとって日本は”機械学習パラダイス”なのか ~LLM(大規模言語モデル)にとっての個人情報保護法とGDPR~

ChatGPTを提供する米OpenAI社のCEOが来日したことが話題になっています。
「ChatGPT」CEO来日、個人データ保護「政府に協力」(日本経済新聞・20230411)
上記記事によれば、OpenAIのCEOは「自ら日本に足を運ぶことで、オープンAIへの支持を広げる狙いがあったとみられる」「日本に拠点を設ける考えも示唆した」とあり、OpenAIは日本を市場として重視しようとしていることが伺われます。
OpenAIにとって、なぜ日本の市場は魅力的なのでしょうか。その理由のひとつとして、GDPR(欧州一般データ保護規則)をはじめとする主要な海外個人データ保護法制よりも、日本の個人情報保護法が機械学習にとって対応しやすいことが挙げられます。
実は日本における著作権法は、各国の法制と比べて機械学習にとって有利な点が多く、早稲田大学の上野達弘教授はこれをして「日本は“機械学習パラダイス”である」と評しておられました(リンク)。以前STORIAのブログでも掘り下げています(進化する機械学習パラダイス ~改正著作権法が日本のAI開発をさらに加速する~)。
本稿は、著作権法のみならず、個人情報保護法分野においても日本は機械学習にとって”パラダイス”と言いうる理由を述べるものです。
Contents
- 1 ChatGPTを規制する欧州や中国、推進する日本
- 2 日本の個人情報保護法とGDPRの相違点(伊でChatGPTが一時停止された理由に沿って)
- 3 LLM(大規模言語モデル)のビジネス3領域と個人情報保護法
- 4 ChatGPTなどのLLMサービスにとって日本は”機械学習パラダイス”となりうる
ChatGPTを規制する欧州や中国、推進する日本
2023年3月、イタリアでは、ChatGPTがGDPRに違反するとして、イタリア国内における利用者の個人データ処理を一時的に停止することが命じられました。
既に中国ではChatGPTの使用が停止されているほか、米国では商業利用の差止めを要請する動きが出ており、このような規制は欧州を中心に今後も拡大していくことが予想されます。
ChatGPT、欧州で規制強化検討へ イタリアがきっかけ(日経ビジネス・20230405)
ChatGPT、イタリアが一時禁止 米では差し止め要請(日本経済新聞・20230401)
中国が対話型AIを警戒、「ChatGPT」は使用停止に(読売新聞オンライン・20230304)
他方で日本においては、一部の企業や大学では規制する動きがあるものの、河野太郎デジタル相が生成AIを省庁の業務で生かすことについて「積極的に考えていきたい」と述べるなど、政府を中心として導入に積極的な意見が目立っています。
岸田文雄首相、「ChatGPT」の企業CEOと面会(日本経済新聞・20230410)
AIホワイトペーパー/自民党AIの進化と実装に関するプロジェクトチーム(衆議院議員塩崎彰久・20230203)
日本の個人情報保護法とGDPRの相違点(伊でChatGPTが一時停止された理由に沿って)
次に日本の個人情報保護法とGDPRの相違点について、イタリア当局がChatGPTを一時停止した理由に沿って検討します。
イタリア当局がChatGPTを一時停止した理由は以下の4点です(イタリアのデータ保護機関であるGDEPのリリース。決定本文はこちら)。
(1) ChatGPTのユーザーやデータ主体に対して、個人データの処理に関して適切な情報提供がなされていない(情報提供義務違反。GDPR5条1項(a)、13条)
(2) ChatGPTにおける個人データの収集と処理について、適切な法的根拠がない(処理の法的根拠。GDPR5条1項(a)、6条)
(3) 出力データが実際のデータと必ずしも一致せず、不正確である(正確性原則違反。GDPR5条1項(d))
(4) 13歳以上しか利用できないと定められているが、適切な年齢確認が行う仕組みが実装されていない(子どもの個人データの取扱いとデータプロテクションbyデザインbyデフォルト。GDPR8条、25条)
(1) 個人データ処理に関する適切な情報提供
GDPRでは、データ管理者はデータ主体に対して、一定の情報を適切に提供する義務があると定めています(GDPR13条)。
日本の個人情報保護法では、個人情報を取得するにあたっては利用目的を通知公表したうえで、特定した利用目的の範囲内で取り扱う必要があること、保有個人データに関する一定の事項については本人の知りうる状態に置くこと1本人の求めに応じて遅滞なく回答する場合を含みます。が求められています(個人情報保護法2以下単に「法」と記載する場合があります。17条、18条、21条、32条)。この点について、両者に本質的な差異はないといえます3ただしGDPRが情報の提供(provide)まで求めているのに対し、日本個情法は公表で足りる場合がある点は相違点といえます。
(2)個人データ処理の法的根拠
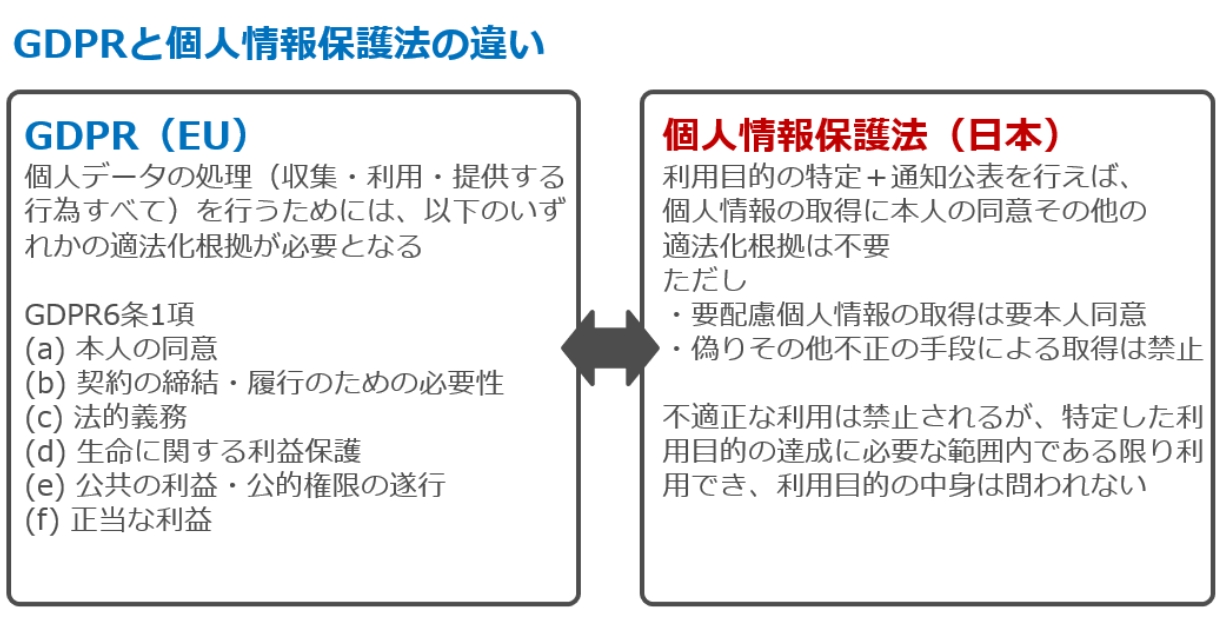
GDPRの場合、取得・利用・提供といったあらゆる個人データ処理について、本人同意、契約締結のための必要性、正当な利益といった6つの適法化根拠のいずれかを有している必要があります(GDPR6条)。
OpenAIは、プライバシーポリシー9項において、データ処理の適法化根拠として、サービスを不正使用、詐欺、セキュリティリスクから保護するため、またはサービス開発、改善、または宣伝する場合における「正当な利益」を挙げています4Our legitimate interests in protecting our Services from abuse, fraud, or security risks, or when we develop, improve, or promote our Services.。しかし一部報道によれば、イタリア当局は、「正当な利益」を適法化根拠とするOpenAIの主張について、現状では「不十分」と考えているとのことです(WIRED)5なお別件ですが、Meta社もユーザーデータを広告に利用するための適法化根拠を「正当な利益」と主張しており(2023年4月時点)、今後、オーストリアの非営利団体noybは何らかの申立てを行う旨を宣言しています(noyb)。
日本の個人情報保護法ではGDPRと異なり、個人データ処理全般における適法化根拠は要求されていません。要配慮個人情報を除けば、個人情報取得時に本人同意も不要です。
偽りその他不正の手段による取得や不適正な利用は禁止されますが(法19条20条)、これらに該当するようなごく例外的なケースでない限り、利用目的を特定して通知公表さえしていれば6契約締結に伴い契約書その他の書面に記載された当該本人の個人情報を取得する場合等は利用目的の明示が必要になります(法21条2項)。利用目的の中身自体は問われず、第三者提供や目的外利用をしない限りは本人同意も不要です(法18条2項、27条28条31条)。
GDPRと個人情報保護法の違い(適法化根拠)
(3)データの正確性
GDPRにおける基本原則のひとつとして、個人データは正確であり、かつ必要な場合は最新の状態に維持されることが求められています(正確性の原則。5条1項(d))。
日本の個人情報保護法でも、個人データを正確かつ最新の内容に保つことが求められていますが、あくまで努力義務にとどまるという違いがあります(法22条)。ただし保有個人データの内容が事実でない場合において、本人から請求があれば、訂正等する義務が生じます(法34条)。
(4)子どもの個人データの取扱い
GDPRでは、SNS等の情報社会サービスを子どもに直接提供する場合、16歳未満(国内法によって13歳まで引下げ可)の子どもの個人データ処理を行うためには、親や法定代理人から同意又は許可を得る必要があります(GDPR8条)。
これに対して日本の個人情報保護法では、委員会ガイドライン(通則編)が、未成年者が同意から生ずる結果について判断能力を有していないなどの場合は、親権者や法定代理人等から同意を得る必要がある旨を記載しているものの7ガイドライン通則編2-16。なお委員会Q&A1ー62は「一般的には 12 歳から 15 歳までの年齢以下の子どもについて、法定代理人等から同意を得る必要があると考えられます。」としています。子供からの個人情報取得が不正取得にあたる例としてガイドライン通則編3-3-1。、子どもの個人データの取扱いについて特別な規定を置いておらず、法文上、取得・利用・提供とも成人と同じ要件で行うことができます。
以上の点からすれば、イタリア当局からはGDPR違反であるとして一時停止を命じられたChatGPTですが8なおChatGPTはイタリア当局等からの指摘に対応する改善策を公表しています(リンク)。、日本の個人情報保護法にはただちに抵触しないと判断される可能性があると思われます。詳しくは次項で述べます。
※なお、EU域内に拠点を有しない事業者については、EU域内の個人に対して商品やサービスを提供しようとしている場合や、EU域内の本人の行動をモニタリングしている場合を除いて、GDPRは適用(域外適用)されません9GDPR の地理的適用範囲(第 3 条)に関するガイドライン(PPC仮訳)。
LLM(大規模言語モデル)のビジネス3領域と個人情報保護法
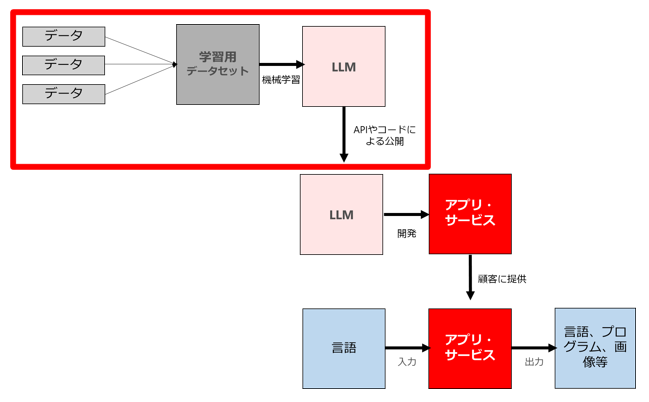
次にChatGPTをはじめとするLLM(大規模言語モデル)における3つのビジネス領域について、弊所の柿沼弁護士が先行するブログで用いた図に従って、個人情報保護法との関係を整理します。
(1) 大規模言語モデルを自ら開発してコードやAPIの形式で公開・提供するビジネス
①データの収集
大規模言語モデルを生成するためには、インターネット上から大量の言語データ(学習用データ)を収集する必要がありますが、それらの言語データに個人情報が含まれている場合があります。
もっとも前述のとおり、利用目的を特定して通知公表していれば、要配慮個人情報が含まれない限り(かつ不正の手段によるものでない限り)、個人情報の収集(取得)は自由に行えます。
ネット上に公開されている要配慮個人情報のうち、取得及び提供に関して本人の同意を得て公開されたものは、当該要配慮個人情報の取得に際して再度の同意取得は必要とされていません(委員会GL(通則編)3-3-2)。また要配慮個人情報が本人や学術研究機関、報道機関等によって公開されている場合も、当該要配慮個人情報の取得に際して同意取得は不要となります(法20条2項7号)。このようにデータ収集段階では、要配慮個人情報が含まれないように最大限の配慮が必要となります。
②個人情報を含む学習用データセットの公開・譲渡
データセットが「個人情報データベース等」に該当する場合、データセットの公開や譲渡は個人データの第三者提供となり、原則として本人の同意を得る必要がありますが(法27条1項)、オプトアウト処理をすることは可能と思われます(法27条2項)。
もっとも言語データの場合、データセットに個人情報が含まれており、かつ検索ができるものであったとしても、個人情報データベース等の定義10法16条1項。「この章及び第八章において「個人情報データベース等」とは、個人情報を含む情報の集合物であって、次に掲げるもの(利用方法からみて個人の権利利益を害するおそれが少ないものとして政令で定めるものを除く。)をいう。 一 特定の個人情報を電子計算機を用いて検索することができるように体系的に構成したもの 二 前号に掲げるもののほか、特定の個人情報を容易に検索することができるように体系的に構成したものとして政令で定めるもの」のうち「体系的に構成したもの」にあたらない場合もあることから11情報法制研究第4号(2018.11)82頁以下も参照。、LLMのデータセットについては「個人情報データベース等」に該当しない場合が相当数あるものと考えられます。この場合、データセットの公開や譲渡に第三者提供規制は適用されないことになります。
③モデルの公開・譲渡
複数人の個人情報を機械学習の学習用データセットとして用いて生成した学習済みパラメータ(重み係数)であっても、当該パラメータと特定の個人との対応関係が排斥されている限りにおいては個人情報に該当しません12委員会Q&A1-8。
よってデータセットが個人情報データベース等に該当するか否か、データセットに個人情報が含まれているか否かに関わらず、モデル自体が個人データ(個人情報データベース等)に該当する場合はほとんどなく、モデルの公開や譲渡について第三者提供規制が適用される可能性はほぼないと考えられます(過去ブログ「個人データ取扱いの委託によるAIモデル開発の可能性と限界を考える」も参照)。
(2) (1)で公開・提供されたモデルを利用したアプリやサービスを新規開発したり既存アプリに組み込んだりして提供するビジネス
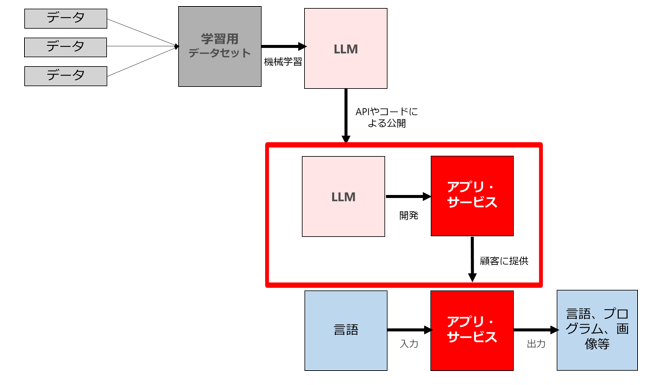
前記(1)の類型と同様の整理が妥当します。モデル自体が個人データ(個人情報データベース等)に該当するケースがほぼない以上、モデルを組み込んだアプリやサービスが個人データ(個人情報データベース等)に該当するケースもまずないと言ってよいと思います。
(3) ビジネスにおいて(2)で公開・提供されたアプリやサービスを利用するケース
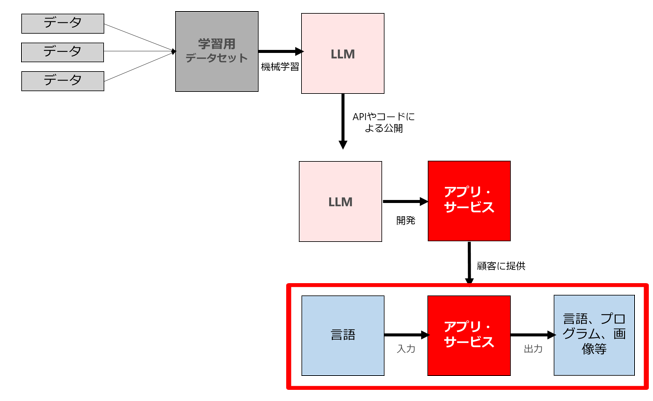
(2)のLLMを利用したアプリやサービス(以下「LLMサービス」ということがあります)を用いて、プロンプト(言語)を入力した結果得られる様々な出力(自然言語、プログラム、画像等)を、ビジネスの様々な領域で利用するケースです。
なおLLMサービスには、①LLM提供者が直接アプリ・サービスを提供しているパターン(例:Web版のChatGPT)と、②外部事業者がAPI経由する等してLLMサービスを提供しているパターン(例:API経由のChatGPT)とがありますが、以下は①を前提とします。ChatGPTとそのユーザーが、外部事業者を介さず直接やりとりをしている場合を想定してもらえればと思います。
①プロンプトの入力行為
LLMサービスのユーザーが、LLMサービスにプロンプトとして特定の個人を識別できる情報を入力する場合を想定します。なお個人情報保護法は個人情報取扱事業者(個人情報データベース等を事業の用に供している者。法16条2項)を規律対象としているため、個人情報取扱事業者にあたらない個人が、特定個人の氏名を入力したとしても規律対象外となります。
a 利用目的の特定
LLMサービスのユーザーが個人情報取扱事業者にあたる場合で、たとえば自社が保有する顧客データをLLMサービスに入力する場合はどうでしょうか。
LLMサービスへの入力も個人情報の利用の一態様であるため、利用目的を特定したうえで通知公表しておくことが必要になります。利用目的は「できる限り特定」(法17条1項)することを要しますが、最終的な利用目的で足りるとされることから13GL通則編3-1-1、「LLMサービスに入力するため」とまでは記載する必要はないと解されますが、LLMサービスに入力することによって、本人に関する行動・関心等の情報を分析する目的(いわゆるプロファイリング目的)の場合は、本人が予測・想定できる程度に利用目的を特定する必要があります14GL通則編3-1-1。
b 個人データの「提供」にあたるか
では顧客データのプロンプト入力は、LLMサービスのユーザーからLLMサービス事業者への個人データの「提供」にあたるでしょうか。
ここに委員会Q&A7-53では、クラウドサービスの利用が提供にあたるかどうかについて、「クラウドサービスを提供する事業者において個人データを取り扱うこととなっているのかどうかが判断の基準」であり、「当該個人データを取り扱わないこととなっている場合とは、契約条項によって当該外部事業者がサーバに保存された個人データを取り扱わない旨が定められており、適切にアクセス制御を行っている場合等が考えられます。」としています。
たとえばChatGPTの場合、利用規約において、API経由で受信したコンテンツについてはサービス開発改善のために利用しないが、API以外(Web版)経由で受信したコンテンツについてはサービス開発改善のために利用する旨が定められています(OpenAI利用規約3(c))15なおChatGPTにおいてユーザーがサービス開発改善のための利用を望まない場合はこちらからオプトアウトができます。。
とすれば、ChatGPTにおいては、API以外(Web版)の場合はもちろん、API経由の場合であっても、「不正使用や悪用を監視する目的」に限ってはアクセスをする可能性がある旨が留保されている点に鑑みれば16API data usage policies参照。この点は植田先生のNoteから情報を得ました。感謝申し上げます。、いずれの場合であってもOpenAIは個人データを取り扱っていると判断される可能性が否定できないため、ChatGPTの利用は個人データの「提供」にあたると整理しておいた方が無難といえます。「提供」にあたるとした場合、第三者提供規制(法27条)をクリアするには委託スキーム(同条5項1号)による場合が多いと考えられます。
さらに海外事業者が提供するLLMサービスの場合、外国第三者提供規制(法28条)もクリアする必要があります。この場合本人からの同意取得は現実的でないため、基準適合体制によることになると思われます。安全管理措置としての外的環境の把握も要します。
②出力行為
プロンプト入力によって、LLMサービスのユーザーは様々な出力(自然言語、プログラム、画像等)を取得することになります。この点も個人情報保護法との関連で様々な点が問題となりそうですが、長くなりそうなので本稿では論点の指摘にとどめます。
・LLMサービスからの出力に個人情報が含まれる場合、ユーザーは個人情報を取得したことになるか
・同様に出力に要配慮個人情報が含まれる場合、ユーザーは要配慮個人情報を取得したことになるか
・不正確な出力があった場合(たとえばある個人の経歴を質問するプロンプトに対して、当該個人の経歴として事実と異なる前科が出力された場合)、当該個人はLLMサービス事業者に訂正や削除を請求できるか(法34条)。この場合、LLM事業者サービスは個人データの正確性確保努力義務(法22条)や安全管理措置(法23条)違反となるか。
③LLMアプリ・サービス提供者の視点
以上はLLMサービスを利用するユーザーの立場で検討しましたが、最後にLLMサービス提供者の立場からも検討します。
前項「日本の個人情報保護法とGDPRの相違点」でも検討した通り、日本の個人情報保護法においては、(1)特定した利用目的を通知公表していれば、個人情報の取得や利用は広く可能であり、(2)要配慮個人情報を除けば、取得や利用するにあたって本人同意その他の適法化根拠も要求されず、(3)データの正確性確保も努力義務にとどまり、(4)子どもの個人データの取得や利用も成人と同様に行うことができます。
以上の(1)(2)(3)(4)についてLLMサービス提供者の代表例であるChatGPT(Web版)について検討すると、OpenAIはプライバシーポリシーにおいて利用目的を公表しており17Privacy policy2項。本サービスの提供、管理、維持、改善および/または分析のため;研究を行うため;お客様とのコミュニケーションのため;新しいプログラムやサービスを開発するため;当社サービスの詐欺、犯罪行為または不正使用を防止し、当社のITシステム、アーキテクチャ、およびネットワークのセキュリティを確保するため。(1)は満たすと考えられます。(2)については、ユーザーのプロンプトに要配慮個人情報が含まれていた場合、サービス提供者にとって当該要配慮個人情報の取得にあたるのかは悩ましいところですが、現在OpenAIは訓練データから個人情報を削除する方針を示しており(リンク)、さらに規約で要配慮個人情報の入力を禁止する等の対応をすることが考えられます18このような施策が講じられたとしても、要配慮個人情報が入力された場合に「取得」したことにならないのかについてはなお課題が存するように思えます。。(3)については不正確な回答が出力された場合に正確性確保努力義務(法22条)違反とはなりうるものの「努力」義務違反にとどまること(別途安全管理措置(法23条)違反は問題となり得る)、(4)は現行法においては直接抵触はしないと考えられます。
以上のとおり、LLMサービス提供者の代表例である「ChatGPT」を日本国内で提供する行為は、いくつかの懸念点はあるものの、GDPRの場合とは異なり、日本の個人情報保護法にはただちに抵触するとまではいえないと考えます。
ChatGPTなどのLLMサービスにとって日本は”機械学習パラダイス”となりうる
以上より、ChatGPTに代表されるLLMサービスにとって、LLMビジネス3類型のうち(1)モデル開発やデータセットの公開、(2)LLMサービスの開発・提供は、個人情報保護法に抵触しない可能性が高いといえます。他方で(3)LLMサービスのビジネス利用については、ユーザー側・サービス提供者側ともいくつかの懸念点はあるものの、GDPRに比べてその抵触リスクは相対的に低いということができます。
加えて日本の個人情報保護法は、GDPRと比べて執行リスクが低い点も指摘できます。GDPRでは、最大2,000万ユーロまたは全世界年間総売上の4%までのいずれか高い方の制裁金が科せられるところ(GDPR83条5項6項)、2022年に欧州各国のデータ保護当局が科した制裁金は過去最高の29億2000万ユーロ(約4200億円)にのぼりました19GDPR違反の制裁金、2022年は過去最高の29億2000万ユーロに(日経BP・2023/01/19)。日本の個人情報保護法も、令和2年改正により罰金の額が最大1億円にまで引き上げられましたが、罰金の執行例は現時点で確認できません。
このような個人情報保護法におけるペナルティの定めや執行実績を諸外国と比べた場合、個人データを取り扱うLLM提供事業者からすれば、日本は個人情報保護分野においても”パラダイス”に見えるのかもしれません。
ただし”パラダイス”というのはあくまでビジネスサイドからの視点であり、個人の権利、とりわけプライバシー侵害が生じてはならないわけですし(特にLLMサービスにおける特定個人に関する不正確な出力は「私生活上の事実または私生活上の事実らしく受け取られるおそれのある事柄」20「宴のあと」事件(東京地判昭39・9・28)判時385号12頁にあたるといえる点に鑑みれば、出力の内容その他ケースによってはプライバシー侵害を構成しうると考えます)、子どもの個人データ利用や、子どもによるLLMサービス利用についても今後適切なルールが設けられるべきでしょう。
LLMは我々の社会生活に劇的な変化をもたらす存在であり、大きなビジネスチャンスに溢れています。であるからこそ、LLMを利用したサービス提供者としては法規制の遵守と適切なルール策定(利用規約等)をしたうえで、この”パラダイス”を生かすべきですし、我が国としても自国の法制度を生かして、世界に先駆けたLLM大国を目指すタイミングが到来しているといえるのではないでしょうか。(弁護士杉浦健二)
- 1本人の求めに応じて遅滞なく回答する場合を含みます。
- 2以下単に「法」と記載する場合があります。
- 3ただしGDPRが情報の提供(provide)まで求めているのに対し、日本個情法は公表で足りる場合がある点は相違点といえます
- 4Our legitimate interests in protecting our Services from abuse, fraud, or security risks, or when we develop, improve, or promote our Services.
- 5なお別件ですが、Meta社もユーザーデータを広告に利用するための適法化根拠を「正当な利益」と主張しており(2023年4月時点)、今後、オーストリアの非営利団体noybは何らかの申立てを行う旨を宣言しています(noyb)
- 6契約締結に伴い契約書その他の書面に記載された当該本人の個人情報を取得する場合等は利用目的の明示が必要になります(法21条2項)。
- 7ガイドライン通則編2-16。なお委員会Q&A1ー62は「一般的には 12 歳から 15 歳までの年齢以下の子どもについて、法定代理人等から同意を得る必要があると考えられます。」としています。子供からの個人情報取得が不正取得にあたる例としてガイドライン通則編3-3-1。
- 8なおChatGPTはイタリア当局等からの指摘に対応する改善策を公表しています(リンク)。
- 9GDPR の地理的適用範囲(第 3 条)に関するガイドライン(PPC仮訳)
- 10法16条1項。「この章及び第八章において「個人情報データベース等」とは、個人情報を含む情報の集合物であって、次に掲げるもの(利用方法からみて個人の権利利益を害するおそれが少ないものとして政令で定めるものを除く。)をいう。 一 特定の個人情報を電子計算機を用いて検索することができるように体系的に構成したもの 二 前号に掲げるもののほか、特定の個人情報を容易に検索することができるように体系的に構成したものとして政令で定めるもの」
- 11情報法制研究第4号(2018.11)82頁以下も参照。
- 12委員会Q&A1-8
- 13GL通則編3-1-1
- 14GL通則編3-1-1
- 15なおChatGPTにおいてユーザーがサービス開発改善のための利用を望まない場合はこちらからオプトアウトができます。
- 16API data usage policies参照。この点は植田先生のNoteから情報を得ました。感謝申し上げます。
- 17Privacy policy2項。本サービスの提供、管理、維持、改善および/または分析のため;研究を行うため;お客様とのコミュニケーションのため;新しいプログラムやサービスを開発するため;当社サービスの詐欺、犯罪行為または不正使用を防止し、当社のITシステム、アーキテクチャ、およびネットワークのセキュリティを確保するため。
- 18このような施策が講じられたとしても、要配慮個人情報が入力された場合に「取得」したことにならないのかについてはなお課題が存するように思えます。
- 19
- 20「宴のあと」事件(東京地判昭39・9・28)判時385号12頁
・STORIA法律事務所へのお問い合わせはこちらのお問い合わせフォームからお願いします。












