人工知能(AI)、ビッグデータ法務 著作権
自然言語系AIサービスと著作権侵害

Contents
第1 はじめに
自然言語処理技術の発展に伴い、自然言語AIを利用したサービスが大変盛り上がっています。
たとえば、検索、要約、翻訳、チャットボット、文章の自動生成、入力補完などのサービスで、近いところで有名なのは、2020年にOpenAIが発表した「GPT-3」ですかね。これは約45TBにおよぶ大規模なテキストデータを学習し、あたかも人間が書いたような文章を自動で生成することが可能な自然言語モデルです。
【参考リンク】
自然言語処理モデル「GPT-3」の紹介
進化が止まらない自然言語処理技術ですが、事業者が自然言語AIを利用したサービス(*ここでは、データの処理がクラウド上で自動的に行われるサービスを前提とします)を提供する際に検討しなければならないことは、大きく分けると、学習済みモデルの構築フェーズの問題と、モデルを利用したサービス提供フェーズに関する問題に分かれます。
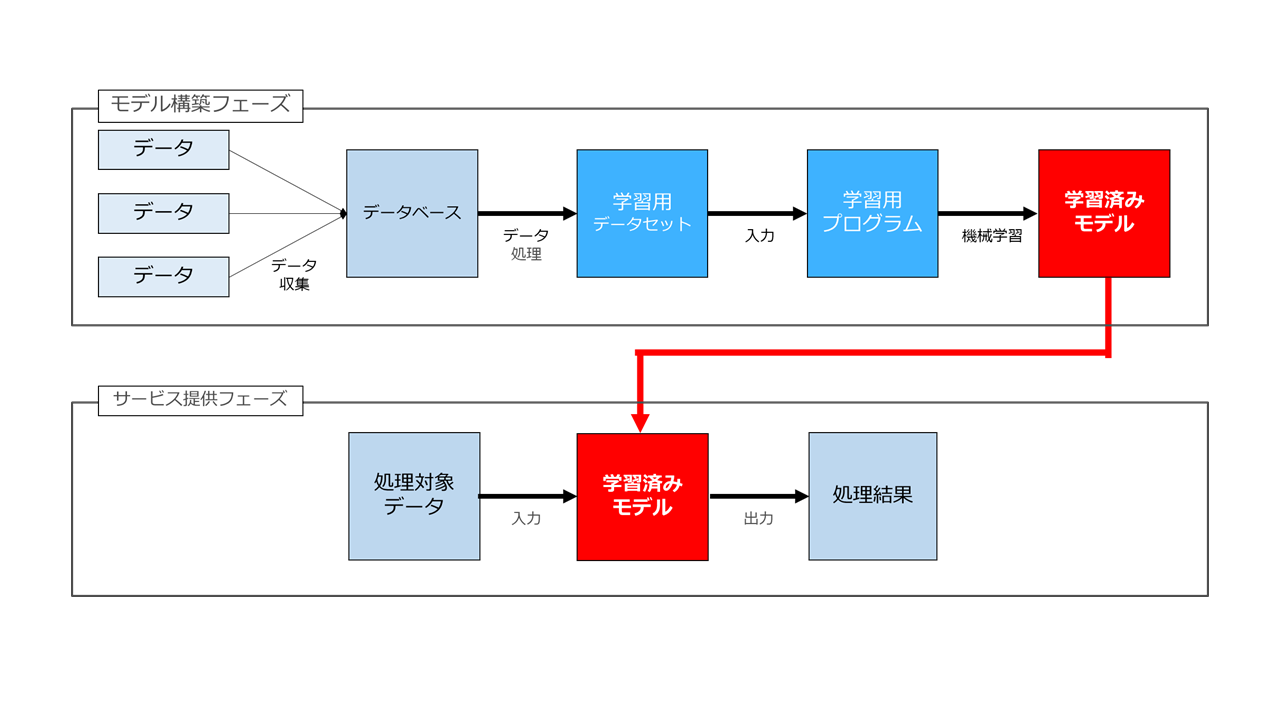
このうち、モデル構築フェーズの問題としては、「モデルの学習のためにどのように適法にデータやデータセットを収集するか」「BERT等のOSSのライセンスの解釈の仕方」「学習済みモデルの知財の帰属」等が問題となります。特に「モデルの学習のためにどのように適法にデータやデータセットを収集するか」については、自然言語、つまりテキストデータを収集・利用するため、まず著作権の適法な処理が問題となりますし、個人情報が含まれたテキストデータであれば個人情報保護法等の処理も必要となります。
次にモデルを利用したサービス提供フェーズに関する問題としては、大きく分けて2つあります。
1つは、サービスの内容によっては、事業者が著作権侵害の責任を問われることがあるため、「事業者がどのような点に注意してサービス設計をすべきか」の問題です。
もう1つは、「自然言語系AIサービスにおいて出力されたデータについてどのような権利が発生し、当該出力データを誰がどのような形で利用できるか」の問題です。この問題は、当該出力データが著作物なのか、著作物だとして入力データと同一性・類似性を有するかによって結論が分かれます。
今回の記事はこのうち、「事業者がどのような点に注意してサービス設計をすべきか」、いいかえれば「どのような場合に自然言語系AIサービスの提供事業者が著作権侵害の責任を問われるのか」についてのものです。他の論点については別の機会に記事にしたいと思います。
第2 自然言語系AIサービス提供の際の注意点
先ほど述べたように、自然言語系AIサービスについてはその内容によっては、事業者が著作権侵害の責任を問われることがあるため、事業者がどのような点に注意してサービス設計をすべきかが問題となります。
この手のサービスは「入力→処理→出力」のプロセスを経るため、それに沿って検討します。またAIサービスにおいては入力されたデータを処理するだけでなく、学習用データとして利用することもありますので、当該「学習」行為の適法性についても検討をする必要があります。
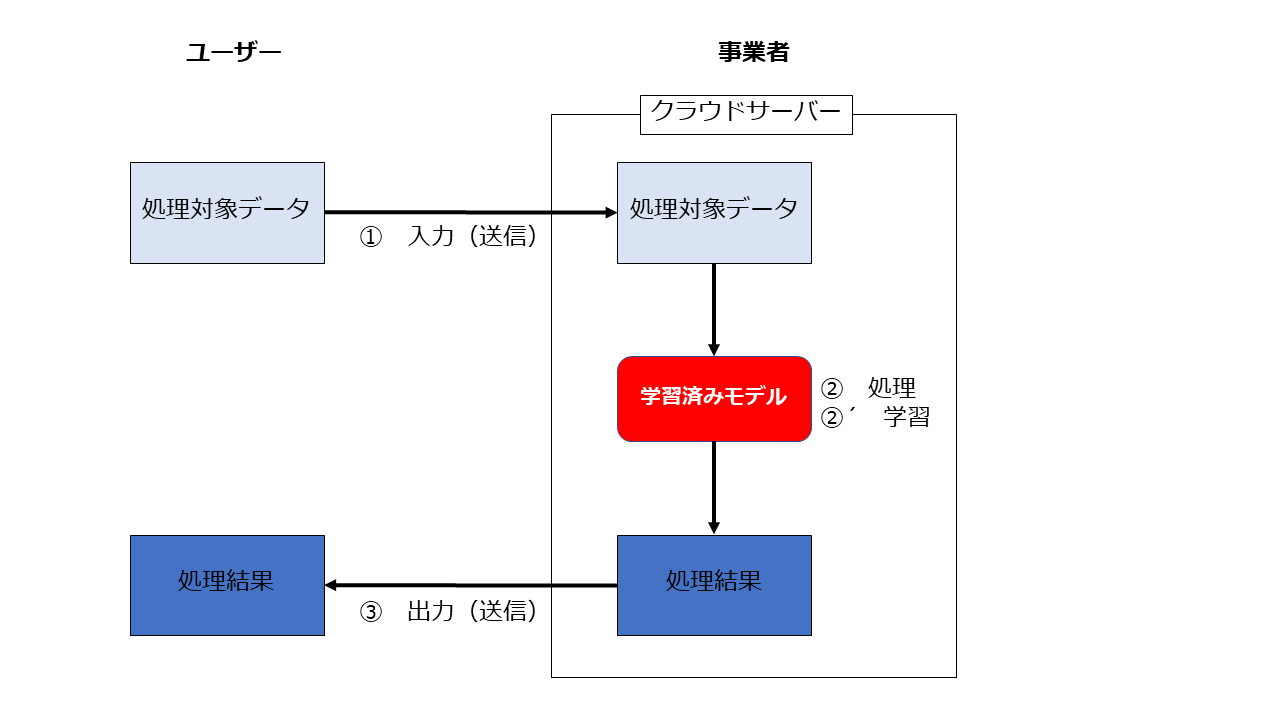
1 「処理」「学習」については著作権侵害にはならない
後に詳細に説明しますが、自然言語系AIサービスにおいて著作権侵害が問題となる典型的な場面は、ユーザーが著作権を侵害するデータ、つまりユーザーが著作権を有していない著作物を入力したときです。
しかし、この「入力→処理→出力」のプロセスのうち「処理」「学習」については、AIモデルを利用した処理やAIモデルの学習行為である限りにおいては、仮に無許諾の著作物が入力されたとしても、著作権侵害は問題となりません。
と言いますのは、著作権法30条の4第2号・3号において以下のとおり一定の場合は著作権者の承諾なく著作物を利用することができると定められており、AIモデルを利用した情報処理やAIモデルの学習行為には、この条文が適用されるためです。
すなわち、AIモデルを利用した情報処理についてはバックエンドで人が全く対象データを知覚することなく行われているため、「著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(に供する)行為」(3号)に該当しますし、AIモデルの学習行為は、「情報解析」(2号)に該当します。
そして、「AIモデルによる処理対象として著作物を利用する」や「AIモデルの学習のために著作物を利用する」ことはいずれも2号3号所定の行為のために「必要と認められる」利用行為であるため、著作権者の承諾なく行うことができるのです。
(著作物に表現された思想又は感情の享受を目的としない利用)
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 略
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
したがって、著作権侵害になるかを検討する必要があるのは、専ら「入力」の部分と「出力」の部分ということになります。また、後に述べますが、ポイントは「入力」「出力」行為の主体が誰か、具体的には、当該「入力」「出力」行為をユーザーが行っているのか事業者が行っているのか、です。
2 各種場合分け
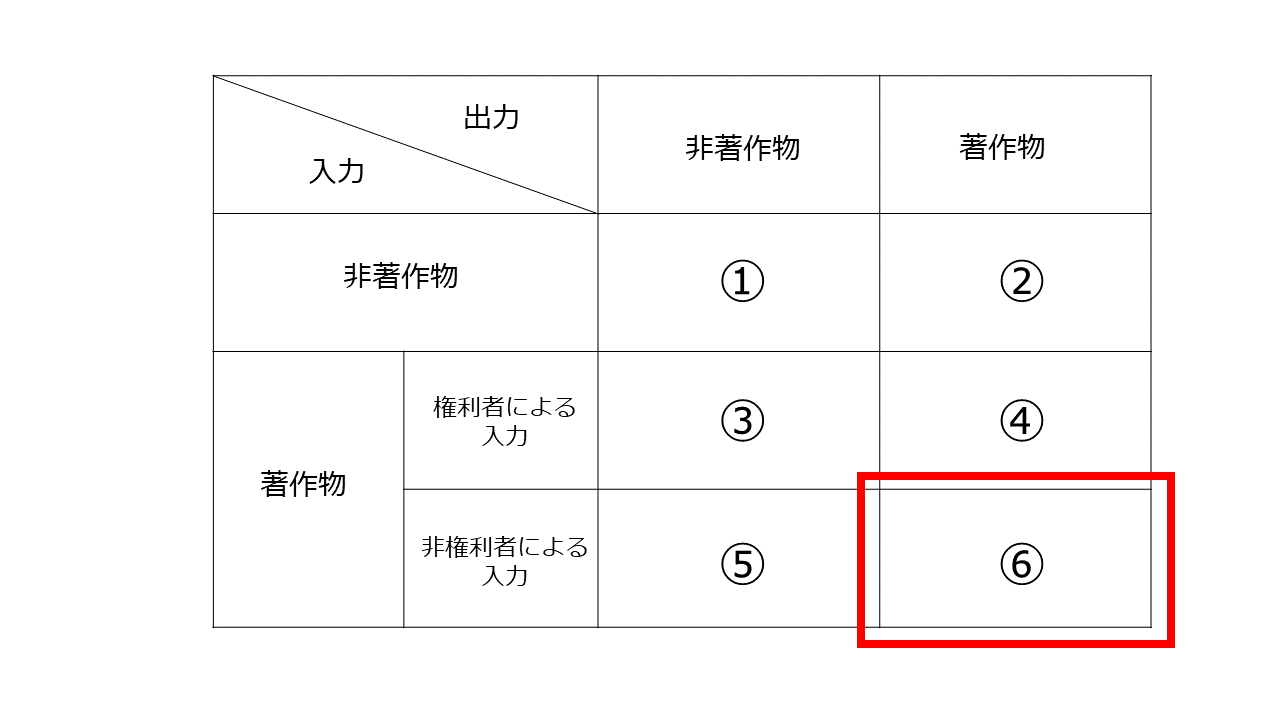
「入力→処理→出力」のプロセスにおいて、どのようなデータが「入力」され、どのようなデータが「出力」されるかの観点で各サービスを分析したのが以下の表です。
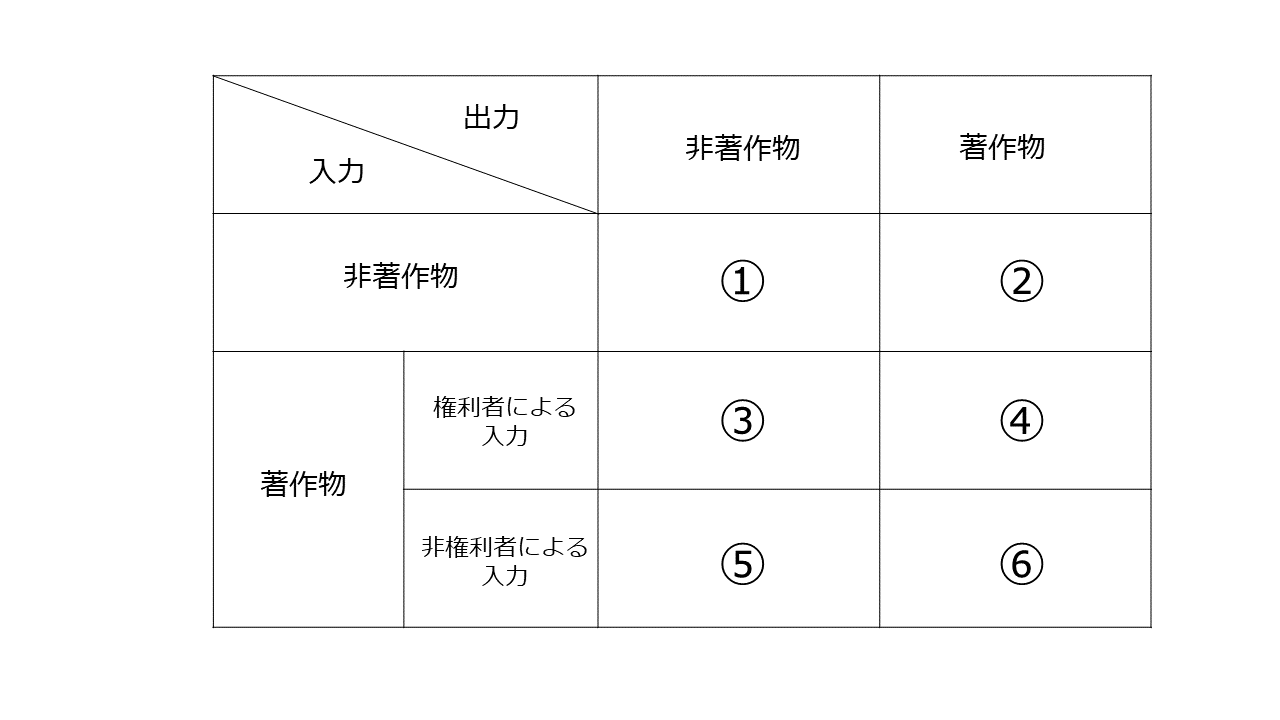
入力されるデータについては「非著作物」か「著作物」か、「著作物」の場合、権利者による入力か非権利者による入力かによって場合分けをし、それと出力データが非著作物か著作物かを組み合わせます。
実務的に最も問題となるのは、「非権利者により著作物が入力され、その処理結果として著作物が出力される場合」(⑥のケース)です。
3 非著作物→非著作物のパターン
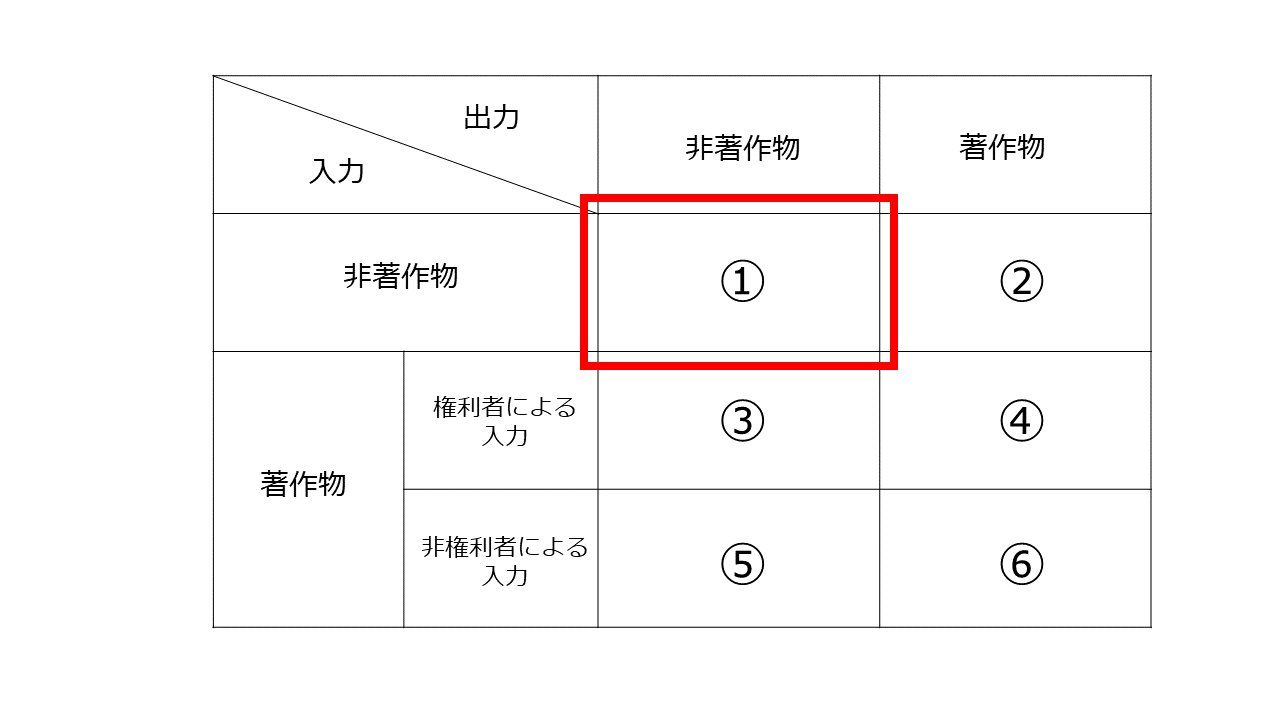
入力については、「非著作物」を入力するケースもありますし、単に「出力指示」しかしない場合も考えられます。
この「非著作物→処理→非著作物」のサービスの例は所在検索サービスです。
所在検索サービスとは、検索対象の語句を入力すると、所在情報を表示するサービスのことで、典型的にはウェブ検索サービスや書籍検索サービスです。それらの検索サービスにおいては、検索対象語句(通常は非著作物)を入力すると、該当サイトのURLや書籍の所在情報(非著作物)が出力されます。
入力、処理、出力共に著作物の利用を伴いませんので、著作権侵害の問題は生じません。
もっとも、このような所在検索サービスにおいては、出力の際に一部著作物が利用(表示)されることが多いです。たとえば、ウェブ検索の結果表示画面には、検索対象ページの一部分であるスニペット(著作物)が表示されていますし、アメリカにおけるGoogleBooksのサービスでは、書籍の一部分(著作物)が表示されています。
このようなケースは、②の「非著作物→著作物」のパターンですが、所在検索サービスの提供に伴う著作物の利用は、それが「軽微」な利用である限り適法とされています(著作権法47条の5)。したがって、これらのスニペット表示や書籍の一部分の利用は適法です(詳細は後述します)。
ちなみに、このようなサービスを提供する際には、サービス提供者が予め大量の著作物を収集してモデルを生成しておく必要がありますが、そのような著作物の利用行為が適法か、の問題は冒頭で紹介した「モデル構築フェーズの問題」です。そして、結論だけ言うと、当該蓄積(複製)行為は適法です(著作権法30条の4第2号、同47条の5第2項)。
4 非著作物→著作物のパターン
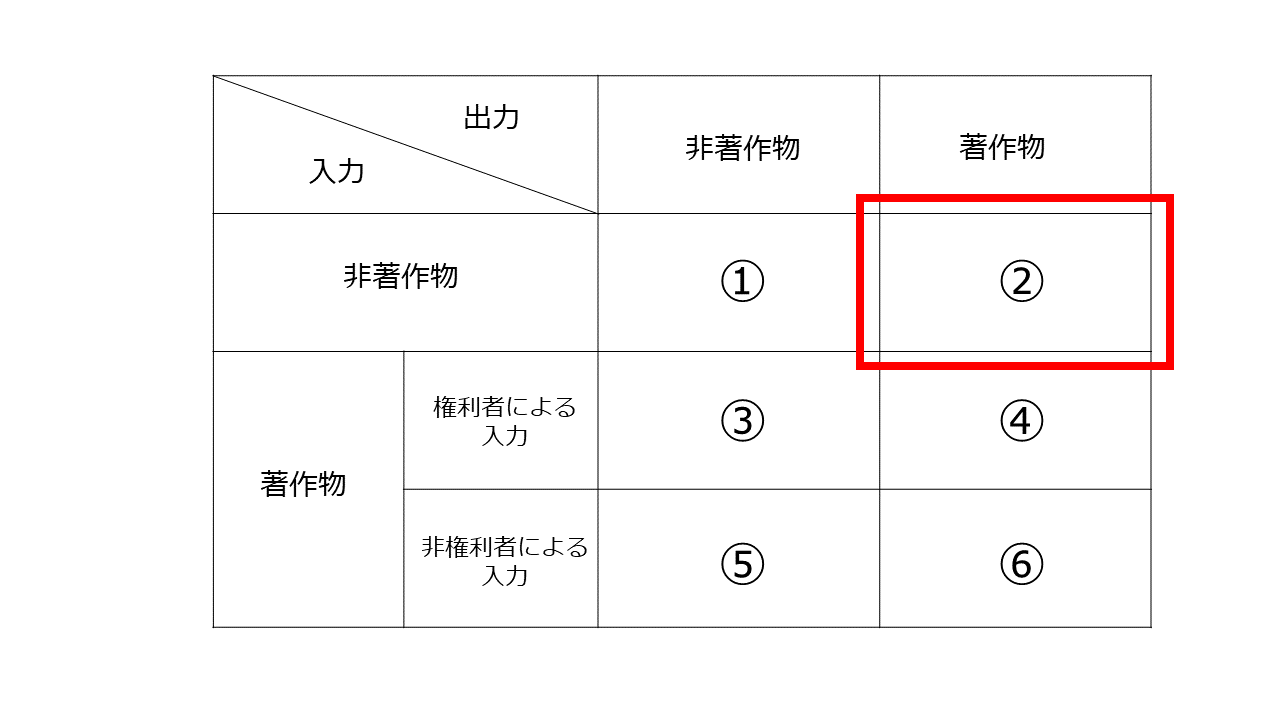
このパターンのサービスは、出力部分については、出力対象となる著作物を事業者が予め蓄積し入力に応じて出力している場合と、処理の都度、当該著作物を自動生成して出力しているかによって結論が分かれます。
(1)出力対象となる著作物を事業者が予め蓄積し、入力に応じて出力している場合
先ほどの所在検索サービスにおいて、検索語を入力すると、所在情報だけでなく、検索対象である著作物がそのまま表示されるようなサービスです。たとえば、論文検索サービスにおいて、予め事業者が論文を蓄積しておいて、ユーザーがある語句を検索語句として入力すると、関連する論文の全文が表示されるようなサービスです。
入力と出力に分けて考えます。
① 入力(送信)
入力行為を行っているのはユーザー自身ですが、入力しているのが非著作物、あるいは単なる出力指示なので著作権侵害の問題は生じません。
② 出力(送信)
出力対象となる著作物を収集・蓄積した上で、ユーザーからの指示に応じて当該著作物の出力行為(ユーザーへの送信行為)を行っているのは事業者ですので、当該著作物の利用主体は事業者です。そして、当該出力行為(ユーザーへの送信行為)は、著作物の公衆送信行為に該当しますので、当該著作物の著作権者の許諾を得なければ、事業者の行為は著作権侵害に該当します。
この点は注意が必要です。
なお、誤解している方がいるのですが、「AIを使った情報処理を行っていれば著作権法30条の4や、同47条の5ですべて適法化される」というわけではありません。
たとえ情報処理(蓄積含む)の段階でAIのような情報解析技術を使っていたとしても、事業者が予め収集・蓄積していた著作物をそのままユーザーに出力(送信)する場合、当該出力(=複製・公衆送信)行為は事業者の行為となり、かつ当該出力行為は「情報解析」等(30条の4)にも該当しません。これは、検索語から適切な出力対象を選択する部分にAI技術が使われていたとしても同様です。
したがって、事業者によるユーザーへの著作物の出力(送信)が無許諾の行為であれば、普通に著作権侵害に該当します。
【軽微利用の場合の例外】
以上のように「非著作物→著作物」のパターンは、著作物の出力行為は事業者の行為であり、当該著作物の出力行為について権利者の許諾を得ていなければ著作権侵害行為となります。
しかし、一定の場合は例外があります。
それが所在検索サービスや情報解析サービスにおいて、その検索結果・解析結果を提供する際の著作物の「軽微利用」です。
軽微利用についての詳細は「平成30年改正著作権法がビジネスに与える「衝撃」を参照していただきたいのですが、簡単に言うと、所在検索サービスや情報解析サービスにおいて、一定の要件を満たしさえすれば、検索結果・解析結果を提供する際に、その結果だけでなく、著作物を「部分的に表示」(軽微利用)できる、という規定です。

先ほど少し触れた、ウェブ検索の結果表示画面には、検索対象ページの一部分であるスニペット(著作物)が表示されていますし、アメリカにおけるGoogleBooksのサービスでは、書籍の一部分(著作物)が表示されていますが、これはこの「軽微利用」として適法になっています。
最近のサービスで言うと、法律書の検索サービスであるLION BOLTですかね。
【参考】
【国内初】100万ページ以上の法律書を全文検索!著作権法47条の5に基づいた「法律書検索サービス」をLION BOLTで公開
このサービスは、法律書の検索サービスですが、キーワードを入力すると、検索結果に付随してキーワードが本文に記載された箇所の一部(切り抜き)も表示されるサービスです。もちろん、検索対象の法律書全文を表示することは出来ませんが、キーワードの周辺が表示されるだけでも検索効率はかなり上がると思いますので、「探す」ということに特化した面白いサービスだと思います。
また、このサービスは「電子化してない重要文献も検索の対象に」という点をセールスポイントとしていますが、「平成30年改正著作権法がビジネスに与える「衝撃」に書いたように、47条の5は、ウェブサイト上の著作物だけではなく紙(リアルワールド)の著作物も対象とすることができますので、このようなことができるのです。
(2) 処理の都度著作物を自動生成している場合
たとえば、GPT-3のように一部の文章(非著作物)を入力すると、その後の文章を自動生成してくれるようなサービスがこれに該当します。
① 入力
入力しているのが非著作物ですので著作権侵害の問題は生じません。
② 出力
自動生成された出力が、「偶然」既存の著作物に類似した場合に著作権侵害の問題が生じることになります。
著作権侵害が成立するためには、元に著作物に「依拠」していることが必要です。先ほどの「出力対象となる著作物を事業者が予め蓄積し、入力に応じてそのまま出力している場合」は明らかに「依拠性」がありますが、「処理の都度、著作物を自動生成している場合」にもこの「依拠性」があるかどうかが問題となります。
いわゆるアナゴさん問題(私しかこの命名使っていませんが)です。
【参考】
AIが偶然に「穴子さん」を生み出した場合、サザエさんの著作権者に怒られるのか?(キャラクター生成AIと著作権問題)
詳しくはこの記事を見ていただきたいのですが、モデル構築の際に用いられた元データに出力データと同じデータが入っていなければ、出力データは完全に「偶然」作成された著作物であり、「依拠性」がないことになります。
難しいのは、モデル構築の際に用いられた元データに出力データと同じデータが用いられている場合です。この場合は、形式的には元データは利用されていることにはなります。もっとも、元データがそのままモデル内に保持されているわけではなく、パラメータ化されている訳ですから、「偶然」といえば偶然のようにも思えます。この場合に依拠性が認められ、著作権侵害になるかについては様々な学説があり1たとえば、横山久芳「AIに関する著作権法・特許法上の問題」(法律時報91巻53~54頁)は、「依拠」とは、既存の著作物が被疑侵害作品に現に利用されていることをいう」とした上で、AIの学習対象著作物がパラメータに抽象化・断片化されても、「これら一群のパラメータは、AIプログラムの処理方法を規定し、AIプログラムが創作する生成物の内容に直接影響を及ぼすものであるから、プログラムの一部とみるべきであり、単なるアイデアと捉えることは適当でないであろう」とし「元の著作物が、一群のパラメータの生成に寄与し、かつ、その一群のパラメータに基づいて生成物が制作されている場合には、表現形式が変換されているとはいえ、元の著作物を利用してAI生成物が制作されたといえるから、依拠を肯定すべきである」とする。そして、「特定の画家の作品のみをAIに学習させ、当該画家の画風を再現する作品を制作するAIを開発したところ、出力された生成物が学習に使用された作品と類似していたという場合にも、依拠を推認することが許されよう」とする。一方、奥邨弘司「技術革新と著作権法性のメビウスの輪」(コピライト№702/Vol59・10頁)は、「AIの中に原告作品が創作的表現の形で保持されていて、それが出力されたということが証明されるならば、複製の対象物が原告の著作物であると機械的・断定的に言えますので、複製権侵害となるのではないかと思います。」とし、さらに「一方で、原告作品が、特徴量など、創作的表現とは呼べない形(=アイデア)に還元され、それに基づいて作成された場合は、原告の著作物が複製対象物だったとは言えないでしょう。」とする。
まず、横山説はパラメータについて「プログラムの一部とみるべきであり、単なるアイデアと捉えることは適当でないであろう」とするが、仮にパラメータがプログラムの動作を規定しているとしてプログラムの一部とみられるとしても、AIプログラムによるAI生成物の生成は、確率的に行われるのであって、同一の生成指示によっても必ず同一のAI生成物が生成されるわけではない。そこには必ず一定程度の「ばらつき」がある。また、横山説にいう「表現形式の変換」とは、「元の著作物→パラメータ→AI生成物」の過程のことを指していると思われるが、元の著作物とパラメータは全く表現形式が異なる。著作権における「依拠性」とは「① 他人の著作物に接し、②それを自己の作品の中に用いること」を指すが、「表現形式の変換」がありつつも依拠性が肯定されるためには、依拠性の要件のうち「② それ(注:原作品)を自己の作品に用いること」、すなわち当該変換の過程において、原作品の創作的表現が維持されていることが必要と考える。そのような観点から奥邨説に賛成する。
、まだ結論が出ていません。
5 権利者等による著作物の入力→非著作物
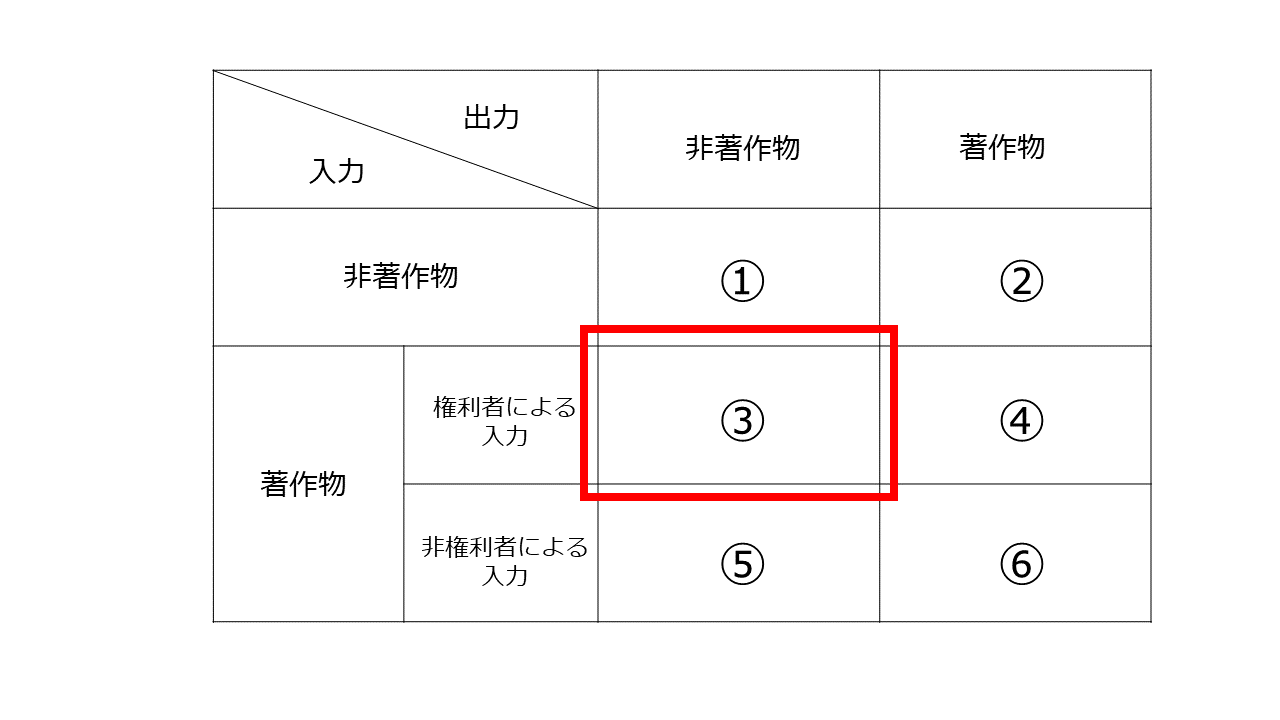
権利者又は権利者から許諾を受けた者が著作物を入力すると非著作物が出力されるパターンです。たとえば「ある文章を入力すると、その文章の『村上春樹度』を測定して点数を出力してくれる」サービスにおいて、ユーザーが自分が作成した文書を入力した場合などが考えられます。
入力・出力共に著作権侵害の問題は起こりません。
6 権利者等による著作物の入力→著作物
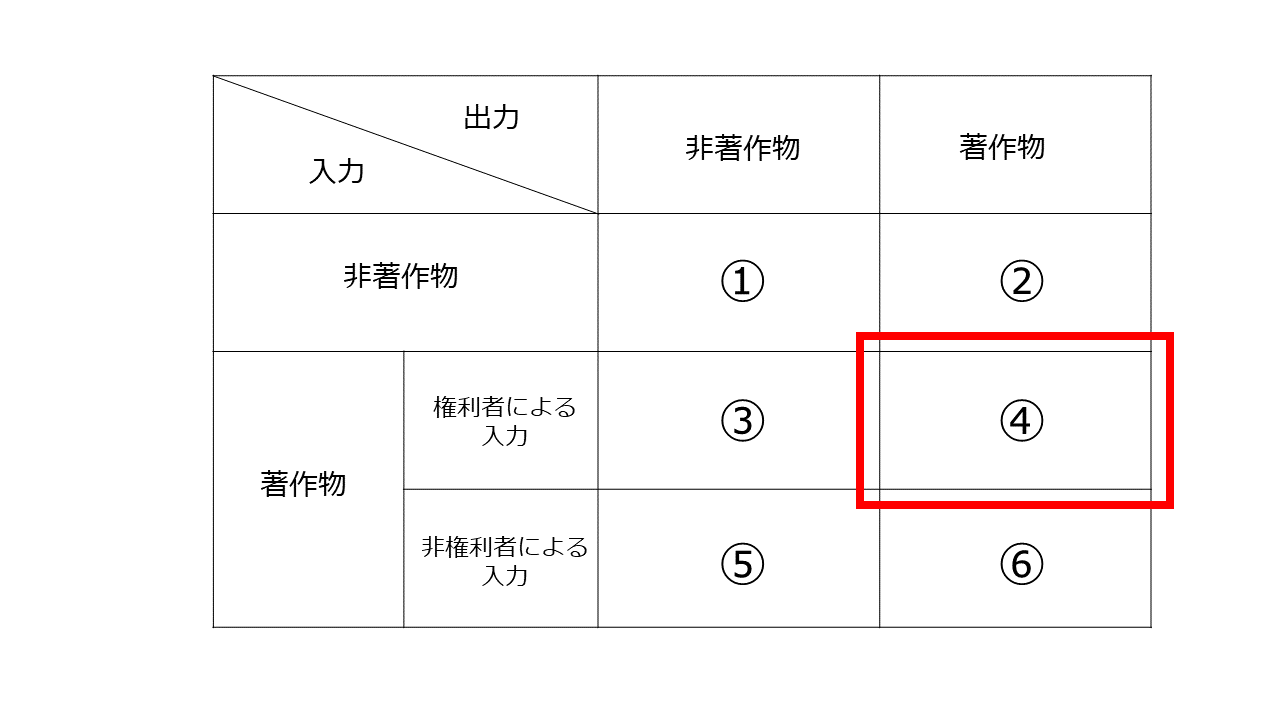
このサービスは、入力された著作物と出力された著作物の関係が問題となります。
(1) 出力された著作物が入力された著作物の翻案の場合
たとえば翻訳や要約サービスで、ユーザーが自ら作成した文書を入力した場合などが考えられます。
このパターンですと、入力も適法ですし、入力が適法である以上、入力の翻案である出力も適法であることになります。
(2) 出力された著作物が入力された著作物の翻案ではない、別の著作物の場合
たとえば、「ある文章を入力すると、その文章の『村上春樹度』を測定して点数を出力してくれる」サービスをちょっと変えて「ある文章を入力すると、その文章の『村上春樹度』を測定して点数を出力すると共に、類似している村上春樹の文章を、村上春樹の著作から探し出して表示してくれる」サービスです。
この場合は、②と同様「出力対象となる著作物を事業者が予め蓄積し、入力に応じて出力している場合」に該当し、出力行為について著作権者の許諾がなければ著作権侵害になります。
7 非権利者による著作物の入力→非著作物
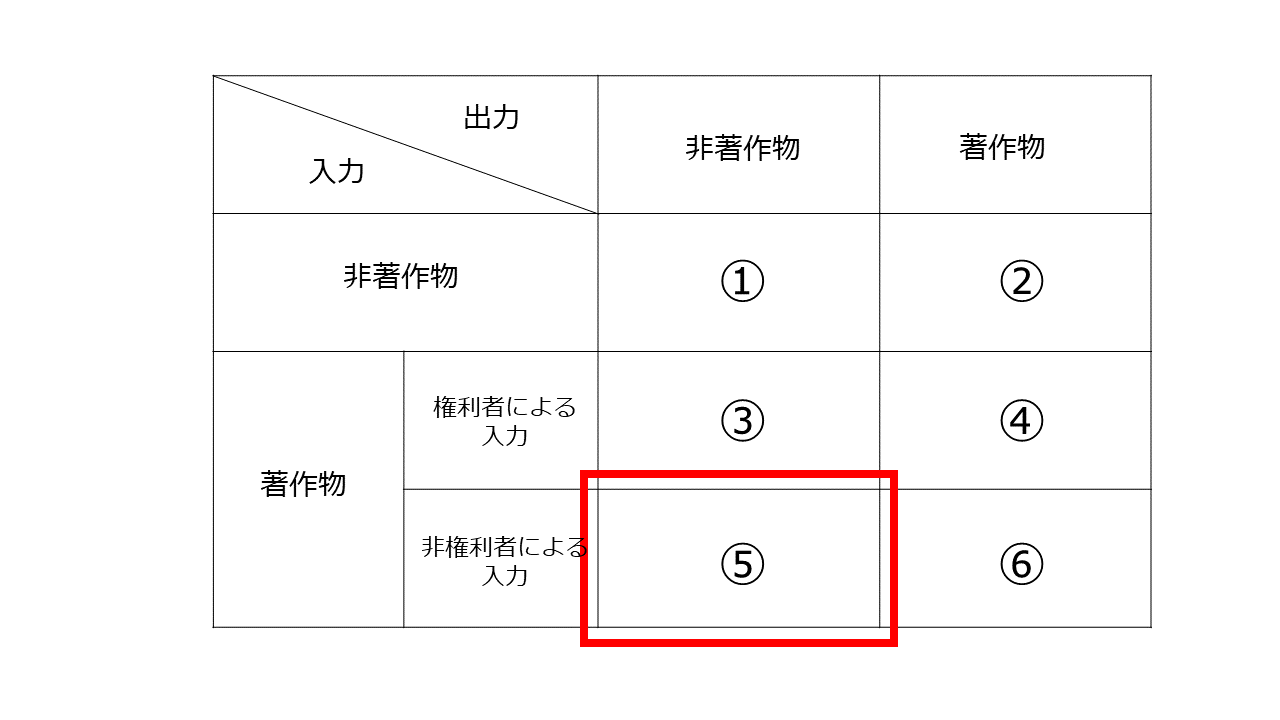
たとえば、③の「ある文章を入力すると、AIによる処理を行ってその文章の『村上春樹度』を測定して点数を出力してくれる」サービスにおいて、ユーザーが、他人が作成した文書を入力した場合などが考えられます。
また、論文要約サービスにおいて、他人の論文を入力すると、AIモデルを用いて当該論文のポイントを抽出してくれるサービス(ただし元の論文を部分的にでも利用していたらNG)なども考えられます。
① 入力
ユーザーによる無権限での著作物の入力行為の評価が問題となりますが、著作権法上の利用行為としては「複製」行為をしていることになります。問題は当該「複製」行為を行っているのが誰か(ユーザーか事業者か)ですが、結論的には当該「複製」行為はユーザーが実施主体であり、したがってユーザーが個人である場合は、当該複製行為は私的利用目的の複製(30条1項)に該当し適法であると思われます(詳細は後述します)。
ただ、このパターンの場合は出力が非著作物であるため、利用主体をいずれと考えたとしても著作物の非享受利用ということで30条の4第3号、同条柱書が適用され適法と考えられます(なお、47条の5と異なり30条の4については著作物の利用主体が限定されていません)。
② 出力
非著作物の出力なので、著作物の利用が行われておらず、問題ありません。
8 非権利者による著作物の入力→著作物
これが実務的には最もシビアな問題だろうと思われます。
たとえば、翻訳や要約サービスにおいて、ユーザーが、他人が作成した文書を当該他人(=著作権者)の同意なく入力し、その翻訳や要約文が出力された場合が考えられます。
これも出力された著作物が入力された著作物の翻案かどうかで分けて考える必要があります。
(1)出力された著作物が入力された著作物の翻案の場合
たとえば、AI翻訳や要約サービスにおいて、ユーザーが、ネット上で公開されている他人が作成した文書を当該他人(=著作権者)の同意なく入力し、その翻案物(翻訳文や要約文)が出力される場合が考えられます。
① 入力(複製行為)
クラウドを利用した自然言語処理AIサービスにおける、ユーザーによる無許諾著作物の入力行為が著作権侵害になるかについては、実はデータ処理においてAI技術を利用しているか否かとは無関係でして、以下の点がポイントとなります。
▼ 入力主体(著作物の利用主体)は誰か
▼ 当該行為に著作権法30条1項が適用されるか
▼ 処理に用いられるクラウドサーバが「公衆用設置自動複製機器(第30条第1項第1号)」に該当しないか
▼ 入力主体(著作物の複製主体)は誰か
ユーザーによるサービスへの著作物の入力行為は、法的には著作物の「複製」行為に該当しますが、この「複製」行為を、ユーザーが行っているのか事業者が行っているのかが問題となります。仮にユーザーが行っているということになれば、著作権法30条1項が適用され適法になる余地はありますが、事業者が行っているということになれば著作権法30条1項が適用されることはなく、他の権利制限規定に該当しない限り著作権侵害となります。
実は、この点は自然言語処理AIサービスに限った問題ではなく、「著作権侵害の主体」という著作権法上の難問として、特にクラウドサービスとして、利用者による私的使用目的の複製行為(著作権法30条第1項)を自動的にサポートするようなサービスにおいて問題となります。
この様なサービスとして、これまで裁判で問題となった有名なケースとしては「MYUTA事件(東京地判平成19・5・25 判時1979 号100 頁)」、「まねきTV事件(最判平成 23・1・18 民集65 巻1 号121 頁)」「ロクラクⅡ事件(最判平成 23・1・20 民集65 巻1 号399 頁)」などがありますし、「クラウドサービスと著作権」という文脈で、平成27年2月に「文化審議会著作権分科会著作物等の適切な保護と利用・流通に関する小委員会」により公表された「クラウドサービス等と著作権に関する報告書」(以下「平成27年報告書」といいます)においても当該論点が検討されています2「クラウドサービスと著作権」という論点については、平成25年6月から第13期文化審議会著作権分科会法制・基本問題小委員会で議論がスタートし、その後約1年半もの間、年度や会議をまたいで非常に濃ゆい議論が事業者・権利者・有識者の中で延々繰り広げられ(会議の回数は1年半で14回、最後の方はほぼ1ヶ月に2回)ています。
ちなみに、平成27年報告書が出来るまでの委員会内での議論はすべて議事録が公開されているのですが(リンクは「参考文献」参照)まあ、極めて激しい議論がされています。インテリな大人ってどうやって口ゲンカ、じゃなかった議論をするんだろうということに興味がある方は是非議事録を見てみてください。
。
【参考リンク】
クラウドサービス等と著作権に関する報告書(平成27年2月、文化審議会著作権分科会・著作物等の適切な保護と利用・流通に関する小委員会)
そして、この点に関する結論だけ述べますと、上記裁判例に対する判例評釈や、各種文献3柴田義明「知的財産訴訟実務体系Ⅲ・著作権侵害の主体」(青林書院、2014年)154頁、中山信弘「著作権法(第3版)」(有斐閣、2020年)730頁等。また侵害主体の議論については「文化審議会著作権分科会著作物等の適切な保護と利用・流通に関する小委員会 (第4回)の大渕委員によるジュークボックス法理の説明が非常にわかりやすいです。 、上記報告書、上記報告書完成に至るまでの小委員会における議論を参照すると、入力・処理・処理までの一連の過程が自動化されたクラウドサービスにおいて、ユーザー自身が著作物の入力行為を行っている場合は、当該著作物の複製主体は事業者ではなくユーザーと捉えることが合理的だと考えます4もっとも、この結論は、クラウドサービスとして入力・処理・出力が自動的に行われることを前提としており、複製等の作業のうち、一部を事業者内の人間が行うサービスの場合は異なる結論となります。自炊代行業者事件判決[知財高判平成 26 年 10 月 22 日最高裁判所ホームページ]などを前提とすると、いわゆる「自炊代行サービス」(ユーザーが書籍を事業者に郵送して事業者がそれを電子化し、電子化したファイルをユーザーに送信する)や、メディア変換サービス(ユーザーが自宅で保管しているビデオテープやレコード等を,事業者が提出を受け,DVD やブルーレイ等別のメディアに変換して返却するサービス)、「プリントサービス」(画像を指定して注文すると,指定画像をプリントした商品が自宅に届くサービス)などは、いずれも利用(複製)主体は事業者であると解されます(平成27年報告書P29~30)。
この考えは、ユーザーは、クラウドサーバを用いて自ら複製をする一方で、事業者はそのための幇助行為をしているに過ぎないと整理するものです。
▼ 当該行為に著作権法30条1項が適用されるか
このように、著作物の入力(複製)主体をユーザーであると考えると、次にユーザーによる入力(複製)行為が著作権法30条1項の要件、特に「個人的に又は家庭内その他これに準ずる限られた範囲内」の要件を満たすかが問題となります。
この点については、確かにユーザーは家庭内にあるPCを利用しているわけではなく、事業者が提供しているクラウド上のサーバ上に設置されたAIモデルに対する入力行為を行っています。この点を捉えて「個人的に又は家庭内その他これに準ずる限られた範囲内」に該当しないのではないかという考え方もあるかと思いますが、第30条第1項本文の趣旨は,利用者自身以外の者が主体的に関与することを否定するものであり,外部の者が関与したからといって直ちに第30条第1項本文該当性は否定されるものではないと思われますので、この要件を満たすと考えます5平成27年報告書P14 。
▼ 処理に用いられるクラウドサーバが「公衆用設置自動複製機器(第30条第1項第1号)」に該当しないか
仮に利用主体がユーザーであり、かつ30条1項の要件を満たすとしても、処理に用いられるクラウドサーバが「公衆用設置自動複製機器(第30条第1項第1号)」に該当すると、権利制限規定の例外となってしまいます。
この点については、公衆用設置自動複製機器を用いた私的使用目的の複製を権利制限の対象としないこととした趣旨は,立法当時,高速ダビング機器等が,業者がコピーする代わりに利用者にさせるという一種の法律回避のために利用されていたためとされています。したがってそもそも立法当時は「公衆用設置自動複製機器」としてクラウド上のサーバは想定されていなかったことから、該当しないというするのが妥当だと考えます6平成27年報告書P15 。
② 出力行為
ユーザーにより入力された著作物について、サービス提供者がサーバ上で自動的に処理を行い、入力された著作物の翻案物をユーザーに提供(出力)していることになります。
この出力行為がユーザーの行為なのか事業者の行為なのかが、入力行為と同様問題となります。仮に事業者の行為だとすると、事業者が公衆送信行為を行っていると解釈される可能性があるからです。
この点については、平成27年報告書P15脚注23において「なお,当該サービスにおいて行われる送信行為についても,権利者の許諾の要否が問題となるが,利用行為主体が利用者と解される場合には,当該サービスにおいて行われる送信は,利用者が自らに対して送信を行っているものと解されるため,著作権法上の公衆送信(第2条第1項第7号の2)には該当しない。したがって,当該送信についても権利者の許諾を得ることは不要と解される。」とされています。
この脚注における「当該サービス」とは、ロッカー型クラウドサービス7クラウド上のサーバ(「ロッカー」)に保存されるコンテンツを,利用者が自らの様々な携帯端末等において利用(ダウンロード又はストリーミング)できるようにするサービスのうちのタイプ28ロッカーに保存されるコンテンツはユーザーが用意し、当該ユーザーしか当該コンテンツを利用できないタイプのことですが、「入力行為をユーザーが行っている場合において、処理結果の出力行為の利用行為主体をどう考えるか」という点においては本件と同様であり、この脚注に記載されている内容は、自然言語処理AIサービスの出力行為についてもそのまま当てはまると考えます。
したがって、出力行為はユーザーが行っていることになり、公衆送信に該当せず著作権侵害は構成しないことになります。
なお、入力・出力共にユーザーが行為主体だという立場に立つと、入力された著作物の要約や翻訳という翻案行為をユーザー自身が行っていることになりますが、この点については著作権法47条の6第1項第1号、同30条1項により適法となります。
(2) 出力された著作物が入力された著作物の翻案ではない、別の著作物である場合
たとえば、「ある文章を入力すると、その文章の『村上春樹度』を測定して点数を出力してくれる」サービスをちょっと変えて「ある文章を入力すると、その文章の『村上春樹度』を測定して点数を出力すると共に、類似している村上春樹の文章を、村上春樹の著作から探し出して表示してくれる」サービスにおいて、他人が書いた文章を入力する場合です。
この場合は、②と同様「出力対象となる著作物を事業者が予め蓄積し、入力に応じて出力している場合」に該当し、出力行為について著作権者の許諾がなければ著作権侵害になります。
第3 まとめ
以上、自然言語系AIサービスを事業者が提供する際に注意すべき事項についてまとめました。
入力・処理・出力の各段階に応じて検討したので、場合分けが多くなってしまいましたが、ほぼ全ての自然言語系サービスのパターンは網羅しているのではないかと思います。またタイトルは「自然言語系AIサービスと著作権」としていますが、著作物を扱うAIサービス、たとえば音楽・画像・映像を扱うAIサービスも同様のフレームワークで検討すれば良いと思います。
検討し始めてから「著作権侵害の主体」という難問にぶちあたり、平成27年報告書に至るまでの全委員会の議論の議事録に全て目を通すなど、かなり時間がかかりました。。。。(でも、この議事録、読んでて「もっとやれ」という気分にはなっても決して退屈しないことはお約束します。)
ご参考になれば幸いです!
第4 参考文献
▼ クラウドサービス等と著作権に関する報告書(平成27年2月、文化審議会著作権分科会・著作物等の適切な保護と利用・流通に関する小委員会)
▼ クラウドコンピューティングと著作権に関する調査研究報告書(平成23年11月、文化庁委託事業)
▼ 議事録・各種資料
(1)平成25年度文化審議会著作権分科会法制・基本問題小委員会(第1回~第3回)
(2)平成25年度文化審議会著作権分科会法制・基本問題小委員会著作物等の適切な保護と利用・流通に関するワーキングチーム(第1回及び第2回)
(3)平成26年度文化審議会著作権分科会著作物等の適切な保護と利用・流通に関する小委員会(第1回~第9回)
- 1たとえば、横山久芳「AIに関する著作権法・特許法上の問題」(法律時報91巻53~54頁)は、「依拠」とは、既存の著作物が被疑侵害作品に現に利用されていることをいう」とした上で、AIの学習対象著作物がパラメータに抽象化・断片化されても、「これら一群のパラメータは、AIプログラムの処理方法を規定し、AIプログラムが創作する生成物の内容に直接影響を及ぼすものであるから、プログラムの一部とみるべきであり、単なるアイデアと捉えることは適当でないであろう」とし「元の著作物が、一群のパラメータの生成に寄与し、かつ、その一群のパラメータに基づいて生成物が制作されている場合には、表現形式が変換されているとはいえ、元の著作物を利用してAI生成物が制作されたといえるから、依拠を肯定すべきである」とする。そして、「特定の画家の作品のみをAIに学習させ、当該画家の画風を再現する作品を制作するAIを開発したところ、出力された生成物が学習に使用された作品と類似していたという場合にも、依拠を推認することが許されよう」とする。一方、奥邨弘司「技術革新と著作権法性のメビウスの輪」(コピライト№702/Vol59・10頁)は、「AIの中に原告作品が創作的表現の形で保持されていて、それが出力されたということが証明されるならば、複製の対象物が原告の著作物であると機械的・断定的に言えますので、複製権侵害となるのではないかと思います。」とし、さらに「一方で、原告作品が、特徴量など、創作的表現とは呼べない形(=アイデア)に還元され、それに基づいて作成された場合は、原告の著作物が複製対象物だったとは言えないでしょう。」とする。
まず、横山説はパラメータについて「プログラムの一部とみるべきであり、単なるアイデアと捉えることは適当でないであろう」とするが、仮にパラメータがプログラムの動作を規定しているとしてプログラムの一部とみられるとしても、AIプログラムによるAI生成物の生成は、確率的に行われるのであって、同一の生成指示によっても必ず同一のAI生成物が生成されるわけではない。そこには必ず一定程度の「ばらつき」がある。また、横山説にいう「表現形式の変換」とは、「元の著作物→パラメータ→AI生成物」の過程のことを指していると思われるが、元の著作物とパラメータは全く表現形式が異なる。著作権における「依拠性」とは「① 他人の著作物に接し、②それを自己の作品の中に用いること」を指すが、「表現形式の変換」がありつつも依拠性が肯定されるためには、依拠性の要件のうち「② それ(注:原作品)を自己の作品に用いること」、すなわち当該変換の過程において、原作品の創作的表現が維持されていることが必要と考える。そのような観点から奥邨説に賛成する。
- 2「クラウドサービスと著作権」という論点については、平成25年6月から第13期文化審議会著作権分科会法制・基本問題小委員会で議論がスタートし、その後約1年半もの間、年度や会議をまたいで非常に濃ゆい議論が事業者・権利者・有識者の中で延々繰り広げられ(会議の回数は1年半で14回、最後の方はほぼ1ヶ月に2回)ています。
ちなみに、平成27年報告書が出来るまでの委員会内での議論はすべて議事録が公開されているのですが(リンクは「参考文献」参照)まあ、極めて激しい議論がされています。インテリな大人ってどうやって口ゲンカ、じゃなかった議論をするんだろうということに興味がある方は是非議事録を見てみてください。
- 3柴田義明「知的財産訴訟実務体系Ⅲ・著作権侵害の主体」(青林書院、2014年)154頁、中山信弘「著作権法(第3版)」(有斐閣、2020年)730頁等。また侵害主体の議論については「文化審議会著作権分科会著作物等の適切な保護と利用・流通に関する小委員会 (第4回)の大渕委員によるジュークボックス法理の説明が非常にわかりやすいです。
- 4もっとも、この結論は、クラウドサービスとして入力・処理・出力が自動的に行われることを前提としており、複製等の作業のうち、一部を事業者内の人間が行うサービスの場合は異なる結論となります。自炊代行業者事件判決[知財高判平成 26 年 10 月 22 日最高裁判所ホームページ]などを前提とすると、いわゆる「自炊代行サービス」(ユーザーが書籍を事業者に郵送して事業者がそれを電子化し、電子化したファイルをユーザーに送信する)や、メディア変換サービス(ユーザーが自宅で保管しているビデオテープやレコード等を,事業者が提出を受け,DVD やブルーレイ等別のメディアに変換して返却するサービス)、「プリントサービス」(画像を指定して注文すると,指定画像をプリントした商品が自宅に届くサービス)などは、いずれも利用(複製)主体は事業者であると解されます(平成27年報告書P29~30)
- 5平成27年報告書P14
- 6平成27年報告書P15
- 7クラウド上のサーバ(「ロッカー」)に保存されるコンテンツを,利用者が自らの様々な携帯端末等において利用(ダウンロード又はストリーミング)できるようにするサービス
- 8ロッカーに保存されるコンテンツはユーザーが用意し、当該ユーザーしか当該コンテンツを利用できないタイプ
・STORIA法律事務所へのお問い合わせはこちらのお問い合わせフォームからお願いします。
・最新情報はTwitterにて随時お届けしております。












