人工知能(AI)、ビッグデータ法務
弁護士が非エンジニアの方に贈る「AIと法律・知的財産」の全体像と「AIの技術的基礎」(前半)
Contents
■ はじめに
(私も含めた)非エンジニアの方にとって、機械学習・深層学習の技術的な基礎を理解するのはかなりハードルが高いものです。
行列、ニューラルネットワーク、パーセプトロン、関数、活性化関数、損失関数、目的関数、線形、非線形等々聞いただけで怖じ気づくような言葉の数々。
ちなみに、私が高校の数学で「行列」について習った際の記憶としては、数学の先生が「行列」の「行」というたびに水平に手刀を切り、「列」というたびに垂直に(しかも一歩前に踏み込みながら)手刀を切る癖のある先生だったので、おかげで「行」が横で、「列」が縦であるということだけが頭に刻み込まれました。
中野先生、ありがとうございます。
「行列」に関する私の知識はそれだけです。
さて、AIの生成や活用自体をビジネスとしている会社はもちろん、AIを自社のビジネスに有効活用していこうとする会社にとって「AIと法律・知的財産」は避けて通れないテーマです。
それらの論点を正確に理解するためには、法律や知財の知識だけでは足りず、機械学習・深層学習の技術的な基礎をがっちりと掴まえることが必要不可欠です。
その意味で経営者、事業部門、マーケティング部門、法務部門、知財部門の方など非エンジニアの方が機械学習・深層学習の技術的な基礎を理解することで、会社全体のAIの理解力が非常に上がるのではないかと思います。
この記事では,前半でAIと法律・知的財産に関する論点の全体像を説明し、後半で機械学習・深層学習の技術的な基礎を非エンジニアの方でも理解できるようになるべく平易に解説してみました。
■ AIと法律・知財に関する問題領域の概観~AIの適法な生成、保護、活用、法的責任~
AIと法律・知的財産については様々な論点があります。
私は、AIと法律・知財についてのセミナーなどを行う際には、以下の図を用いて問題領域の全体像をまず説明することにしています。
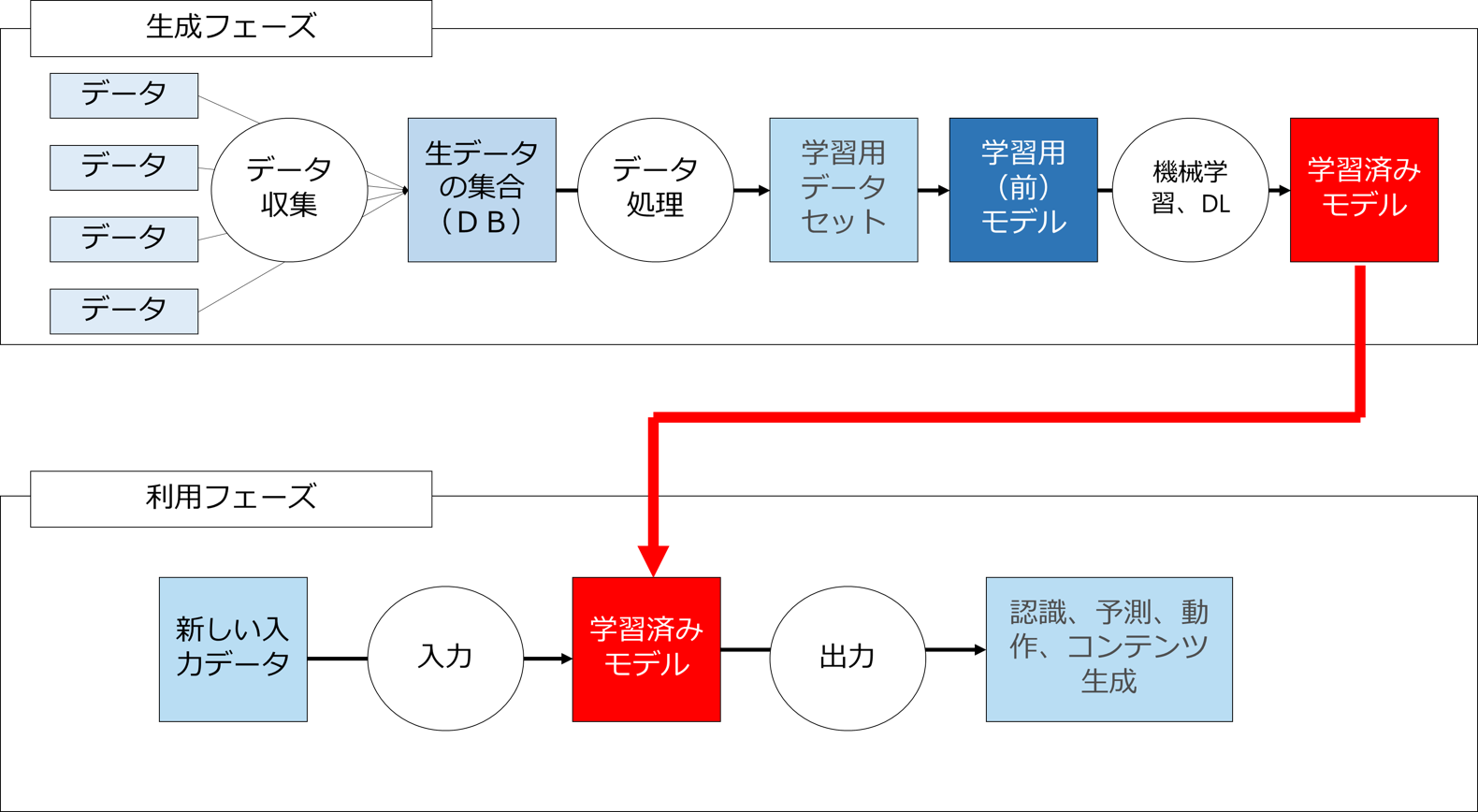
AIについては、大きく分けると「生成フェーズ」と「利用フェーズ」が存在します。
「生成フェーズ」とは、データを用いて学習作業を行って学習済みモデルを生成するフェーズ、「利用フェーズ」とは生成された学習済みモデルを用いて目的とする処理(たとえば画像認識や予測、機械翻訳やコンテンツ生成)を行うフェーズです。
そして、AIと法律・知財に関する論点もこの両フェーズに対応して存在し、「生成フェーズ」に関しては「様々なデータから適法にAIを生成する方法」「生成された学習済モデルの帰属」「学習済みモデルの保護方法」が問題となり、「利用フェーズ」においては「AI生成物の保護方法」「AI利用によって損害が発生した場合の法的責任」が問題となります。
様々なデータから適法にAIを生成する方法
AIの生成には一般的に大量のデータが必要ですが、当該データには第三者が何らかの法的権利(著作権、肖像権等)を有していたり利用に関して様々な法的規制が存在するもの(個人情報など)が存在します。AIを生成する際にそれらのデータを適法に利用するにはどうしたらよいかというのがここでの問題です。
例えばこのような問題。
・ WEB上の無数の画像データを利用して学習用データセット及び画像認識用モデルを適法に生成するにはどうしたらよいか
・ WEB上の無数の画像データを利用してモデル生成のための学習用データセットを生成し、ネットに公開したり不特定の第三者に販売する行為は適法か
・ 医療用読影AIのために、大量の医療画像を利用して、学習用データセット及び画像認識用モデルを適法に生成するにはどうしたらよいか
詳細は以下の2つの記事を参照下さい。
▼ 第三者のデータやデータセットを利用して適法にAIを生成するための基礎知識
▼ 萌えキャラ生成AIを題材に「AIビジネスと法律」を学ぼう
生成された学習済モデルの帰属
共同開発契約を締結した上で、先方から生データの提供を受けて当社においてモデルを生成することになっているが、生成されたモデルの帰属や利用方法についてどのような契約交渉をしたらよいか。
データの収集から加工、学習済みモデルの生成までを1つの事業者が行う場合ももちろんあるのですが、現在ではデータを保有している企業(以下「データ保有企業」という)が学習済みモデルを生成する企業(以下「AI生成企業」という)に学習済みモデルの生成を委託することの方が多いと思われます。
たとえば医療用の読影AIを生成する場合、大量の医療用画像データが必要となりますが、それらの医療用画像データを保有している医療機関自らが学習済みモデルを生成するのではなく、AI生成企業に当該データを提供して学習済みモデルを生成して貰うことになります。
そのようにデータ保有企業とAI生成企業が異なる場合、生成された学習済みモデルがどちらの当事者に帰属するのかというのが「生成された学習済モデルの帰属」に関する問題です。
この問題は実務では非常にシビアな問題であり、精度が高い学習済みモデルができたときほど問題が先鋭化します。
学習済みモデルの生成作業を委託するに際して何らかの契約を締結するのが通常であることから、当該契約の中で「生成された学習済モデルの帰属」についての各種条項を定めるべきなのですが、実際には明確に定められていないことのほうが多いのです。
この問題については経産省が「データ契約ガイドライン検討会」を開催し、具体的なユースケース検討を通じて「契約によるデータの適切な利用やAIに係る責任関係・権利関係を含む法的問題への対応」のためのガイドライン改訂のための検討を行っています。
ちなみに筆者も同検討会のメンバーの一員でして、2018年3月にガイドラインの改訂版が出される予定です。
学習済みモデルの保護方法
深層学習によりAIを生成する際には、大量の生データを用いて学習用データセットを生成し、当該学習用データセットを用いてDLを行って学習済みモデルを生成します。
学習済みモデル生成のためには質の良いデータセットと強力な計算資源が必要であるため、AIの中核的価値は学習済みモデルにあると言ってよいでしょう。
したがって自ら、あるいは外注して生成した学習済みモデルをどのように保護するかはビジネスにおいて非常に重要な課題となります。
たとえば以下のような問題です。
工場用ロボット操業用の学習済モデルを生成したうえでロボットに組み込んでメーカーX社に納品したが、X社の担当役員によりモデルごとロボットが持ち出されてZ社に持ち込まれ、Z社により同じモデルを組み込んだロボットが販売された。どのように対処したら良いか。
別の機会に説明しますが、学習済みモデルを知的財産制度のみによって保護するのにはいくつかの難問があるため「技術」「契約」「法律(知的財産制度)」によって総合的に保護することを考えなければなりません。
詳細はこの記事を参照下さい。
▼ AIにおける学習済モデルを守る3つの方法(基礎編)
AI生成物の保護方法
・ 過去3年分の自分の詳細なライフログ、その日の自分のスケジュールや外部環境(天気、温度、湿度等)を元に、「ボタンを押せばその瞬間最も自分が心地よく感じる音楽」を自動生成する音楽生成AIを自分のためだけに作成した。毎日快適に使っており、AIが生成した音楽のうち気に入ったものについては自分のブログにアップしていた。そうしたところある日、自分のブログにアップしたAI生成音楽が無断で他の人のブログに転載されているのを発見した。どのように対処したら良いか。
・ 過去の金相場の値動きデータや、相場に影響を及ぼす可能性のあるデータを元に、金相場を予測する高精度の投資アドバイス用AIを開発した。クラウド上でサービスを提供することとし、利用契約を締結した会員のみが限定してアドバイスを受けられるようにした。しばらくして同種のサービスを提供する競合サービスが現れたが、当社のAIによるアドバイスと全く同一であり、当社AIによる出力結果のみをどこからか入手して利用していると思われる。どのように対処したら良いか。
AIが自動生成した生成物が法的に保護されるかがここでの論点です。
絵画や音楽、ロゴ、テキストなどをAIが自動生成するサービスが近時爆発的に増えていますが、そのようないわゆるコンテンツに限らず、何らかの判定・判断・提案結果などをAIが生成することも当然ありえます。したがって「一定の入力に基づき、学習済みモデルが出力したもの」という意味でのAI生成物の保護が問題となります。
この論点については、平成29年3月に知的財産戦略本部から出された「新たな情報財検討委員会報告書-データ・人工知能(AI)の利活用促進による産業競争力強化の基盤となる知財システムの構築に向けて-」が詳しく論じています。
少し古い記事ですが、当ブログの「人工知能(AI)が作ったコンテンツの著作権は誰のものになるのか?」もご参考まで。
AI利用によって損害が発生した場合の法的責任
・ サザエさん風キャラ生成用AIを作成するためにサザエさんの全てのキャラクターと全ての漫画作品をデータとして用いて学習済モデルを生成した。完成したAIをWEBサービスとして公開し、利用者Aがキャラ作成の指示をしたところ、偶然「アナゴさん」に酷似したキャラクターが生成された。この場合、Aは当該キャラを利用できるのか、またAIをWEBサービスとして提供している事業者は著作権侵害等何らかの責任を負うのか。
・ 医師が利用した読影AIがガンを見落とし、その後ガンが発見された際には既に治療のしようがない手遅れ状態になった場合に、医師やAIメーカーは患者に対して責任を負うのか。
AIの利用によって損害が発生した場合に法的責任を負うのは誰なのかという点はAIの社会実装において非常に重要な論点です。よく論じられるのは自動運転であるが、私が相談されることが多いのは上記のようなケースです。
詳細はこの記事をご参照ください。
▼ AIが偶然に「穴子さん」を生み出した場合、サザエさんの著作権者に怒られるのか?(キャラクター生成AIと著作権問題)
■ まとめ
以上概観したようにAIと法律・知財に関する論点は、「生成フェーズ」に関しては「様々なデータから適法にAIを生成する方法」「生成された学習済モデルの帰属」「学習済みモデルの保護方法」が問題となり、「利用フェーズ」においては「AI生成物の保護方法」「AI利用によって損害が発生した場合の法的責任」など多岐にわたります。
後半では機械学習・深層学習の技術的な基礎を非エンジニアの方でも理解できるようになるべく平易に解説していきます!
(弁護士柿沼太一)












