人工知能(AI)、ビッグデータ法務
弁護士が非エンジニアの方に贈る「AIと法律・知的財産」の全体像と「AIの技術的基礎」(後半)

Contents
■ はじめに
前回の記事で、以下のように書きました。
・ AIの生成や活用自体をビジネスとしている会社はもちろん、AIを自社のビジネスに有効活用していこうとする会社にとって「AIと法律・知的財産」は避けて通れない
・ それらの論点を正確に理解するためには、法律や知財の知識だけでは足りず、機械学習・深層学習の技術的な基礎をがっちりと掴まえることが必要不可欠。
・ その意味で経営者、事業部門、マーケティング部門、法務部門、知財部門の方など非エンジニアの方が機械学習・深層学習の技術的な基礎を理解することで、会社全体のAIの理解力が非常に上がるのではないか。
【参考記事】
弁護士が非エンジニアの方に贈る「AIと法律・知的財産」の全体像と「AIの技術的基礎」(前半)
前回の記事では,AIと法律・知的財産に関する論点の全体像を説明しましたので、後半である本記事では、機械学習・深層学習の技術的な基礎を非エンジニアの方でも理解できるようになるべく平易に解説してみたいと思います。
なお、あくまで基礎的な理解のための説明なので、技術的に若干不正確だったり割愛している部分があることについてはご容赦ください。
1 AIとは何か
まずそもそもAIとは何かということですが、法的、あるいは公的な定義は特に存在せず論者によって様々な定義付けがされています。
たとえば、人工知能の著名な研究者である松尾豊東大准教授の定義は「人工的につくられた人間のような知能、ないしはそれを作る技術」としていますし、長尾真京都大学名誉教授は「人間の頭脳活動を極限までシミュレートするシステム」、浅田稔大阪大学大学院工学研究科教授に至っては「知能の定義が明確でないので、人工知能を明確に定義できない」としています。
ただ、AIについて厳密に定義をする必要もあまりないので、ここでは簡単に「人間の知的能力の一部または全部をコンピュータで代替する」ということだと捉えておけば十分だと思われます。
2 AIの目的
そもそもAIはどのような目的のために開発されているのでしょうか。
それは人間が行っている知的な活動、たとえば
▼ ある画像が猫なのか、ピューマなのか、トラなのかの分類・認識
▼ 株価の予測
▼ 顧客への商品リコメンド
▼ 目の前の信号は青信号だが、歩行者が信号無視して横断しており、一方後続車は歩行者に気づかずにかなりのスピードで自車に追従している。どのように運転したらよいか。
▼ 翻訳
などを、コンピュータに自動的に判断させるためです。
そして人間が行っている上記活動を非常にシンプルに描くとこのようになります。
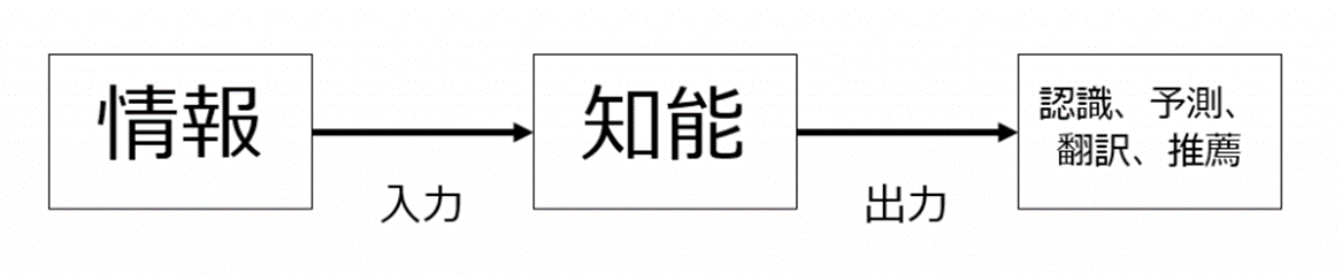
たとえば、「ある画像が猫なのか、ピューマなのか、トラなのか」という問題については、視覚を通じて「ある特徴を持った画像」という情報を入力し、当該情報を「知能」によって何らかの処理を行い、その結果「この画像はトラである」との認識を出力しています。
人工知能とは、この「判断プロセス」を人間が行うのではなくコンピュータにやらせようという話であるため、人間の代わりに判断を行ってくれる、なんらかの「判断モデル」が必要となります。
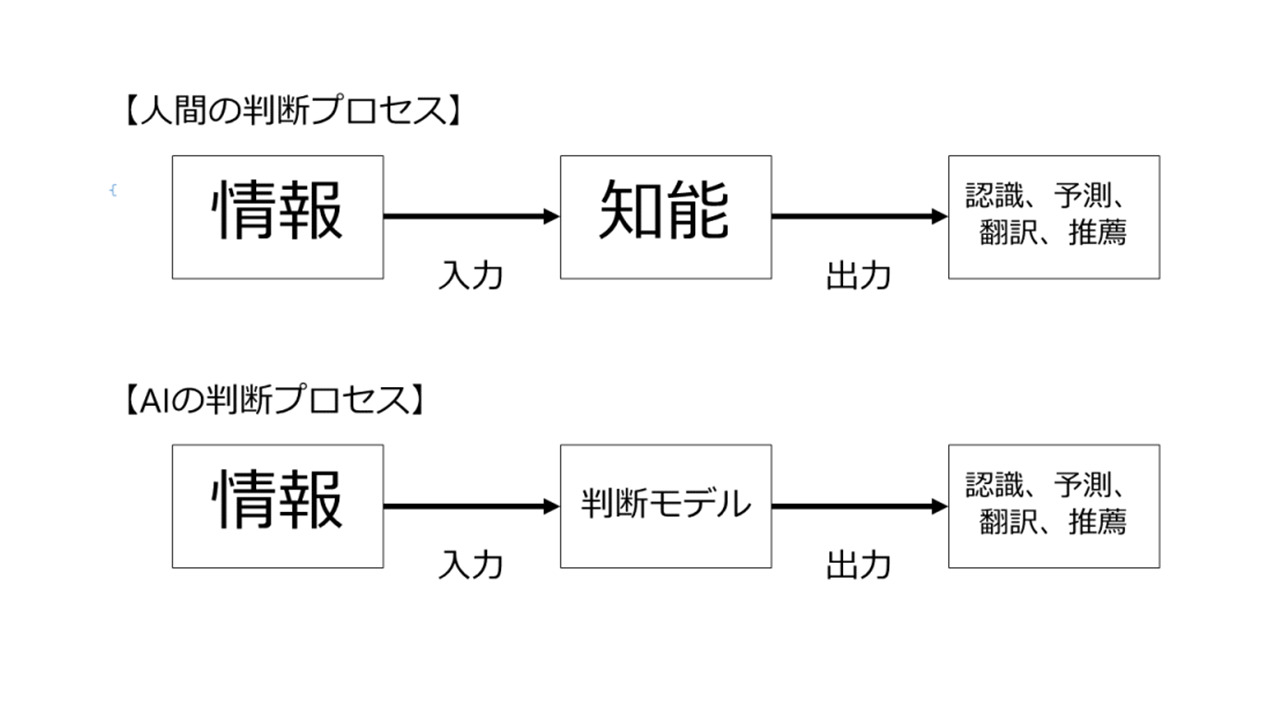
「判断モデル」を作る方法にはさまざまなものがありますが、機械学習やディープラーニングというのは、この「判断モデル」を作成する手法の1つです。
3 判断モデルを作る方法
判断モデルを作る方法には様々な手法が存在しますが、それら各手法にはかなりレベルの高低があります。たとえば「ある画像が猫なのか、ピューマなのか、トラなのかを認識する」ような判断モデルを作る場合、大きく分けて3つのレベルの方法があるように思います(あくまでこれはわかりやすくするための説明で、実際にもっと様々な分類方法があります)。
【第1段階】人間自身がアルゴリズム・プログラムを作る人工知能
【第2段階】機械学習を取り入れた人工知能
【第3段階】深層学習(ディープラーニング)を取り入れた人工知能
4 第1段階:人間自身がアルゴリズム・プログラムを作る人工知能
「こういう情報が入力されたら、こう分類する」というアルゴリズムを人間自身が設計して、それに基づいたプログラムを人間が作成する方法です。
先ほどの画像認識の例で言うと、個体の大きさ、顔の形、毛の長さ、色等々さまざまな要素を人間がピックアップし、人間がそれらの要素の重み付けを行い、その重み付けにしたがってアルゴリズムを人間が設計し、そのアルゴリズムに沿って動くプログラムを人間が作り、当該プログラムを利用して出力(認識)を行う方法です。
このような手法は「ルールベース(ド)」とも言われ、ルールは単純なものから複雑なものまで様々ですが、当然のことながらアルゴリズムは人間が一から設計する必要があり、人間が考えつかないアルゴリズムは出てこないという限界があります。
「人工知能搭載」と謳っている製品は世の中にあふれていますが、その中にはこのような「人間自身がアルゴリズム・プログラムを作る人工知能」も多数含まれていると思われます(それを本当の意味の「人工知能」と言うかどうかはともかくとして)。
5 第2段階:機械学習を取り入れた人工知能
機械学習とは、一言で言うと「AI生成用プログラムが自動的に『学習』を行って『判断モデル』を構築する仕組」です。
「機械学習」や「深層学習」という言葉自体は読者の皆さんも聞いたことがあると思われますが、特に「機械学習」や「深層学習」における「学習」とは何か」「学習の結果生成される『判断モデル』とは何か」について正確な把握をしておくことが重要です。
以下の具体例を考えてみましょう。
【具体例】
都市の犯罪発生率を予測したい。
200都市について、犯罪発生率に関係ありそうな要素(変数)である「非雇用率」「人口密度」「平均所得」の3種類のデータが存在する。
未知の都市についての犯罪発生率を予測できるような関数(予測器)を求めよ。

ここで「犯罪発生率=y」「非雇用率=x1」「人口密度=x2」「平均所得額=x3」とし、非雇用率、人口密度、平均所得額が増加すると、一定割合で犯罪発生率も増加(あるいは減少)すると仮定します。
この仮定の下では犯罪発生率の予測式は以下のように書くことができます。
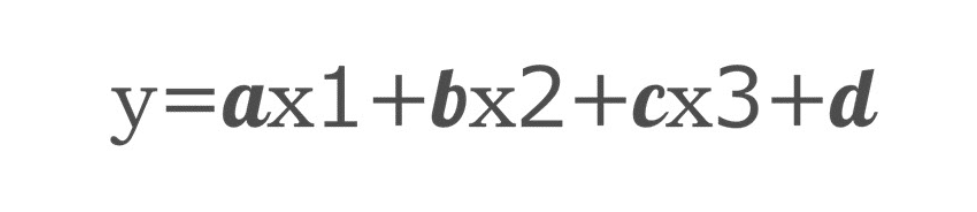
この式のa,b,c,dを「パラメーター(係数)」といい、数値(たとえば、a=0.383、b=0.837、c=-0.3984、d=1.389など)として存在しています。
そして、結論から先に言うと「機械学習」「深層学習」における「学習」とは、「上記関数における適切なパラメーター(という数値)を推定・調整すること」であり、「判断モデル」とは「パラメーター(という数値)の推定・調整が完了し、未知のデータについても適切に判断ができるようになった関数」です。
先ほどの例でいうと「学習」の具体的方法は以下のとおりとなります。
1「y=ax1+bx2+cx3+d」のパラメーター「a,b,c,d」をとりあえず仮に定める(例えば、、a=0.383、b=0.837、c=-0.3984、d=1.389) 。
とすると
y=0.383×1+0.8371×2-0.3984×3+1.389
となる。
2 実際の都市(都市A)におけるデータ(非雇用率、人口密度、平均所得額)を、x1、x2、x3に代入する。
3 「2の計算の結果、出て来たy」と、「都市Aにおける実際の犯罪率」を比較する。
4 当然3における両者は異なっている。
5 「2の計算の結果、出て来たy」≒「都市Aにおける実際の犯罪率」となるようにパラメーターa,b,c,dを調整する
6 以下200都市について繰り返す。
図で示すと以下のようになります。
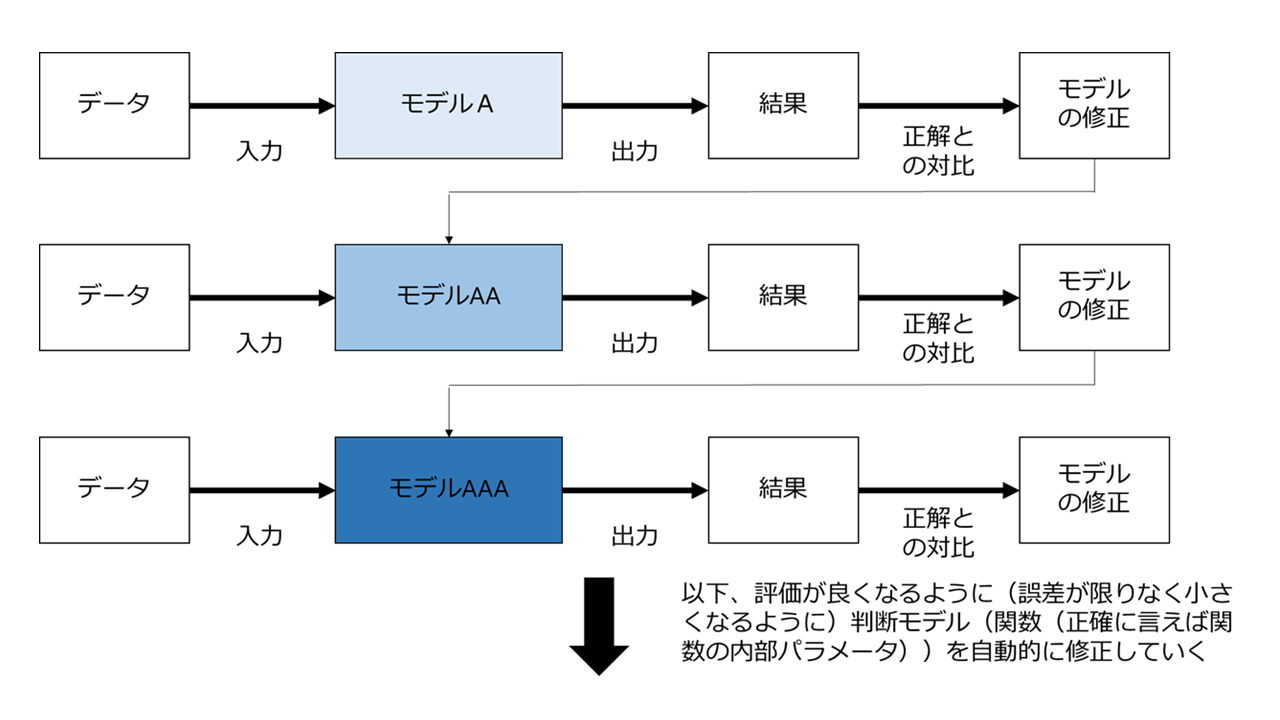
このパラメーターの更新作業を「学習」といい、この学習作業をコンピューターにやらせる手法を「機械学習」と言うのです。
6 第3段階:深層学習を取り入れた人工知能
このような機械学習による判断モデル生成方法は1990年代から発展し、2000年代のビックデータ時代を迎えて更に進化してきたと言われていますが、実は機械学習には大きな課題がありました。
それは「特徴量の設計を人間がやらなければ認識・分類の精度が上がらない」ということです。
そのため、機械学習では2000年ころには精度向上が頭打ちとなり、1年かけて1%エラー率が下がるという世界に入っていたそうです。
この限界をぶち破ったのが深層学習(ディープラーニング)です。
これは「人間が行うしかない」と思われていた「特徴量設計」自体をコンピュータ自らが自動的に行う仕組です。
深層学習(ディープラーニング)という手法自体は1940年代から研究が開始されていましたが、その後何度かブームが来ては下火になると言うことを繰り返しました。
しかし、2012年に世界的な画像認識のコンペティション「ILSVRC(Imagenet Large Scale Visual Recognition Challenge)で、トロント大学が開発した深層学習を利用したSuperVisionが圧倒的な勝利を果たしてから一気に深層学習ブームに火が付きました。
深層学習には「ニューラルネットワーク」という関数(数理モデル)を利用することが多いため、ニューラルネットワークについて以下説明します。
ニューラルネットワークとはなにか
ニューラルネットワークは関数(数理モデル)の1種ですが、人間の脳神経回路の働きを真似しているところに特徴があります。
人間の脳内では「ニューロン」という神経細胞があり、このニューロンは他のニューロンからの電気的刺激を受けて、刺激の合計がある一定値を超えると自分も興奮して電気的刺激を他のニューロンに伝えますが、これを模倣したのがニューラルネットワークです。
具体的には、以下のような構造を持ってます。
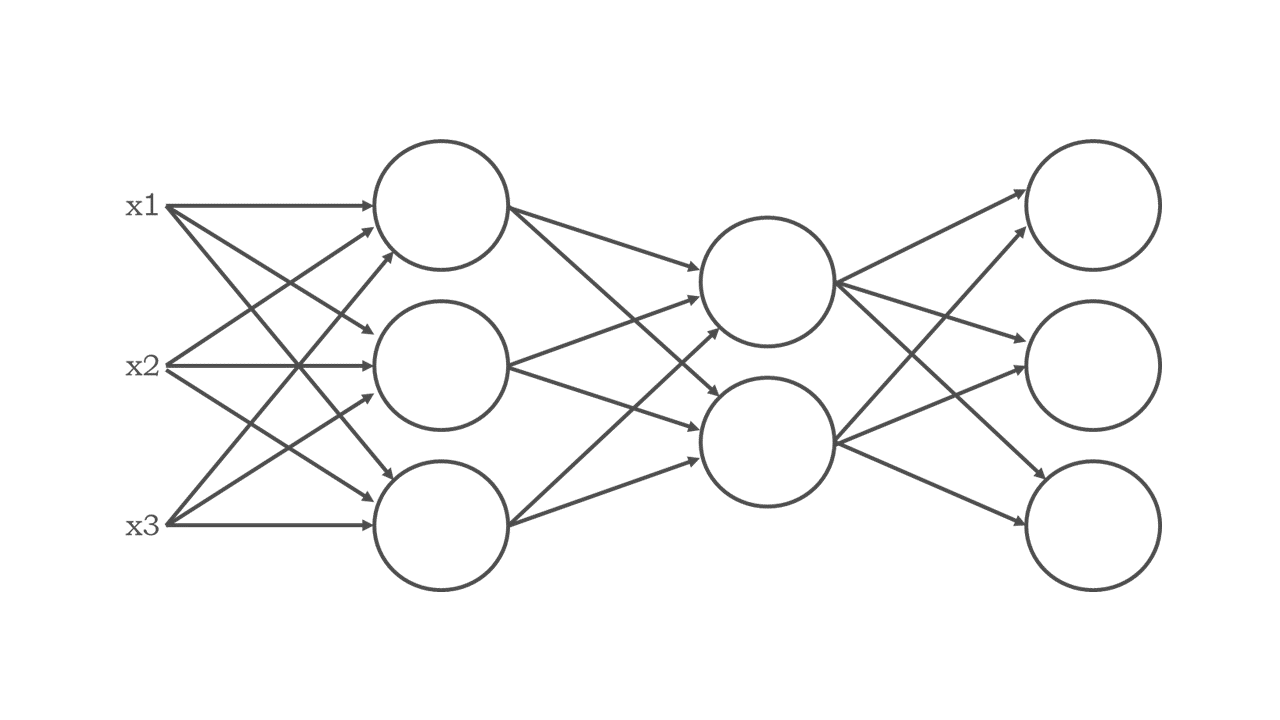
この構造を構成している要素を「ユニット」といい、各ユニットは複数の入力値を受取り、1つの値を出力します。
ユニットを1つだけ取り出してみましょう。
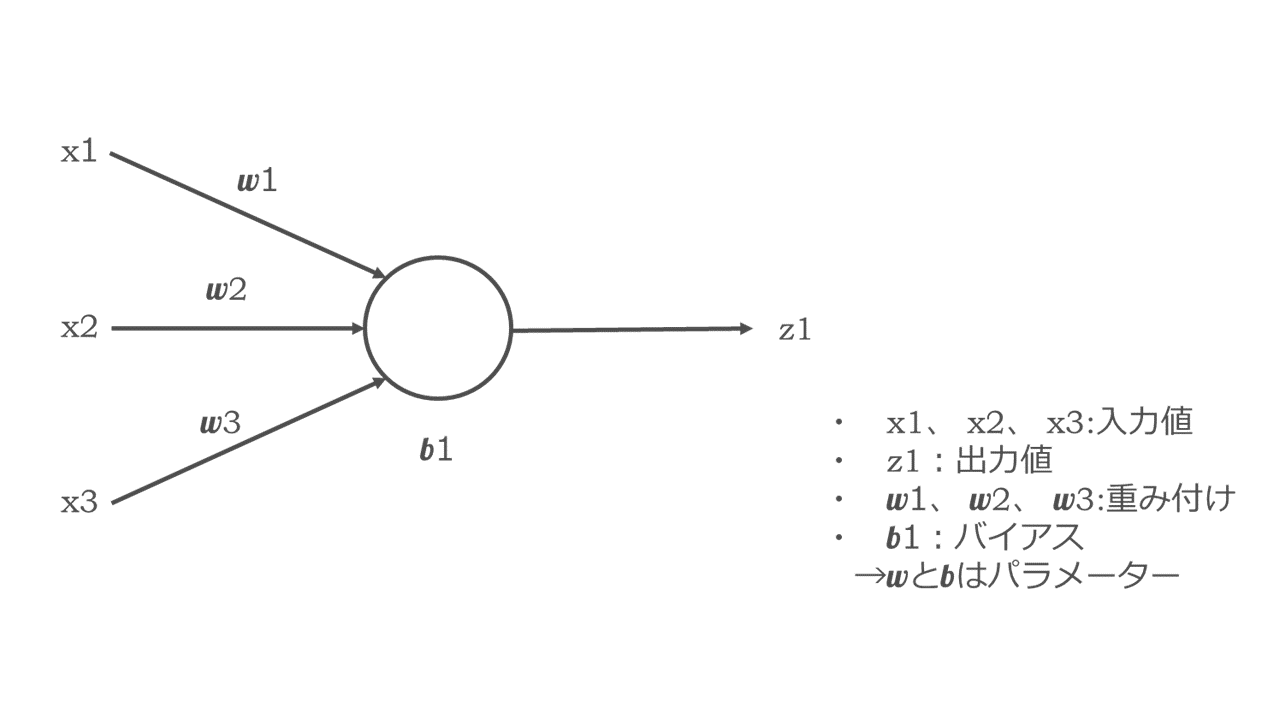
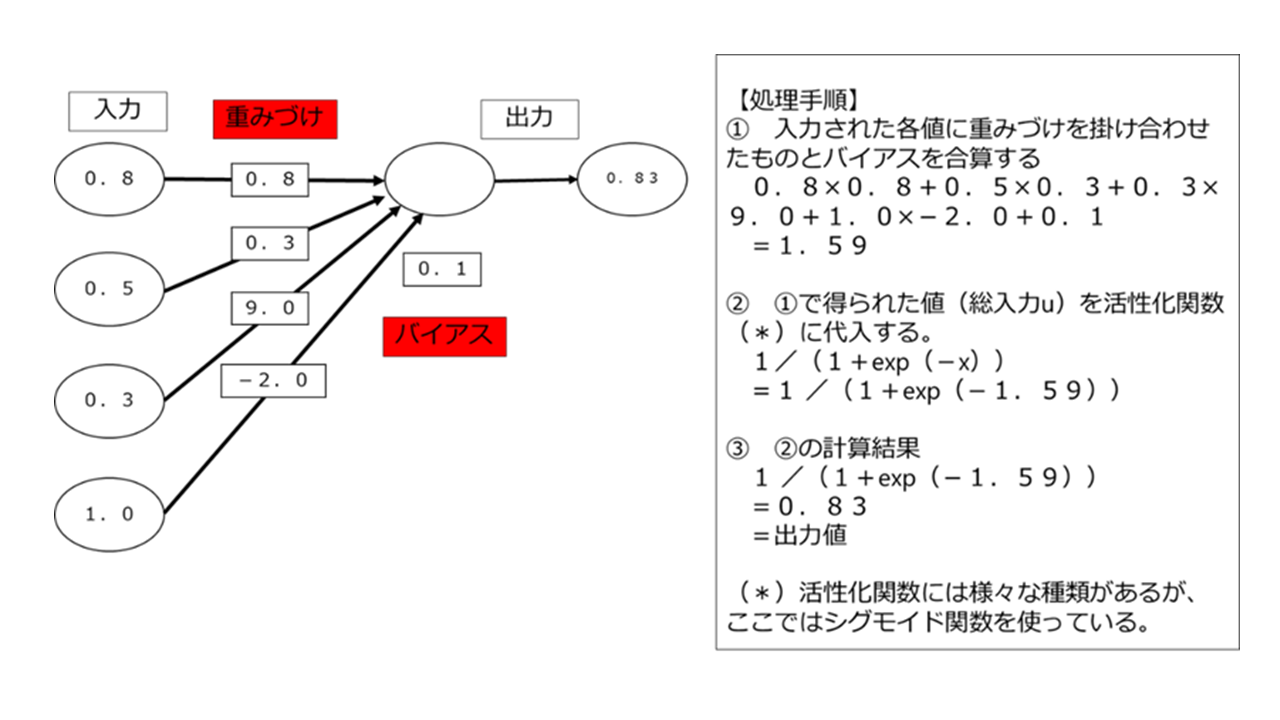
ここで「x1、 x2、 x3」は入力値であり、「z1」は出力値、「w1、 w2、 w3」は重み付け、「b1」はバイアスです。
そして、w1、 w2、 w3、b1はこの関数のパラメーター(ある特定の数値。先ほど紹介した関数「y=a1x1+b1x2+c1x3+d1」におけるa1、b1、c1、d1と同じもの)です。
この図はニューラルネットワークを図式化したものですが、この図で行っている入力値(x1、 x2、 x3)から出力値(z1)までの処理を、順番を追って計算式で表すと以下のようになります。
【 z1:出力値の計算手順】
1 まずx、w、bから総入力uを計算
総入力u= w1 x1+ w2x2+ w3 x3+ b1
つまり、入力値x1に重み付けw1を掛け合わせ、同じく入力値x2にw2、入力値x3にw3を掛け合わせたものにバイアスb1を足したものがユニットに入力される値uとなる。
2 1で算出された総入力を活性化関数f に代入
3 活性化関数の出力=z1
z1 =f(u)
ちなみに活性化関数とは、「ばらつきの多い値を0~1の間に納める処理を施すことによって、「オン(1)」か「オフ(0)」かを判定しやすくする関数」(例:シグモイド関数(=(1/(1+exp(-x)))のことをいいます。
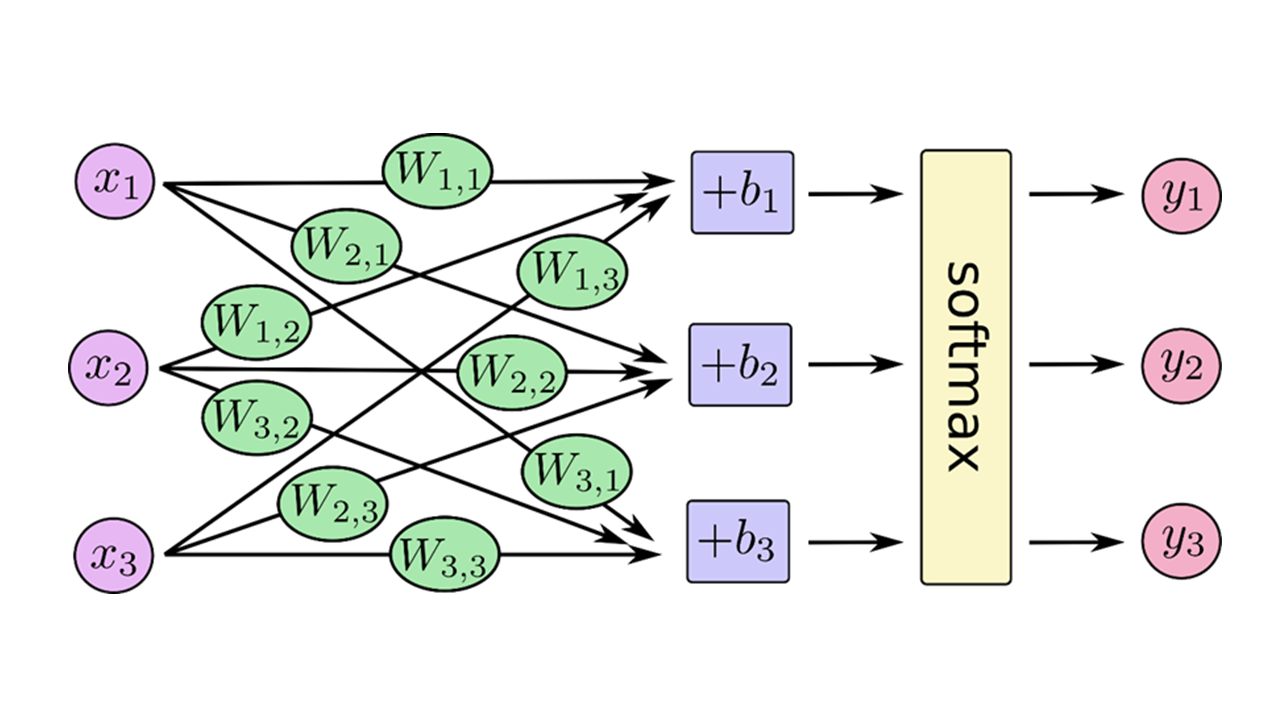
ニューラルネットワークは、このようなユニットが複数集まって出来ていますが、ごく簡単な1層のニューラルネットワークの構造を図示すると以下のとおりとなります(以下の3つの図はいずれもhttps://www.tensorflow.org/versions/master/get_started/mnist/beginnersより引用。)。
x1、x2、x3という入力値にそれぞれ重み付けwを掛け合わせ、最後にバイアスbを足して活性化関数の一種であるsoftmax関数に代入して出力値yが出力されていることが分かりますね。
そして上図のニューラルネットワークを計算式で表現すると以下のとおりとなります。
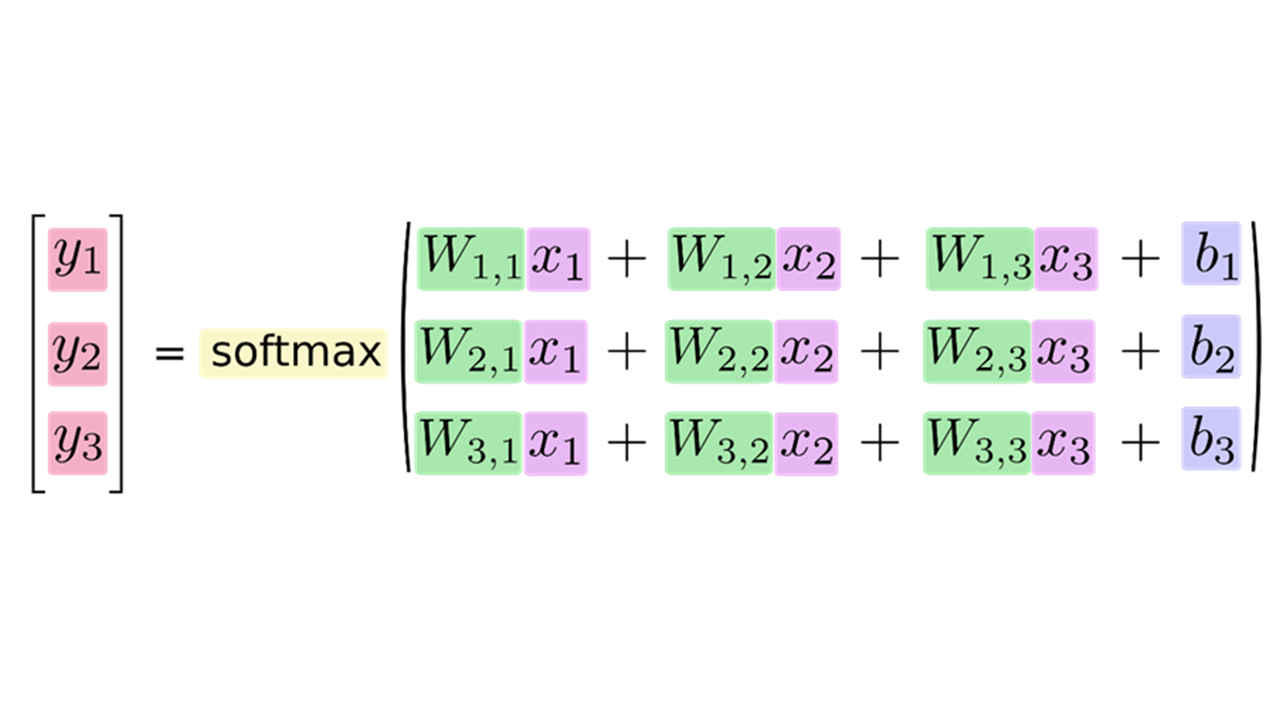
出力値y1、y2、y3は、総入力(w1.1×1+w1.2×2+w1.3×1+b1、・・・・・以下略)を活性化関数softmaxに入力して出て来た値であるということを意味しています。
この計算式をパラメーター部分と変数部分に分けると以下のとおりとなります。
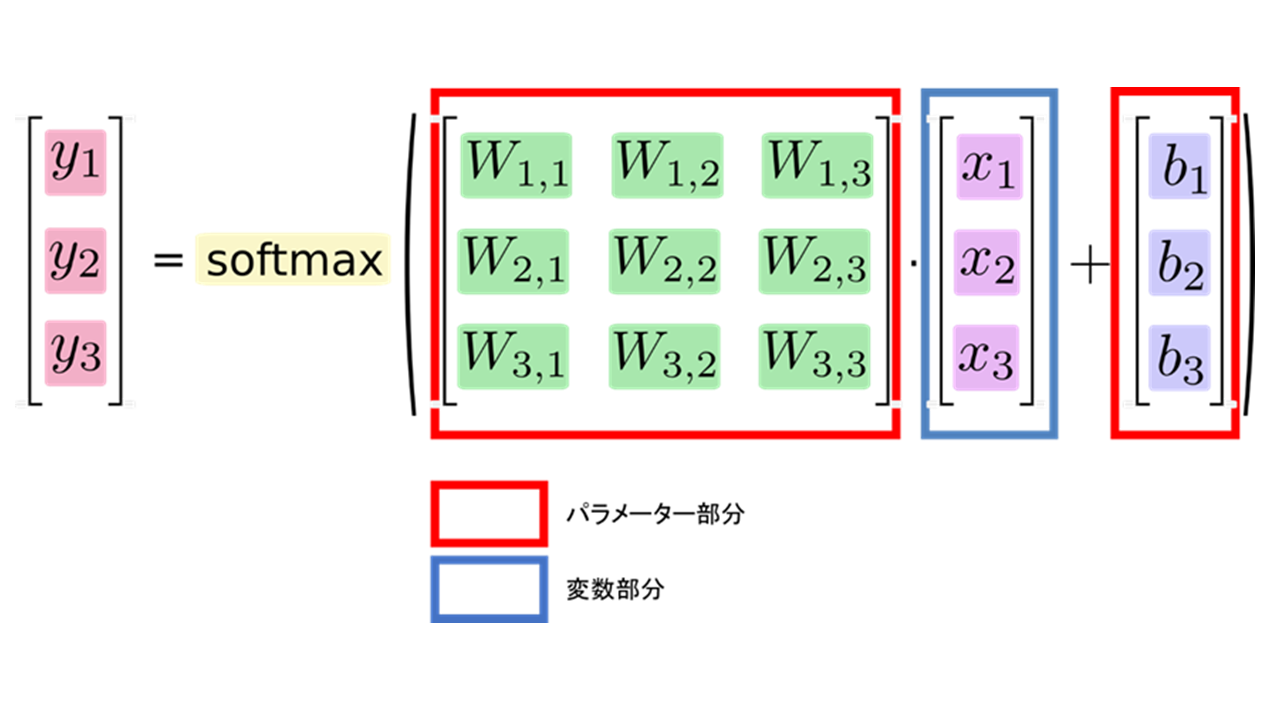
この計算式から分かるように、ニューラルネットワークにおけるパラメーターは数値、正確には行列の形式として存在しています。
具体的な数値を用いた計算例は以下のとおりとなります。
深層学習における「学習」とは
先ほど「機械学習」「深層学習」における「学習」とは、「関数における適切なパラメーター(という数値)を推定・調整すること」であると説明しました。
ニューラルネットワークにおけるパラメーターは重み付けw1、 w2、 w3とバイアスb1ですから、ニューラルネットワークを用いた「深層学習」における「学習」とは、このw1、 w2、 w3、b1を調整していくことを意味します。
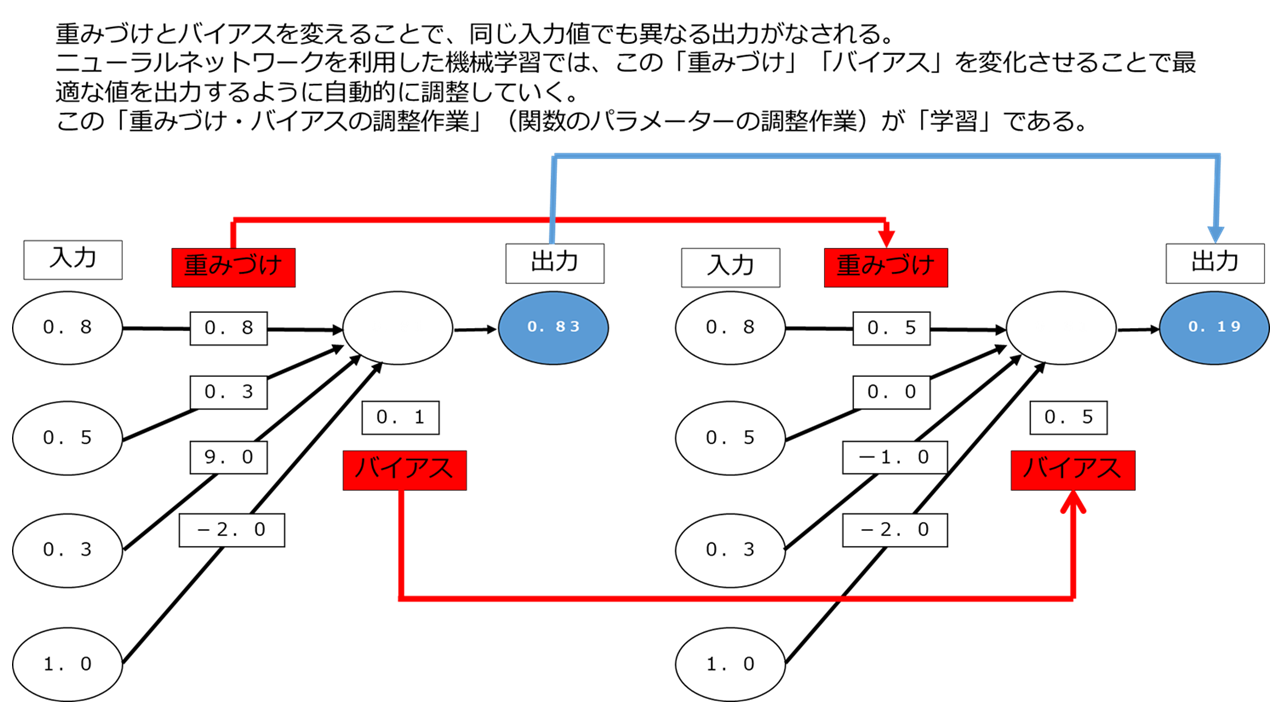
そして、多層のニューラルネットワークでは、あるユニットの出力値が次のユニットの入力値になることから、あるパラメーターの調整によりすべてのユニットの出力値に影響を及ぼすことになります(全結合の場合)。このような仕組みにより多層のニューラルネットワークは極めて複雑な処理を実現できるのです。
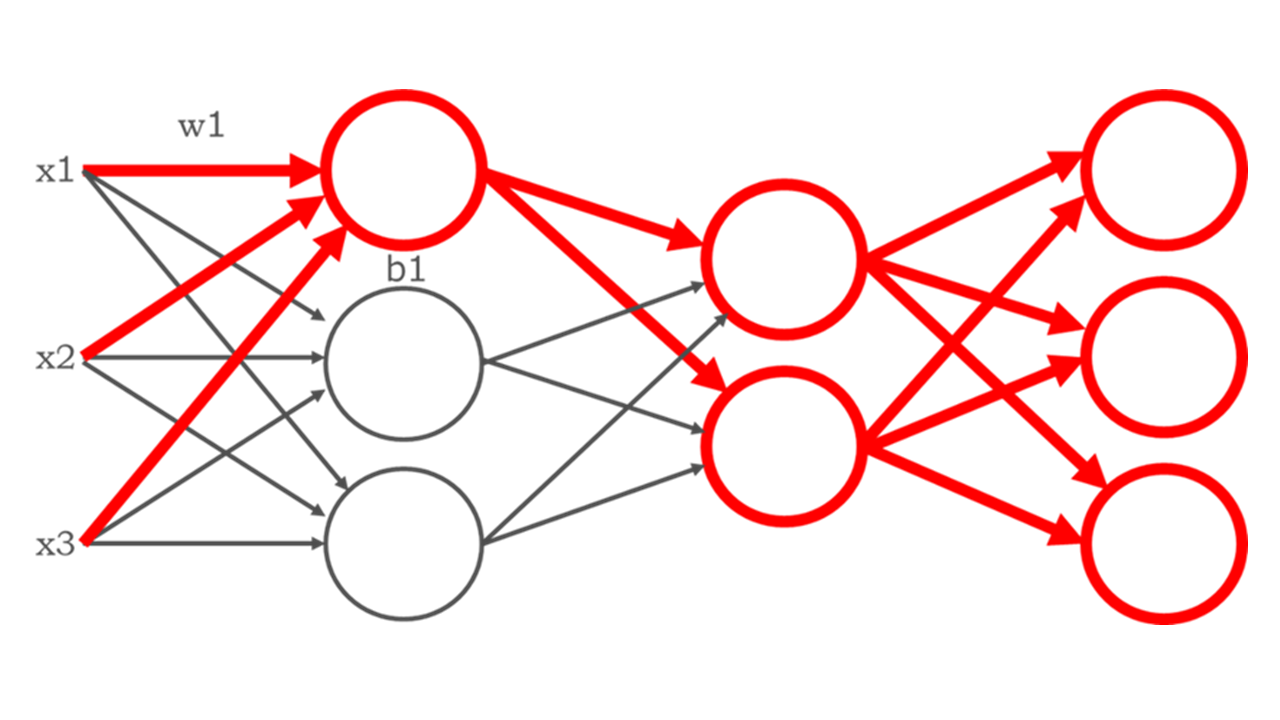
ネットワーク構造とパラメーター
上記の図のように多層のニューラルネットワークはニューラルネットワークの層を多数重ねた構造を持っていますが、このような層の数や処理の順番などの構造を「ネットワーク構造」といい、重み付けw、バイアスbという数値のことを「パラメーター」といいます(後者は繰り返し説明しているとおりです)。
この両者を区別して考えることが非常に重要です。
このうち、「ネットワーク構造」については、言い換えれば「入力値をどのような手順で処理して出力するか」という処理の手順(アルゴリズム)のことです。
そして多様なタスク(画像認識、音声認識等)に、どのようなネットワーク構造が適しているかという研究が日々続いており、様々なネットワーク構造が論文として発表されてます
下記はその一例です。
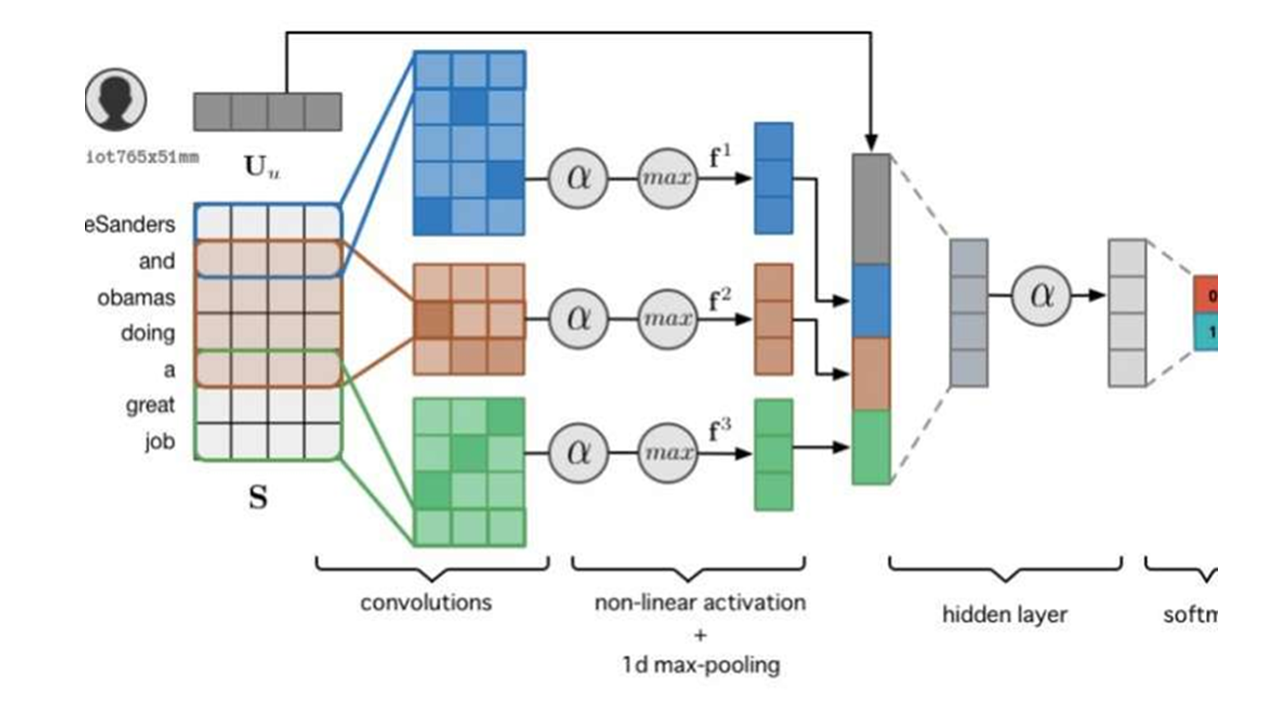
https://techxplore.com/news/2016-08-deep-neural-network-approach-sarcasm.htmlより
また、ILSVRC2012で優勝したAlexNetと呼ばれるDNN(ディープニューラルネットワーク)のネットワーク構造は以下のとおりです。
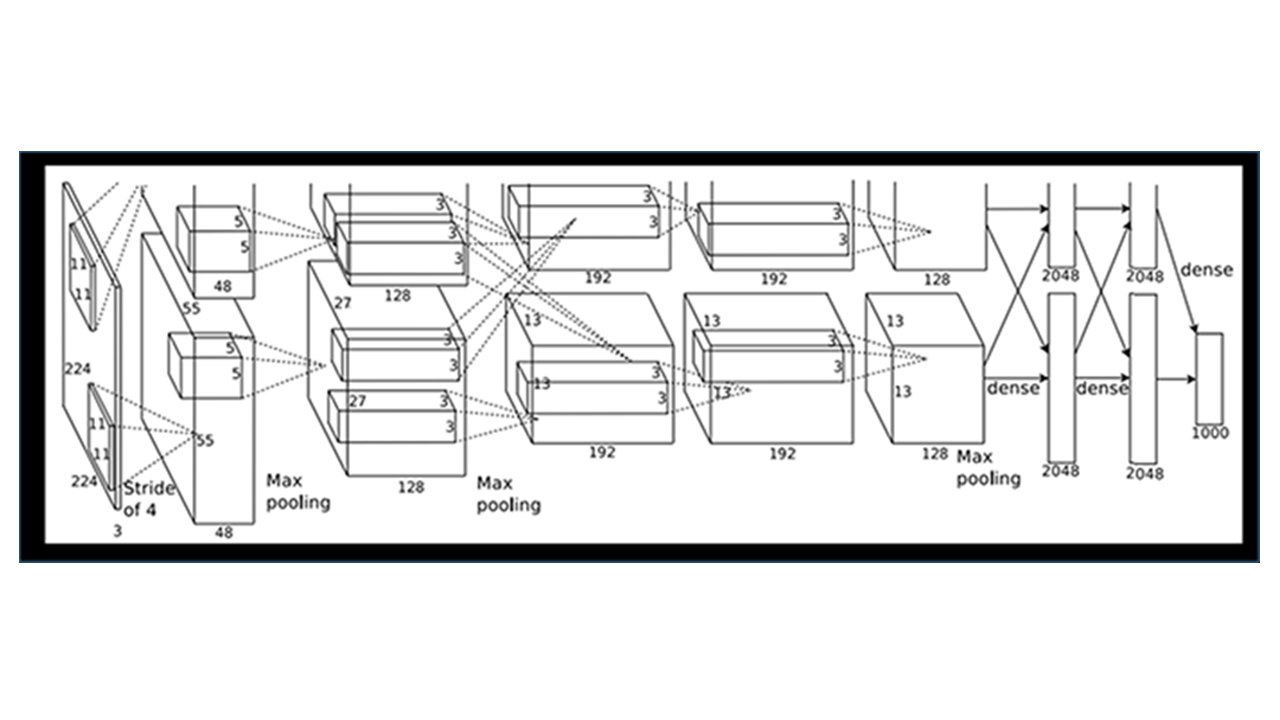
Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks”, NIPS2012.
学習済みモデルはどのような形式として存在しているのか
さて、ここまでの長い長い説明は「学習済みモデルはどのような形式として存在しているのか」を説明するための前振りでした。
繰り返しになりますが、「判断モデル(学習済みモデル)」とは「パラメーター(という数値)の推定・調整が完了し、未知のデータについても適切に判断ができるようになった関数」のことです。
そして、ディープニューラルネットワーク(DNN)の場合、関数は「ネットワーク構造」+「パラメーター」として表現されています。
このうち「ネットワーク構造」は通常はプログラムの形式で記述され、「パラメーター」は数値(正確に言うと大量の数値の行列)の形式で存在しています。
つまり「学習済みモデルはどのような形式として存在しているのか」という問いに対しては「『ネットワーク構造というプログラム』+『パラメーターという数値データ』の形式で存在しています」が答えとなります。
ちなみに、パラメーターについては、複雑なモデルでは1,600億パラメーター、フローティングポイントの浮動小数点の数が何百億、何千億という非常に大きな数の集合と言われています。
ネットワーク構造とそれを記述したプログラムの例が下記図です。左側の枠で囲ったのがネットワーク構造を図示したものであり、それを記述したプログラムが右側の枠部分です。
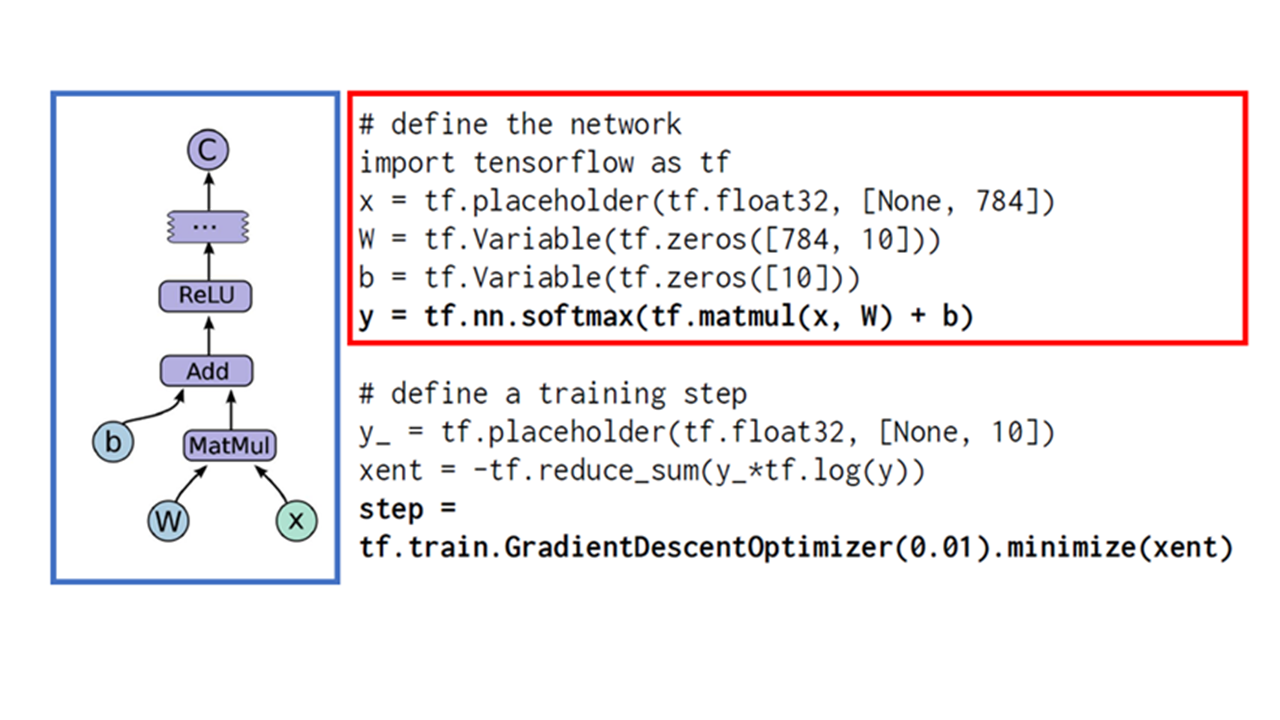
http://www.meti.go.jp/committee/sankoushin/chitekizaisan/eigyohimitsu/pdf/007_04_00.pdfより
学習「前」モデルと学習「済」モデル
ここまで、「学習」や「学習済みモデル」の具体的な意味について説明をしてきました。
そして、学習済みモデルは「(プログラムの形式で存在する)ネットワーク構造」+「(大量の数値の集合として存在する)パラメーター」を組み合わせたものだと解説しました。
この学習済みモデルを生成する際には、もちろん自らネットワーク構造を一から設計してもよいのですが、各社から提供されているソフトウェアフレームワーク(Googleの「Tensorflow」やプリファードネットワーク社の「Chainer」など)を利用することも多いのが実情です。
これのソフトウェアフレームワークはオープンソースソフトウェア(OSS)として無償で提供されていることがほとんどで、「ネットワーク構造と、調整「前」のパラメーターをセットにしたもの」であり、わかりやすく言い換えれば「学習用(前)モデル」と言ってもよいでしょう。
つまり、この「学習用(前)モデル」について「学習用データセット」を用いて「学習」を行ったものが「学習済モデル」ということになります。

手書き文字認識を例にとって
3層のニューラルネットワークを使って手書き文字認識のための判断モデルを作成することを考えてみましょう。
手書き文字認識のための学習モデルを作成するために用いられる学習用データセットとしてはMNIST(エムニスト)というデータセットが有名です。このデータセットでは、1つ1つの手書き文字が28ピクセル×28ピクセル=784ピクセルの画像となっています。
この画像が7万枚あって、それぞれの画像に、どの数字に該当するかの正解ラベルが付けられています。
このデータセットをニューラルネットワークに読み込ませるわけですが、ピクセル単位に分割して読み込ませるので、入力層の数は784個になります。
入力された値は入力層→隠れ層→出力層の順番で出力され、出力層では、0~9までのどの数字に該当するかの確率が出力されます
そこで出て来た確率が正解であればよいのですが、不正解であれば、答え合わせをして間違えるたびに、「入力層」と「隠れ層」をつなぐ部分の重みW1の値,「隠れ層」と「出力層」をつなぐ部分の重みW2の値の調整を繰り返して認識の精度を上げていく作業(つまりパラメーターの更新作業)を行います。
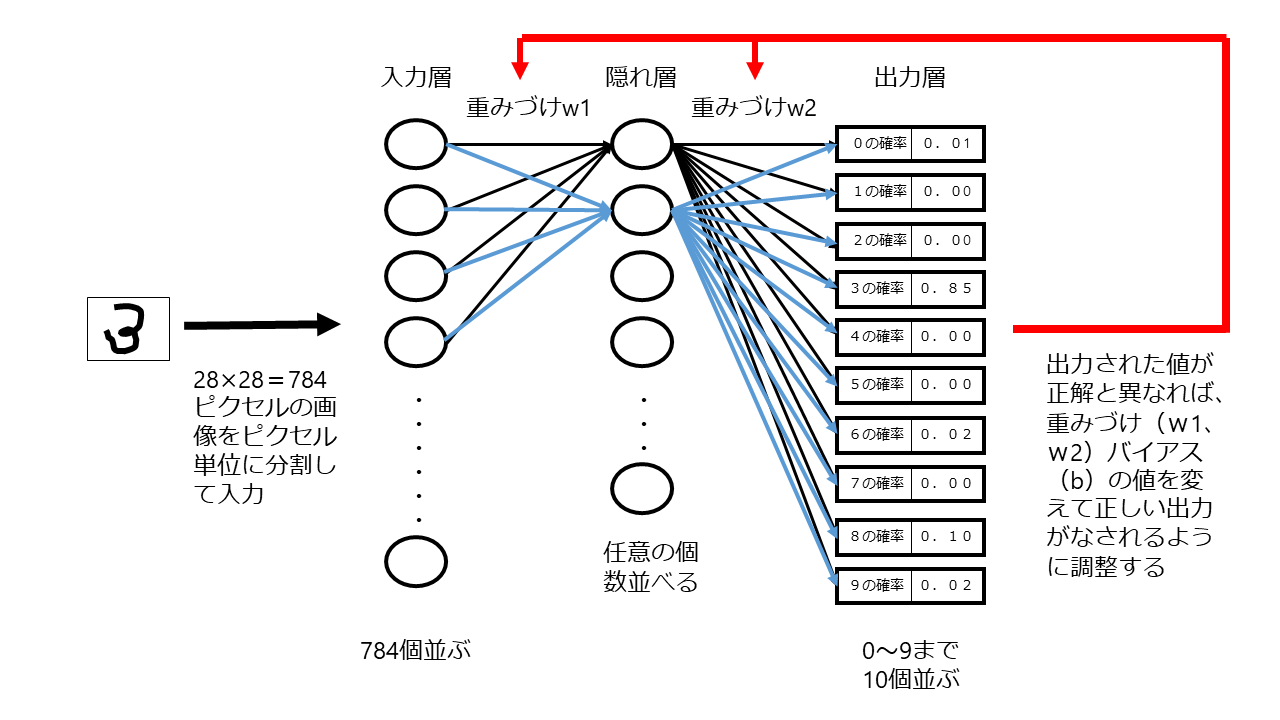
「人工知能は人間を超えるか」(松尾豊・株式会社KADOKAWA)P129頁の図を参考に柿沼が作成
隠れ層の数が仮に100個の場合
1 W1の数:784×100=7万8400個
2 W2の数:10×100=1000個
3 W1+W2の数:約8万個
となります。
学習に際しては、この8万個の重み付けを微調整することを繰り返す、ということになります。
7 まとめ
以上かなり長くなりましたが、AIの技術的な基礎について説明をしました。
繰り返しになりますが、ここでのポイントは「「機械学習」や「深層学習」における「学習」とは何か」「学習の結果生成される『判断モデル』とはどのような形式で存在しているのか」であり、その点に関する答えは以下のとおりです。
1 学習用モデル(学習前モデル)
ネットワーク構造(プログラム)+調整「前」パラメーター(数値の集合)
2 学習
大量のデータを利用して学習用モデルのパラメーターを調整すること
3 学習済みモデル
ネットワーク構造(プログラム)+調整「後」パラメーター(数値の集合)
生成された学習済モデルの帰属や、学習済みモデルを知的財産制度で保護できるかについて検討するためには、上記の点についての正確な理解が必須です。
(弁護士柿沼太一)












