人工知能(AI)、ビッグデータ法務
進化する機械学習パラダイス ~改正著作権法が日本のAI開発をさらに加速する~

Contents
■ はじめに
学習済みモデル生成のためには大量の生データや生データを元に生成した学習用データセットが必要となりますが、その際に著作物である生データ(文章、写真、静止画、動画など)を利用することも多くあります。
著作権法上、著作物は著作権者に無断で利用(ダウンロードや改変等)することは出来ませんが、実は日本の今の著作権法には47条の7という世界的に見ても希な条文があるため(詳細は後述)、AI開発目的であれば、一定限度で著作権者の許諾なく著作物を利用できます。
その点を捉えて、早稲田大学法学学術院の上野達弘教授は「日本は機械学習パラダイスだ」と評しています。言い得て妙ですね。
【参考】
コラム:機械学習パラダイス(上野達弘)
ただ、この47条の7には「ある限界」もありました。
2019年1月1日に改正著作権法の施行が予定されていますが、同改正法が施行されると、この47条の7が廃止され、新しい条文である新30条の4や新47条の5が発効します。
これによりAI開発のために可能な行為がより広くなるため、AI開発がより加速し、AI関連企業にとっては非常に大きなビジネスチャンスとなる可能性があります。
この記事では、「現行著作権法47条の7で可能な行為」「現行著作権法47条の7の限界」「改正著作権法30条の4等により可能となった行為」についてまとめます。
なお、今回の著作権法改正は、文化審議会著作権分科会報告書(2017年4月)に基づいて行われていますので、この報告書を以下「2017年報告書」として適宜引用します。
■ 現47条の7で可能な行為
まず、現47条の7で可能な行為を整理してみましょう。
モデル生成の際に行う作業
生データ収集からモデル生成の一連の流れを図にするとこのようになります。

この図で言う「データ収集」「データ処理」「機械学習、DL」とは、具体的には、データのコピーだったり、整形だったり、データセットを用いた機械学習や深層学習ですが、これらの行為は「複製」や「翻案」に該当することから、著作権者の承諾を得ない限り原則として著作権侵害となります。
日本の機械学習の救世主「著作権法47条の7」
しかし、そこで颯爽と現れるのが著作権法47条の7です。
著作権法47条の7は学習済みモデル生成に際しては非常に重要な条文ですのでぜひ覚えておいてください。
条文は以下のとおりです。
第四十七条の七 著作物は、電子計算機による情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の統計的な解析を行うことをいう。以下この条において同じ。)を行うことを目的とする場合には、必要と認められる限度において、記録媒体への記録又は翻案(これにより創作した二次的著作物の記録を含む。)を行うことができる。ただし、情報解析を行う者の用に供するために作成されたデータベースの著作物については、この限りでない。
簡単に言うと「情報解析」のためであれば、必要な範囲で、著作権者の承諾なく著作物の記録や翻案ができる、というものです(ただし一部例外あり)。
したがって「情報解析」に「機械学習・深層学習」が含まれるとすれば、「機械学習・深層学習」のためであれば著作物について著作権者の承諾なく自由に記録や翻案ができる、ということになります。
そして、この点については、私が知る限りでは、「情報解析」に「機械学習・深層学習」は含まれる、すなわち「機械学習・深層学習」に著作権法47条の7は適用されるという意見が多数を占めていると思います(後述しますが、この点については改正法ではより明確になりました)。
そのような見解に立つと、たとえ他人の著作物であっても、機械学習・深層学習のためであれば著作権法47条の7により無許諾で自由に利用できる、ということになります。 さらに、この条文の最大のポイントは、「非営利目的の利用」に限定されていないことです。
つまり営利目的(販売・有償提供目的)の学習済みモデル生成のためにもこの条文は適用され、営利目的であっても著作物の「記録・翻案」が可能なのです。
ちなみに諸外国でも日本著作権法47条の7と同趣旨の規定はあるのですが、いずれも非営利目的の開発や、研究機関による開発の場合にのみ許容されていますので、営利目的の場合でも適用がある日本著作権法47条の7は、世界的に見ても特異的と言われています。
つまり、端的に言うと「著作権法47条の7は日本の機械学習の宝」であり「機械学習するなら日本においで」ということになります。
よくある質問
私はセミナーなどでこの著作権法47条の7を紹介することも多いのですが、そのたびに参加者の皆さんからは、声にならない驚きの声が上がります。私の手柄でも何でもないのですが少し気持ちの良い瞬間です。
ただそのたびに、よく受ける質問がありますので、以下に整理しておきます(ちなみに、以下の質問と回答は改正著作権法の下でも同様に当てはまります)
1 日本著作権法47条の7が適用されると著作物の無断利用も適法になるいうことだが、外国のサーバ上で学習作業を行ってもこの47条の7は適用されるのか
これは、著作物の利用行為の準拠法の問題(ある利用行為にどこの国の法律が適用されるかの問題)ですが、著作権法については、著作物の「利用行為地」における法律が適用されるとされています。
ただ、特にネットを利用した利用行為の場合、どこが「利用行為地」であるかの解釈は難しい問題です。
1つの考え方としては、「サーバの所在地」が利用行為地であるというものですが、A国にいる人がB国に所在しているサーバを利用して学習行為を行った場合にA国の著作権法が適用されるのか、B国の著作権法が適用されるかは難しい問題です。
ただ、「日本国内にサーバがあり、日本国内にいる人が同サーバを利用してデータのダウンロードやラベル付け、学習行為を行う」ケースであれば、日本著作権法47条の7が適用されることはほぼ間違いないと思われます。
なので「機械学習するなら(物理的に)日本においで」ということなのです。
2 国外の権利者(たとえばディズニーなど)が権利を持っている著作物を利用する行為についても47条の7は適用されるのか
これも準拠法の問題ですが、準拠法の問題は「利用行為地」によって決される問題であり「権利者の所在地」は無関係です。
したがって、国外の権利者が権利を持っている著作物についても、日本国内で学習作業が行われる限り、日本著作権法47条の7が適用され適法となります。
なのでやっぱり「機械学習するなら(物理的に)日本においで」ということなのです。
3 海外の大学や事業者とAI開発に関する共同研究を行う場合、著作権等の法律はどこの国の法律が適用されるのでしょうか(データがあるところ?作業するところ? 見ることができるところ?等)
これまでの説明からおわかりのとおり、「学習作業をする場所」の国の法律が適用されることになります。
■ 現47条の7の限界
ただ、現47条の7は、あくまで生データ収集、データベース作成、学習用データセット作成、機械学習、DLを同一の事業者が一連の流れとして行う場合のみにしか適用されません。
これは、47条の7で許容されている行為が「記録媒体への記録・翻案」のみであること、47条の10(複製権の制限により作成された複製物の譲渡)に47条の7が含まれていないことから導かれる結論です。
したがって、以下のようなケースにおいては現47条の7は適用されず、原則に戻って、著作権者の同意なく行った場合には著作権侵害となります。
1 自らモデル生成を行うのではなく、モデル生成を行う他人のために学習用データセットを作成して不特定多数の第三者に販売したりWEB上で公開する行為
例:WEB上あるいは権利者から公衆に提供されている大量の画像データを複製して、画像認識用モデル生成のための学習用データセットを作成して販売するケース
2 自らモデル生成をするために学習用データセットを作成し、これを用いてモデルを生成した事業者が、使用済みの当該学習用データセットを不特定多数の第三者に販売したりWEB上で無償公開する行為
例:画像生成用モデルを生成した事業者が同モデル生成に利用した学習用データセットとモデルをセットにして販売するケース
3 特定の事業者で構成されるコンソーシアム内で、学習用データセットを共有する行為
例:深層学習を利用した自動翻訳エンジンを生成する事業者が、WEB上の自然言語データを大量に収集して生成した対訳コーパスを、事業者団体内部で相互に共有するケース
なお、1と2のケースについては、「特定の第三者に対して譲渡する行為」であれば適法である可能性もあるのですが、どこまでが「特定の第三者」に該当するかについては、その範囲を非常に狭く解釈した裁判例もあり、確立した見解がありませんでした。
この問題点については、知財戦略本部の「新たな情報財検討委員会報告書」(平成29年3月)や、2017年報告書でも指摘されており、その対応の必要性が共有されていました。
■ 改正著作権法30条の4
どう変わるのか
このような問題意識の下、現47条の7は、柔軟化・拡充され、新30条の4第2号となりました。
早速条文を見てみましょう。
第三十条の四
著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
(中略)
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
(以下略)
現47条の7から新30条の4第2号への主要な改正点についてまとめたのが以下の表です。
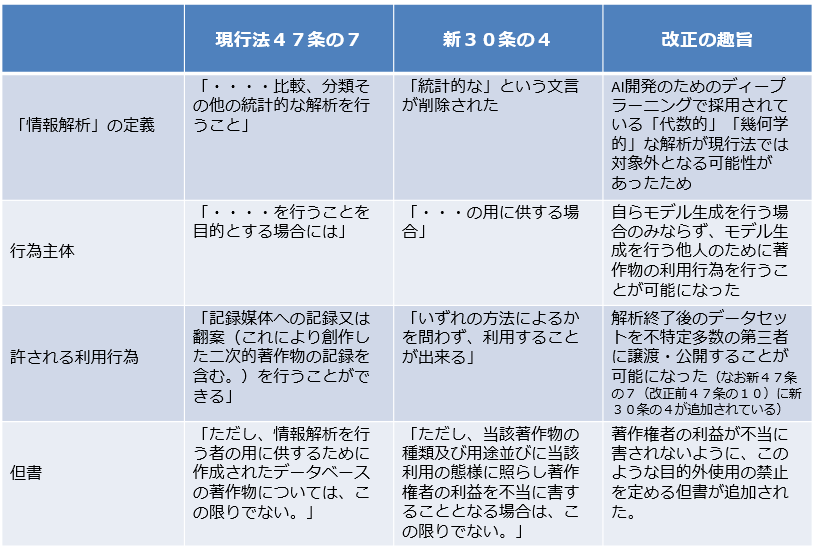
これにより、先ほど「現47条の7が適用されず違法となる行為」として紹介した以下の3つの行為にはいずれも新30条の4が適用され、適法になります。
1 自らモデル生成を行うのではなく、モデル生成を行う他人のために学習用データセットを作成して不特定多数の第三者に販売したりWEB上で公開する行為
例:WEB上あるいは権利者から公衆に提供されている大量の画像データを複製して、画像認識用モデル生成のための学習用データセットを作成して販売するケース
2 自らモデル生成をするために学習用データセットを作成し、これを用いてモデルを生成した事業者が、使用済みの当該学習用データセットを不特定多数の第三者に販売したりWEB上で無償公開する行為
例:画像生成用モデルを生成した事業者が同モデル生成に利用した学習用データセットとモデルをセットにして販売するケース
3 特定の事業者で構成されるコンソーシアム内で、学習用データセットを共有する行為
例:深層学習を利用した自動翻訳エンジンを生成する事業者が、WEB上の自然言語データを大量に収集して生成した対訳コーパスを、事業者団体内部で相互に共有するケース
なお、新47条の5第1項2号では「電子計算機による情報解析とその結果提供」が定められています。
したがって、データセットを生成して公衆に販売するビジネスを行う際に、当該データセット内に含まれている著作物を一定限度で利用する行為(たとえば販売サイトにデータのごく一部を掲載する行為など)も許容されることになります。ただ、ここで許容されている利用行為は「軽微利用」(「当該公衆提供提示著作物のうちその利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なもの」)に限られているので、無制限に著作物が利用できるわけではありません。
■ 改正著作権法施行後、実務で問題になることが確実な論点
このように、新30条の4によって、2019年1月1日以降は、学習用データセットの公衆提供・譲渡が可能になります。
その後、実務的に論点になるのは、同条本文但書の「ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。」とは具体的にはどのようなケースなのか、ということだと思われます。
まず、以下の2つは確実です。
現47条の7本文但書に該当する行為はNG
まず、現47条の7本文但書に該当する行為、つまり「情報解析を行う者の用に供するために作成されたデータベースの著作物」を利用する行為は新30条の4本文但し書きに該当し、NGということになると思われます(平成30年4月6日衆議院文部科学委員会における中岡文化次長答弁)。
現47条の7本文が適用されて適法だった行為が違法となることはない
次に、国会付帯決議の内容からすると、現47条の7本文が適用されて適法だった行為が違法となることはないと思われます。
では、それ以外のケースで一般的に「著作権者の利益を不当に害することとなる場合」とはどのような場合を指すのでしょうか。
もう少し掘り下げて考えてみましょう。
この論点については、著作権法の構造や、今回の著作権法改正のうち「柔軟な権利制限規定の整備」の背景にあると思われる思想を理解する必要があります。
■ 今回の著作権法改正のうち「柔軟な権利制限規定の整備」の背景思想
権利制限規定の3層構造
これまで紹介してきた新30条の4や同47条の5の規定は、今回の著作権法改正の複数のテーマのうち「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定の整備」に関するものです。
「権利制限規定」というのは、著作権者の権利を一定限度で制限する制度ですので、要するに「著作権者の許諾がなくても著作物を利用できるのはどのような場合か」という点に関する規定を整備したということになります。
今回の著作権法改正は2017年報告書の提言を具体化したものですが、この報告書は、権利制限規定を3つの「層」に分類し、当該3つの層について、それぞれ適切な柔軟性を確保した規定を整備することが適当であるとしています。
まず、現行法の規定をこの3層に従って分類するとこうなります。
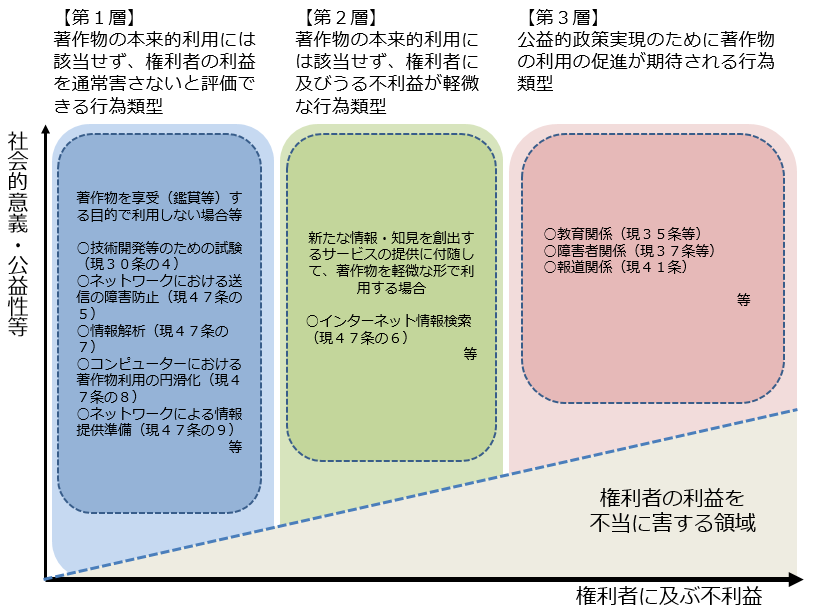
2017報告書40頁「図:権利者に及び得る不利益の度合いに応じた権利制限規定の三つの層について」をもとに作成。
次に、改正法の規定を分類するとこうなります。
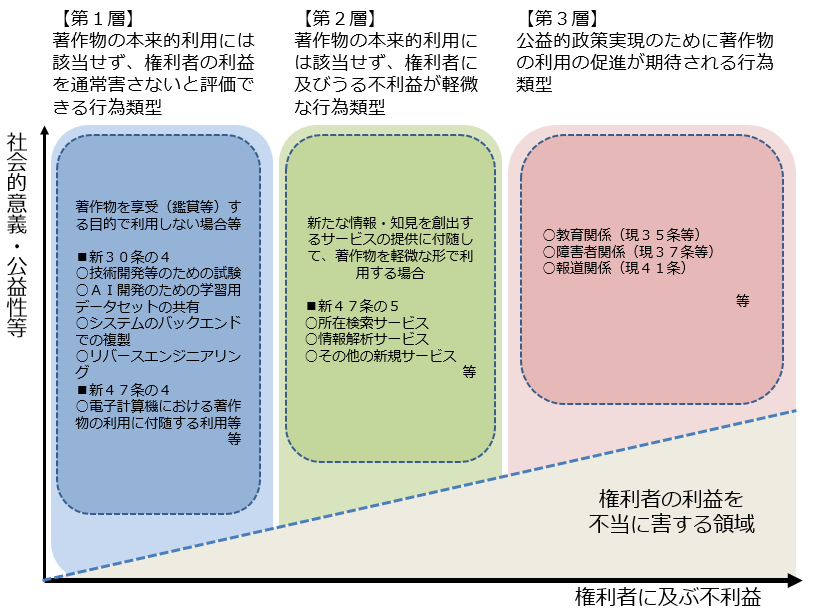
2017報告書40頁「図:権利者に及び得る不利益の度合いに応じた権利制限規定の三つの層について」をもとに作成。
このうち第1層については「著作物の本来的利用には該当せず、権利者の利益を通常害さないと評価できる行為類型」であって、今回ずっと説明してきた改正法30条の4はこの第1層に属する権利制限規定です。
では、第1層でいう「著作物の本来的利用」や「権利者の利益」とは具体的に何を意味するのでしょうか。
著作権法の構造
1 著作権法が前提としている「著作物の経済的価値」や「権利者の利益」とはなにか
そもそも著作物の経済的価値はどこにあるのでしょうか。
人は何を期待して著作物にお金を払うのか、ということです。
まず、著作物の視聴者が著作物を「見て楽しむ」「聞いて楽しむ」ためにお金を支払う、つまり「著作物の視聴者が当該著作物を視聴して満足することと引き換えに支払う対価」が「著作物の経済的価値」に該当することは言うまでもありません。
ただ、実は「著作物を視聴して満足する」以外にも著作物が持っている経済的価値はあります。
たとえば、「情報解析のために著作物を利用する」「技術開発のために著作物を利用する」「情報通信設備のバックエンドで著作物を利用する」「AI開発のために著作物を利用する」「サイバーセキュリティソフト確保のためにソフトウェアをリバースエンジニアリングする」などに対して利用者が支払う対価も、「著作物の経済的価値」です。
もっとも、これら複数の「著作物の経済的価値」のうち、著作権法が保護しようとしているのは「著作物の視聴者が当該著作物を視聴して満足することと引き換えに支払う対価」という部分だけです。
この点について、2017年報告書41頁では「視聴者が著作物に表現された思想又は感情を享受することによる知的又は精神的欲求の充足という効用の獲得を期待して,著作物の視聴のために支払う対価が著作物の経済的価値を基礎付ける」としています。
つまり「著作物の本来的利用」とは「著作物に表現された思想・感情の享受」を意味し、「権利者の利益」とは、「視聴者が著作物の視聴のために支払う対価」を意味するのです。
2 「著作権」とはなにか
そして、著作権法はこの「著作物の経済的価値」を著作権者に与えるために、著作権者に「著作権」、具体的には「複製権」「上演権」「公衆送信権」などの権利を与えています。
これは、著作物を、「著作権者から著作物の受領者に届ける流通過程をコントロールする権利」と言い換えてもいいでしょう。
著作権者の下で発生した著作物が、遠く離れた場所にいる(隣にいる人でもいいのですが)受領者に届くまでには「複製」や「上演」「公衆送信」などの各種の流通行為が必要です。
「著作権」というのは、その流通行為を著作権者がコントロールすることが出来る権利なのです。
3 著作権法が著作権の対象としている行為
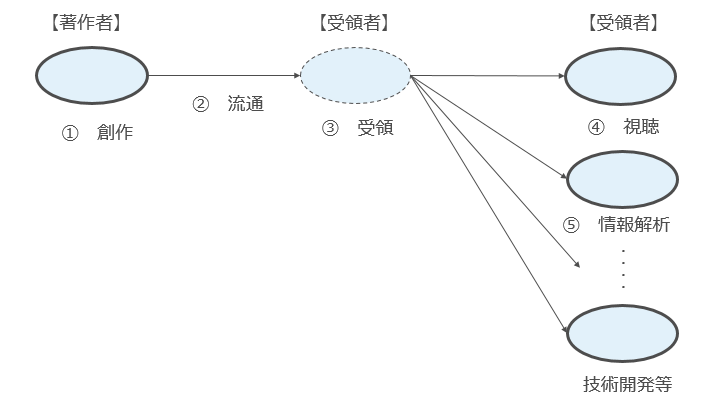
簡単な図で示すとこのようになります。
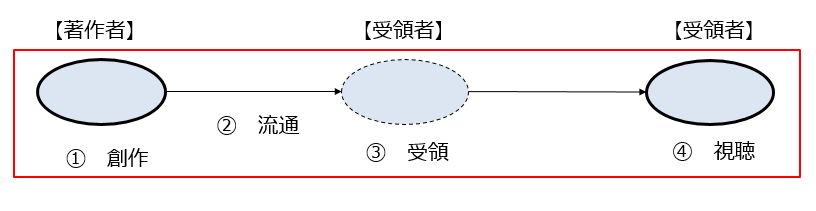
まず、1で著作者が著作物を創作します。
その上で2で著作物が流通し、3で当該著作物を受領者が受領します。
そして、4で受領者は当該著作物を視聴することで満足するということになります。
著作権法が保護の対象としている「流通行為(複製・上演等)」、言い換えれば「著作物の本来的利用」に向けられている「流通行為(複製・上演等)」は、この「視聴に向けられた流通行為(複製・上演等)」ということになります(上記図の赤枠)。
4 著作権法が著作権の対象としていない行為
一方で、先ほど述べたように著作物には「著作物を視聴して満足する」以外にも著作物が持っている経済的価値はあります。
ただ、その経済的価値は著作権法が前提としているものではありません。
そうすると、「著作物を視聴して満足する」ことを前提としていない、つまり「著作物の本来的利用」に向けられていない流通行為(複製・上演等)については、著作権法の保護の対象ではないということになります。つまり下記図の青枠部分は著作権法では保護されません。
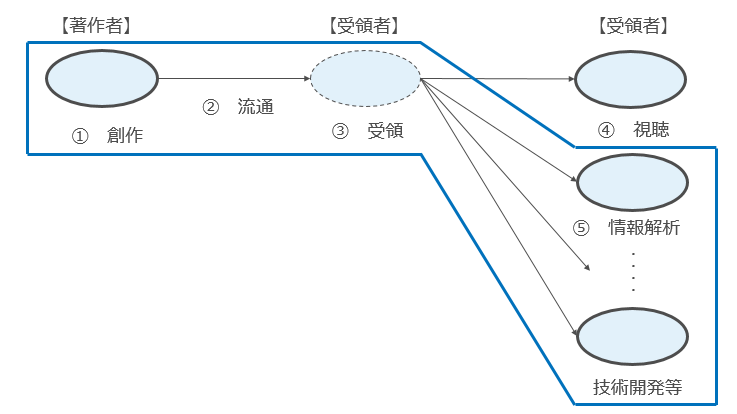
このような考え方が権利制限規定のうち「著作物の本来的利用には該当せず、権利者の利益を通常害さないと評価できる行為類型(第1層)の背景にあるのです。
まとめ
長くなりました。
問題は新30条の4本文但書の「ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。」とは具体的にはどのようなケースなのかということでした。
そこでは「著作権者の利益」という文言が使われています。
そして、この「著作権者の利益」というのは、先程説明したような著作権法の構造や「第1層」の権利制限規定の趣旨からすると「著作物の受領者が当該著作物を視聴して満足することと引き換えに支払う対価を得る機会が確保されること」ということになります。
つまり「当該著作物の受領者が当該著作物を視聴して満足する」ような「種類・用途・利用態様」による利用こそが、この但書に当たるということになります。
もっとも、新30条の4はそもそも「著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」を類型化したものですから、同本文の要件をクリアすれば、この但書は原則として適用されないということになります。
例外的に但書が適用されるケースとして、たとえば「●●風キャラクター生成モデル用学習用データセット」と銘打って特定の作家の全漫画を単にデジタル化しただけのデータセットを販売するようなケースが考えられます。このケースは確かに学習済みモデル生成用の学習用データセットとして使おうと思えば使える(ただし自分でラベル付などは行わなければなりませんが)データセットですので、本文2号「情報解析」には該当しますが、このデータは、そのまま視聴して楽しむことも十分に可能です。とすると、但書に該当することになると思われます。
■ まとめ
▼ 機械学習のために他人の著作物を利用する行為は、同一事業者がモデル生成まで一気通貫に行う場合には、現行著作権法47条の7により適法
▼ ただし、「自らモデル生成を行うのではなく、モデル生成を行う他人のために学習用データセットを作成して不特定多数の第三者に販売したりWEB上で公開する行為」「自らモデル生成をするために学習用データセットを作成し、これを用いてモデルを生成した事業者が、使用済みの当該学習用データセットを不特定多数の第三者に販売したりWEB上で無償公開する行為」「特定の事業者で構成されるコンソーシアム内で、学習用データセットを共有する行為」は現47条の7の適用がなく著作権侵害に該当する。
▼ 2019年1月1日施行の改正著作権法30条の4の下では、先程の3つのパターンがいずれも適法となる。
▼ 実務的には新30条の4但書がどのような場合かが大きな問題になると思われるが「当該著作物の受領者が当該著作物を視聴して満足する」ような「種類・用途・利用態様」による利用でなければ同本文但書には該当しないため、本文の要件をクリアすれば、この但書は原則として適用されないということになると思われる。
(弁護士柿沼太一)












