人工知能(AI)、ビッグデータ法務
第三者のデータから学習用データセットや学習済みモデルを適法に生成・利用できるのはどのような場合か具体的に考えてみる
前回の記事「第三者のデータやデータセットを利用して適法にAIを生成するための基礎知識」に引き続き、「第三者のデータから学習用データセットや学習済みモデルを適法に生成・利用できるのはどのような場合か具体的に考えてみる」の記事です。

Hexagon grid with various terms for machine learning with a robot head 3D illustration
この記事を読む前に、ぜひ前回の記事を読んでみてください。
その方が今回の記事をより楽しめると思います。
Contents
- 1 ■ 今回の記事の全体像
- 2 ■ 第三者の生データ収集、データベース作成、学習用データセット作成、機械学習、深層学習を一連の流れとして行い、当該学習済みモデルを提供・販売する行為は適法なのか
- 3 2 第三者の生データからデータベースを作成し、当該データベースにラベル処理等をして学習用データセットを作成し、当該データセットを公表・販売する行為は適法なのか
- 4 3 第三者の学習用データセットを利用して機械学習、深層学習を行って学習済みモデルを生成し、当該学習済みモデルを提供・販売する行為
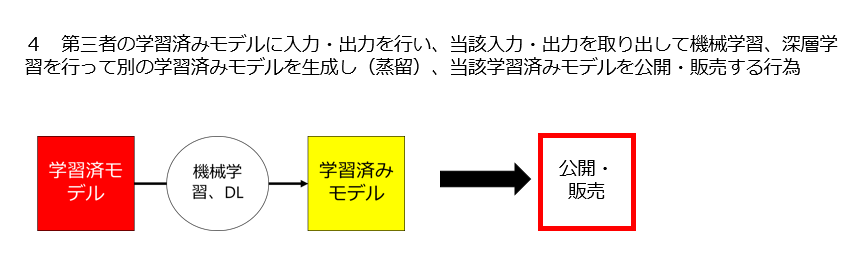
- 5 4 第三者の学習済みモデルに入力・出力を行い、当該入力・出力を取り出して機械学習、深層学習を行って別の学習済みモデルを生成し(蒸留)、当該学習済みモデルを提供・販売する行為
- 6 ■ まとめ
■ 今回の記事の全体像
前回記事と重複しますが、念のため再掲します。
人工知能については、2つのフェーズがあります。
1つは「人工知能を作るフェーズ(学習フェーズ)」、もう1つは「作成された人工知能を使うフェーズ(予測・認識フェーズ)」です。
両者を簡単に図示しておきます。
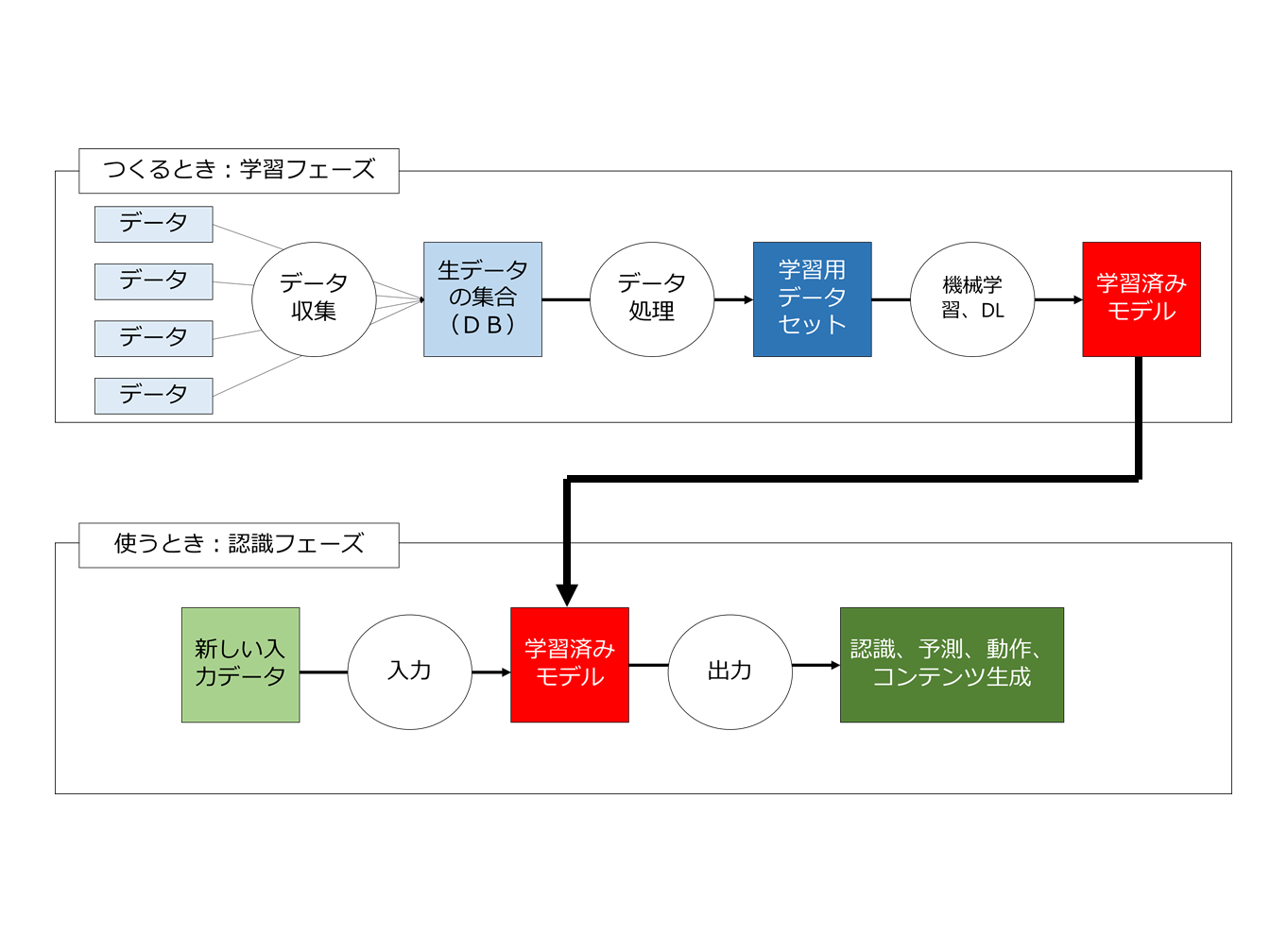
今回検討するのは以下の4つの問題です。
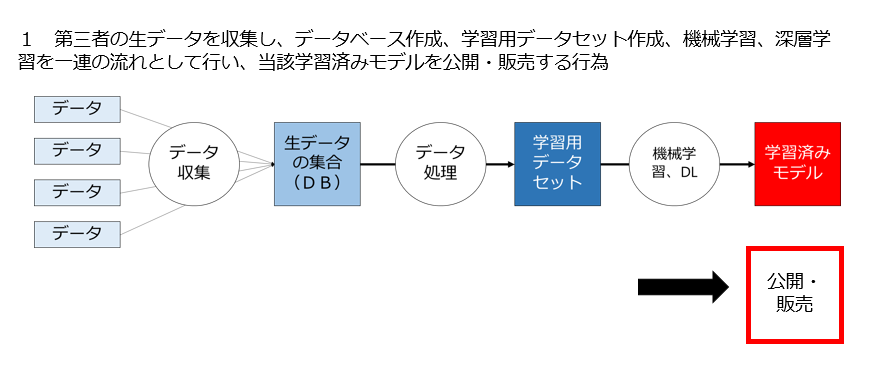
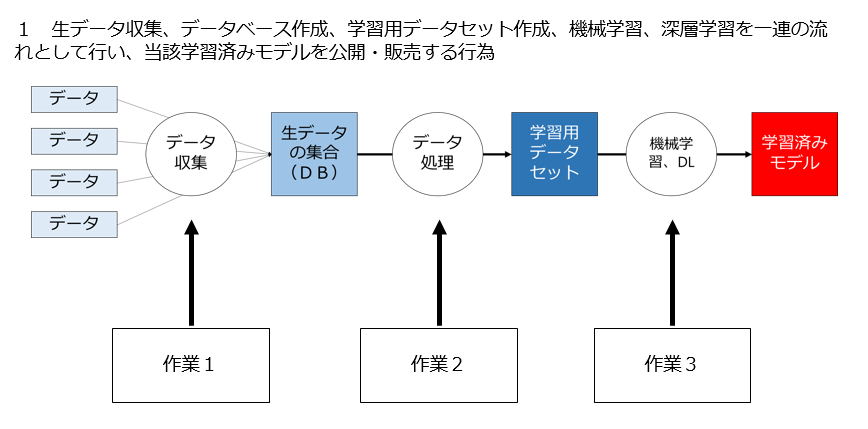
1 第三者の生データを収集し、データベース作成、学習用データセット作成、機械学習、深層学習を一連の流れとして行い、当該学習済みモデルを提供・販売する行為は適法なのか
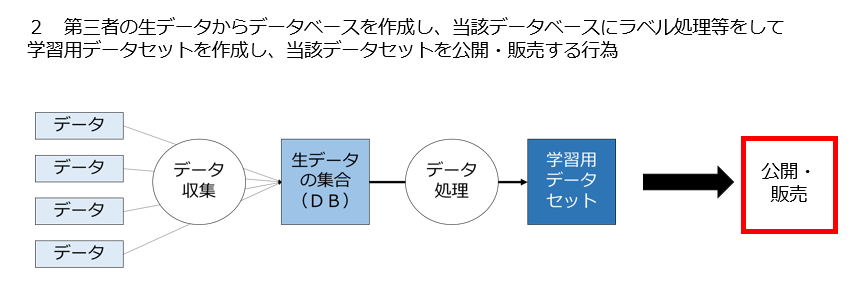
2 第三者の生データからデータベースを作成し、当該データベースにラベル処理等をして学習用データセットを作成し、当該データセットを提供・販売する行為は適法なのか
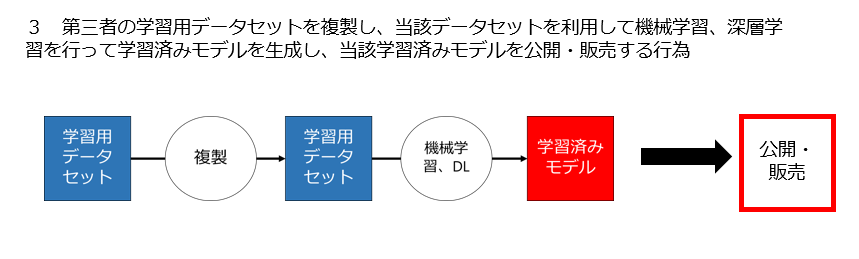
3 第三者の学習用データセットを利用して機械学習、深層学習を行って学習済みモデルを生成し、当該学習済みモデルを提供・販売する行為は適法なのか
4 第三者の学習済みモデルに入力・出力を行い、当該入力・出力を取り出して機械学習、深層学習を行って別の学習済みモデルを生成し(蒸留)、当該学習済みモデルを提供・販売する行為は適法なのか
図で示すとこんな感じですね。
上記4つの問題を検討する際に場合分けが必要なのは、元になる「生データ」「データベース」「学習用データセット」「学習済みモデル」について自分以外の第三者が何らかの権利を持っているかどうかです。
自分が権利を持っている生データを基に何をしても自由なのは当然ですが、第三者が何らかの権利を持っている生データやデータベース等を利用して、データベースやモデル生成行為を行うことが適法なのかが実務的には重要です。
■ 第三者の生データ収集、データベース作成、学習用データセット作成、機械学習、深層学習を一連の流れとして行い、当該学習済みモデルを提供・販売する行為は適法なのか
注意して欲しいのは、このパターンはあくまで、生データから学習済みモデル生成までの作業を一連の流れで行う場合を想定しています。どこか途中から作業が開始する、あるいは途中で作業が終わる場合は別のパターンになりますので当該パターンの解説を参照してください。
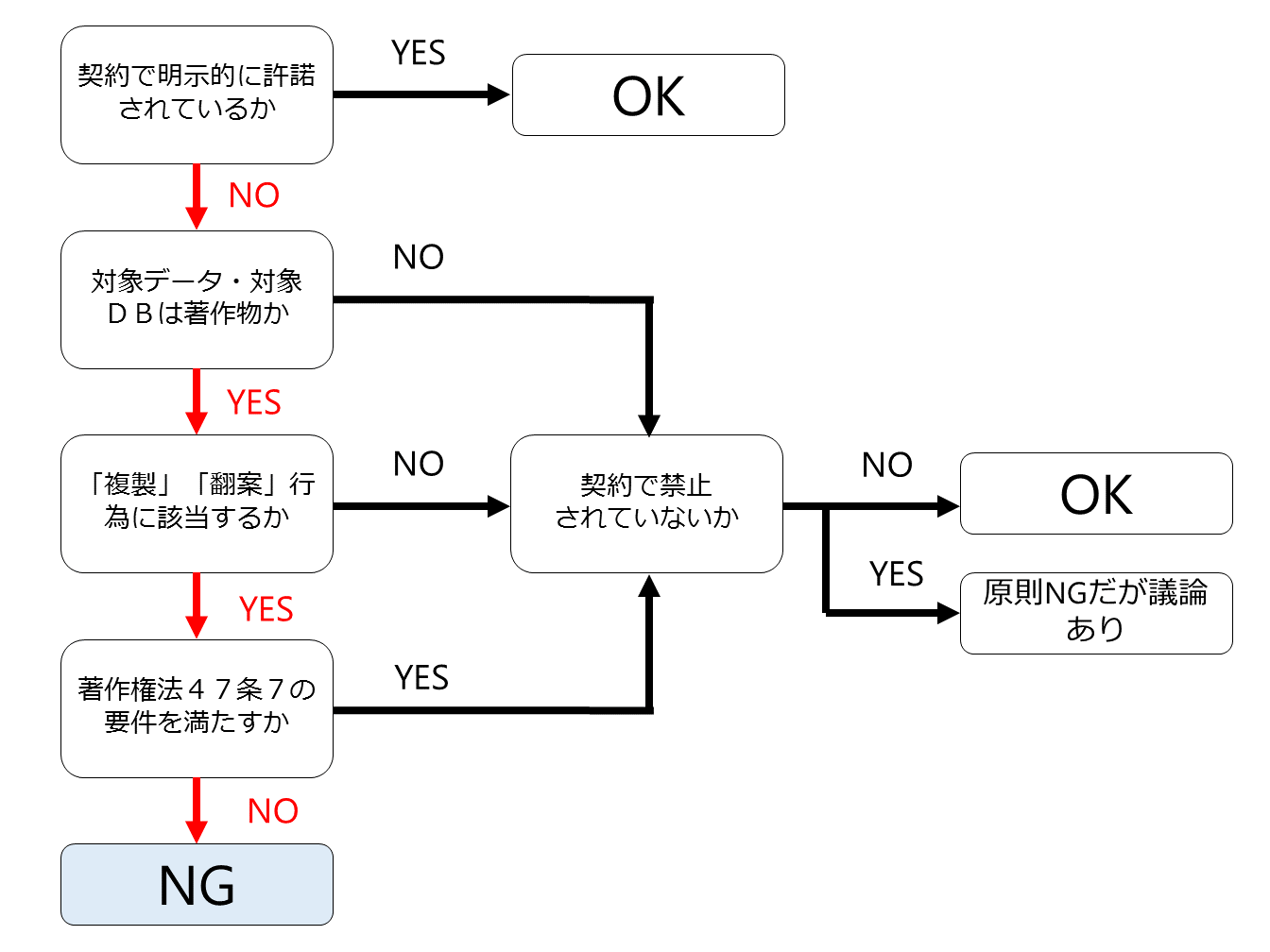
先ほど説明したように、第三者の生データが「著作物」かどうかで場合分けをする必要があります。
【(1) 第三者の生データが「著作物」である場合】
たとえば、WEB上の大量の写真、画像を収集してデータベースを作成し、当該データベースにラベルを付して学習用データセットを作成、当該学習用データセットを用いて深層学習を行って、画像識別用AIを生成する場合などです。
▼ 作業1
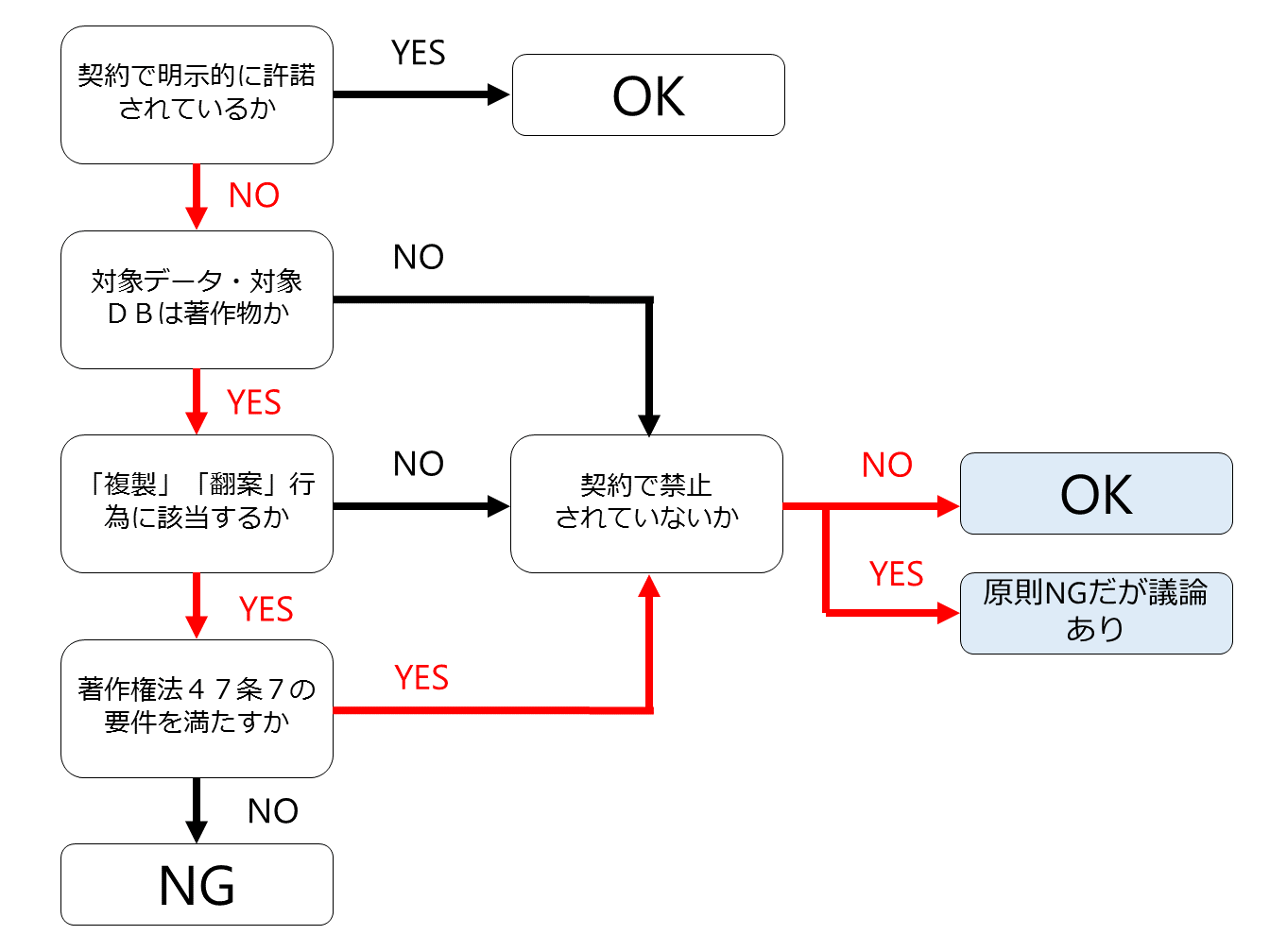
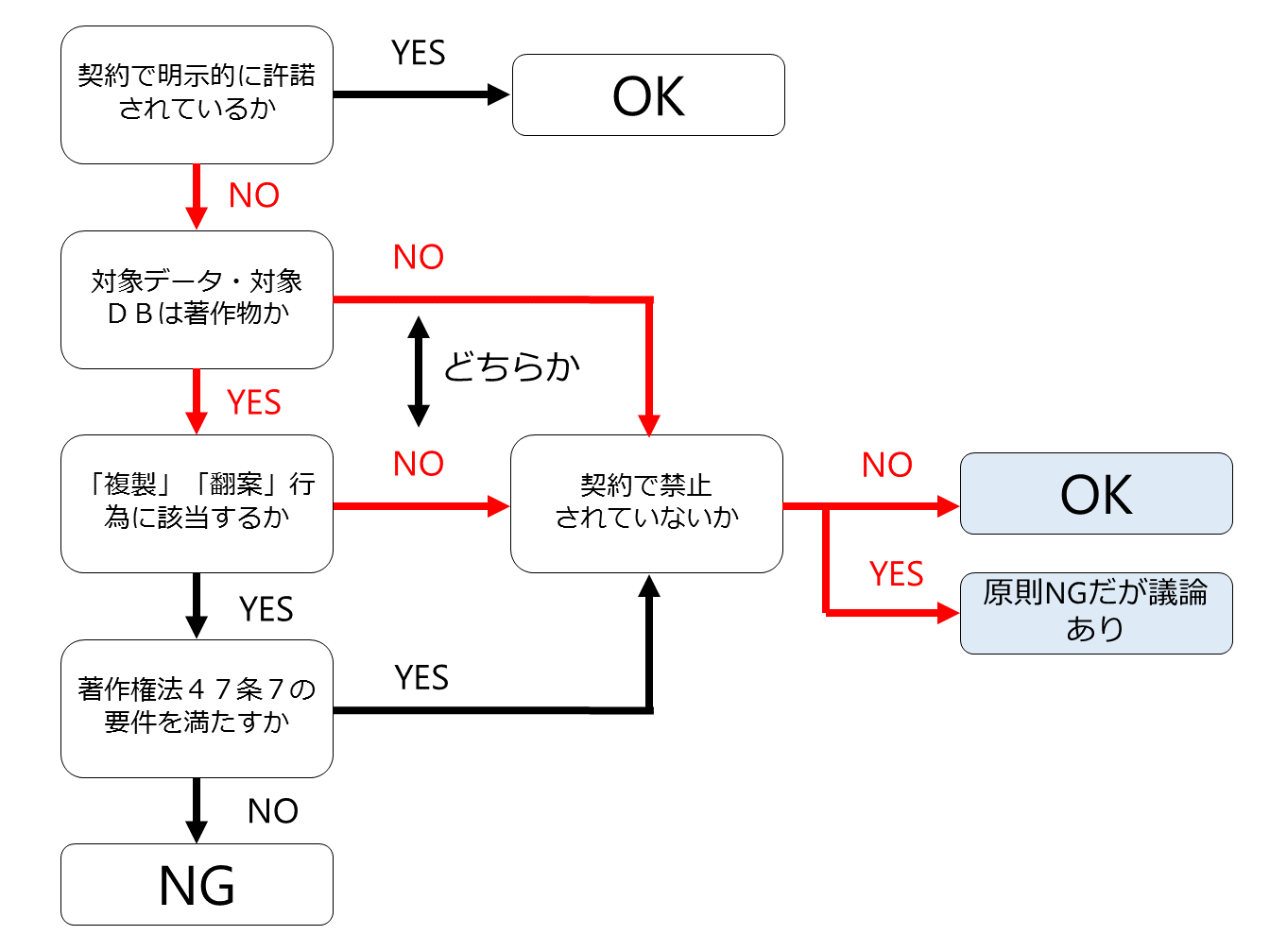
前回紹介したフローチャートを使って判断していきましょう。
まず、対象となる生データは著作物であることが前提で、しかも作業1は、生データをコピーしてきてDBを作成する行為ですので、生データの「複製」行為を行っていることになります。
次に著作権法47条の7の適用があるかです。
この点については、前回記事で説明したように、著作権法47条の7が深層学習にも適用があると理解すると、作業1については著作権法47条の7の適用があり、個々の著作者の同意を得なくても原則として著作権侵害にはならない、ということになります。
ただし、これまた前回記事で説明したように契約で別の定めがある場合には様々な見解があり得ます。
▼ 作業2
作業2についても先ほどのフローチャートに沿って判断することになります。
作業2は、生データの集合(DB)にラベルなどを付して学習用データセットを生成する行為ですが、生データに様々な情報を付したり変形したりしていますので、生データの「翻案」行為を行っていることになると思われます。
そして、先ほどの作業1と同様、深層学習用の学習済みモデル生成のためであれば、著作権法47条7の適用がありますので、著作権者の了解を得なくても原則として作業2を適法に行うことができます。
▼ 作業3
作業3は、学習用データセットを用いて機械学習・深層学習を行って学習済みモデルを生成する作業です。
この作業は作業1,2とちょっと違います。
というのは、学習用データセットという著作物を利用してはいるのですが、「学習用データセットを元に学習済みモデルを生成する行為」は「複製」でも「翻案」でもないのです。
「複製」とは「印刷、写真、複写、録音、録画その他の方法により有形的に再製すること」(著作権法2条1項15号)で、「翻案」とは簡単にいうと「ある著作物の表現上の本質的な特徴の同一性を維持しつつ,具体的表現に修正,増減,変更等を加える行為」(最高裁江差追分事件)です。
しかし、通常は、生成された学習済みモデルの中には生データや学習用データセットの痕跡は全く残っていません。そのような場合、学習済みモデル生成行為は「複製」でも「翻案」でもないことになります(ちなみに、データセットのデータ構造がほぼそのままモデルの中に残るモデル生成方法もあるようです。そのような場合には別途検討が必要となります)
したがって、学習用データセットを元に学習済みモデルを生成する行為は「複製」「翻案」ではないことから、著作権者の同意を得なくても行うことができる、ということになります。
ただ、ここでも「このデータを機械学習・深層学習用の学習済みモデル生成のために利用すること(著作権法47条の7に定める「記録・翻案」を含む)を禁じます」という契約の規定がある場合にはどうなるか、という問題は残ります。
▼ まとめ
以上をまとめますと、生データに第三者の著作権がある場合でも、契約に別段の定めがなければ、生データ収集、データベース作成、学習用データセット作成、機械学習、深層学習を一連の流れとして行い、当該学習済みモデルを提供・販売する行為は適法である、ということになります。
「契約に別段の定めがなければ」という点がおそらく実務的には最大のポイントであることは前回記事で強調したとおりです。
【(2) 生データが第三者の著作物ではない場合】
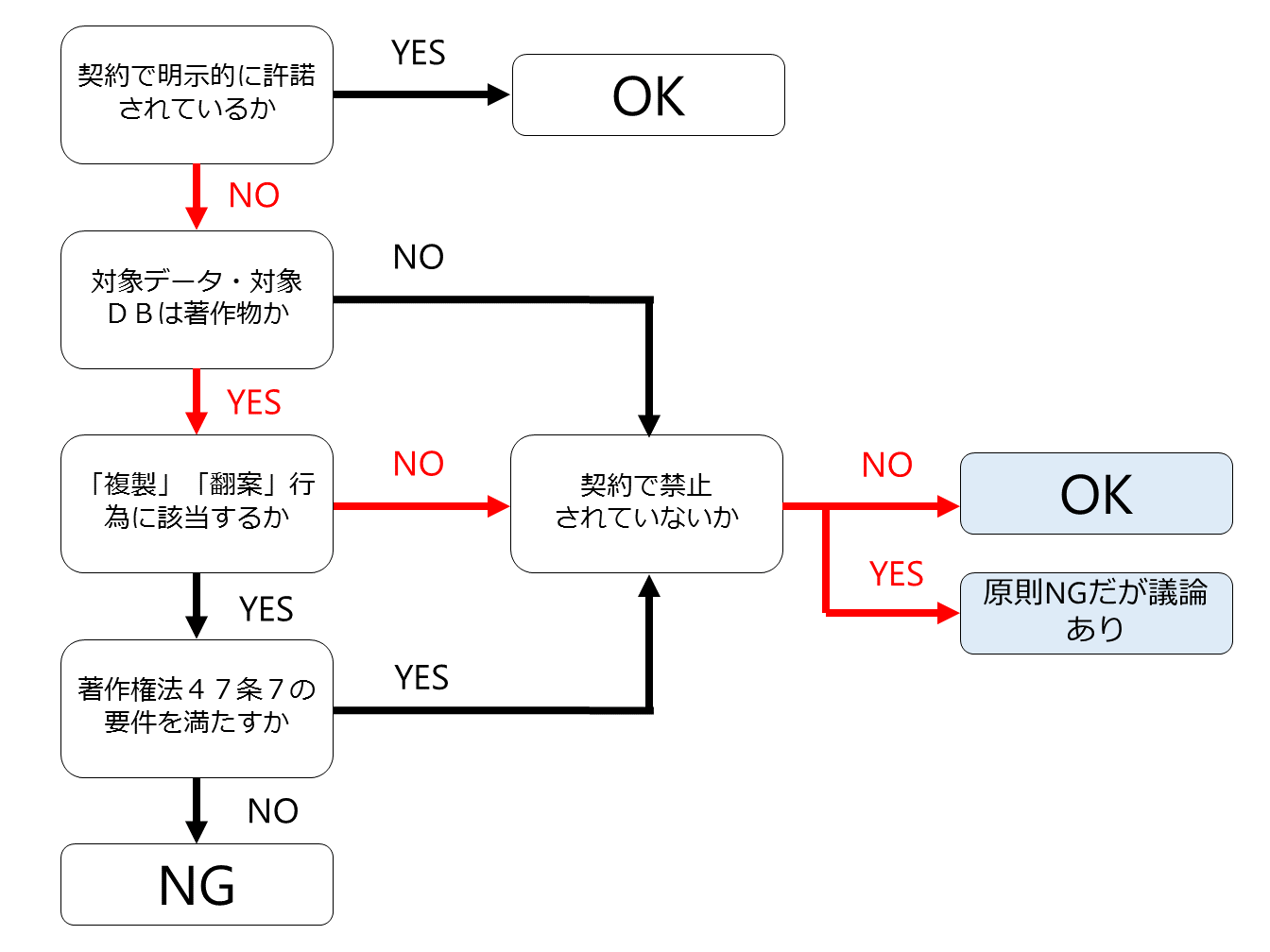
この場合でも(1)の「生データに著作権がある場合」とまったく同じ作業1~3が必要となりますが、第三者の著作権がない場合ですので、例のフローチャートの第2分岐のみで判断することになります。
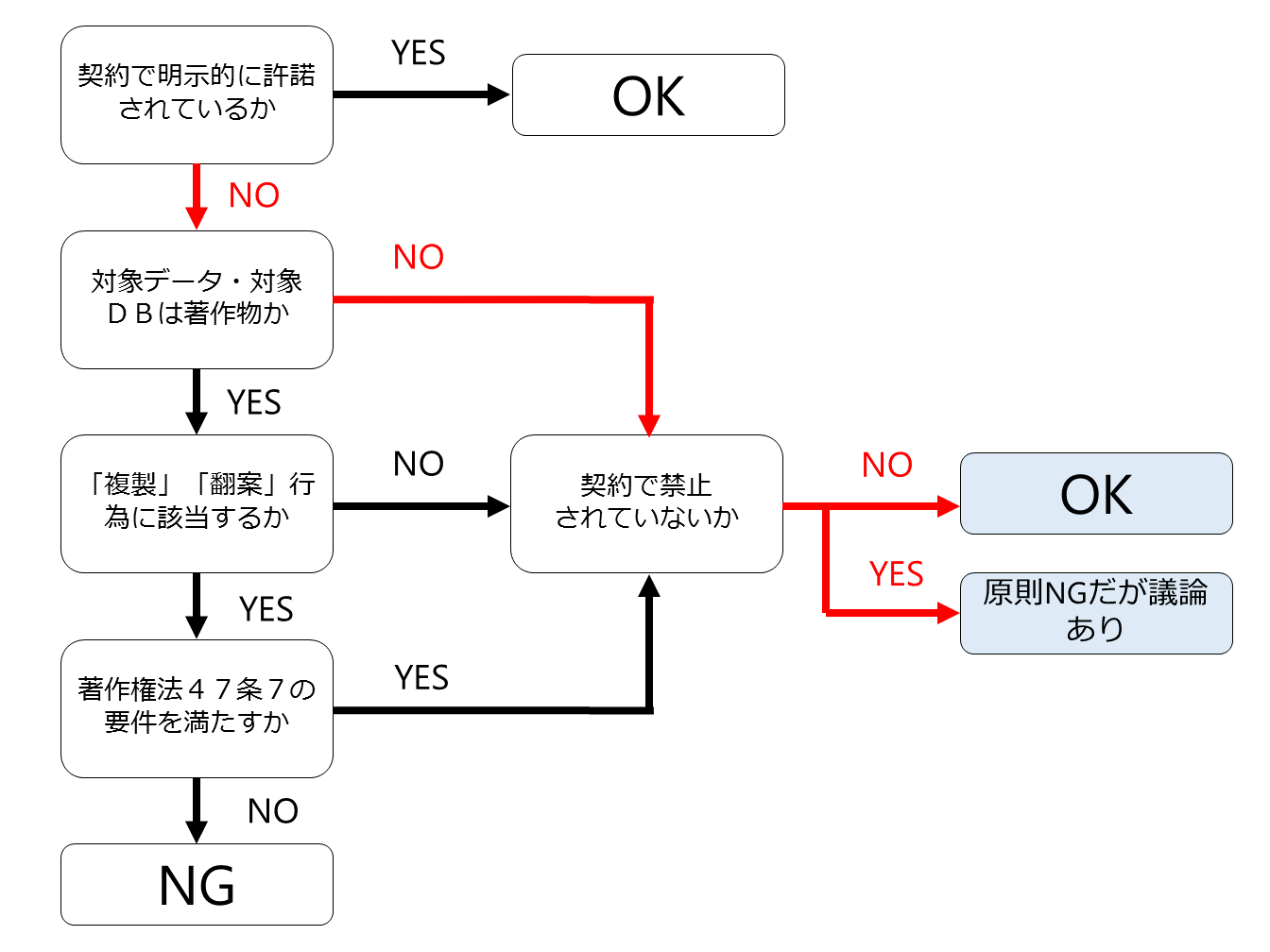
となると、(2)の場合でも、(1)と同じ結論、つまり契約に別段の定めがなければ、生データ収集、データベース作成、学習用データセット作成、機械学習、深層学習を一連の流れとして行い、当該学習済みモデルを提供・販売する行為は適法である、ということになります。
2 第三者の生データからデータベースを作成し、当該データベースにラベル処理等をして学習用データセットを作成し、当該データセットを公表・販売する行為は適法なのか
これは、1と異なり学習済みモデルの生成まで行わず、学習用データセット生成までを行い、当該データセットを公表・販売する行為です。
【(1) 生データが第三者の著作物である場合】
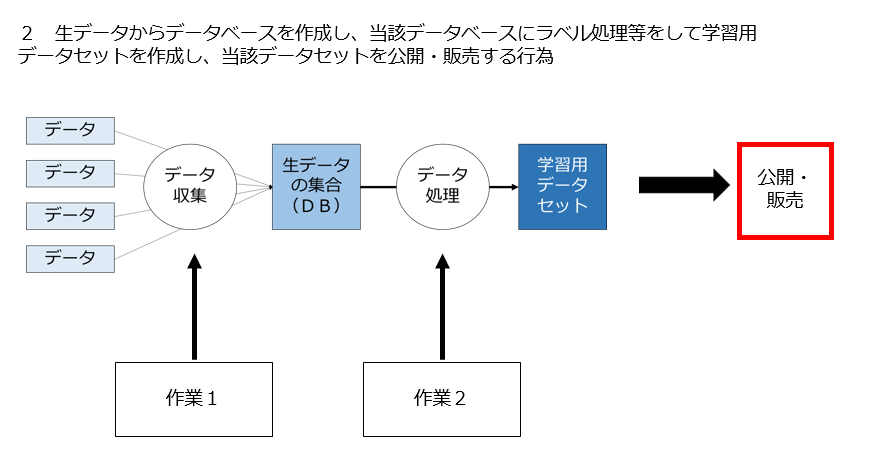
この場合も作業1、作業2について例のフローチャートを使います。
この場合は、作業1、2共に「対象データが著作物」でありかつ「複製・翻案行為」です。ですので、「著作権法47条の7の適用があるか」によって適法か否かが決まることになります。
結論から言うと、このパターンについては「著作権法第47条の7は適用されない」、つまり違法になります。
著作権法47条の7は「情報解析」のための記録・翻案だけを許容する規定です。そして、同条は、情報解析を行う主体自らが記録・翻案を行うことを前提としているため、他人の情報解析のために記録・翻案を行う行為は含まれません。
また、47条の7で認められるのはあくまで「記録・翻案」に限られ、譲渡や公衆送信を行うことができません。
したがって、第三者の著作物である生データからデータベースを作成し、当該データベースにラベル処理等をして学習用データセットを作成し、当該データセットを公表・販売する行為は現行の著作権法の下では違法ということになります。
【(2) 生データが第三者の著作物ではない場合】
この場合は、作業1、2共に例のフローチャートの第2分岐のみ使いますので、契約に別段の定めがなければ適法であるということになります。
3 第三者の学習用データセットを利用して機械学習、深層学習を行って学習済みモデルを生成し、当該学習済みモデルを提供・販売する行為
前回記事で説明したように、データーベースは「その情報の選択又は体系的な構成によって創作性を有するもの」であれば「データベースの著作物」として保護されますが、そのような創作性がないデータベースは著作権法上は保護されません。
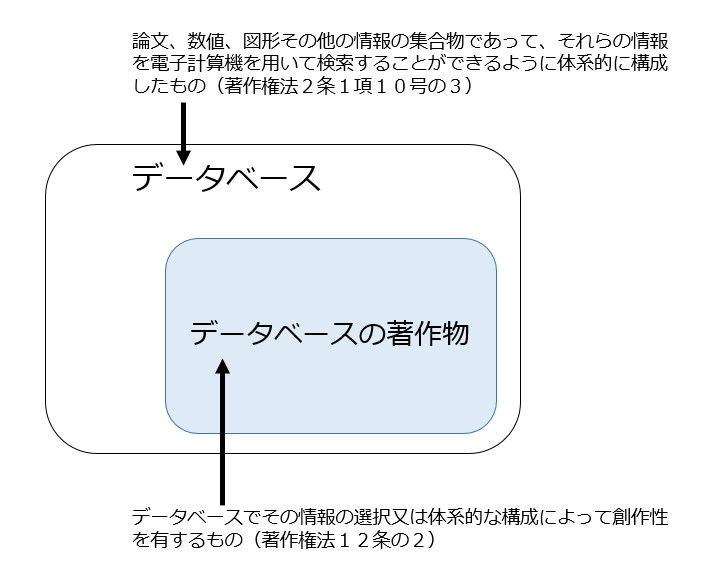
ですので、3のパターンにおいては、「第三者の学習用データセット」が「データベースの著作物」である場合もありますし、そうでない場合もあります。
学習用データセットにおけるデータへのラベルの付与の仕方にはいろいろあります。単純に各データの全体にラベルを振る場合もあれば、各データの一部の領域にラベルを振る場合もあります。ラベルの振り方によって、訓練の仕方の幅が広がったり、精度が高くなりやすかったりするので、この点には創意工夫が必要であり、そのような工夫がなされたデータセットについては「データベースの著作物」に該当することもあるでしょう。
逆に、いわゆるビッグデータを集積したデーターベースを元にしたデータセットの場合は、あらゆるデータが網羅的に記載されていることになりますので、データの選択や体系的構成にも創作性がないとして「データベースの著作物」には該当しないとされる可能性があります。
【(1) 第三者の学習用データセットが「データベースの著作物」である場合】
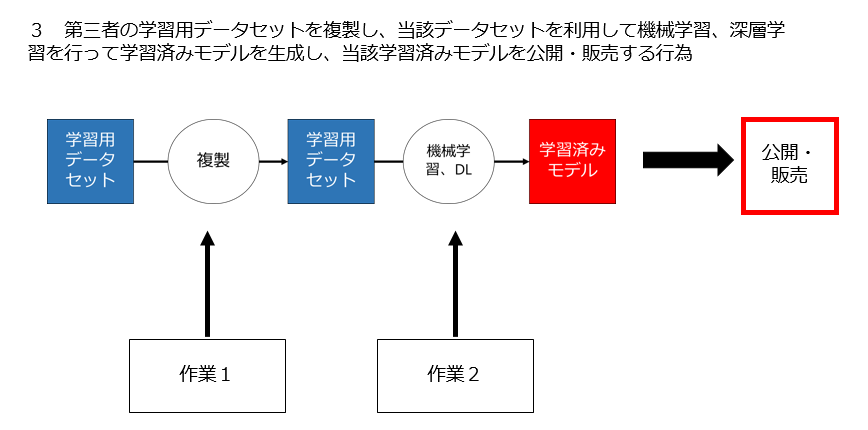
▼ 作業1
第三者の学習用データセットから学習済みモデルを生成する場合、どこか(たとえばサイトからデータセットをダウンロードするとき)では必ず学習用データセットを「複製」することになります。
これが、パターン3における作業1です。
この作業は、当該データベースの複製ないし翻案となりますので、フローチャート第1分岐、第2分岐を通過します。
で、深層学習=情報解析目的なので著作権法47条7の要件も満たす、と思うかもしれませんがちょっと待ってください。
条文をもう一度見てみましょう。
(情報解析のための複製等)
第四十七条の七 著作物は、電子計算機による情報解析(略)を行うことを目的とする場合には、必要と認められる限度において、記録媒体への記録又は翻案(略)を行うことができる。ただし、情報解析を行う者の用に供するために作成されたデータベースの著作物については、この限りでない。
「ただし、情報解析を行う者の用に供するために作成されたデータベースの著作物については、この限りでない。」とありますね。
ですので、データベースの著作物に該当するデータセットを元にした学習済みモデル生成行為については、著作権法47条7の要件を満たさず、原則として違法となります。
たとえば、医療用AIを生成するために、出版社が作成した医学論文のデータベース(データベースの著作物に該当するとします)を利用する場合がこれに該当します。
しかし、これはあくまで「データベースの著作物」が著作権法47条の7の例外だというだけで、「データベースの著作物」を構成する個々の著作物については例外にあたりません。ですので、たとえば、先ほどの医療用AIの例で言えば、データベースからではなく、データ自体、つまり医学論文そのものから直接複製する行為については著作権法47条7の適用があるということになります。
作業1が原則として違法ということになりますので、作業2の判断は不要となります。
【(2) 学習用データセットが「データベースの著作物」ではない場合】
この場合はフローチャートの第2分岐だけで判断されますので、契約に別段の定めがなければ適法であるということになります。
4 第三者の学習済みモデルに入力・出力を行い、当該入力・出力を取り出して機械学習、深層学習を行って別の学習済みモデルを生成し(蒸留)、当該学習済みモデルを提供・販売する行為
第三者の学習済みモデルに入力・出力を行い、当該入力・出力を取り出して機械学習、深層学習を行って別の学習済みモデルを生成することができます。
これを「蒸留」といいます。
「蒸留」については、清水亮氏の以下の記事に詳しく解説されています。
【参考記事】
深層ニューラル・ネットワークの効率を劇的に上げる「蒸留」
この「蒸留」が果たして適法なのか。
この点については著作権だけではなく、たとえば、ある学習済みモデルやその生成方法が特許により保護されている場合や、営業秘密として保護されている場合には別の検討が必要なのですが、ここでは著作権だけを考えてみます。
これもフローチャートに沿って判断することができます。
▼ 「学習済みモデル」は著作物なのか
まず、「学習済みモデル」は著作物なのかが問題となりますが、結論から言いますと著作物性を認めるのは非常に難しいと思います。
そもそもモデルは機械(プログラム)が自動的に生成しているものですから、人間の「創作」とは言えない可能性が高いでしょう。
さらに、たとえばニューラルネットワークの手法で生成された学習済みモデルは「ネットワークの構造+各リンクの重み」であり、「大量の数値の列」です。
このようなものが、著作権法における「データベースの著作物」や「プログラム」あるいはその他の著作物に該当するかというと、大いに疑問があります。
したがって、学習済みモデルは著作物に該当しないということになると思われます。
▼ 「蒸留」行為は「複製」「翻案」行為か
次に、このハードルを何とか越えて仮に学習済モデルが著作物として保護されるとしても、「蒸留」行為が「複製・翻案」行為かというと、これもおそらく否定されます。
学習済みモデルを直接複製しているわけではなく、あくまで入力・出力をコピーしてその結果を新しいモデルに学習させているだけだからです。
また、元になった学習済みモデルの「表現の本質的特徴」が新しい学習済みモデルに残っていると言うこともちょっと考えにくいでしょう。
したがって、仮に学習済みモデルが著作物だとしても、蒸留行為は適法であるということになると思われます。
契約で蒸留を禁止すれば結論は異なるかもしれませんが、実際問題として「この学習済みモデルは、別のモデルを蒸留したものである」ということを証明するのは極めて難しいので、契約で禁じても、ほとんど意味はないでしょう。
ちなみに、学習済みモデルを著作権では保護できないとなると、保護のためには別の方法を考えなければなりません。
この蒸留を防ぐ方法として、先ほどの清水氏の記事では「ネットワークのすべてをエッジに搭載させず、クラウド側に重要なニューラル・ネットワークを持つようにすることです。エッジ側では特徴抽出の前段階だけ行い、クラウド側に次元圧縮したデータを送ってクラウド側で推定するようにします。」という方法が提案されています。
■ まとめ
以上をまとめたのが下記表になります。

いかがでしたでしょうか。
AI生成に関する法的問題点については、まだまだ議論が始まったばかりです。
当事務所ではAI生成/提供をビジネスにしている企業の相談もお受けしておりますので、お気軽にお問い合わせください。
(弁護士柿沼太一)












