人工知能(AI)、ビッグデータ法務
第三者がライセンス違反により生成した学習済みモデルに追加学習させて二次モデルを生成する行為は違法か
この記事は「AI法務Q&A~AIの生成・保護・活用に関する法務Q&A~」のうちのQ&Aの1つです。
Q&Aの全体像については「AI法務Q&A~AIの生成・保護・活用に関する法務Q&A~」をご参照ください。
Contents
■ 質問
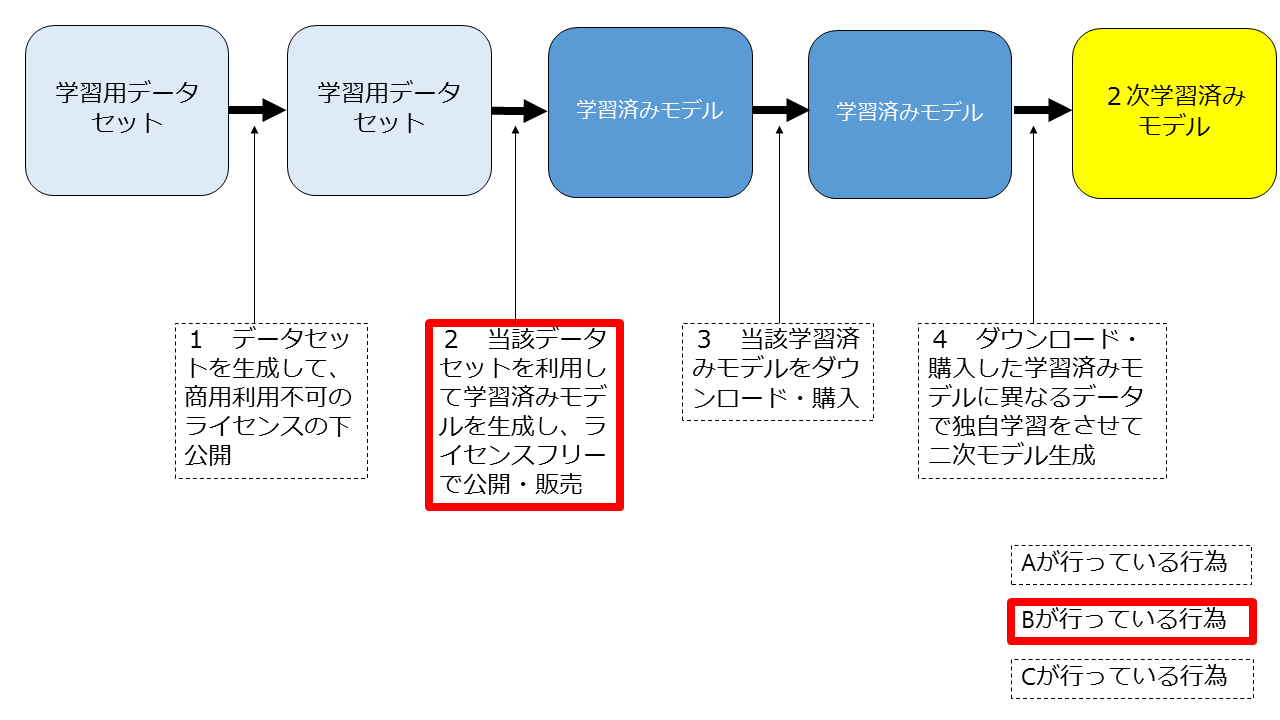
Aがデータセットを生成し、商用利用不可のライセンスの下で公開したところ、Bが当該データセットを利用して学習済みモデルを生成してライセンスフリーで公開・販売した。Cが当該モデルをダウンロードして独自データを用いて学習させて2次モデルを生成する行為は適法か。
■ 結論
Cの行為は適法と思われます。
■ 説明
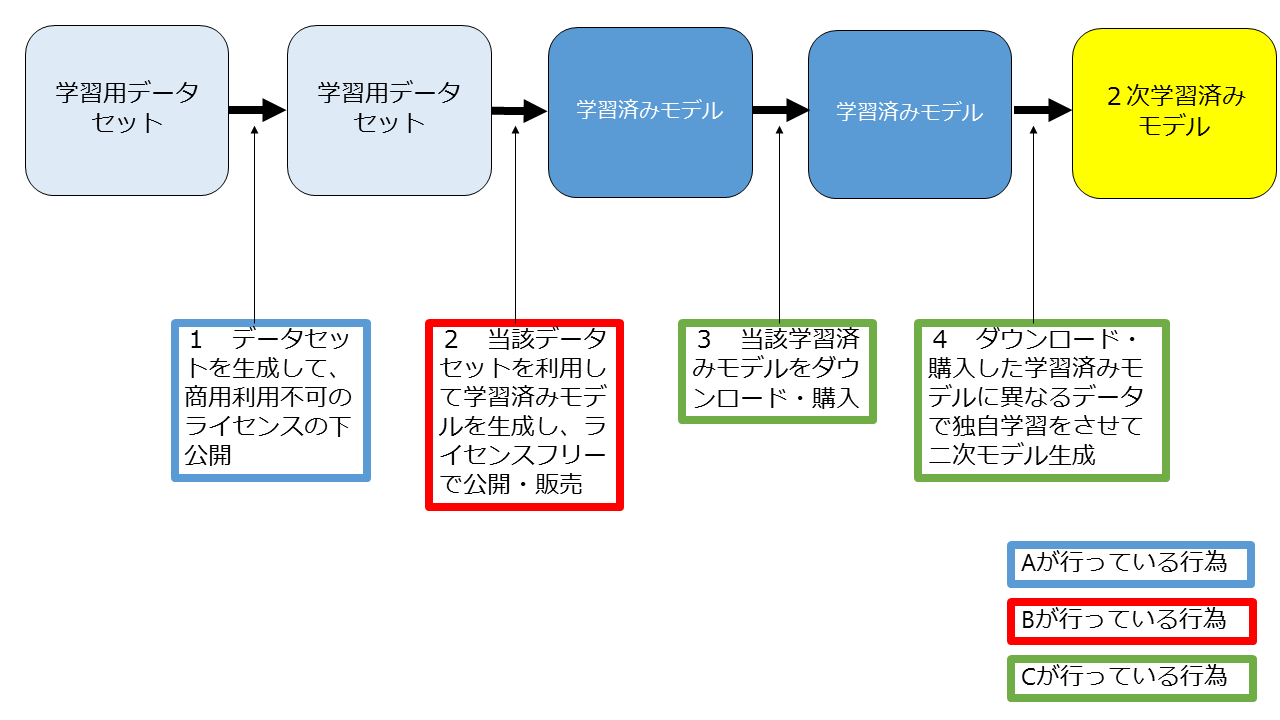
上記の図にしたがって説明していきます。
ここでは、Aが生成したデータセットが「データベースの著作物」に該当する場合を前提とします(該当しない場合は、Cの行為が著作権侵害になることはありません)。
1 Aが生成したデータセットを用いてBが学習済みモデルを生成し、公開・販売する行為
著作物であるデータセットを用いて学習済みモデルを生成するBの行為が、当該データセットの「複製」や「翻案」に該当するかがまず問題となります。
「複製」や「翻案」に該当するのであれば、Bが生成した学習済モデルは、データセットの「複製物」「翻案物」となり、A(及びB)が学習済モデルについて著作権を有することになるからです。
「複製」とは「印刷、写真、複写、録音、録画その他の方法により有形的に再製すること」(著作権法2条1項15号)で、「翻案」とは簡単にいうと「ある著作物の表現上の本質的な特徴の同一性を維持しつつ,具体的表現に修正,増減,変更等を加える行為」(最高裁江差追分事件)です。
しかし、通常は、生成された学習済みモデルの中には生データや学習用データセットの痕跡は全く残っていません。そのような場合、学習済みモデル生成行為は「複製」でも「翻案」でもないことになります(ちなみに、データセットのデータ構造がほぼそのままモデルの中に残るモデル生成方法もあるようです。そのような場合には別途検討が必要となります)。
また、そもそも学習済みモデルに著作物性を認めるのは非常に難しいと思います。
まず学習済みモデルは機械(プログラム)が自動的に生成しているものですから、人間の「創作」とは言えない可能性が高いでしょう。
さらに、たとえばニューラルネットワークの手法で生成された学習済みモデルは「ネットワークの構造+各リンクの重み」であり、「大量の数値の列」です。
このようなものが、著作権法における「データベースの著作物」や「プログラム」あるいはその他の著作物に該当するかというと、大いに疑問があります。
したがって、Bが生成した学習済みモデルはAまたはBが著作権を持つ著作物ではないということになると思われます。
以上からすると、結局のところ、BがAの学習用データセットを元に学習済みモデルを生成する行為は「複製」でも「翻案」でもなく、学習済みモデルは学習用データセットの「複製物」でも「翻案物」でもないということになります。
ただし、「商用利用不可」というライセンスの下公開されているデータセットを利用して学習済モデルを生成して公開・販売しているので、Bが行っている行為は、Aとの間のライセンス違反には該当します。
2 Bが公開した学習済みモデルをダウンロード・購入するCの行為

次に、Bが公開した学習済みモデルをダウンロード・購入するCの行為について検討します。
先ほど述べたように、「学習済みモデル」は A(またはB)が著作権を持つ著作物ではありません(ちなみに、ライセンス違反行為によって生成された学習済みモデルであっても、学習済みモデルが著作物か否かの判断には影響を及ぼしません)。
確かに、この学習済みモデルは、Aのデータセットを元にBがライセンス違反行為によって生成した学習済みモデルなのですが、Bの行為は単にAとBとの間の「ライセンス違反(契約違反)」というに過ぎません。
ライセンス(契約)は契約を締結した当事者(この場合はAとB)にしか効果は及びませんので、Cにはライセンス違反の問題は生じません。
したがって、結論的にはBが公開した学習済みモデルをダウンロード・購入するCの行為はAまたはBの著作権侵害にもならないし、Aとのライセンス違反にもならない、つまり適法ということになります。
3 ダウンロード・購入した学習済みモデルに異なるデータで独自学習をさせて二次モデルを生成するCの行為
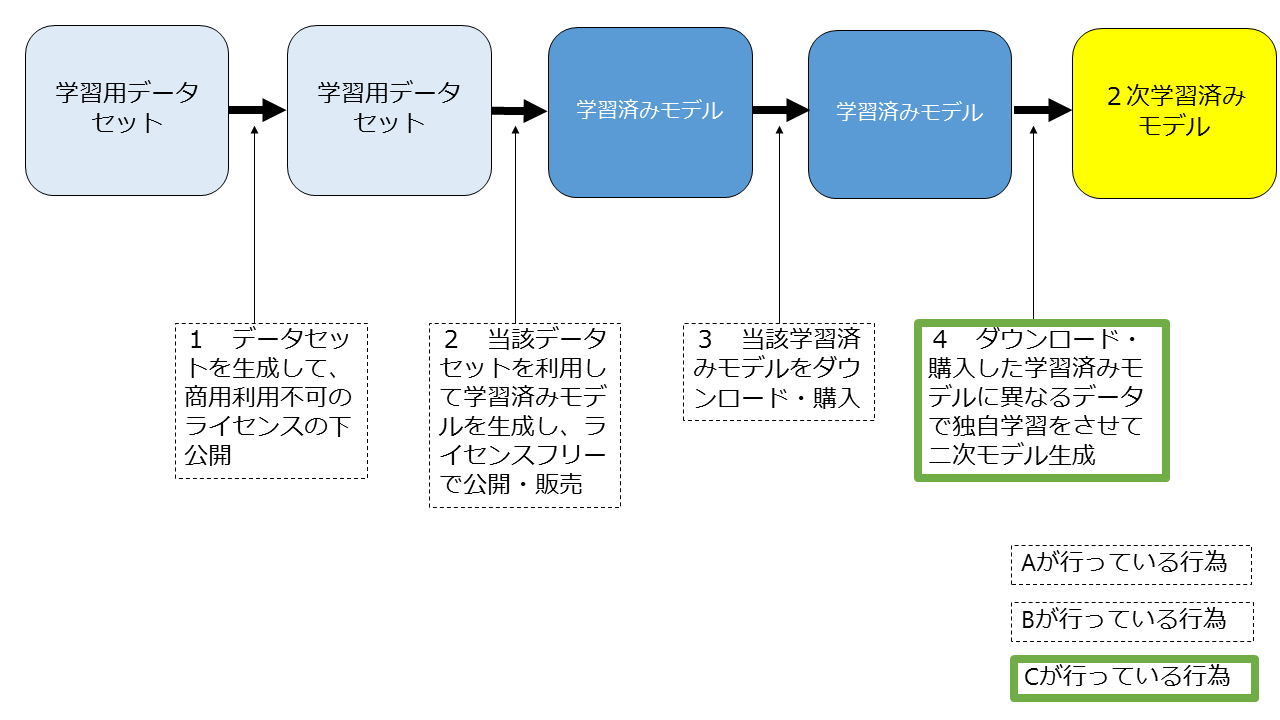
学習済みモデルが著作物でない以上、当該学習済みモデルを用いて二次モデルを生成する行為は著作権侵害ではありませんし、先ほど述べたようにAのライセンスの効果はCには及びませんので、ライセンス違反にもなりません。
したがってダウンロード・購入した学習済みモデルに異なるデータで独自学習をさせて二次モデルを生成するCの行為は適法ということになります。
なお、その他のQ&Aについては「AI法務Q&A~AIの生成・保護・活用に関する法務Q&A~」をご参照ください。
【注意事項】
AIと法律・知的財産権の領域は、技術の進歩に法律が追いつけていないのが現状です。そのため、各論点についてまだ確定した見解はなく、しかもある時点で正しかった見解が1ヶ月後には間違っている、ということも容易に起こりえます。
したがって、本Q&Aの内容の正確性を保証することはできませんし、必ず最新の内容にアップデートされているわけではないことはご了承ください。
(弁護士柿沼太一)