人工知能(AI)、ビッグデータ法務
文化庁「AIと著作権に関する考え方について(素案)令和6年1月15日時点版」の検討

1 はじめに
2024年1月15日に文化審議会著作権分科会法制度小委員会(第6回)が開催され、そこで「AIと著作権に関する考え方について(素案)令和6年1月15日時点版」(以下これを単に「素案」といいます。また、以下素案の該当頁を示す際には同素案の「見え消し版」の頁数を示します)が公開されました。
同素案は、現行著作権法の解釈指針を示すものに過ぎず、最終的な司法判断に代わるものでは当然ありませんが(素案3頁)、内容的にはかなり詳細かつ踏み込んだものとなっており、また、文化庁が作成・公表したものであるため、実務に非常に強い影響を及ぼすと思われます。
AIと著作権については重要論点はいくつもありますが、素案はそれらの論点を丁寧に網羅・解説しています。
各論点に関する素案の記載内容については概ね賛同しますが、素案には大規模言語モデルの開発・提供に非常に強い萎縮的効果をもたらす部分があり、その部分については素案から削除した方が良いと考えています。
本記事ではその点について掘り下げて検討します。
2 何が問題か
日本の著作権法では、第30 条の4第2号により、AI開発のような「情報解析」に必要な範囲において原則として著作物を自由に利用できることとなっています。
もっとも、同条は、そのただし書において「当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。」と規定し、これに該当する場合は同条が適用されないこととされています。
問題は、どのようなケースがこの「当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合」に該当するかです。
素案では、いくつかの具体的ケースについて、この「当該著作物の種類及び用途並びに・・・不当に害することとなる場合」に該当するという見解を示していますが、そこに重大な疑問があります。
3 本記事で検討対象とするケース
(1) 従来該当するとされていたケース(ケース1)
まず、従来、30条の4但書に該当するとされていたケースは以下のケースです(素案21頁及び「基本的な考え方」9頁)
大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為
(2) 今回問題となっているケース1(ケース2)
次に、素案が例示しているケースの1つ目は以下のケースです(素案21頁)。
インターネット上のウェブサイトで、ユーザーの閲覧に供するため記事等が提供されているのに加え、データベースの著作物から容易に情報解析に活用できる形で整理されたデータを取得できるAPIが有償で提供されている場合において、当該APIを有償で利用することなく、当該ウェブサイトに閲覧用に掲載された記事等のデータから、当該データベースの著作物の創作的表現が認められる一定の情報のまとまりを情報解析目的で複製する行為
(3) 今回問題となっているケース2(ケース3)
素案がもう一つ例示しているケースは、以下のケースです(素案22頁)。
あるウェブサイト内の記事にAI 学習のための著作物の複製等を防止する技術的な措置(”robots.txt” への記述等)が講じられており、かつ、かつ、このような措置が講じられていること等の事実から、当該ウェブサイト内のデータを含み、情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることが推認される場合に、当該技術的な措置を回避して当該ウェブサイトからAI学習のための複製等をする行為
4 検討の視点
30条の4ただし書該当性を検討するに当たっては、「著作権者の著作物の利用市場と衝突するか、あるいは将来における著作物の潜在的販路を阻害するかという観点から、技術の進展や、著作物の利用態様の変化といった諸般の事情を総合的に考慮して検討することが必要」とされています(素案P19)。
30条の4本文に沿った形で、上記「著作権者の著作物の利用市場と・・・・・観点」について要件と効果に分解すると以下のとおりとなります。
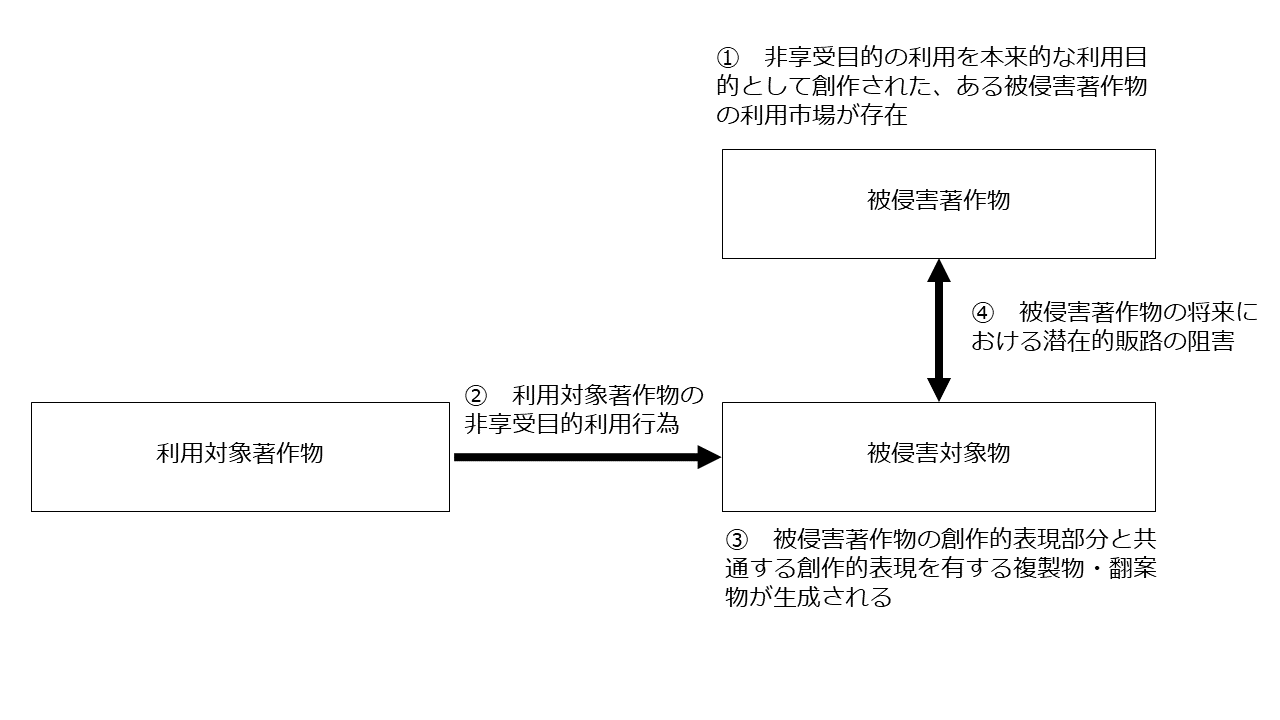
【要件】
① 非享受目的の利用を本来的な利用目的として創作された、ある著作物(「被侵害著作物」と言います)の利用市場が存在している場合において
② ある著作物(「利用対象著作物」と言います)の非享受目的利用行為により
③ ①の被侵害著作物の創作的表現部分と共通する創作的表現を有する複製物・翻案物が生成され
【効果】
④ その結果、①の被侵害著作物の将来における潜在的販路が阻害されるため、ただし書に該当し①の被侵害著作物の著作権侵害に該当する
つまり、被侵害著作物について①②③の要件を満たすと、被侵害著作物について④の効果が発生し、30条の4ただし書に該当することで、被侵害著作物の著作権侵害が成立する(他の権利制限規定の適用がなければ)ことになります。
①の要件を満たさなければ、そもそも保護されるべき著作物が存在しませんので当然但し書きの適用はありません
また、③の要件も必要です。仮に利用対象著作物の非享受目的利用行為があったとしても、当該利用行為により①の被侵害著作物の創作的表現部分と共通する創作的表現を有する複製物・翻案物が生成されなければ、著作権侵害には該当しないからです。
図で示すと以下のとおりとなります。
なお、通常は「被侵害著作物」=「利用対象著作物」であると思われます。
なぜなら、ある著作物が利用された際に、当該著作物「以外」の著作物の潜在的販路が阻害されることは通常はないためです。もっとも、後述するように、素案のケース2、3では「被侵害著作物」と「利用対象著作物」が異っており、それが素案の該当部分の理解を難しくしているのではないかと推察します。
また、「被侵害著作物」=「利用対象著作物」の場合、要件②と③は、通常は区別する必要がありません。著作物の利用とは、当該著作物における創作的表現の利用のことだからです。ただ、後述するように、素案の内容を理解するには、この二つを分けた方がわかりやすいかと思い、あえて分けてます。
以上を前提にケース1,2,3について検討をしていきます。
5 ケース1について
(1) ケース1
言葉や図だけでは分かりにくいと思うので、ケース1にこれを当てはめてみます。
ケース1は「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為」でした。
つまり以下のような関係があるケースです。
【ケース1】
① 被侵害著作物として、大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物(以下「情報解析用DBの著作物」といいます)の利用市場が存在している場合において
② 情報解析用DBの著作物(「利用対象著作物」)の非享受目的利用行為(「情報解析目的で複製等する行為」)により
③ 情報解析用DBの著作物の創作的表現部分と共通する創作的表現を有する複製物・翻案物が生成され
④ その結果、情報解析用DBの著作物の将来における潜在的販路が阻害されるため但し書きに該当し、情報解析用DBの著作物の著作権侵害に該当する
(2)著作権法上のデータベース及びデータベース著作物の扱い
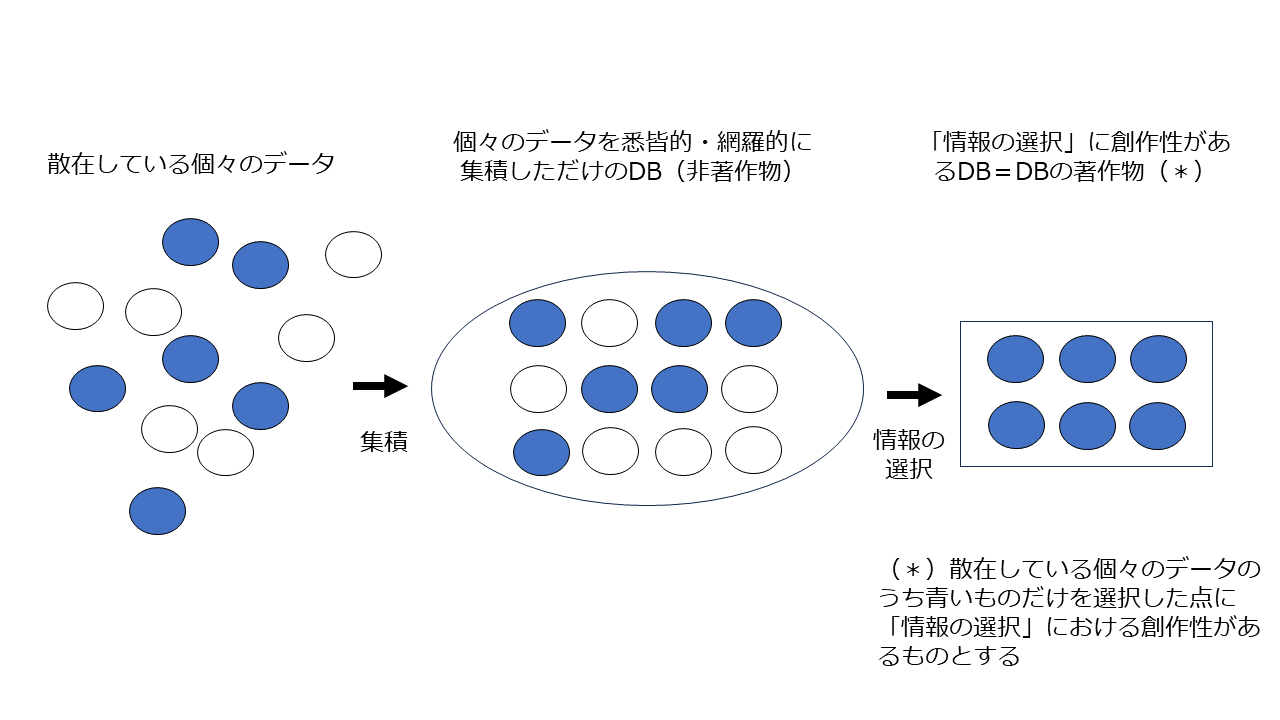
ここで、「データベース(DB)」や「DBの著作物」の概念が出てきました。
今回の素案の問題点を理解するに際しては、著作権法上の、「DB」と「DB著作物」の定義及び区別を理解することが、極めて重要です。
著作権法上は「データベース」とは「論文、数値、図形その他の情報の集合物であつて、それらの情報を電子計算機を用いて検索することができるように体系的に構成したもの」(著作権法2条1項10の3)と定義され、「データベースの著作物」とは「データベースでその情報の選択又は体系的な構成によつて創作性を有するもの」(法12条の2第1項)と定義されています。
つまり、著作権法上、データベースのうち、一定の要件(「データベースでその情報の選択又は体系的な構成によつて創作性を有する」)を満たしたものだけが、DBの著作物として保護されるのであって、それ以外のDBについては著作物ではないということになります。
(3) ケース1の検討
ケース1を図で示すと以下のとおりとなります。
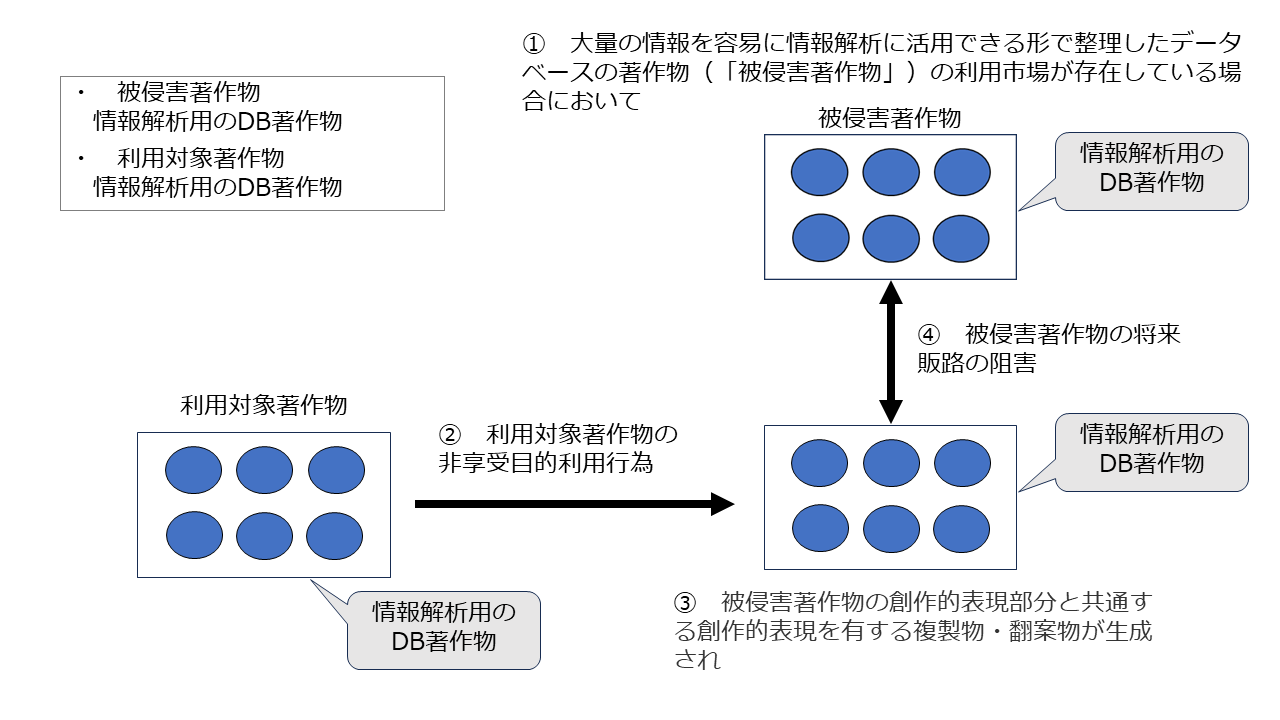
このケースは「被侵害著作物」=「利用対象著作物」=情報解析用DBの著作物であり、③で、非侵害著作物である情報解析DBの創作的表現を利用する複製物が生成されていますので、情報解析用DBの市場との衝突が総じており、但書に該当するのは当然だと思います。
6 ケース2について
(1) ケース2の内容
ケース2は以下のケースです。
【ケース2】
インターネット上のウェブサイトで、ユーザーの閲覧に供するため記事等が提供されているのに加え、データベースの著作物から容易に情報解析に活用できる形で整理されたデータを取得できるAPI が有償で提供されている場合において、当該API を有償で利用することなく、当該ウェブサイトに閲覧用に掲載された記事等のデータから、当該データベースの著作物の創作的表現が認められるに一定の情報のまとまりを情報解析目的で複製する行為
(2) 検討
このケースを先ほどのフレームワークに当てはめると以下のとおりとなり、①②③の要件を満たせば、④の効果が発生します。
① 情報解析用DBの著作物(「被侵害著作物」)の利用市場が存在している場合において
② ウェブサイトに閲覧用に掲載された記事等のデータ(「利用対象著作物」)の非享受目的利用行為(API を有償で利用せずにクローリング等の複製行為等)により
③ ①の情報解析用DBの著作物と共通する創作的表現を有する複製物・翻案物が生成され
④ その結果、①のDBの著作物の著作物の将来における潜在的販路が阻害される
これを図で示すと以下のとおりです。
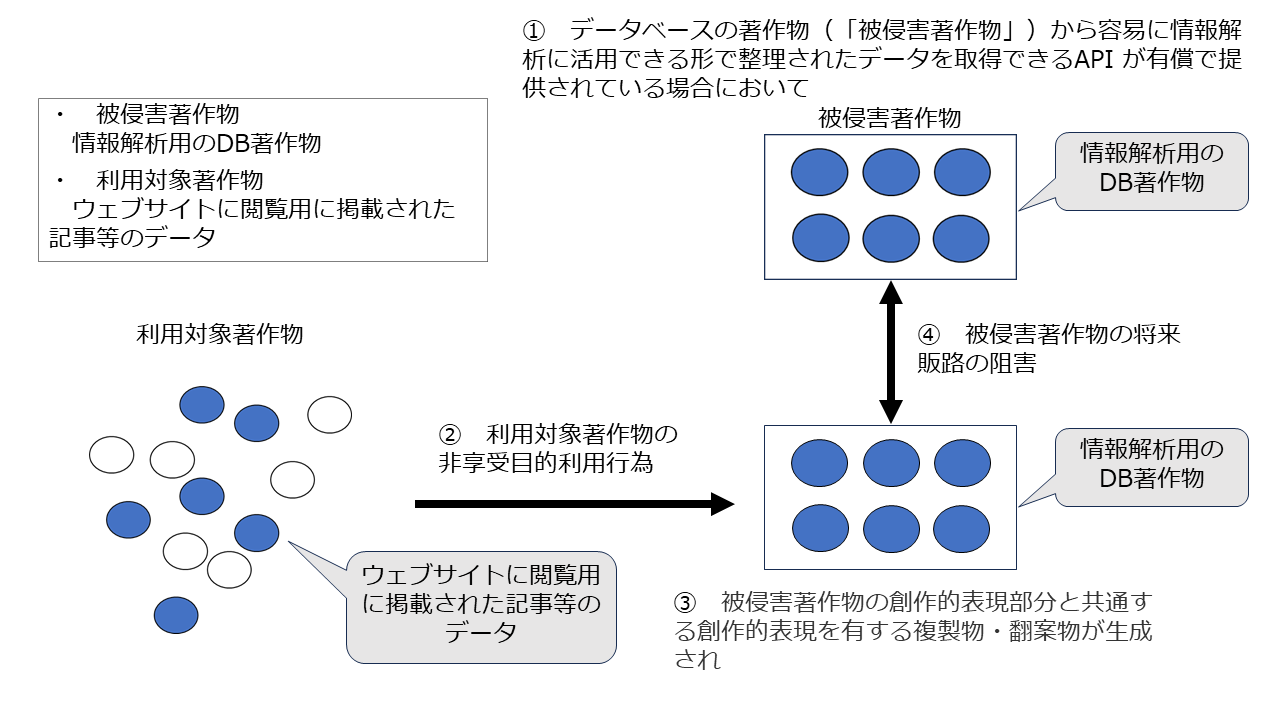
このケースでは「被侵害著作物」が「情報解析用DB著作物」、「利用対象著作物」が「ウェブサイトに閲覧用に掲載された個々の記事等のデータ」ですから、「被侵害著作物」≠「利用対象著作物」です。
ここが判りにくいところだと思います。
ただし、このケースで著作権侵害の有無が問題になっているのは、あくまで「被侵害著作物」である「情報解析用DB著作物」であり、「利用対象著作物」である「ウェブサイトに閲覧用に掲載された個々の記事等のデータ」ではありません。
第6回の委員会でも、素案のケース2,ケース3(素案の(ウ)(エ))は、個々の記事データの著作権侵害ではなく、あくまで情報解析DB著作物の著作権侵害に該当するか否かの問題である、と事務局が繰り返し念押しをしていました。
私のメモによると、事務局は、この部分について、概要「素案21頁の(ウ)、同22頁の(エ)の例が前提としている被侵害著作物は情報解析用のDB著作物であり、問題となる著作物の利用行為も情報解析用のDB著作物の複製行為である。個々のデータの利用行為の著作権侵害の問題は素案では記載していない。ただし、個々のデータのクローリング等の複製により、DB著作物の複製が行われていると評価できる場合には、DB著作物の著作権侵害に基づく差止、あるいは将来の侵害行為の予防措置の請求として、個々のデータの利用行為を差し止めることができるという趣旨で記載した」とおっしゃっていました。
しかし、①②③の要件を満たすことは理論上は考えられますが、実際にはほぼあり得ないでしょう。
たとえば、以下のようなケースは上記①②③のいずれかの要件を満たさず但書には該当しないことになります。
ア ①の要件を満たさない場合
まず、APIにより有償提供されているのがDB著作物ではなく単なるDBの場合です。
この場合はそもそも「被侵害著作物」が存在しないので、①の要件を満たさず、ただし書に該当することはあり得ません。
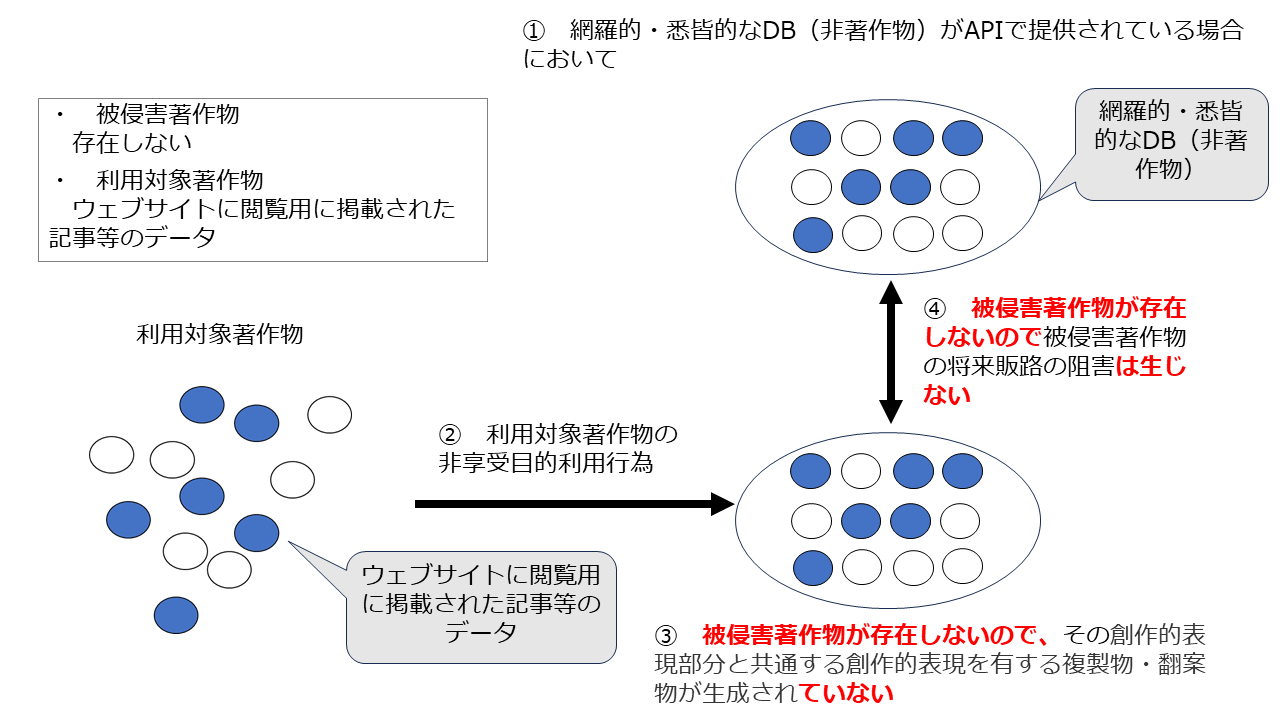
実際には、報道機関が提供しているDBについてはこのケースが多いと思われます。
素案脚注20には、「具体例」として「学術論文の出版社が論文データについてテキスト・データマイニング用ライセンス及びAPI を提供している事例や、新聞社が記事データについて同様のライセンス及びAPI を提供している事例」が「データベース著作物」の提供の具体例としてあげられていますが、これらはケースバイケースではありますが、通常は、DBではありますが、DB著作物ではないことがほとんどだと思われます1同じ脚注には「もっとも、テキスト・データマイニング用ライセンス及びAPI を提供しているとしても、当該API が「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物」に当たるとは限らないといった意見もあった。」と記載がありますが、これは極めて控えめな表現で、実際には「当該APIはデータベースの著作物の提供にあたることは稀である」が正確ではないでしょうか。
というのは、これらのDBには網羅性・悉皆性が求められ、情報の選択における創作性はむしろ「ない」ことが求められるためです。
ちなみに「ある一定のテーマについての論文のDB」「ある特定の期間の記事データのDB」という程度では「情報の選択」における創作性はありません。
たとえば、読売新聞は「読売新聞記事データ(1987年~)」を言語資源コーパスとして提供しています。
このデータベースは、説明書きによると「読売新聞の過去30年を超える年数分の東京・中部・大阪・西部各本支社の本版と全地域版(県版)の記事を年間約30万本収録しています。タイトル、本文、掲載日のほか、キーワード、分類コードなど詳細情報15項目のタグが付けられています。」とされ、同データベースの仕様書を見ると、15項目のタグの具体的内容が記載されています。
また、朝日新聞は日本語研究のための記事テキストデータ集として「朝日新聞記事データ(学術・研究用)」を提供していますし、毎日新聞もコーパス研究も含め、自然言語処理の分野ではスタンダードな基礎データとして「毎日新聞記事データ」を提供しています。
少なくとも、ここで紹介したような新聞社のデータベースは、その中身を見ないとはっきりしたことは言えませんが、網羅的・悉皆的なデータベースであり、「情報の選択」や「体系的な構成」に創作性があるデータベースの著作物ではない可能性が高いと考えます。
イ ①の要件は満たすが、③の要件を満たさない場合
仮にAPIにより提供されているのが単なるDBではなくDB著作物であったとしても、②により当該DB著作物の「創作的表現」が利用されていなければ、③の要件を満たさないことになります。
たとえば以下のようなケースです。
(ア) ウェブサイトに閲覧用に掲載された記事等のデータをAPIを経由せずに収集して、情報解析用DB著作物ではなく単なるDBを作成する場合
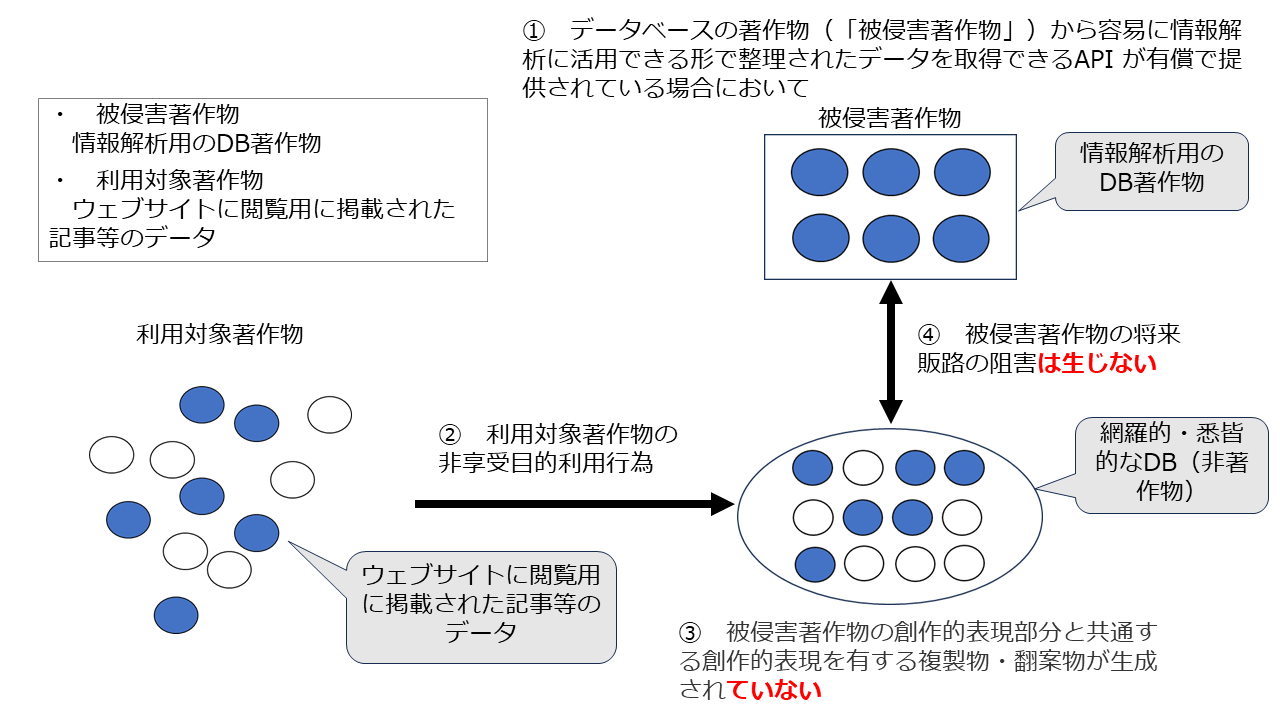
この場合、③の要件を満たしません。
(イ) ウェブサイトに閲覧用に掲載された記事等のデータをAPIを経由せずに収集してDB著作物を作成しているが、①のDB著作物とは、情報の選択において異なる創作性を有するDB著作物を作成している場合
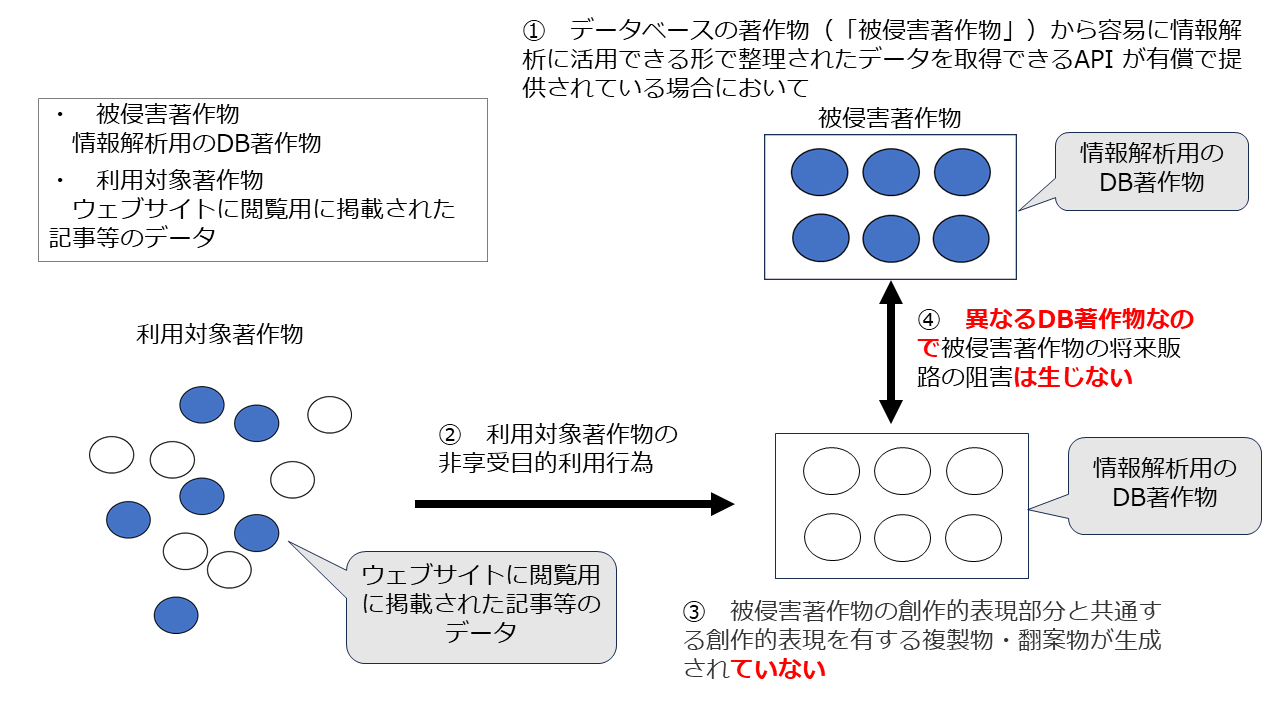
この場合も③の要件を満たしません。
ウ 結論
つまり、ケース2において、①②③を満たすのは、②でウェブサイトに閲覧用に掲載された記事等のデータをAPIを経由せずに収集する者が、③で、あえて①と同じ「情報の選択の創作性」を有するDBの著作物を作成する場合のみです。
このようなことは現実的にはほぼあり得ないでしょう。
そもそも、データ収集者としては、そのような行為をあえて行う必要性が全くありません。
7 ケース3について
(1) ケース3の内容
ケース3は以下の内容です。
【ケース3】あるウェブサイト内の記事にAI 学習のための著作物の複製等を防止する技術的な措置(”robots.txt” への記述等)が講じられており、かつ、かつ、このような措置が講じられていること等の事実から、当該ウェブサイト内のデータを含み、情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることが推認される場合に、当該技術的な措置を回避して当該ウェブサイトからAI学習のための複製等をする行為
(2) 検討
これを先ほどのフレームワークに当てはめると以下のとおりとなり、確かに①②③の要件を満たせば、④の効果は発生します。
① 情報解析用DB著作物(「被侵害著作物」)が将来販売される可能性があり、その利用市場が存在する場合において
② 技術的な学習防止措置が講じられた、ウェブサイトに閲覧用に掲載された記事等のデータ(「利用対象著作物」)の非享受目的利用行為により
③ ①の情報解析用DBの著作物と共通する創作的表現を有する複製物・翻案物が生成され
④ その結果、①のDBの著作物の将来における潜在的販路が阻害される
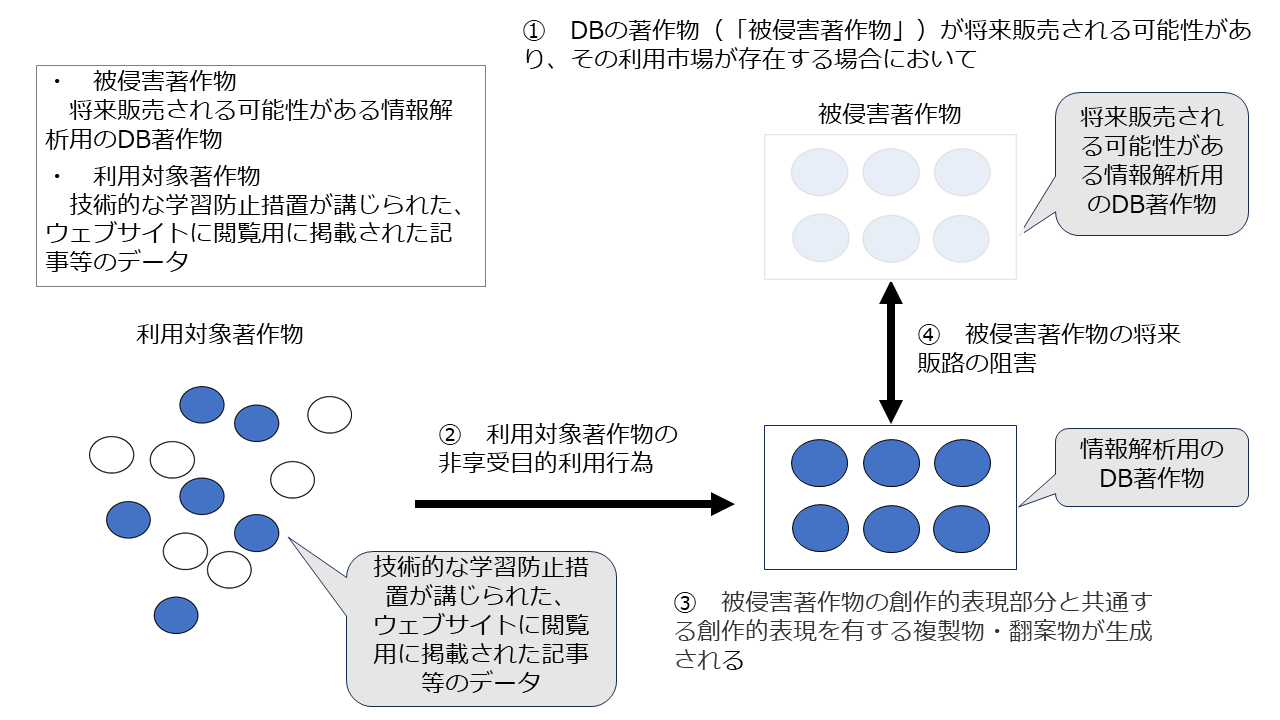
先ほどのケース2では、①②③の要件を満たすことはほぼあり得ないとお伝えしましたが、ケース3でも同様に、①②③の要件を満たすことはほぼあり得ません。むしろケース3は「将来販売される可能性がある情報解析用DB著作物」の将来販路の阻害を念頭に置いているため、①②③の要件を満たす可能性はケース2よりもっと低いでしょう2素案脚注23(p23)には「この点に関しては、この措置を回避して行うAI 学習のための複製等であっても、当該データベースの著作物の将来における潜在的販路を阻害する行為に当たるとは限らない、といった意見もあった。」とありますが、むしろ「そのような行為に該当することは極めて稀である」が正確なのではないかと思われます。
ア そもそも①の要件を満たさない場合
ケース2と同様、そもそも将来販売される予定のDBが、情報解析用DB著作物ではなく単なるDBの場合です。
ケース2と同様、この場合は被侵害著作物が存在しませんので、そもそも「被侵害著作物の将来販路の阻害」が起こりようがありません。
イ ①は存在するが、③の要件を満たさない場合
仮に、将来販売される予定のDBが単なるDBではなく情報解析用DB著作物であったとしても、ケース2と同様、②により当該DB著作物の「創作的表現」が利用されていなければ、③の要件を満たさないことになります。
たとえば以下のようなケースです。
(ア) 技術的な学習防止措置を講じられた、ウェブサイトに閲覧用に掲載された記事等のデータを収集して単なるDBを作成する場合
この場合、ケース2と同様③の要件を満たしません。
(イ) 技術的な学習防止措置を講じられた、ウェブサイトに閲覧用に掲載された記事等のデータを収集してDB著作物を作成しているが、①の、将来販売される予定のDB著作物とは、情報の選択において異なる創作性を有するDB著作物を作成している場合
この場合も、ケース2と同様③の要件を満たしません。
ウ 結論
以上をまとめると、ケース3においては、技術的な学習防止措置を講じられた、ウェブサイトに閲覧用に記載された記事等のデータ(利用対象著作物)を利用して、「将来販売される可能性のある情報解析用DBの著作物」(つまり、現時点では未だこの世に存在していないDBの著作物ということです)と、偶然同じ「情報の選択性」を有するDBの著作物を作成する場合のみが30条4の但し書きに該当することになります。
こんなことは、実際にはおよそあり得ないのではないでしょうか3なお、著作権自体が未だに発生しておらず、かつ侵害行為も行われていない段階での予防請求を認めた裁判例は存在しますが(東京地判平5・8・30知的裁集25巻2号380頁(ウォール・ストリート・ジャーナル事件)、同裁判例については、「被侵害著作物が未だ存在しない場合の差止請求は極めて例外的であり,同判決は一般化できないであろう」とされています(中山信弘 (東京大学名誉教授)/著『著作権法 第3版』(有斐閣、2020年)727頁)
8 まとめ
以上見てきたとおり、素案に記載されているケース2,ケース3は「理論的にはありえるが、発生する可能性がほぼないケース」ではないかと思います。
言い方は悪いですが、「ただし書に該当する具体的事例がないかと、なんとか探してひねり出した想像上の事例」といってもいいと思います。
怖いのは、この素案が一人歩きすることで、権利者(特に報道機関)がこの部分を拡大解釈し、以下のような主張をすることです。
ここまで詳細に見てきたように、以下のような主張は、素案が示しているケースを権利者に有利に拡大解釈したものにすぎず、その主張に合理性はないと考えています。
– DB著作物ではない単なるDBしか提供していないのに、AI開発者による個々の記事データのクローリングが但し書きに該当すると主張する
– AI開発者が個々の記事データをクローリングして、提供されているDB著作物とは異なるDBやDB著作物を作成した場合でも但し書きに該当すると主張する
– ウェブサイト内の記事にAI 学習のための著作物の複製等を防止する技術的な措置(”robots.txt” への記述等)を講じるだけで、当該措置を回避して行われるデータ収集について一律但し書きに該当すると主張する
大規模な報道機関からこのような主張をされた場合、きちんと反論できるAI開発者(特に日本のAI開発者)がどの程度いるかというと、かなり心もとありません。
民間やアカデミアのAI開発者の萎縮的効果を考えると、私は素案から、この部分の記載は削除すべきと考えます。
このままでは、日本における大規模言語モデル開発が、他国における開発に比べて一歩も二歩も後退しかねません。
この素案については、若干の修正後、2024年1月半ばからパブコメに付される予定です。
大規模言語モデルの開発を行う、日本のAI開発者・提供者のみなさんは危機感を持って対応した方が良いと思います。












