人工知能(AI)、ビッグデータ法務
第三者のデータやデータセットを利用して適法にAIを生成するための基礎知識
人工知能(AI)界隈の話題がますます盛り上がってきていまして、ネットや各マスメディアで人工知能(AI)のことを目にしない日はないほどです。

柿沼は個人的にAIにとても興味があるため、色々情報収集や勉強をしており、このブログでもAIネタの投稿がだいぶ溜まってきました。
【参考】
人工知能がコンテンツ業界に与えるインパクトを考えると冷や汗が出てくる
人工知能(AI)を利用したビジネスモデルを考えてみた
人工知能(AI)が作ったコンテンツの著作権は誰のものになるのか?
自動運転で事故した場合、運転手に法的責任はあるのか?
弁護士による人工知能(AI)、機械学習、深層学習(ディープラーニング)の基礎講座
で、最近はさらにAIのことをよりよく知るために
・ データアナリストの方にお願いして機械学習・深層学習について個別連続レクチャーを受けたり
・ 有名国内AIベンチャーの最高知財責任者の方とお会いしたり
・ お仕事で知り合ったAI系の会社の方に厚かましく機械学習のことを根掘り葉掘り聞いたりしています。
とくにデータアナリストの先生による個別レクチャーについては、毎回3時間、1対1で、機械学習の理解に必要な数学や統計の基礎からPythonの基本的な使い方などみっちり教えて頂いています。予習復習もろくにしていないダメ生徒である私に、毎回キレることなく優しく、冷静に教えてくれる先生にはいつも感謝しています。先生にはAIが搭載されているのかもしれません。
さて、
弁護士による人工知能(AI)、機械学習、深層学習(ディープラーニング)の基礎講座で書いたように、AIについては知的財産との関係を避けて通ることができません。
前回の記事では「2 人工知能(AI)、機械学習、深層学習と知的財産制度」について書きますと宣言しましたが、ちょっと漠然としすぎていますので、少し細切れにします。
今回は「第三者のデータやデータセットを利用して適法にAIを生成するための基礎知識」、次回は「第三者のデータから学習用データセットや学習済みモデルを適法に生成・利用できるのはどのような場合か具体的に考えてみる」です。
両方の記事を読んで頂ければ、おそらく「人工知能を作るフェーズ(学習フェーズ)についての法的問題点」については、ある程度理解できるのではないかと思います。
■ 今回と次回の記事の全体像
おさらいになりますが、人工知能については、2つのフェーズがあります。
1つは「人工知能を作るフェーズ(学習フェーズ)」、もう1つは「作成された人工知能を使うフェーズ(予測・認識フェーズ)」です。
両者を簡単に図示しておきます。
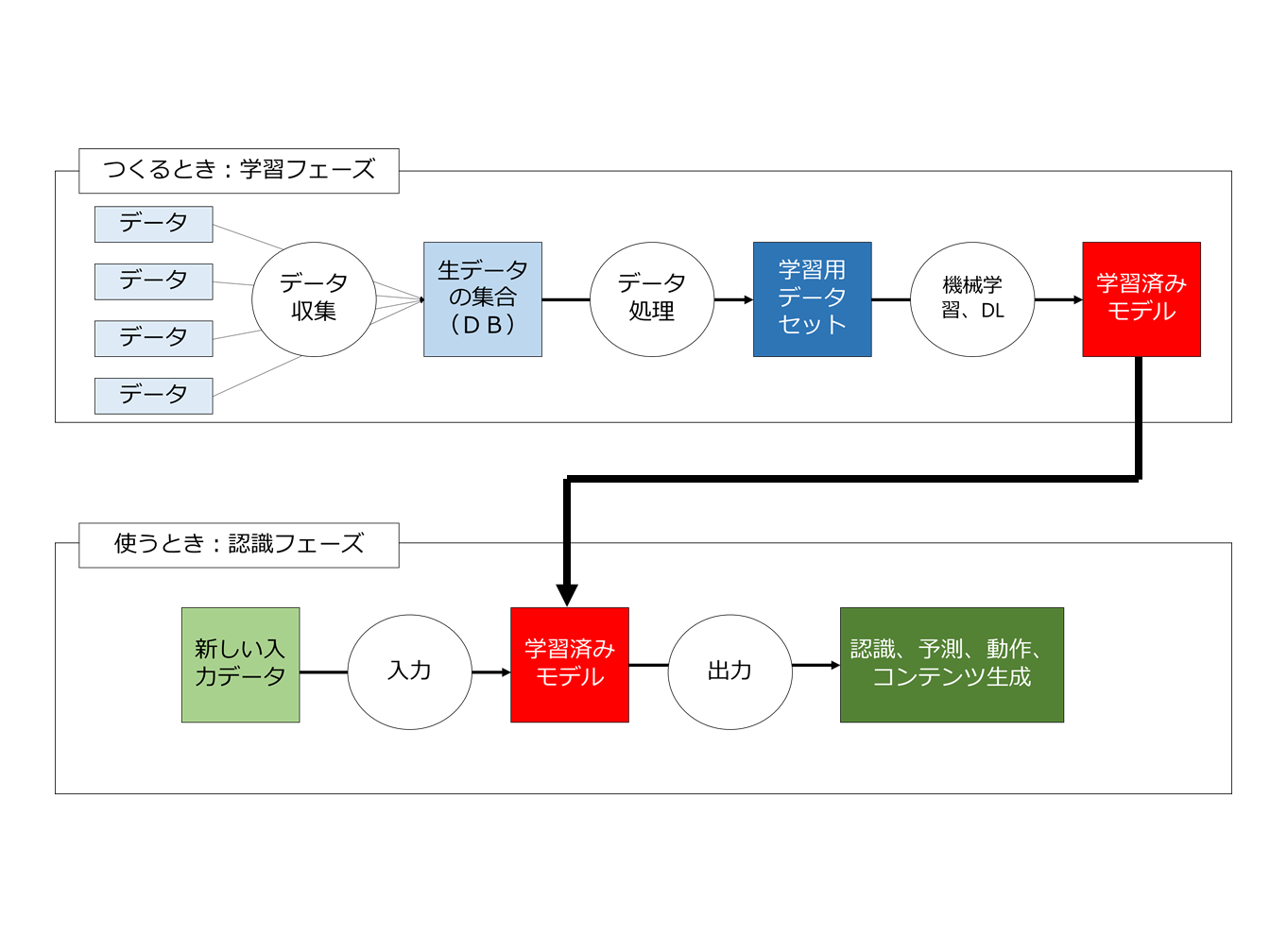
今回と次回のブログはこのうち「人工知能を作るフェーズ(学習フェーズ)」に関するもので、最終的に次回検討するのは以下の4つの問題です。
1 第三者の生データを収集し、データベース作成、学習用データセット作成、機械学習、深層学習を一連の流れとして行い、当該学習済みモデルを提供・販売する行為は適法なのか
2 第三者の生データからデータベースを作成し、当該データベースにラベル処理等をして学習用データセットを作成し、当該データセットを提供・販売する行為は適法なのか
3 第三者の学習用データセットを利用して機械学習、深層学習を行って学習済みモデルを生成し、当該学習済みモデルを提供・販売する行為は適法なのか
4 第三者の学習済みモデルに入力・出力を行い、当該入力・出力を取り出して機械学習、深層学習を行って別の学習済みモデルを生成し(蒸留)、当該学習済みモデルを提供・販売する行為は適法なのか
図で示すとこんな感じですね。
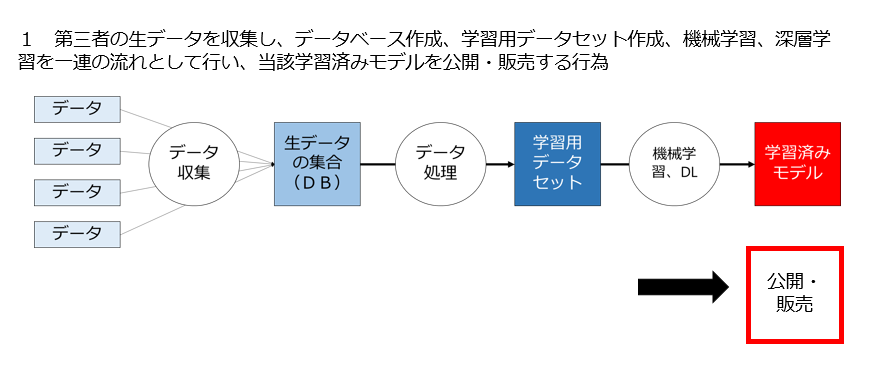
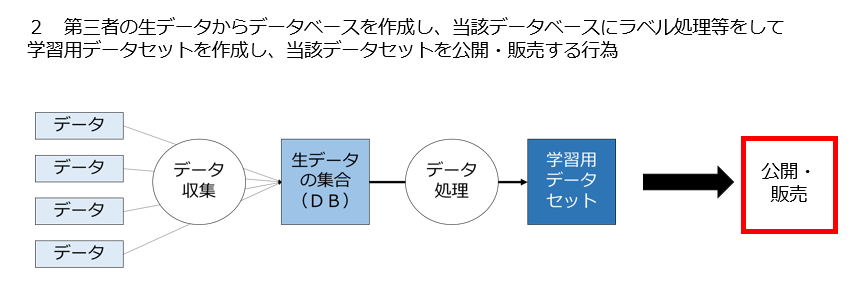
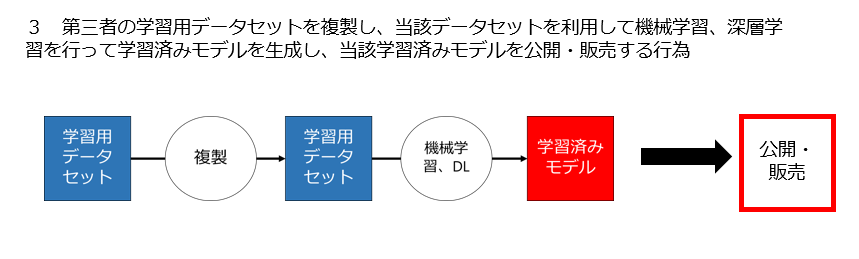
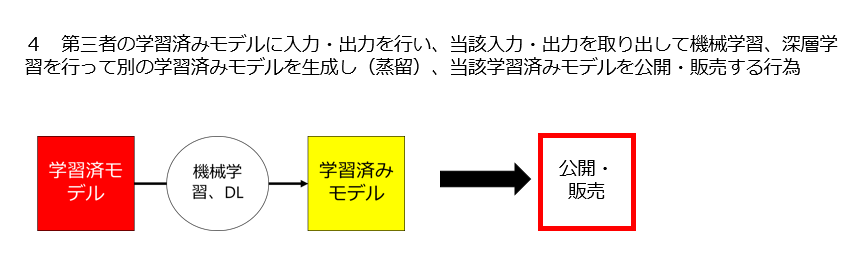
上記4つの問題を検討する際に場合分けが必要なのは、元になる「生データ」「データベース」「学習用データセット」「学習済みモデル」について自分以外の第三者が何らかの権利を持っているかどうかです。
自分が権利を持っている生データを基に何をしても自由なのは当然ですが、第三者が何らかの権利を持っている生データやデータベース等を利用して、データベースやモデル生成行為を行うことが適法なのかが実務的には重要です。
以下、まずは基礎知識を押さえていきましょう。
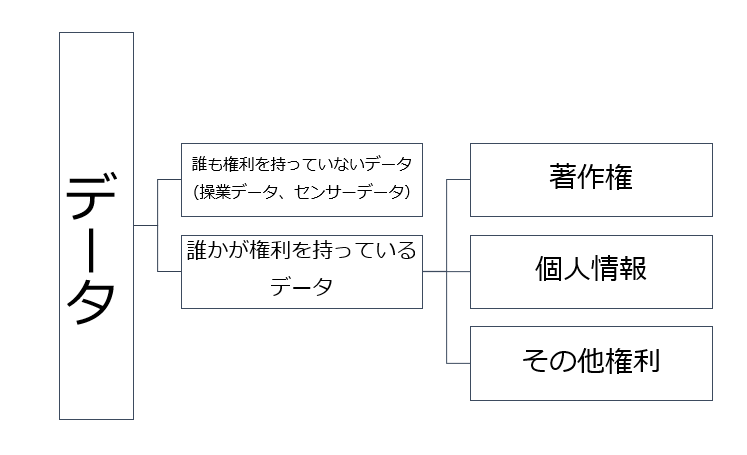
■ 生データに関する権利
生データには大きく分けて「誰も何の権利を持っていないデータ」と「誰かが何らかの権利を持っているデータ」があります。
前者については、たとえば、工場機械の操業データや自動車のセンサーデータ、天気のデータなどがあります。日本の法律ではデータそのものに何らかの権利が発生することはありませんので、それらのデータについては誰も何の権利も持っていません。
ですから、それら権利がないデータを利用してデータベースを作ったり、学習済みモデルを生成する行為は原則として何の問題もありません。
「誰かが何らかの権利を持っているデータ」についてもっとも問題になるのは著作権で保護されているデータ、つまり「著作物」です(個人情報は正確には「権利」ではないのですが、ここでは便宜的に記載しています)。
たとえば、文章、写真などの著作物は創作した人が著作権を持つ著作物ですから、WEB上の文章を元にコーパスを生成する場合や、WEB上の画像を元に画像識別用のモデルを生成する場合に、それら著作権者の著作権を侵害しないかという問題があります。
また、診断補助用の医療AIを生成する場合には、医学論文・文献など著作権があるデータ、大量の患者さんの診断データ・画像データなど個人情報が含まれているデータを利用しなければなりませんが、そのようなことが可能なのかどうかが問題となります。
このように「誰も何の権利を持っていないデータ」と「誰かが何らかの権利を持っているデータ」かでは、その後の処理の仕方が全く異なりますので、場合分けが必要となります。
■ データベースに関する権利
先ほど書いたように、生データは「誰も何の権利も持っていないデータ」と「誰かが何らかの権利を持っているデータ」があります。
しかし、これら生データが集合体(データベース)になると、ちょっと違った配慮が必要となります。
「誰も何の権利を持っていないデータ」のデータベースについては、元になるデータに権利がないのだから、その集合体であるデータベースにも権利は発生しないだろう、というのは実は間違いなのです。
著作権法では
・ 全てのデータベースが著作物となるわけではない。
・ ただし、一定の要件を満たしたデータベースについては「データベースの著作物」として保護される
ということになっています。
これはデータベースの構成要素であるデータそのものの著作物性とは無関係でして、データそのものに著作物性がなくても、その集合体であるデータベースに著作物性が発生することがあります。
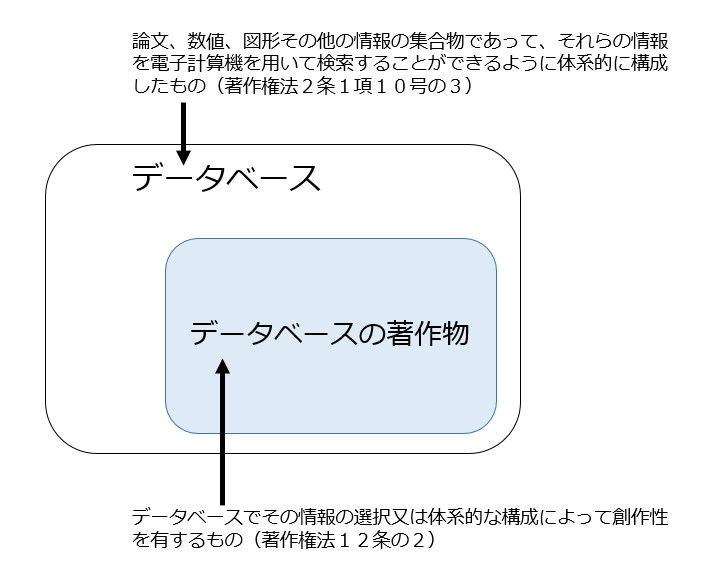
では、どのような場合に「データベースの著作物」として保護されるかですが、著作権法には以下の定めがあります。
(データベースの著作物)
第十二条の二 データベースでその情報の選択又は体系的な構成によつて創作性を有するものは、著作物として保護する。
2 前項の規定は、同項のデータベースの部分を構成する著作物の著作者の権利に影響
つまりデータベース(DB)のうち、「その情報の選択又は体系的な構成によって創作性を有するもの」については、仮に個々のデータに著作物性がなくても「データベースの著作物」として保護されることになるのです。
たとえば裁判で問題になったケースを紹介しますと、タウンページDB事件(東京地裁平成12年3月17日)があります。
これはNTTのタウンページを模倣した業種別データが、タウンページのDB著作権を侵害していると判断された事件です。タウンページに記載されているのは電話番号ですから、個々のデータに当然著作物性はありません。しかし、タウンページの場合「職業別分類体系」という体系に沿って電話番号が分類されているのですが、この「職業別分類体系」に創作性が認められたのです。
AI生成に関して言うと、たとえば生データに著作物性がなくても、そのDBや学習用データセット生成に際して、「その情報の選択又は体系的な構成によって創作性を有するもの」と評価されれれば、DBや学習用データセットに著作物性が発生する、ということになります。
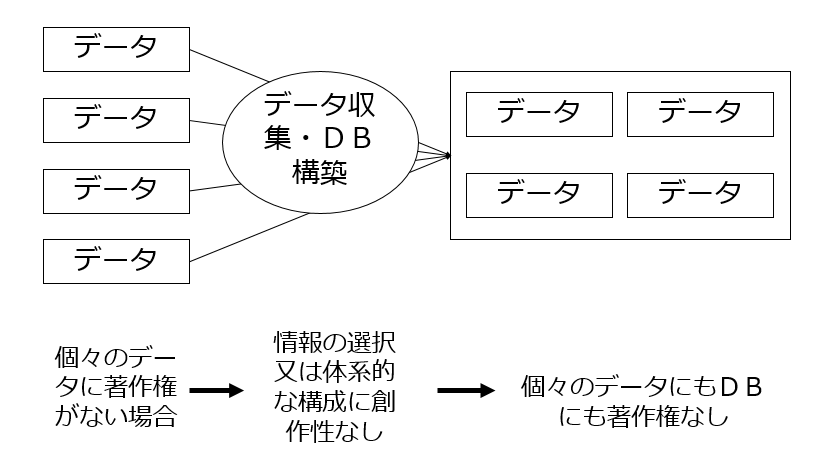
この場合にはDBに著作権が発生することはありませんが、
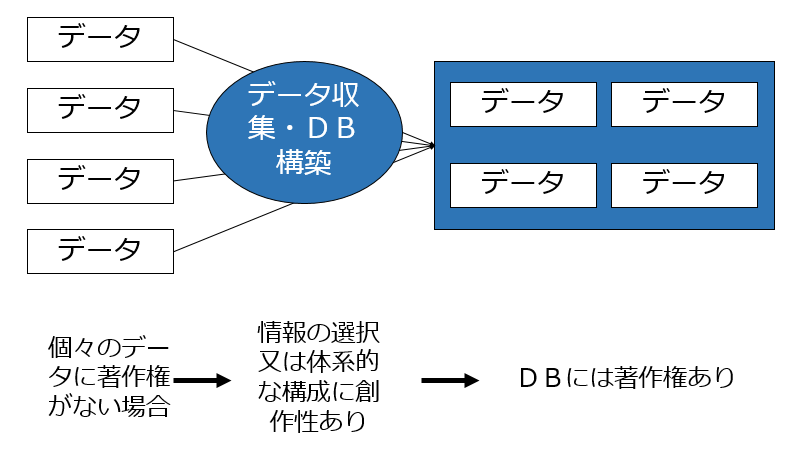
この場合にはDBに著作権が発生します。
学習用データセットにおけるデータへのラベルの付与の仕方にはいろいろあります。
単純に各データの全体にラベルを振る場合もあれば、各データの一部の領域にラベルを振る場合もあります。ラベルの振り方によって、訓練の仕方の幅が広がったり、精度が高くなりやすかったりするので、この点には創意工夫が必要であり、そのような工夫がなされたデータセットについては「データベースの著作物」に該当することもあるでしょう。
逆に、いわゆるビッグデータを集積したデーターベースを元にしたデータセットの場合は、あらゆるデータが網羅的に記載されていることになりますので、データの選択や体系的構成にも創作性がないとして「データベースの著作物」には該当しないとされる可能性があります。
■ 適法性判定のためのフローチャート
学習用データセットや学習済みモデル生成における各作業が適法かどうかを判定するためのフローチャートを作成してみました。
もしかしたら、もっと優れたフローチャートがあるかもしれませんが、とりあえずということで。
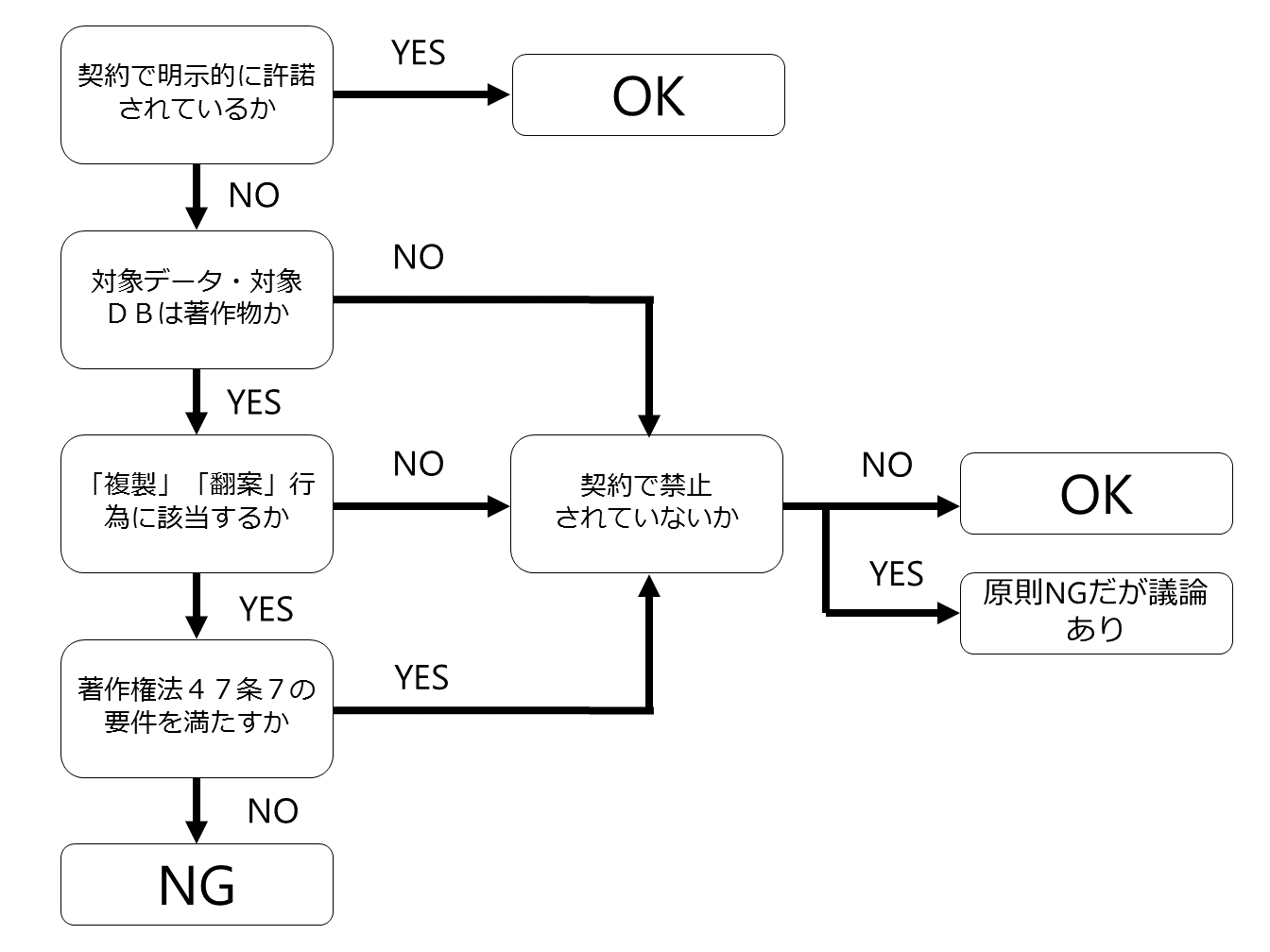
まず、このフローチャートについて説明をしますが、以下の5つがポイントです。
1 契約によって明示的に許諾されているか
2 対象データ・対象DBは著作物か
3 「複製」「翻案」行為に該当するか
4 著作権法47条7の要件を満たすか
5 契約で禁止されていないか
【1 契約によって明示的に許諾されているか】
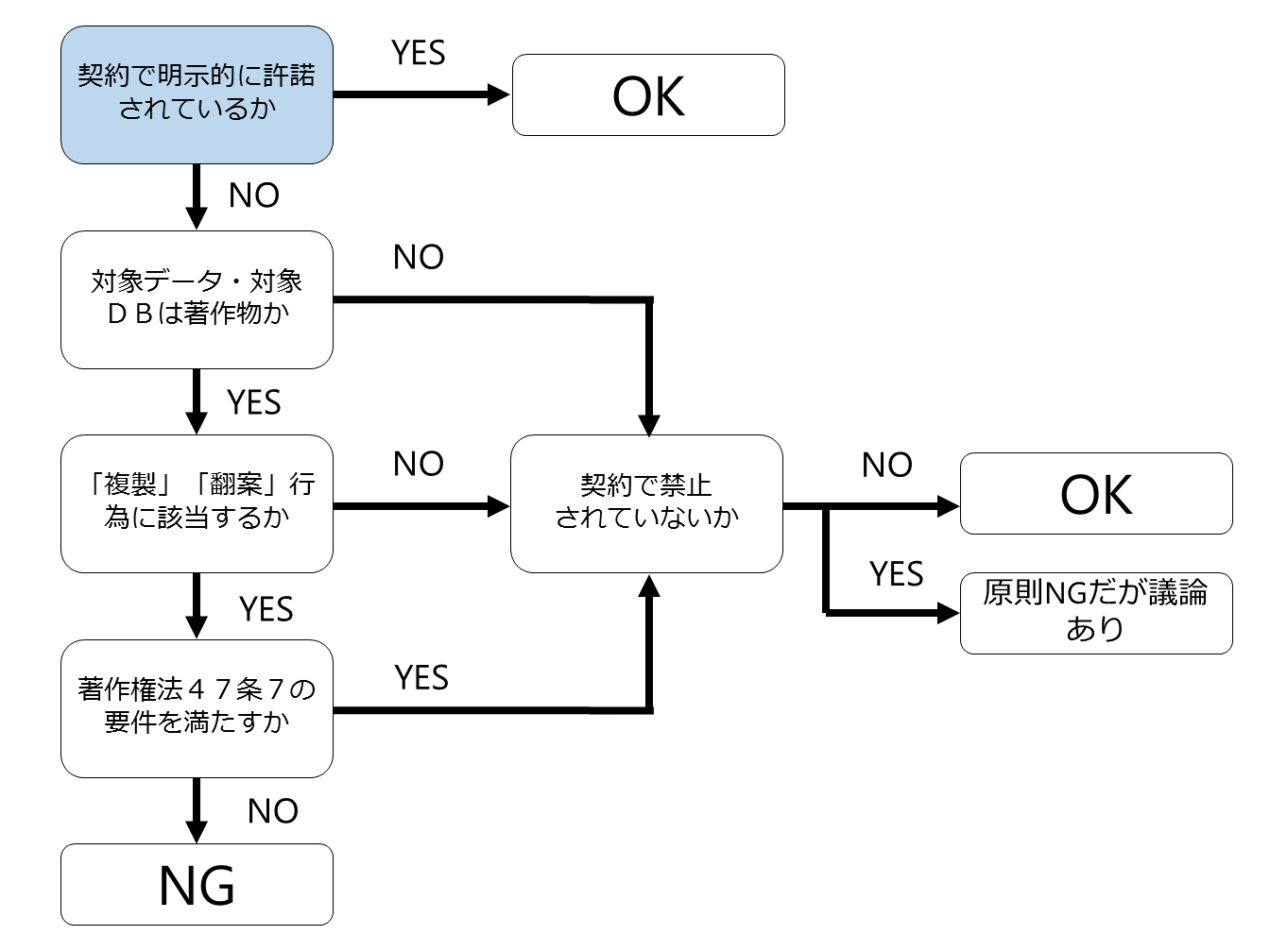
まず、対象となる生データや学習用データセットについて契約や規約によって明確に「営利目的でも利用していいよ」とされている場合があります。
たとえば、学習用データセットはMITライセンスの下で公開されていることがあります。
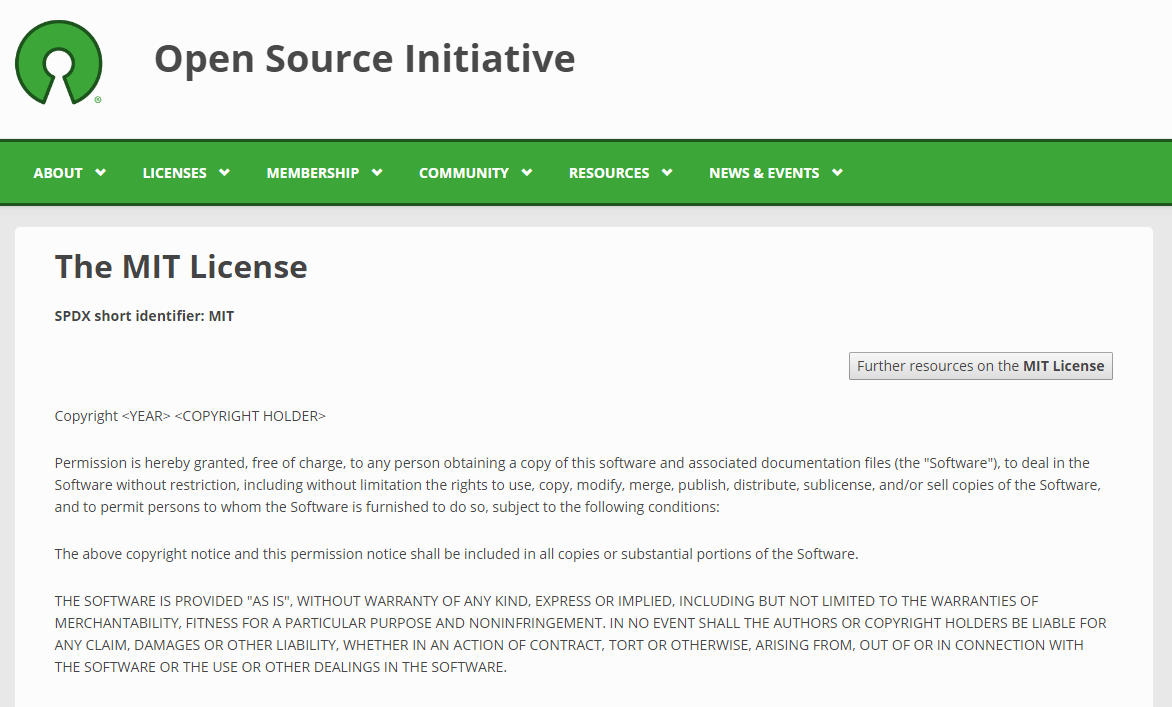
https://opensource.org/licenses/mit-license.phpより引用
このMITライセンスとは具体的には以下の内容です。
・ 改変でも、再配布でも、商用利用でも、有料販売でも、どんなことにでも自由に無料でつかうことができる。
・ そのための条件は、「著作権表示」と「MITライセンスの全文」を記載することのみ。
このMITライセンスの下で公開されている学習用データセットであれば、条件さえ守れば営利目的でも利用することができ、学習済みモデルを生成して提供・販売することも当然「適法」ということになります。
【2 対象データ・対象DBは著作物か】
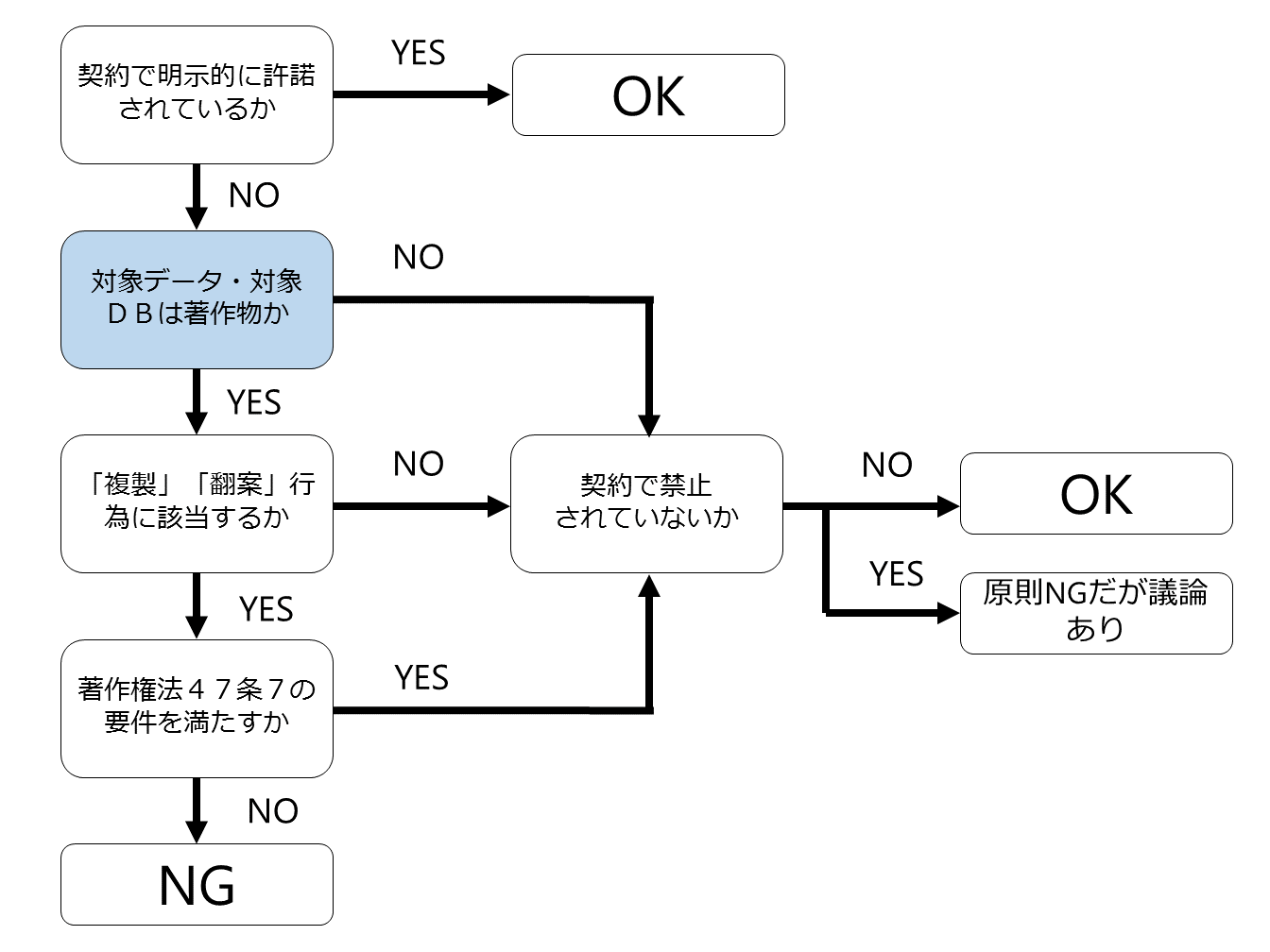
2以下は契約や規約によって明示的に許諾されていない場合です。
まず、対象データ・対象DBが著作物ではない場合は、契約で別の定めがなければ、誰がどのように利用するのも原則として自由です。
したがって、対象データ・対象DBが著作物かどうかが2つめのチェックポイントとなります。
【3 「複製」「翻案」行為に該当するか】
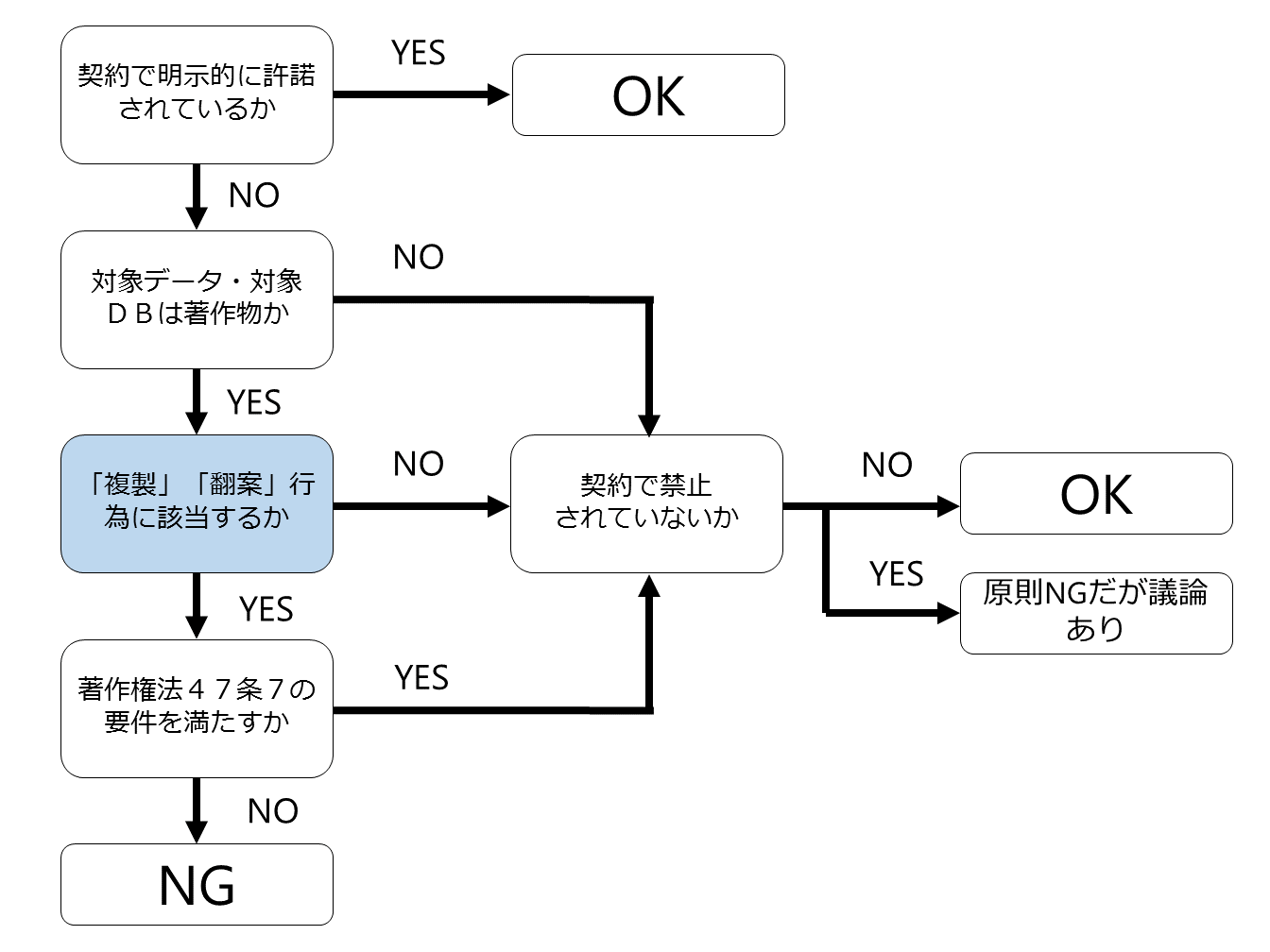
次に、対象データ・対象DBが著作物だとしても、その著作物の「複製」や「翻案」などの著作物の利用行為にあたらない行為は、自由に行うことができます。
著作権法上、「複製」や「翻案」については定義規定や確定判例がありますので(詳しくは後述)、その概念に該当するかどうかが3つめのチェックポイントになります。
ちなみに、結論を先走って言うと、機械学習行為・深層学習行為は「複製」にも「翻案」にも該当しません。
【4 著作権法47条7の要件を満たすか】
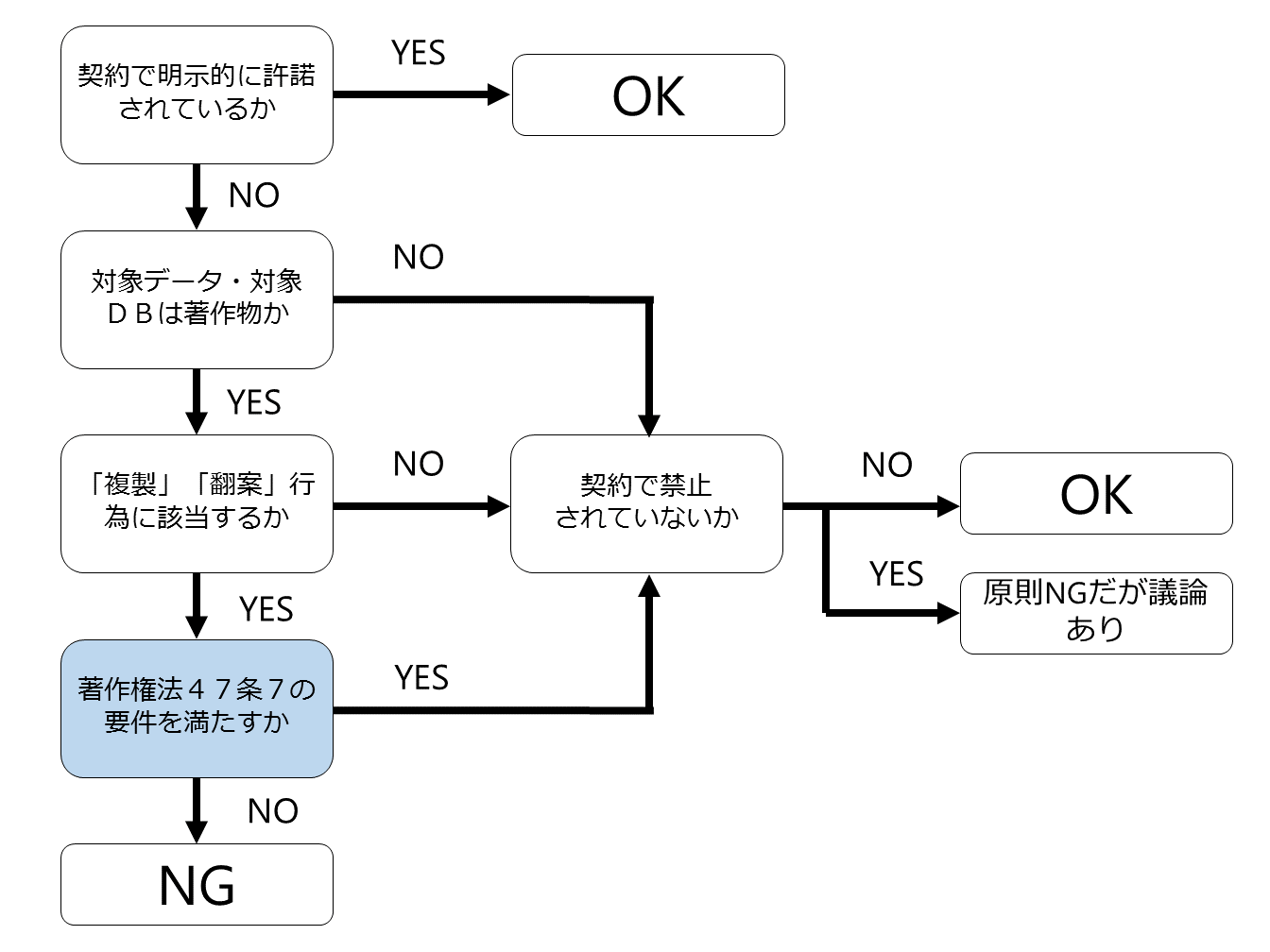
▼ 著作権法47条の7
著作権法47条の7は学習済みモデル生成に際しては非常に重要な条文ですのでぜひ覚えておいてください。
条文は以下のとおりです。
第四十七条の七 著作物は、電子計算機による情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の統計的な解析を行うことをいう。以下この条において同じ。)を行うことを目的とする場合には、必要と認められる限度において、記録媒体への記録又は翻案(これにより創作した二次的著作物の記録を含む。)を行うことができる。ただし、情報解析を行う者の用に供するために作成されたデータベースの著作物については、この限りでない。
簡単に言うと「情報解析」のためであれば、必要な範囲で、著作権者の承諾なく著作物の記録や翻案ができる、というものです(ただし一部例外あり)。
この場合「情報解析」に「深層学習」が含まれるとすれば、「深層学習」のためであれば著作物について自由に記録や翻案ができる、ということになります。
この点については定まった学説はありませんが、慶応大学教授の奥邨弘司先生などは「情報解析」に「深層学習」は含まれるとしていますし、条文の定め方からなどから考えると、私も同じ意見です。
▼ 深層学習にこの条文を適用する際のポイント
深層学習にこの条文を適用する際のポイントは2つあります。
1つは、「非営利」に限定されていないこと。
つまり営利目的(販売・有償提供目的)の学習済みモデル生成のためにもこの条文は適用されますので、著作物の「記録・翻案」が可能です(ちなみに諸外国の例では非営利目的のみ許容されているようです)。
もう1つは「記録・翻案」しか許されていないこと。
あくまで「情報解析」に向けての「記録・翻案」のみが許容され、それ以外の「譲渡」や「公衆送信」は許されていません。
▼ まとめ
このように「対象データ・対象DBが著作物」であり、かつ「『複製』『翻案』行為に該当する」場合でも「著作権法47条7の要件」を満たせば、著作権者の同意を得なくても適法に複製等ができることになります。
これが4つめのチェックポイントです。
【5 契約で禁止されていないか】
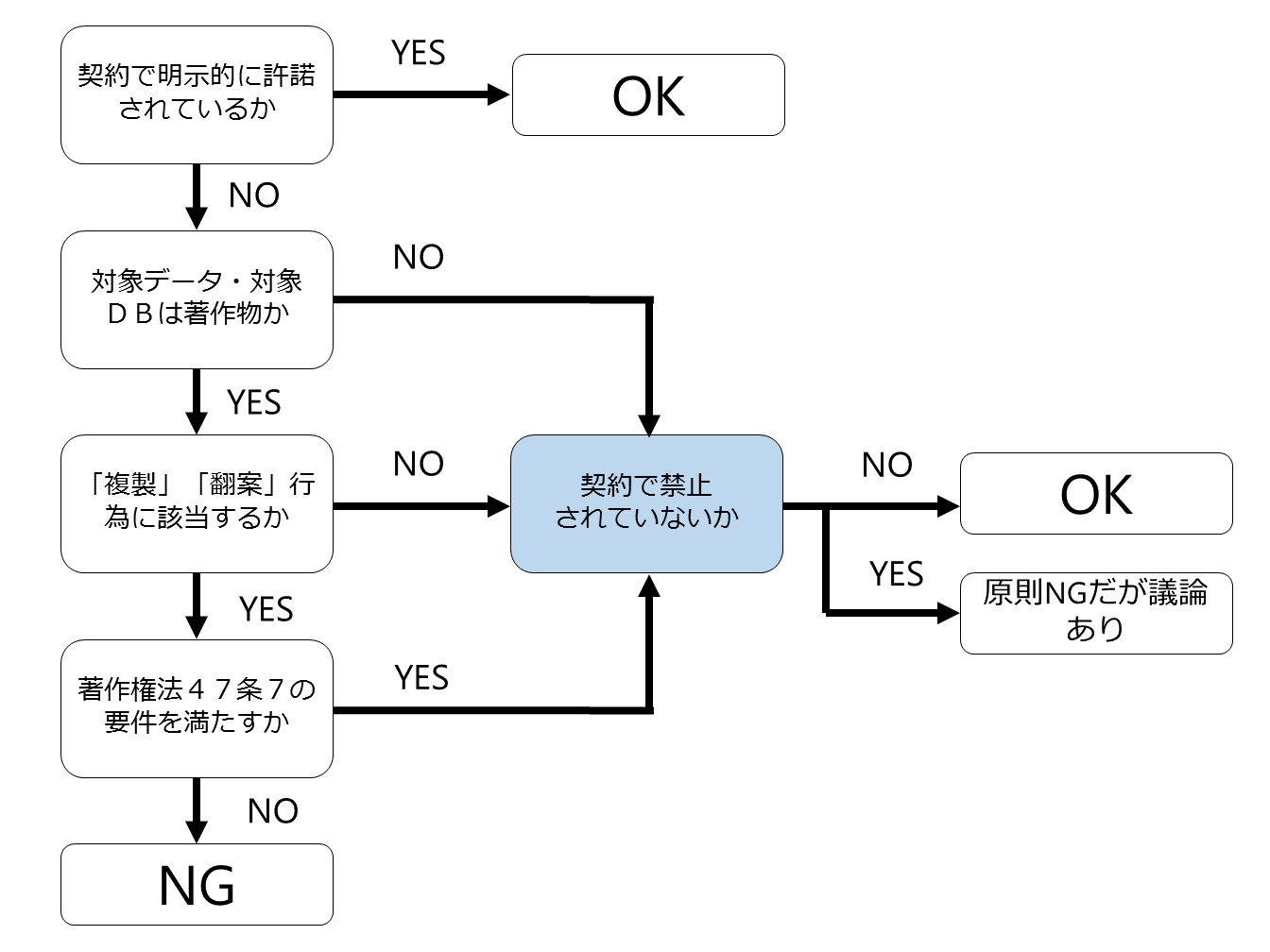
さて、最後のチェックポイントです。
実は、ここは実務的には非常に重要なポイントです。
つまり、
1 対象データ・対象DBが著作物でない場合
2 『複製』『翻案』行為に該当しない場合
3 著作権法47条7の要件を満たす場合
のいずれかに該当すれば、本来であれば、第三者の生データやデータベース、学習用データセットについて誰の承諾も必要なく適法に利用できるはずです。
しかし、生データやデータベース、学習用データセットについて以下のような定めがある場合はどうでしょうか。
「目的外利用を禁止します」
「一切の複製行為(著作権法で許容されている行為を含む)を禁止します」
「機械学習・深層学習用の学習済みモデル生成のために利用すること(著作権法47条の7に定める「記録・翻案」を含む)を禁じます」
▼ 契約による禁止の例
たとえば、このサイトでは、自動運転用AI生成のためのデータセットを公開しています。
【参考サイト】
The KITTI Vision Benchmark Suite
このサイトには「Copyright」という部分があり、CCライセンスに基づいて公開されていることが分かります(CCライセンスについてはこのサイトを参照。)

http://www.cvlibs.net/datasets/kitti/より
CCライセンスには色々な種類があるのですが、このサイトで設定されているライセンス条件はいわゆる「表示・非営利・継承」です。
つまり
・ 原作者のクレジット(氏名、作品タイトルなど)の表示が必要
・ 非営利目的に限定
・ また改変を行った際には元の作品と同じ組み合わせのCCライセンスで公開することを主な条件に、改変したり再配布したりすることができる
というライセンス条件です。
このサイトで公開されているデータセットを利用する場合にはこの条件に従って利用しなければなりませんから、仮にこのデータセットが「データベースの著作物」ではない場合でも、営利目的で学習済みモデルを生成する行為は契約違反ということになります(単にライセンス条件を表示するだけで同意クリックも要求されていない場合に契約が成立するか、という問題はあるのですが)。
▼ どのように考えるべきか
これは、一般化して言うと「著作権法上許容されている行為を、契約で禁止することができるか」という問題です(「契約による制限規定のオーバーライド問題」といいます)。
たとえば著作権法32条の「引用」の要件を満たしさえすれば、著作権法上は、著作権者の同意を得なくても複製はできるのですが、「著作権法に定める引用を禁止します」という条件を付されている著作物について引用ができるのか、という問題です。
この点については、そのような契約について「一律無効」「一律有効」ということではなく、実際には、権利制限規定の趣旨、ビジネス上の合理性、ユーザーに与える不利益の程度、及び不正競争又は不当な競争制限を防止する観点等を総合的にみて個別に判断するとされています。
深層学習を行う場合にどう考えるべきか、という点について確立した学説はないのですが、私は情報解析のための利用、つまり著作権法47条の7の要件を満たす利用行為であれば、たとえそれが契約で禁止されていたとしても当該契約は無効、つまり適法に利用できるのではないかと考えています(私見です。)
理由は以下のとおりです。
1 著作権法47条の7で著作権が制限されているのは「情報解析」に社会的意義があるためであること
2 著作権法47条の7で許容されているのは、あくまで情報解析のための、いわば内部的な記録・翻案行為のみであるから、その要件を満たしてさえいれば著作権者の権利を害することはほとんどないこと
また、実を言うと、契約の定めがあっても実際に契約違反行為を発見可能かというと、ほぼ不可能ではないかと思います(ただしモデルの種類によっては可能かもしれません)。
公開・提供された学習済みモデルを解析して、元になった生データやデータセットの痕跡を探すというのはおそらく不可能だからです。
ですので、仮に生データやデータセットについて契約で「一切複製不可」「学習済みモデル生成に利用することも不可」としたとしても、公開・提供された学習済みモデルを解析して当該契約違反だと言うことを立証するのは至難の業だと思います。
さらに、そもそも「契約が禁止されているか」についてもケースによって異なります。
たとえば、利用条件を承諾した上でデータベースシステムの会員になって利用を行っている場合には当然当該利用条件どおりの契約は締結されていますが、一方でWEB上に公開されている情報で、特に利用規約への同意をしなくても利用できるものについては「利用条件について契約を締結している」とはいえない場合も多いと思いでしょう。
最後に、当然のことですが、契約関係にない人(たとえば、契約に基づいてデータベースを利用している者から更に当該データベースの提供を受けた人)については契約の拘束を受けないので契約違反の問題は生じない、ということになるでしょう(一般不法行為の問題は生じるかもしれません)。
以上まとめると
・ 契約で禁止されている場合でも当該契約が有効か否かは議論の余地がある。
・ 契約で禁止されていても実際には発見は非常に困難
・ そもそも「契約で禁止」されていないケースもある
・ 契約当事者以外は契約で拘束できない
ということですね。
■ まとめ
今回のまとめは以下のとおりです。
これを押さえておくと、次回の「第三者のデータから学習用データセットや学習済みモデルを適法に生成・利用できるのはどのような場合か具体的に考えてみる」がとてもよく分かると思います。












