人工知能(AI)、ビッグデータ法務
大規模言語モデル(LLM)に関連するビジネスを展開する際に留意すべき法規制・知的財産権・契約
![]()
OpenAIのChatGPT、MicrosoftのBing、GoogleのBardなど、言語系のAIサービスが急速に普及し始めました。1ちなみに記事冒頭のアイキャッチ画像は, 会社のロゴ風画像で「GPT」という文字をなんとか表示させようと画像生成AIで1時間悪戦苦闘したが結局、意味不明の文字列しか出てこなかったロゴ」です
これらのサービスは、いずれも大規模言語モデル(Large Language Models; LLMs)をベースにしているという共通点があり、社会や産業に極めて大きなインパクトを与えると予想されています。
そこで、このような大規模言語モデル(LLM)に関連するビジネスを展開する際に留意すべき法規制・知的財産権・契約について、何回かに分けてまとめてみようと思います。
今回は、まずは総論部分として「大規模言語モデル(LLM)に関連するビジネス3つの領域」と「それぞれの領域において法的に問題となる事柄」について簡単に説明をします。
Contents
1 大規模言語モデル(LLM)に関連するビジネス3つの領域
東京大学の松尾豊先生が「AIの進化と日本の戦略」(2023/2/17)という資料で「日本の戦略」として以下の3つを提示されています。
1. 大規模言語モデルを自ら開発する
– 数百億円あれば同じようなものは作れる(ただし、その間に相手はもっと先に行く。)- 今後のインパクトの大きさを考えれば、この戦いに参入するチケットとしては安い。この機会が開いているウィンドウは短い。2. APIを使いサービスを作ることを奨励する
– ChatGPTなどのAPIを使って、ローカライズした専用アプリ、専用ソフトウェアが多く出現。国内の市場になるので、最低限ここはしっかり伸ばすべき。
– 一方Apple Store等と同じく、手数料を払い続けないといけない。3. ユーザとしての活用を促進する
– DXが進んでいない現状において、言語による指示ができることは、DXの決め手になる可能性はある
– つまり、DXにおけるリープフロッグ。(アフリカに固定電話が入ってないのに携帯が入ったように。)
大規模言語モデル(LLM)に関連するビジネスは、この松尾先生の分類を使うと整理がしやすいと思います。
全体像を図で示すと以下のようなイメージです。
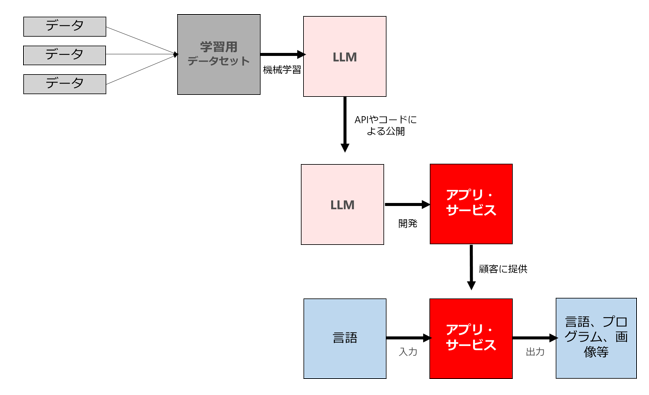
(1) 大規模言語モデルを自ら開発してコードやAPIの形式で公開・提供するビジネス
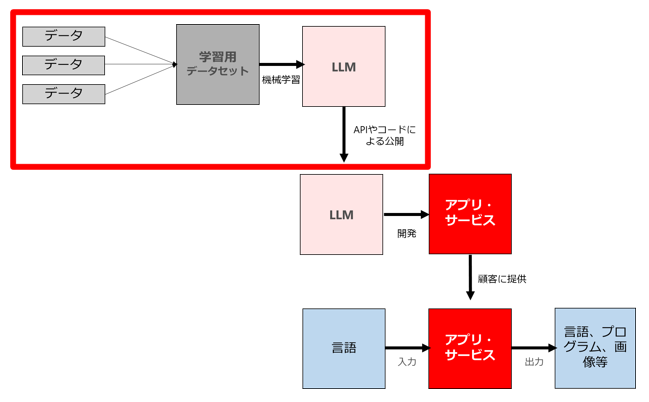
まず、一番上が「(1)大規模言語モデルを自ら開発してコードやAPIの形式で公開・提供するビジネス」です。
大量のデータ及び大規模な計算資源が必要であるため、OpenAIやDeepMind、MetaやGoogleなどが存在感を示している領域ですが、ソニーやLINE、それ以外のスタートアップも取り組んでいます。
最近では自民党が、日本語版大規模言語モデルの開発にこだわるべきか否かなどを含んだ「AIホワイトペーパー」を公表予定とのことで注目を集めています。
(2) (1)で公開・提供されたモデルを利用したアプリやサービスを新規開発したり既存アプリに組み込んで提供するビジネス
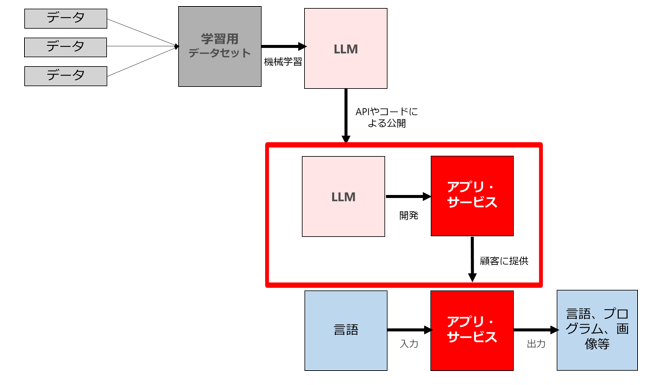
次に「(1)で公開・提供されたモデルをベースにアプリやサービスを新規開発したり既存アプリに組み込んで提供するビジネス」です。
「LINEで使えるChatGPTが「3週間で77万登録」の大ヒット。社員2人のベンチャーが開発、課題は“コスト”」で紹介されているようなアプリですね。
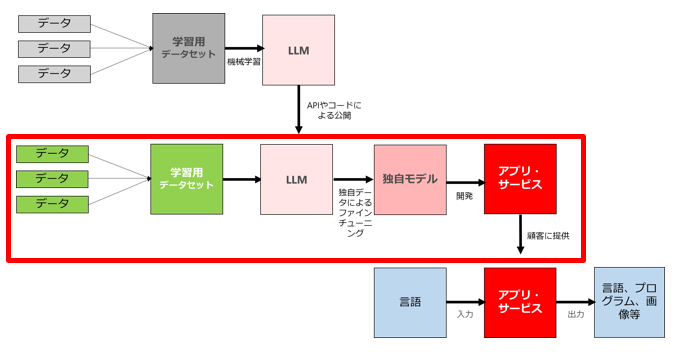
この領域では、上記の図のようにシンプルに(1)のモデルをそのままアプリ等に組み込んで提供する場合もありますが、(1)のモデルに、独自のデータセットを用いて特定の目的(法律や会計、医学知識等)に特化した学習を行い、独自モデルを生成することもあります。
下記のようなイメージです。
(3) ビジネスにおいて(2)で公開・提供されたアプリやサービスを利用する行為
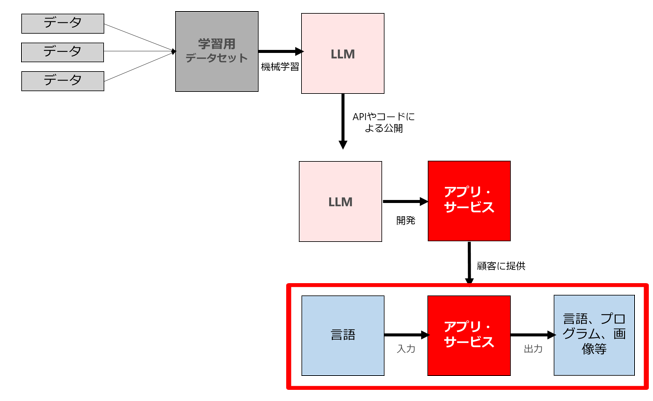
最後が、「(3)ビジネスにおいて(2)で公開・提供されたアプリやサービスを利用する行為」です。
(2)のアプリ・サービスを利用すれば、言語による入力をすることで、目的に応じた様々な出力(自然言語、プログラム、画像等)を簡単に得る事ができますので、ビジネスの様々な領域で利用されることが予想されます。
2 それぞれの領域において法的に問題となる事柄
それぞれの領域において法的に問題となる事柄は異なります。
(1)大規模言語モデルを自ら開発してコードやAPIの形式で公開・提供するビジネス
① データの収集・利用についての著作権法・個人情報保護法制・契約上の条件のクリア
大規模言語モデルを生成するためには、まず大量の言語データを収集する必要がありますが、当該データを収集するためには法規制のクリアや知的財産権の権利処理が必要となります。
実務上、よく問題となるのは「個人情報保護法制のクリア」「著作権の権利処理」「データベースの利用契約を締結した上で利用する場合の契約上の条件のクリア」です。
データを収集した後、データセットやモデルを生成することになりますが、その後の公開に際しては、モデルだけではなくデータセットも公開することがよくあります。データセットの公開と、データセットを用いて学習したモデルの公開とでは問題となる事柄が異なりますので注意が必要です。
② データセット・モデルの知的財産権
生成したデータセットやモデルに知的財産権(特に著作権)が発生するかの問題です。データセットやモデルのライセンス違反が生じた場合に著作権侵害の責任を追及できるかという形で問題となります。
③ データセットやモデルを公開・提供する場合の利用条件
生成したデータセットやモデルをコードやAPI等の様々な形式で公開・提供する場合にはその利用条件・ライセンスを適切に設定する必要があります。
④ データセットやモデルのユーザーによる違法行為
データセットやモデルを公開した場合、(2)のように当該モデルを用いて様々なアプリやサービスが開発されることが予想されますが、当該アプリやサービスの利用ユーザにより何らかの違法行為が行われる可能性もあります。その場合、データセットやモデルの提供者が責任を負うか、が問題となりますが、大規模なデータセットや当該データセットで学習を行った大規模言語モデルの提供の場合、モデル・データセット提供者が責任を負う可能性は極めて低いと思われます。
(2)(1)で公開・提供されたモデルを利用したアプリやサービスを開発して提供するビジネス
① ライセンスの解釈
(1)の大規模言語モデルは通常APIやOSSとして公開されているため、当該API・OSSに関するライセンス条件の的確な解釈が必要となります。
② 独自のデータセットで独自学習を行う場合
(1)の大規模言語モデルをベースにして、独自のデータセットでファインチューニングを行う場合には、(1)と同様「データの収集・利用についての著作権法・個人情報保護法制・契約上の条件のクリア」や「データセット・モデルの知的財産権」が問題となります。
③ 開発したアプリやサービスをユーザーに提供する際のサービス内容や利用規約の設計
アプリやサービスを提供する際には利用規約が必要となりますが、生成AIを利用したサービスの場合は特に「免責規定の設計」と、「ユーザーがサービス利用に際して入力したデータやフィードバックを追加学習に利用するためのデータの利用条件の明確化」が必要です。
免責規定はサービス提供者のリスクをコントロールするために重要なツールですが、万能ではありません。たとえば、サービス提供者に故意・重過失があった場合には免責規定は適用されませんし、権利侵害を容易に引き起こすようなツールを提供した場合、免責規定の有無に関わらず権利者から直接権利行使されることがあります。後者の部分についても、ユーザーのフィードバックはモデルやアプリを改善するための貴重な「材料」になりますので今後極めて重要になると思われます。
④ 公開したアプリを利用してユーザーが何らかの違法行為を行った際のサービス提供者の責任をどう考えるか
LLMを利用したアプリ・ツールは様々な活用が可能であり、当該ツールを利用してユーザーが違法行為(著作権侵害行為や、名誉毀損行為等)を行うことも十分にありえます。その場合、当該ユーザーが民事上・刑事上の責任を負うことは当然として、当該ツールを提供する事業者自身も何らかの責任を負うことがありえるか、の問題です。
データセットや大規模言語モデルの公開と異なり、当該モデルに独自学習を施してアプリを作成・公開する場合、学習のさせ方によっては権利侵害を容易に引き起こす可能性もあるため、注意が必要です。
⑤ 特定の領域における法規制
特定の領域のサービス(例:AI医療機器やリーガルテック)については特別な法規制が掛かっているため、当該領域においてAIを利用したアプリ・サービスを提供するに際しては当該法規制をクリアする必要があります。AI医療機器については主として薬機法、リーガルテックについては主として弁護士法や弁理士法が問題となります。
(3)ビジネスにおいて(2)で公開・提供されたアプリやサービスを利用する行為
この領域は、実際に言語生成AIをビジネスでユーザーが活用する際に生じる、いわば川下の問題ですので、今後沢山の問題が発生すると思われます。また、実際には、サービスのユーザーだけではなく、サービスを提供するベンダサイドで「当該サービスの利用行為が適法であること」について整理した上できちんとユーザーに説明することが求められるでしょう。
この領域については、データの入力行為が適法かという問題と、出力行為の問題を分けて考えるとよいと思います。
① 入力行為
言語生成AIを利用する場合、様々な種類のデータを入力することが考えられますが、法的に問題となるのは以下の3種類のデータだと思われます。いずれもかなりセンシティブな問題でして、特にcについては機密漏洩を懸念して業務上での言語生成AIの利用を禁止する企業が出てきています。
a 他人が知的財産権(特に著作権)を有しているデータを入力する行為は適法か
b 個人情報・個人データを入力する行為は適法か
c a,b以外の価値がある情報(社内規定上秘密保持義務が課されている情報、自社の営業秘密、他社から秘密保持義務を課されて開示された情報・営業秘密等)を入力する行為は適法か
② 出力行為
a 出力テキストに著作権が発生するか
「AIの出力に著作権が発生するか」は画像生成AIではよく問題となる点です。
画像生成AIと言語生成AIでは利用されている技術は異なりますが(画像生成AIは拡散モデル、言語生成AIは深層学習モデル「Transformer(トランスフォーマー)」が利用されていることが多い)言語生成AIでも出力の著作物性は同じように問題となります。
具体的には画像生成AIと同様、「創作的寄与」と「創作意図」があるかにより判断されますが、言語生成AIの利用者が何らかの指示をして、何らかのリサーチ結果、アイデアや回答を得た場合、出力テキストには利用者の創作意図と創作的寄与は通常はありませんので著作権は発生しないということになるでしょう。
ChatGPTから、よりよい出力を引き出すために、質問(入力)の仕方のTIPSが沢山公開されていますが、利用者が質問をするにあたってそれらのTIPSを駆使したとしても、出力テキストに対する利用者の創作意図と創作的寄与が認められることはないように思います。
b 当該出力の生成行為が違法行為(著作権侵害や名誉毀損等)に該当しないか
これも画像生成AIではよく問題となる点ですが、言語生成AIでももちろん問題となります。
こちらの記事にかなり詳しくまとめてあるので、よろしければご参照下さい。
3 まとめ
以上、大規模言語モデル(LLM)に関連するビジネスを展開する際に留意すべき法規制・知的財産権・契約について、「大規模言語モデル(LLM)に関連するビジネス3つの領域」と「それぞれの領域において法的に問題となる事柄」について整理をしました。
次回以降は、これらの3つの領域についてより詳細に検討していこうと思います。
- 1ちなみに記事冒頭のアイキャッチ画像は, 会社のロゴ風画像で「GPT」という文字をなんとか表示させようと画像生成AIで1時間悪戦苦闘したが結局、意味不明の文字列しか出てこなかったロゴ」です












