人工知能(AI)、ビッグデータ法務
Midjourney、Stable Diffusion、mimicなどの画像自動生成AIと著作権(その2)

前回記事「Midjourney、Stable Diffusion、mimicなどの画像自動生成AIと著作権」は、おかげさまで沢山の方に読んで頂き、いろいろな意見や御質問や取材を頂きました。
それらの意見・御質問や取材を通じて、自分の中で新たな整理ができたので、続編の記事を書きたいと思います。
Contents
第1 どのような場合に著作権侵害になるのか
みなさんの興味関心が強いトピックとして「画像自動生成AIを利用して画像を自動生成し、既存著作物の類似画像が生成された場合に著作権侵害に該当するか」があります。
前回の記事では「学習に用いられた画像と同一の画像が『偶然』自動生成された場合、著作権侵害に該当するか」について解説をしましたが、今回の記事では、もう少し多くのパターンについて検討をしたいと思います。
まず、その前提として「著作権侵害の要件」と「著作権侵害の効果」について説明をします。
この「要件」と「効果」というのは、法律的な問題を検討する際にはよく出てくるフレームワーク(と言うほど大げさなものではありませんが)でして、要するに「どのような条件を満たすと著作権侵害に該当するか」と「著作権侵害に該当する場合、著作権を侵害された者は侵害者に対して何を請求できるか」ということです。
1 著作権侵害の要件:どのような条件を満たすと著作権侵害に該当するか
前回の記事でも簡単に説明をしましたが、著作権侵害の要件は、① 当該著作物が既存著作物と類似していること(類似性)及び② 依拠性の2つです。
AI自動生成物特有の論点は②の「依拠性」の部分なのですが(詳細は後で説明します)、①の「類似性」についても多くの意見・感想を頂きました。
特に「既存著作物に画風・作風が類似しているだけでも『類似性』は肯定されるのではないか」というご意見が多かったです。
この点については、これまでの裁判上の判断基準としては一応はっきりしていまして、「類似性」が肯定されるためには「既存著作物の表現上の本質的な特徴を直接感得できること」が必要であるとされており1最判平成13年6月28日判事1754号144頁(江差追分事件)、知財公判平成25年9月30日判事2223号98頁(風にそよぐ墓標事件)等。 、「作風」「スタイル」レベルでしか類似していない場合には、類似性を満たさず、著作権侵害には該当しません。
簡単に図示するとこんな感じです。
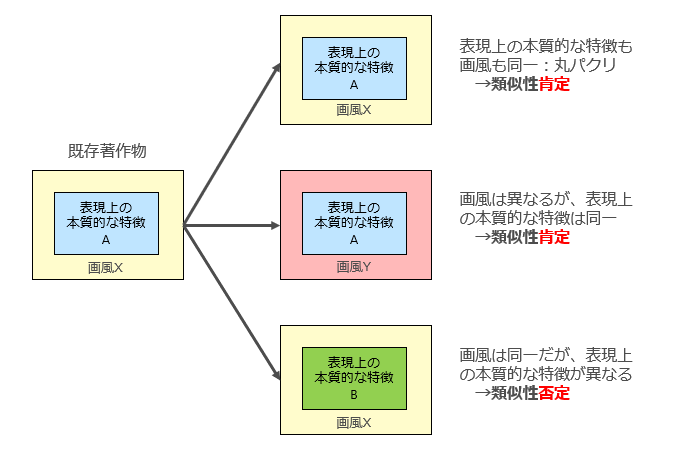
一番下の「画風は同一だが、表現上の本質的な特徴が異なる」というものは、たとえば「宮崎駿がこの絵を描くのであればこの様に描くのだろうが、実際には宮崎駿は過去一度もこの絵そのものを描いていない」パターンです。
このように図で概念的に示すのは簡単なのですが、実際には、何が「表現上の本質的な特徴」で何が「画風・作風」なのかという区別自体がはっきりしませんので、著作権侵害訴訟では非常に揉める論点です。
2 著作権侵害の効果:著作権侵害に該当する場合、著作権を侵害された者は侵害者に対して何を請求できるか
次に著作権侵害に該当する場合、著作権を侵害された者は侵害者に対して何を請求できるかです。
みなさんがよくご存じなのは、「差止請求」と「損害賠償請求」ではないでしょうか。
(1) 差止請求
「差止請求」というのは「著作権侵害行為の停止」を求めることを意味します。たとえば、著作権侵害のイラストがあった場合に、当該イラストがWEBサイト上に掲載されていれば当該掲載の停止を求めることができますし、書籍として出版されている場合は当該書籍の出版の停止を求めることができます2ただし、書籍の一部分のみにしか当該イラストが掲載されていない場合に、書籍全体の出版の差し止めを求められるかは議論がある。。
重要なポイントは、損害賠償請求と異なり、侵害者に故意・過失がなくとも差止請求は認められるということです。
したがって、著作権侵害の要件(依拠性+類似性)を満たした場合において、侵害者に過失がない場合には、差止請求のみ認められ、損害賠償請求は認められないということになります。
(2) 損害賠償請求
「損害賠償請求」は読んで字のごとく、損害賠償金というお金の支払いを求めることができるという意味です。先ほど説明したとおり、損害賠償請求が認められるためは、差止請求と異なり、侵害者に故意・過失があることが必要です。
この点は、後述の「既存画像が学習用データに用いられていることをAI利用者が知らない」パターンで結論を大きく左右します。
(3) 廃棄請求
また、著作権法112条2項において、差止請求に際し「侵害の行為によって作成された物」の廃棄を請求することができるとされていますので、裁判でAI生成物に著作権侵害が認められた場合には、侵害者の手元にある侵害物品については廃棄を命じられる可能性があります。
(4) 回収・廃棄請求
では、裁判でAI生成物に著作権侵害が認められた場合に、過去に販売したAI生成物の回収まで命じられる可能性があるのでしょうか。
この点については、著作権法112条2項において廃棄請求は認められていますが、すでに販売してしまった物について、侵害者が回収して廃棄せよと命じることはできないと考えられています。これは、販売してしまった物については、すでに販売先の所有物となっているためです3中山信弘・著作権法(第3版)724頁。
3 著作権侵害が問題となるパターン
以上を前提として、画像自動生成AIを利用して画像を自動生成し、既存著作物の類似画像が生成された場合、どのようなケースが著作権侵害に該当し、どのようなケースが侵害に該当しないかについて検討していきましょう。
以下、いずれのパターンでもAI利用者は既存画像の利用許諾を得ていないものとします。夜明けと海
(1) パターン1
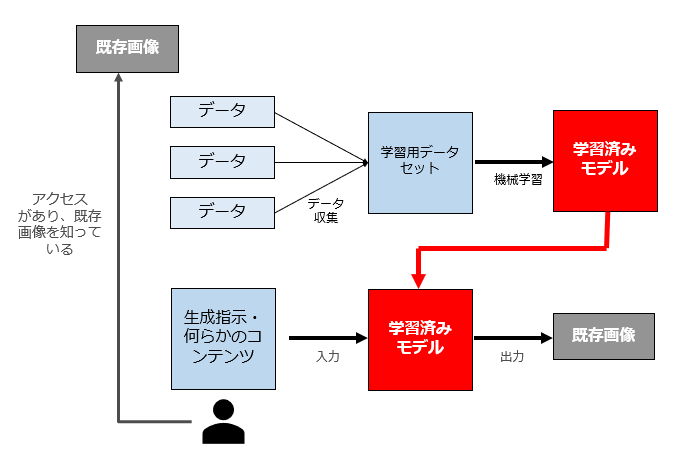
まず、「既存画像は学習に利用されていないが、AI利用者が当該画像に接したことがあり(アクセスがあり)、既存画像の存在を知っているパターン」です。
既存画像が有名画像の場合に多いパターンと思われます。
このパターンでAIを利用して既存画像を生成する行為は、要するに「知ってパクった」ことになります。
したがって依拠性及び類似性の要件を満たしますし、AI利用者に故意過失もありますので、AI利用者は著作権侵害フルコンボ(差止+損害賠償+廃棄)の責任を負うことになります。
(2) パターン2
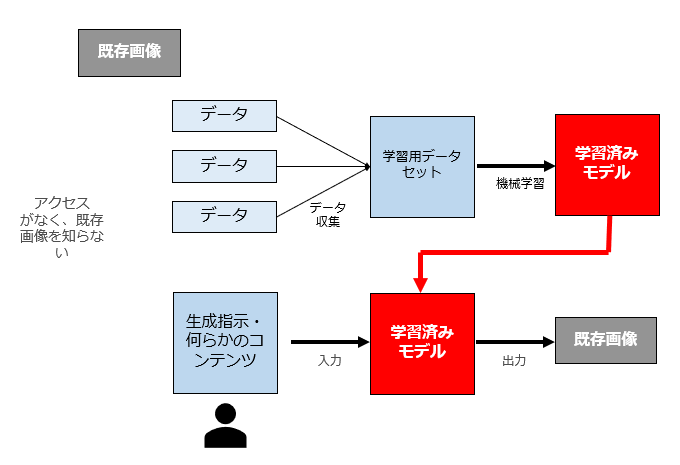
これは、「既存画像は学習に利用されておらず、かつAI利用者が当該画像に接したこともなく(アクセスがなく)、既存画像の存在を知らないパターン」です。
この場合は、依拠性がないためAI利用者の独自創作に該当し、AI利用者が著作権侵害の責任を問われることはありません。
このパターンが裁判に持ち込まれた場合は、依拠性の存在、つまりAI利用者が当該既存画像に接したことがあるか否かが最大の論点になります。
著作権侵害訴訟においては依拠性が争われた場合、裁判所は「これだけ細部まで似ているものが別個独立に創作されることはあり得ない。ここまで似ているのだから依拠性はあるはずだ」という判断を行うことが多いと言われています4たとえば、東京地八王子支判昭和59年2月10日判時1111号134頁(ゲートボール事件)では、既存の著作物と同一あるいは類似のものを作成した場合、それは依拠したことを推認する資料となりうるのであって、それが酷似すればするほどその度合いは強くなる、と述べている。 。
したがって、このパターンでは、実際には「既存画像と自動生成画像がどこまで類似しているのか」が大きな論点になるのではないかと思われます。
(3) パターン3
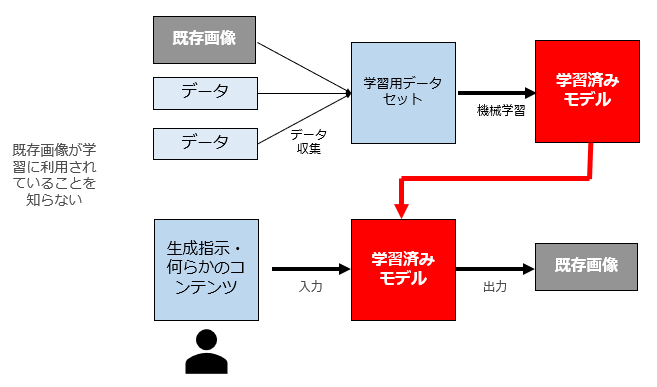
これは、「利用許諾を得ていない既存画像が学習用データとして利用されているが、AI利用者がそれを知らないパターン」です。まあ、普通はAI利用者は当該AIの学習用データとして何が利用されているかは知らないことがほとんどなので、このパターンは結構多いと思います。
このパターンで著作権侵害が認められるかは、依拠性が認められるかどうかにかかっているのですが、この点については肯定説と否定説があることは前回記事にて説明したとおりです。もっとも、私の観測範囲では、このパターン(学習用データに既存著作物が利用されているパターン)においては、依拠性を肯定する学説が多いかなと思います。
依拠性を肯定するという解釈を採用する場合、AI利用者の行為は著作権侵害に該当することになります。
したがって、AI利用者はまず当該AI生成物の将来の利用について差止請求を受けることになります。
もっとも、このパターンはAI利用者が、当該AIの学習用データとして何が利用されているか知らないのですから、AI利用者に故意も過失もないことになります。
したがって、このパターンの場合、AI利用者は、差止請求は受けるが損害賠償責任は負わないと考えます5ただし、この点については①既存のものと類似する画像が作成された段階と②作成された画像を外部に提供する(譲渡・公衆送信等)段階とで過失要件を分けて整理する学説も存在する(愛知靖之「AI生成物・機械学習と著作権法」パテント73巻8号146頁)。
(4) パターン4
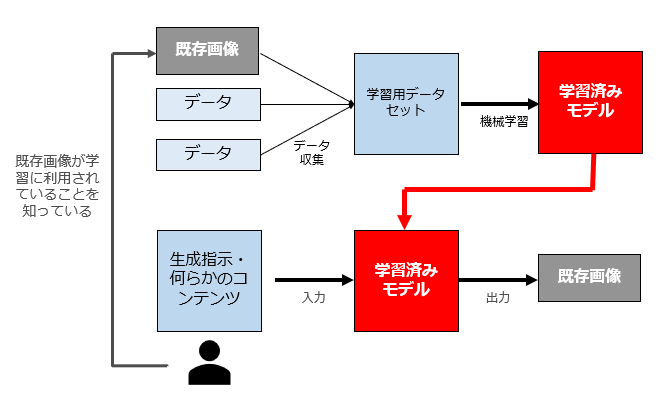
これは、「既存画像が学習用データとして利用されており、かつAI利用者がそれを知っているパターン」です。
mimicのようなAIモデル生成ツールにおいて、利用許諾を得ていない既存画像を学習に利用するのは、まさにこのパターンですね。
この場合は、依拠性肯定説をとると「依拠性肯定+AI利用者の故意過失も肯定」ですので、AI利用者は著作権侵害フルコンボの責任を負います。
(5) パターン5
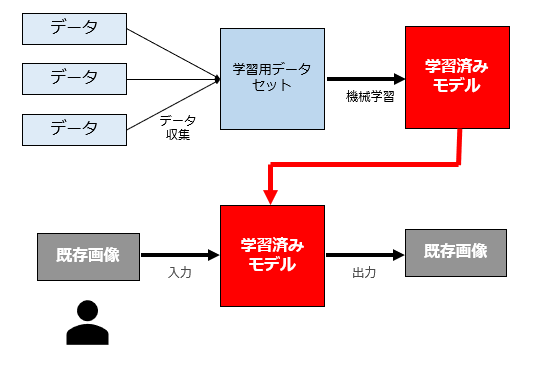
最後のパターンです。
これは、「いわゆるimage2image(指定画像をAIに入力して画像を生成させる)機能を利用して、利用許諾を得ていない既存画像を入力し、類似画像を出力するパターン」です。
このパターンは、当然のことながら依拠性+類似性+AI利用者の故意過失も肯定されますので、著作権侵害フルコンボです。
(6) おまけ
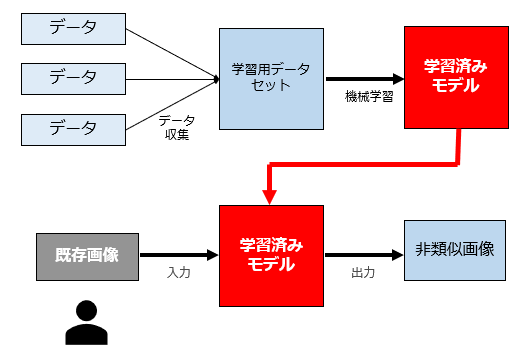
最後におまけです。
これも、いわゆるimage2image(指定画像をAIに入力して画像を生成させる)機能を利用して、利用許諾を得ていない既存画像を入力するパターンですが、先ほどのパターンと異なり非類似画像を出力しています。
したがって、問題となるのは、AI利用者が既存画像をモデルに入力する行為だけ、ということになります(非類似画像は既存画像の表現上の本質的特徴を含まないので、その出力は自由ですし、出力された非類似画像を利用することも自由です)。
AI利用者が既存画像をモデルに入力する行為は、既存画像の「複製」行為を行っていることになりますが、AI利用者が個人であれば、私的利用目的複製(著作権法30条)に該当するでしょうし、あるいは、既存画像の創作的な表現が利用されていないとして、著作権法30条の4柱書の「当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」に該当する可能性も高いと思われます。
いずれにしても、このパターンにおいて「AI利用者が既存画像をモデルに入力する行為」は著作権侵害を構成しないと考えます。
第2 自分の創作した絵を機械学習の学習用データに使われることへのクリエイターの強い拒否感と著作権法30条の4
次に、自分の創作した絵を機械学習の学習用データに使われることへのクリエイターの強い拒否感と、それを可能にしてしまう著作権法30条の4ってどうなのよ、という意見があります。
この場合、前回記事に書いたように、クリエイターが画像を利用されたくなければ、単純に「AI学習利用禁止」と表明するだけでは足りず、AI学習利用禁止を明記した利用規約に同意した後に初めて画像にアクセスできるなどの仕組みが最低限必要です(ただし、そのような利用規約の有効性については前記事に書いたように争いがあります)。
ただ、強調しておきたいのは、著作権法30条の4で適法化されるのは、あくまで「AI(学習済みモデル)を生成する」ところまでであって、「著作権法30条の4があるから、生成したAIを利用して既存著作物と同じものを生成し放題」ということではないということです。
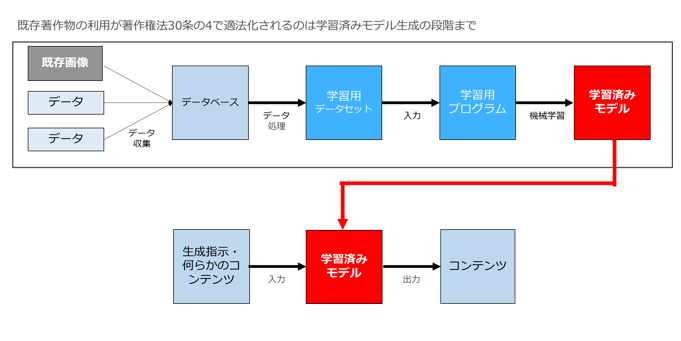
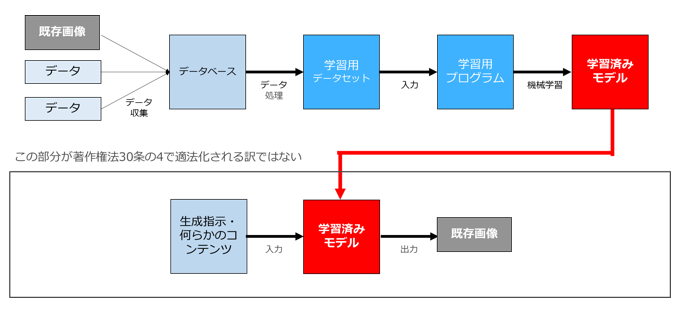
「既存画像と類似の画像を出力した場合に著作権侵害に該当するか」の論点は、先ほど「どのような場合に著作権侵害になるのか」において、細かくパターン分けをして説明したとおりです。そこでは著作権法30条の4の話は一つも出てなかったことからおわかりのように、著作権法30条の4の問題ではありません。
AIロンダリング(人間が行えば著作権侵害になる行為が、AIを利用することで非侵害になる)などというものはありません。
ちなみに、なぜ著作権法30条の4のような条文によって既存著作物の利用が許されているのかなのですが、一言で言うと、著作権法30条の4が想定している著作物の利用方法が「非享受利用」だからです。「非享受利用」とは、著作物の本来的利用(享受利用)である「著作物を見たり聞いたり読んだりして楽しむ」以外の方法による利用のことです。
詳細については、著作権法の平成30年改正について解説したこちらのブログをご参照ください。
【参考】
進化する機械学習パラダイス ~改正著作権法が日本のAI開発をさらに加速する~
第3 ご意見・質問に対する回答
以下ではSNSや取材を通じて頂いたご意見・質問を適宜アレンジしてご紹介・答していきます。
■ これまでも著作権侵害に関する紛争は沢山あったと思うが、AI自動生成画像が普及していくと、それらの紛争において何か新しい論点が生じるのか
「著作権侵害」には様々なパターンがありますが、「イラストの無断複製」に絞って説明します。
侵害者による「著作権侵害」が認められるためには「①著作権が存在するイラストに②依拠した③類似作品を④侵害者が作成して利用している」ことを、著作権侵害を主張する側が証明する必要があります。
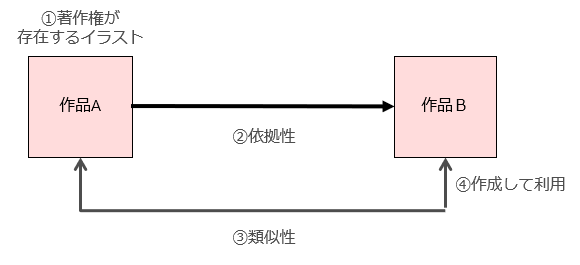
まず①の「著作権が存在するイラスト」については、侵害者側から「この時代、AIを利用して生成されたイラストの可能性があるから作品Aに著作権はない」という反論がなされることが考えられます。これまでイラストは人間が創作するのが当然だったため「当該イラストを、そもそも人間が創作したのか」が裁判で争われたことは私が知る限りありません(もちろん「誰が創作したか」が争われるパターンはあります)。
ただ、今後はその点が争われた場合、著作権侵害を主張する人は「自らの創作行為により著作権が発生していること」、つまり対象となるイラストがAI生成物(AIが自律的に生成した生成物)ではなく、自分という人間が、創作意図と創作的寄与を持って、AIを道具として創作したものであることを証明する必要が生じることになります6愛知靖之「AI生成物・機械学習と著作権法」(パテント73巻8号139頁)、。
その際には、当該イラストを作成した際のツールのログなどが重要な証拠になるでしょう。
ただ、こうなると全ての著作権侵害訴訟でまず原告が「AIではなく自分という人間が創作したものであること」を証明しなければならないことになるかもしれません。その点について指摘しているのが慶応大学の奥邨先生の「AI自律生成コンテンツの僭称問題」の記事です。、
次に、②依拠性については、昔から著作権侵害を主張する側による証明が難しい論点でした。
しかも、AI時代になると、当該事件が、この記事で説明したどのパターンなのか(学習用データに含まれていないが依拠性ありのパターン、学習用データに含まれているパターン、あるいは入力データに含まれているパターン)を、著作権侵害を主張する側が証明する必要があるでしょう。ただ、その証明はかなり難しそうですよね。。。この点は、侵害を主張する側にとっての高いハードルになるかもしれません。
③の類似性については、AI生成物特有の論点はありません。これまでの裁判同様「既存著作物の表現上の本質的な特徴を直接感得できる」かどうかで結論が変わります。
最後の④については、前の記事でも言及したとおり、公開されているAIを利用して生成されたイラストの利用が著作権侵害に該当する場合、当該利用者だけでなく、当該AIというツールを提供した者も何らかの責任を問われるのか、という問題が生じます。
ただ、この点も「著作権侵害をもたらす可能性のあるツール提供者が責任を負うか」という形でこれまで複数の裁判例が積み重ねられています。今後はそれらの裁判例との整合性も見ながら判断が積み重ねられていくと思います。
■ 日本では著作権法の穴を契約のオーバーライドで塞ぐことが出来ないとなると、OSSコードのGPLライセンスなどもAIを通せば無効になるということでしょうか?
大変面白い御質問です。
2つの論点を考える必要があると思います。
まず、OSSコードを大量に収集してきて、それを訓練データとしてコード自動生成AIモデルを制作する(言語生成系のAIモデルでは既にそのようなことを行っているかもしれませんね)場合に、OSSコードの中にGPLライセンスが付されているものがあり、当該コードを学習に利用する際にGPLライセンスにより何らかの制限がかかるのか、という問題です(学習における問題)。
もう1つは、OSSコードを学習用に用いてコード自動生成AIモデルを生成し、当該モデルに指示をしたところ、当該OSSコードと同一のコードが生成された場合に、生成されたコードの利用について、元のOSSコード(学習に用いられたOSSコード)に付されていたGPLライセンスが適用されるか、という問題もあります(生成物の利用における問題)。
(1) 学習における問題
オーバーライド問題というのは、通常「学習における問題」として議論されていますので、まずそちらから。
あまり考えたことがないのですが、GPLライセンスによる制限は、対象OSSを第三者に「配布」する場合にしか発動しないと理解しており、OSSを学習に利用するだけでは「配布」に該当しないことから、特にGPLライセンスによる制限は問題にならないのではないかと思います(間違っていたらどなたかご指摘下さい)。
ちなみに、CCライセンスについてはこの問題は既に解決済みです。
つまり、CCライセンスは著作権法の権利制限規定を上書きしないとされています。
具体的には「『非営利』の条件があるCCライセンスのついた作品を利用する際、著作権法上規定されている「引用」に該当すれば、仮に営利を目的とする利用でも認められることとなります。」とされています。
つまり、CCライセンスがついている著作物については、オーバーライド問題は起こらず、著作権法30条の4などの権利制限規定の要件を満たしてさえいれば、営利目的であったとしても、『非営利』の条件があるCCライセンスのついた著作物を適法に学習に利用できることになります。
(2) 生成物の利用における問題
この点については考えたことがありませんでした。
ただ、先ほどの「著作権侵害が問題となるパターン」において、著作権侵害が認められると結論づけたパターン(学習用データに含まれていないが依拠性ありのパターン、学習用データに含まれているパターン、及び入力データに含まれているパターン)に該当する場合は、出力されたコードは学習に用いられたコードの翻案物ということになります。
そうすると、当該パターンにおいては、出力されたコード(翻案物)についても、元のOSSコード(学習に用いられたOSSコード)に付されていたGPLライセンスが適用されるのではないでしょうか。
CCライセンスの場合は、元の著作物に付されていたCCに「SA(継承」条件が含まれていれば、出力された著作物には、元の著作物のCCライセンスがそのまま適用されると思います。一方、「元の著作物に付されていたCCに「SA(継承」条件が含まれてなければ、元の作品についているライセンスよりも同じか、より制限を課す条件でのライセンス下での利用が可能になります。この点についてはCCライセンスのFAQが参考になると思います。
■ 著作権法30条の4の条文はあくまで「多数の著作物」を学習データとするのを前提としていますが、機械学習では、少数データを教師とすることもあると思います。mimicも、問題とされていたのは、大量データによる事前学習よりも、「作風」を学習する十数枚の画像による部分でした。そのような少数画像の利用でも著作権法30条の4は適用されるのでしょうか。
この質問は複数の方から聞かれました。
この点については、先ほど記事をご紹介した奥邨先生がツイートしているので、以下参照して頂ければと思います。
30条の4などにおける情報解析について・・・
情報解析については「多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うこと」と定義されているが、法律用語として「その他の」直前の語は例示に過ぎない。— KJ_OKMR (@OKMRKJ) August 31, 2022
ここで著作権法30条の4の条文をもう一度見てみましょう。
(著作物に表現された思想又は感情の享受を目的としない利用)
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 略
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 略
問題は、少数の画像から学習する行為が2号の「情報解析」の定義に該当するかです。
条文をよく読むと、「情報解析」の定義は「多数の著作物その他の大量の情報から」と書いてあります。奥邨先生がわかりやすく解説していますが、このような記載ぶりからすると、「多数の著作物」というのは、あくまで「大量の情報」の一例に過ぎません7勁草書房・著作権法コンメンタール(第2版)第2巻・573頁(奥邨弘司)。
したがって「多数の著作物」を利用していなくても「大量の情報」を利用していれば「情報解析」に該当することになります。
そして、少数の画像を学習に利用することを考えたときに、「1枚1枚の画像」に着目すると確かに「多数の著作物」には該当しませんが、「当該1枚1枚の画像に含まれる情報(個々の画素の内容、画素の位置関係等)」に着目すれば「大量の情報」に該当することはあり得ると思います。
したがって結論としては、少数画像を学習に利用する場合であっても、著作権法30条の4の「情報解析」に該当し、同法が適用されことはある、ということになります。
■ AI生成物に著作権が生じないのであれば、AIを利用して既存著作物と類似するAI生成物を作成して利用したとしても、著作権侵害責任を負わないのでは?著作権が発生しないのに侵害責任だけ負うのはアンバランスだと思います。
前の記事で「3つ論点があります」と説明をしましたが、そのうちの2つの論点、すなわち「AI生成物に著作権が生じるか」と「AIを利用して既存著作物と類似するAI生成物を作成して利用した場合に著作権侵害責任が生じるか」は全く別の論点であり無関係の論点です。
つまり、AI生成物に著作権が生じない場合(たとえば極めて短い呪文だけで画像を生成した場合)であっても、当該AI生成物が既存著作物と類似しており、依拠性も満たしていれば、著作権侵害は成立します。
逆に、AI生成物に著作権が生じる場合(具体的・複雑な呪文や、複数のAI生成物から選択するなど)であっても、当該AI生成物が既存著作物と類似していない、あるいは依拠性がない場合には、著作権侵害は成立しません。
■ mimicってどう思います?
これは取材で毎回聞かれました笑。
私の意見はシンプルで「このツールの提供は違法ではない」「このツールを使って著作権侵害を犯した利用者がいたとしてもツール提供者は責任を問われない」です。
ここは色々な意見があるところかもしれませんが、今後の日本における、コンテンツ自動生成系ツール提供のビジネスに極めて大きな影響を与える論点なので、自分の意見をきちんとお伝えしようと思います(もちろん、私の意見と異なる学者さんもおられます)。
理由は、前回記事でかなり詳細に説明したとおりなので繰り返しませんが、ツール提供者の責任を判断するに際しては「著作権侵害発生の実質的危険性を有する物品を、侵害発生を知り、又は知るべきでありながら、侵害発生防止のための合理的措置を採ることなく、当該侵害のために提供する行為」かどうかで判断すべきと考えます。
そして、「ツール」と一言で言っても「著作権侵害発生の実質的危険性を有する」かどうかはケースバイケースです。
たとえば学習用データセットや、多種多様なデータで学習させた学習済みモデル(AI)、学習済みモデルを作成できるツール(これがmimicですね)は、いくらでも適法に利用できるツールですので、「著作権侵害発生の実質的危険性を有する」とまでは言えないでしょう。
したがって、それらのツールを使った利用者が、仮に著作権侵害行為を行ったとしても、ツール提供者が責任を負うことはないと考えます。
一方で「ある特定のイラストレーターの既存作品を自動生成することを目的として、当該イラストレーターの既存作品のみを収集してデータセットを作成し、同データセットを用いて学習させた学習済みモデル」は「著作権侵害発生の実質的危険性を有する物品」に該当すると思います。したがって、そのようなモデルを提供し、当該モデルを使った利用者が著作権侵害行為を行った場合には、モデル提供者は責任を問われる可能性が高いでしょう。
第4 まとめ
以上「どのような場合に著作権侵害になるのか」についてのまとめと、著作権法30条の4の適用範囲、ご意見・御質問に対する回答、をしてきました。
画像自動生成AIに関して、今後書こうと思っている記事は「画像自動生成AIを利用したビジネスにおいて留意すべき事項」「一般の利用者が画像自動生成AIを利用する場合の注意点」「各画像自動生成AIの利用規約を読んでみよう」「コンテンツ自動生成AIにおける著作権以外の権利侵害(肖像権、パブリシティ権侵害など)について」などです。
ちょっと先になるかもしれませんが、お楽しみに!
【文中脚注】
- 1最判平成13年6月28日判事1754号144頁(江差追分事件)、知財公判平成25年9月30日判事2223号98頁(風にそよぐ墓標事件)等。
- 2ただし、書籍の一部分のみにしか当該イラストが掲載されていない場合に、書籍全体の出版の差し止めを求められるかは議論がある。
- 3中山信弘・著作権法(第3版)724頁
- 4たとえば、東京地八王子支判昭和59年2月10日判時1111号134頁(ゲートボール事件)では、既存の著作物と同一あるいは類似のものを作成した場合、それは依拠したことを推認する資料となりうるのであって、それが酷似すればするほどその度合いは強くなる、と述べている。
- 5ただし、この点については①既存のものと類似する画像が作成された段階と②作成された画像を外部に提供する(譲渡・公衆送信等)段階とで過失要件を分けて整理する学説も存在する(愛知靖之「AI生成物・機械学習と著作権法」パテント73巻8号146頁)
- 6愛知靖之「AI生成物・機械学習と著作権法」(パテント73巻8号139頁)、
- 7勁草書房・著作権法コンメンタール(第2版)第2巻・573頁(奥邨弘司)












