人工知能(AI)、ビッグデータ法務 著作権
【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~第3回

【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~
本連載は、2024年3月15日に文化審議会著作権分科会法制度小委員会「AIと著作権に関する考え方について」(以下「考え方」」といいます)が公表されたことを受けて、2024年4月時点でのAIと著作権に関する法的論点とその基本的な考え方について網羅的に整理したものです。
本連載の作成にあたっては、文化庁の「考え方」をベースに、関連する各書籍や論文等を参照し、かつ私自身が実務で経験したことを最大限盛り込んでいます。
特に「上野達弘・奥邨弘司(編)「AIと著作権」勁草書房、2024年」は、2024年時点の最新の論点について、理論的・実務的な観点から極めて詳細な検討がされている書籍であり、本連載作成に際しても大いに参考にしています。
本連載では、網羅的、かつ最新の知見を盛り込みつつも、学説の対立の紹介は最小限にとどめて、できるだけ一般的な結論を記載するようにしています。
もっとも、連載の中での「通説」「一般的」という表現は、あくまで筆者の個人的な見解ですので、そのつもりでお読み下さい。
■ 連載目次
1 AIと著作権法に関する全体像
(1) 分析の視点
(2)「開発・学習」段階と「生成・利用」段階の意味
(3) 誰が、どのような行為に対して、どのような責任を負う可能性があるのか
(4) 開発・学習段階と生成・利用段階を分けて検討する意味
【以上第1回】
2 開発・学習段階
(1)分析の視点
(2)学習目的による制限
【以上第2回】
(3)学習対象による制限
ア はじめに
イ 情報解析に活用できる形で整理したデータベースの著作物
ウ 海賊版等の権利侵害複製物
【以上第3回】
エ 学習禁止意思が付されている著作物
オ 学習を防止するための機械可読方法による技術的な措置が付されている著作物
カ 情報解析用DB著作物以外の著作物のうちライセンス市場が形成されている(すでにライセンス・販売されている)もの
(4)開発・学習段階での著作権侵害行為について権利者はどの範囲で差止請求等ができるか
(5)生成・利用段階における情報解析と30条の4
(6)30条の4と47条の5の役割分担
【以上第4回】
3 生成・利用段階
(1)検討の視点
(2)依拠
【以上第5回】
(3)行為主体性
(4)入力
(5)生成
(6)送信
(7)利用
【以上第6回】
4 結局、著作権者は誰に何を請求できるのか
5 AI開発者・AIサービス提供者・AI利用者は著作権侵害とならないために何をすれば良いのか
6 RAGと著作権侵害についての整理
7 AI生成物の著作物性について
8 日本著作権法の適用範囲
2 開発・学習段階
(3) 学習対象による制限
ア はじめに
次に「学習対象による制限」について検討します。
具体的には「イ 情報解析に活用できる形で整理したデータベースの著作物」「ウ 海賊版等の権利侵害複製物」「エ 学習禁止意思が付されている著作物」「オ 学習を防止するための機械可読方法による技術的な措置が付されている著作物」「カ 情報解析用DB著作物以外の著作物のうちライセンス市場が形成されている(すでにライセンス・販売されている)もの」の5つです。
このうち「イ 情報解析に活用できる形で整理したデータベースの著作物」については、2018年の著作権法改正の前から、AI開発・学習の対象にはできないことが明確化されていた学習対象です。もっとも「考え方」においては、より具体的に、踏み込んだ記載がされているので、本記事でかなりの紙幅を割いて検討しました。
また「ウ 海賊版等の権利侵害複製物」についても、海賊版対策との関係上、学習対象とすることに対して大きな批判があるところです。
「エ 学習禁止意思が付されている著作物」「オ 学習を防止するための機械可読方法による技術的な措置が付されている著作物」「カ 情報解析用DB著作物以外の著作物のうちライセンス市場が形成されている(すでにライセンス・販売されている)もの」については、従来からいろいろな議論がなされていましたが、「考え方」によって一定の整理がなされたのではないかと思われます。
イ 情報解析に活用できる形で整理したデータベースの著作物
① 情報解析用DB著作物とは
30条の4柱書但書に該当する例として、同条制定当時から、「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為」が示されていました(「考え方」24頁)1ただし、大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為」については、30条の4柱書但書の問題ではなく、当該データベース著作物の本来的利用であるとして享受目的併存により30条の4が適用されない、という説もある(前田健「生成AIの利用が著作権侵害となる場合」(法学教室№523・30頁、「AIと著作権」座談会232頁)。
この「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物」を、以下「情報解析用DB著作物」といいます。
情報解析用DB著作物については、それを学習(情報解析)目的で利用したり、生成・利用段階で、AIによる解析(情報解析)目的で入力したりする行為は、30条の4柱書但書に該当し、他の権利制限規定が適用されなければ著作権侵害になります。
もっとも、注意しなければならないのは、「考え方」24頁~27頁で「(ウ)情報解析に活用できる形で整理したデータベースの著作物の例について」「(エ)本ただし書に該当し得る上記(ウ)の具体例について(学習のための複製等を防止する技術的な措置が施されている場合等の考え方)」に記載されているのは、この「情報解析用DB著作物」の複製に該当するか、という点であり、それ以外の著作物に関するものではない、ということです。
上記「(ウ)」「(エ)」(考え方P24~P27)においては、報道機関がウェブ上で個々の記事を提供しているケースについて記載されていますが、これは当該個々の記事の著作権侵害のことを問題にしているわけではありません。
つまり、「考え方」のこの部分は、「個々の記事をクローリングした結果、報道機関が別途提供している(あるいは将来提供予定の)情報解析用DB著作物の複製に該当する場合には、当該情報解析用DB著作物の著作権侵害になりえる」と述べているだけであって、あくまで、当該情報解析用DB著作物の著作権侵害を問題にしているに過ぎません。
これは「考え方」26頁の「○ そのため、AI 学習のための著作物の複製等を防止する技術的な措置が講じられて・・・・・」の部分において、「この措置(注:複製防止のための技術的措置)を回避して、クローラにより当該ウェブサイト内に掲載されている多数のデータを収集することにより、AI学習のために当該データベースの著作物の複製等をする行為」とされていることからも明らかです(強調部分筆者)。
また、小委員会でも上野委員ら複数の委員からこの点について指摘があり、事務局から明確に以下のような回答があったところです(第6回小委員会議事録・上野委員、澤田委員・中川委員発言参照)。
【三輪著作権課調査官】事務局でございます。ただいま委員の先生方からいただきました意見を踏まえまして少し補足させていただきますと、今おっしゃっていただきましたように、この点、記載の趣旨としては、先ほど事務局から御説明申し上げたとおり、対象の著作物として考えておりますのは、情報解析用のデータベースの著作物であり、問題にする行為としても、情報解析用のデータベースの著作物の複製と言えるような行為については、30条の4ただし書に該当し、権利制限の対象とはならない場合があると、そういう趣旨の記載をしているというところでございます。
また、同委員会の主査である茶園先生も以下のように整理しています((第6回小委員会議事録)
【茶園主査】ほかにございますでしょうか。
この点は、そもそもrobots.txtを回避するという行為をどう評価するか、それが30条の4ただし書とどのように関係するかとか、30条4のただし書の適用範囲は何かとかの、様々な論点が係わると思いますけれども、事務局の考え方では、先ほど説明していただきましたように、23ページに書かれているのは基本的にデータベースの著作物を対象にしたものであるということです。それでは、記事の著作物についてはどうなるかという点は、この点には様々な御意見があるかもしれませんが、ここでは触れていないということであると思います。データベースの著作物に関しては、皆さんに御賛同いただけるのであれば、ここはデータベースの著作物についての記載であることを明確にすることでどうでしょうか。
ただ、データベースのことを例に挙げると、記事について何らかの意味があるように感じられる可能性もありますけれども、そういうことを全て気にすると何も書けないということもあります。ここではデータベースの著作物についてのことであることを明確にして、上野委員や他の委員の先生方に言っていただいたような修正等を検討するということでよろしいでしょうか。
② 情報解析用DB著作物の複製が行われるパターン
考え方「(ウ)」「(エ)」(「考え方」24頁~27頁)で示されている、情報解析用DB著作物の複製が行われるパターンは以下の3つです。
▼ パターン1
情報解析用DB著作物がDVD等の記録媒体に記録して提供されている場合にそのまま当該記録媒体から複製するパターン▼ パターン2
インターネット上のウェブサイトで、ユーザーの閲覧に供するため記事等が提供されているのに加え、情報解析用DB著作物がAPI を通じて有償で提供されている場合において2なお「考え方」25頁脚注28には「この点に関して、インターネット上のウェブサイトに掲載されたデータについては、AI 学習のための複製を行うクローラによるウェブサイト内へのアクセスが、後述するウェブサイト内のファイル”robots.txt”への記述により制限されていない場合、「(大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が)販売されている場合」に該当しないことを推認させる要素となるものと考えられる」との記載がある。この記載内容は合理的であるが、このような技術的措置が講じられていない事実は、パターン3における「情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があること」に該当しないことを推認させる要素にもなると思われる(パブコメ191参照)。、当該 API を有償で利用することなく、当該ウェブサイトに閲覧用に掲載された記事等のデータから、当該データベースの著作物の創作的表現が認められる一定の情報のまとまりを情報解析目的で複製するパターン▼ パターン3
AI 学習のための著作物の複製等を防止する技術的な措置が講じられており、かつ、このような措置が講じられていることや、過去の実績(情報解析に活用できる形で整理したデータベースの著作物の作成実績や、そのライセンス取引に関する実績等)といった事実から、当該ウェブサイト内のデータを含み、情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることが推認される場合に、この措置を回避して、クローラにより当該ウェブサイト内に掲載されている多数のデータを収集することにより、AI学習のために当該データベースの著作物の複製等をするパターン
(ⅰ) パターン1
このうちパターン1については、改正前47条の7の但書に該当する行為であって、情報解析用DB著作物の複製として30条の4柱書但書に該当することは明らかです。
一方、パターン2及びパターン3は、一言で言うと「理論的にはありえるが、発生する可能性がほぼないケース」と考えています。
詳細はブログ記事「文化庁「AIと著作権に関する考え方について(素案)令和6年1月15日時点版」の検討」をご参照下さい。
このブログ記事に書いたように、「考え方」「(ウ)」「(エ)」(「考え方」24頁~27頁)の部分については、その前身となる「考え方(素案)」において既に記載がされていました。
私は、ブログ執筆当時、当該「考え方(素案)」に対して、パターン2及びパターン3のような「理論的にはありえるが、発生する可能性がほぼないケース」を「考え方」に記載すると、権利者(特に報道機関)がこの部分を拡大解釈して権利行使する可能性が高まることから、削除した方が良いと述べたのですが、残念ながら、そのまま残ってしまいました。
残ってしまった以上、仕方がないのですが、繰り返しになりますが、パターン2及びパターン3については、権利者(報道機関)にとって、「考え方」の記載を根拠に著作権侵害を主張することは非常に難しいと考えます。
(ⅱ) パターン2
パターン2で権利者(報道機関)が著作権侵害を主張する場合、主張立証しなければならないのは以下の事実です。
▼ 自社が情報解析用DB著作物をAPIを通じて提供していること
まず、単なるDBを提供しているだけではこの要件を満たしません。
後述するように、情報解析用DB著作物以外についてのライセンス市場がある場合であっても、当該DBを情報解析の対象とすることは30条の4柱書但書に該当しないからです。
また、仮に当該DBがDB著作物だとしても、当該DB著作物は「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物」(情報解析用DB著作物)でなければなりません。
たとえば、印刷用やウェブサイトに利用するためのイラストや画像で構成されるDB著作物については、それを情報解析に利用したとしても、当該DB著作物の市場を害することはないため、30条の4本文但書には該当しないと考えられます3「AIと著作権法」 座談会・奥邨先生発言(231頁)は「例えば,一般的な印刷用とかウェブサイトの挿絵用とかでライセンスされているフォトストックのデータベースだと著作物の種類はデータベースでも, 用途は観賞用,利用態様は,情報解析用機器で全部複製するという当てはめになります。これはもともと、柱書本文がやってもいいよと書いてあることをやっているだけなので,不当に害する余地はない,大丈夫じゃないかなと私は思います。」とする。 。要するにDB著作物であっても、「情報解析に使おうと思えば使える」だけでは足りず、「大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物」である必要があるのです4前田健「⽣成AIにおける学習⽤データとしての利⽤と著作権」(有斐閣オンライン)脚注16。
報道機関の提供している記事DBは、通常は「ある一定の期間の記事を網羅的に収録したDB」であると思われます。
その場合、そもそも「情報の選択」についての創作性がないことから、DB著作物、ましてや情報解析用DB著作物には該当しない可能性が高いでしょう。
▼ AI開発者がウェブ上の個別の記事を集積した結果、権利者が販売している情報解析用DB著作物の創作的表現部分を利用するに至ったこと
また、パターン2で著作権侵害が認められるには「AI開発者がウェブ上の個別の記事を集積した結果、権利者が販売している情報解析用DB著作物の創作的表現部分を利用するに至ったこと」が必要です。
つまり、AI開発者が個別の記事を集積してDB(学習用データセット)を生成したとしても、それが権利者が販売している情報解析用DB著作物の創作的表現部分を利用していなければ(異なるDB、あるいは異なるDB著作物であれば)著作権侵害にはなりません。
そして、報道機関の提供している記事DBが情報解析用DB著作物に該当する可能性があるとすると、「世の中のありとあらゆる事実関係の中から、報道に値する事実関係を選択した」という点に「情報の選択」における創作性が認められる場合ではないかと思われます5ただし、そう考えるとしても、他の新聞社も同様の事実関係を報道していればそのような「情報の選択」についての創作性はない。
もっとも、AI開発者は、AI開発のために複数の報道機関のニュース記事や他のWEB上の文章をまとめて大規模に収集するのが通常ですから、1つの報道機関だけの、かつ当該報道機関のみが報道しているニュースのみをあえて対象にして収集して学習に用いることはほぼ考えられません。
そのように、AI開発者が、複数の報道機関のニュース記事や他のWEB上の文章をまとめて大規模に収集して学習に用いた場合、仮にある報道機関の情報解析用DB著作物において、記事の選択に創作性が認められるとしても、当該創作的表現を利用したことにはならず、当該情報解析用DB著作物の著作権侵害には該当しません。
▼ まとめ
つまり、パターン2において著作権侵害に該当するのは、ウェブサイトに閲覧用に掲載された記事等のデータをAPIを経由せずに収集するAI開発者が、あえて「情報解析用DB著作物」と同じ「情報の選択の創作性」を有するDBの著作物を作成するという極めて「偶然」の場合のみです。
このようなことは現実的にはほぼあり得ないでしょう。
そもそも、AI開発者としては、そのような行為をあえて行う必要性が全くないからです。
(ⅲ) パターン3
パターン3の場合「将来販売される可能性がある情報解析用DB著作物」の将来販路が阻害されることが必要ですが、そのような事態は、パターン2以上に「現実的にはあり得ない」と言って良いと考えます。
なぜなら、パターン2の場合には、「現実に販売されている情報解析用DB著作物」がある場合において、当該情報解析用DB著作物の創作劇表現部分を利用する行為を対象にしていましたが、パターン3の場合には「将来販売される可能性がある(言い換えれば、まだ世の中に存在していない)情報解析用DB著作物」を対象とするものだからです。
このように「将来販売される可能性がある情報解析用DB著作物」の将来販路が阻害されることを理由に個々のウェブ記事の収集行為が30条の4柱書但書に該当するという「考え方」の解釈は、実質的には、現時点では存在しない、将来発生する可能性のある著作物についての著作権侵害を認める解釈と言ってよいと思います。
確かに、著作物自体が未だに発生しておらず、かつ侵害行為も行われていない段階での予防請求を認めた裁判例は存在します(東京地判平5・8・30知的裁集25巻2号380頁(ウォール・ストリート・ジャーナル事件)。
この決定は、米国において日刊新聞 The Wall Street Journal(「本件新聞」)を継続して発行する X(債権者・被控訴人)が、わが国において本件新聞の記事を抄訳して紙面構成に対応して配列した文書(以下「本件文書」という)を募集した会員に作成・頒布する Y(債務者・控訴人)に対し、本件文書の作成・頒布は、債権者の本件新聞について有する編集著作権を侵害するとして申し立てた本件文書の作成・頒布の差止仮処分が認められた事案です。
この事件では、将来作成される著作物の編集著作権に基づく差止めの可否等が問題となり、差し止めが認められました。
しかし、この事件は、過去に具体的な編集著作権侵害行為が継続して行われていたことを根拠として、将来的に同様の著作権侵害が発生する可能性が相当高度であることを認め、その結果差止請求を認めたものにすぎず、一般化することはできません。
現に同裁判例については、「被侵害著作物が未だ存在しない場合の差止請求は極めて例外的であり,同判決は一般化できないであろう」とされています6中山信弘『著作権法 第3版』(有斐閣、2020年)727頁 。
したがって、同裁判例を根拠として「将来発生する可能性のある著作物についての潜在的販路の阻害」行為が30条の4柱書但書に該当するとすることはできないと考えます。
ウ 海賊版等の権利侵害複製物
AI開発者が、海賊版等の権利侵害複製物を開発・学習段階で収集・利用した場合、著作権侵害責任を問われることがあり得ますが、それが「開発・学習行為」に関する責任なのか「生成・利用行為」に関する責任なのかは明確に区別する必要があります。
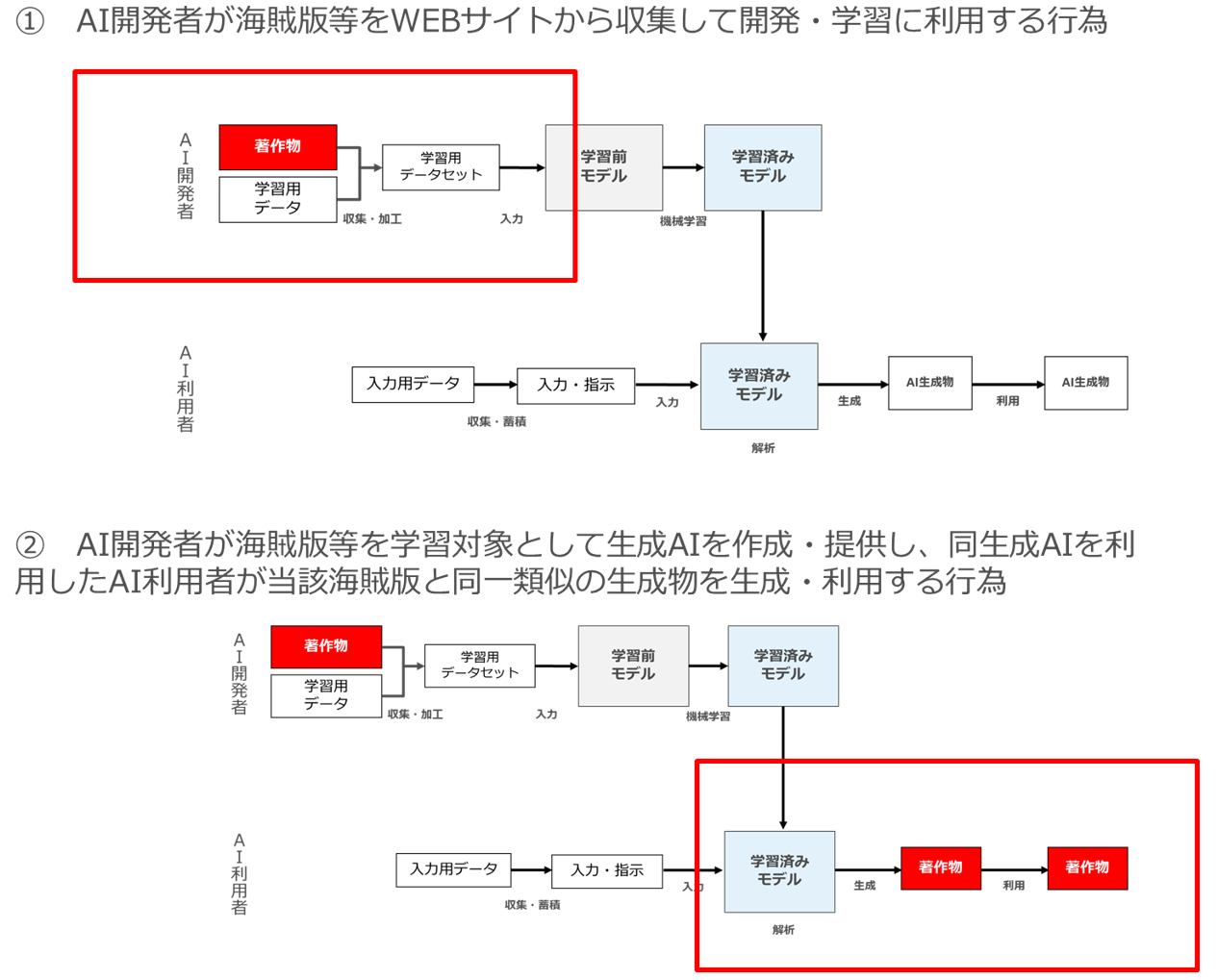
① 開発・学習段階においてAI開発者が海賊版等をWEBサイトから収集して開発・学習に利用する行為
諸外国の情報解析規定においては、情報解析の客体が適法にアクセスしたものであることを条件とした立法例が多く(英国法、欧州DSM指令、スイス法、シンガポール法)、そのような立法の下では、AI開発者が海賊版等をWEBサイトから収集して開発・学習に利用した場合、当該開発・学習行為自体が著作権侵害になります。
一方、日本国著作権法の30条の4にはそのような条件が設けられていないことから、AI開発者が海賊版等をWEBサイトから収集して開発・学習に利用する行為についても同条が適用されて原則として適法となります7「AIと著作権法」上野先生66頁。
「考え方」やパブコメにおいても、AI開発者が海賊版等をWEBサイトから収集して開発・学習に利用する行為が30条の4柱書但書に該当して著作権侵害になるという記載はありません8 ただし、「考え方」28頁には「AI 開発事業者や AI サービス提供事業者においては、学習データの収集を行うに際して、海賊版を掲載しているウェブサイトから学習データを収集することで、当該ウェブサイトへのアクセスを容易化したり、当該ウェブサイトの運営を行う者に広告収入その他の金銭的利益を生じさせるなど、当該行為が新たな海賊版の増加といった権利侵害を助長するものとならないよう十分配慮した上でこれを行うことが求められる。」との記載があり、パブコメ266等においては「このような助長行為があった場合、個別具体的な事案によっては、侵害行為の幇助となる場合もあると考えられます。」と記載されている。。
また、文化庁小委員会でも各委員から以下のような指摘がなされています(第4回早稲田委員発言・澤田委員発言)。
各委員発言中の③は「学習のための複製を防止する技術的な措置が講じられているにも関わらず、これを回避して著作物をAI学習のため複製することは、本ただし書に該当するか。」の論点であり、④は「海賊版のような権利侵害複製物をAI学習のため複製することは、本ただし書に該当するか。」の論点です。
▼ 早稲田委員
それから、エの③のところですけれども、これも非常に難しいところではありますけれども、権利制限規定を技術的な措置で適用がないようにするという、それ自体は権利制限規定が強行法規、強行規定でなくて任意規定というように、解釈されるのだと思いますので、それはいいと思うんですけども、さらにそれを回避して複製した場合はどうなのかというのは、これはなかなか難しい問題ではあるとは思いますが、例えば47条の5のインターネット検索のURLを提示するようなところでは、それなりにそういう技術については、それを回避してはいけないような規定になっておりますので、そういう規定がない限りはちょっとこれもただし書には該当しないんじゃないかなと個人的には考えております。
そうしますと④の海賊版のような権利侵害複製物について、これも著作権者の非常に御懸念があるということは重々承知ではございますけれども、単に情報解析をするということであれば、海賊版であっても情報解析をするという目的には非享受目的であれば該当するのではないかなと思っておりますので、これもただし書には該当しないのではないかなと個人的には思っております。
▼ 澤田委員
③、④に関しまして、先ほど早稲田委員からも少し御指摘がありましたけれども、③の技術的な措置の回避については、これまでの著作権法の中でも例えば30条の私的複製の例外や47条の5のrobot.txtの例で、回避をしたら権利制限の対象外という規定がわざわざ設けられています。④の海賊版に関しても、30条や47条の5の1項のただし書で違法なものを用いるケースは権利制限の対象外ということは明記されているところです。
そのため、法体系全体の整合性からすると、特にそういった明記のない30条の4については、③、④の事情があるという一事をもってただし書に当たらない(柿沼注:文脈からすると「ただし書に当たる」の誤記ではないかと思われます)ということにはならないのではないかと考えております。
② AI開発者が海賊版等を学習対象として生成AIを作成・提供し、同生成AIを利用したAI利用者が、生成・利用段階で当該海賊版と同一類似の生成物を生成・利用する行為
一方、①とは別の問題があります。
生成・利用段階の問題として、AI開発者が海賊版等を学習対象として生成AIを作成・提供し、同生成AIを利用したAI利用者が当該海賊版と同一類似の生成物を生成・利用した場合に、AI開発者が同生成・利用についてどのような責任を負うか、という問題です。
この点については、物理的にはAI利用者が海賊版と同一類似の生成物を生成・利用していることになるため 、AI利用者が行為主体として著作権侵害責任を負いますが、一定の場合には、当該生成・利用に用いられたAIの開発者・サービス提供者が同生成・利用による著作権侵害行為の規範的な主体として責任を負う場合があり得ます。
考え方28頁の以下の記載はその点を説明したものです。
○ 特に、ウェブサイトが海賊版等の権利侵害複製物を掲載していることを知りながら、当該ウェブサイトから学習データの収集を行うといった行為は、厳にこれを慎むべきものである。この点に関して、生成・利用段階においては、後掲(2)キのとおり、既存の著作物の著作権侵害が生じた場合、AI 開発事業者又は AI サービス提供事業者も、当該侵害行為の規範的な主体として責任を負う場合があり得る。この規範的な行為主体の認定に当たっては、当該行為に関する諸般の事情が総合的に考慮されるものと考えられる。
○ AI 開発事業者や AI サービス提供事業者が、ウェブサイトが海賊版等の権利侵害複製物を掲載していることを知りながら、当該ウェブサイトから学習データの収集を行ったという事実は、これにより開発された生成 AI により生じる著作権侵害についての規範的な行為主体の認定に当たり、その総合的な考慮の一要素として、当該事業者が規範的な行為主体として侵害の責任を問われる可能性を高めるものと考えられる(AI 開発事業者又は AI サービス提供事業者の行為主体性について、後掲(2)キも参照)。
この記載は「生成・利用段階においては」や「これにより開発された生成 AI により生じる著作権侵害についての」とあることから明らかなように、先ほどの①の問題、すなわち開発・学習段階におけるAI開発事業者における海賊版の収集・利用行為が著作権侵害に該当するという記述ではありません9パブコメに寄せられた意見の中には「海賊版をAI学習のために複製することについて、30条の4柱書但書に該当して許容されないものと整理すべき」という意見が権利者側から複数寄せられているが(パブコメ256,257,262、277,278)、文化庁はそのような整理をしていない。。
あくまで、生成・利用段階において学習に用いられた海賊版と同一・類似のAI生成物が生成された場合に、AI開発者またはAIサービス提供者が当該生成・利用について行為主体として責任を問われる場合がある、つまり生成・利用段階に関する②についての記述です。
「考え方」も強調するように、海賊版に対する対策が重要であることは言うまでもありません。もっとも、繰り返しになりますが、開発・学習段階の①の問題と、生成・利用段階の②の問題を明確に区別することが必要でしょう。
また、「考え方」28頁には海賊版等の権利侵害複製物について、以下の記載があります。
○ この点に関して、こうした海賊版等の権利侵害複製物を掲載するウェブサイトからの学習データの収集は、少量の学習データを用いて、学習データに含まれる著作物の創作的表現の影響を強く受けた生成物が出力されるような追加的な学習を行うことを目的として行われる場合もあると考えられる。このような追加的な学習を行うことを目的として、学習データの収集のため既存の著作物の複製等を行う場合、開発・学習段階においては上記イ(イ)のとおり、具体的事案に応じて、学習データの著作物の創作的表現を直接感得できる生成物を出力することが目的であると評価される場合は、享受目的が併存すると考えられるが、これに加えて、生成・利用段階においては、これにより追加的な学習を経た生成 AI が、当該既存の著作物の創作的表現を含む生成物を生成することによる、著作権侵害の結果発生の蓋然性が認められる場合があると考えられる。
○ そのため、海賊版等の権利侵害複製物を掲載するウェブサイトからの学習データの収集を行う場合等に、事業者において、このような、少量の学習データに含まれる著作物の創作的表現の影響を強く受けた生成物が出力されるような追加的な学習を行う目的を有していたと評価され、当該生成 AI による著作権侵害の結果発生の蓋然性を認識しながら、かつ、当該結果を回避する措置を講じることが可能であるにもかかわらずこれを講じなかったといえる場合は、当該事業者は著作権侵害の結果発生を回避すべき注意義務を怠ったものとして、当該生成 AI により生じる著作権侵害について規範的な行為主体として侵害の責任を問われる可能性が高まるものと考えられる。
この記載には2つの内容が含まれています。
1つ目の○の前半部分(「○ この点に関して~享受目的が併存すると考えられるが」の部分については、①の開発・学習行為についての記述です。
要するに、海賊版等を掲載したサイトから、学習データに含まれる著作物の創作的表現の影響を強く受けた生成物を出力させる目的での学習は享受目的が併存し、30条の4が適用されない、という内容です。
もっとも、これは学習対象著作物が海賊版だから30条の4が適用されないという説明ではなく、学習目的が表現出力目的だから30条の4が適用されないと説明しているに過ぎません。
その後に引き続く部分は、生成・利用段階において学習に用いられた海賊版と同一・類似のAI生成物が生成された場合に、AI開発者またはAIサービス提供者が当該生成・利用について行為主体として責任を問われる場合がある、つまり先ほどの②に関する記述です。
以上を前提に、海賊版等の権利侵害複製物に関して「考え方」に記載されている内容をまとめると以下のとおりとなります。
① 開発・学習段階の行為について
開発・学習段階においてAI開発者が海賊版等の権利侵害物をWEBサイトから収集して開発・学習に利用する行為については30条の4が適用され、原則として適法である10「考え方」29頁脚注36参照。
ただし、少量の学習データを用いて、学習データに含まれる著作物の創作的表現の影響を強く受けた生成物が出力されるような追加的な学習を行うことを目的として海賊版等の権利侵害複製物を掲載するウェブサイトからの学習データの収集を行う場合は、表現出力目的がある(享受目的併存)ため、30条の4が適用されず、それ以外の権利制限規定が適用されなければ違法となる。② 生成・利用段階の行為について
AI開発者が海賊版等を学習対象として生成AIを作成・提供し、同生成AIを利用したAI利用者が、生成・利用段階において当該海賊版と同一類似の生成物を生成・利用する行為について、以下のような事実がある場合には、AI開発者が規範的行為主体として責任を問われる可能性が高まる。
(ⅰ) AI 開発事業者や AI サービス提供事業者が、ウェブサイトが海賊版等の権利侵害複製物を掲載していることを知りながら、当該ウェブサイトから学習データの収集を行ったという事実
(ⅱ) 少量の学習データを用いて、学習データに含まれる著作物の創作的表現の影響を強く受けた生成物が出力されるような追加的な学習を行うことを目的として海賊版等の権利侵害複製物を掲載するウェブサイトからの学習データの収集を行う
(ⅲ) 当該生成 AI による著作権侵害の結果発生の蓋然性を認識している
(ⅳ) 当該結果を回避する措置を講じることが可能であるにもかかわらずこれを講じなかった
上記記載は、基本的にそのとおりだと思いますが、②(ⅰ)は若干疑問です。
「海賊版であることを知らなかった場合にはAI開発事業者が規範的行為主体としての責任を問われる可能性が低くなる」、つまり「知っていること」が必要条件であるとは言えると思いますが、単に「ウェブサイトが海賊版等の権利侵害複製物を掲載していることを知りながら、当該ウェブサイトから学習データの収集を行った」というだけで、AI開発事業者の規範的行為主体としての責任を問われる可能性が高まるとまでは言えないと考えます11 現に、考え方36頁の「キ 侵害行為の責任主体について」にも、AI開発事業者やAIサービス提供者が規範的行為主体として著作権侵害の責任を負う場合が記載されているが、その部分には上記(ⅰ)の要素の記載はない。。
また、この「海賊版等の権利侵害物を学習対象とした場合に30条の4柱書但書に該当するか」の論点との関係では、画像生成AI等のコンテンツ生成AIと、LLMのようなテキスト生成AIとを明確に区別することも重要です。
確かに、コンテンツ生成AIの場合、「考え方」に示されている要素を満たす、すなわち学習対象著作物の表現出力目的がある収集・学習行為(開発・学習段階)や、学習対象著作物と類似・同一のAI生成物が生成・利用される(生成・利用段階)ことはあり得ます。
一方、
したがって、LLMを開発するために、ウェブ上の大量のデータをクローリングしたり、公開されている学習用データセットを複数利用したところ、その一部の学習用データセットの中に権利侵害複製物が含まれていた場合であっても(あるいは、収集後事後的に権利者から警告を受けて、学習用データセットの中に権利侵害複製物が含まれていることを知ったとしても)、当該開発・学習行為が30条の4柱書但書により違法となることはほぼあり得ないと考えます。
エ まとめ
以上、本記事では、「学習対象による制限」のうち「イ 情報解析に活用できる形で整理したデータベースの著作物」と「ウ 海賊版等の権利侵害複製物」について検討しました。
「イ 情報解析に活用できる形で整理したデータベースの著作物」については、実際にどのような場合が「情報解析用DB著作物」の複製に該当するかは慎重な検討が必要です。
また「ウ 海賊版等の権利侵害複製物」については、「開発・学習段階」の問題か「生成・利用」の問題なのかの区別が重要となります。
【第4回記事】へ続く
【脚注】
- 1ただし、大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為」については、30条の4柱書但書の問題ではなく、当該データベース著作物の本来的利用であるとして享受目的併存により30条の4が適用されない、という説もある(前田健「生成AIの利用が著作権侵害となる場合」(法学教室№523・30頁、「AIと著作権」座談会232頁)
- 2なお「考え方」25頁脚注28には「この点に関して、インターネット上のウェブサイトに掲載されたデータについては、AI 学習のための複製を行うクローラによるウェブサイト内へのアクセスが、後述するウェブサイト内のファイル”robots.txt”への記述により制限されていない場合、「(大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が)販売されている場合」に該当しないことを推認させる要素となるものと考えられる」との記載がある。この記載内容は合理的であるが、このような技術的措置が講じられていない事実は、パターン3における「情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があること」に該当しないことを推認させる要素にもなると思われる(パブコメ191参照)。
- 3「AIと著作権法」 座談会・奥邨先生発言(231頁)は「例えば,一般的な印刷用とかウェブサイトの挿絵用とかでライセンスされているフォトストックのデータベースだと著作物の種類はデータベースでも, 用途は観賞用,利用態様は,情報解析用機器で全部複製するという当てはめになります。これはもともと、柱書本文がやってもいいよと書いてあることをやっているだけなので,不当に害する余地はない,大丈夫じゃないかなと私は思います。」とする。
- 4前田健「⽣成AIにおける学習⽤データとしての利⽤と著作権」(有斐閣オンライン)脚注16
- 5ただし、そう考えるとしても、他の新聞社も同様の事実関係を報道していればそのような「情報の選択」についての創作性はない
- 6中山信弘『著作権法 第3版』(有斐閣、2020年)727頁
- 7「AIと著作権法」上野先生66頁
- 8ただし、「考え方」28頁には「AI 開発事業者や AI サービス提供事業者においては、学習データの収集を行うに際して、海賊版を掲載しているウェブサイトから学習データを収集することで、当該ウェブサイトへのアクセスを容易化したり、当該ウェブサイトの運営を行う者に広告収入その他の金銭的利益を生じさせるなど、当該行為が新たな海賊版の増加といった権利侵害を助長するものとならないよう十分配慮した上でこれを行うことが求められる。」との記載があり、パブコメ266等においては「このような助長行為があった場合、個別具体的な事案によっては、侵害行為の幇助となる場合もあると考えられます。」と記載されている。
- 9パブコメに寄せられた意見の中には「海賊版をAI学習のために複製することについて、30条の4柱書但書に該当して許容されないものと整理すべき」という意見が権利者側から複数寄せられているが(パブコメ256,257,262、277,278)、文化庁はそのような整理をしていない。
- 10「考え方」29頁脚注36参照
- 11現に、考え方36頁の「キ 侵害行為の責任主体について」にも、AI開発事業者やAIサービス提供者が規範的行為主体として著作権侵害の責任を負う場合が記載されているが、その部分には上記(ⅰ)の要素の記載はない。












