人工知能(AI)、ビッグデータ法務
萌えキャラ生成AIを題材に「AIビジネスと法律」を学ぼう
Contents
はじめに
AI(人工知能)に関するセミナーやお話をする機会が最近とみに増えているのですが、いつも冒頭で「AIと法律・知財に関する問題領域の概観」をお話しするようにしています。「AIと法律」「AIと知財」は、とにかく論点が多いので、「それらの論点がどこの領域に関するものなのか」を意識しながら聞いて頂くとより理解が深まるためです。
そこでいつも使っている図がこちら。
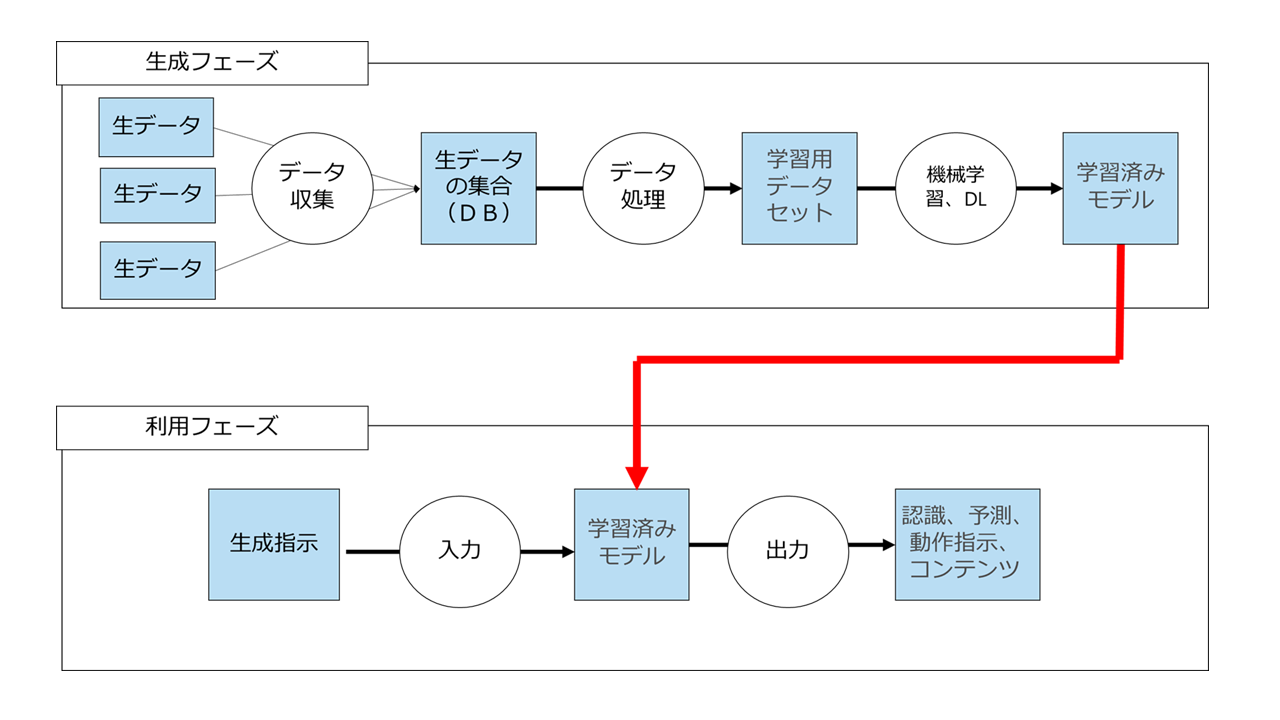
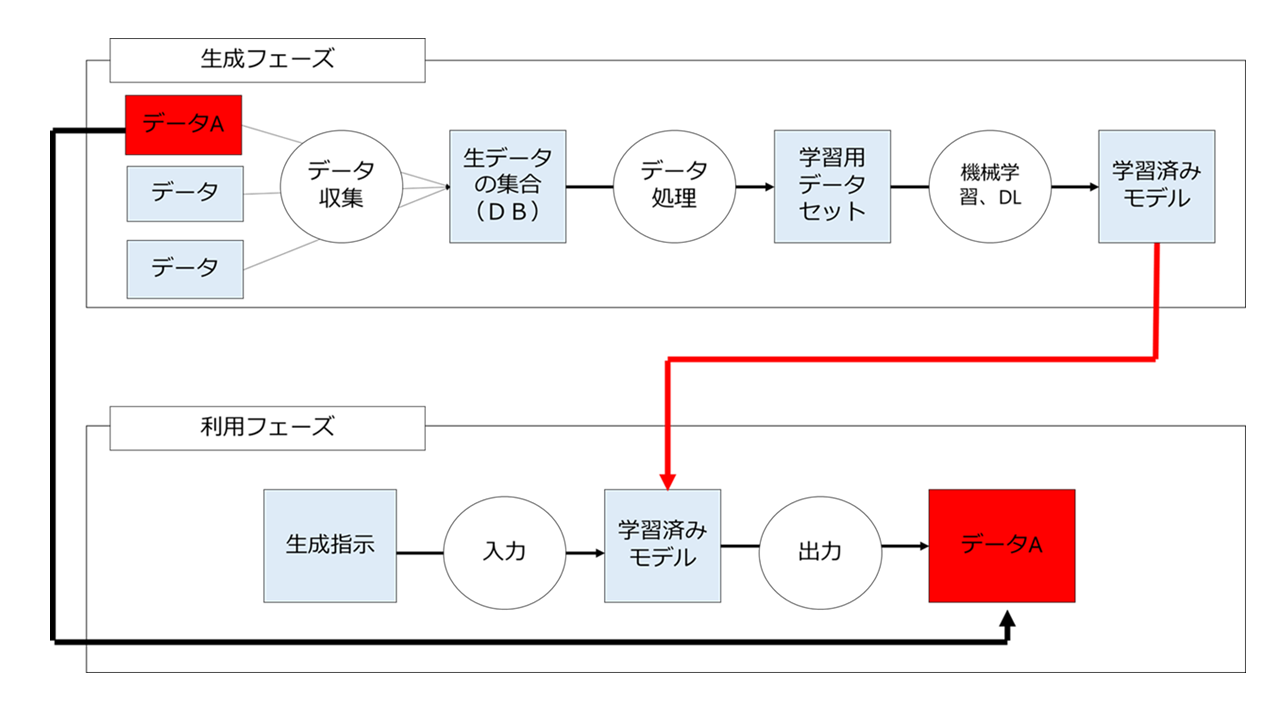
上の段がAIの生成フェーズ、下の段がAIの利用フェーズです。
ただ、これはあくまで抽象的な図なので、より理解を深めていただくため、「AIと法律・知財」に関する論点をカバーするような具体的事例がないかと思っていたところ、見つかりました。
Web系メディアの記者さんから教えて貰ったサービスなのですが、深層学習で萌えキャラを作「MakeGirls.moe」です。
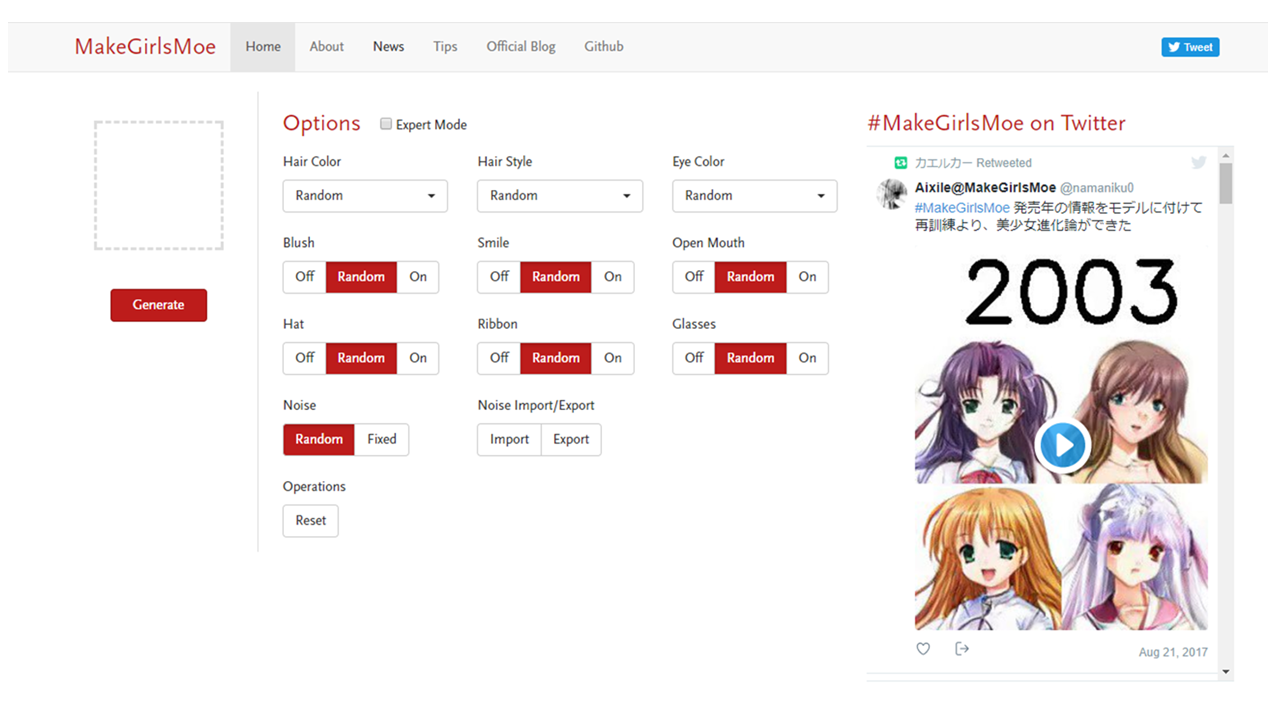
http://make.girls.moe/#/より
これは、各種パラメーターを選択して「生成」ボタンを押すと、AIが自動的に萌えキャラを生成するというサービスです。
開発者の方のブログを見ると、深層学習の中でもGAN(Generative Adversarial Networks、敵対的生成ネットワーク)というフレームワークを利用して萌えキャラを自動生成しているようです。
実は、このサービスは、「AIと法律・知財」に関する論点を理解するのに非常に適した題材です。
たとえば、このサービスを構築するに際しては、大量の萌えキャラデータを読み込んでキャラ生成用のAI(具体的には学習済みモデル)を生成する必要がありますが、そのようなキャラデータの読み込み行為はキャラデータの著作権侵害にならないのでしょうか。
また、それ以外にも
「生成された学習済みモデルは誰のものか」
「学習済みモデルで自動作成した萌えキャラ画像については誰が権利を有するのか」
「自動生成された萌えキャラを俺は愛せるか」
「モデルが自動的に生成した萌えキャラ画像が、学習済みモデル生成に利用した生データの1つに『偶然』似てしまった場合、当該生データの著作権侵害にならないのか」
といった疑問点が湧いてきます。
すみません、疲れているようです。1つ変なのが混じっていました。無視してください。
1 仮に生データを権利者の許諾なくダウンロードしてモデルを生成していた場合、生データの著作権侵害にならないのか
モデル生成に利用しているデータ
先ほどの開発者のブログを読むと、このサービスはAI生成に必要なデータとして、「Getchu」というサイトに掲載されているゲームの立ち絵キャラの画像を利用しているということです。
To teach computers to do things requires high quality data, and our case is not an exception. The quality of images on large scale image boards like Danbooru and Safebooru varies wildly, and we think this is at least part of the reason for the quality issues in previous works. So, instead, we use “standing pictures” (立ち絵) from games sold on Getchu, a website for learning about and purchasing Japanese games. Standing pictures are diverse since they are rendered in different styles for different genres of game, yet reasonably consistent since they are all part of the domain of game character images.
もちろん、「Getchu」から許可を得て利用しているのであれば何の問題もないのですが、ここでは、仮に「Getchu」の許可を取っていなかったとします。
その場合に、「Getchu」掲載のキャラをモデル生成に利用できるか、という問題です。
モデル生成の際に行う作業
生データ収集からモデル生成の一連の流れを図にするとこのようになります。
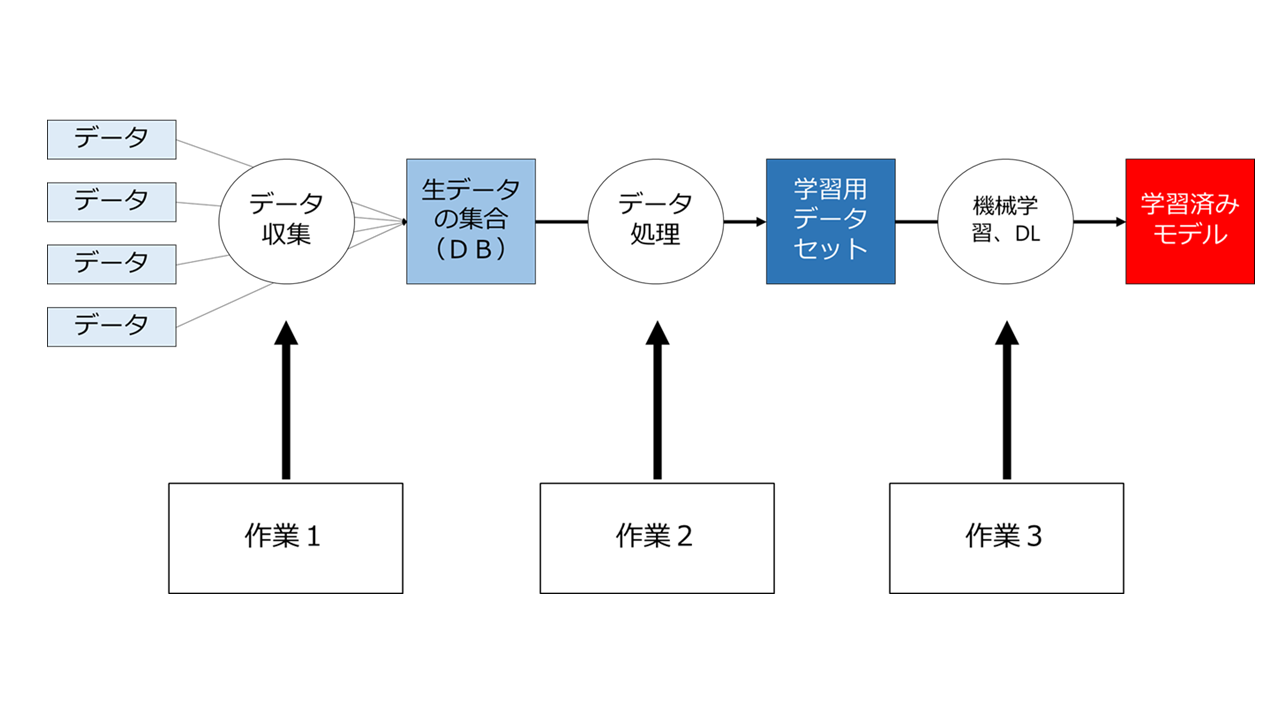
上の図で言う「作業」とは、具体的には、データのコーピーだったり、整形だったり、データセットを用いた機械学習や深層学習ということになりますが、これらの行為を適法に行うにはどうしたらよいのでしょうか。
著作権侵害行為になるようにも思える
具体的には、これらの作業1~3で行っている行為が著作権法上の「複製」や「翻案」に該当するかどうかです。
仮に「複製」や「翻案」に該当すると、著作権者の許可なしに行った場合、原則として著作権侵害行為となります。
まず作業1,2のところです。
この作業1,2においては、生データのダウンロードや整形などを行います。
今回の例でいうと、対象サイト上の画像データをダウンロードする行為ですし、あるいは買ってきた漫画をスキャンしてデジタルデータ化するなどの行為ですね。
この作業1,2においては明らかに、生データの「複製」や「翻案」を行っていることになります。
作業3はどうでしょうか。
作業3における機械学習や深層学習行為自体は、データセットの「複製」でも「翻案」でもありません。
「複製」とは「印刷、写真、複写、録音、録画その他の方法により有形的に再製すること」(著作権法2条1項15号)、「翻案」とは簡単にいうと「ある著作物の表現上の本質的な特徴の同一性を維持しつつ,具体的表現に修正,増減,変更等を加える行為」(最高裁江差追分事件)ですが、通常は、生成された学習済みモデルの中には生データや学習用データセットの痕跡は全く残ってないからです(ちなみに、データセットのデータ構造がほぼそのままモデルの中に残るモデル生成方法もあるようです。そのような場合には別途検討が必要です)
ただ、学習過程で「複製」や「翻案」が行われることはあります。
とすると、結局作業1~3においては、著作権者の同意なく「複製」や「翻案」を行っていることになり、著作権侵害となるように思われます。
日本の機械学習の救世主「著作権法47条の7」
しかし、そこで颯爽と現れるのが著作権法47条の7です。
著作権法47条の7は学習済みモデル生成に際しては非常に重要な条文ですのでぜひ覚えておいてください。
条文は以下のとおりです。
第四十七条の七 著作物は、電子計算機による情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の統計的な解析を行うことをいう。以下この条において同じ。)を行うことを目的とする場合には、必要と認められる限度において、記録媒体への記録又は翻案(これにより創作した二次的著作物の記録を含む。)を行うことができる。ただし、情報解析を行う者の用に供するために作成されたデータベースの著作物については、この限りでない。
簡単に言うと「情報解析」のためであれば、必要な範囲で、著作権者の承諾なく著作物の記録や翻案ができる、というものです(ただし一部例外あり)。
したがって「情報解析」に「機械学習・深層学習」が含まれるとすれば、「機械学習・深層学習」のためであれば著作物について著作権者の承諾なく自由に記録や翻案ができる、ということになります。
そして、この点については、私が知る限りでは、「情報解析」に「機械学習・深層学習」は含まれる、すなわち「機械学習・深層学習」に著作権法47条の7は適用されるという意見が多数を占めていると思います。
そのような見解に立つと、たとえ他人の著作物であっても、機械学習・深層学習のためであれば著作権法47条の7により無許諾で自由に利用できる、ということになります。
さらに、この条文の最大のポイントは、「非営利目的の利用」に限定されていないことです。
つまり営利目的(販売・有償提供目的)の学習済みモデル生成のためにもこの条文は適用されますので、営利目的であっても著作物の「記録・翻案」が可能なのです。
ちなみに諸外国でも日本著作権法47条の7と同趣旨の規定はあるのですが、いずれも非営利目的のみ許容されていますので、営利目的の場合でも適用がある日本著作権法47条の7は、世界的に見ても特異的であり、端的に言うと「著作権法47条の7は日本の機械学習の宝」であり「機械学習するなら日本においで」ということになります。
結論
このように、仮にMakeGirls.moeが、著作権者の許諾を得ないで「Getchu」掲載のキャラをモデル生成に利用していたとしても著作権法47条の7により著作権侵害にはならない、ということになります。
実は、これ以外にも「「Getchu」のライセンス上、著作権法47条の7による利用も禁じる旨規定されていた場合にはどうなるのか」という問題があります。もっとも、この点については、「Getchu」において利用ユーザーが当該ライセンスに同意したことになるのかが若干疑問なので、ここでは割愛します。
2 生成された学習済モデルは誰のものか
このように、生データを利用して学習済モデルを生成した場合、その学習済みモデルに関する権利を誰が持つのか、ということが次に問題になります。
MakeGirls.moeのように、WEB上に公開されているデータを自ら収集してくるケースの場合にはあまり表面化しない論点なのですが、「モデル生成事業者が、特定の第三者が保有しているデータを、当該第三者との間の契約に基づいて提供を受けてモデル生成をした場合」には、この「生成された学習済モデルは誰のものか」は非常にシビアな問題となります(私たちもよく相談を受ける点です)。
たとえば、あるモデル生成事業者が医療用の病変画像発見AIを生成する際には大量の医療画像が必要となりますが、そのような医療画像は現時点では医療機関から提供を受けるしかありません(「現時点では」と書いたのは次世代医療基盤整備法が施行されれば状況が変わる可能性があるからですが、ここでは省略します)。
つまり、医療機関からデータ提供を受けてモデル生成をした場合、そのモデルは医療機関が保有するのか、モデル生成事業者が保有するのか、あるいは共有なのか、ということです。
データ提供者からすれば「データがなければ学習はできないはず。なのでモデルはデータ提供者が保有している」と主張しますし、モデル生成事業者からすれば「生データそのままでは学習ができないので必要なデータ処理をしなければならないし、データのどこに着目して学習するかなどの点に高度なノウハウがある。さらに実際に生成作業をしているのだから、モデル生成事業者がモデルを保有している」と主張したいところです。
もっとも、「データ提供者とモデル生成者が異なった場合に、どちらがモデルに関する権利を保有するか」という点については決まったルールなどはなく、結局のところ契約交渉によって解決するしかないのではないかと考えています。
ここでは、そのような契約交渉におけるポイントだけご紹介します。
1 モデルに関する権利をどちらに帰属させるか
(1) データ提供者
(2) モデル開発者
(3) 共有
2 双方がモデルについてどのような利用(マネタイズ)ができるか
(1) 自己使用
(2) 第三者にライセンスしてロイヤリティ徴収
(3) 譲渡
3 相手方当事者に対する対価支払いの方法・有無
(1) 単発支払
(2) 継続支払
(3) 対価支払いなし
の3点です。
契約交渉により上記1、2、3を適宜組み合わせたスキームを構築していくイメージです。
結果的には、たとえば以下のようなパターンのスキームが考えられます。
▼ パターン1 データ提供者のみに権利帰属・独占利用、モデル制作時にのみモデル開発者に対価を支払う(データ提供者によるモデルの買い切り)
▼ パターン2 データ提供者とモデル開発者がモデルを共有。データ提供者はモデル利用不可。モデル開発者のみがモデルを独占利用できるが、モデル開発者はデータ提供者に継続的な対価を支払う
▼ パターン3 モデルを両者で共有して利益をシェアする
▼ パターン4 モデルを両者で共有して両者それぞれがビジネスを展開し、対価の支払いは行わない
3 生成されたモデルで自動作成した萌えキャラ画像については誰が権利を有するのか
AI著作物は誰が権利を有するのか
これは「AI著作物について誰が権利を持つか」という問題です。
この点については、「AI著作物の創作に人間がどう関与しているかによって結論が変わる」ということになります。
具体的には以下のとおりとなります。
▼ 人間の「創作意図」+「創作的寄与」がある場合
AIを「道具」として利用した人間の創作物であり、当該人間が創作した著作物となる。
▼ 人間の寄与が、「創作的寄与」が認められないような簡単な指示に留まる場合
当該AI生成物は、AIが自律的に生成した「AI創作物」であると整理され、現行の著作権法上は著作物と認められず、だれも権利を保有しない。
具体的なイメージは下記のとおりとなります。
▼ 人間の「創作意図」+「創作的寄与」がある場合
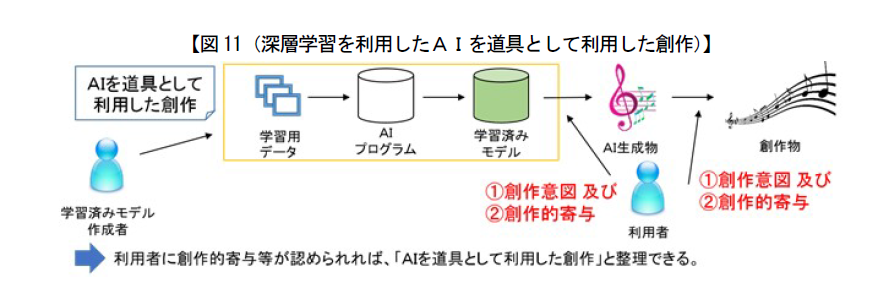
知的財産戦略本部 検証・評価・企画委員会新たな情報財検討委員会による「新たな情報財検討委員会報告書」(平成29年3月)P36より
▼ 人間の寄与が、「創作的寄与」が認められないような簡単な指示に留まる場合
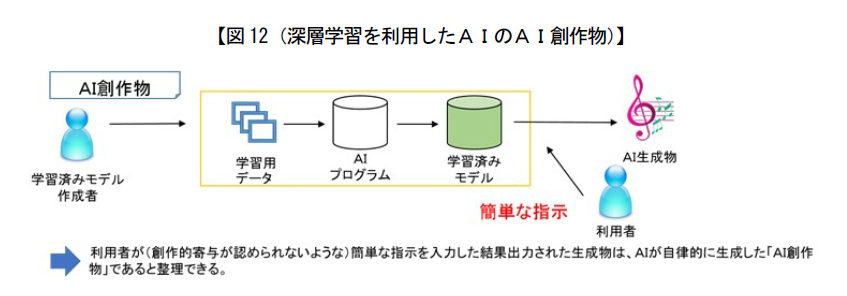
知的財産戦略本部 検証・評価・企画委員会新たな情報財検討委員会による「新たな情報財検討委員会報告書」(平成29年3月)P36より
詳細は知的財産戦略本部 検証・評価・企画委員会新たな情報財検討委員会による「新たな情報財検討委員会報告書」(平成29年3月)P35~36をご参照ください。
以上を簡単にまとめると、人間の「創作意図」「創作的寄与」の有無によって結論が変わるということになります。しかし、これは基準としてはわかりやすいですが、具体的にどのような場合に「創作的寄与」があるかはよくわかりません。
MakeGirls.moeで考えてみましょう。
このサービスは「Options」として「Hair Color」「Hair Style」「Eye Color」「Blush」「Smile」「Noise」「Open Mouth」「Hat」「Noise」「Ribbon」「Glasses」!「Noise Import/Export」の11種類について「Off」「Random」「On」などを選べるようになっています(「Expert Mode」ではもっと微調整可能)。
http://make.girls.moe/「#/より
これを前提とすると「Options」としては、単純計算でも27万通りくらいの組み合わせがありますので、どの「Options」を選ぶのかという点については、選んだ人の「創作的寄与」はあると考えても良いような気がします。
また、大量の萌え画像を生成し、その中から気に入った画像を選別するという行為をした場合にはその選択行為に「創作的寄与」があると考えてもよいかもしれません。
ということで、一応MakeGirls.moeについては、サービスを利用した人に「創作的寄与」ありとして、生成された萌え画像はサービス利用者が著作権を持つ著作物ということになるのではないかと思います(ちなみにこのブログ記事のアイキャッチ画像は、私がこのサービスを利用して生成した萌えキャラです)。
ただ、そうすると、このサービスを利用して大量の萌え画像を生成した利用者がいた場合、それら全ての萌え画像について当該利用者が著作権を持つということになってしまうため、本当にそれで良いのかというのは非常に難しい問題です。その点については私も迷っているところでして、結論は出ていません。
ちなみに、MakeGirls.moeのライセンス条件をみると「The web interface is under the GPLv3 license.」「Model training scripts are under the MIT license. (Available Soon)」としか記載されていないので、サービスを利用して生成された萌えキャラの著作権がサービス提供者に帰属するということにはなっていないようです。
4 モデルが自動的に生成した萌えキャラ画像が、モデル生成に利用した生データの1つに「偶然」似てしまった場合、当該生データの著作権侵害にならないのか
これは以下の図のような問題です。
この点に関しては以前「AIが偶然に「穴子さん」を生み出した場合、サザエさんの著作権者に怒られるのか?(キャラクター生成AIと著作権問題)」にて詳細に解説したので是非そちらをご覧下さい。
結論的には、「依拠性なしとして著作権侵害とならないという考えも十分成り立ちうるが、現行法上の解釈を前提とすると依拠性ありとして著作権侵害となると思われる。」というものです。
5 まとめ
以上をまとめておきます。
MakeGirls.moeについては
1 仮に生データを権利者の許諾なくダウンロードしてモデルを生成していた場合、生データの著作権侵害にならないのか
→著作権法47条の7により、原則として著作権侵害にはならない。
2 生成された学習済みモデルは誰のものか
→MakeGirls.moeサービスの場合はあまり問題にならないが、「モデル生成事業者が、特定の第三者が保有しているデータを、当該第三者との間の契約に基づいて提供を受けてモデル生成をした場合」には、この「生成された学習済モデルは誰のものか」は非常にシビアな問題となる。
3 学習済みモデルで自動作成した萌え画像については誰が権利を有するのか
→モデルを用いて画像を生成するに際して「創作的寄与」があるかどうかの問題だが、MakeGirls.moeの場合は「創作的寄与」ありと解釈されるのではないか。ただし大量にAI画像生成された場合の問題は残る。
4 自動生成された萌えキャラを俺は愛せるか
→自分次第。
5 モデルが自動的に生成した萌え画像が、モデル生成に利用した生データの1つに「偶然」似てしまった場合、生データの著作権侵害にならないのか
→現行法では「依拠性」ありとして著作権侵害の可能性高い。












