人工知能(AI)、ビッグデータ法務
弁護士による人工知能(AI)、機械学習、深層学習(ディープラーニング)の基礎講座
【「AIと契約・知財・法律」セミナーのご案内】
2018年12月19日(水曜日)に東京で、2018年末時点におけるいわば「AI法務の総まとめ」として「AIビジネスの最前線からお送りする『AIと契約・知財・法律』」と題するセミナーを開催いたします。
過去の参加者の声や申込、詳細はこちらのページからどうぞ!

人工知能(AI)、機械学習、深層学習(ディープラーニング)という言葉を目にしない日はない今日この頃ですが、実はこれから日本がAI領域で世界をリードするために非常に重要なポイントが1つあります。
それは「人工知能を利用したビジネスをどうやって知的財産制度で保護するか」です。
そこで、今回から3回にわたって人工知能分野に関する以下の記事を書いていきます。
1 弁護士による人工知能(AI)、機械学習、深層学習(ディープラーニング)の基礎講座
2 人工知能(AI)、機械学習、深層学習と知的財産制度
3 弁護士がデータアナリストに機械学習と深層学習の基礎を教わったよ
今回は第1回の「弁護士による人工知能(AI)、機械学習、深層学習(ディープラーニング)の基礎講座」です。
これを読んで頂ければ、今話題の「人工知能(AI)、機械学習、深層学習(ディープラーニング)」の具体的イメージがかなりの程度まで掴めるのではないかと思います。
Contents
■ 「人工知能を利用したビジネスをどうやって知的財産制度で保護するか」は今非常に熱い論点
まず、「人工知能を利用したビジネスをどうやって知的財産制度で保護するか」については、具体的には以下のような論点があります。
(1) 生データ収集・複製行為が生データの著作権を侵害しないか
(2) 生データの集合が知的財産として保護されるか
(3) 学習用データセットの作成行為が生データやその集合の著作権を侵害しないか
(4) 学習用データセットは知的財産として保護されるか
(5) 機械学習・深層学習が学習用データセットの著作権を侵害しないか
(6) 学習済みモデルが知的財産として保護されるか
(7) 2次モデル、3次モデルの保護
(8) AIを利用した発明、コンテンツ等AI創作物の権利者は誰か
実はこの議論は世界でもまだ始まったばかりで、まだ定説というものがありません。
ただ、「人工知能を利用したビジネスをどうやって知的財産制度で保護するか」という点が非常に重要であるという認識は、政府や民間事業者、研究者で共通しておりまして、政府の知的財産戦略本部に設置された「新たな情報財検討委員会」(第1回は平成28年10月31日に開催)でも、その点について議論がされることになっています。
【参考】
知的財産戦略本部新たな情報財検討委員会(第1回)議事次第
この委員会では、具体的には以下のような検討を行うとされています。
2)AIの作成・保護・利活用の在り方
AIについては、昨年度の検討対象だった「AI創作物」だけでなく、その生成過程である「学習用データセット」及び「学習済みモデル」自体が価値の源泉になり得るとの指摘がある。
これらについては、現行知財法制度上の整理、その保護の在り方の検討が十分になされていないため、昨年度の検討を踏まえ、「学習用データセット」、「学習済みモデル」、「派生モデル」等の現行知財法制度上の取扱いを整理したうえで、AI創作物を含め、これらの保護・利活用の在り方について、更なる検討を行う。
http://www.kantei.go.jp/jp/singi/titeki2/tyousakai/kensho_hyoka_kikaku/2017/johozai/dai1/siryou1.pdfより
ここで言及されている「昨年度の検討対象だった「AI創作物」」については当ブログでもいくつか記事を書いているので参考にしてください。
【参考】
▼人工知能がコンテンツ業界に与えるインパクトを考えると冷や汗が出てくる
▼人工知能(AI)が作ったコンテンツの著作権は誰のものになるのか?
▼人工知能(AI)を利用したビジネスモデルを考えてみた
ただ、この点を検討する前提として、そもそも人工知能(AI)、機械学習、深層学習(ディープラーニング)が具体的にどのようなものなのか、どのような仕組みで動いているのかをある程度理解しないと議論についていけません。
■ 人工知能に関する2つのフェーズ
実は、人工知能に関しては2つのフェーズがあります。
1つは「人工知能を作るフェーズ(学習フェーズ)」、もう1つは「作成された人工知能を使うフェーズ(予測・認識フェーズ)」です。
どちらも重要な論点を含んでいるのですが、日本の競争力強化という意味から、より重要なのは前者の「人工知能を作るフェーズ(学習フェーズ)」のところです。
簡単に図示しておきます。
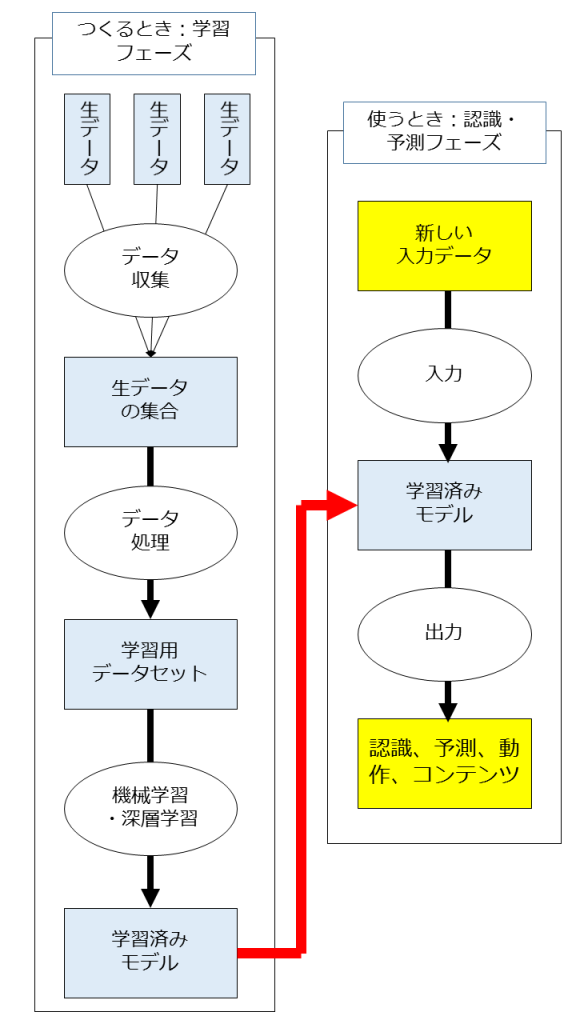
詳しくは後ほど説明します。
■ 基礎の基礎を理解する必要性
おそらく、AIに関する一般的な人の認識は「人工知能は、機械学習や深層学習によって自動的に賢くなる。賢くなった人工知能に指示をすると、分類、予測、認識、コンテンツ生成などを人間の代わりにやってくれる」というようなイメージなのではないでしょうか。
ただ、よく考えてみると、以下のような疑問が生じます。
▼「機械的に学習する」というがそもそも「コンピュータが学習する」というのは具体的に何をするのか
▼「学習」のためには何が必要なのか
▼「賢くなった人工知能」は、どのような形で存在しているのか。
▼「賢くなった人工知能」に指示をして分類、予測、認識、コンテンツ生成が行われる場合、中でどのような処理がされているのか
新しい物好きの私としては、色々本を買い込んで勉強してみました(役に立つ書籍や記事は本記事の末尾にまとめてあります)。
また、データサイエンティストの方と契約して、12月から約2ヶ月間、5回にわたって一対一で講義をして貰うことになっています(その様子もまた後日記事化します)。
かなり技術的な分野ですので、数式や統計、プログラムの話が出て来てバリバリの文系弁護士の私にとってちょっとつらかったのですが、それ以上に「新しい産業革命が生まれる時代に自分が立ち会っている」というワクワク感が半端ありませんでした。
今回の「弁護士による人工知能(AI)、機械学習、深層学習(ディープラーニング)の基礎講座」は、それらの情報や知識を私なりにまとめたものです。
なるべく分かりやすく書いてみましたので、この記事を読んで頂ければ、先ほどの疑問(「▼「機械的に学習する」というがそもそも「コンピュータが学習する」というのは具体的に何をするのか」等)は解消するのではないかと思います。
■ 人工知能(AI)とは何か
まず人工知能(AI)とは何か、ということですが、結論から言うと「定義は決まっていない。」です。
たとえば、人工知能の著名な研究者である松尾豊東大准教授の定義は「人工的につくられた人間のような知能、ないしはそれを作る技術」ですし、長尾真京都大学名誉教授は「人間の頭脳活動を極限までシミュレートするシステム」、浅田稔大阪大学大学院工学研究科教授に至っては「知能の定義が明確でないので、人工知能を明確に定義できない」としています。
ただ、厳密に定義をする必要もあまりないので、ここでは簡単に「人間の知的能力の一部または全部をコンピュータで代替する」ということだと捉えておけば十分だと思います。
■ 人工知能の目的
では、そもそも人工知能はどのような目的のために開発されているのでしょうか。
それは人間が行っている知的な活動、たとえば
▼ ある画像が猫なのか、ピューマなのか、トラなのかの分類・認識
▼ 株価の予測
▼ 顧客への商品リコメンド
▼ 目の前の信号は青信号だが、歩行者が信号無視して横断しており、一方後続車は歩行者に気づかずにかなりのスピードで自車に追従している。どのように運転したらよいか。
▼ 翻訳
などを、コンピュータに自動的に判断させるためです。
そして人間が行っている上記活動をものすごくシンプルに分析すると
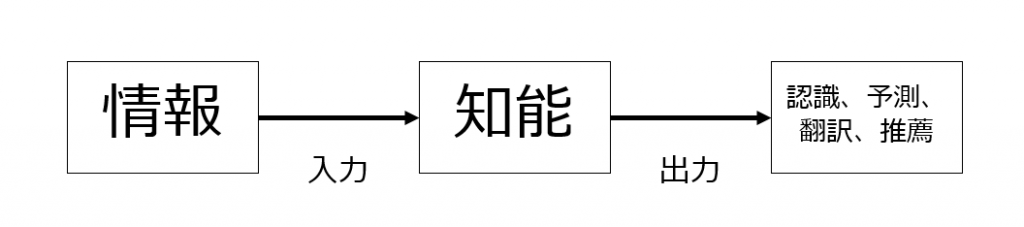
となります。
具体的には以下のとおりです。
▼ ある画像が猫なのか、ピューマなのか、トラなのか
「ある特徴を持った画像」→知能→「この画像はトラである」との認識
▼ 株価の予測
「現在の状況(景気動向、売買取扱高・・・)」→知能→「この株式の株価はこのように推移する可能性が高い」との予測
▼ 顧客への商品リコメンド
「ある属性の顧客」→知能→「この属性の顧客が購入する可能性が高いのはこの商品である」
▼ 目の前の信号は青信号だが、歩行者が信号無視して横断しており、一方後続車は歩行者に気づかずにかなりのスピードで自車に追従している。どのように運転したらよいか。
「自車を取り巻くあらゆる状況」→知能→「事故の発生確率が一番低い行動はこの行動である」
▼ 翻訳
「この文脈の中でこの単語はどのような意味で使われているのか」→知能→「このような意味で使われている」
■ 人工知能の機能
人工知能とは、この「判断プロセス」を人間が行うのではなくコンピュータにやらせようという話です。
なので、人間の代わりに判断を行ってくれる、なんらかの「判断モデル」が必要となります。
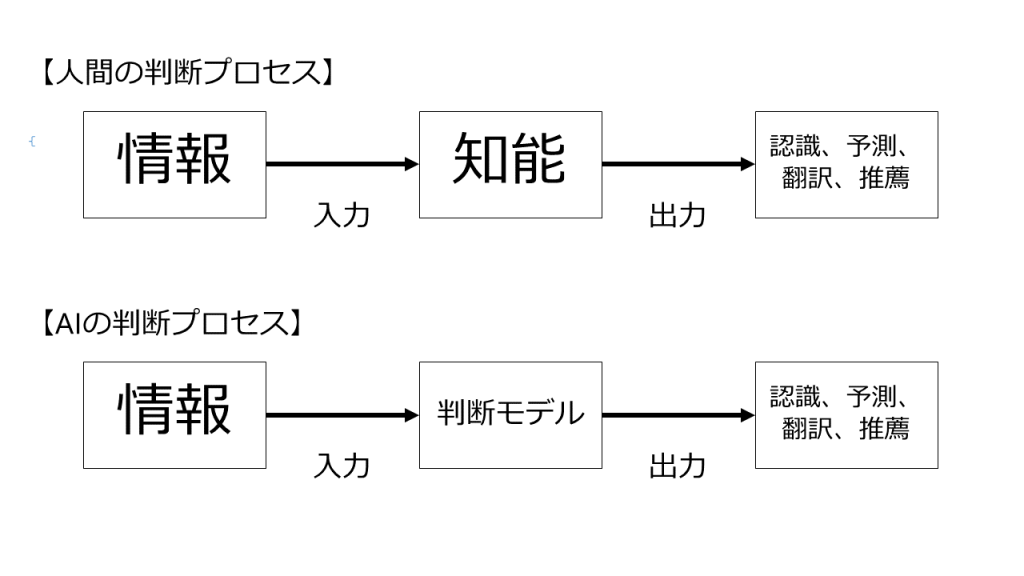
「判断モデル」を作る方法には色々あります。
実は、機械学習やディープラーニングというのは、この「判断モデル」を作成する手法の1つです。
いきなり「判断モデル」と言う言葉が出て来て意味がわからないと思いますが、もう少し我慢して読み進めてください。
■ 判断モデルを作る方法
判断モデルを作る方法には様々な手法があるのですが、それら各手法にはかなりレベルの高低があります。
たとえば「ある画像が猫なのか、ピューマなのか、トラなのかを認識する」判断モデルを作るとしましょう。
これには大きく分けて3つのレベルの人工知能があります。
【第1段階】人間自身がアルゴリズム・プログラムを作る人工知能
【第2段階】機械学習を取り入れた人工知能
【第3段階】ディープラーニングを取り入れた人工知能
順に見ていきましょう。
▼ 第1段階:人間自身がアルゴリズム・プログラムを作る人工知能
「こういう情報が入力されたら、こう分類する」というアルゴリズムを人間が設計して、それに基づいたプログラムを人間が作成する方法です。
画像認識の例で言うと、個体の大きさ、顔の形、毛の長さ、色等々さまざまな要素を人間がピックアップし、人間がそれらの要素の重み付けを行い、その重み付けにしたがってアルゴリズムを人間が設計し、そのアルゴリズムに沿って動くプログラムを人間が作る。
で、そのプログラムを利用して出力(認識)を行う方法です。
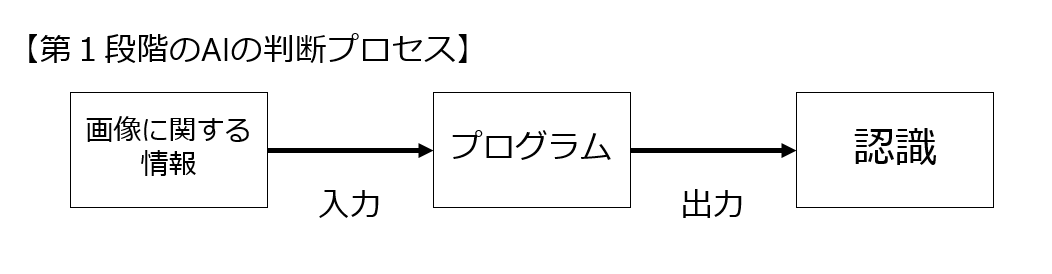
アルゴリズムを考えてプログラムを作成するところまですべて人間がやらなければなりません。ですので、当然人間が考えつかないアルゴリズムは出てくるはずがありませんし、プログラムも人間が書かなければならない、ということになります。
現在世にでている「人工知能搭載家電!」は、その大部分がこの「第1段階」つまり「人間自身がアルゴリズム及びプログラムを作る人工知能」を意味しているのではないかと思います。
▼ 第2段階:機械学習を取り入れた人工知能
機械学習とは、「人工知能のプログラムが自動的に「判断モデル」を構築する仕組み」です。
1990年代から発展し、2000年代のビックデータ時代を迎えて更に進化してきたと言われています。実は、機械学習というのは目新しい手法ではなく, もう20年以上の歴史を持つ分野なのです。機械学習には様々な手法(ナイーブベイズ法、サポートベクターマシン、ニューラルネットワーク等)がありますが、基本はすべて以下の過程を経ます。
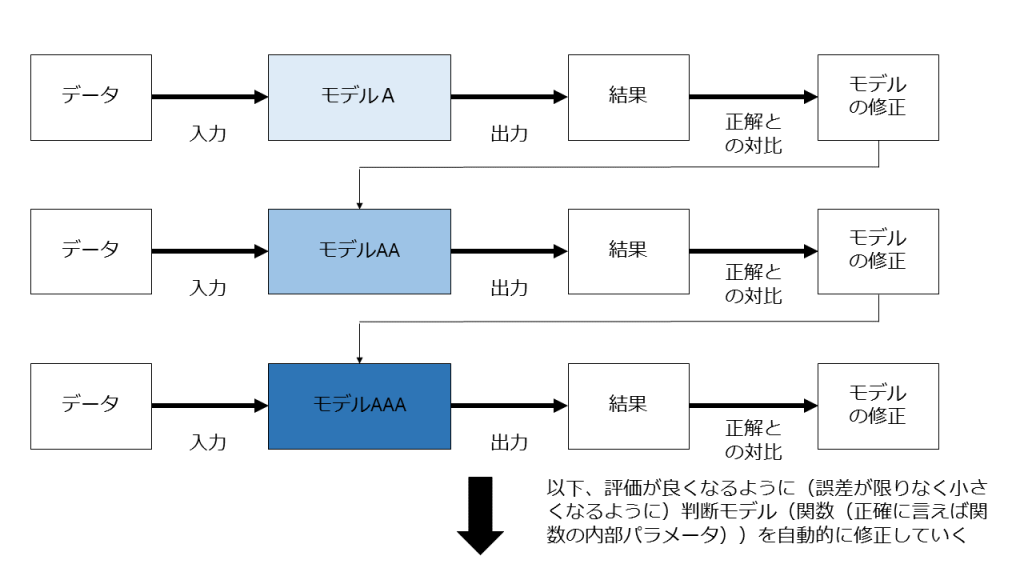
データ入力(情報)→判断→出力(分類)→評価(誤差の有無)→判断モデルの修正→データ入力・・・・・
を大量に繰り返して、評価が良くなるように(誤差が限りなく小さくなるように)判断モデル(関数(正確に言えば関数の構造と内部パラメータ))を自動的に修正していく過程(教師あり学習の場合)
この過程を「(機械)学習」といいます。
これが1つ目の疑問、「▼「機械的に学習する」というがそもそも「コンピュータが学習する」というのは具体的に何をするのか」に対する答えです。
画像認識の例で言うと、
1 沢山の生の画像データを収集してくる。
2 収集した生の画像データに正解のラベルを付けるなどして学習用に整形する(学習用データセット)
3 学習用データセットについて、ある判断モデルを用いて分類させてみる
4 分類結果について評価(正解・不正解)をする
5 評価が良くなるように、プログラムが判断モデルを自動的に修正していく
6 最終的な判断モデル(学習済モデル)が出来る
これが、人工知能の2つのフェーズのうちの1つ目「人工知能を作るフェーズ(学習フェーズ)」です。
下の図(再掲)の左側ですね。
ここで、2つ目の疑問「▼「学習」のためには何が必要なのか」についても答えが出ましたね。
答えは「「学習」のためには「学習用データセット」と「機械学習(判断モデルの自動修正)」が必要」ということになります。
特に、一般に「学習用データセットに含まれるデータの数は多ければ多いほどよい学習モデルが生成できる」と言われており、AI領域で成功するためには、いかに膨大なデータを手に入れることができるかが鍵だとも言われています。
【ニューラルネットワークとはなにか】
さて、機械学習の手法は色々ありますが、そのうち「ニューラルネットワーク」という手法が、後で説明する深層学習の元になっている手法です。
そこで、まずニューラルネットワークについて説明しましょう。
ニューラルネットワークは機械学習の中の一手法ですが、人間の脳神経回路での働きを真似しているところに特徴があります。
人間の脳内では「ニューロン」という神経細胞があり、このニューロンは他のニューロンからの電気的刺激を受けて、刺激の合計がある一定値を超えると自分も興奮して電気的刺激を他のニューロンに伝えます。
これを真似したのがニューラルネットワークです。
図解してみましょう。
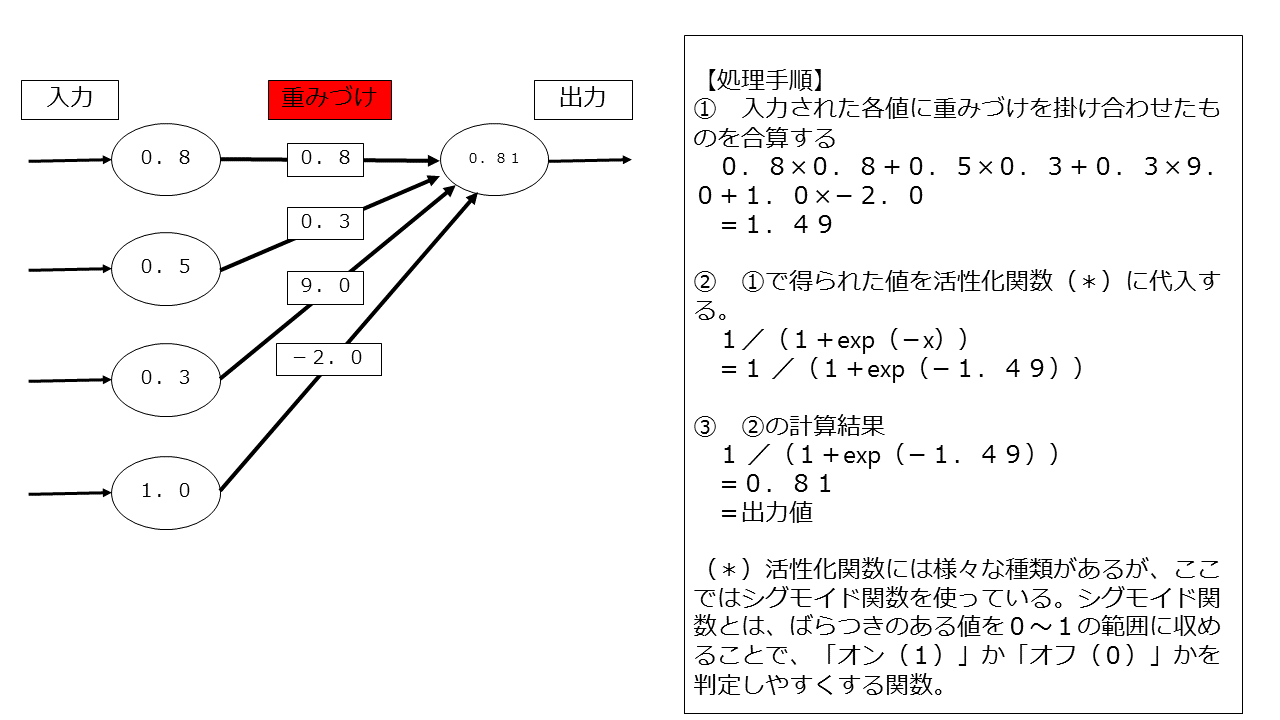
左側の図がニューラルネットワークの模式図です。
左から受け取った入力値に重みづけを掛け合わせ、その和を活性化関数に入力して出力値を求めます。
活性化関数というのは一言で言うと「ばらつきの多い値を0~1の間に納める処理を施すことによって、「オン(1)」か「オフ(0)」かを判定しやすくする関数」のことです。
たとえば、上の図例で言うと、まず4つの入力値にそれぞれ重みづけを掛けあわせたものを合算すると1.49になります。
この「1.49」という値を、シグモイド関数(1/(1+exp(-x)))に代入します(エクセルを使えば簡単です)。
そうすると0.81が出力値となります。
出力値の最大値は1ですから、0.81というのはかなり次のニューロンへの影響力が大きいと言えます。
この処理の中で重要なのは「重みづけ」の部分でして、この「重みづけ」の部分を調整すると、同じ入力値でも異なる出力値が出て来ます。
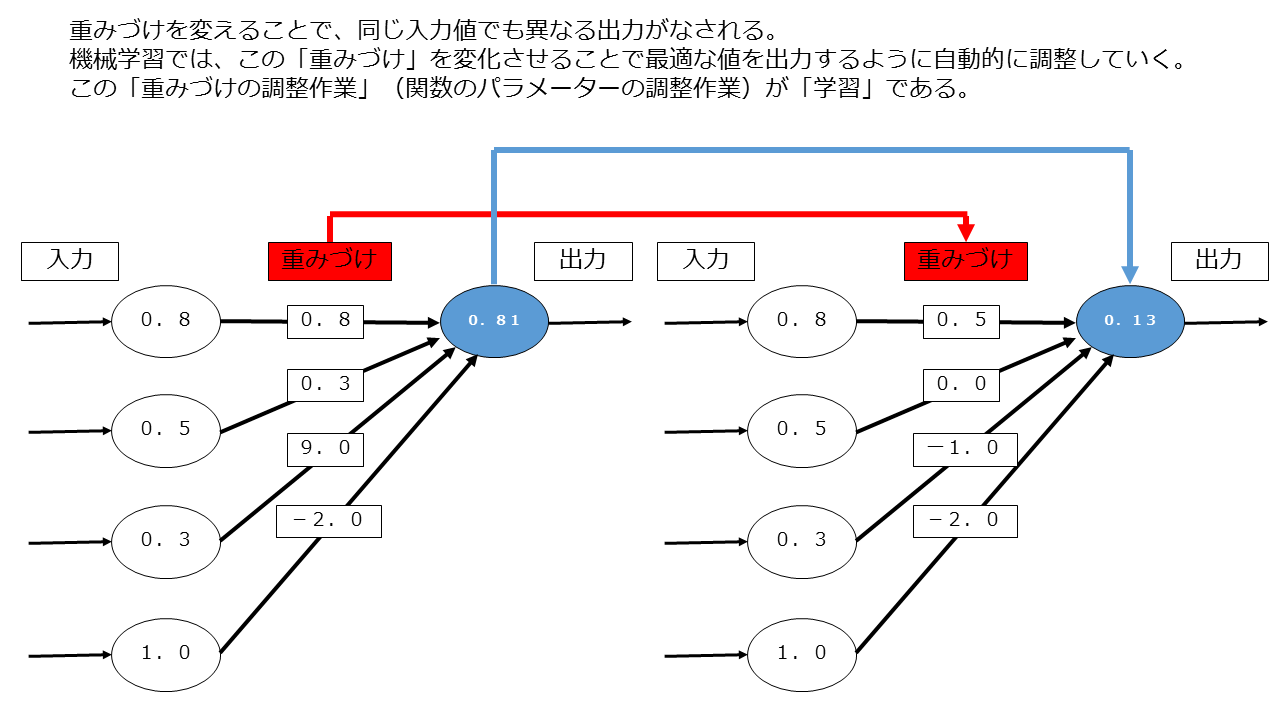
機械学習では、最適な値が出力されるように「重みづけ」を自動的に調整していきますが、この「重みづけの自動調整」(関数のパラメーターの調整作業)が、ニューラルネットワークにおける「学習」なのです。
3層のニューラルネットワークを使って手書き文字認識のための判断モデルを作成することを考えてみましょう。
手書き文字認識のための学習モデルを作成するために用いられる学習用データセットとしてはMNIST(エムニスト)というデータセットが有名です。このデータセットでは、1つ1つの手書き文字が28ピクセル×28ピクセル=784ピクセルの画像となっています。
この画像が7万枚あって、それぞれの画像に、どの数字に該当するかの正解ラベルが付けられています。
このデータセットをニューラルネットワークに読み込ませるわけですが、ピクセル単位に分割して読み込ませるので、入力層の数は784個になります。
入力された値は入力層→隠れ層→出力層の順番で出力され、出力層では、0~9までのどの数字に該当するかの確率が出力されます。
そこで出て来た確率が正解であればよいのですが、不正解であれば、答え合わせをして間違えるたびに、「入力層」と「隠れ層」をつなぐ部分の重みW1の値,「隠れ層」と「出力層」をつなぐ部分の重みW2の値の調整を繰り返して認識の精度を上げていく作業を行います。
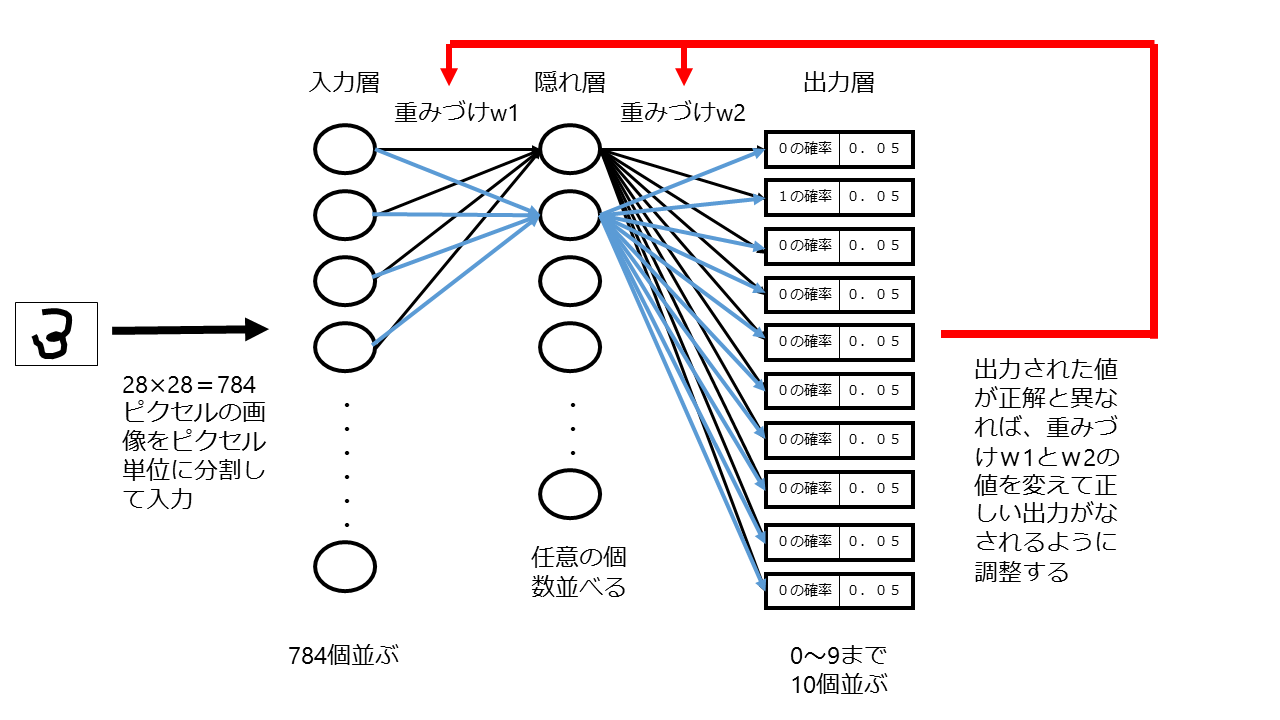
「人工知能は人間を超えるか」(松尾豊・株式会社KADOKAWA)P129頁の図を参考に柿沼が作成
隠れ層の数が仮に100個の場合
1 W1の数:784×100=7万8400個
2 W2の数:10×100=1000個
3 W1+W2の数:約8万個
となります。
この8万個の重み付けを微調整することを繰り返すのです。
▼ 第3段階 ディープラーニングを取り入れた人工知能
このように、ニューラルネットワークを始めとする機械学習では、「学習」を自動的に行うことが可能となったのですが、実は機械学習には大きな課題がありました。
それは「どんな特徴量を入力するか」の設計を人間がやらなければ、認識・分類の精度が上がらないということです。
*特徴量:入力データのどの要素に着目すれば正しく認識・分類できるか、つまり「ここに注目したらうまく分類できるよ」という「ここ」のこと。
たとえば、自動運転における自車の最適な行動の判断を考えてみましょう。
「目の前の信号は青信号だが、歩行者が信号無視して横断しており、一方後続車は歩行者に気づかずにかなりのスピードで自車に追従している。どのように運転したらよいか」という課題です。
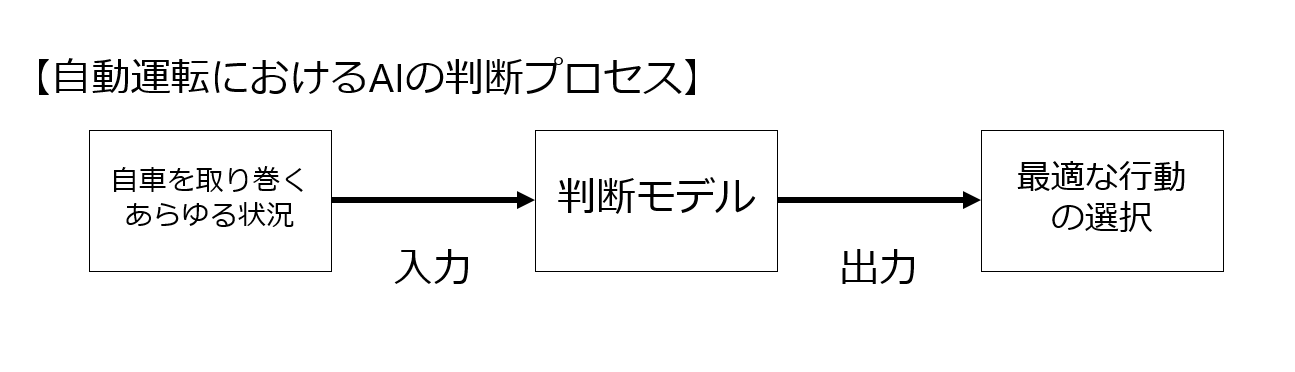
ここで考えられる入力データは、信号までの距離、自車のスピード、歩行者の歩行速度、歩行者がこちらを見ているか(気づいているか)、後続車の距離・スピード、温度、湿度、路面状況・・・・等々無限に近い数があります。
しかし、これら考えられる要素すべての入力データを入力して学習させても、よい学習モデルは生成できません。
「これらの入力データのうち、どの要素に着目すればよい判断ができるのか」が「特徴量の設計」ですが、これは自動化が出来ず、人間がやるしかありませんでした。
この「特徴量の設計」は、長年の知識と経験がものをいう職人技であり、職人技により、機械学習のアルゴリズムと特徴量の設計が少しずつ進んでいたそうです(画像認識の世界でいうと1年かけて1%エラー率が下がるという世界)。
これを2012年に突然ぶち破ったのがディープラーニングです。
ディープラーニングとは、多層階のニューラルネットワークのことで、先ほどのニューラルネットワークを何層にも重ねたものです。
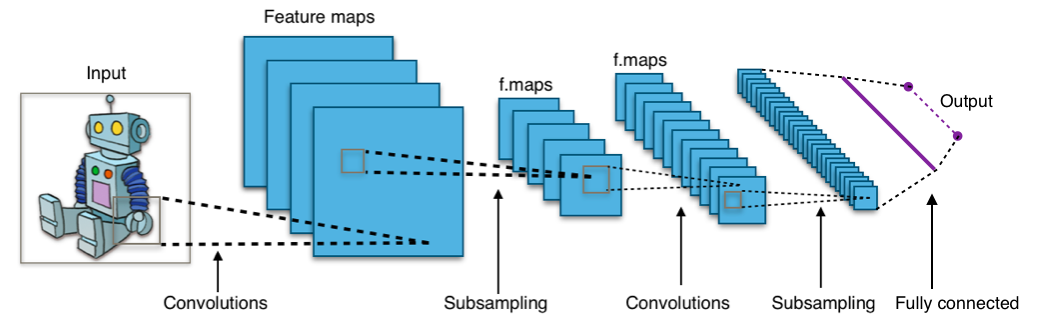
(https://en.wikipedia.org/wiki/Convolutional_neural_network#/media/File:Typical_cnn.pngより
このディープラーニングのどこが凄いのかと言うと、一言で言うと先ほど「人間が行うしかない」と言っていた「特徴量設計」自体をコンピュータ自らが自動的に行う点です。
この点は極めて画期的でした。
どれくらい画期的かというと、松尾豊東大准教授は、著書「人工知能は人間を超えるか」の中で「人工知能研究における50年来のブレークスルー」とし、対談本(「よくわかる人工知能(清水亮・株式会社KADOKAWA)の中では「ディープラーニング(深層学習)は農業革命に匹敵する進化だ」と語ってるほどです。
ただ、「ディープラーニングと言っても特徴量設計が完全に自動化されるわけではなく、人が大部分の特徴量を決めないと、よい学習済みモデルはできない」という意見もあるようです。
たとえばデータサイエンティストの尾崎隆氏のブログ「「人工知能」ブームに乗り遅れた!という方々に捧げる人工知能(機械学習)まとめ記事」では以下のように記載されています。
「一方、この記事の中で色々試行錯誤しているところからも見て取れるように、Deep Learningは一般にベストのパラメータ設定でないと高いパフォーマンスを打ち出すことができず、そのパラメータ設定も多種多様で煩雑なため、専門知識と試行錯誤なくしてその真価を発揮させることが難しい機械学習手法です。(中略)
特に巷では「Deep Learningは自分で特徴量を作り出す・抽出するのでヒトが手を下して特徴量を決める必要がない」と喧伝される向きもありますが、CNNの畳み込み層での処理がそう見えるだけで、機械学習として運用する限りは他の手法同様にヒトが大部分の特徴量を決めない限りはDeep Learningといえどもきちんと機能しないという点にもご注意を。」
実は、この部分、すなわち特徴量設計自体が完全に自動化されるのか、あるいは人間が試行錯誤しなければならないのか、という点は「学習済みモデルが知的財産として保護されるか」という極めて重要な論点に大きな影響を与える部分です。
ですので、正確なところを理解したいのですが、正直言ってまだよく分かりません。
私が実際にディープラーニングのプログラムを動かしてみて(できるのか不安。。。。)、また意見を追記したいと思います。
では、3つ目の疑問「▼「賢くなった人工知能」は、どのような形で存在しているのか。」です。
ここまで読み進めてきた方は「賢くなった人工知能」というのがやや不正確な表現であり、正確には「学習済モデル」のことだとわかると思います。
ニューラルネットワークにおける機械学習とは、先ほどニューロンとニューロンをつなぐ「重みづけ」を自動的に調整する作業だと言いましたが、その学習の結果できあがる「学習済モデル」は「ネットワークの構造+各リンクの重み」です。
これだけだと何のことやらわかりませんが、「学習済みモデルがどのような形で存在しているか」という視点で説明すると「大量の数値の列」です。
この数がどのぐらいあるかというと、物によっては複雑なモデルでは1,600億パラメーター、フローティングポイントの浮動小数点の数が何百億、何千億という非常に大きな数の集合と言われています。
下記の資料は、経済産業省産業構造審議会商務流通情報分科会情報経済小委員会分散戦略WG(第2回)における資料4から抜粋したものです。この資料は、後で紹介する株式会社Preferred Networksの丸山氏プレゼン資料です。
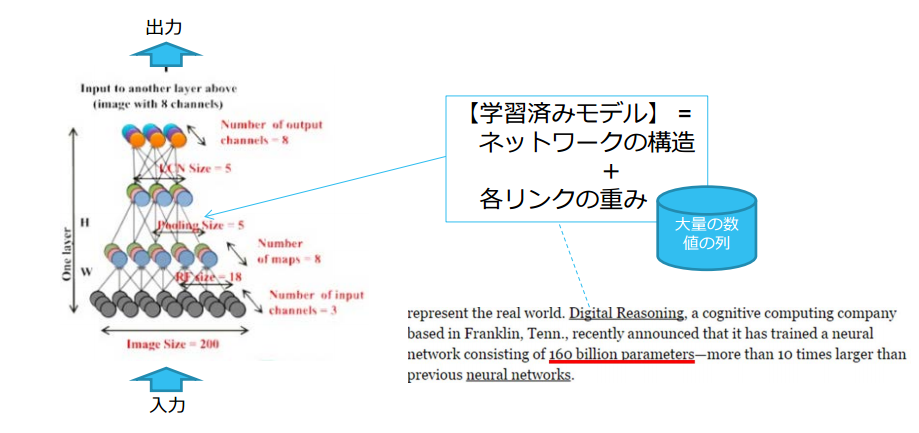
経済産業省産業構造審議会商務流通情報分科会情報経済小委員会分散戦略WG(第2回)資料4 株式会社Preferred Networks 丸山氏プレゼン資料より抜粋
で、3つ目の疑問「▼「賢くなった人工知能」は、どのような形で存在しているのか。」については「大量の数値の列という形で存在している」が答えになります。
■ 実際の機械学習、深層学習の過程を見てみよう
ここで1つの動画を紹介したいと思います。
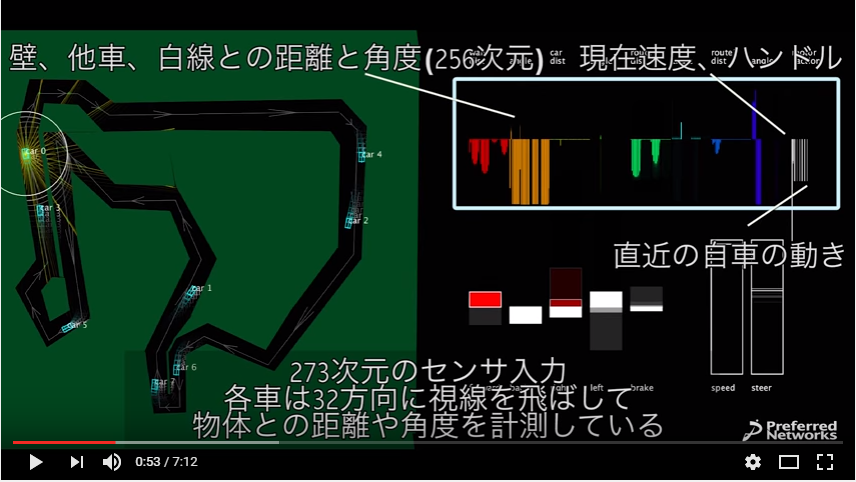
https://www.youtube.com/watch?v=a3AWpeOjkzwより
この動画は、株式会社 Preferred Networks(本社:東京都文京区、代表取締役社長:西川徹、以下 PFN)が制作したものです。
PFNは、2014年に設立された東京大学発のベンチャー企業で、ディープラーニングをIoT(Internet of Thing)や製造業に活用したり、リアルタイム機械学習技術をどのようにビジネスに活用するかといった研究をしているところです。
機械学習やディープラーニングでは日本でトップクラスの企業ですね。
ちょっと古いですが、PFNについては、この記事が詳しいです。
【参考】
AIが勢力図を塗り替える業界とは PFNが絞った3つの領域
そして、特筆すべきはこのPFNのブログ。
私のような素人にも非常にわかりやすく機械学習やディープラーニングのことを解説してくれています。
おまけに動画もいくつかアップされていて、とてもわかりやすい。
ここで紹介している動画はそのうちの1つで、「分散深層強化学習でロボット制御」という記事内で自動運転技術を紹介したものです。
【参考】
分散深層強化学習でロボット制御
この動画、必ず見ていただきたいのですが、ポイントは以下の4点です。
▼ 強化学習という手法で学習
通常のロボットの制御では、「こういう状況の時にはこういう動きをすべき」というルールを人間が作ります。たとえば、「障害物が何mの位置に来たら、ハンドルを何度に回す」みたいなルールを設計するのです。
しかし、あらゆるシチュエーションを想定してルールを設計するのは不可能です。
そこで、目標とするロボットの最適な動き(たとえば自動運転で言えば障害物が何mの位置に来たら、ハンドルを何度に回す」を正解として与える代わりに、ロボットの各行動(つまり動きの「結果」としての行動)に対して報酬を与えます。今回の課題では、道にそって速い速度で進んだときにプラスの報酬を、壁や他の車にぶつかったり、道を逆走したときにマイナスの報酬(罰)を与えます。
それにより、ロボットはどのように行動するとどれくらいの報酬が得られそうかを学習していき、最も多くの報酬が得られそうな行動、つまり最適な行動を選択するようになります。
これを強化学習といいます。
強化学習は機械学習の一類型ですが、「どう行動するか」を正解として与えるのではなく「結果として正しい成果を上げたかどうか」について事後的に評価する手法です。
たとえば、「迷路を1分以内に抜けられたときはプラスの報酬を与えられるが、どのような行動をするか(たとえば、どこの角でどう曲がるべきだったか)は教えて貰えない」タスクなどです。
ここでは深層強化学習(深層学習+強化学習)の手法が用いられています。
▼ 入力データは273個
・ 車は周囲32方向に仮想的なセンサビームを飛ばして壁、他車、道路の中心線までの距離と角度を取得している
32(方向)×4( 壁/他車/一番近い白線/二番目に近い白線)×2(距離/角度)
・ 自車の行動
3( 直近3ステップの自車の行動)×5(アクション数(アクセル/ブレーキ/右/左/バック))
・ 現在の状況
2(現在速度/ハンドルの角度)
・ 32*4*2+3*5+2
=273個の入力データ
▼ 出力データは5個
アクセル、ブレーキ、左右ハンドル、バックの5種類の行動
▼ 7層のニューラルネットワークでディープラーニング
今回の問題では7層(273-600-400-200-100-50-5)のニューラルネットを用いて(ディープラーニング)273成分から5成分への出力を行っている。そして、得られる報酬が最大化するように、ニューラルネットの中の重み付けを変化させ(学習させ)ている。
■ まとめ
以下、今回の「弁護士による人工知能(AI)、機械学習、深層学習(ディープラーニング)の基礎講座」のまとめです。
▼ 人工知能には「人工知能を作るフェーズ(学習フェーズ)」と「作成された人工知能を使うフェーズ(予測・認識フェーズ)」の2つのフェーズがある。日本の競争力強化という意味から、より重要なのは前者の「人工知能を作るフェーズ(学習フェーズ)」のところです。
▼ 人工知能の(1つの)目的は、入力(情報)→判断→出力(分類・認識・予測等)を自動的に行うことである。
▼ 判断モデルを生成する方法には3段階ある。「【第1段階】人間自身がアルゴリズム・プログラムを作る人工知能」「【第2段階】機械学習を取り入れた人工知能」「【第3段階】ディープラーニングを取り入れた人工知能」である。
▼ 機械学習とは、人工知能のプログラム自身が自動的に「判断モデル」を構築する仕組み。データ入力(情報)→判断→出力(分類)→評価(誤差の有無)→判断モデルの修正→データ入力を大量に繰り返して、評価が良くなるように(誤差が限りなく小さくなるように)判断モデル(関数(正確に言えば関数の構造と内部パラメータ))を自動的に修正していく。この過程を「(機械)学習」という。
▼ 機械学習の弱点であった「特徴量の設計を人間が行わなければならない」という点を乗り越え「機械が自動的に特徴量設計を行う」というのがディープラーニングであり、極めて大きなインパクトを持つ。
▼ PFNのブログは素晴らしい。
今回は以上です。
次回は、今回の記事を踏まえて「人工知能(AI)、機械学習、深層学習と知的財産制度」を書きます!
【参考文献】
▼ 人工知能は人間を超えるか(松尾豊・株式会社KADOKAWA)
とても読みやすく、これまでの人工知能の進歩の仕方や機械学習の仕組み、深層学習がいかに優れたものかを知るのに非常にお勧め。最初に読むべき1冊。
▼ よくわかる人工知能(清水亮・株式会社KADOKAWA)
最先端の研究をしている人工知能関係者との対談と、人工知能の解説を組み合わせた本。対談相手は、松尾准教授、田島玲・ヤフージャパン研究所所長、山川宏・ドワンゴ人工知能研究所所長などそうそうたるメンバーだが読みやすく、お勧め。最後の対談相手である齋藤元章PEZYComputing代表取締役との対談はスケールが大きすぎて背筋が寒くなること必至。
▼ データサイエンティスト養成読本・機械学習入門編(比土将平ら・技術評論社)
技術本で数式や関数、プログラムが満載だが、初学者にも読みやすい。機械学習の技術的な基礎を学ぶためには最適。
▼ イラストで学ぶ人工知能概論(谷口忠大・講談社)
数式がかなり出てくるので、正直、初学者にはかなりきつい。ただ、我慢して読み通すと、さまざまな概念の関係性がうっすらわかるので役に立つ。
▼ PFNのブログ
素人にもわかりやすく機械学習が実際にどのように動いているのかを説明してくれているのでお勧め。
特に
▼ 画風を変換するアルゴリズム
▼ CES2016でロボットカーのデモを展示してきました
▼ 分散深層強化学習でロボット制御
はお勧めです。
▼ 「人工知能」ブームに乗り遅れた!という方々に捧げる人工知能(機械学習)まとめ記事
データサイエンティスト・尾崎隆氏のブログ。専門的内容と素人的内容を絶妙に行ったり来たりする記事なので、非常に理解がはかどる。
▼ 人工知能アドベントカレンダー「機械学習」
機械学習に関する各概念がシンプルにわかりやすく説明されている。
▼ 「著作権法 THE NEXT GENERATION~著作権の世界の特異点は近いか?」(COPYRIGHT No.666・奧邨弘司)
▼ 経済産業省産業構造審議会商務流通情報分科会情報経済小委員会分散戦略WG(第7回)事務局資料
▼ 知的財産戦略本部新たな情報財検討委員会(第1回)資料3「本検討委員会において検討すべき事項・論点、基本的な視点について(案)」
(弁護士柿沼太一)
【「AIと契約・知財・法律」セミナーのご案内】
2018年12月19日(水曜日)に東京で、2018年末時点におけるいわば「AI法務の総まとめ」として「AIビジネスの最前線からお送りする『AIと契約・知財・法律』」と題するセミナーを開催いたします。
過去の参加者の声や申込、詳細はこちらのページからどうぞ!












