人工知能(AI)、ビッグデータ法務 スタートアップ
LLM技術と外部データ活用による検索・回答精度向上手法(ファインチューニング、セマンティック検索、In-Context Learning、RAG)と著作権侵害

Contents
- 1 第1 はじめに
- 2 第2 ファインチューニング
- 3 第3 セマンティック検索
- 3.1 1 セマンティック検索とは
- 3.2 2 パターン1(検索結果提供と共に、マッチングした検索対象文書の全部が表示されるパターン)
- 3.3 3 パターン2(検索結果提供と共に、マッチングした検索対象文書の一部が表示されるパターン)
- 3.3.1 (1) 「① 検索対象文書とそのベクトルをベクトルDB内に蓄積」について
- 3.3.2 (2) 「⑥ 検索結果提供及びそれに伴う検索対象文書の表示」
- 3.3.2.1 ア 47条の5第1項1号「一 電子計算機を用いて、検索により求める情報(以下この号において「検索情報」という)が記録された著作物の題号又は著作者名、送信可能化された検索情報に係る送信元識別符号(略)その他の検索情報の特定又は所在に関する情報を検索し、及びその結果を提供すること。」
- 3.3.2.2 イ 「(・・・当該行為を政令で定める基準に従って行う者に限る。)」該当性
- 3.3.2.3 ウ 「当該行為に付随して」
- 3.3.2.4 エ 「軽微利用」
- 3.3.2.5 オ 「当該各号に掲げる行為の目的上必要と認められる限度において」
- 3.3.2.6 カ ただし書(「ただし、当該公衆提供等著作物に係る公衆への提供等が著作権を侵害するものであること(国外で行われた公衆への提供等にあつては、国内で行われたとしたならば著作権の侵害となるべきものであること)を知りながら当該軽微利用を行う場合その他当該公衆提供等著作物の種類及び用途並びに当該軽微利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。」
- 3.3.3 (3) まとめ
- 3.4 5 パターン3(検索結果提供と共に、マッチングした検索対象文書が一切表示されないパターン)
- 4 第3 In-Context Learning
- 5 第4 RAG(拡張検索)
- 6 第5 30条の4と47条の5の関係について
- 7 第6 文化庁資料について
- 8 第6 著作権侵害にならないシステム設計とは
- 9 第8 複数主体が関与する場合
- 10 第9 まとめ
第1 はじめに
FAQシステムやチャットボットなど「何か知りたいこと(検索文・質問文)」を入力して検索や回答生成を行うに際して、検索や回答精度を向上させたり、回答根拠を明示させるために、LLM技術と外部データを組み合わせたシステムの研究開発や実装が急速に進んでいます。
LLMが外部データを参照できるようにするには、LLMそのものをFine-tuningする方法、プロンプトで情報を与える方法、RAGによって外部データを保存したデータベース (Data Base; 以下DB) から呼び出す方法の3つがあります。
ここでいう「外部データ」とは、「LLMの外部にあるデータ」という意味でして、その中には社内文書や、書籍・ウェブページ上のデータなどが含まれます。当該「外部データ」の中には、他人が著作権を持つ著作物(以下「既存著作物」といいます)も含まれるため、それら既存著作物を外部データとして利用する場合には、、著作権侵害にならないよう注意をする必要があります。
そこで、本稿では、LLM技術と外部データ活用による検索・回答精度向上のいくつかの手法(ファインチューニング、セマンティック検索、In-Context Learning、RAG)と著作権侵害について検討します。
本記事のテーマについて2023年12月26日に無料セミナーを開催いたします!
ご興味がある方は是非こちらからお申し込み下さい。
第2 ファインチューニング
1 ファインチューニングとは
出力精度向上のための方法として、まずLLMそのものを追加の訓練データで学習させるファインチューニングの方法があります。この方法は、モデル内の一部のパラメーターの物理的な更新を行うものです。
下の図は文化審議会著作権分科会法制度小委員会(第1回)で公開された資料3「AIと著作権に関する論点整理について」内の図に筆者が加筆したものです(赤枠部分を筆者加筆)。
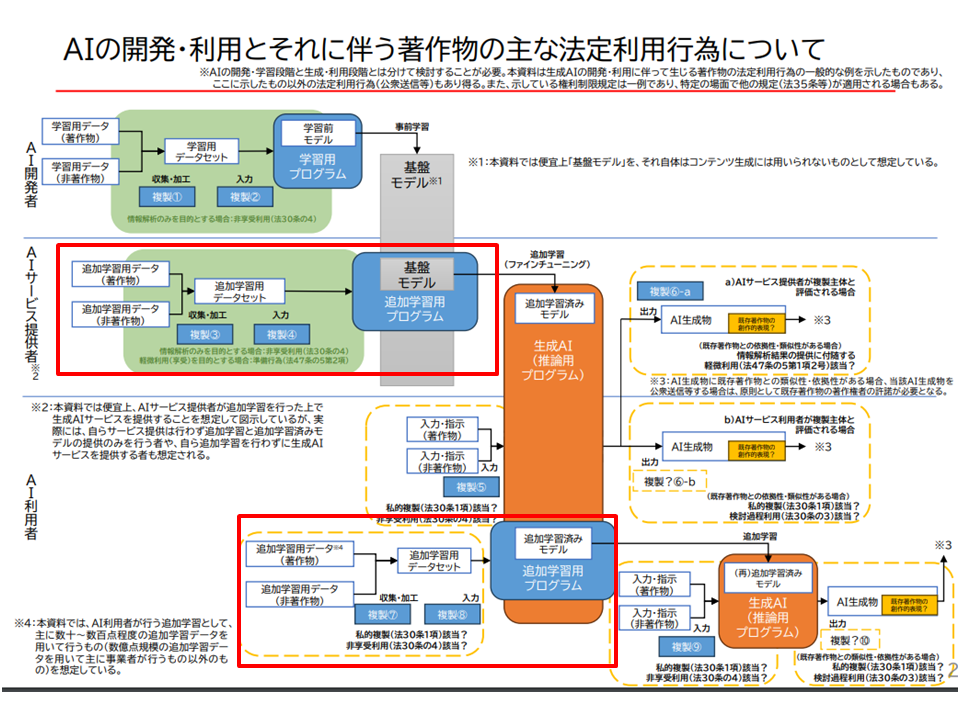
赤枠で囲んだのがファインチューニング部分です。
この図にあるように、ファインチューニングは、AIサービス提供者が行う場合もありますし、AI利用者が行う場合もありますが、著作権法との関係で言うと、当該ファインチューニングに既存著作物を利用することが著作権侵害に該当しないかが問題となります。
なお、ファインチューニングとは、いわゆる学習と呼ばれる行為ですが、本稿ではこの「学習」という言葉を、「モデル内の一部のパラメーターの物理的な更新を伴う行為」を指す言葉として使います。後述するIn-Context Learning(ICL)では、モデル内のパラーメーターの物理的な更新行為は行われませんので、この意味での「学習」とは区別する必要があります(ただし、法的には同じ扱いで良いと考えています。詳細は後述)。
2 ファインチューニングと著作権法
ファインチューニングのような「学習」行為は、いつもの図(「学習」と「生成・利用」を分けた全体図)で説明すると以下の図のような行為です。
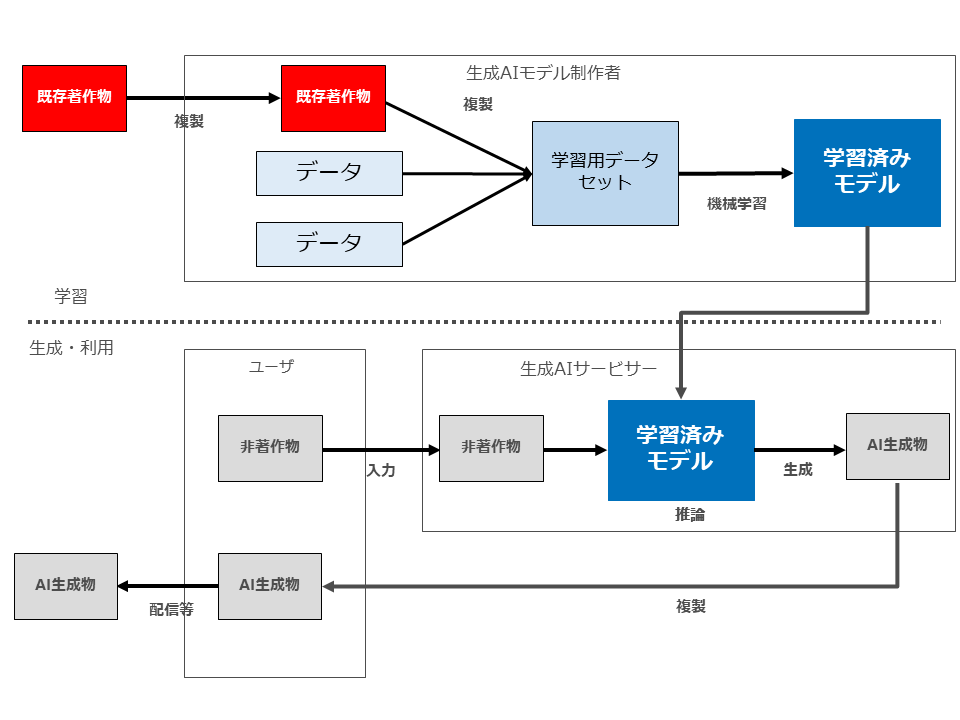
そして、よく知られているように、当該「学習」行為は、著作権法30条の4第2号に定める「情報解析」に該当します。そして、「学習」のために既存著作物を複製・加工することは、当該「学習(=情報解析)」に必要な行為であることから、原則として著作権者の承諾なく行うことができます。
(著作物に表現された思想又は感情の享受を目的としない利用)
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
もっとも、30条の4には例外が2つあります。
1つは、当該著作物の利用行為に「情報解析」目的以外に「享受目的」が併存している場合です。著作権法30条の4は、著作物の非享受目的利用について例外的に許容する規定ですから、当該利用行為に享受目的が併存している場合は適用されません。
そして、生成AIの場合、その学習・利用行為における「享受目的」とは「情報解析の対象となる既存著作物の『表現上の本質的特徴』を感じ取れるような生成物の生成を目的として行うこと」を言います1文化庁著作権課資料「AIと著作権の関係等について」の「*1 例えば・・・・」の部分参照 。
LLMのファインチューニングにおいて、そのような「享受目的」があることは通常想定されませんので、この例外には該当しません。
もう1つは同条柱書但書である「当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合」に該当する場合です。
但書に該当するか否かは、同様の但書を置いている他の権利制限規定(法35条第1項等)と同様に、著作権者の著作物の利用市場と衝突するか、あるいは将来における著作物の潜在的市場を阻害するかという観点から判断されます。
一般論としては「ある非享受目的の利用を本来的な利用目的として創作された著作物について、当該目的で利用する行為」について、本但書に該当することが多いとされていますが、実際には非常にレアなケースではないかと思われます。
現時点で「ある非享受目的の利用を本来的な利用目的として創作された著作物について、当該目的で利用する行為」に該当するとされている行為は、改正前47条の7ただし書に該当する行為、具体的には「情報解析の用に供するために作成されたデータベースの著作物」の利用行為だけです。
ファインチューニングにおける既存著作物の利用行為は当該行為に該当しませんので、同条柱書但書にも該当しません。
3 まとめ
以上の通りですので、LLMのファインチューニングのための既存著作物の利用行為が著作権侵害に該当するリスクはほぼないと言えます。
第3 セマンティック検索
1 セマンティック検索とは
次に、LLM技術を用いた検索精度向上手法としてセマンティック検索という手法があります。
この手法は質問文(検索クエリ)と、検索対象文書それぞれをLLM技術を用いてベクトル化することで、それぞれの意味内容の把握や高精度なマッチングを実現するものです。技術的に詳細な内容はこちらの記事が分かりやすいです。
このセマンティック検索は、後述するRAG(拡張検索)の前半部分である「検索」部分に該当します。
セマンテック検索は、通常以下のフローで行われます。検索対象文書をベクトル化(エンベディング)する部分にLLMが利用されます。
① 検索対象文書とそのベクトルをベクトルデータベース(ベクトルDB)内に蓄積
② ユーザーによる質問文の入力
③ 質問文のベクトル化
④ 質問文ベクトルと検索対象文書をマッチング
⑤ 質問文ベクトルと関連性が高い検索対象文書を抽出
⑥ 検索結果提供及びそれに伴う検索対象文書の表示
図で表示すると以下のとおりです(なお、この図では分かり易くするために⑤⑥の段階で抽出・表示される検索対象文書を1つしか図示していませんが、実際には⑤の段階で複数の検索対象文書が関連性が高い順に抽出され、⑥においてその順番で検索結果が表示されます。GoogleのWeb検索結果画面をイメージしていただければと思います。)
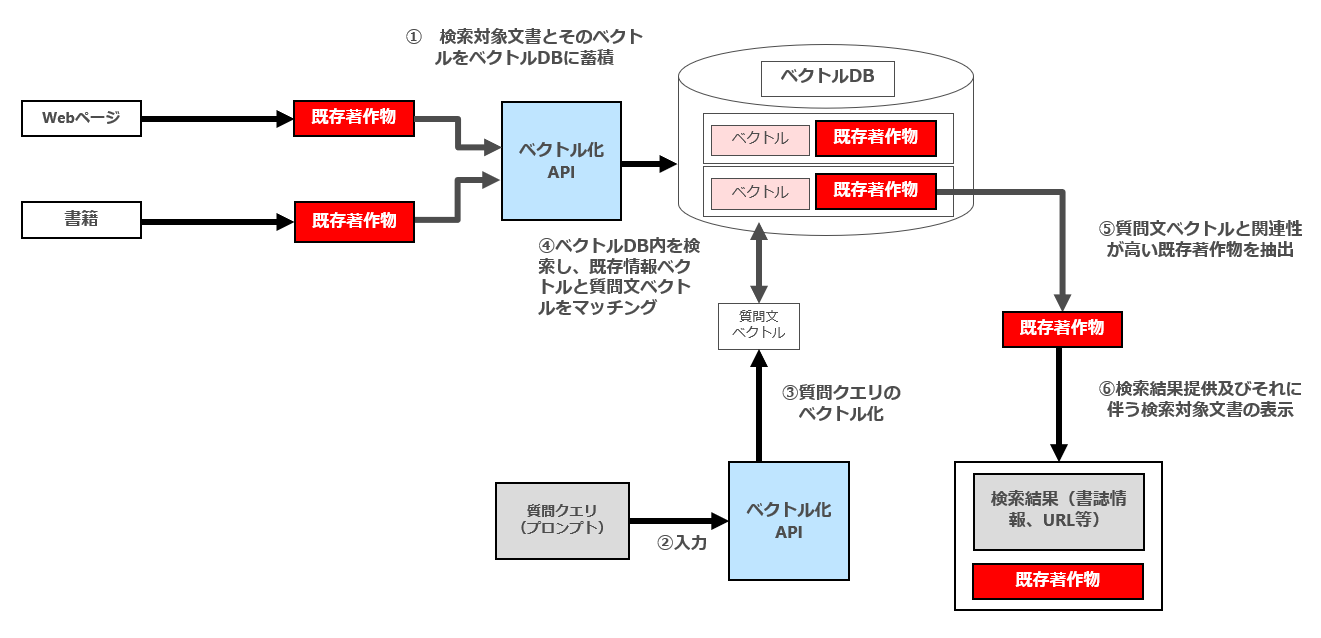
そして、検索対象文書として既存著作物が利用される場合、著作権侵害の有無が問題となりますが、具体的に問題となるのは「① 検索対象文書とそのベクトルをベクトルDB内に蓄積」と「⑥ 検索結果提供及びそれに伴う検索対象文書の表示」です。
ここでは、最後の「⑥ 検索結果提供及びそれに伴う検索対象文書の表示」における検索対象文書の利用方法(表示方法)に応じて、以下の3つのパターンを検討します。
【パターン1】検索結果提供(ヒットした書籍の書誌情報やURLの提供)と共に、マッチングした検索対象文書の全部が表示される
【パターン2】検索結果提供と共に、マッチングした検索対象文書の一部が表示される
【パターン3】検索結果提供だけが行われ、マッチングした検索対象文書は一切表示されない
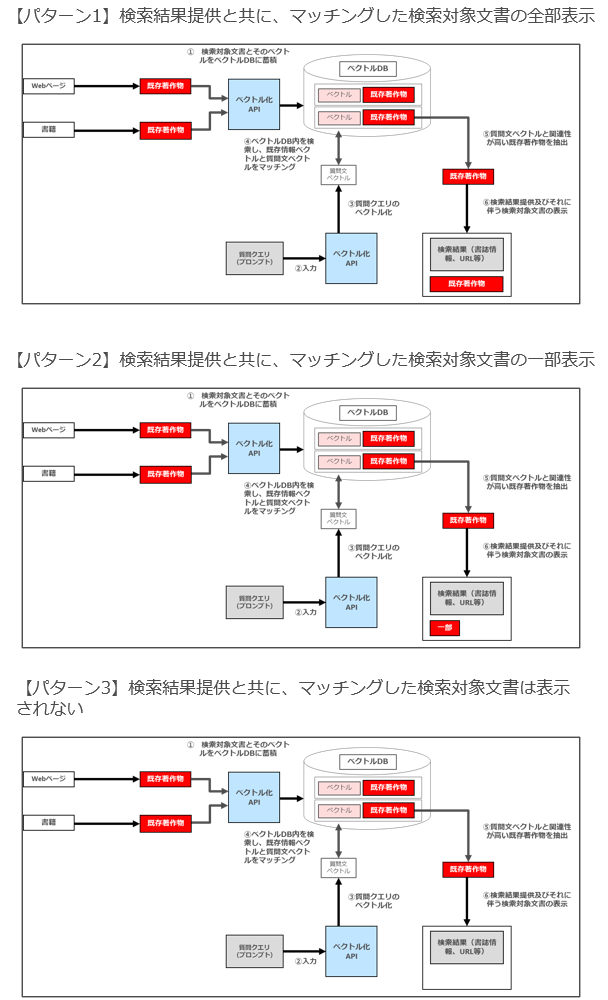
2 パターン1(検索結果提供と共に、マッチングした検索対象文書の全部が表示されるパターン)
(1)「① 検索対象文書とそのベクトルをベクトルDB内に蓄積」について
検索や情報解析に必要な著作物利用行為について適用可能な権利制限規定は、30条の4と47条の5第1項・同2項です(両者の異同については後述)。
具体的には、検索や情報解析の一連のプロセスの中に、「情報解析」(30条の4第2号)「著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用に供する場合」(同第3号)「電子計算機を用いた検索」(47条の5第1項第1号)「電子計算機を用いた情報解析」(同2号)(以下まとめて「情報解析等」といいます)のいずれかが存在し、当該情報解析等に必要な著作物利用行為、あるいは当該情報解析等の結果提供のために必要な著作物利用行為であれば、30条の4や47条の5が適用される可能性があるということになります。
そのため、セマンテック検索においても、そのプロセスのどこに「情報解析等」に該当する行為が存在するかをまず検討する必要があります。
ア 著作権法30条の4第2号・同第3号の適用可能性
セマンテック検索において、質問文・検索文をベクトル化する行為や、ベクトル化された検索対象文書とマッチングする行為は、30条の4第2号「情報解析」あるいは同3号「著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用に供する場合」に該当すると思われます。
それを前提とすると、当該情報解析等に必要な行為として「① 検索対象文書の蓄積・インデックス化」は30条の4により適法になるのではないかと考える方がいるかもしれません。
しかし、パターン1の場合、最終的な「⑥ 検索結果提供及びそれに伴う検索対象文書の表示」に伴って、検索対象文書(既存著作物)の全部が表示されていますので、「① 検索対象文書の蓄積・インデックス化」(情報解析等の対象著作物の利用行為)をする際に、情報解析等の対象となる既存著作物の「享受目的」が併存することになります。
したがって、パターン1の①の行為には著作権法30条の4は適用されません。
イ 著作権法47条の5第1項・同第2項の適用可能性
一方、30条の4と同様、情報解析等について定めた別の条文として47条の5があります。
この47条の5は「検索及び検索結果の提供(1号)」や、「情報解析及び情報解析結果の提供(2号)」のために必要な著作物利用行為であれば、享受目的が併存している場合であっても一定の要件を満たせば既存著作物を利用することができると定める条文です。
もう少し細かく言うと、47条の5第1項が「検索及び検索結果の提供に伴う既存著作物の利用(例:検索結果の表示に伴って検索対象文書を表示する)」に関する条文で、同2項が「1項の準備のための既存著作物の利用行為(例:検索対象文書の蓄積・インデックス化)に関する条文です。
(電子計算機による情報処理及びその結果の提供に付随する軽微利用等)
第四十七条の五 電子計算機を用いた情報処理により新たな知見又は情報を創出することによつて著作物の利用の促進に資する次の各号に掲げる行為を行う者(当該行為の一部を行う者を含み、当該行為を政令で定める基準に従つて行う者に限る。)は、公衆への提供等(公衆への提供又は提示をいい、送信可能化を含む。以下同じ。)が行われた著作物(以下この条及び次条第二項第二号において「公衆提供等著作物」という。)(公表された著作物又は送信可能化された著作物に限る。)について、当該各号に掲げる行為の目的上必要と認められる限度において、当該行為に付随して、いずれの方法によるかを問わず、利用(当該公衆提供等著作物のうちその利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なものに限る。以下この条において「軽微利用」という。)を行うことができる。ただし、当該公衆提供等著作物に係る公衆への提供等が著作権を侵害するものであること(国外で行われた公衆への提供等にあつては、国内で行われたとしたならば著作権の侵害となるべきものであること)を知りながら当該軽微利用を行う場合その他当該公衆提供等著作物の種類及び用途並びに当該軽微利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 電子計算機を用いて、検索により求める情報(以下この号において「検索情報」という。)が記録された著作物の題号又は著作者名、送信可能化された検索情報に係る送信元識別符号(自動公衆送信の送信元を識別するための文字、番号、記号その他の符号をいう。第百十三条第二項及び第四項において同じ。)その他の検索情報の特定又は所在に関する情報を検索し、及びその結果を提供すること。
二 電子計算機による情報解析を行い、及びその結果を提供すること。
三 前二号に掲げるもののほか、電子計算機による情報処理により、新たな知見又は情報を創出し、及びその結果を提供する行為であつて、国民生活の利便性の向上に寄与するものとして政令で定めるもの
2 前項各号に掲げる行為の準備を行う者(当該行為の準備のための情報の収集、整理及び提供を政令で定める基準に従つて行う者に限る。)は、公衆提供等著作物について、同項の規定による軽微利用の準備のために必要と認められる限度において、複製若しくは公衆送信(自動公衆送信の場合にあつては、送信可能化を含む。以下この項及び次条第二項第二号において同じ。)を行い、又はその複製物による頒布を行うことができる。ただし、当該公衆提供等著作物の種類及び用途並びに当該複製又は頒布の部数及び当該複製、公衆送信又は頒布の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
とすると、パターン1の場合、情報解析等として「電子計算機を用いた検索」(47条の5第1項第1号)が行われていることから、47条の5第2項を適用することで「① 検索対象文書とそのベクトルをベクトルDB内に蓄積」が適法化されるのではないかとも考えられますが、やはりダメです。
47条の5第2項で許容されている著作物の利用行為は、「47条の5第1項該当行為の準備行為」だけで、「47条の5第1項該当行為」とは「既存著作物の軽微利用」に限定されているからです。
パターン1の場合、最終的な「⑥ 検索結果提供及びそれに伴う検索対象文書の表示」に伴って、検索対象文書(既存著作物)の全部が表示されており、当該利用は「軽微利用」には該当しません。
とすると、⑥の行為について47条の5第1項が適用されませんから、そもそも⑥の行為が著作権侵害に該当し、その前提となる①の行為についても同条2項は適用されず著作権侵害ということになります。
(2) まとめ
結局のところ、パターン1は「① 検索対象文書とそのベクトルをベクトルDB内に蓄積」と「⑥ 検索結果提供及びそれに伴う検索対象文書の表示」いずれについても30条の4も47条の5も適用されず著作権侵害に該当します。
3 パターン2(検索結果提供と共に、マッチングした検索対象文書の一部が表示されるパターン)
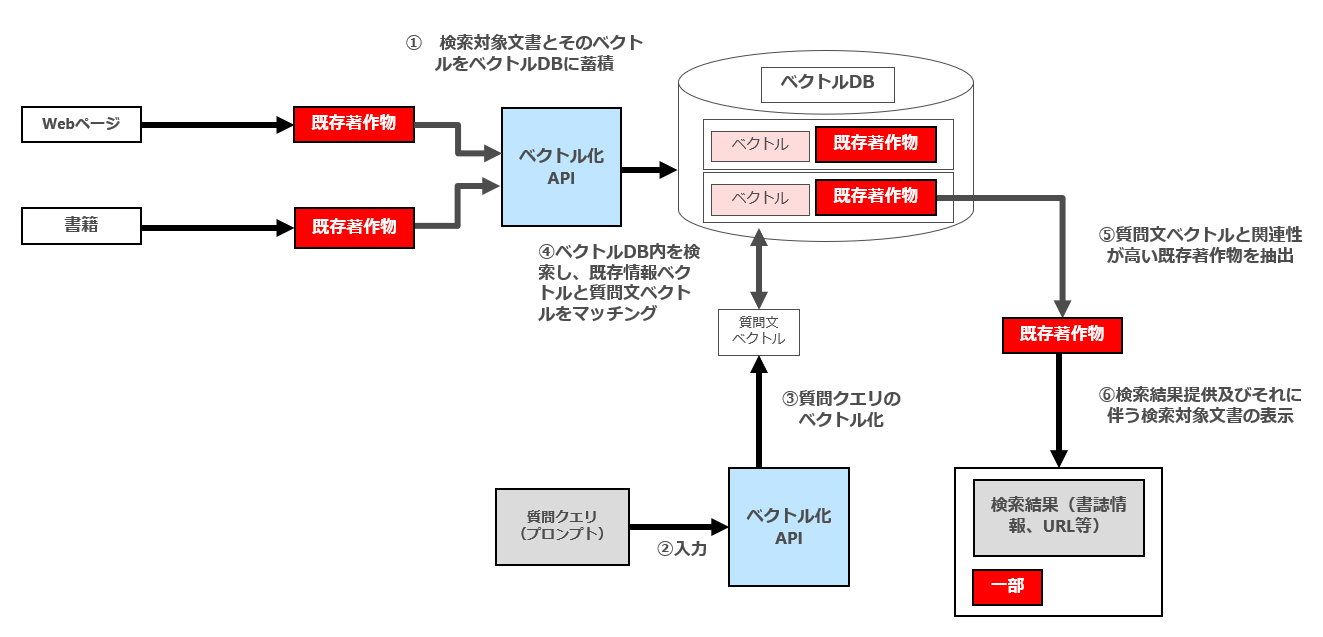
次にパターン2について検討します。
(1) 「① 検索対象文書とそのベクトルをベクトルDB内に蓄積」について
パターン2の場合でも、最終的な「⑥ 検索結果提供及びそれに伴う検索対象文書の表示」において検索対象文書の一部を表示しますので、「① 検索対象文書の蓄積・インデックス化」の際に、情報解析等の対象となる既存著作物の「享受目的」が併存することになります。
したがって、パターン1同様、パターン2にも著作権法30条の4は適用されません。
一方、パターン2の場合、情報解析等として「電子計算機を用いた検索」(47条の5第1項第1号)が行われていることから、「⑥ 検索結果提供に伴う検索対象文書の一部表示」が「軽微利用」に該当するなどして47条の5第1項の要件を満たして適法となれば、その準備行為である①の行為も、47条の5第2項に定める他の要件を満たせば、同項の適用により適法になる余地があります。
つまり、①の行為に47条の5第2項が適用されて適法になるためには、「⑥の行為が47条の5第1項の要件を満たすこと」と「①の行為が47条の5第2項に定める他の要件を満たすこと」の2つが必要となります。
「⑥の行為が47条の5第1項の要件を満たすこと」については後ほど検討しますので、ここでは「①の行為が47条の5第2項に定める他の要件を満たすこと」について検討します。
ア 「前項各号に掲げる行為の準備を行う者(当該行為の準備のための情報の収集、整理及び提供を政令で定める基準に従って行う者に限る。)」
この点については、著作権法施行令7条の4第2項2号に定める基準に従うこと、具体的には「二 法第四十七条の五第二項の規定の適用を受けて作成された著作物等の複製物に係る情報の漏えいの防止のために必要な措置を講じること。」が必要です。
「情報の漏洩の防止のために必要な措置」とは、大量の情報を扱うビジネスを行うに当たって社会通念上求められる外部からのアクセスを防ぐような措置を指し、一般的なデータベースよりも高度なアクセス防止措置を求めるものではありません。
したがって、セマンテック検索においても、①②で作成された複製物やベクトルDBについて通常のアクセス制限を行えば、この要件は満たします。
イ 同項の規定による軽微利用の準備のために必要と認められる限度において
47条の5第2項は、同条1項に規定する軽微利用の準備のために行われる行為を対象とするものですが、軽微利用の前提となる検索や情報解析などの情報処理を行うに当たって、その検索等を行う対象となる母集団となる情報を収集等する目的であれば当該要件を満たします。
そして、①の行為は当該目的を持った行為であるため本要件を満たします。
ウ ただし、当該公衆提供等著作物の種類及び用途並びに当該複製又は頒布の部数及び当該複製、公衆送信又は頒布の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りではない。
47条の5第2項は、ただし書を置いていますが、典型的なただし書該当行為は、他人が提供している検索用のデータベースの著作物を、47条の5第1項1号の行為に供する目的で複製する行為とされており2松田政行 編『著作権法コンメンタール別冊 平成30年・令和2年改正解説』(勁草書房、2022年)112頁、そのような行為を行っていなければ、ただし書に該当することはありません。
(2) 「⑥ 検索結果提供及びそれに伴う検索対象文書の表示」
「⑥ 検索結果提供及びそれに伴う検索対象文書の表示」における検索対象文書の利用行為は以下の要件を満たせば47条の5第1項により適法となります。
ア 47条の5第1項1号「一 電子計算機を用いて、検索により求める情報(以下この号において「検索情報」という)が記録された著作物の題号又は著作者名、送信可能化された検索情報に係る送信元識別符号(略)その他の検索情報の特定又は所在に関する情報を検索し、及びその結果を提供すること。」
セマンテック検索では、ユーザーが入力した検索内容(クエリ)について、電子計算機を用いて、検索情報(クエリに関連する情報)が記録された検索対象文書の書誌情報(「検索情報の特定又は所在に関する情報」。具体的には書籍の題号、著作者名等)を検索し、当該書誌情報(「結果」)を提供していますので、47条の5第1項1号の要件を満たしています。
イ 「(・・・当該行為を政令で定める基準に従って行う者に限る。)」該当性
47条の5第1項の適用を受けるためには、政令で定める基準を満たす必要があります。
政令で定める基準は「インターネット情報検索サービス(送信可能化された検索情報に係る送信元識別符号を検索し、及びその結果提供する行為)」か否かによって異なります。
セマンティック検索の場合、「インターネット情報検索サービス」に該当する場合としない場合(インターネットではなく書籍DBを検索するような場合)がありますが、ここでは、後者のケースを前提とします。
その場合、以下の3つの要件を満たす必要があります。
(ア) 47条の5第2項により作成された著作物等の複製物を使用する場合に、当該複製物に係る情報の漏えいの防止のために必要な措置を講じること(施行令7条の4第1項2号)
この点については先ほど説明したので省略します。
(イ) 要件の解釈を記載した書類の閲覧、学識経験者への相談等(施行令7条の4第1項3号及び施行規則4条の5第1号)
「要件の解釈を記載した書類」としては、47条の5に関する文化庁著作権の作成・公開している解説やコンメンタールが該当します。また「学識経験者」とは著作権法に精通している者を意味し、例えば、学者、弁護士や弁理士等を意味します。
(ウ) 問合せを受けるための連絡先等の情報の明示(施行令7条の4第1項3号及び施行規則4条の5第2号)
本要件については、サービス実施者のメールアドレスや電話番号等の連絡先をサービス利用規約等に表示すれば足ります。
ウ 「当該行為に付随して」
セマンティック検索において、検索対象となった既存著作物の一部を表示する行為(「著作物利用行為」)は、書誌情報(「結果」)を提供する行為(「結果提供行為」)に「付随して」の要件を満たす必要があります。
このような「付随して」の要件が要求されるのは、セマンティック検索のような所在検索サービスの主たる目的はあくまで結果提供行為にあり、著作物利用行為は、当該「結果」がユーザーの求める情報であるか否か容易に確認することができるようにするために限定的に許容されているに過ぎないためです。
「付随して」と言えるためには、① 書誌情報(「結果」)の提供行為(結果提供行為)と、当該提供に伴う検索対象となった既存著作物の一部を表示する行為(著作物利用行為)の区分可能性及び② 前者が「主」、後者が「従」の関係になければなりません。結果提供行為と著作物利用行為が一体化している場合については、区分可能性がなく、また著作物の利用が主たる目的であることも多いと考えられるため「付随して」の要件を満たさないことが多いと思われます。
セマンティック検索サービスの設計に際してはその点を満たすように留意が必要であり、たとえば書誌情報を省略して単に検索結果である書籍の一部分のみを表示することがないようにする必要があります。
エ 「軽微利用」
47条の5第1項は、著作物の利用行為について「いずれの方法によるかを問わず、利用(当該公衆提供等著作物のうちその利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なものに限ります。以下この条において「軽微利用」という)を行うことができる。」としています。
「軽微」であるかどうかは、外形的な要素を総合的に考慮して、著作物の本来的な市場に影響を与える可能性が類型的に低い程度の利用態様であるか否かによって判断されます。
オ 「当該各号に掲げる行為の目的上必要と認められる限度において」
47条の5第1項で権利制限の対象となっている著作物の利用行為は、あくまで同項1号から3号に定める行為の目的上必要と認められる範囲だけです。したがって、それ以外の目的での利用行為をすることはできません。たとえば、DB化した検索対象文書にユーザーが容易にアクセスできてその中を直接検索して検索対象文書の全部を閲覧できるような仕組みの場合、47条の5は適用されません3この点は、(セマンテック)検索だけでなく、ICLやRAGでも同様です。
カ ただし書(「ただし、当該公衆提供等著作物に係る公衆への提供等が著作権を侵害するものであること(国外で行われた公衆への提供等にあつては、国内で行われたとしたならば著作権の侵害となるべきものであること)を知りながら当該軽微利用を行う場合その他当該公衆提供等著作物の種類及び用途並びに当該軽微利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。」
法47条の5第1項ただし書では、著作権者の利益が不当に害されることとなる場合には、権利制限の適用を受けないことを定めています。
まず、違法アップロードされた著作物について、違法アップロードされた著作物であることを知りながら軽微利用を行う場合は但書に該当します。30条の4においては違法アップロードされた著作物の利用も権利制限の対象となっていることとは対照的です。
また、それ以外にも、但書該当行為については、著作権者の著作物の利用市場と衝突するかあるいは将来における著作物の潜在的販路を阻害するかという観点から、最終的には司法の場で具体的に判断されることになります。
(3) まとめ
パターン2については、⑥の行為については、47条の5第1項の要件(特に「付随性」「軽微性」に注意が必要)、①の行為については、同2項の要件(結構細かい)を満たせば適法ということになります。
5 パターン3(検索結果提供と共に、マッチングした検索対象文書が一切表示されないパターン)
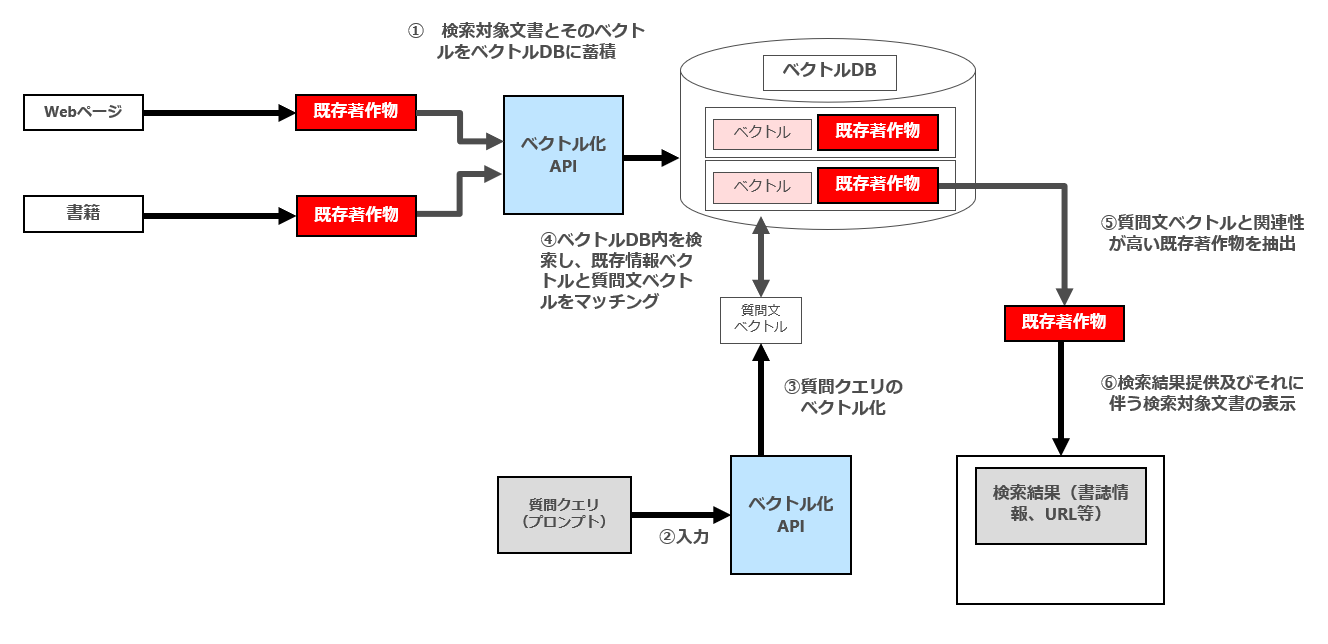
パターン3の場合、最終的な⑥の検索結果提供に伴って検索対象文書を全く表示しません。
そのため、「① 検索対象文書の蓄積・インデックス化」の際に、情報解析等の目的しかなく、情報解析の対象となる既存著作物の「享受目的」が存在しないことになります。
したがって、パターン3の場合「① 検索対象文書とそのベクトルをベクトルDB内に蓄積」には著作権法30条の4が適用され、原則として適法になると思われます4ただ、30条の4で権利制限の対象となっている著作物の利用行為は、あくまで同項1号から3号に定める行為に必要と認められる範囲だけです。したがって、それ以外の目的での利用行為をすることはできません。たとえば、DB化した検索対象文書にユーザーが容易にアクセスできてその中を直接検索して検索対象文書の全部を閲覧できるような仕組みの場合、30条の4は適用されません。この点は、(セマンテック)検索だけでなく、ICLやRAGでも同様です。
なお、パターン2の場合は、「① 検索対象文書の蓄積・インデックス化」について47条の5第2項が適用可能であり、同条の要件を満たせば適法であると説明をしました。
とすると、パターン3の場合も同じく47条の5第2項の適用可能性だけ検討すればいいのでは?と思われる方もおられるかもしれません。
しかし、「① 検索対象文書の蓄積・インデックス化」を47条の5第2項で適法化するためには、先ほど説明したように細かい要件を全て満たさなければならないのですが、30条の4の場合はそのような細かい要件を満たす必要はありません。
そのため、30条の4が適用可能なのであれば、そちらを適法化根拠とした方がよい、と言うことになります(もちろん47条の5第2項の適用を前提としたスキームを構築しても問題はありません。47条の5第2項の要件は、30条の4より厳しいので、前者を満たせば後者も満たすことがほとんどと思われるからです)。
ちなみに、同じ「情報解析」に関する条文で、30条の4と47条の5にこのような要件の差があるのは、30条の4の場合は対象著作物の非享受利用しかされていないのに対し、47条の5の場合は「情報解析」の結果提供に伴って対象著作物の享受利用(軽微利用)がされており、著作権者の権利に与える影響がより大きいからです。
■ 2023年12月4日追記
平成30年改正時の文化庁資料の問16(P14)には以下の記載があります。この回答の前半部分は、まさにパターン3のことを指しています。後半部分はパターン1または2のことです。
問 16 書籍や資料などの全文をキーワード検索して,キーワードが用いられている書籍や資料のタイトルや著者名・作成者名などの検索結果を表示するために書籍や資料などを複製する行為は,権利制限の対象となるか。
【回答】
書籍や資料などの文章中にキーワードが存在するか否かを検索する行為は,当該著作物の視聴等を通じて,視聴者等の知的・精神的欲求を満たすという効用を得ることに向けられた行為ではないものと考えられることから,キーワード検索を行うために書籍や資料などを複製する行為は,著作物に表現された思想又は感情の享受を目的としない行為として,権利制限の対象となるものと考えられる。
一方で,キーワードが用いられている書籍や資料のタイトルや著者名・作成者名などの検索結果とともに,キーワードを含む本文の一部分(著作物)を併せて提供する場合に,当該提供される本文の一部分(著作物)の提供は,当該著作物の視聴等を通じて,視聴者等の知的・精神的欲求を満たすという効用を得ることに向けられた行為であると考えられることから,そのような利用に供する目的で書籍や資料などを複製する行為は,著作物に表現された思想又は感情の享受を目的とする行為として,法第30条の4の権利制限の対象とはならないものと考えられる。このような行為については,軽微性等の要件を満たせば,第47条の5第1項の準備のための行為として,第47条の5第2項における権利制限の対象となるものと考えられる。
第3 In-Context Learning
1 In-Context Learningとは
LLMにおけるIn-Context Learning(ICL)とは、LLMへ入力するプロンプトとして、① 指示文(質問文)と共に、② 出力生成の際に参考にさせたいデータや、理想的な入出力例のデータを同時に追加入力することで、出力精度を上げる手法です。
そのような追加データを全く入力しない手法をZero-shot Learning、1つだけ与える手法をOne-shot Learning、いくつか与える手法をFew-shot Learningと言います。
たとえばLLMへの入力プロンプトとして「・・・について説明して下さい。その際には以下の資料を参考にして下さい。#資料1#資料2」のように、指示文と共に、正確な出力生成に必要な文書等のデータ(以下「同時入力文書」といいます)を同時に入力する方法です。
先ほど紹介したファインチューニングの場合、学習のためにかなりの量の学習用データが必要ですし、ファインチューニングしたからといって必ず精度向上が保証されるわけではありませんが、ICLの場合、いくつかの追加データを同時入力することで精度の高い出力を生成することができるというメリットがあると言われています。
先ほどのセマンテック検索が、後述するRAG(拡張検索)の前半部分である「検索」部分に該当したのに対し、このICLは後半部分の「生成」部分に該当します。
ICLは、通常、以下のフローで行われます。
① 同時入力文書の準備(複製等)
② 指示文(プロンプト)と①の同時入力文書をLLMに入力
③ LLM内で指示文(プロンプト)と同時入力文書を解析
④ 出力生成
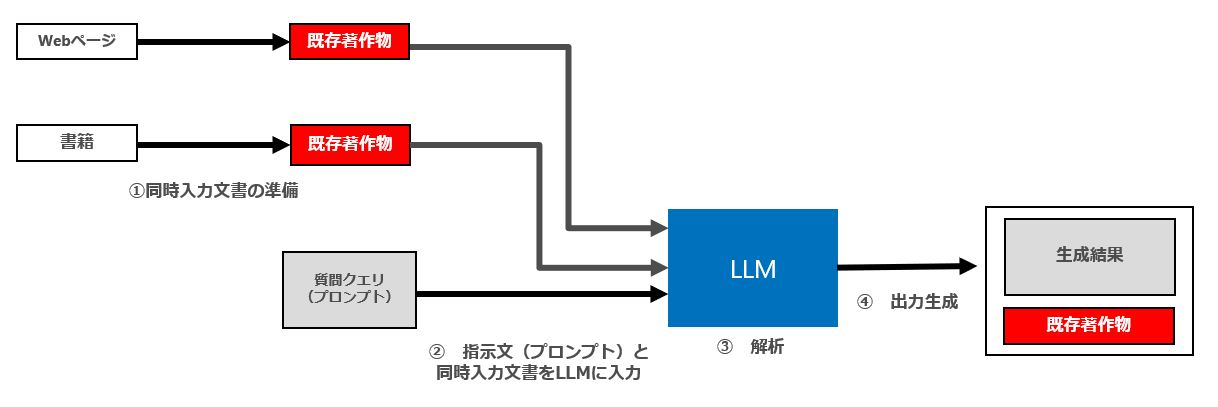
同時入力文書として既存著作物が利用される場合、著作権侵害の有無が問題となりますが、具体的に問題となるのは「① 同時入力文書の準備(複製等)」「② 指示文(プロンプト)と①の同時入力文書をLLMに入力」「④ 出力生成」です。
ここでもセマンティック検索と同じく、「④ 出力生成」の内容に応じて、以下の3つのパターンを検討します。
【パターン1】出力結果として新たに生成された出力と同時入力文書の全部が表示される
【パターン2】出力結果として新たに生成された出力と、同時入力文書の一部が表示される
【パターン3】出力結果として新たに生成された出力のみが表示され同時入力文書の内容が一切表示されない
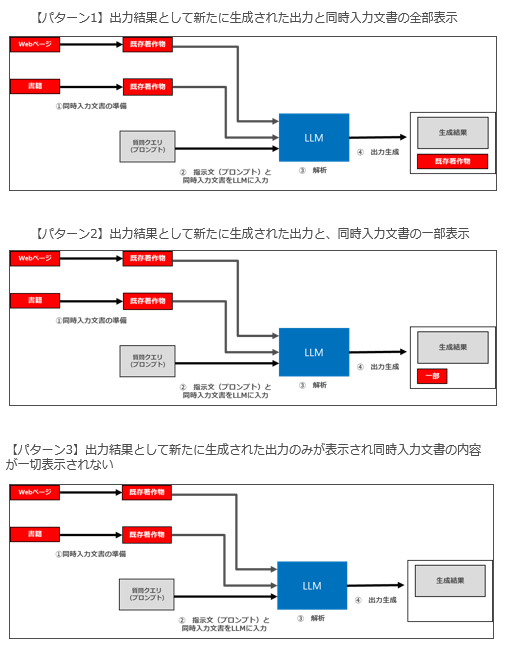
この3つのパターンをいつもの図で説明すると以下のようになります。
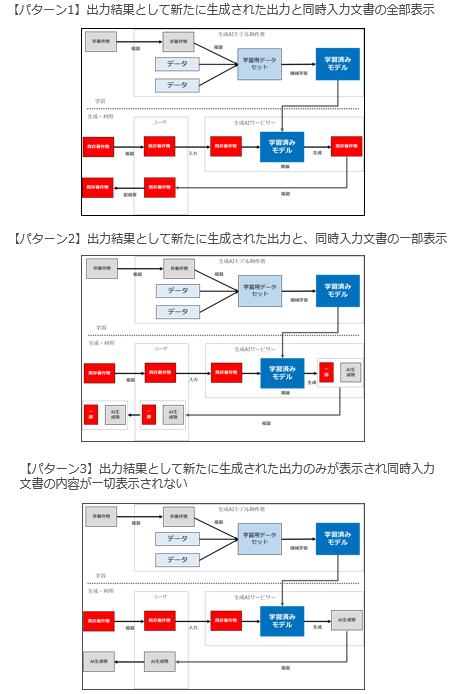
このICLは「学習段階」ではなく「生成・利用段階」で行われることに注意が必要です。
2 パターン1(出力結果として新たに生成された出力と同時入力文書の全部が表示されるパターン)
(1)「① 「同時入力文書の準備(複製等)」「② 指示文(プロンプト)と①の同時入力文書をLLMに入力」について
ア 「情報解析等」該当行為は何か
ここでも先ほどのセマンティック検索と同様、ICLのプロセスのどこかに情報解析等が存在し、当該情報解析等に必要な著作物の利用行為であれば、30条の4及び47条の5が適用される可能性がありますので、その点をまず検討します。
ICLにおいては、「入力された質問文及び同時入力文書を解析して出力を生成」する行為が行われていますので、この行為は「情報解析」(30条の4第2号)の定義に該当します。
もっとも、「入力された質問文及び同時入力文書を解析して出力を生成」する際には通常のAIモデルの「学習」と異なり、学習済みモデル内のパラメーターの物理的な更新は行われません5AIモデルの「学習(ファインチューニング、追加学習を含む)」においては、モデル内のパラメータの物理的な更新行為が行われることから、当該学習行為は問題なく「情報解析」(30条の4第2号)に該当するとされています(松田政行 編『著作権法コンメンタール別冊 平成30年・令和2年改正解説』(勁草書房、2022年)14頁)。
そのため、「入力された指示文及び同時入力文書を解析して出力を生成」する行為が「情報解析」に該当するかが問題となります。
この点については、私の知る限り30条の4立法当時には議論されていなかった点と思われますが、結論としては、当該行為は「情報解析」に該当すると考えています。
まず、著作権法30条の4における「情報解析」とは、「大量の情報の傾向や性質と言った何らかの特徴などを明らかにするために、当該情報から要素を抽出し、比較、分類するなどの方法により調べることを意味し、多種多様な情報処理を包含する広範な概念であるとされています6松田政行 編『著作権法コンメンタール別冊 平成30年・令和2年改正解説』(勁草書房、2022年)14頁。
また、ICLにおいては、モデル内のパラメータの物理的な更新行為は行われませんが、見方を変えると、あたかもパラメータを変えて学習した場合と同様に、指示や今生成しているデータにあわせて、パラメータを一時的に更新し、モデルを急速に適応させているとみなすことができるとされています7岡野原大輔「大規模言語モデルは新たな知能か」(岩波書店)114頁。
このように「情報解析」が広範な概念であるとされていること、技術的にはICLにおいてもパラメータの更新行為が行われていると同視できることからすると、ICLにおける「入力された指示文及び同時入力文書を解析(して出力を生成)」も「情報解析」(30条の4第2号)に該当すると考えます。
すなわち、ファインチューニングにおける学習済みモデル内のパラメーター更新行為も、ICLにおける入力された指示文及び同時入力文書を解析して出力を生成・出力する行為もいずれも30条の4第2号「情報解析」に該当し、法的な扱いは同一であるということになります。
イ 30条の4または47条の5第2項の要件該当性
上記を前提とすると、当該「情報解析」(30条の4第2号)に必要な行為として「① 同時入力文書の準備(複製等)」「② 指示文(プロンプト)と①の同時入力文書をLLMに入力」が30条の4により適法になるようにも思えます。
しかし、セマンティック検索におけるパターン1と同様、最終的な「④ 出力生成」に伴って、同時入力文書が全部表示されています(なお、ICLの場合、ファインチューニングと異なり、やろうと思えばな「④ 出力生成」に伴って同時入力文書を全部表示することが容易です(プロンプトで「参考にした同時入力文書の該当部分を全て表示してください」と指示すればよい)。
したがって、パターン1の場合、ICLにおける「① 「同時入力文書の準備(複製等)」「② 指示文(プロンプト)と①の同時入力文書をLLMに入力」(情報解析等の対象著作物の利用行為)の際に、情報解析の目的に加えて、情報解析の対象となる既存著作物の「享受目的」が併存することになります。
したがって、パターン1の①②の行為には著作権法30条の4は適用されません。
では、47条の5はどうでしょうか。
パターン1の場合、最終的な④の出力生成に伴って、同時入力文書が全部表示されますので、④における同時入力文書の利用行為は「軽微利用」には該当しません。
その結果、セマンティック検索と同様、④の行為について47条の5第1項が適用されませんから、その前提となる①②の行為についても同条2項は適用されないということになります。
ウ まとめ
結局のところ、パターン1は「① 同時入力文書の準備(複製等)」「② 指示文(プロンプト)と①の同時入力文書をLLMに入力」「④ 出力生成」いずれについても30条の4も47条の5も適用されず違法と言うことになります。
先ほど、ファインチューニングにおける学習行為もICLにおける「入力された指示文及び同時入力文書を解析(して出力を生成)」も「情報解析」(30条の4第2号)に該当する、とお伝えしましたが、当該「情報解析」のための著作物の利用行為の際に享受目的が併存しているかどうかによって結論が分かれることになります。
ファインチューニングによる学習行為の際には、通常享受目的が併存することはありませんが、ICLの場合、やろうと思えば容易に同時入力文書を表示することが可能であり、その場合には享受目的が存在することになります。
4 パターン2(出力結果として新たに生成された出力と、同時入力文書の一部が表示される)
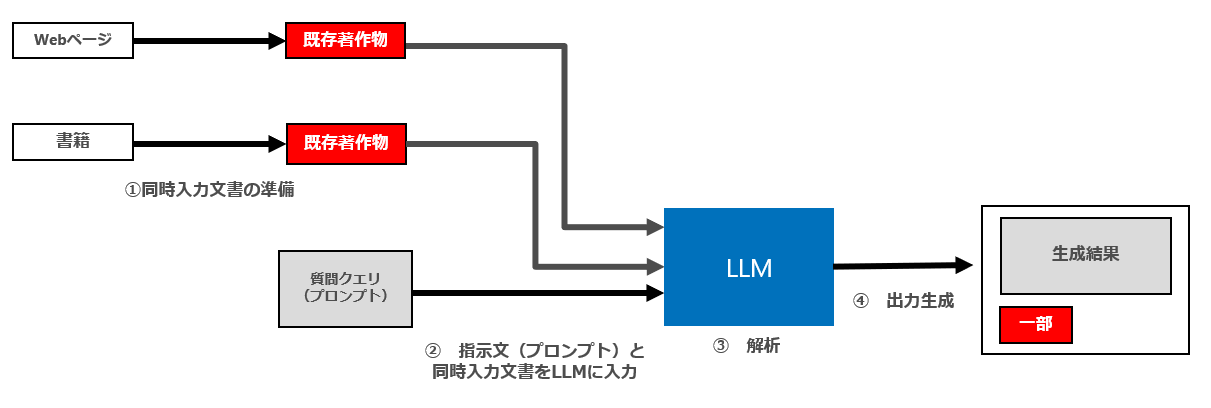
次にパターン2について検討します。ここでも、パターン1と同様、セマンティック検索において説明したことがほぼそのまま当てはまります。
(1) ① 「同時入力文書の準備(複製等)」「② 指示文(プロンプト)と①の同時入力文書をLLMに入力」について
パターン2の場合でも、最終的な「④ 出力生成」に伴って同時入力文書の一部を表示しますので、情報解析の際に、情報解析の対象となる既存著作物の「享受目的」が併存することになります。
したがって、パターン2にも著作権法30条の4は適用されません。
一方、パターン2の場合、「④ 出力生成」に伴う同時入力文書の一部表示が「軽微利用」(47条の5第1項)に該当すれば、同利用行為は適法となり、その準備行為である①②の行為も47条の5第2項の適用により適法になる余地があります。
その場合、先ほど説明したようないくつかの要件を満たせば、①②について47条の5第2項が適用され著作権侵害にならないことになります。
(2) 「④ 出力表示」
「④ 出力表示」に伴う同時入力文書の表示は、当該表示行為が「軽微利用」等の47条の5第1項の要件を満たせば適法となります。
先ほど47条の5第1項の要件として「付随性」が必要であると説明しました。
この「付随性」とは、① 出力(「結果」)の提供行為(結果提供行為)と、当該提供に伴う検索対象となった既存著作物の一部を表示する行為(著作物利用行為)の区分可能性及び② 前者が「主」、後者が「従」の関係になければなりません。
結果提供行為と著作物利用行為が一体化している場合については、区分可能性がなく、また著作物の利用が主たる目的であることも多いと考えられるため「付随して」の要件を満たさないことが多いと思われます。
ICLの設計に際してはその点を満たすように留意が必要であり、たとえば出力(生成)結果を表示せず、単に同時入力文書の一部分のみを表示することがない設計にするよう注意が必要です。
(3) まとめ
パターン2については、④の行為については、47条の5第1項の要件(特に「付随性」「軽微性」に注意が必要)、①②の行為については、同2項の要件を満たせば適法ということになります。
5 パターン3(出力結果として新たに生成された出力のみが表示され同時入力文書の内容が一切表示されない)
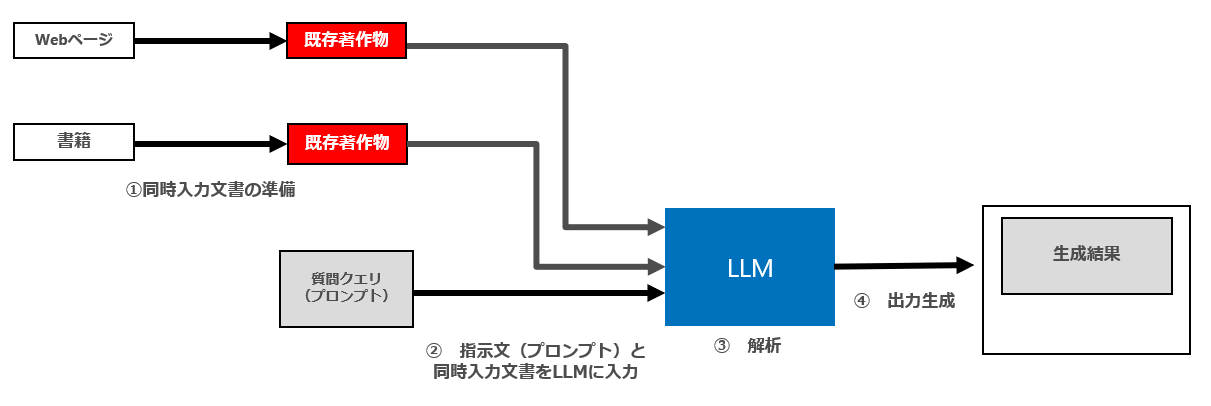
パターン3の場合、最終的な④の生成結果の提供に伴って同時入力文書を全く表示しません。
そのため、情報解析のための既存著作物の利用行為(「① 同時入力文書の準備(複製等)」「② 指示文(プロンプト)と①の同時入力文書をLLMに入力」)の際に、情報解析の対象となる既存著作物の「享受目的」が存在しないことになります。
したがって、パターン3の場合、セマンティック検索と同様①②には著作権法30条の4が適用され、原則として適法になると思われます。
第4 RAG(拡張検索)
1 RAG(Retrieval Augmented Generation、拡張検索)とは
RAG(Retrieval Augmented Generation、拡張検索)とは、あらかじめ社内文書や書籍、ウェブページなどの外部データをデータベース(DB)として準備しておき、ユーザからの質問がなされた場合には、当該質問と関連性が高い外部データを検索し、その外部データを質問文に付加してLLMに入力することで、精度が高い、かつ実際の外部データに紐付いた回答を生成することができるというものです。
具体的には以下のフローとなります。
① 同時入力文書とそのベクトルをベクトルDB内に蓄積
② ユーザーによる質問クエリ(プロンプト)の入力
③ 質問クエリ(プロンプト)のベクトル化
④ 質問文ベクトルと同時入力文書をマッチング
⑤ 質問文ベクトルと関連性が高い同時入力文書を抽出
⑥ 質問文(プロンプト)と⑤の同時入力文書をLLMに入力
⑦ LLM内で質問文(プロンプト)と同時入力文書を解析
⑧ 出力生成
⑨ 出力利用
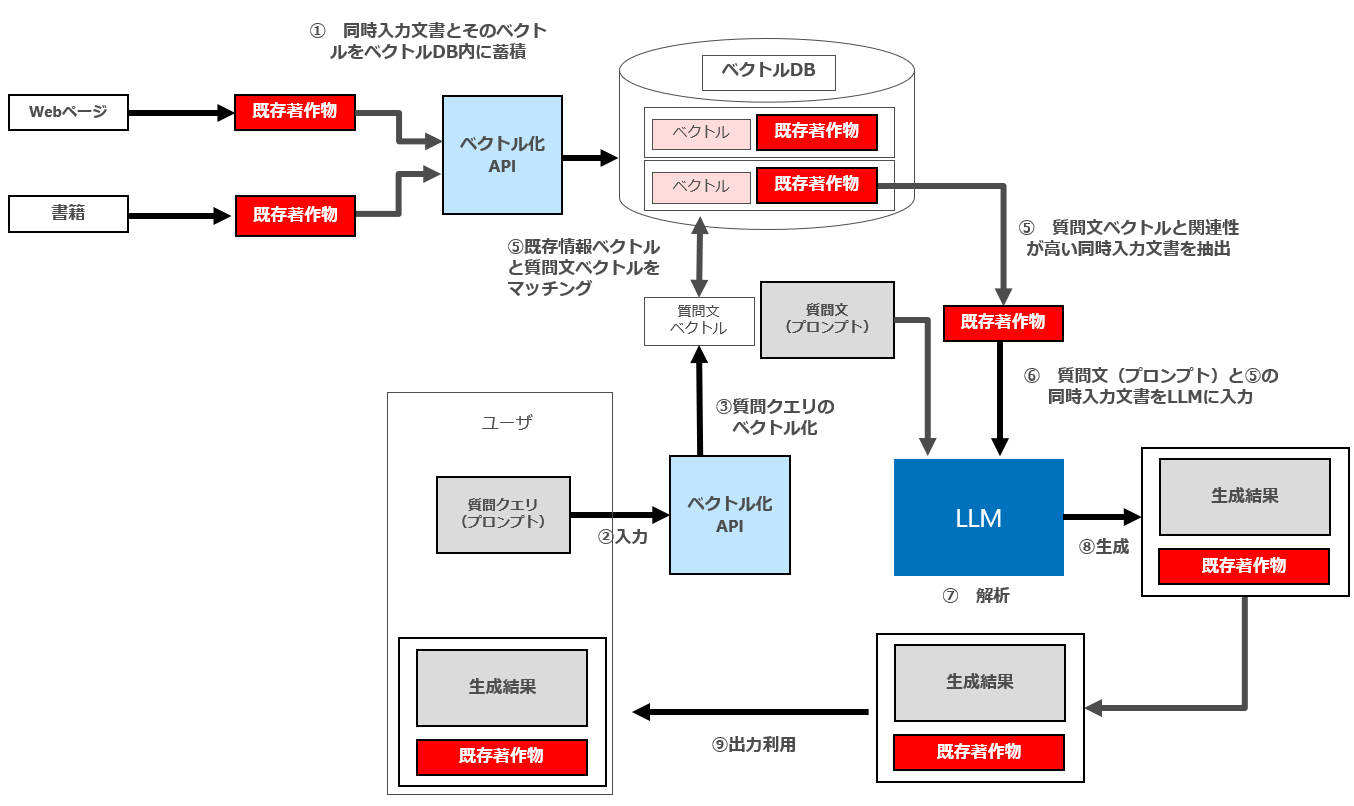
要するにRAG(Retrieval Augmented Generation、拡張検索)は、「検索」と「生成」を組み合わせた手法です。
そして著作権侵害との関係では、「検索」部分については、セマンテック検索について説明した内容が、「生成」部分についてはICLについて説明した内容が当てはまります。
そのためRAGについても、③出力結果の表示における既存著作物の利用方法(表示方法)に応じて、以下の3つのパターンを検討します。
【パターン1】出力結果として新たな生成結果及び同時入力文書の全部が表示される
【パターン2】出力結果として新たな生成結果及び同時入力文書の一部が表示される
【パターン3】出力結果として新たな生成結果のみが表示され同時入力文書の内容が一切表示されない
なお、RAGにおいては「学習」は一切行われていませんので、RAGのプロセスにおける既存著作物の利用行為は、すべて「生成・利用」フェーズにおける著作物の利用行為です。
2 パターン1(出力結果として新たな生成結果及び同時入力文書の全部が表示される)
(1) ① 同時入力文書とそのベクトルをベクトルDB内に蓄積
ア 情報解析等に該当する行為は何か
ここでも、これまでと同様、RAGのプロセスのどこかに情報解析等に該当する行為が存在し、当該情報解析等に必要な著作物の利用行為であれば、30条の4または47条の5が適用される可能性がありますので、その点をまず検討します。
RAGのプロセスにおいて情報解析等に該当する可能性があるのは③の「質問文・検索文をベクトル化」、④の「ベクトル化された検索対象文書とマッチング」及び⑦の「LLM内で質問文(プロンプト)と同時入力文書を解析」する行為です。
理屈としては、③④⑦いずれも情報解析等に該当すると思われますが、(ⅰ)RAGにおける検索部分である③④は途中のプロセスに過ぎず、RAGの最終目的は、「LLMによる分かり易い出力を生成すること」にあること、(ⅱ)プロセス途中での「⑥ 質問文(プロンプト)と⑥の同時入力文書をLLMに入力」は全く人の知覚を伴っていないこと、(ⅲ)情報解析等の「後段階」の著作物の利用行為を適法化する根拠は47条の5しかないことからすると、適法にRAGを設計・利用するという見地からすると、なるべく情報解析等を遅い段階で把握した方が適法化される余地が大きいことからすると、RAGにおいては最終段階に近い「⑦ 入力された質問文及び同時入力文書を解析する行為」を情報解析等と考えるべきではないかと考えます。
イ 30条の4または47条の5第2項の要件該当性
上記を前提とすると、「⑦ 入力された質問文及び同時入力文書を解析する行為」(情報解析等)に必要な行為として「① 同時入力文書(書籍やウェブページ等)の蓄積」行為は30条の4により適法になるようにも思えます。
しかし、ここまで読んできた方はおわかりかと思いますが、セマンティック検索、ICLにおけるパターン1と同様、パターン1のRAGも最終的な「⑨ 出力利用」に伴って、同時入力文書が全部表示されています。
したがって、パターン1の場合「① 同時入力文書(書籍やウェブページ等)の蓄積」行為(情報解析等の対象著作物の利用行)をする際に、情報解析等の対象となる既存著作物の「享受目的」が併存することになります。
したがって、パターン1の①の行為には著作権法30条の4は適用されません。
また、パターン1のRAGの場合、最終的な「⑨ 出力利用」に伴って、同時入力文書が全部表示されますので、「⑨ 出力利用」における著作物の利用行為は「軽微利用」には該当しません。つまりパターン1のセマンティック検索やICLと同様、⑨の行為について47条の5第1項が適用されませんから、その前提となる①の行為についても同条2項は適用されないと言うことになります。
ウ まとめ
結局のところ、パターン1のRAGは、① 同時入力文書(書籍やウェブページ等)の蓄積、⑨ 出力利用いずれについても30条の4も47条の5も適用されず違法と言うことになります。
3 パターン2(出力結果として新たな生成結果及び同時入力文書の一部が表示される)
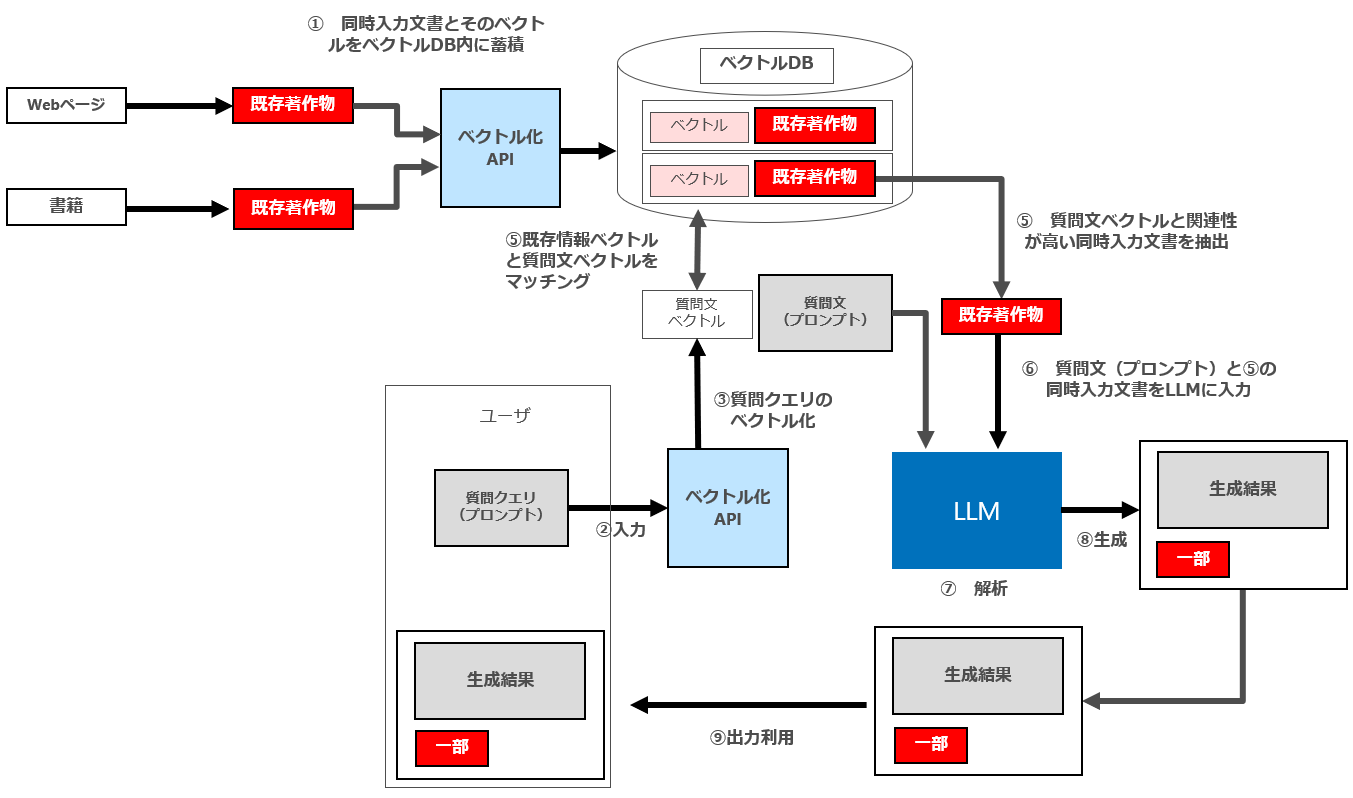
次にパターン2について検討します。ここでも、パターン1と同様、セマンティック検索・ICLにおいて説明したことがほぼそのまま当てはまります。
(1) ① 同時入力文書(書籍やウェブページ等)の蓄積
パターン2の場合でも、最終的な⑨の出力利用に伴って同時入力文書の一部を表示しますので、「① 同時入力文書(書籍やウェブページ等)の蓄積」行為(情報解析等の対象著作物の利用行)をする際に、情報解析等の対象となる既存著作物の「享受目的」が併存することになります。
したがって、パターン2にも著作権法30条の4は適用されません。
一方、パターン2の場合、⑨の出力利用に伴う同時入力文書の一部表示が「軽微利用」(47条の5第1項)に該当すれば、⑨における著作物の利用行為は適法となり、その準備行為である①の行為も47条の5第2項の適用により適法になる余地があります。
そして、先ほど説明したようないくつかの要件を満たせば、① 同時入力文書(書籍やウェブページ等)の蓄積についても、47条の5第2項が適用されます。
(2) 「⑨ 出力利用」
「⑨ 出力利用」に伴う同時入力文書の表示は、当該表示行為が「軽微利用」等の47条の5第1項の要件を満たせば適法となります。
なお、RAGの設計に際しても「⑨ 出力利用」についてICLと同様「付随性」を満たすように留意が必要であり、たとえば出力(生成)結果を表示せず、単に同時入力文書の一部分のみを表示することがないようにする必要があります。
(3) まとめ
パターン2については、⑨の行為については、47条の5第1項の要件(特に「付随性」「軽微性」に注意が必要)、①の行為については、同2項の要件を満たせば適法ということになります。
5 パターン3(出力結果として新たな生成結果のみが表示され同時入力文書の内容が一切表示されない)
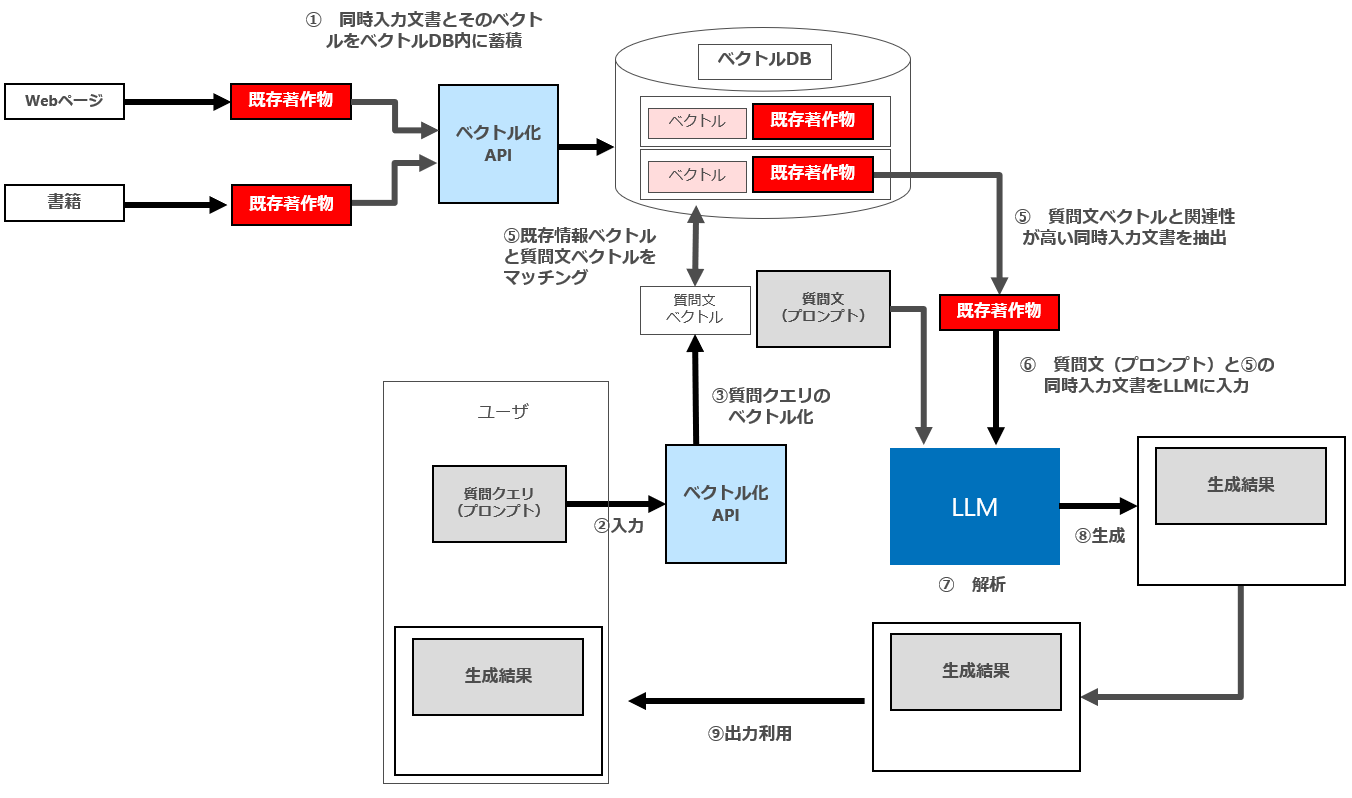
パターン3の場合、最終的な⑨の出力利用に伴って同時入力文書を全く表示しません。
そのため、「① 同時入力文書(書籍やウェブページ等)の蓄積」行為(情報解析等の対象著作物の利用行)をする際に、情報解析等の対象となる既存著作物の「享受目的」が存在しないことになります。
したがって、パターン3のRAGの場合、パターン3のセマンティック検索・ICLと同様「① 同時入力文書とそのベクトルをベクトルDB内に蓄積」には著作権法30条の4が適用され、原則として適法になると思われます。
第5 30条の4と47条の5の関係について
以上、精度向上の手法としてファインチューニング、セマンティック検索、In-Context Learning及びRAGと著作権侵害について説明してきました。繰り返しになりますが、ファインチューニングは学習段階における工夫、In-Context Learning及びRAGは生成・利用段階における工夫ということになります。
ここまでの説明で30条の4と47条の5について適宜言及をしてきましたが、両者の関係についてあらためて説明し、これら精度向上手法が著作権侵害に該当しないようにするための判断フローチャートを提案します。
1 30条の4と47条の5の共通点
いずれも権利制限規定の一種であり、「ある特定の目的」のためであれば著作権者の承諾無く著作物を利用することが原則として自由である、という規定です。
LLMのようなAI技術との関係で言うと、「ある特定の目的」とは、具体的には「情報解析」(30条の4第2号)「著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用に供する場合」(同第3号)、「電子計算機を用いた検索及び検索結果提供」(47条の5第1項第1号)「電子計算機を用いた情報解析及び解析結果提供」(同2号)を目的とすることです。
これらの目的のための著作物利用であれば、30条の4及び47条の5が適用され適法となる可能性があります。
2 どのように使い分けるのか
両者の使い分けの視点として、まず1つは「情報解析等」のために必要な著作物の利用行為(いわば「情報解析等の前段階」における著作物の利用行為)を適法化する規定なのか、「情報解析等の結果提供」のために必要な著作物の利用行為(いわば「情報解析等の後段階」における著作物の利用行為」)を適法化する規定なのか、があります8ここでいう「情報解析の前段階」や「情報解析の後段階」は厳密な意味ではありません。「情報解析等」と同時に行われる利用行為もあるからです。もっとも、「前」と「後」の方がイメージがしやすいと思いますので、この表現を使います。
30条の4は、あくまで「情報解析等」のために必要な著作物の利用行為にしか適用されず、「情報解析等の結果提供」のために必要な著作物の利用行為には適用されません。つまり、「情報解析」の「後段階」の著作物の利用行為(出力結果の表示など)には30条の4は適用されません。
一方、47条の5は、「情報解析等」のために必要な「前段階」の著作物の利用行為(同条2項)にも、「情報解析等の結果提供」のために必要な「後段階」の著作物の利用行為(同条1項)にも適用されます。
また、著作物の利用行為の際に「享受目的」(生成AIの場合で言うと、「情報解析等の対象となる既存著作物の『表現上の本質的特徴』を感じ取れるような生成物の生成を目的として行うこと」)がある場合に適用されるか否かも両者の重要な相違点です。
30条の4は、当該利用行為の際に「享受目的」が一部でも存在している場合は適用されませんが、47条の5は、当該利用行為の際に「享受目的」が併存していても、当該享受が「軽微利用」の範囲に収まるのであれば適用される可能性があります。
また、30条の4の方が権利制限規定としての適用要件が緩いので、実際の検討の順番としては、まず30条の4の適用を先に検討し、NGなら47条の5の適用を検討するという順番になります。
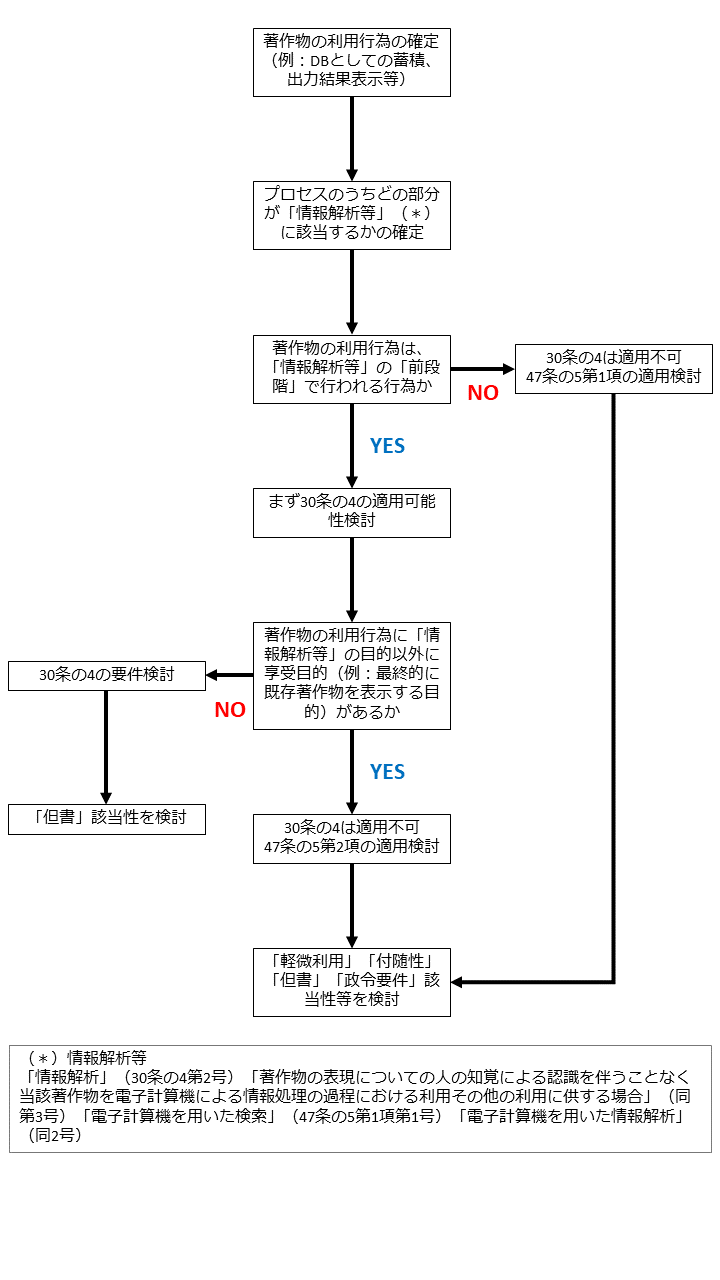
3 フローチャート
以上を前提に、LLM出力の精度向上手法(ファインチューニング、セマンティック検索、In-Context Learning及びRAGなど)の著作権侵害の有無を判断するためのフローチャートを作ってみました。
ご参考になさってください。
第6 文化庁資料について
以下の図は、文化庁文化審議会著作権分科会法制度小委員会(第4回)の資料1-2「法30条の4と法47条の5の適用例について」の2頁目です。
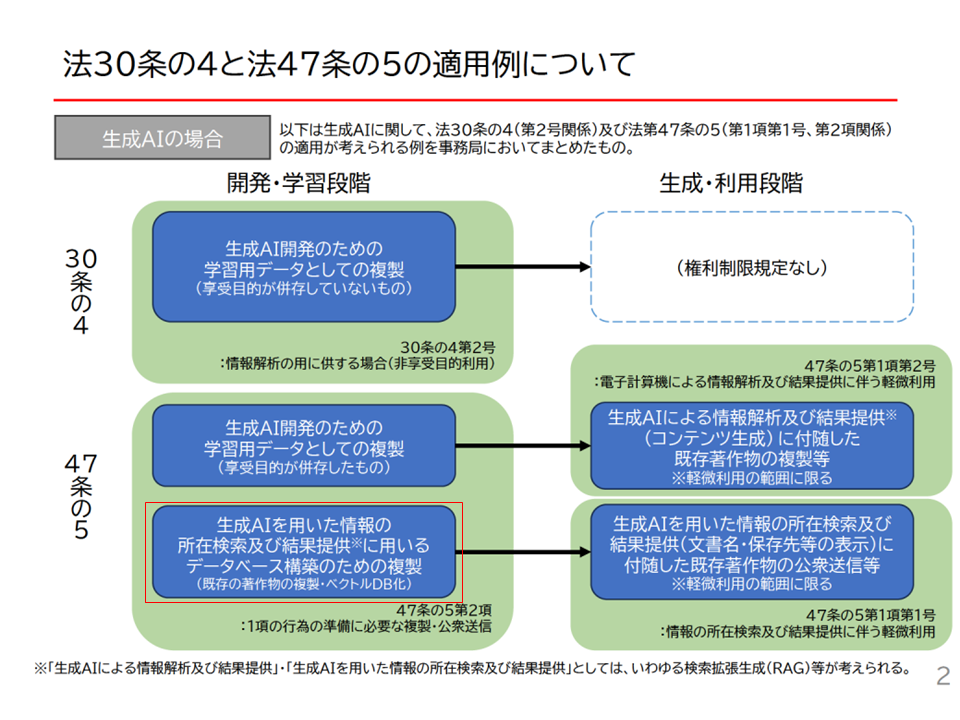
実はこの図に関しては、2点違和感があります。
1 RAGにおける著作物の利用行為は「開発・学習段階」ではなく全て「生成・利用段階」で行われているのではないか
1つは、この資料の一番下に「*「生成AIによる情報解析及び結果提供」・「生成AIを用いた情報の所在検索及び結果提供」としては、いわゆる検索拡張検索(RAG)等が考えられる」と記載されている点です。
本記事で説明をしたとおり、RAGにおいては生成AIの「開発・学習段階」では著作物の利用行為は行われません。
あくまで「生成・利用段階」において、LLMに入力するための蓄積行為や入力行為、あるいは結果の生成・表示行為のために著作物の利用行為が行われているのです。
ちなみに文化庁文化審議会著作権分科会法制度小委員会(第3回)の議事録において、RAGについては、以下のやりとりのとおり「学習」段階の問題ではなく、「生成・利用」段階での問題であることが明確にされています。
【福井委員】すみません、2度目の福井ですけれども、大事なところなので、最後確認させていただきたいんですけれども、今回お示しいただいた3つの類似例は、いずれも検索と生成を組み合わせたもので、よって、新聞記事がインプットされて、それがAIによって要約されたから似たものが出てきたというケースですよね。
30条の4によって、学習したことによって何か既存の記事と似た記事が生まれてしまったという例は今回はお示しいただいていないと受け取ったんですけれども、これ自体は理解としてよろしいでしょうか。【日本新聞協会(是枝氏)】それで問題ないかと思います。
つまりRAG(軽微利用パターン)は実際には下図1なんですが、この文化庁の資料だと下図2のようなケースを指してしまうことになると思います。
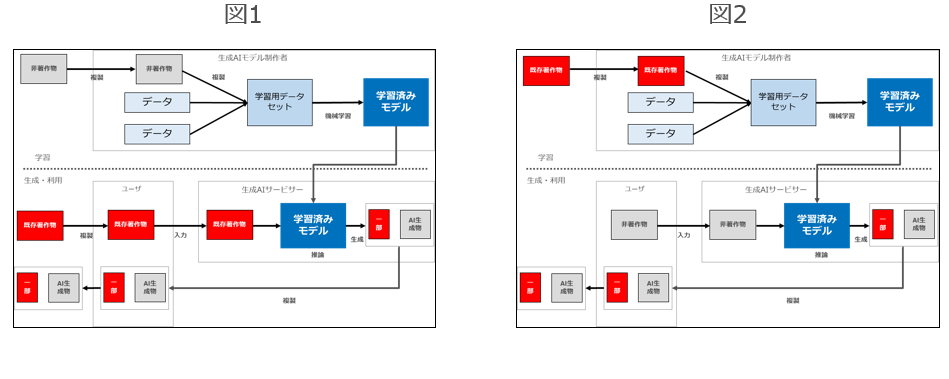
2 ICLやRAGには、生成・利用段階で30条の4が適用されるパターンもあるのではないか
また、この図では「開発・学習段階」と「生成・利用段階」で場合分けをして、「生成・利用段階」で30条の4が適用されることはないかのような図になっていますが、ICLやRAGについては、これでは説明ができないのではないパターンがあるのではないかと思います。
繰り返しになりますが、ICLやRAGの場合、「開発・学習段階」ではなく「生成・利用段階」で「情報解析」が行われています。
そして、当該「生成・利用段階」の著作物の利用行為において、享受目的がないパターンの場合には、47条の5ではなく30条の4が適用されるのではないかと思うんですよね。
つまり、ICLやRAGには「最終段階の情報解析結果提供や検索結果提供に伴って、情報解析等の対象となった著作物が「軽微利用」されるタイプのICL、RAG」(パターン2のICL、RAG)と「最終段階の情報解析結果提供や検索結果提供に伴って、情報解析等の対象となった著作物が「軽微利用」されないタイプのICL、RAG」(パターン3のICL・RAG)があります。
後者のタイプのICL・RAGの場合は、生成・利用段階における著作物の利用行為について、47条の5ではなく30条の4が適用されると思われることは既に説明したとおりです。
この2つのタイプのICL・RAGの区別の実益は、軽微利用がされないタイプのICL・RAG(パターン3のICL、RAG)の場合は既存著作物の利用に30条の4が適用されるため、権利処理がより容易になるという点です。
したがって、文化庁の図で言うと、RAGに対する言及を削除するか、あるいは、パターン3のICLやRAGの場合、30条の4が生成・利用段階でも適用される余地があることを明示した方が良いのではないかと思います(読者のわかりやすさという点からは、後者の方が望ましいと思いますが)。
ただ、実は同じ文化庁文化審議会著作権分科会法制度小委員会(第4回)のもう1つの資料「AI と著作権に関する考え方について(骨子案)」の「5.各論点について」では「(1)学習・開発段階」の論点としてではあるものの、「ウ 検索拡張生成(RAG)等の、生成 AI によって検索結果の要約等を行い回答を生成するものについては、法第 30 条の4の適用の余地はあるか。あるいは同条以外の規定(法第 47 条の5等)が適用され得ると考えるべきか。」とか【その他の論点】において「カ 生成指示のため生成 AI に著作物を入力(複製等)する行為について、法第 30 条の4の適用はどのように考えられるか。」との記載があるので、この論点について文化庁の方はよくわかっておられるのではないかと思いますが。。。。
第6 著作権侵害にならないシステム設計とは
ここまで長々書いてきましたが、結局、一言でまとめると、利用対象となった著作物が検索結果や生成結果として全部表示されている場合はNG、「軽微利用」に該当すれば47条の5の要件満たせばOK、全く表示されていなければ30条の4によりOKということです。
とすると、結局「利用対象となった著作物が検索結果や生成結果として全部表示されている」かどうかが、著作権侵害になるかどうか分かれ目ということになります。
したがって、著作権侵害を回避するためには、ビジネス的・技術的に可能なのであれば「利用対象となった著作物が検索結果や生成結果として全部表示され」ないシステム設計を目指すべきということになります。
この具体的意味は、言語の著作物を考えた場合、利用対象となる既存著作物に含まれている具体的表現と、検索結果や生成結果に含まれている具体的表現を比較した場合において、後者が前者の「複製」「翻案」に該当しないことを意味しています。
言語の著作物の「翻案」該当性の要件について判断した最高裁判例は江差追分事件(最一小判平成13年6月28日民集55巻4号837頁)です。同最判が示した基準はその後の下級審判例でもほぼそのまま踏襲されており、ほぼ確立した判断基準となっています。
同最高裁判決においては、「要旨2」として「既存の著作物に依拠して創作された著作物が、思想、感情若しくはアイデア、事実若しくは事件など表現それ自体でない部分又は表現上の創作性がない部分において、既存の著作物と同一性を有するにすぎない場合には、翻案には当たらないと解するのが相当である。」と判示されています。
そして、これを学説や学術論文の場合についてみると、学説や思想それ自体は、著作権法により保護されるものではなく、自然科学上の法則やその技術的思想の創作である発明も、いかに独創的又は新規性があっても、著作権法上保護の対象とならないし、学術論文の内容が類似する場合でも翻案にあたらないこととなります9髙部真紀子「実務詳説著作権訴訟【第2版】」(きんざい)262頁,大阪地判昭和54年9月25判タ397号152頁(発光ダイオード学位論文事件)。
したがって、検索結果や生成結果を生成・表示する際に、利用対象となった著作物の「表現上の本質的な特徴」ではなく、当該著作物のうち「思想、感情若しくはアイデア、事実若しくは事件など表現それ自体でない部分」や「表現上の創作性がない部分」のみを利用するように設計すれば良いということになります。
たとえば、技術的・法律的な質問に回答するQAシステムの場合、回答において、利用対象著作物(例:書籍やウェブページ)の「表現上の本質的な特徴」ではなく、利用対象著作物内の「法令、告示、通達、判決や決定等」(著作権法13条1ないし3号参照)「著者の見解を普通の表現で論じた部分」「一般的な見解」「法令・通達内容や法令又は判例・学説によって当然に導かれる事項」のみを表示するようにすれば「翻案」等に該当しないということです。
技術的・法律的な質問に回答するQAシステムの場合は、そのような回答でも十分利用目的を達成することができるでしょうし、LLMを利用することで、利用対象著作物の「表現上の本質的な特徴」を出力・生成しないようにコントロールすることも可能でしょう。
第8 複数主体が関与する場合
本記事では、説明をシンプルにするために、著作物の複数の利用行為をすべて1人の主体が行うことを基本的な前提としていました。
もっとも、実際には、複数の主体が関与する場合も多いと思われます。
たとえば、あるスタートアップが自社RAGサービスとして以下のようなサービスを提供することを考えてみます。
① サービサー側が、ある特定のジャンルの既存著作物(書籍やWEBページの収集やDB化、システム構築を行う
② ユーザーが質問文や検索文を同サービスに入力する
③ 出力結果が生成される
④ ユーザーが同出力結果を利用する
この場合、ユーザーとサービサーはそれぞれどのような場合に著作権侵害の責任を負うのでしょうか。
1 ユーザーが著作権侵害の責任を負う場合
ユーザーの行っている行為は、②質問文の入力行為、③出力結果の生成、④出力結果の利用行為です。
ユーザーが入力した質問文に既存著作物が含まれていない以上、①の質問文の入力行為が著作権侵害になることはありません。
そのため、問題になるのは③④です。
この場合、LLMに既存著作物が入力され、当該既存著作物の一部または全部が出力された場合、著作権侵害の要件である「依拠性」は確実に満たします(一方、ファインチューニングにおいて、学習用データがそのまま出力された場合に依拠性が認められるかは争いがあるところです)。
次に、出力結果の中に同時入力著作物が一切含まれていなければ、ユーザーによる出力結果の利用行為が著作権侵害に該当することはありません。
また、出力結果の中に同時入力著作物が一部含まれていても、それが「軽微利用」の範囲であれば、ユーザーは出力結果を、検索結果や情報解析結果として提供する目的内であれば自由に利用することができます(著作権法47条の5及び47条の7)。
さらに、「軽微利用」の範囲外であったり、検索結果や情報解析結果として提供する目的がない場合であっても、「引用」(著作権法32条)などの別の権利制限規定の要件を満たせば出力結果に含まれる同時入力著作物を利用可能です。
一方、出力結果の中に同時入力著作物が含まれており、かつそれが「軽微利用」の範囲を超えており、他の権利制限規定の適用もない場合、ユーザーが出力結果を利用(公衆に提供等)すると、当該利用行為はユーザーの著作権侵害に該当します。
2 サービサーが著作権侵害の責任を負う場合
(1) ユーザーの著作権侵害行為の幇助者としての責任を負う場合
ユーザーが著作権侵害行為を行った(たとえば、出力結果に「軽微利用」として含まれていた同時入力著作物を、他の権利制限規定も満たさない形で目的外利用した)場合に、サービサーがその幇助者として共同不法行為責任を負うかという問題です。
この場合、同RAGサービスの提供が著作権侵害の幇助行為と言えるかという問題と、サービサーにその点についての故意過失があるかという問題があります。
何らかの技術的な工夫により、「ユーザーがどのような質問をしても、出力結果に「軽微利用」を超える同時入力著作物が含まれない」(つまりパターン2またはパターン3しかありえない)ような厳格な仕組みになっているのであれば、「軽微利用」部分を目的外利用しているのはもっぱらユーザー側によってなされている行為ですので、サービサーのサービス提供行為はユーザーの著作権侵害の幇助行為とは言えないのではないかと思われます。
その場合はサービサーが共同不法行為責任を負うことはありません。
一方、そのような仕組みを備えず、場合によっては「軽微利用」を超える出力結果が容易に生成されるようなサービスであれば、そのようなサービス提供は著作権侵害の幇助行為に該当するでしょうし、ユーザーの著作権侵害行為に対するサービサーの故意過失もあることになります。
その場合はサービサーも共同不法行為責任を負うことになります。
(2) サービサー自身が著作権侵害主体としての責任を負う場合
ユーザーの質問内容に関わらず、必ず「軽微利用」を超える出力を生成するようなサービスの場合(パターン1)は、サービサー自身が同時入力著作物を蓄積した上でユーザーに対して公衆送信していることになるため、サービサー自身が著作権侵害主体としての責任を負うことになります。
第9 まとめ
以上LLM技術と外部データ活用による検索・回答精度向上手法(ファインチューニング、セマンティック検索、In-Context Learning、RAG)と著作権侵害について解説してきました。
いずれの手法についても、最終的な結果表示において、利用されている既存著作物が利用されているか否かに応じて3つのパターンに分けて説明をしていますので、ユーザーが自らシステム構築をする場合も、ベンダが自社サービス、あるいは受託作業としてシステム構築する際にも参考にしてください。
本記事で説明したような内容に沿ってサービスやシステム設計をすれば著作権侵害に該当するリスクをかなり減らすことができると思います。
なお、文中のフローチャートや、文化庁資料に対するツッコミなどは、ちょっと生煮えのところがありますので、ご意見あれば是非よろしくお願いいたします。
【注意】本記事は著作物の各利用行為に日本法が適用されることを前提としています。
- 1文化庁著作権課資料「AIと著作権の関係等について」の「*1 例えば・・・・」の部分参照
- 2松田政行 編『著作権法コンメンタール別冊 平成30年・令和2年改正解説』(勁草書房、2022年)112頁
- 3この点は、(セマンテック)検索だけでなく、ICLやRAGでも同様です
- 4ただ、30条の4で権利制限の対象となっている著作物の利用行為は、あくまで同項1号から3号に定める行為に必要と認められる範囲だけです。したがって、それ以外の目的での利用行為をすることはできません。たとえば、DB化した検索対象文書にユーザーが容易にアクセスできてその中を直接検索して検索対象文書の全部を閲覧できるような仕組みの場合、30条の4は適用されません。この点は、(セマンテック)検索だけでなく、ICLやRAGでも同様です
- 5AIモデルの「学習(ファインチューニング、追加学習を含む)」においては、モデル内のパラメータの物理的な更新行為が行われることから、当該学習行為は問題なく「情報解析」(30条の4第2号)に該当するとされています(松田政行 編『著作権法コンメンタール別冊 平成30年・令和2年改正解説』(勁草書房、2022年)14頁)
- 6松田政行 編『著作権法コンメンタール別冊 平成30年・令和2年改正解説』(勁草書房、2022年)14頁
- 7岡野原大輔「大規模言語モデルは新たな知能か」(岩波書店)114頁
- 8ここでいう「情報解析の前段階」や「情報解析の後段階」は厳密な意味ではありません。「情報解析等」と同時に行われる利用行為もあるからです。もっとも、「前」と「後」の方がイメージがしやすいと思いますので、この表現を使います
- 9髙部真紀子「実務詳説著作権訴訟【第2版】」(きんざい)262頁,大阪地判昭和54年9月25判タ397号152頁(発光ダイオード学位論文事件)












