人工知能(AI)、ビッグデータ法務 著作権
AIと著作権【第7回】類似AI生成物の「生成」における依拠性をどのように考えるか~複雑な論点を解きほぐす~

2025年7月にSTORIA法律事務所の柿沼・杉浦の共著で日本加除出版から書籍「AIと法 実務大全」を出版します。
本書は650頁超というボリュームでありながらも、AI開発や利活用に問題となる点を「網羅的」に解説するものではありません。あくまで、現場の方がAI開発や利活用を行う際に、法律的によく問題となる論点とその解決手法に照準を絞っています。その分個々の論点については、最先端の議論を下敷きにしつつ実務的に相当深掘りした記述となっています。
書籍の出版に先立ち、その一部である「第2章 生成AI開発・提供・利用と著作権」について日本加除出版からご了解を得て、ブログで連載記事として先行公開することとしました。
「一部」といっても記事合計13万字を越えるボリューム(ほぼ新書1冊分!)であり、ブログ公開を快諾いただいた日本加除出版には感謝しかありません。
この連載記事を読んで興味が湧いた方は是非書籍をお買い求めください!
連載「AIと著作権」全18回の目次を表示
- 第1回 プレイヤー・フェーズ・提供形態による法的整理
- 第2回 AI学習段階での著作物利用はどこまで許されるか?──著作権法第30条の4の射程
- 第3回 学習用データとして“何を使ってはいけないか”を見極める~学習対象の観点からの検討~
- 第4回 海賊版や学習禁止表示がされている著作物をAI学習に利用することができるか
- 第5回 開発・学習段階での著作権侵害行為が発生した場合、侵害者はどのような責任を負うか
- 第6回 生成・利用段階では何が問題になるのか?
- 第7回 類似AI生成物の「生成」における依拠性をどのように考えるか~複雑な論点を解きほぐす~
- 第8回 類似AI生成物の「生成」における行為主体性~ロクラクⅡ事件判決をベースに徹底的に考える~
- 第9回 生成された類似AI生成物を利用すると著作権侵害?
- 第10回 類似AI生成物の「送信」は誰の責任?──クラウド提供型AIにおける著作権侵害リスクを検証する
- 第11回 生成・利用段階で著作権侵害行為が認められた場合、権利者は何を請求できるのか
- 第12回 RAG・ロングコンテクストLLMと著作権侵害(前編)
- 第13回 RAG・ロングコンテクストLLMと著作権侵害(後編)
- 第14回 RAGシステムのための既存著作物の蓄積・入力などは著作権侵害になるのか
- 第15回 RAGとAI利用者の責任~入力・送信・出力のそれぞれで何が問われるか?~
- 第16回 AI生成物に著作権はあるのか?~著作物性と“創作的寄与”の最新実務論~
- 第17回 その行為に日本著作権法は適用されるか~準拠法の問題~
- 第18回 で、結局何に気をつければよいのか~AI開発者・AI提供者・AI利用者それぞれの注意事項~
この記事の内容を、対話形式の音声で聞くことができます。
▶ 対話形式で聞く
※ 対話形式の音声はNotebookLMを利用して自動的に作成したものです。正確な内容は記事本文をご参照ください。
Contents
(6) 類似AI生成物の「生成」について
ア 依拠性
(ア) どのような場合に類似AI生成物の「生成」について依拠が認められるか
結論から述べると、「考え方」33頁~34頁の記載を踏まえると、AI利用者が生成AIを利用して既存著作物と同一・類似のAI生成物を生成した場合に、既存著作物との依拠性が認められるかは以下のフローチャート(図52)1『AI と著作権』118 頁〔奥邨〕のフローチャート及び「考え方」33 頁〜34 頁をもとに筆者が作成したものに従って判断すべきと考えます。
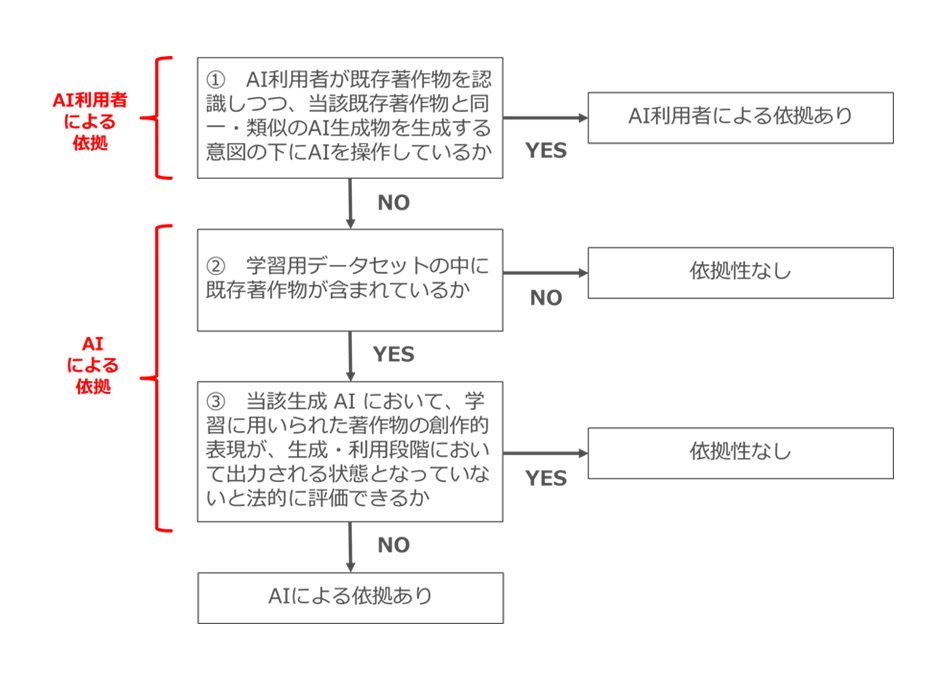
図52
たとえば、パターン2のようにAI利用者が既存著作物をAIに入力して同一・類似AI生成物を生成している場合や、パターン3において、AI利用者が当該既存著作物と同一・類似のAI生成物を生成する意図の下にプロンプトを工夫して同一・類似AI生成物を生成している場合です。
この場合は、AI利用者がAIを単なるツールとして利用して、既存著作物と同一・類似のAI生成物を生成していることから、当然のことながら依拠性は認められます。
なお、この場合に、既存著作物と類似するAI生成物が生成(複製)されたのは、専らAI利用者の行為に起因していることから、本書では、この場合を「AI利用者による依拠」と呼ぶことにします2奥邨先生はこの場合を「操作者による依拠」と呼ぶが(『AI と著作権』109 頁)、本書では「AI 利用者による依拠」と呼ぶこととする。。
この点について、考え方33頁には「① AI 利用者が既存の著作物を認識していたと認められる場合」との記載がありますが、「単にAI利用者が既存の著作物を認識している(知っている)」だけで、当該既存著作物に似せる意図がない場合や、似せる努力(選択含む)を全くしてない場合に依拠性が認められるかについては、学説上争いがあります。
たとえば、ミッキーマウスを知っているAI利用者が、「子供が好きそうなキャラを出して欲しい」という極めて抽象的なプロンプトをAI(ミッキーマウスの画像は学習用データに含まれていないものとします)に入力したところ、極めて低い確率ですが1発でミッキーマウスのキャラクターが生成された場合については、独自創作だとして当該生成行為について依拠性を否定するのが通説ではないかと思われます3『AI と著作権』で愛知先生は「単にそのAI 利用者が既存の著作物を知っています(中略)というときに、なんらAI がアクセスしていない(筆者注:学習用データに既存著作物が含まれていないこと)というときに、果たして依拠を肯定できるのかというのは、ちょっと疑問が残るところではあります」とする(277 頁)、また、同じく横山先生もこのケースで依拠性を否定する(281 頁)。。
もっとも、この考え方にたつ論者も、「AI利用者が既存著作物を認識しつつ、多数回生成を試行して、その中から同一・類似物を選択した場合」「AI利用者が既存著作物を認識しつつ、同一・類似物を生成するために詳細な指示をした場合」には依拠性を認めてよいとします4『AI と著作権』280 頁〔愛知〕。
また、「考え方」33頁が「① AI 利用者が既存の著作物を認識していたと認められる場合」の例として挙げている以下の例は、単に「AI利用者が既存の著作物を認識している(知っている)」場合ではなく、「AI利用者が既存著作物を認識しつつ、当該既存著作物と同一・類似のAI生成物を生成する意図の下にAIを操作している」場合ではないかと思われます567)『AI と著作権』268 頁〜285 頁では、この論点を巡って激しく議論がされている。もっとも奥邨先生も「AI 利用者が既存の著作物を認識して(知って)生成した」だけで依拠性を肯定しているわけではないように思われる(「AI を使って、意図的に似たものを出力した、そしてそれを世間に出していくという場合には(出さなくてもいいですけども)」(268 頁)、「Bが描いたものを、似ているとわかって世に出せば」(278 頁)、「ドラえもんとインプットしなくても、未来から来た猫型ロボットと入力して、100 万回試してそのうちの1回がドラえもんでそれを世に出すというのでも、操作者に依拠を認めてよいと思っています」(280 頁)、「私としては、詳しい指示をしなくても、操作者が見聞きした著作物に似てるものがAI から出力されて、操作者は似ていることが分かった上でそれを選ぶのならば、操作者による依拠ありだと思うんです。」(281 頁)。
(例)Image to Image(画像を生成 AI に指示として入力し、生成物として画像を得る行為) のように、既存の著作物そのものを入力する場合や、既存の著作物の題号などの特定の固有名詞を入力する場合
以上のことから「AI利用者による依拠」として、「AI利用者が既存著作物を認識しつつ、当該既存著作物と同一・類似のAI生成物を生成する意図の下にAIを操作している場合」には依拠性が認められると考えます。
これを前提とすると、たとえば、パターン2、5,7,10は、AI利用者自身が既存著作物を入力していますので当然AI利用者による依拠が認められます。
また、パターン3,4,7、10においても「AI利用者が既存著作物を認識しつつ、当該既存著作物と同一・類似のAI生成物を生成する意図の下にAIを操作している」場合には、学習用データに既存著作物が含まれていなくとも、依拠性を満たすこととなります。
一方、パターン3及び8において、AI利用者にそのような意図・操作がなければ、学習用データセットにも既存著作物が含まれていないことから(この場合は後述のAIによる依拠もないことになります)、独自創作として依拠性は存在しないことになります。
(ⅱ) AI利用者が既存著作物を認識していなかった(当然のことながら 学習用データに当該著作物が含まれることも認識していない)が、学習用データに当該著作物が含まれる場合(AIによる依拠)
たとえば、パターン4及び9(いずれも学習用データに当該著作物が含まれる場合)において、AI利用者が既存著作物を認識していなかった(当然のことながら 学習用データに当該著作物が含まれることも認識していない)場合がこれに該当します。
この場合は、AI利用者が既存著作物を認識していないことから、「AI利用者による依拠」は認められません。
もっとも、既存著作物(学習用データ)と同一・類似のAI生成物が複製されたのは、学習用データに当該著作物が含まれていたが故とも思われ、それを理由とした依拠が認められるかがさらに問題となります。
本書では、「学習用データに当該著作物が含まれていることを理由とする依拠」を「AIによる依拠」と呼びます。
「AIによる依拠」が認められるかどうかにおいて、検討しなければならない問題点は2つあります。
1つは「①学習用データに当該著作物が含まれていることをAI利用者が認識していない場合でも依拠性を認めて良いのか」という問題です。
もう1つは「②学習用データに当該著作物が含まれていさえすれば、AI内でどのような形でそれが保持・利用されていても依拠性を認めてよいか」という問題です6『AI と著作権』114 頁〔奥邨〕。
① 学習用データに当該著作物が含まれていることをAI利用者が認識していない場合でも依拠性を認めて良いのか
この点については、生成AIにおける依拠性の論点においては、学習用データに当該著作物が含まれていることをAI利用者が認識していない場合でも、依拠性を認めてよいとする立場が主流と思われます7前田健「生成AI の利用が著作権侵害となる場合」法学教室523 号28 頁、『AI と著作権』114 頁、120 頁、123頁〔奥邨〕、本山雅弘「生成AI による著作物の利用主体―生成AI による類似表現物の作出行為における利用行為の成否とその主体―」SOFTIC Law Review 1巻2号(2024)14 頁。
② 学習用データに当該著作物が含まれていさえすれば、AI内でどのような形でそれが保持・利用されていても依拠性を認めてよいか
この点については、2つの考え方があります。
1つは、「学習用データに既存著作物が含まれていさえすれば、AI内でどのような形でそれが保持・利用されていても依拠性を認める説」(全面肯定説)です870)愛知靖之「AI 生成物・機械学習と著作権法」パテント73 巻8号(2020)143 頁〜144 頁。また、本山先生も「AI 生成の基礎とされた学習済みモデルに記録されたのが学習対象著作物のアイデアと評価される部分に過ぎないとしても、そのことから直ちに、当該AI 生成物に依拠性を欠くとして権利保護範囲を遮断することは困難と解されよう。」とする(本山雅弘「生成AI による著作物の利用主体―生成AI による類似表現物の作出行為における利用行為の成否とその主体―」SOFTIC Law Review 1巻2号(2024)16 頁)。。
もう1つは「学習用データに既存著作物が含まれていても、AI内に保持・利用されているのが当該既存著作物の表現部分である場合に限って依拠性を認める説」(限定肯定説)です9『AI と著作権』112 頁、120 頁〔奥邨〕。
両説の違いを図示すると以下のとおりとなります(図53)。
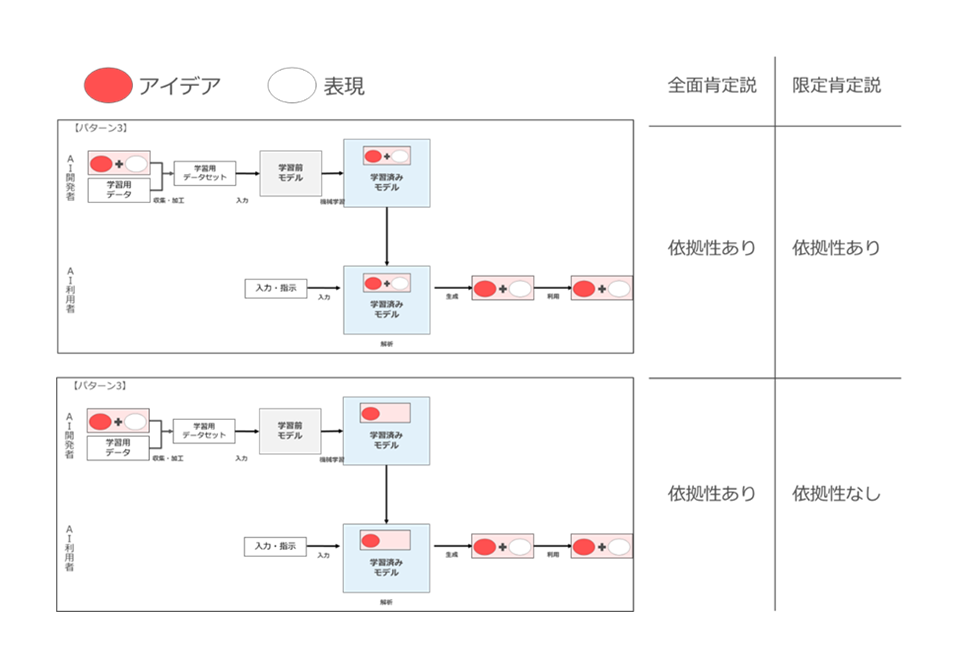
図53
そのうえで、全面肯定説は、学習用データに既存著作物(学習対象著作物)が含まれていれば、AI内に保持されているのが、学習対象著作物の「アイデア+表現」であろうと(上の図)、「アイデア」のみであろうと(下の図)依拠性を認める考え方です10ただし、厳密には全面肯定説は、AI モデル内に保持されているのは常に「アイデア+表現」であり、図53のような区分は存在しないことを前提としている。。
一方、限定肯定説は、学習用データに既存著作物(学習対象著作物)が含まれていても、AI内に保持されているのが学習対象著作物の「アイデア」のみ(下の図)であれば依拠性を否定する考え方です。
つまり、AI内に保持されているのが学習対象著作物の「アイデア+表現」の場合(上の図の場合)は両説の帰結に違いはありません。
学説的には、どちらかというと全面肯定説が多いように思われますが11 『AI と著作権』271 頁以下、「考え方」34頁には、この点に関して以下の記載があります。
② AI 利用者が既存の著作物を認識していなかったが、AI 学習用データに当該著作物が含まれる場合
✓ AI 利用者が既存の著作物(その表現内容)を認識していなかったが、当該生成 AI の開発・学習段階で当該著作物を学習していた場合については、客観的に当該著作物へのアクセスがあったと認められることから、当該生成 AI を利用し、当該著作物に類似した生成物が生成された場合は、通常、依拠性があったと推認され、AI 利用者による著作権侵害になりうると考えられる。
✓ ただし、当該生成 AI について、開発・学習段階において学習に用いられた著作物の創作的表現が、生成・利用段階において生成されることはないといえるような状態が技術的に担保されているといえる場合(*)もあり得る。このような状態が技術的に担保されていること等の事情から、当該生成 AI において、学習に用いられた著作物の創作的表現が、生成・利用段階において出力される状態となっていないと法的に評価できる場合には、AI 利用者において当該評価を基礎づける事情を主張することにより、当該生成 AI の開発・学習段階で既存の著作物を学習していた場合であっても、依拠性がないと判断される場合はあり得ると考えられる。
(*)
具体的には、学習に用いられた著作物と創作的表現が共通した生成物が出力されないよう出力段階においてフィルタリングを行う措置が取られている場合や、当該生成 AI の全体の仕組み等に基づき、学習に用いられた著作物の創作的表現が生成・利用段階において生成されないことが合理的に説明可能な場合などが想定される。
この記載を前提とすると、「考え方」に示されているのは、限定肯定説そのものではないかと思われます。
同記載は、学習対象に既存著作物が含まれており、当該既存著作物に類似した生成物が生成された場合、通常は依拠性があったと推認されるとする一方で「当該生成 AI において、学習に用いられた著作物の創作的表現が、生成・利用段階において出力される状態となっていないと法的に評価できる場合」には、依拠性が否定される可能性があるとしているからです。
筆者としては、著作権に関する表現・アイデア二分論からすると、むしろ限定肯定説の方が筋が通っているのではないかと思われること、プログラム開発におけるクリーンルーム方式では依拠性が否定されていることからすると12『AI と著作権』121 頁以下〔奥邨〕、「考え方」にも示されている限定肯定説が妥当だと考えます。
また、全面肯定説にたつと、大量の学習用データの中にわずか1つ含まれていた著作物と同一・類似のAI生成物がたまたま生成された場合でもAIによる依拠が肯定され、著作権侵害に該当することになりますが、そのような解釈を採用すると、AI開発者やAI利用者が不測の損害を被ることとなり、AIの開発や利用に大きな萎縮的効果が生じると思われます。
以上を前提にした依拠性判断についてのフローチャートが下図のとおりとなります(図54、再掲)。
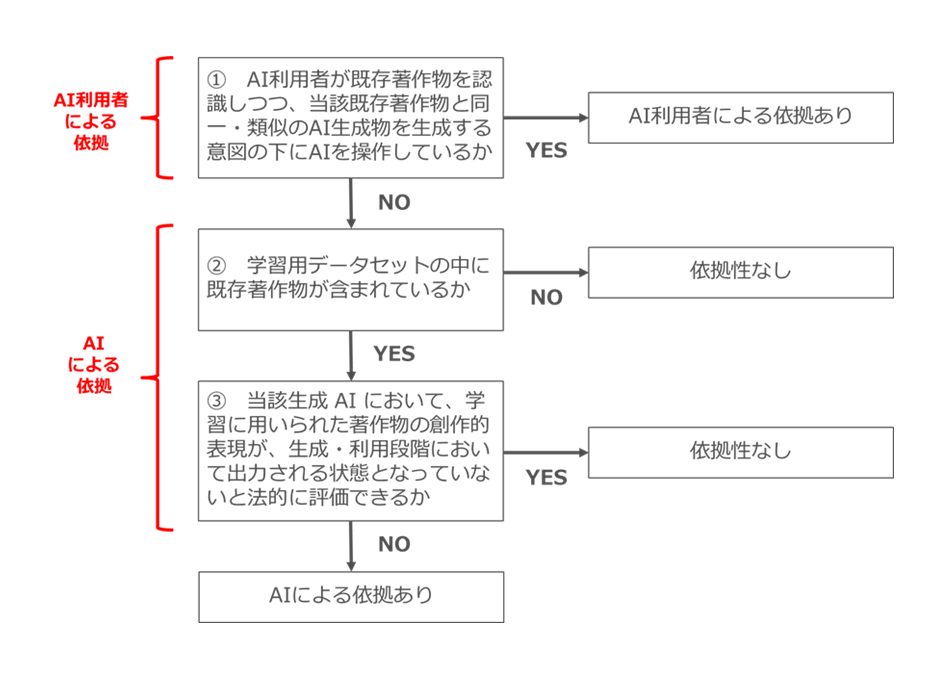
図54
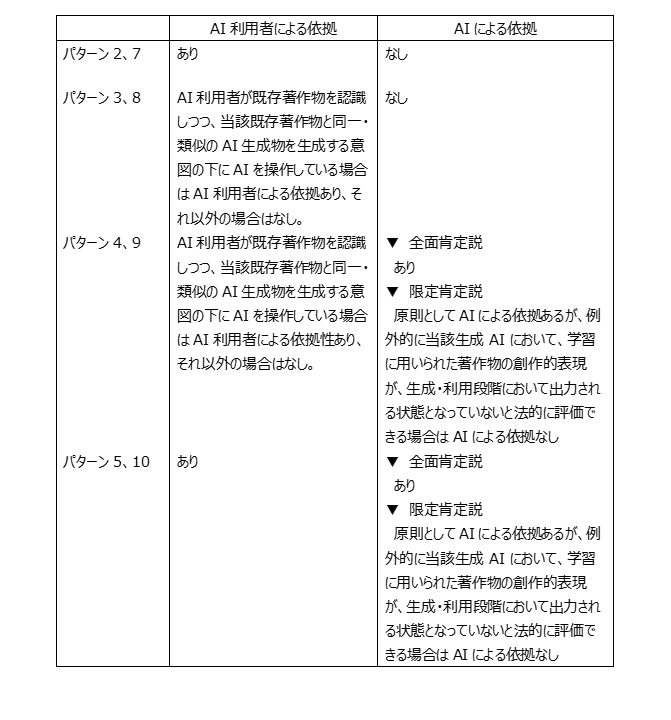
表9
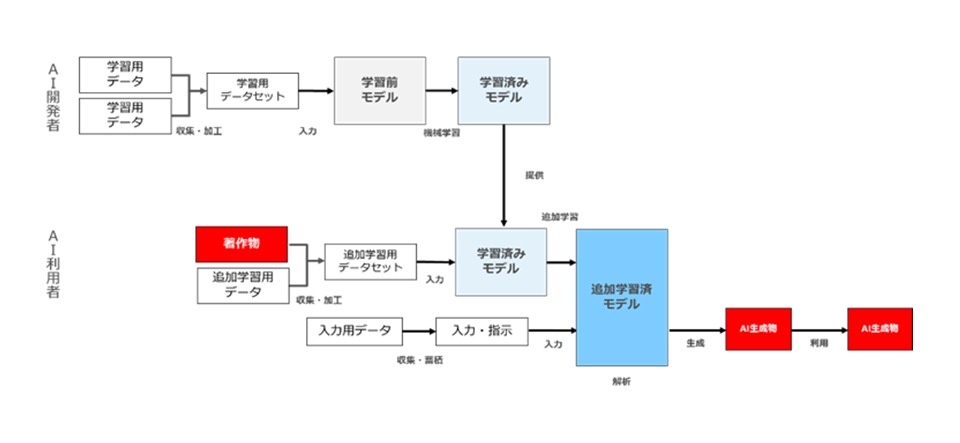
図55
(イ)権利者は依拠性を証明するために実際には何をすれば良いのか
もっとも、「依拠性」について、図52のフローチャートを元に判断するにしても、実際には「AI利用者の認識・意図」(AI利用者による依拠)や「学習用データセットの中に既存著作物が含まれているか」「当該生成 AI において、学習に用いられた著作物の創作的表現が、生成・利用段階において出力される状態となっていないと法的に評価できるか」(AIによる依拠)について、権利者が直接立証することは非常に難しいといえます。
「依拠性」については、著作権侵害を主張する権利者に主張立証責任がありますが、既存の判例・裁判例においては、被疑侵害者の既存著作物へのアクセス可能性、すなわち既存の著作物に接する機会があったことや、類似性の程度の高さ等の間接事実により依拠が推認され、被疑侵害者(被告)がそれを覆せない限り、依拠が肯定されてきました14『AI と著作権』124 頁〔奥邨〕、「考え方」33 頁〜34 頁。
それを前提とすると、実際に権利者が依拠性(「AI利用者による依拠」または「AIによる依拠」)を証明するためには、以下のような主張立証を行うことになると思われます。
(ⅰ) AI利用者による依拠の主張立証
この点については、従来の著作権侵害訴訟と同様となります。
すなわち、権利者としては、既存著作物が世の中によく知られている著作物であること、被疑侵害者において既存著作物へのアクセス可能性があったことや、生成物に既存著作物との高度な類似性があること等を立証すれば、依拠性(AI利用者による依拠)があるとの推認を得ることができると思われます15「考え方」34 頁、『AI と著作権』125 頁脚注41〔奥邨〕。
(ⅱ) AIによる依拠の主張立証
① 主張立証責任の分配
AIによる依拠に関する主張立証責任の分配としては、限定肯定説を前提とすると、権利者が「学習用データセットに既存著作物が含まれていること」を主張し、それが直接立証される、あるいは間接事実から推認される場合に、被疑侵害者がそれに対する反論として「当該生成 AI において、学習に用いられた著作物の創作的表現が、生成・利用段階において出力される状態となっていないこと」を主張立証すべきと考えます16全面肯定説を前提とすると、依拠性については「学習用データセットに既存著作物が含まれていること」を権利者が立証できるかだけが問題となる。。
② 「学習用データセットに既存著作物が含まれていること」の主張立証
権利者は、まず「学習用データセットに既存著作物が含まれていること」を直接的に立証することが考えられます。
典型的には、AI生成物の生成に用いられたAIの学習用データセットの開示をAI開発者に対して求めたうえで、それにより直接立証する方法です。
具体的には、法第114 条の3(書類の提出等)や、民事訴訟法上の文書提出命令(同法第 223 条第1項)、文書送付嘱託(同法第 226 条)等に基づく開示請求が考えられます17「考え方」38 頁。
もっとも、AI開発者が不明、あるいは連絡方法が不明等の理由により、AI開発者に対する学習用データセットの開示請求が難しい場合もあると思われます。そのような場合は間接事実により依拠性を推認させることとなります。
「学習用データセットに既存著作物が含まれていること」を推認させる具体的な間接事実としては、① 既存著作物が世の中によく知られている著作物であること、②当該既存著作物とAI生成物の高度な類似性、③少ない試行回数で類似度が高い表現が生成されることなどが考えられます18 『AI と著作権』125 頁〔奥邨〕。
③ 当該生成 AI において、学習に用いられた著作物の創作的表現が、生成・利用段階において出力される状態となっていないことの主張立証
権利者側が「学習用データセットに既存著作物が含まれていること」を直接立証、あるいは間接事実により推認させた場合、被疑侵害者(被告)側としては「当該生成 AI において、学習に用いられた著作物の創作的表現が、生成・利用段階において出力される状態となっていないこと」を主張立証しなければなりません。
その点の主張立証はかなり難しいのではないかと思われますが19『AI と著作権』125 頁〔奥邨〕 、「考え方」は例として以下の2点を紹介しています(「考え方」34頁)。
① 学習に用いられた著作物と創作的表現が共通した生成物が出力されないよう出力段階においてフィルタリングを行う措置が取られている場合
② 当該生成 AI の全体の仕組み等に基づき、学習に用いられた著作物の創作的表現が生成・利用段階において生成されないことが合理的に説明可能な場合
①については、AI開発者において実際にそのような措置をとっていればAI利用者がその点を主張立証することは可能だと思われます。
一方、②が具体的にどのような場合を指しているかは明確ではありませんが、これは、当該生成AIモデルの学習・生成に用いられるAI技術の内容に依存するでしょう。
例えば、現在の画像生成AIは拡散モデルの技術を利用していることが多いので、以下それを前提に説明します。
非常に単純に言うと、拡散モデルにおいては、学習時と生成時において以下のような内容の処理が行われます(図56)。
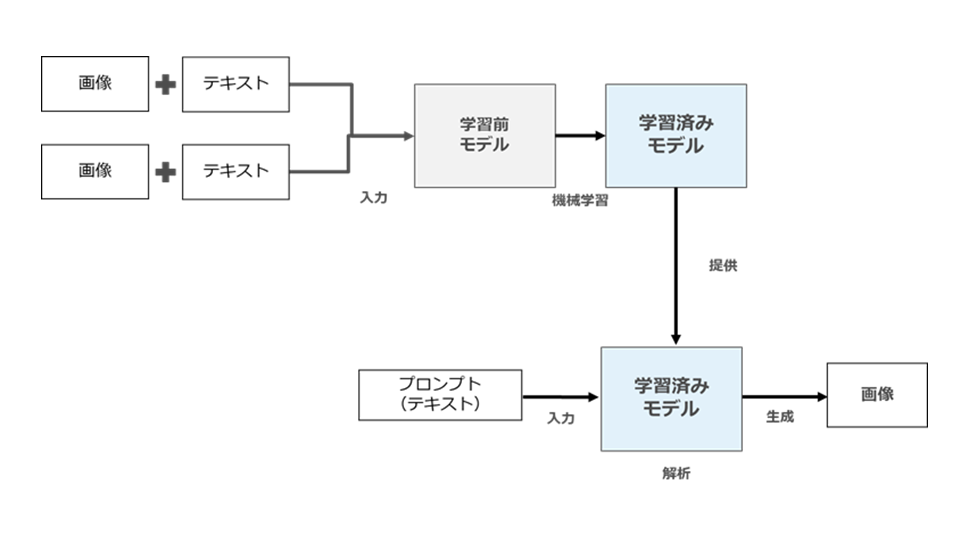
図56
① 学習時
「特定の画像」と「当該画像を説明するテキスト」を組み合わせて大量に学習させてAI内部のパラメータを調整・生成する。
② 生成時
あるテキストがプロンプトとして入力されると、パラメーターを利用して「当該テキストをうまく表現するような画像」が生成(シードノイズから徐々にノイズを除去して当該テキストに寄った画像が生成)される。
開発・学習段階で生成された生成AI内部のパラメーターとは、比喩的に表現するのであればAI生成物の「設計図」であり、生成・利用段階段階で、テキスト(プロンプト)が入力されると、当該プロンプトと当該「設計図」を参照してAI生成物が生成・出力されます。
そして、その「設計図」には多様なものがありえます。
具体的には、① ある特定のテキスト(プロンプト)が入力されると、高い確率である特定のAI生成物を出力するような、「精度の高い」設計図(いわば、テキストと画像が密結合状態のパラメーター)もありますし、② 特定のテキスト(プロンプト)が入力されても、都度異なるAI生成物を出力するような、「精度の低い」設計図(テキスト・画像が疎結合状態のパラメーター)もあります。
たとえば、①の、テキストと画像が密結合状態の設計図(パラメーター)だと、「犬」というプロンプトを入力すると、何度生成しても同じ画像が生成されます(図57)。
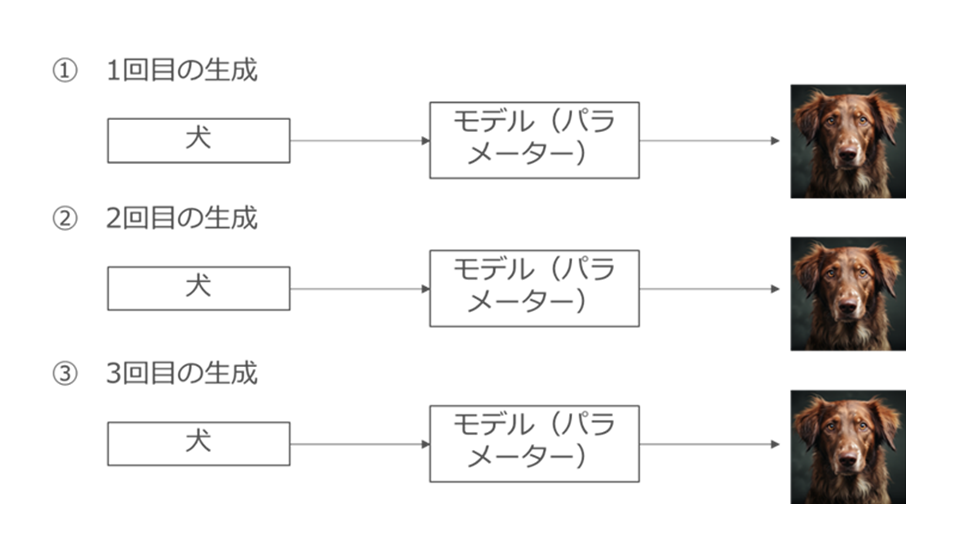
図57
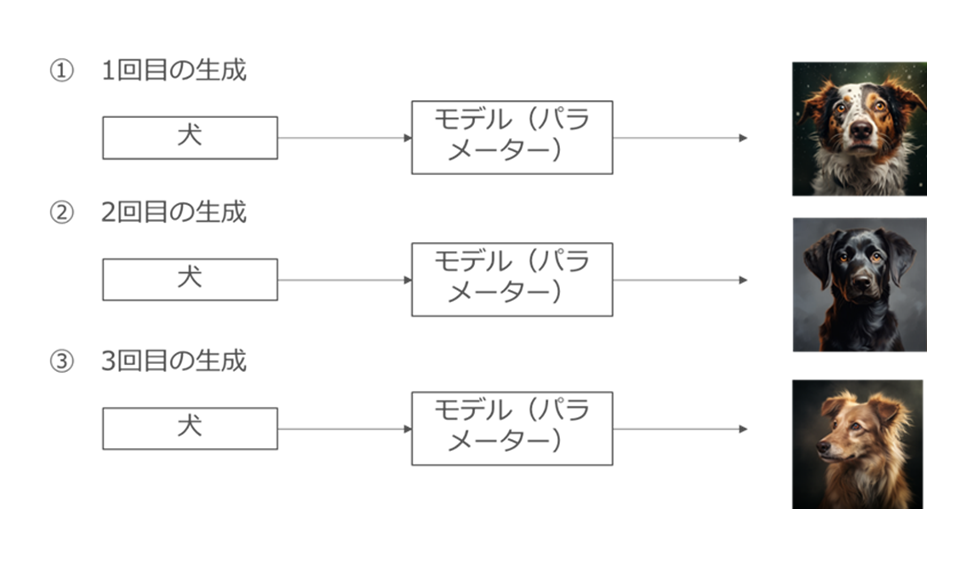
図58
そして、パラメーターは学習によって調整されることから、パラメーターの状態の差異(密結合or疎結合)は、学習のさせ方によって生じるものです。
具体的には、学習段階で「特定のテキスト」+「特定の表現上の特徴を有する画像」で学習させるとテキスト・画像密結合状態の「精度の高い」パラメーターが生成され、生成段階で当該「特定のテキスト」を入力すると、当該「特定の表現上の特徴を有する画像」が精度高く生成されることになります。
たとえば「ピカチュウ」という単語と、あの「ピカチュウ」の様々な大量の画像を組み合わせて学習させた場合、「ピカチュウ」という単語と「ピカチュウ」の画像(の創作的表現)は極めて強く結合して(密結合)学習されます。
これは「ピカチュウ」という単語が造語であり、あの「ピカチュウ」の画像としか結びついていないからです。
このような学習を行うと、生成時に「ピカチュウ」というプロンプトを入力すると、極めて高い確率で「ピカチュウ」の画像が生成されます(図59)。
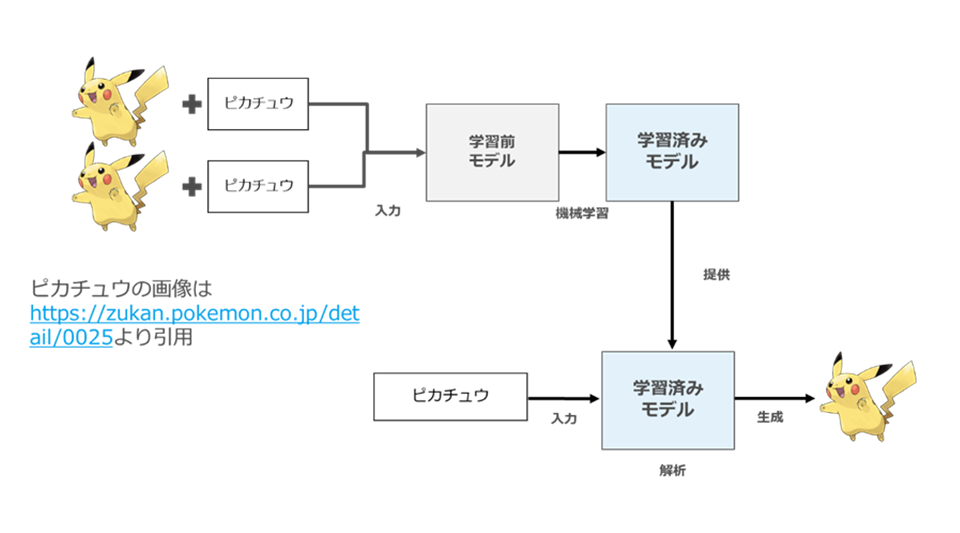
図59
このように疎結合な学習がなされた場合、生成時に「ピカチュウ」というプロンプトを入力しても、「ピカチュウ」の画像が生成されることはまず考えられません。「ピカチュウ」という単語は造語ですし、そもそも学習に用いられていない単語だからです212024 年9月現在で提供されている主要な画像AI サービスにおいては「ピカチュウ」という単語をプロンプトとして入力しても著作権侵害防止のため画像生成ができない。そのため本図では「?」と表示している。 (図60)。
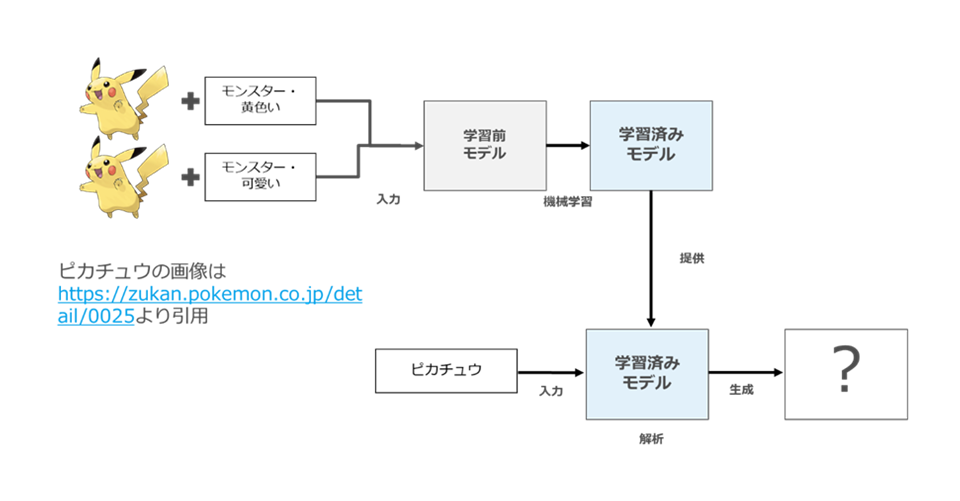
図60
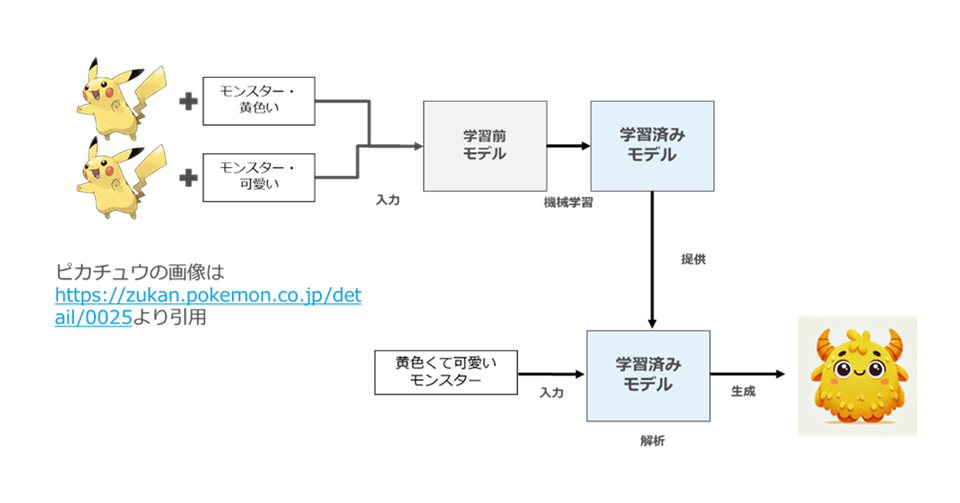
図61
具体的にどのような場合がこの「当該生成 AI の全体の仕組み等に基づき、・・・合理的に説明可能な場合」に該当するかは、当該生成AIモデルの学習やAI生成物の生成に用いられるAI技術の内容に依存するでしょう。
(ⅲ) まとめ
以上述べたように、AI利用者による依拠にせよ、AIによる依拠にせよ、依拠性を直接立証することは困難なことが多いため、実際の訴訟では、いずれが間接事実を証明できるかが勝負の分かれ目になるのではないかと思われます。
AI利用者による依拠と、AIによる依拠に関する原告と被告の主張立証構造を整理したのが以下の図です(図62)。
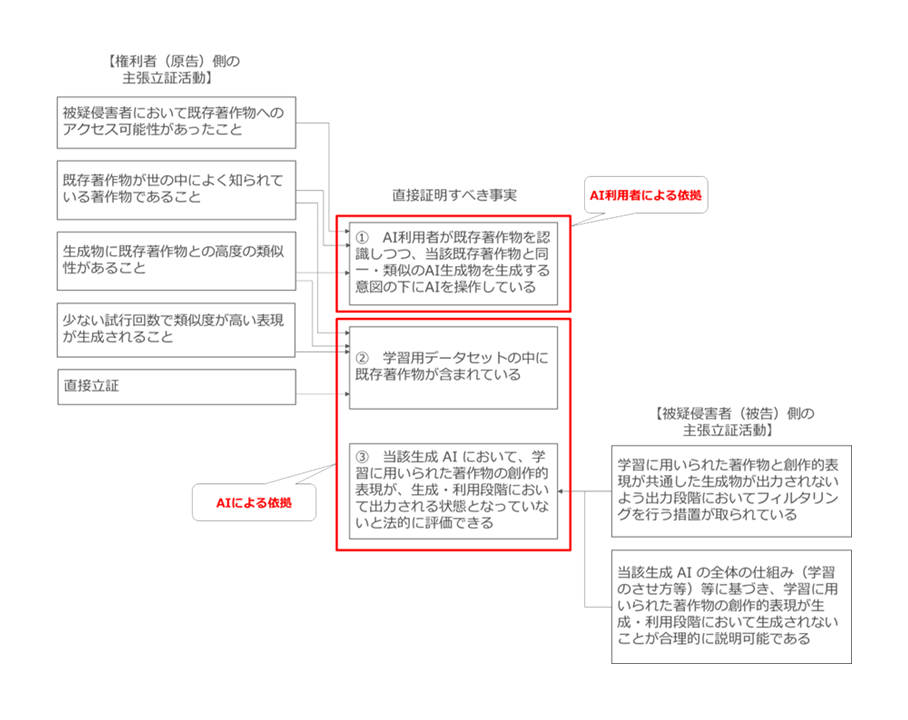
図62
脚注一覧
- 1『AI と著作権』118 頁〔奥邨〕のフローチャート及び「考え方」33 頁〜34 頁をもとに筆者が作成したもの
- 2奥邨先生はこの場合を「操作者による依拠」と呼ぶが(『AI と著作権』109 頁)、本書では「AI 利用者による依拠」と呼ぶこととする。
- 3『AI と著作権』で愛知先生は「単にそのAI 利用者が既存の著作物を知っています(中略)というときに、なんらAI がアクセスしていない(筆者注:学習用データに既存著作物が含まれていないこと)というときに、果たして依拠を肯定できるのかというのは、ちょっと疑問が残るところではあります」とする(277 頁)、また、同じく横山先生もこのケースで依拠性を否定する(281 頁)。
- 4『AI と著作権』280 頁〔愛知〕
- 567)『AI と著作権』268 頁〜285 頁では、この論点を巡って激しく議論がされている。もっとも奥邨先生も「AI 利用者が既存の著作物を認識して(知って)生成した」だけで依拠性を肯定しているわけではないように思われる(「AI を使って、意図的に似たものを出力した、そしてそれを世間に出していくという場合には(出さなくてもいいですけども)」(268 頁)、「Bが描いたものを、似ているとわかって世に出せば」(278 頁)、「ドラえもんとインプットしなくても、未来から来た猫型ロボットと入力して、100 万回試してそのうちの1回がドラえもんでそれを世に出すというのでも、操作者に依拠を認めてよいと思っています」(280 頁)、「私としては、詳しい指示をしなくても、操作者が見聞きした著作物に似てるものがAI から出力されて、操作者は似ていることが分かった上でそれを選ぶのならば、操作者による依拠ありだと思うんです。」(281 頁)
- 6『AI と著作権』114 頁〔奥邨〕
- 7前田健「生成AI の利用が著作権侵害となる場合」法学教室523 号28 頁、『AI と著作権』114 頁、120 頁、123頁〔奥邨〕、本山雅弘「生成AI による著作物の利用主体―生成AI による類似表現物の作出行為における利用行為の成否とその主体―」SOFTIC Law Review 1巻2号(2024)14 頁
- 870)愛知靖之「AI 生成物・機械学習と著作権法」パテント73 巻8号(2020)143 頁〜144 頁。また、本山先生も「AI 生成の基礎とされた学習済みモデルに記録されたのが学習対象著作物のアイデアと評価される部分に過ぎないとしても、そのことから直ちに、当該AI 生成物に依拠性を欠くとして権利保護範囲を遮断することは困難と解されよう。」とする(本山雅弘「生成AI による著作物の利用主体―生成AI による類似表現物の作出行為における利用行為の成否とその主体―」SOFTIC Law Review 1巻2号(2024)16 頁)。
- 9『AI と著作権』112 頁、120 頁〔奥邨〕
- 10ただし、厳密には全面肯定説は、AI モデル内に保持されているのは常に「アイデア+表現」であり、図53のような区分は存在しないことを前提としている。
- 11『AI と著作権』271 頁以下
- 12『AI と著作権』121 頁以下〔奥邨〕
- 13パターン1と6はそもそも類似AI 生成物の「生成」が行われていないので検討対象外。
- 14『AI と著作権』124 頁〔奥邨〕、「考え方」33 頁〜34 頁
- 15「考え方」34 頁、『AI と著作権』125 頁脚注41〔奥邨〕
- 16全面肯定説を前提とすると、依拠性については「学習用データセットに既存著作物が含まれていること」を権利者が立証できるかだけが問題となる。
- 17「考え方」38 頁
- 18『AI と著作権』125 頁〔奥邨〕
- 19『AI と著作権』125 頁〔奥邨〕
- 20『AI と著作権法』298 頁〔谷川発言〕
- 212024 年9月現在で提供されている主要な画像AI サービスにおいては「ピカチュウ」という単語をプロンプトとして入力しても著作権侵害防止のため画像生成ができない。そのため本図では「?」と表示している。
- 22図61 における生成画像は、筆者がChatGPT-4o に「黄色くて可愛いモンスター」というプロンプトを入力して生成した画像である。
この記事の内容を、対話形式の音声で聞くことができます。
▶ 対話形式で聞く
※ 対話形式の音声はNotebookLMを利用して自動的に作成したものです。正確な内容は記事本文をご参照ください。












