人工知能(AI)、ビッグデータ法務 著作権
【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~第1回

Contents
【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~
本連載は、2024年3月15日に文化審議会著作権分科会法制度小委員会「AIと著作権に関する考え方について」(以下「考え方」」といいます)が公表されたことを受けて、2024年4月時点でのAIと著作権に関する法的論点とその基本的な考え方について網羅的に整理したものです。
本連載の作成にあたっては、「考え方」をベースに、関連する各書籍や論文等を参照し、かつ私自身が実務で経験したことを最大限盛り込んでいます。
特に「上野達弘・奥邨弘司(編)「AIと著作権」勁草書房、2024年」は、2024年時点の最新の論点について、理論的・実務的な観点から極めて詳細な検討がされている書籍であり、本連載作成に際しても大いに参考にしています。
本連載では、網羅的、かつ最新の知見を盛り込みつつも、学説の対立の紹介は最小限にとどめて、できるだけ一般的な結論を記載するようにしています。
もっとも、連載の中での「通説」「一般的」という表現は、あくまで筆者の個人的な見解ですので、そのつもりでお読み下さい。
■ 連載目次
1 AIと著作権法に関する全体像
(1) 分析の視点
(2)「開発・学習」段階と「生成・利用」段階の意味
(3) 誰が、どのような行為に対して、どのような責任を負う可能性があるのか
(4) 開発・学習段階と生成・利用段階を分けて検討する意味
【以上第1回】
2 開発・学習段階
(1)分析の視点
(2)学習目的による制限
【以上第2回】
(3)学習対象による制限
ア はじめに
イ 情報解析に活用できる形で整理したデータベースの著作物
ウ 海賊版等の権利侵害複製物
【以上第3回】
エ 学習禁止意思が付されている著作物
オ 学習を防止するための機械可読方法による技術的な措置が付されている著作物
カ 情報解析用DB著作物以外の著作物のうちライセンス市場が形成されている(すでにライセンス・販売されている)もの
(4)開発・学習段階での著作権侵害行為について権利者はどの範囲で差止請求等ができるか
(5)生成・利用段階における情報解析と30条の4
(6)30条の4と47条の5の役割分担
【以上第4回】
3 生成・利用段階
(1)検討の視点
(2)依拠
【以上第5回】
(3)行為主体性
(4)入力
(5)生成
(6)送信
(7)利用
【以上第6回】
4 結局、著作権者は誰に何を請求できるのか
5 AI開発者・AIサービス提供者・AI利用者は著作権侵害とならないために何をすれば良いのか
6 RAGと著作権侵害についての整理
7 AI生成物の著作物性について
8 日本著作権法の適用範囲
1 AIと著作権法に関する全体像
(1)分析の視点
AIと著作権法に関する論点は多岐にわたりますが、以下の3つの視点で整理をするとわかりやすいのではないかと思います。
① 主体(「AI開発者」「AIサービス提供者」「AI利用者」)
② フェーズ(「開発・学習段階」「生成・利用段階」)
③ システム・サービスの内容(「クラウド」「ローカル」)
AIの開発から利用までを時系列順に並べると、①AIの開発・提供、②開発されたAIを利用したAIサービスの開発・提供、③提供されたAIサービスの利用という順になります。
本記事では、それぞれの行為を行う主体を「AI開発者」「AIサービス提供者」「AI利用者」といいます(①主体)。もちろん同一の者が複数の主体(たとえば「AI開発者」と「AIサービス提供者」)を兼ねることもあります。
そして、それぞれの主体によって「AIの開発・学習」段階の行為と「AI生成物の生成・利用」段階の行為の一方、あるいは双方が行われます(②フェーズ)。
さらに、生成AIシステム・サービスは、AIサービス提供者からAI利用者に対するクラウドサービスとして提供される場合もありますし、AI利用者自身がローカル環境1ここでいう「ローカル」には、AI利用者自身が管理するクラウド環境も含みます。でAI生成物を生成・利用することもあります(③システム・サービスの内容)。
まず、最もシンプルなパターンとして「AI開発者」と「AI利用者」のみが登場し、「AI開発者」は「AIの開発・学習」のみを、「AI利用者」は「AI生成物の生成・利用」のみを行うパターンを図示してみましょう(図1)。
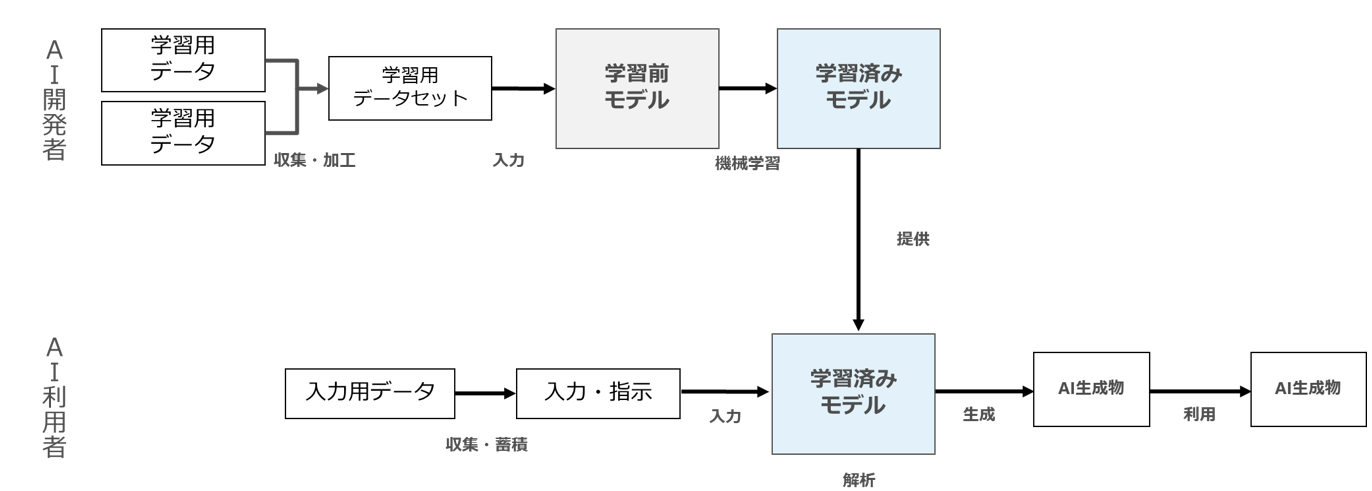
図1
図1は、「AI開発者」が開発したAI(学習済みモデル)を「AI利用者」に提供し、AI利用者が自らの手元で(ローカルで)当該AIを利用して「AI生成物の生成・利用」を行うパターンです。
次に、「AI開発者」と「AI利用者」のみが登場し、「AI開発者」は「AIの開発・学習」を、「AI利用者」が「AIの開発・学習(追加学習)」と「AI生成物の生成・利用」を行うパターンを図示してみます(図2)。
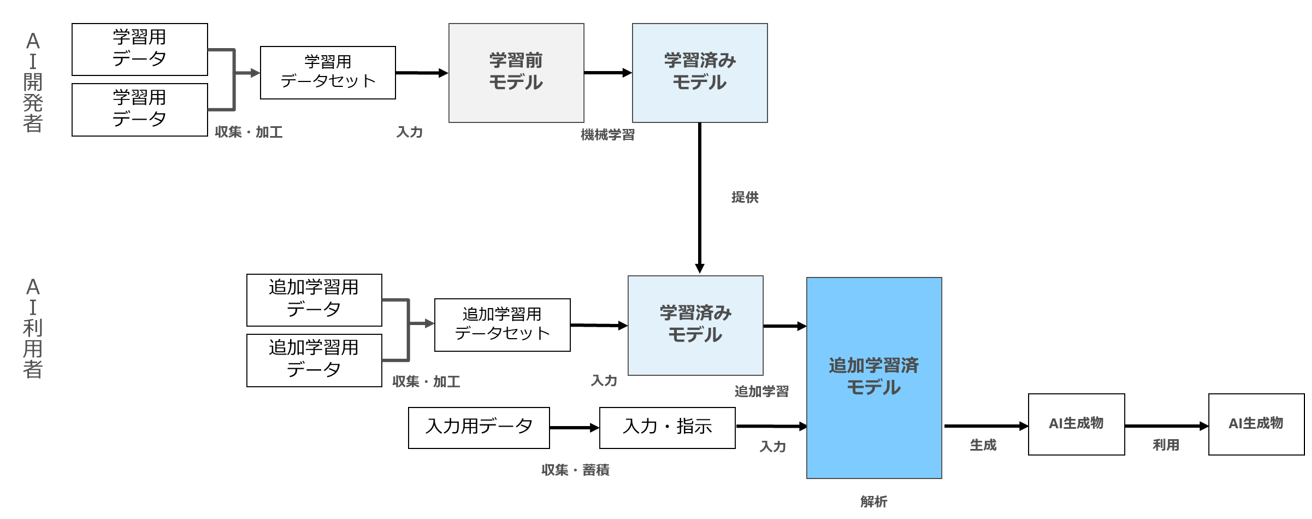
図2
図2は、「AI開発者」が開発したAI(学習済みモデル)を「AI利用者」に提供し、AI利用者が自らの手元で(ローカルで)、自ら収集した少量のデータで追加学習した上で、学習後のAIを利用して「AI生成物の生成・利用」を行うパターンです。
さらに「AI開発者」「AIサービス提供者」が「AIの開発・学習」を、「AI利用者」が「AIの開発・学習」と「AI生成物の生成・利用」をそれぞれ行う場合(いわばフルコース)は以下の図となります(図3)。
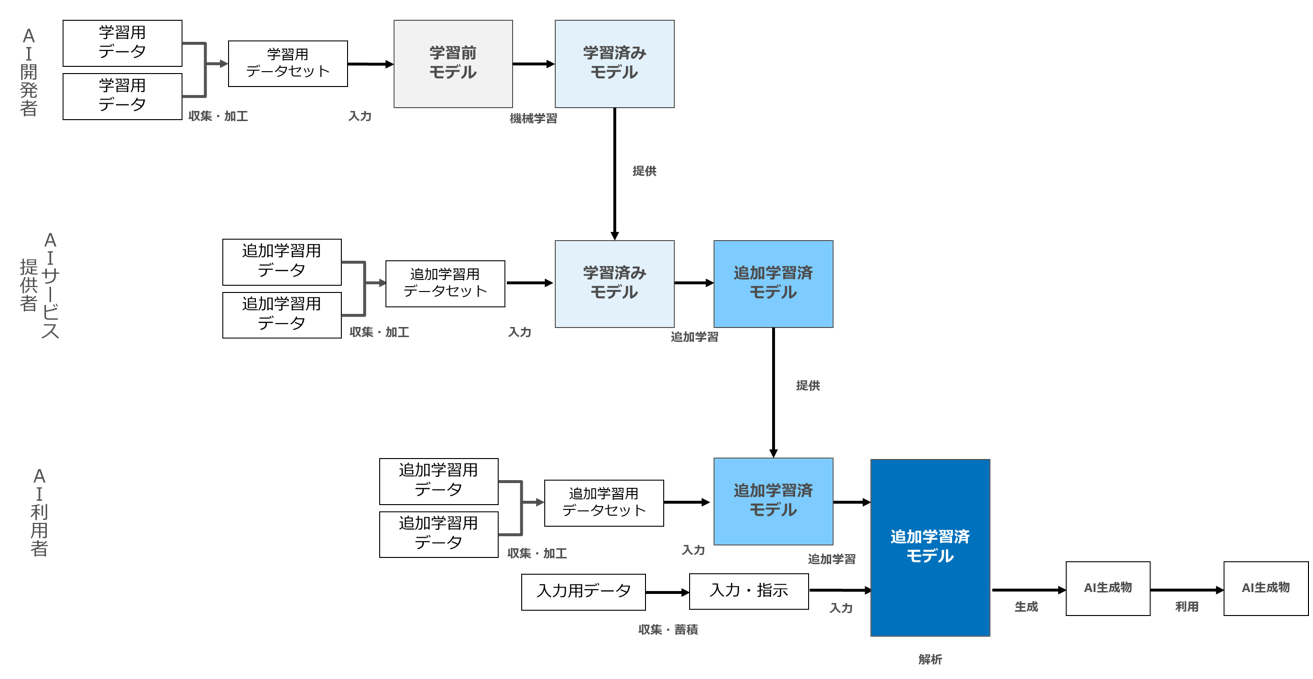
図3
AIと著作権の問題について検討する際には、このように基本的には「主体」×「フェーズ」の組み合わせで分析することになります。
図2や図3のように、フェーズとして「開発・学習段階」や「生成・利用段階」が複数組み合わさることもありますが、基本的に各フェーズにおける著作権侵害の有無の考え方は同一です(ただし、AIサービス提供者やAI利用者における「学習」は少量の学習用データで学習することが多く、その際には後述の学習目的による制限がかかることもあります)。
また、先ほどの図1~3では、「AI開発者」が開発したAIを「AI利用者」に提供し、AI利用者が自らの手元で当該AIを利用して「AI生成物の生成・利用」を行うパターンでしたが、実際には、AIがAI開発者・AIサービス提供者からAI利用者に対して、クラウド上のサービスとして提供されている場合もあります(むしろこのパターンの方が多いかもしれません)。
この場合は以下の図4になります。
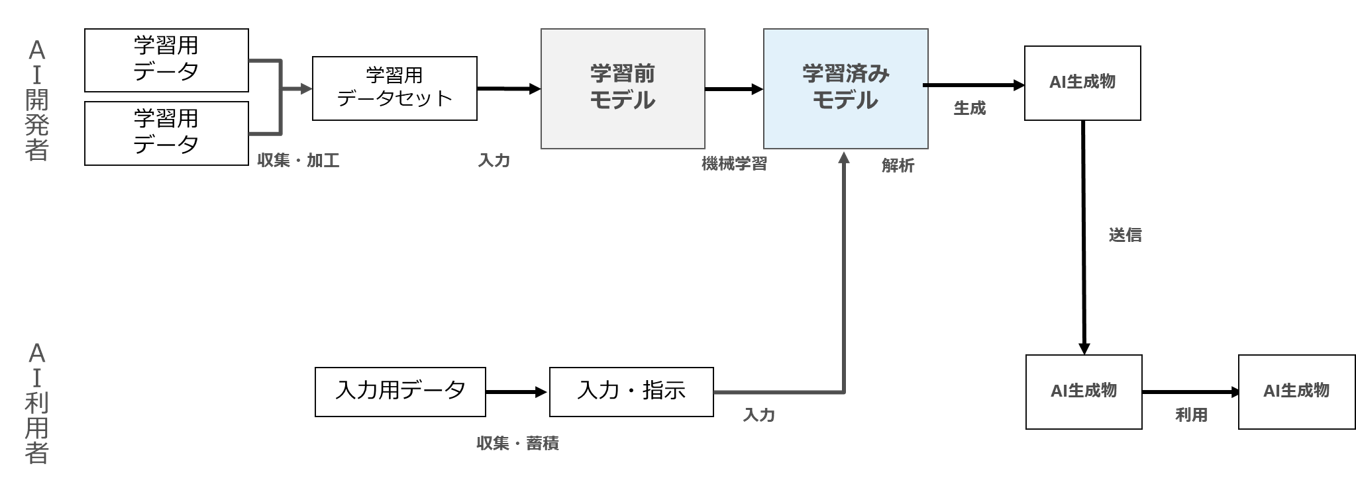
図4
先ほどの図1~3との違いは、「生成・利用」を物理的に誰が行っているのか、という点です。
先ほどの図1~3では、「生成・利用」を物理的に行っているのはAI利用者ですが、図4では、物理的に見ると、「生成・利用」のうち「入力」はAI利用者、生成はAI開発者、生成したAI生成物の送信はAI開発者、送信されたAI生成物の利用はAI利用者が行っています。
このことは、「生成・利用」について、AI開発者がどのような責任を負うかを考えるに際して重要なポイントとなります。
「AIの開発・学習」行為や「AI生成物の生成・利用」行為と言っても、物理的に分解していった場合、誰がどのような行為を行っているかを細かく検討しないと、誰が著作権侵害の責任を負うかが明らかにならないという点に注意が必要です。
(2) 「開発・学習」段階と「生成・利用」段階の意味
本記事では、「開発・学習」段階と「生成・利用」段階という用語について、一般的な用法にしたがって、以下の図の意味で用います。
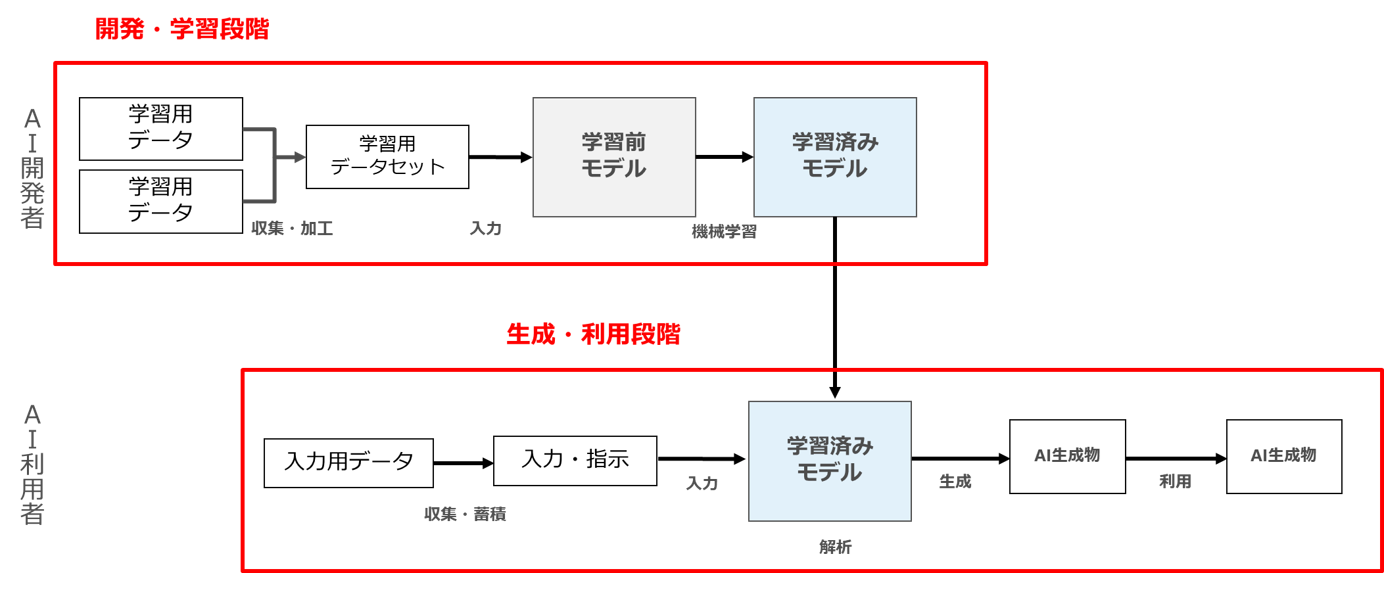
つまり、AIを開発するための行為が行われるフェーズを「開発・学習」段階、開発されたAIを用いて実際にAI生成物が生成されるフェーズを「生成・利用」段階と呼んでいます。
おそらく、一般的に用いられている、「開発・学習」段階と「生成・利用」段階という用語の意味はこのような整理ではないかと思われます。
このように整理すると、ここでいう「学習」とは、機械学習技術を用いて、AIのパラメーターを物理的に更新する行為を指します。
一方「考え方」において用いられている、「開発・学習」段階と「生成・利用」段階の用語の意味が、個人的にはずっと不明でした。
「考え方」では、「開発・学習」段階における問題として、「生成AIへの指示・入力に用いるためのデータベースの作成に伴う著作物の利用行為」(「考え方」19頁図3)や、RAGのことが紹介されていたり(同21頁以下)するのですが、これらの問題は、上記の通常の用語の意味に従うと「生成・利用」段階の問題だからです。
この点ではパブコメでも指摘されているのですが、「何でだろう。。。?」とずっと疑問に思っていました。
しかし、この連載記事を書くに当たってもう一度考えたところ「実は「考え方」における「開発・学習段階」「生成・利用段階」の意味と、自分が理解している「開発・学習段階」「生成・利用段階」の意味が違うのでは。。。?」ということに、はたと気付きました。
というのは、「学習」という言葉は、上記の意味での「学習」(機械学習技術を用いて、AIのパラメーターを物理的に更新する行為)に加えて、いわゆるIn-Context Learning(ICL)の意味を含めて用いられることがあるからです。
ICLとは、LLMへ入力するプロンプトとして、① 指示文(質問文)と共に、② 出力生成の際に参考にさせたいデータや、理想的な入出力例のデータを同時に追加入力することで、出力精度を上げる手法です(そのような追加データを全く入力しない手法をZero-shot Learning、1つだけ与える手法をOne-shot Learning、いくつか与える手法をFew-shot Learningと言います。)
たとえばLLMへの入力プロンプトとして「・・・について説明して下さい。その際には以下の資料を参考にして下さい。#資料1#資料2」のように、指示文と共に、正確な出力生成に必要な文書等のデータを同時に入力する方法がICLです。
ファインチューニングを含めた学習の場合、学習のためにかなりの量の学習用データが必要ですし、ファインチューニングしたからといって必ず精度向上が保証されるわけではありませんが、ICLの場合、いくつかの追加データを同時入力することで精度の高い出力を生成することができるというメリットがあると言われています。
そして、「考え方」の整理を見ていると、おそらく「考え方」における「開発・学習」とは、「学習」(AIのパラメーター更新行為)と、そのようなパラメーター更新行為を伴わないICLの双方を総称した概念なのではないかと思われます。そうすると、「考え方」における「生成・利用段階」というのは、生成AIにおけるAI生成物の生成・利用行為を指していると思われます。
以上の理解を前提に、「考え方」における整理をまとめると下図のようなイメージです。
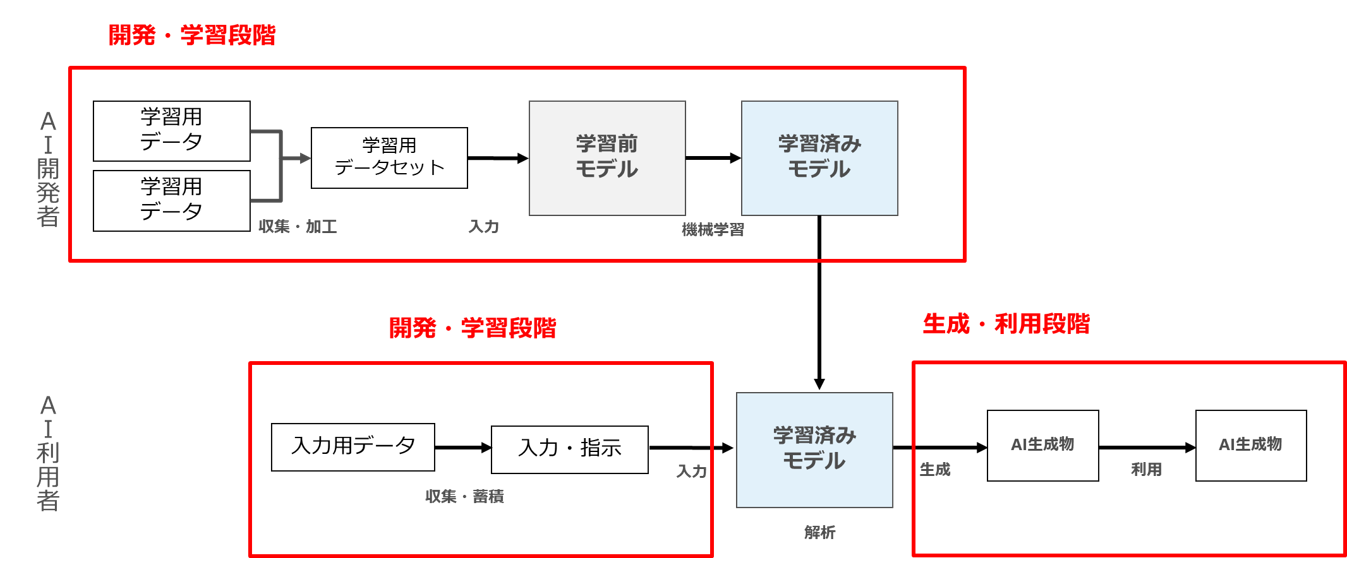
こう考えると、考え方19頁「図3 生成AIへの指示・入力に用いるためのデータベースの作成に伴う著作物の利用行為」が「開発・学習段階における著作物の利用行為」として整理されていることにも納得がいきます2パブコメ105、111,112、152等も参照。
ただ、考え方37頁では「その他の論点」として「ク 生成時のための生成AIへの著作物の入力について」を「(2)生成・利用段階」の論点として位置づけているのですよね。。。
もっとも、本連載では、これまで一般的に使われてきた用語との整合性という観点から、先ほど説明したような意味で「開発・学習段階」と「生成・利用段階」の用語を用いることにします。
なお、「学習」も「In-Context Learning(ICL)」もいずれも「情報解析」(法30条の4第2号)に該当すると思われます3これは、「情報解析」が多種多様な情報処理を包含する広範な概念であること、また、ICLにおいては、モデル内のパラメーターの物理的な更新行為は行われませんが、見方を変えると、あたかもパラメーターを変えて学習した場合と同様に、指示や今生成しているデータにあわせて、パラメーターを一時的に更新し、モデルを急速に適応させているとみなすことができるとされていることを根拠とします。 ので、「開発・学習」「生成・利用」をどのような意味で用いるかによって、著作権侵害についての結論が変わるわけではありません。
(3) 誰が、どのような行為に対して、どのような責任を負う可能性があるのか
本連載では、第2回以下で、「AI開発者」「AIサービス提供者」「AI利用者」のうち誰が、どのような行為に対して、どのような責任を負う可能性があるのかについて詳細に検討をしていきますが、最初に全体表を示しておきます。
いきなりこの表を見ても意味がわかりにくいと思いますが、本連載を通読して頂いた後に、再度見て頂くとよくわかると思います。
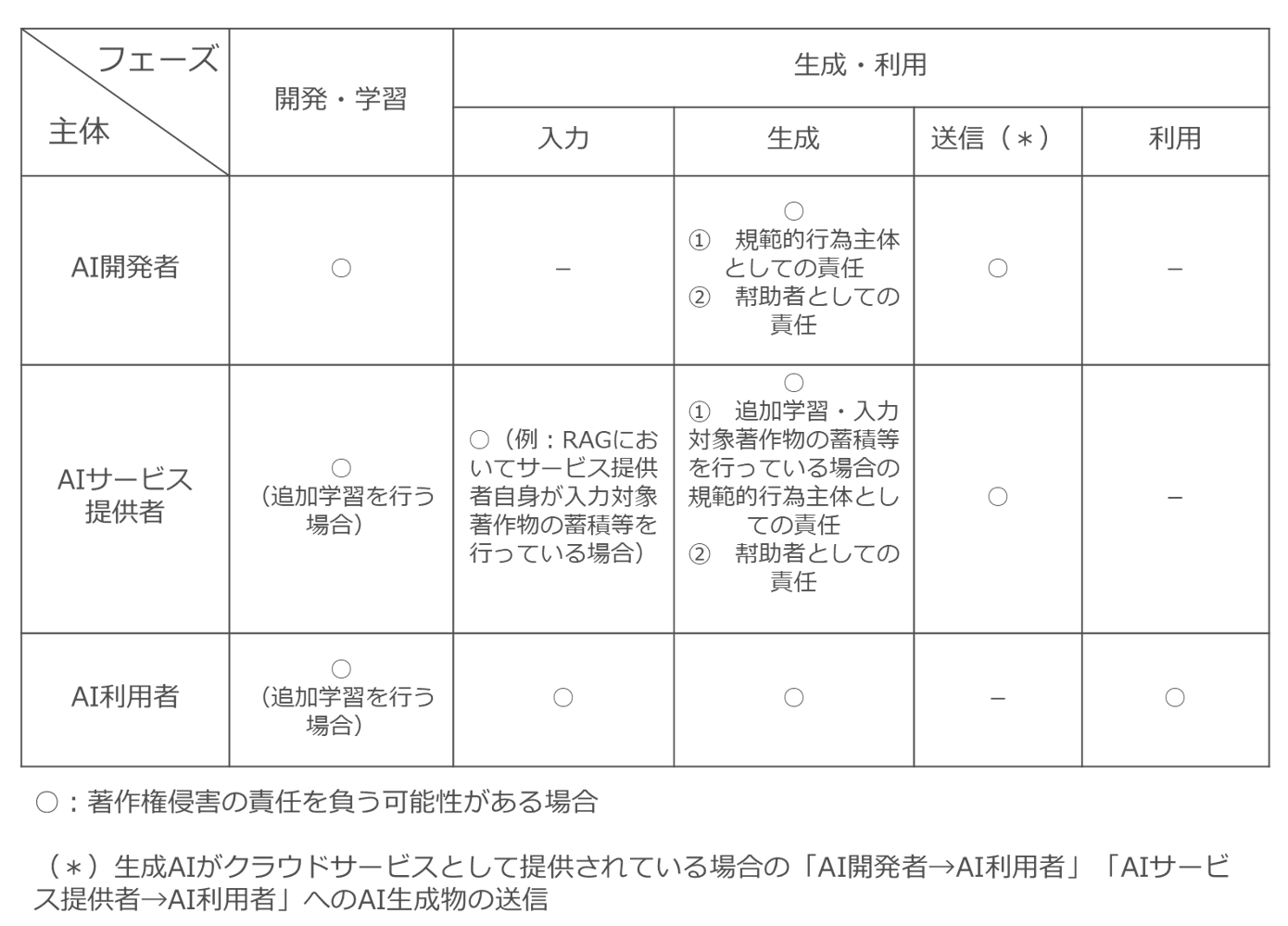
(4) 開発・学習段階と生成・利用段階を分けて検討する意味
先ほど、著作権侵害について検討する場合には、開発・学習段階における利用行為と生成・利用段階における利用行為を分けて検討する必要があるとお伝えしました。
これは、著作権侵害の有無を検討する際には著作物の利用行為ごとに分けて検討するのが鉄則であることと、通常、開発・学習を行う主体と生成・利用を行う主体が別当事者であるためです。
しかし、実は、両者を分けて検討する本当の意味は、著作権者にとっても、AI開発者・AIサービス提供者・AI利用者にとっても、その影響範囲が格段に異なるからです。
具体的には以下の表の通りです。
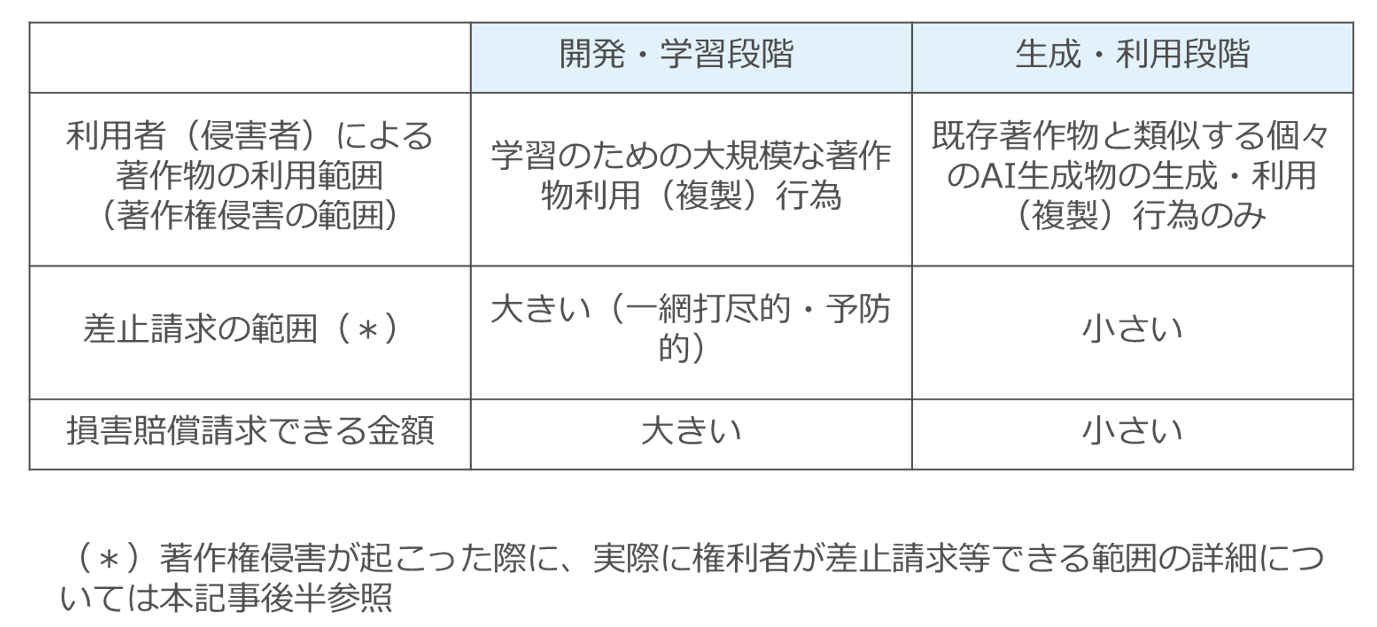
特に、多数の著作物を、無断で学習に利用される可能性がある主体(報道機関等)にとっては、この点は大きなポイントと思われます。
開発・学習段階におけるAI開発者による学習自体が著作権侵害(直接侵害)となると、学習に用いられた多数の記事単位で侵害責任を問えます。
一方、後に詳述するように、AI開発者が、規範的行為主体として、生成・利用行為について行為主体(侵害主体)となることがあります(間接侵害)。もっとも、それは生成・利用段階の問題に過ぎず、仮にAI開発者が行為主体になったとしても、あくまで生成された(複製された)著作物単位でしか侵害責任を問えないのです。
そのため、 開発・学習段階におけるAI開発者による学習自体が著作権侵害かどうかが激しく争われているのです。
なお、AIと著作権における各論点の中には、学者さんの間でもかなり激しい意見の相違が見られるものがあります。
私が見るところ、その相違の根本的な理由としては、「学習用データとして用いられた著作物の類似物が生成された」という生成・利用段階で縛りをかければ十分と考えるのか、そのような出力行為が行われる可能性がある場合には、大元の学習段階でも縛りをかけ、出力行為による著作権侵害を未然に防ぐ必要があると考えるかの違いであるように思われます4愛知先生は、生成・利用段階における多数の著作権侵害を惹起する蓋然性が極めて高い場合には、学習段階において、それらの侵害を「未然防止」することが肝要であるとする(「AIと著作権」31頁)。一方、奥邨先生(「AIと著作権」221頁)、谷川先生(「AIと著作権」223頁)は、学習段階であまり広く規制すべきではないというお考えのように読めます。 。
もっとも、開発・学習段階と生成・利用段階を分けて検討する必要はありますが、それぞれの段階は全くの無関係という訳ではありません。
たとえば、「生成段階の事情を根拠に学習行為が違法とされる場合」として、「表現出力目的での学習行為については30条の4が適用されない」があります。
また、「学習段階の事情を根拠に生成行為が違法(あるいは行為主体とされる)とされる場合」として、「学習用データセットに生成物が含まれている場合に依拠が認められる」や「学習行為を行う主体が、生成についても規範的行為主体として責任を負うことがある」というように、両段階は相互に影響し合っていると言えます。
【第2回記事】へ続く
【脚注】
- 1ここでいう「ローカル」には、AI利用者自身が管理するクラウド環境も含みます。
- 2パブコメ105、111,112、152等も参照
- 3これは、「情報解析」が多種多様な情報処理を包含する広範な概念であること、また、ICLにおいては、モデル内のパラメーターの物理的な更新行為は行われませんが、見方を変えると、あたかもパラメーターを変えて学習した場合と同様に、指示や今生成しているデータにあわせて、パラメーターを一時的に更新し、モデルを急速に適応させているとみなすことができるとされていることを根拠とします。
- 4愛知先生は、生成・利用段階における多数の著作権侵害を惹起する蓋然性が極めて高い場合には、学習段階において、それらの侵害を「未然防止」することが肝要であるとする(「AIと著作権」31頁)。一方、奥邨先生(「AIと著作権」221頁)、谷川先生(「AIと著作権」223頁)は、学習段階であまり広く規制すべきではないというお考えのように読めます。












