人工知能(AI)、ビッグデータ法務
「生成AIと著作権侵害」の論点についてとことん検討してみる

Contents
- 1 はじめに~この議論が影響する範囲はかなり大きい~
- 2 1 議論の前提
- 3 2 生成AIを作ること(機械学習)と著作権侵害
- 4 3 生成AIを利用してAI生成物を生成・利用することと著作権侵害
- 4.1 (1) 分析の視点
- 4.2 (2) 5つのパターン分け
- 4.3 (3) 生成AIに既存著作物を入力しているだけであり、生成AIによる処理結果として類似著作物が生成されていないパターン(パターン1)
- 4.4 (4) 既存著作物を入力し、同既存著作物と類似するAI生成物を生成するパターン(パターン2)
- 4.5 (5) 既存著作物を入力し、同既存著作物と類似するAI生成物を生成して配信等を行うパターン(パターン3)
- 4.6 (6) 非著作物等を入力し、既存著作物と類似するAI生成物を生成するパターン(パターン4)
- 4.7 (7) 非著作物等を入力し、既存著作物と類似するAI生成物を生成し配信するパターン(パターン5)
- 4.8 (8) まとめ
- 4.8.0.1 ・ 生成・利用段階を検討する際には、「著作物の入力行為」「AI生成物の生成行為」「AI生成物の送信行為」の3段階に分けて検討することが必要。
- 4.8.0.2 ・ 具体的には5つのパターンがあり、各パターンにおいて、著作物の利用行為ごとに①類似性と依拠性、②権利制限規定(情報解析、私的利用、検討目的利用等)適用有無を検討する必要がある。
- 4.8.0.3 ・ 「著作物の入力行為」「AI生成物の生成行為」「AI生成物の送信行為」は独立した利用行為であるため、基本的には、個別に適法性を検討すればよいが、それらの行為が連続して行われた場合には、特に「著作物の入力行為」の「享受目的」の併存有無を判断する際に各行為を完全に切り離して検討することができない。すなわち、パターン1、パターン2,パターン3それぞれにおいて、「著作物の入力行為」の「享受目的」の併存有無の判断は異なる。
- 5 4 機械学習×生成・利用と著作権侵害
- 5.1 (1) 分析
- 5.1.0.1 ・ 学習済みモデルの中の学習済みパラメーターは、学習段階において「当該画像を表現するテキスト+画像」によって訓練され「あるテキストが生成段階で入力されると、当該テキストに沿った画像を生成する」という役割を果たす。
- 5.1.0.2 ・ そして、学習済みパラメーターは「ある特定のテキストが生成段階で入力されると、学習段階で当該テキストと共に学習された画像を非常に高い確率で生成する」状態のパラメーターと「ある特定のテキストが生成段階で入力されても、表現の幅の広いバラバラの画像を生成する」パラメーターまで様々なものがある。前者は、いわば「精度の高い」(テキストと画像が一対一対応になっている)パラメーターで、後者は「精度の低い」(1つのテキストに対して多数の画像が対応している)パラメーター。
- 5.1.0.3 ・ 依拠性の議論においては、「学習段階で既存著作物が利用されているか」だけではなく、学習の結果生成された学習済みパラメーターの状態を区別して議論すべき。前者については依拠性が肯定されるが、後者については依拠性は否定される。
- 5.2 (2) 責任主体
- 5.1 (1) 分析
- 6 5 まとめ
はじめに~この議論が影響する範囲はかなり大きい~
「生成AIと著作権侵害」に関する論点は、ざっくりいうと「生成AIを作ること(機械学習)と著作権侵害」「生成AIを利用してAI生成物を生成・利用することと著作権侵害」に分かれます。
この論点には、これまであまり論じられていなかった部分も含まれており、文化庁がセミナーや資料を公開するなど非常に盛り上がっています。
一方、「生成AIと著作権侵害」は、特に画像生成AIに関して論じられることが多いからか、ChatGPTなどの文章生成AIをビジネスに用いることにどのような影響を及ぼすかはあまり認識されていないようにも思います。
しかし、実際には、この論点は、画像生成AIはもちろんのこと、ChatGPTなどの文章生成AIをビジネスに用いることにも大きな影響を及ぼします。
たとば、ビジネスにおいて独自ドメインでの精度向上のために、独自データでファインチューニングや追加学習を行うことが増えてきていますが、この場面においては、まさに「生成AIを作ること(学習)と著作権侵害」が問題となります。「学習」とは、典型的にはモデル内のパラメーターの更新であり、それは事前学習モデルを作る場合でもFTの場合でも区別されないためです。
また、最近では、セマンティック検索のために、他者が著作権を有しているデータを含むデータを適宜分割してベクトル化し、ベクトルデーターベースに格納した上で、LLMへの入力データに利用することが行われるようになりました。
ここで行われていることは「既存著作物を生成AIに入力する」(あるいは入力のために蓄積する)行為であり、「生成AIを利用してAI生成物を生成・配信等することと著作権侵害」が問題となります。仮に「既存著作物を生成AIに入力する」行為を行うだけで(その後類似著作物が生成されていない場合でも)著作権侵害に該当するのであれば、このようなセマンティック検索において他者が著作権を有しているデータを利用する行為についても著作権侵害になる可能性が生じます。
本記事では、「生成AIと著作権侵害」の論点について、これまでの議論を振り返りつつ、令和5年6月19日に文化庁著作権課が開催した令和5年度著作権セミナー「AIと著作権」で用いられた講演資料(以下、当該資料引用する際には「文化庁資料」といいます)を引用しながら、以下の4つに分けて検討していきます(なお、この文化庁のセミナーは大変優れた内容なので、まだ視聴されていない方は是非視聴して下さい)。
1 議論の前提
2 生成AIを作ること(機械学習)と著作権侵害
3 生成AIを利用してAI生成物を生成・利用することと著作権侵害
4 機械学習×生成・利用と著作権侵害
1 議論の前提
生成AIと著作権侵害の論点を検討する前に、議論の前提としていくつか押さえておいていただきたいことがあります。文化庁資料がよくまとまっていますので、適宜引用しながら説明をしていきます。
(1) 全体像
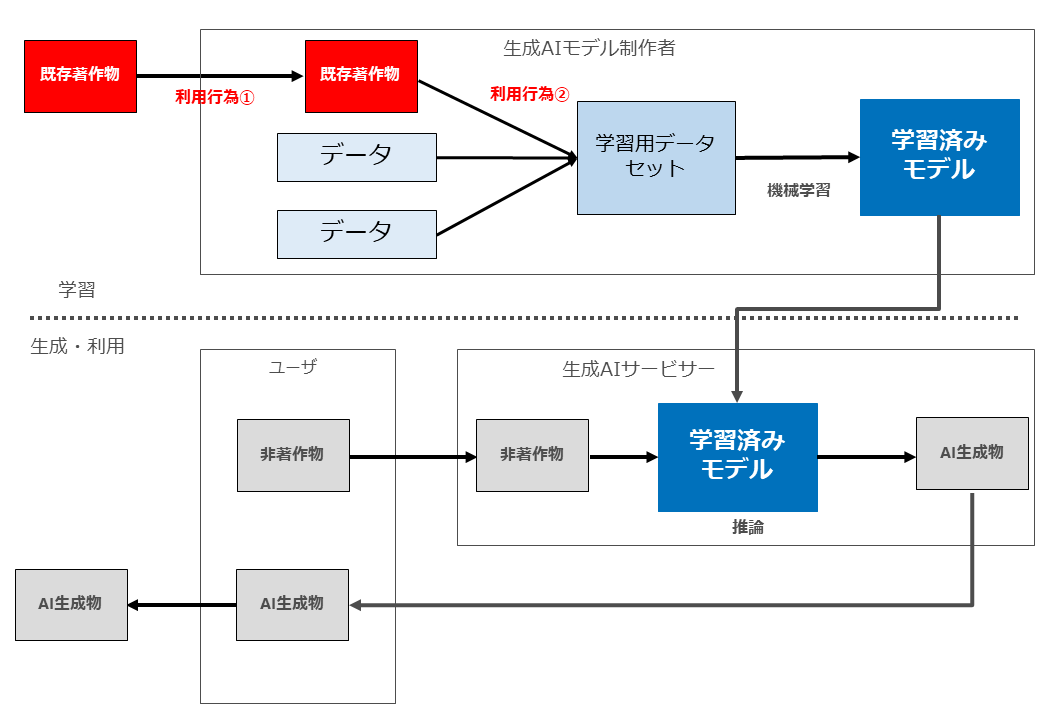
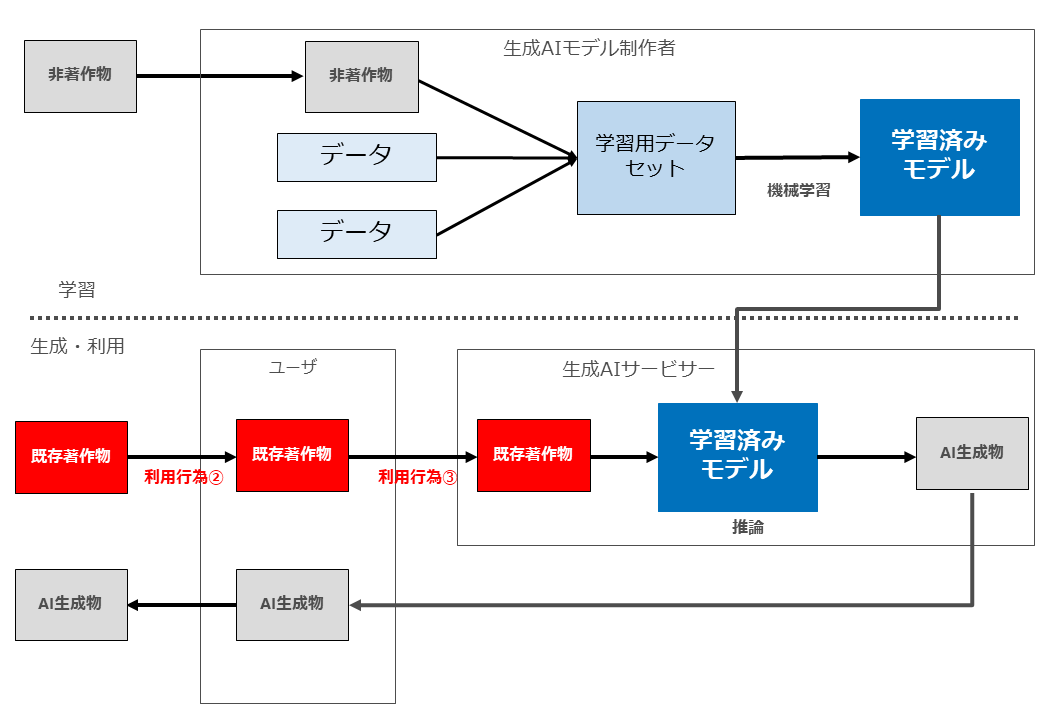
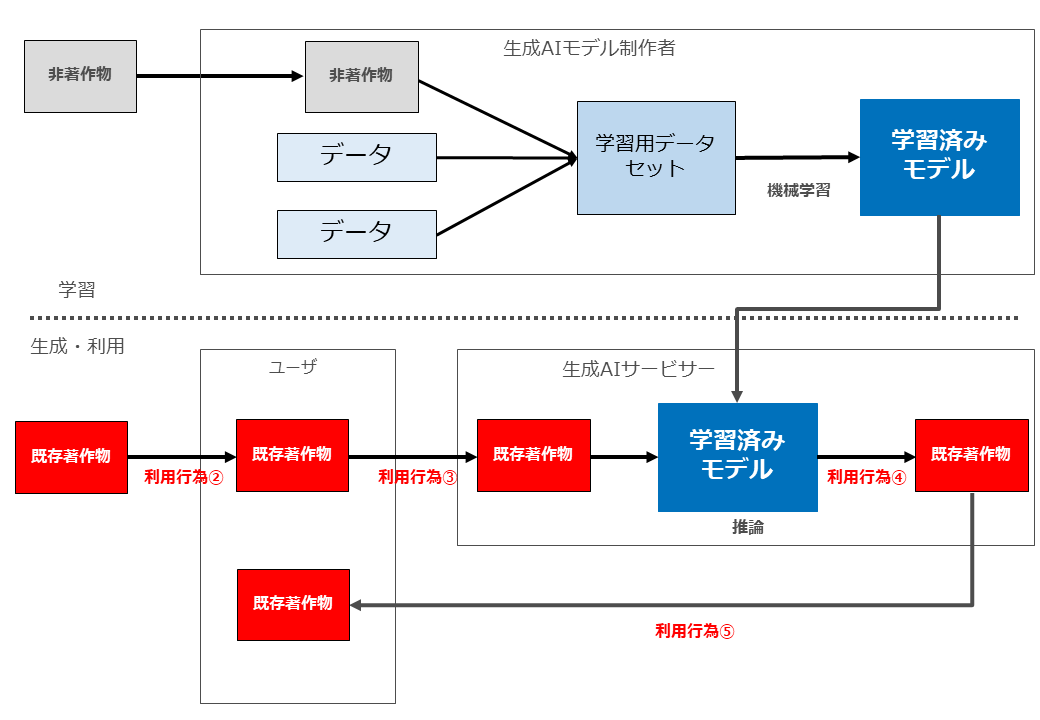
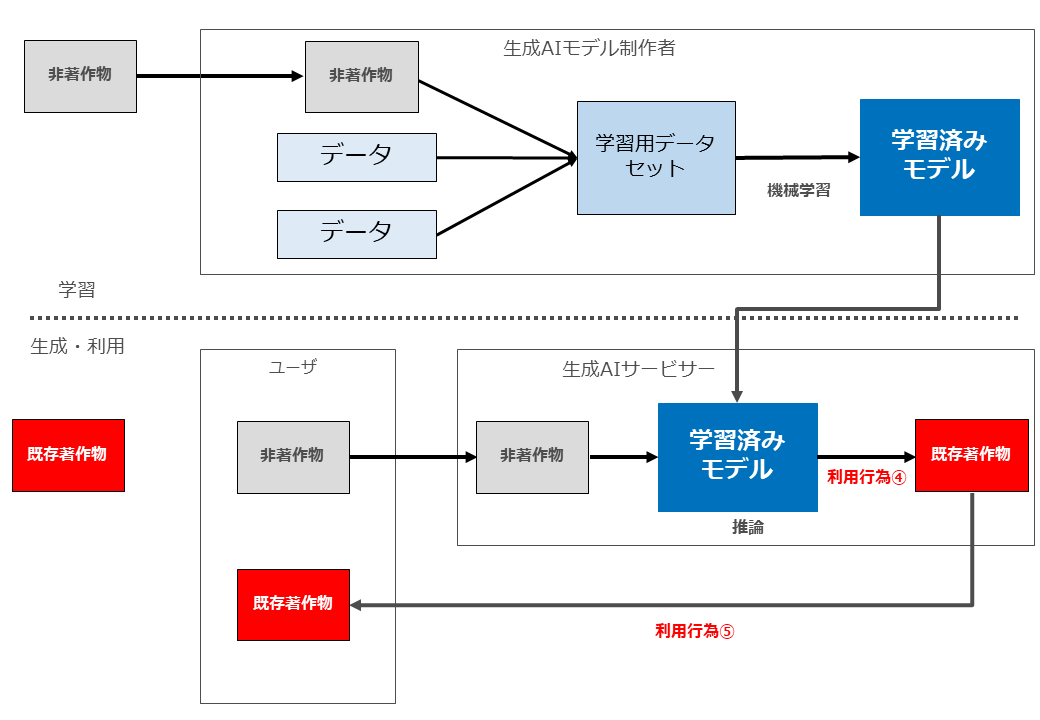
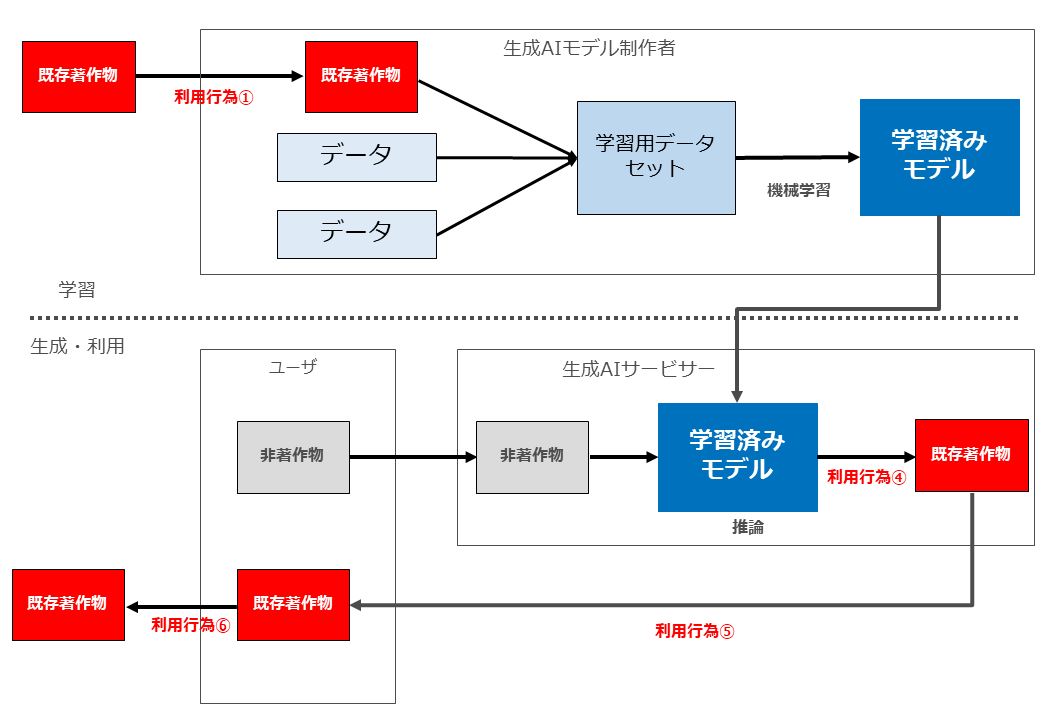
生成AIと著作権侵害が問題となる場面の全体像をお示しします。
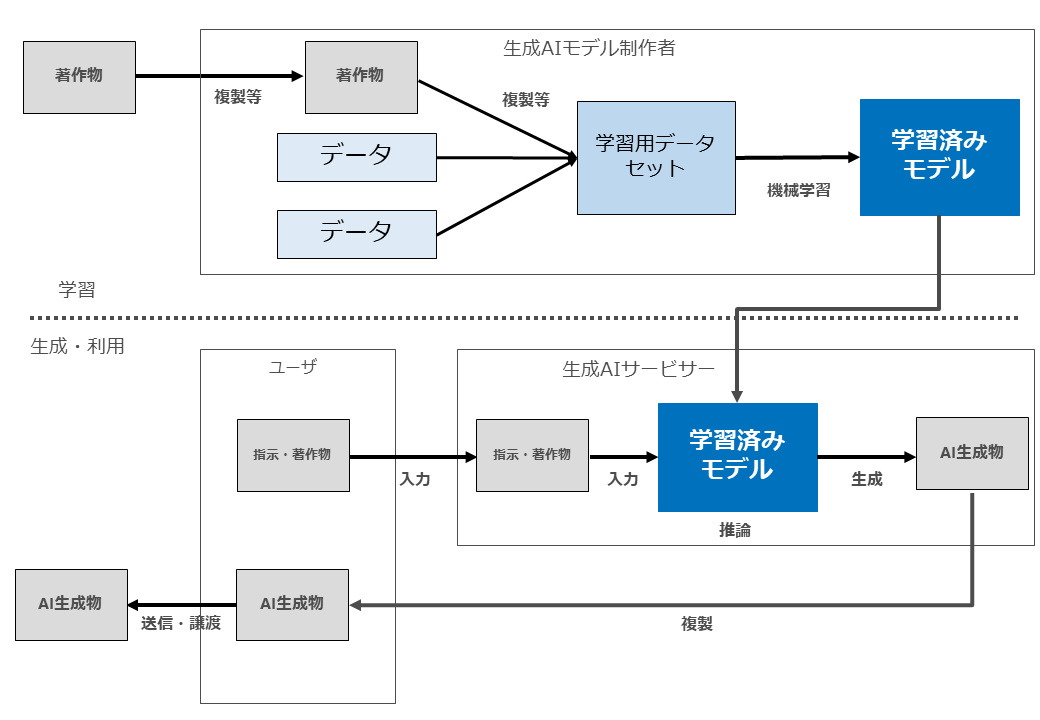
よく言われているように、まず「学習」フェーズと「生成・利用」フェーズを分けます。
「学習」においては、生成AIモデル制作者が、著作物を収集(複製等)した上で、学習用データセットを作成し、同データセットを用いて学習済みモデルを制作します。
そのようにして制作された学習済みモデルを組み込んだサービスを提供するのが「生成AIサービサー」です。
生成AIサービスの「ユーザー」は「生成・利用」フェーズにおいて、何らかの指示や著作物を生成AIサービスに入力し、当該入力データを用いた推論が行われた結果、AI生成物が生成されます。
そして生成されたAI生成物をユーザーがみずからの手元に複製等を行ったうえで、その後当該AI生成物を外部に配信したり譲渡したりすることとなります。
この図では、説明がしやすいように、関与するプレーヤーとして「生成AIモデル制作者」「生成AIサービサー」「ユーザー」の3つに分けていますが、1社(1人)が複数のプレーヤーを兼ねる場合もあります。
ChatGTPやMidjourneyのように「生成AIモデル制作者」+「生成AIサービサー」というプレーヤーもいますし、ユーザーが自らの手元にOSSの学習済みモデルをダウンロードした上で、ファインチューニングをしたモデルでAI生成物を生成する場合には当該ユーザーは「生成AIモデル制作者」+「生成AIサービサー」+「ユーザー」だということになります。
そのように、1社(1人)が複数のプレーヤーを兼ねる場合には、それぞれのプレーヤーとしての責任を検討する必要があります。
(2) 著作権侵害を検討する際には著作物の利用行為ごとに検討する必要がある
このように、一連の流れとして行われる行為が著作権侵害に該当するかを検討するに際して重要なのが「著作物の個々の利用行為(複製・公衆送信・譲渡等)ごとに著作権侵害の有無を検討する必要がある」ということです。
この点については、文化庁資料15頁でも指摘されています。
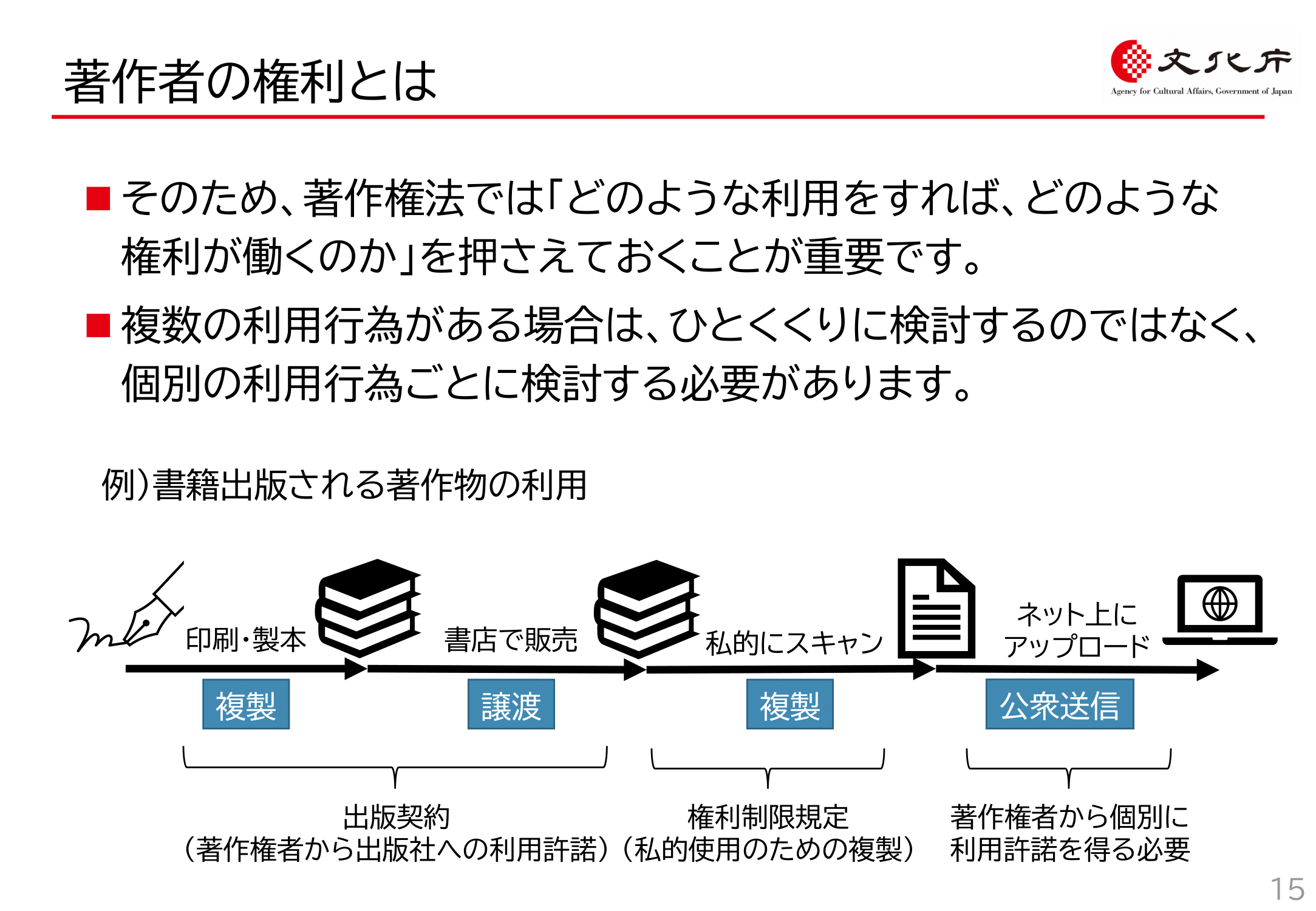
文化庁資料p15
「生成AIと著作権侵害」の論点においても、先ほどの図の「複製等」「機械学習」「入力」「生成」「複製」「送信・譲渡」という著作物の利用行為ごとに著作権侵害を検討する必要があります。
これは大変重要なポイントです。
(3) 著作権侵害の要件
著作権侵害が成立するためには、まず① 「後発の作品が既存の著作物と同一、又は類似していること」(類似性)と② 「既存の著作物に依拠して複製等がされたこと」(依拠性)の2つが必要です。この点についても文化庁資料P21で説明されているとおりです。
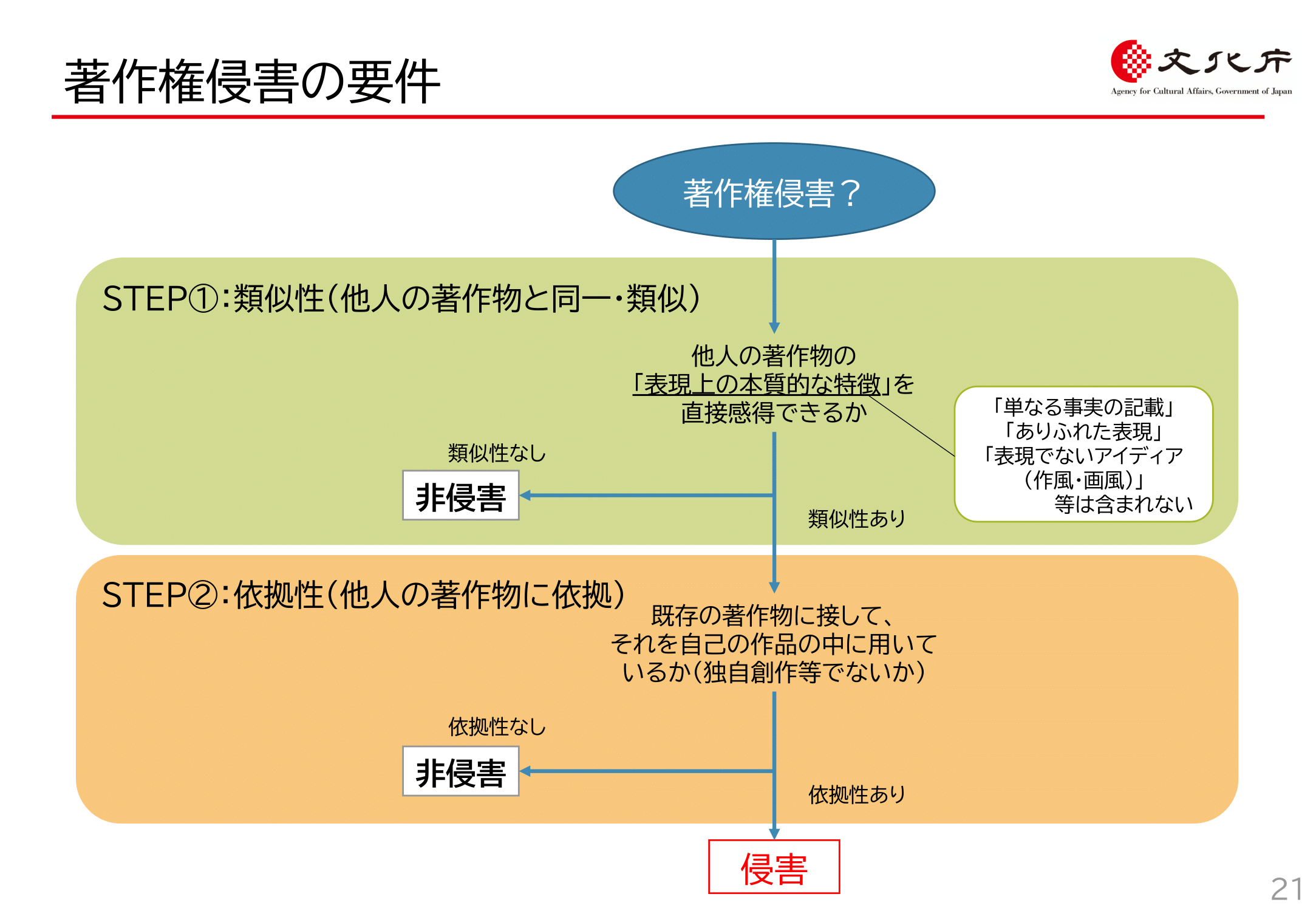
文化庁資料p21
「生成AIと著作権侵害」の論点においても、当然この2つは問題になります。
このうち「類似性」については、AI特有の問題はありません(特に画像生成AIについては作風の類似が問題になることが多いですが、作風が類似しても、著作権侵害の要件である「類似性」を満たさないことは上記文化庁資料P21記載の通りです)。
一方、「依拠性」については、生成AI特有の問題があり、解釈が分かれている点もあります(詳細は後述します)。
さらに、ある既存著作物の利用行為が「類似性」と「依拠性」を満たしていたとしても、当該利用行為に著作権法上の「権利制限規定」の適用があれば著作権侵害にはなりません。
ここでも文化庁資料24頁を引用します。
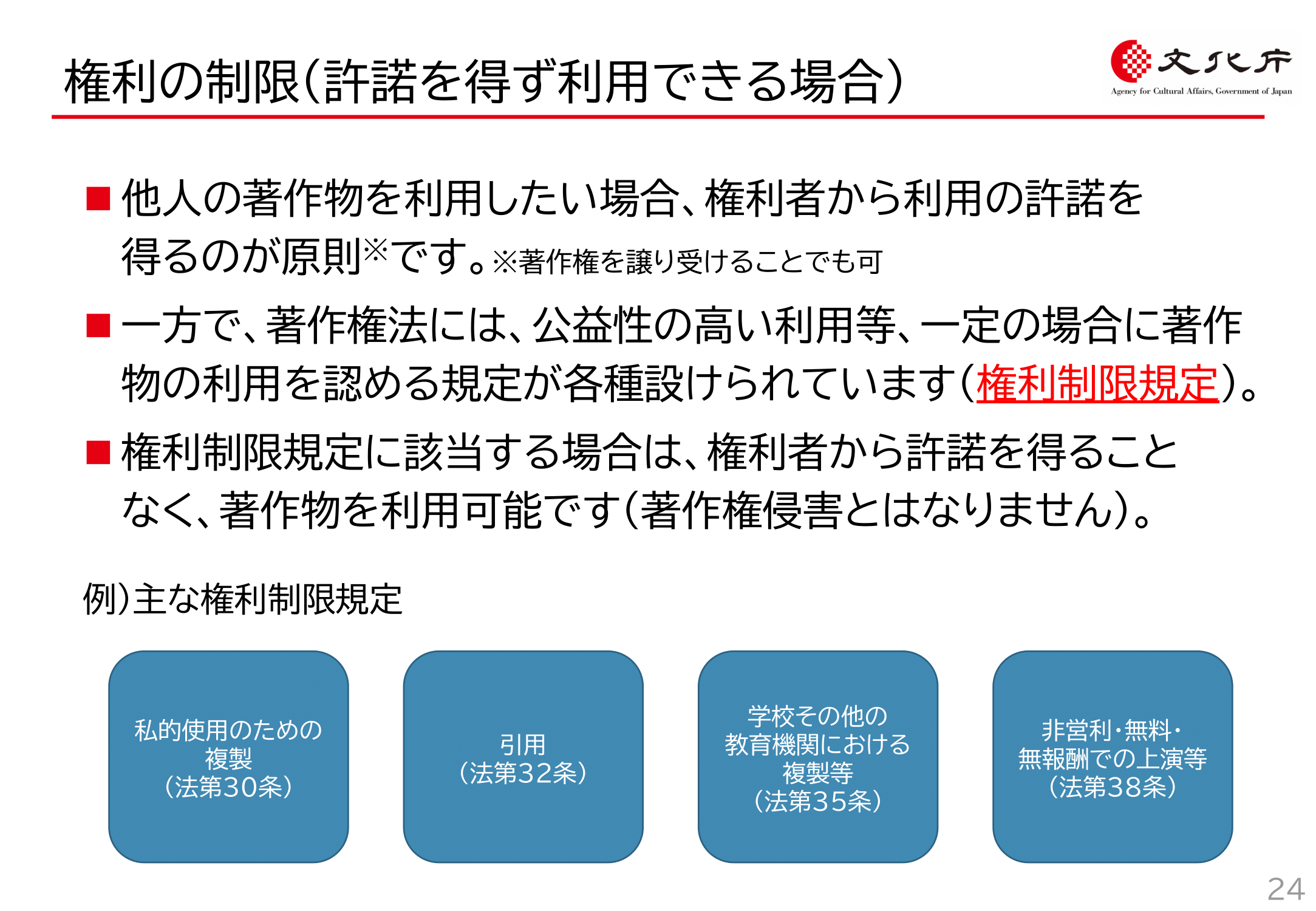
文化庁資料P24
なお、この24頁の例には記載されていませんが、AI制作・利用に関して問題となることが多い、著作権法30条の4及び47条の5も、この「権利制限規定」の一種です。
(4) まとめ
以上をまとめると、生成AIと著作権侵害について検討する際には、①著作物の個々の利用行為ごとに、②著作権侵害の要件(類似性・依拠性・権利制限規定適用の有無)を検討する必要がある、ということになります。
(5) 「享受」とは
そして、最後に「享受」についても説明しておきます。
AIの制作や利用に関して議論されることが多い著作権法30条の4は「著作物に表現された思想又は感情の享受を目的としない利用」についての権利制限規定です。
つまり「著作物に表現された思想又は感情の享受を目的としない利用」であれば、通常は著作権者の利益を害さないことから権利制限の対象としているのです。
したがって、逆に言えば「著作物に表現された思想又は感情の享受を目的」としていれば(非享受目的と享受目的が併存している場合も含む)30条の4は適用されないということになります。
このように、対象著作物を利用するにあたって、対象著作物にに表現された思想又は感情の「享受目的」があるかどうかが、30条の4が適用されるか否かの重要な分水嶺となりますので、そもそも「享受」とは何かが問題となります。
この点については「享受」とは、著作物の視聴等を通じて、視聴者等の知的・精神的欲求を満たすという効用を得ることに向けられた行為(例:文章を閲読すること、音楽・映画を鑑賞すること、プログラムを実行すること、されています。
この点についても文化庁資料36頁にわかりやすく説明されているので、引用します。

文化庁資料P36
2 生成AIを作ること(機械学習)と著作権侵害
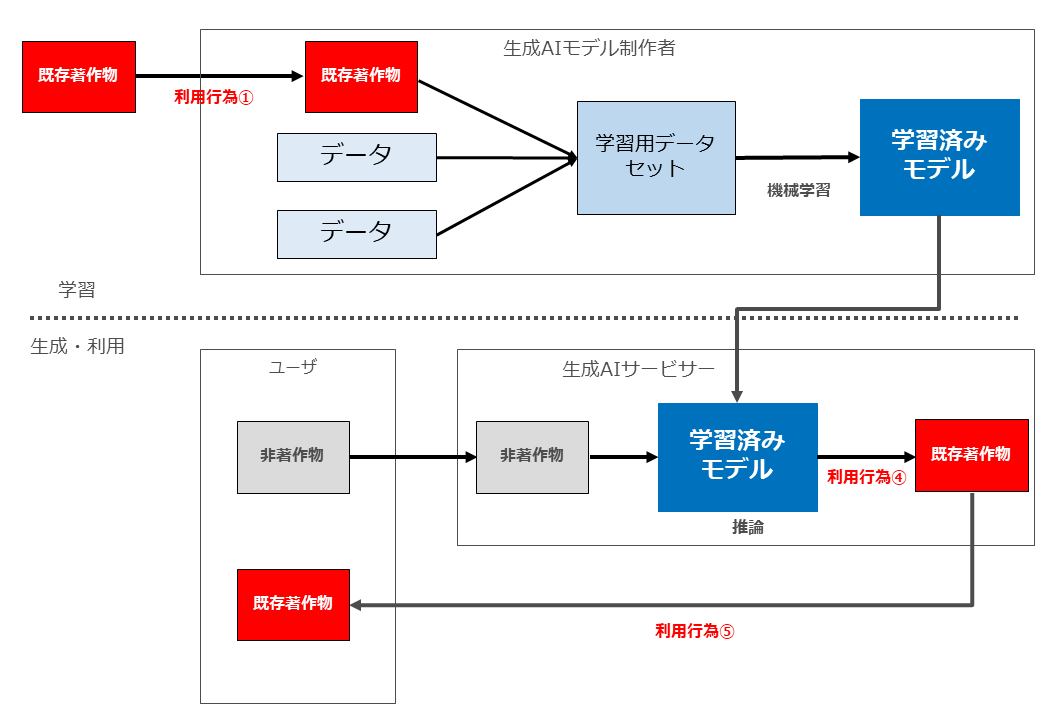
この論点は、「生成AIを作ること(機械学習)のために必要な既存著作物の利用行為(複製等)が著作権侵害になるか、というものです。
先ほどお伝えしたように、①著作物の個々の利用行為ごとに、②著作権侵害の要件(類似性・依拠性・権利制限規定適用の有無)を検討していきます。上記の図の「利用行為①」と「利用行為②」です(ただ、利用行為①と②の侵害判断基準や判断結果は同一であることから、以下ではまとめて検討します)
(1) 類似性・依性性
既存著作物を認識しながら利用(複製等)していますので、この点は問題なく肯定されます。
(2) 権利制限規定の適用
生成AI(学習済みモデル)を作る(機械学習)行為は、技術的にはモデル内のパラメーターを更新する行為ですので、30条の4第2号に定める「情報解析」に該当します。
そして、当該行為のために著作物を利用(複製等)する行為は、「情報解析」のために必要な行為であることから、利用行為①及び②いずれについても30条の4が適用され、原則として適法となります。
ただし「原則として」と記載したように、2つ例外があります。1つは「学習対象著作物の「享受目的」が併存している場合」、もう1つは「30条の4但書が適用される場合」です。
(3) 学習対象著作物の「享受目的」が併存している場合
1つ目は、生成AI(学習済みモデル)を作る(機械学習)行為のような「情報解析」行為であっても、学習対象著作物の「表現上の本質的な特徴」を感じ取れるような映像の作成を目的として行う場合、すなわち学習対象著作物の「享受目的」が併存している場合には著作権法30条の4の適用がない、という点です。
この点については、文化庁と内閣府が公表した資料(以下「文化庁・内閣府資料」といいます)の「AI開発・学習段階(著作権法第30条の4)」の部分の解説に下記記載があることから話題になりました(といっても、資料発表当時、私が騒いでいたただけですが。。。。後述のように、現在では、文化庁のこの見解に問題はない(ただし「享受目的」は慎重に認定すべき)と思っております。)
※1 例えば、3DCG映像作成のため風景写真から必要な情報を抽出する場合であって、元の風景写真の「表現上の本質的な特徴」を感じ取れるような映像の作成を目的として行う場合は、元の風景写真を享受することも目的に含まれていると考えられることから、このような情報抽出のために著作物を利用する行為は、本条の対象とならないと考えられる
ア この論点は学習段階と生成・利用段階の双方で問題となる
文化庁・内閣府資料の記載では「必要な情報を抽出する場合」とありますが、この「情報の抽出」というのは、著作権法上の「情報解析」の定義内にある「情報(の)抽出」のことを指していると思われます。
そして、私は著作権法30条の4の「情報解析」には、条文の定義規定からすると、学習段階における学習行為(学習対象著作物を用いたパラメータの更新行為)と、推論段階(生成段階)におけるAI生成物の生成行為(正確に言うとAI生成物の生成を行うための、入力著作物のモデル内での解析行為)の両方が含まれると考えております(この点についての詳細は、過去のブログ記事「Midjourney、Stable Diffusion、mimicなどの画像自動生成AIと著作権(その2)」の「第3 ご意見・質問に対する回答」の部分をご覧下さい。この記事では「少数のデータで学習する行為」について解説していますが、この考え方は「生成AIに入力されたデータを解析する行為」にも同じく当てはまります。)
このように、「情報解析」に、学習行為及び生成行為双方が含まれているという前提に立つと、学習対象著作物の「享受目的」が併存しているか否かの論点は、学習段階でも、生成・利用段階でも問題になることとなります。
文化庁・内閣府資料の上記記載が、学習行為及び生成行為のどちらかだけを対象としているのか、双方を対象としているのかははっきりしませんが、同資料中の「AI開発・学習段階」に関する解説部分なので、少なくとも学習行為を対象としていることは間違いないと思います。(ちなみに、文化庁の2023年6月19日のセミナーの33:00~あたりでは、享受目的も併存する情報解析の具体例として「AIの仕様によって元の写真がテクスチャーとして貼り付けられた3DCGが出力される場合」を挙げておられますが、「AI開発・学習段階」に関する解説なので、やはり、少なくとも学習行為についてはこの論点を問題にしていると思われます。)
イ この論点は生成AIで初めて生じた
この問題を一般化すると「情報解析(学習or生成)のために対象著作物の利用行為を行うに際して、対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物の作成目的(=対象著作物の享受目的)が併存している場合、対象著作物の利用行為は30条の4の対象になるか」という問題となります。
この問題は、AIに関しては、生成AIで初めて生じた論点ではないかと思われます。
識別AIや予測AIの場合、そもそも「情報解析の対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物の作成」ということ自体が生じないからです。
ウ 文化庁の見解の分析
文化庁・内閣府資料における上記部分は、論理的には以下のステップで検討しています。
① 「情報解析」(学習or生成)のために必要な対象著作物の利用行為であったとしても、「享受目的が併存している利用行為」については30条の4の適用はない
② 「情報解析」(学習or生成)の対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物の作成を目的として行われる利用行為は、「享受目的が併存している利用行為」である
③ したがって、「情報解析(学習or生成)の対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物の作成を目的として行われる利用行為」については30条の4の適用はない。
このうち、①については、立法過程からしてその通りであり、特に異論はありません(私はこの点について、過去に異なる意見を公表したこともありますが意見を修正します。)
一方、②における「情報解析(学習or生成)の対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物の作成目的」(以下「享受目的」といいます)の認定は、特に学習段階(つまり、まだAI生成物が生成されていない段階)においては慎重に行うべきであり、安易に享受目的を認定すべきでないと考えます。
エ 検討
このように、特に学習段階における情報解析(2号)行為の「享受目的」を安易に認定すべきではないと考える理由は、以下の3つです。
まず、1つ目は、まだ類似生成物が生成されていない段階(学習段階)での著作物の利用行為の問題なので、安易にこの「享受目的」を認定してしまうと、技術開発やビジネスに対する大きな萎縮効果を生じさせるためです(ちなみに、同じ情報解析でも推論段階(生成段階)における情報解析は、生成にもっと「近い」行為なので別途考慮が必要であるのは後述します)。
次に、これはやや形式的な理由ですが「情報解析」を含む30条の4第1号~3号該当行為は、享受目的が存在していることは通常存在しない類型として(例外はあるにせよ)定められた行為類型ですから、1号~3号該当行為について享受目的が併存することは例外的なケースとして、享受目的が併存するか否かを慎重に判断すべきという点です(なお、後述の文化庁の平成30年改正時資料における享受目的が併存していることから非享受利用が否定されるケースは、1号~3号該当行為ではありません)。
最後に、実は、非享受目的と享受目的が併存している著作物の利用行為には2類型あり、分けて検討する必要があるのではないか、という点です。
最後の点がわかりにくいと思うので、説明します。
(ア)対象著作物の利用行為と同時に享受行為が行われる(正確に言うと「享受可能な状態になる」)パターン
文化庁の平成30年改正時資料においては、享受目的が併存していることから非享受利用が否定されるケースとして以下の2つの例が挙げられています(問7)。
・ 家電量販店等においてテレビの画質の差を比較できるよう市販のブルーレイディスクの映像を常時流す行為(上映)(問7)
・ 漫画の作画技術を身につけさせることを目的として,民間のカルチャー教室等で手本とすべき著名な漫画を複製して受講者に参考とさせるために配布したり,購入した漫画を手本にして受講者が模写したり,模写した作品をスクリーンに映してその出来映えを
吟味してみたりするといった行為(問7)
この2つの例は、対象著作物の利用行為と同時に享受行為が行われています。
すなわち、「映画の上映という利用行為と同時に映画を視聴するという享受行為が行われる」「漫画の複製という利用行為と同時に、漫画を読むという享受行為が行われる」という関係にあります(なお、「享受されること」は著作権侵害の要件ではありませんので、このパターンは正確に言うと「利用行為と同時に享受可能な状態になる」パターンです)。
このパターンの場合は、利用行為と同時に享受行為が行われているため、利用行為における「享受目的」は判断しやすいですし、通常「享受目的」があることにになると思われます。
(イ)著作物の利用行為と同時に享受行為が行われず、後で享受行為が行われるパターン
著作物の利用行為と同時には享受行為が行われず、後で享受行為が行われるパターンもあります。
典型的な例が、今回問題にしている、「情報解析(学習)において対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物の作成を目的とした利用行為」です。
情報解析(学習)の場合、対象著作物の利用行為が行われた時点では、まだAI生成物が生成されていませんから、享受行為が行われていません(享受可能な状態にはなっていません)。
当該利用行為の「後」に、生成AIによって学習対象著作物の「表現上の本質的な特徴」を有するAI生成物が生成された段階(そのようなAI生成物が生成されるか否かすら学習段階では決まっていません)で、はじめて享受行為が行われることとなります。
したがって情報解析(学習)において「享受目的」を認定する際には、非常に慎重になされるべきと考えています。単に「対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物が作成される可能性がある」という程度でこの「享受目的」を認めるべきではありません。繰り返しになりますが、このパターンで享受目的を広く認めてしまうと、特に生成AIにおける学習に大きな制限がかかるためです。
そもそも、「享受目的」における「目的」というのは 行為者の主観的な認識を問題としているので、認定が難しいんですよね。。。
以上の3つの理由から、私は学習段階における情報解析(2号)行為の「享受目的」を安易に認定すべきではないと考えています。
オ その他
(ア) 対象著作物の作風の再現を目的として行う利用行為の場合
この論点は「情報解析に際して、情報解析の対象著作物の「表現上の本質的な特徴」を感じ取れるような著作物の作成目的(=対象著作物の享受目的)が併存している場合、対象著作物の利用行為は30条の4の対象になるか」という問題ですから、LoRAなどの技術を利用し「対象著作物の作風の再現を目的として行う利用行為」の場合は、「享受目的はない」ということになると思われます。
ただし、学習段階において「作風の再現を目的とする」と「表現の本質的な特徴の再現を目的とする」を区別することは相当難しいでしょうね(だからこそ、学習段階における享受目的の認定には慎重に、と繰り返し強調しているところです)。
(イ) 47条の5の適用可能性
また、「情報解析に際して、対象著作物の享受目的が併存しており、30条の4が適用されない場合」であっても、著作権法47条の5が適用される可能性があります。
この47条の5は、「電子計算機による情報解析を行い、及びその結果を提供すること」を目的とする著作物の利用行為(ただし軽微利用に限る、同1項2号)や、そのための準備行為(同2項)についての権利制限規定です。
つまりこの条文によって、「情報解析の結果」の提供に際しての著作物の軽微利用は許されるのですが、まず、生成AIにおける情報解析のうち「学習行為」については、「結果」とは学習済みモデルですから、(後に生成される可能性のある)AI生成物を「結果」と捉えて同条を適用することは難しいように思います。
一方、生成AIにおける情報解析のうち「AI生成物の生成行為」については、AI生成物が情報解析の「結果」でしょうから、47条の5が適用されると思われます(その結果著作権侵害になるかどうかは「軽微利用」に該当するかどうかに依存しますが、対象著作物に類似するAI生成物をそのまま利用する場合は通常、軽微利用に該当しないと思われます。)。
(4) 30条の4但書に該当する場合
もう1つの例外は、30条の4但書「ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。」に該当する場合です。
この但書に該当する場合は、たとえ情報解析のためであっても著作物の利用は許されません。
具体的にどのようなケースがこれに該当するかは議論されているところですが、「情報解析を行う者の用に供するために作成されたデータベースの著作物の利用行為」については但書に該当することは明らかです。
文化庁資料39頁でもその点は明確化されています。
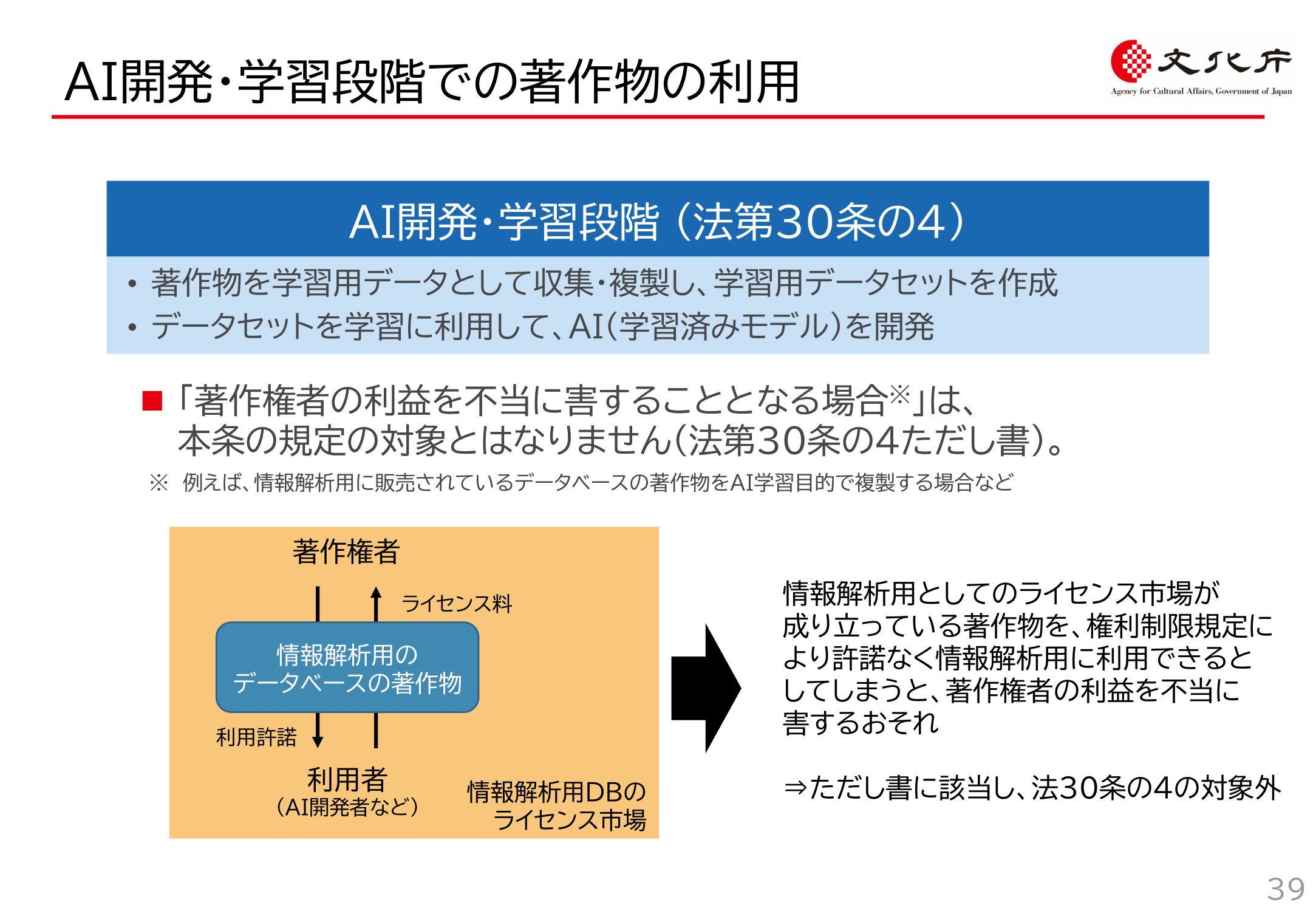
文化庁資料P39
(5) まとめ
以上、長くなりましたがまとめです。
・ 生成AIを作ること(機械学習)のために既存著作物を利用することは著作権法30条の4第2号により原則として適法だが、2つ例外がある。
・ 1つは、「学習対象著作物の「享受目的」が併存している場合」。ただし、そのような「享受目的」を安易に認めるべきではない。
・ もう1つの例外は30条の4の但書が適用される場合。「情報解析を行う者の用に供するために作成されたデータベースの著作物の利用行為」は但書に該当するが、それ以外のケースは議論中。
3 生成AIを利用してAI生成物を生成・利用することと著作権侵害
(1) 分析の視点
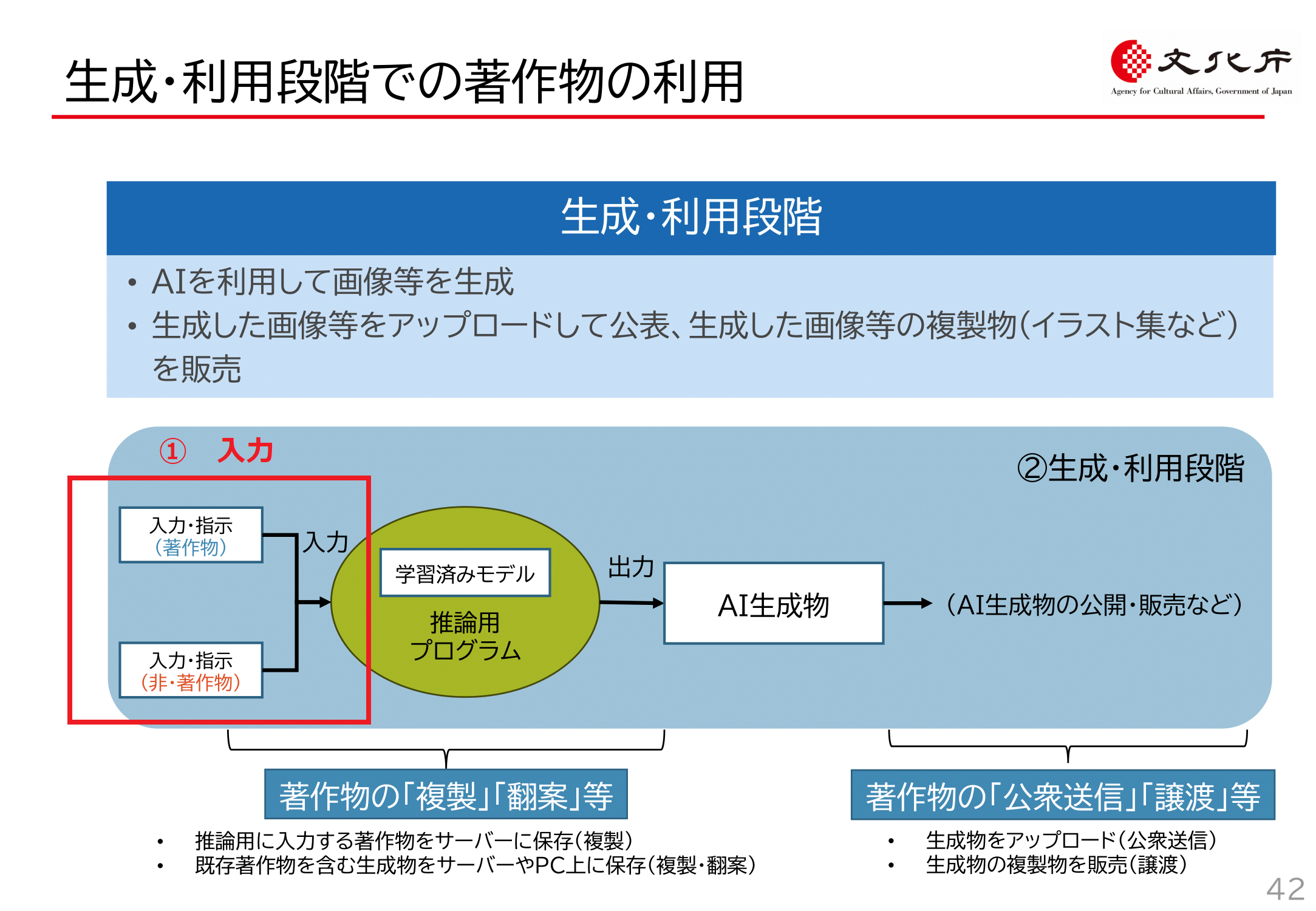
AIと著作権侵害の問題を考える際に、学習段階と生成・利用段階を分けて考えることが重要ですが、さらにその先、つまり生成・利用段階を検討する際にも、「著作物の入力行為」「AI生成物の生成行為」「AI生成物の送信行為」の3段階に分けて検討することが必要だと考えています。
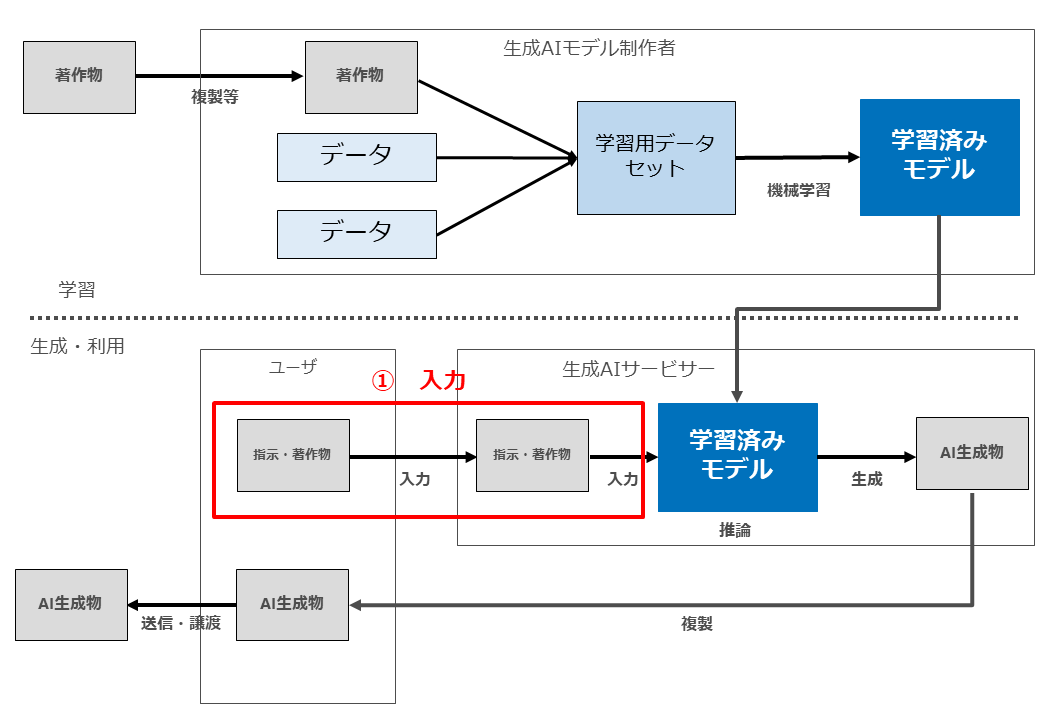
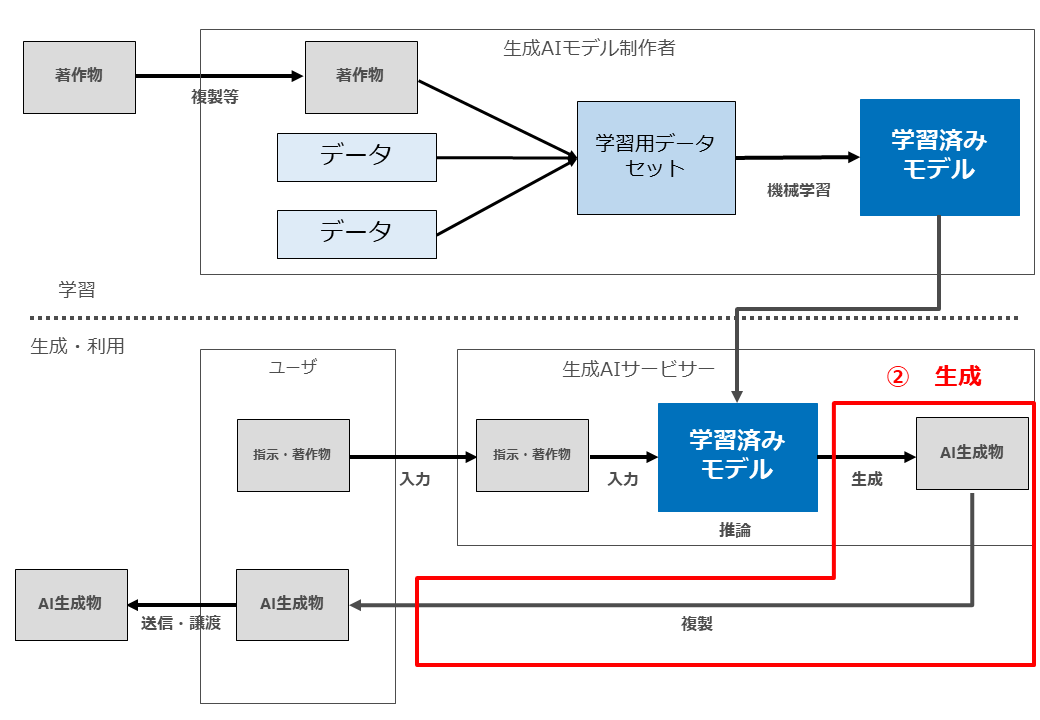
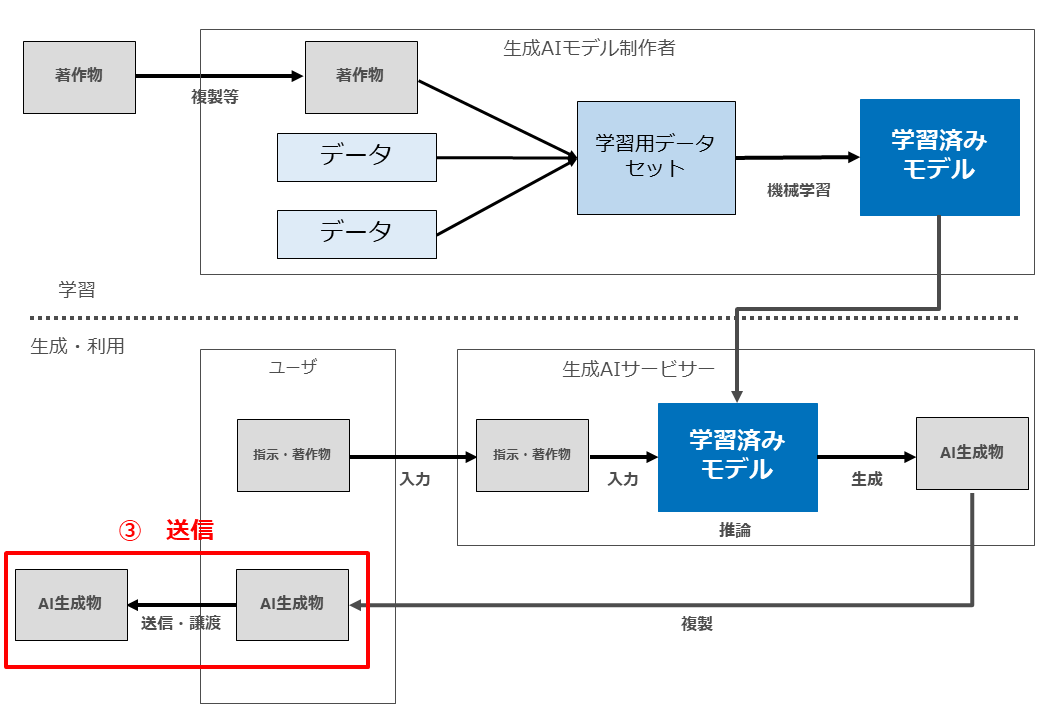
文化庁資料P42でも、この3段階を分けて検討しています(以下の3つの図表はいずれも文化庁資料P42。赤枠・赤字部分は柿沼が加筆した部分)。
文化庁資料P42(赤字と赤枠部分は筆者が加筆)
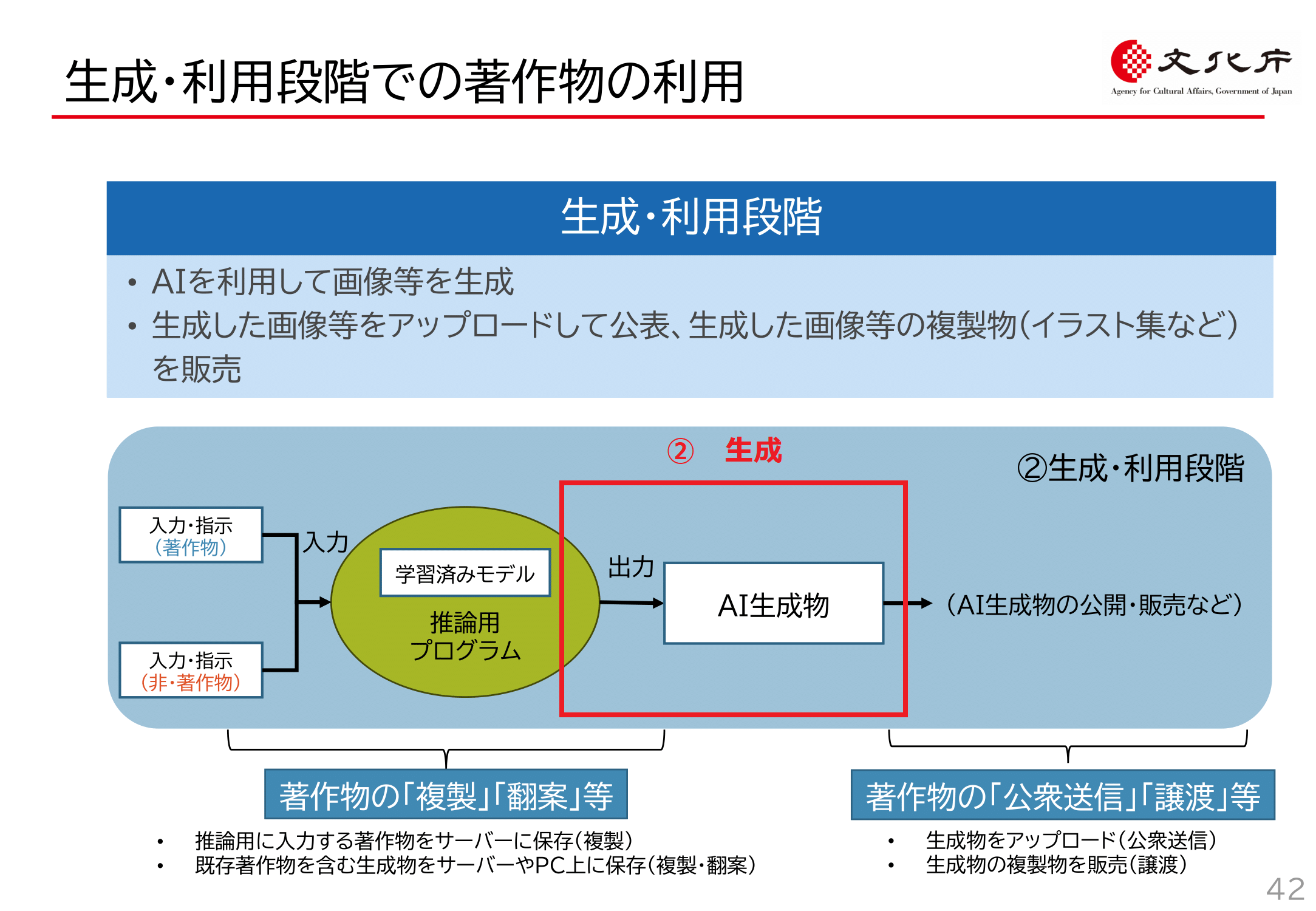
文化庁資料P42(赤字と赤枠部分は筆者が加筆)
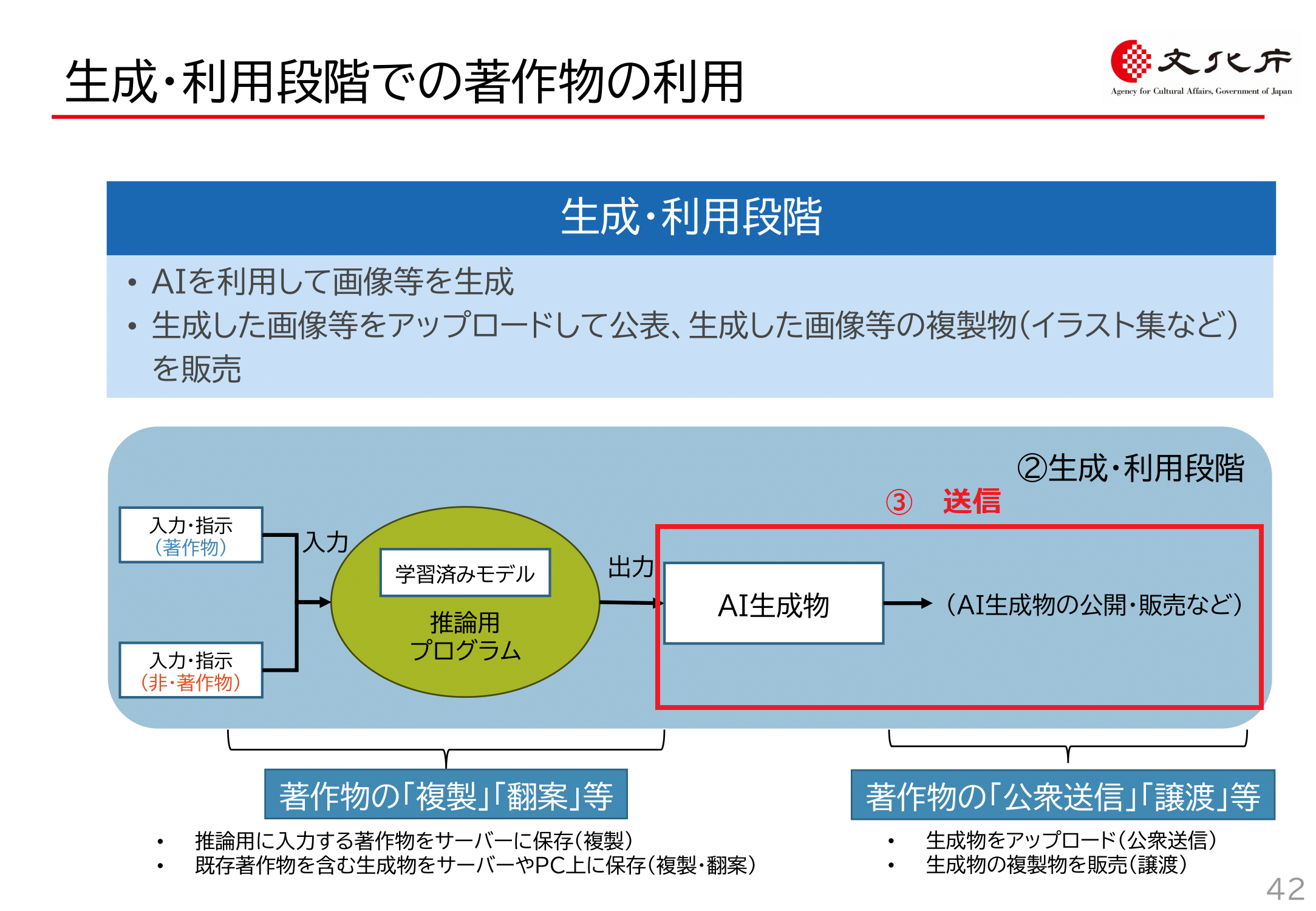
文化庁資料P42(赤字と赤枠部分は筆者が加筆)
生成・利用段階を3段階に分けて検討と言うと「また細かいことを・・」と思う方もおられるかもしれませんが、後述するように、この3段階をそれぞれ検討することは、生成AIをビジネスで利用することを検討する際に非常に有益だと考えています。
以下では、この3段階に分けて検討します。
ちなみに、先ほどの「2 生成AIを作ること(機械学習)と著作権侵害」では、学習段階でのみ既存著作物が利用されているケースを検討しました。
この「3 生成AIを利用してAI生成物を生成・利用することと著作権侵害」では、「生成・利用段階」にフォーカスして考えるために、学習段階では既存著作物の利用がないものとして検討します。
学習段階と生成・利用段階の双方で既存著作物の利用があるケースは、後の「4 機械学習×生成・利用と著作権侵害」で検討します。
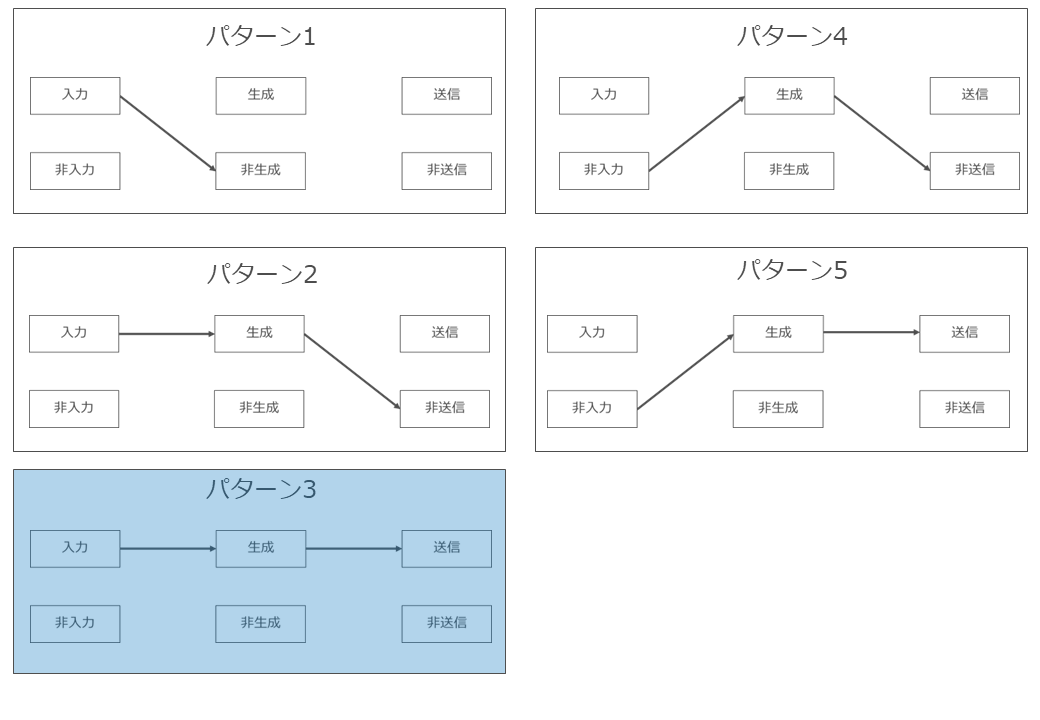
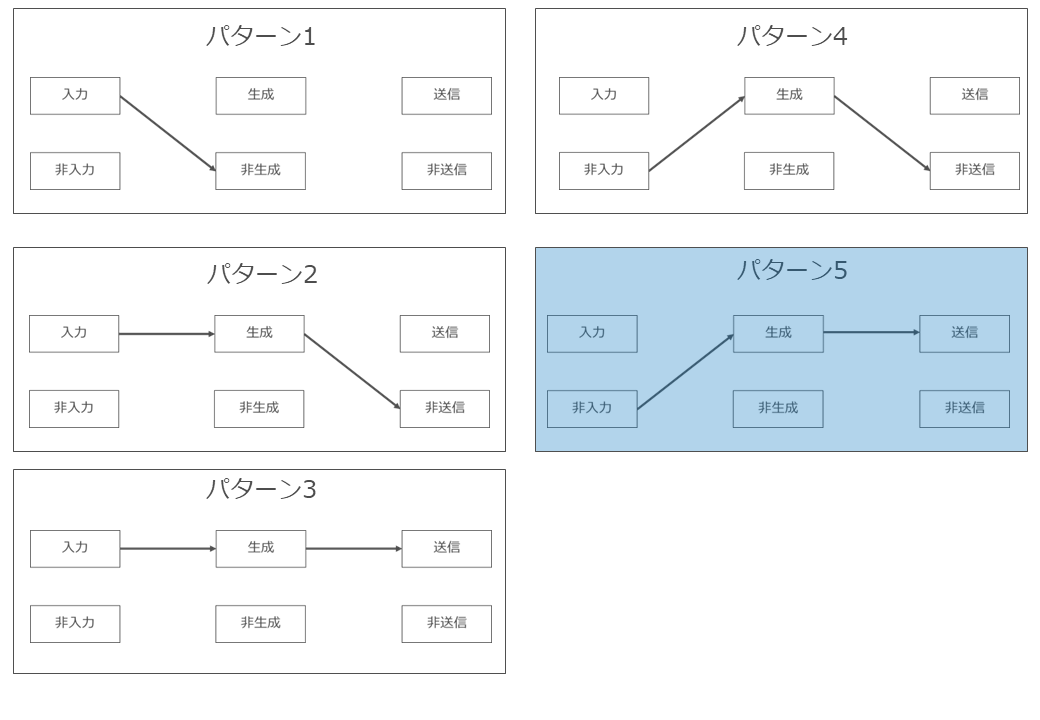
(2) 5つのパターン分け
「著作物の入力行為」「AI生成物の生成行為」「AI生成物の送信行為」の3段階に分けて検討する場合、それぞれの段階において「著作物を入力している/していない」「AI生成物を生成している/生成していない」「AI生成物を送信している/送信していない」の選択肢があることになります。
これらを組み合わせると、実際に検討する必要があるパターンは以下の5つとなります。
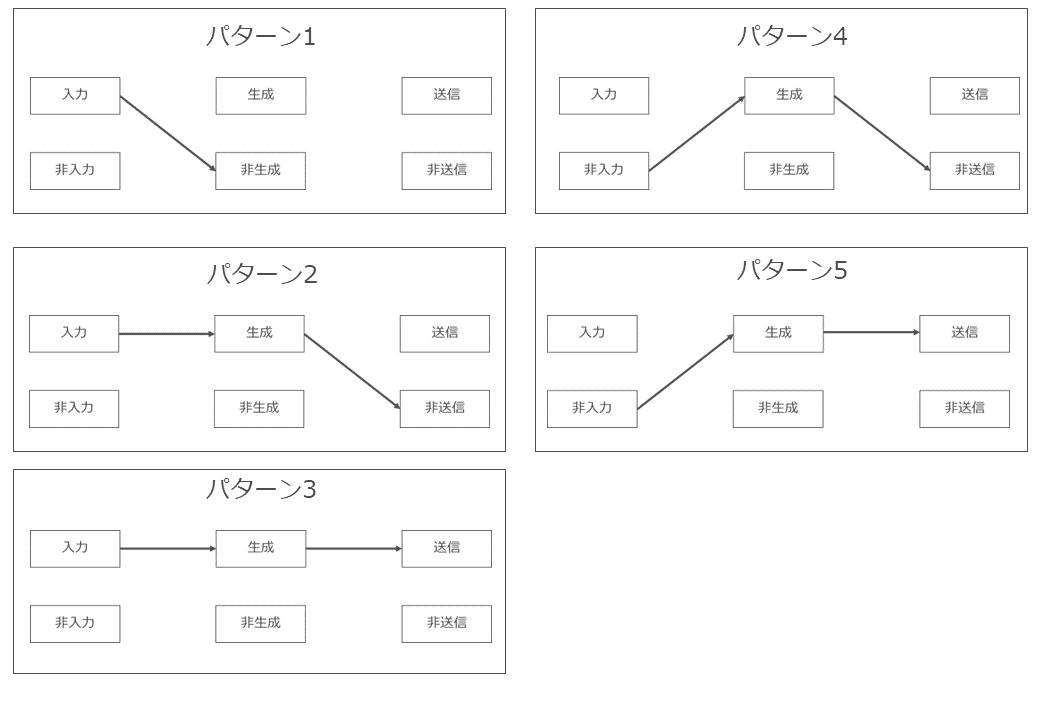
(3) 生成AIに既存著作物を入力しているだけであり、生成AIによる処理結果として類似著作物が生成されていないパターン(パターン1)
ア どのようなパターンか
生成AIに既存著作物を入力しているだけであり、生成AIによる処理結果として類似著作物が生成されていないパターンです。ここでは下記図の利用行為②と③が問題になりますが区別して検討する実益に乏しいので、まとめて検討します。
イ 類似性・依拠性
問題なく肯定されます。
ウ 権利制限規定の適用
まず、先ほど述べたように、生成AI内において、入力された既存著作物を解析しAI生成物を生成する行為(正確には「AI生成物の生成を行うための、入力著作物のモデル内での解析行為」)は条文の定義上「情報解析(30条の4第2号)に該当すると思われます。
したがって、当該「情報解析」のために既存著作物を入力する行為である利用行為②③は「情報解析のために必要な行為」に該当し、30条の4第2号により原則として適法です。
ただし、ここでも、「2 生成AIを作ること(機械学習)と著作権侵害」で述べたことがあてはまります。
つまり「享受目的併存の場合」と「30条の4但書」に該当する場合には30条の4は適用されません。このうち、生成AIに既存著作物を入力する行為が30条の4但書に該当することは通常考えられません。
一方、「享受目的併存」が認められる可能性は、学習段階における既存著作物の利用の場合よりも高いのではないかと思われます。学習段階に比べると、生成・利用段階での既存著作物の利用は、AI生成物が生成され享受される場面に、より「近い」場面での著作物の利用行為だからです。
ただし、このパターン1はまだAI生成物が生成されていないパターンですからやはり慎重に検討すべきでしょう。
また、より重要なことがあります。
それは、この「享受目的」の有無は、画像生成AIと言語生成AIとでかなり異なるという点です。
画像生成AIの場合は「特定の既存著作物に似た著作物を生成しよう」という目的で利用されることが十分考えられますが、ChatGPTなどの言語生成AIがビジネスで活用される場合に、そのような目的があることはむしろ稀だからです(もちろん翻訳や要約などの目的に利用する場合には享受目的併存が認められることもあるでしょう。【20230704追記】ただ、その場合でもAI生成物の生成フェーズに別の権利制限規定(30条等)が適用されるケースであれば入力行為にも当該権利制限規定が適用されると思います)。
したがって、ChatGPTなどの言語生成AIをビジネスで活用する場合、既存著作物の入力行為に「享受目的」が存在することはほとんどないのではないかと考えています。
ただし、これは、あくまでこのパターン(生成AIに既存著作物を入力しているだけであり、生成AIによる処理結果として類似著作物が生成されていない)に当てはまる議論です。
後述のように実際に既存著作物と類似のAI生成物を生成し、当該AI生成物を配信等した場合には、入力行為にも享受目的併存が認められやすくなるでしょう。
エ ビジネスへのインパクト
このパターン1(既存著作物を入力しているだけのパターン)が適法か否かは、ビジネスに大きな影響があります。
記事冒頭でも紹介したように、最近では、セマンティック検索のために、他者が著作権を有しているデータを含むデータを適宜分割してベクトル化し、ベクトルデーターベースに格納した上で、LLMへの入力データに利用することが行われるようになりました。
ここで行われていることは「既存著作物を生成AIに入力する」(あるいは入力のために蓄積する)行為ですが、「既存著作物を生成AIに入力する」行為を行うだけで(その後類似著作物が生成されていない場合でも)著作権侵害に該当するのであれば、このようなセマンティック検索において他者が著作権を有しているデータを利用する行為についても著作権侵害になる可能性が生じるためです。
したがって、パターン1(既存著作物を入力しているだけのパターン)と、後ほど説明するパターン2(既存著作物を入力し、同既存著作物同一・類似のAI生成物が生成されているパターン)やパターン3(既存著作物を入力し、同既存著作物同一・類似のAI生成物が生成され、かつそれを配信等しるパターン)とは明確に区別をする必要があります。
なお、セマンティック検索の出力結果に、既存著作物がそのまま含まれている場合には、後述のパターン2やパターン3に該当することになります。
【2023年7月6日追記】
生成AIへのプロンプトとしての既存著作物の入力に類似している問題として、「検索エンジンへのクエリとして既存著作物を入力する行為と著作権侵害」という問題があります。
検索エンジン内では入力情報についての「情報解析」(法30条の4第2号)が行われている点については、生成AIと共通しています。ただ、検索エンジンの場合、検索者が行なっていることは、著作物の入力行為までであり、新たな著作物の生成行為はしていないので、入力行為の部分だけ(生成AIで言えば入力だけを行ったケースだけ)を問題にすれば足ります。
そして、検索時に、クエリと同一・類似の著作物を「生成」する目的はないので、生成AIへの既存著作物の入力時のような例外はなく、結論として検索エンジンへの既存著作物の入力行為が著作権侵害になることはないように思います。
もちろん、検索者が類似著作物にたどり着いて、それをダウンロードしてさらに配信等すれば著作権侵害になります。
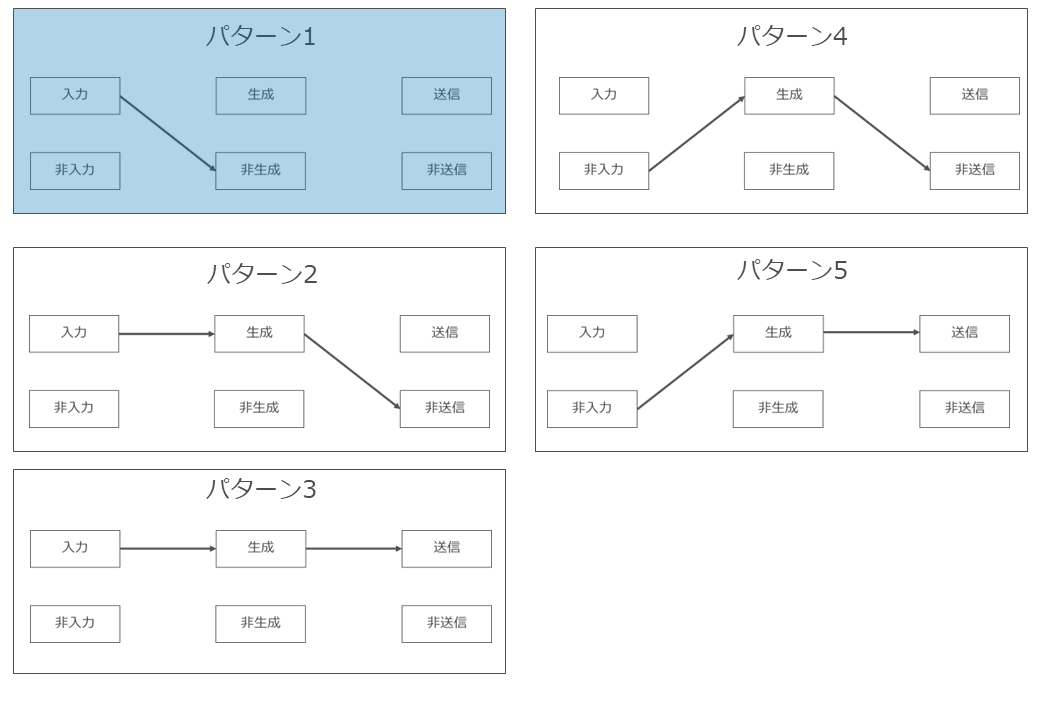
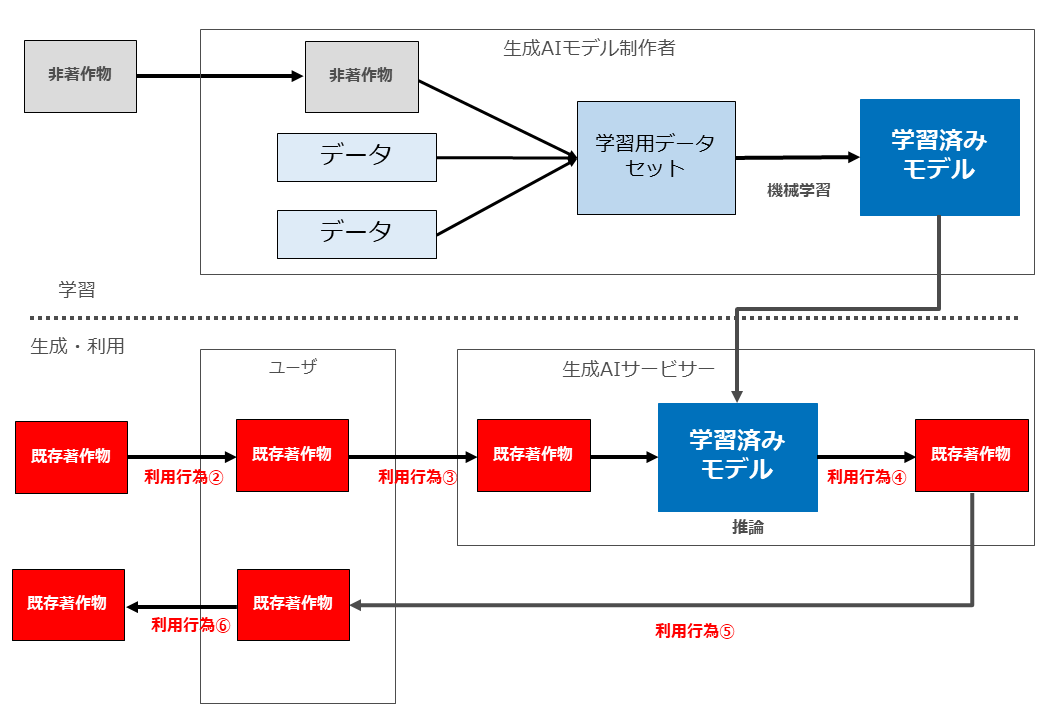
(4) 既存著作物を入力し、同既存著作物と類似するAI生成物を生成するパターン(パターン2)
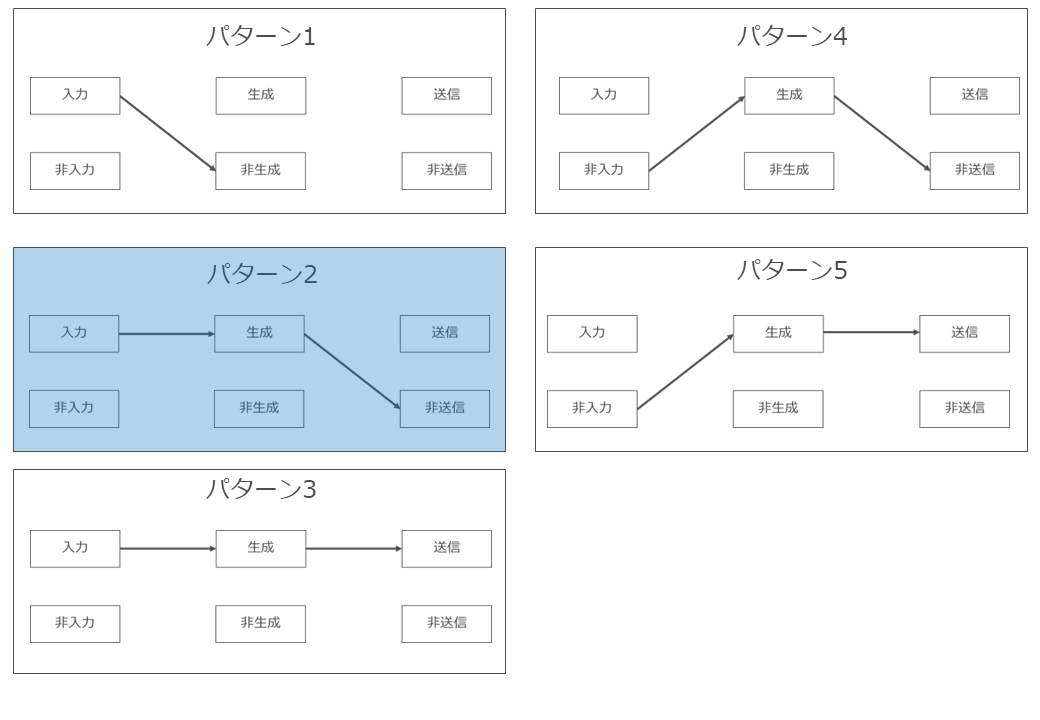
ア どのようなパターンか
生成AIに既存著作物を入力し、生成AIによる処理結果として既存著作物に類似するAI生成物を生成したが、ユーザー内部でのみ利用し、外部に配信等がなされていないパターンです。
以下、入力行為(上記の図の「利用行為②③」)と、AI生成物の生成行為(上記の図の利用行為④⑤」)に分けて検討します。
イ 入力行為(図の「利用行為②③」)
(ア) 類似性・依拠性
問題なく肯定されます。
(イ) 権利制限規定
この「入力行為」に権利制限規定が適用されるかは、すでにパターン1で述べたことが基本的に当てはまります。すなわち、「情報解析」に必要な行為として30条の4第2号により原則として適法だが享受目的併存の場合は同条が適用されない、ということになります。
ただし、パターン2はパターン1と異なり、実際にAI生成物が生成されていることから、入力行為にも、より享受目的が認められやすいのではないかと思われます。
ウ AI生成物の生成行為(図の「利用行為④⑤」)
(ア) 類似性・依拠性
問題なく肯定されます。
依拠性についても、既存著作物を自ら生成AIに入力してAI生成物を生成していることから問題なく肯定されると思われます。
文化庁資料49頁には「《依拠性に関する今後の検討事項(一例)》」として「・ AI利用者が既存の著作物を認識しており、AIを利用してこれに類似したものを生成させた場合は、依拠性が認められると考えてよいのではないか」「・ AI利用者が、Image to Image (i2i)で既存著作物を入力した場合は、依拠性が認められると考えてよいのではないか」とありますが、私はこのいずれのケースでも依拠性はあると考えています。
(イ) 権利制限規定
日本の著作権法には権利制限規定が複数存在しますが、それらの権利制限規定のいずれかに該当すれば適法です。そこで、以下、順番に検討していきます。
① 情報解析(30条の4第2号)
AI生成物は情報解析の「結果」として生じている行為ですから、その生成行為は「情報解析に必要な行為」ではありませんし、AI生成物を人間が享受することが当然の前提となっているため、同条は適用されません。
② 情報解析の結果提供に伴う軽微利用(47条の5第1項第2号)
AI生成物という「情報解析の結果」の提供に伴う著作物の利用には該当しますが、既存著作物に類似する著作物が生成されており軽微利用に該当しないため、同条は適用されません。
③ 私的利用目的複製(30条)
私的に鑑賞するためにAI生成物を生成する場合には、私的利用目的複製(30条)に該当し適法と思われます(文化庁資料46頁(下記参照)でもその点が明示されています)。
ただし私的利用目的複製(30条)の制限規定は、企業における利用では適用がありません。
④ 検討過程における利用(30条の3)
企業内での利用の際に適用される可能性がある権利制限規定は、「検討の過程における利用」(30条の3)です。
これは、「著作権者の許諾を得て(略)著作物を利用しようとする者」が、「これらの利用についての検討の過程(当該許諾を得、又は当該裁定を受ける過程を含む。)における利用に供することを目的とする場合」に適用される権利制限規定です。
この要件を満たしさえすれば、企業内での利用でも30条の3が適用され、適法となる可能性はあると思われます。

文化庁資料P46
(5) 既存著作物を入力し、同既存著作物と類似するAI生成物を生成して配信等を行うパターン(パターン3)
ア どのようなパターンか
生成AIに既存著作物を入力し、生成AIによる処理結果として既存著作物と類似するAI生成物を生成し、当該AI生成物を配信・譲渡等するパターンです。
ここでも、既存著作物の入力行為(上記の図の「利用行為②③」)、AI生成物の生成行為(上記の図の利用行為④⑤」)、AI生成物の配信行為(上記の図の利用行為⑥」に分けて検討します。
イ 入力行為(図の「利用行為②③」)
(ア) 類似性・依拠性
問題なく肯定されます。
(イ) 権利制限規定
この「入力行為」に権利制限規定が適用されるかは、すでにパターン1、2で述べたことが基本的に当てはまります。すなわち、「情報解析」に必要な行為として30条の4第2号により原則として適法、ただし享受目的併存の場合は同条が適用されない、ということになります。
ただし、パターン3は、パターン1、2と異なり、AI生成物を実際に生成し、かつ配信等していることから、入力行為については、さらに享受目的が認められやすいのではないかと思われます。
ウ AI生成物の生成行為(図の「利用行為④⑤」)
(ア) 類似性・依拠性
依拠性についても、既存著作物を認識しつつ入力してAI生成物を生成していることから問題なく肯定されると思われます。
(イ) 権利制限規定
パターン2で述べたことが当てはまります。
エ 配信行為(図の「利用行為⑥」)
(ア) 類似性・依拠性
問題なく肯定されます。
依拠性についても、既存著作物を認識しつつ入力してAI生成物を生成・配信していることから問題なく肯定されると思われます。
(イ) 権利制限規定
パターン3における配信行為に権利制限規定が適用されることはなく、著作権侵害に該当すると思われます(下記文化庁資料P47参照)。

文化庁資料P47
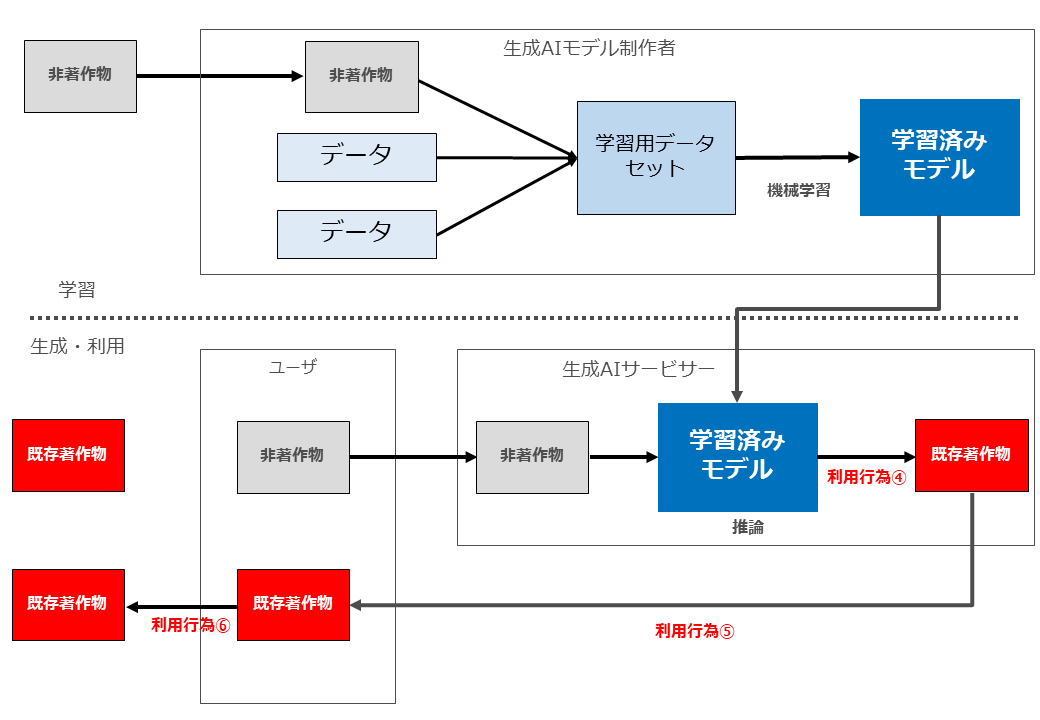
(6) 非著作物等を入力し、既存著作物と類似するAI生成物を生成するパターン(パターン4)
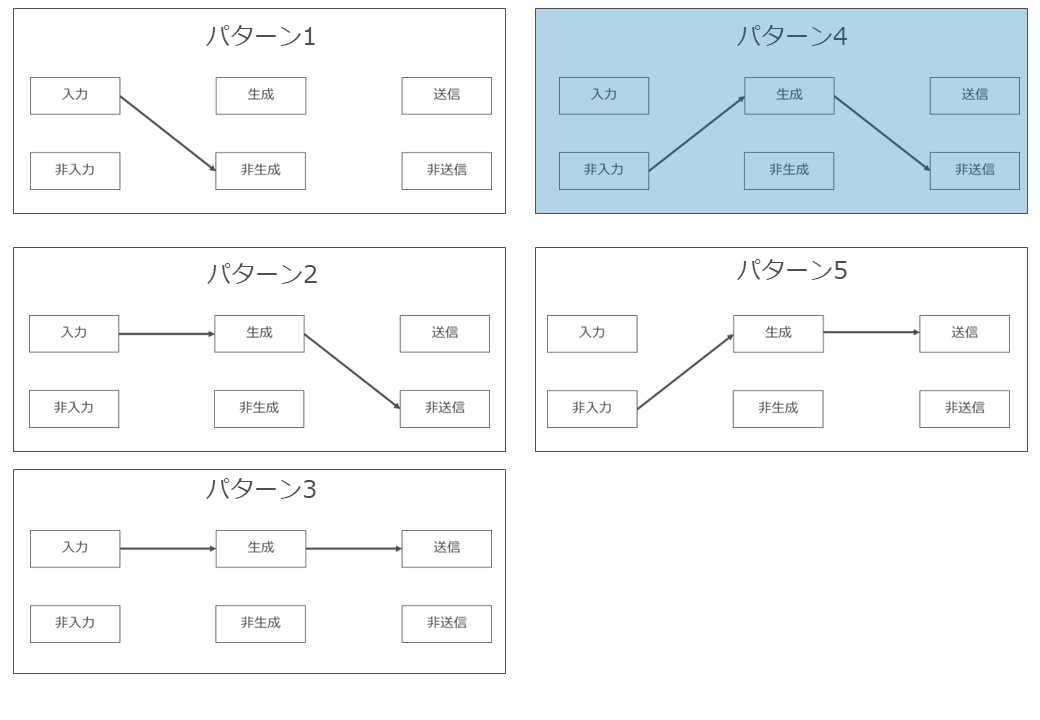
ア どのようなパターンか
生成AIに生成指示や非著作物を入力したところ、生成AIによる処理結果として既存著作物の類似著作物が生成されたが、当該類似著作物を利用(公衆送信・譲渡等)していないパターンです。
このパターンは、ユーザーが既存著作物の存在を知っているか否かによって結論が異なります(パターン1~3は、ユーザー自身が既存著作物を生成AIに入力していますので、当然ユーザは既存著作物の存在を知っています)。
イ ユーザーが既存著作物の存在を知っている場合
(ア) 類似性・依拠性
問題なく肯定されます。
依拠性についても、既存著作物の存在を認識しつつ生成していることから問題なく肯定されると思われます。
(イ) 権利制限規定
パターン2で述べたことが当てはまり、私的利用目的複製・検討過程における利用が適用される可能性があります。
イ ユーザーが既存著作物の存在を知らない場合
このパターンの場合は、ユーザーが既存著作物の存在を認識せずに、偶然既存著作物と類似するAI生成物を生成していることから、依拠性はなく独自創作として適法と考えられます。
依拠性が否定されることから、権利制限規定の適用を検討するまでもなく適法です。
もちろん、これは「理屈上はこうなる」という話でして、実際に既存著作物と類似したAI生成物を生成した場合に、「既存著作物の存在を知らなかった」という主張が通るかどうかは別問題です。
この点については、従来も依拠性の判断において問題になっていた点でして、下記文化庁資料P20に記載されているとおり、過去の裁判例では「後発の作品の制作者が、制作時に既存の著作物(の表現内容)を知っていたか(既存の著作物に接する機会があったか、既存の著作物が周知・著名だったか等)「後発の作品と、既存の著作物との同一性の程度(経験則上、依拠していない限りこれほど類似することはないといえる程の顕著な類似性、誤植・透かし・無意味な部分などを含めて既存著作物と一致していること等)「後発の作品の制作経緯(既存の著作物に依拠せず専ら独自創作した経緯を合理的に説明できていること、制作の時系列等)」を総合的に考慮して判断されることになります。

文化庁資料P20
(7) 非著作物等を入力し、既存著作物と類似するAI生成物を生成し配信するパターン(パターン5)
ア どのようなパターンか
生成AIに生成指示や非著作物を入力したところ、生成AIによる処理結果として既存著作物の類似著作物が生成し、当該類似著作物を利用(公衆送信・譲渡等)するパターンです。
このパターンは、パターン4と同様、ユーザーが既存著作物の存在を知っているか否かによって結論が異なります。
イ ユーザーが既存著作物の存在を知っている場合
(ア) 類似性・依拠性
問題なく肯定されます。
依拠性についても、既存著作物の存在を認識しつつ生成していることから問題なく肯定されると思われます。
(イ) 権利制限規定
パターン2で述べたことが当てはまり、私的利用目的複製・検討過程における利用が適用される可能性があります。
イ ユーザーが既存著作物の存在を知らない場合
パターン4で述べたことが当てはまります。
本当に「ユーザーが既存著作物の存在を認識せずに、偶然既存著作物と類似するAI生成物を生成した」ということであれば、依拠性はなく独自創作として適法と考えられます。依拠性の判断要素についても先ほど紹介したとおりです。
(8) まとめ
生成・利用段階に関するまとめです。
・ 生成・利用段階を検討する際には、「著作物の入力行為」「AI生成物の生成行為」「AI生成物の送信行為」の3段階に分けて検討することが必要。
・ 具体的には5つのパターンがあり、各パターンにおいて、著作物の利用行為ごとに①類似性と依拠性、②権利制限規定(情報解析、私的利用、検討目的利用等)適用有無を検討する必要がある。
・ 「著作物の入力行為」「AI生成物の生成行為」「AI生成物の送信行為」は独立した利用行為であるため、基本的には、個別に適法性を検討すればよいが、それらの行為が連続して行われた場合には、特に「著作物の入力行為」の「享受目的」の併存有無を判断する際に各行為を完全に切り離して検討することができない。すなわち、パターン1、パターン2,パターン3それぞれにおいて、「著作物の入力行為」の「享受目的」の併存有無の判断は異なる。
4 機械学習×生成・利用と著作権侵害
(1) 分析
「2 生成AIを作ること(機械学習)と著作権侵害」は学習にのみ既存著作物が利用されているパターン、「3 生成AIを利用してAI生成物を生成・利用することと著作権侵害」は生成・利用にのみ既存著作物が利用されているパターンについて検討をしました。
ここでは、学習にも生成・利用にも既存著作物が利用されているパターンについて検討します。
「生成・利用」において既存著作物が利用されているパターンは前述のように5つありますが、この5つのパターンは以下のように分類できます。
(1) 生成・利用において著作権侵害が成立するパターン
パターン3,及びパターン5においてユーザーが既存著作物を知っているパターン
(2) 生成・利用において著作権侵害が成立しないパターン
(2)-1 生成・利用行為についてなんらかの権利制限規定が適用されることにより適法であるパターン
パターン1,パターン2、パターン4
(2)-2 生成・利用行為について依拠性が否定されることにより適法であるパターン
パターン5においてユーザーが既存著作物を知らないパターン
まず、このうち「(1) 生成・利用において著作権侵害が成立するパターン」については、学習に既存著作物が利用されていない場合でもユーザーによる利用行為に著作権侵害が成立するのですから、学習に既存著作物が利用されているパターンであっても当然ユーザーに著作権侵害が成立します。
次に、「(2) 生成・利用において著作権侵害が成立しないパターンのうち「(2)-1 生成・利用行為についてなんらかの権利制限規定が適用されることにより適法であるパターン」については、学習に既存著作物が利用されていても、生成・利用行為に適用される権利制限規定の適用がなくなるという関係には立たないため、権利制限規定が適用されれば、ユーザーの行為は適法であると考えます。
難問は(2)のうち「(2)-2 生成・利用行為について依拠性が否定されることにより適法であるパターン」です。
このパターンは、「パターン5においてユーザーが既存著作物を知らないパターン」つまり「学習用データに既存著作物が利用されているが、ユーザーがそれを知らずに非著作物を入力指示し、結果的に既存著作物の類似著作物が出力された」というパターンです。
これが従来から「生成AIと著作権侵害」として議論されてきたパターンです。
生成・利用フェーズにおいて生成されたAI生成物がユーザー内部にとどまっているのか、ユーザーが当該AI生成物を外部に配信等しているのかによって以下の2つに分かれます。
このケースには、ユーザーによる生成行為・配信行為という著作物の利用行為(利用行為④⑤⑥)に、既存著作物への「依拠性」が認められるか否かが問題となります。
多数説は、学習用データの中に既存著作物が含まれている以上は依拠性を肯定しますが、私は違う立場をとっています。
この議論について書き始めると長くなるので詳細は別記事に譲りますが、私の意見の概要は以下のとおりです(拡散モデルを用いた画像生成AIを前提としています)。
・ 学習済みモデルの中の学習済みパラメーターは、学習段階において「当該画像を表現するテキスト+画像」によって訓練され「あるテキストが生成段階で入力されると、当該テキストに沿った画像を生成する」という役割を果たす。
・ そして、学習済みパラメーターは「ある特定のテキストが生成段階で入力されると、学習段階で当該テキストと共に学習された画像を非常に高い確率で生成する」状態のパラメーターと「ある特定のテキストが生成段階で入力されても、表現の幅の広いバラバラの画像を生成する」パラメーターまで様々なものがある。前者は、いわば「精度の高い」(テキストと画像が一対一対応になっている)パラメーターで、後者は「精度の低い」(1つのテキストに対して多数の画像が対応している)パラメーター。
・ 依拠性の議論においては、「学習段階で既存著作物が利用されているか」だけではなく、学習の結果生成された学習済みパラメーターの状態を区別して議論すべき。前者については依拠性が肯定されるが、後者については依拠性は否定される。
(2) 責任主体
著作権侵害が生じる場合、「誰が当該著作権侵害の責任を負うか(責任主体)」という問題があります。
本記事では、「2 生成AIを作ること(機械学習)と著作権侵害」「3 生成AIを利用してAI生成物を生成・利用することと著作権侵害」「4 機械学習×生成・利用と著作権侵害」の順番で検討していますが、このうち「2 生成AIを作ること(機械学習)と著作権侵害」については、既存著作物を用いて学習行為を行っている生成AI制作者が責任主体になります。
また、「3 生成AIを利用してAI生成物を生成・利用することと著作権侵害」においては、生成・利用フェーズにおいて、既存著作物を生成AI入力したり、AI生成物を生成したりしているユーザーが責任主体となります。
難しいのは「4 機械学習×生成・利用と著作権侵害」における責任主体です。ユーザーの責任主体性はすでに議論したところですが、生成AIを利用してユーザーが著作権侵害行為を行った場合に、当該著作権侵害に用いられた生成AIの制作者にも著作権侵害の責任が生じるか、という問題があります。
本記事では紙幅の関係上詳細には検討しませんが、仮に生成AIを利用してユーザーが著作権侵害を行った場合に生成AI制作者にも著作権侵害の責任があるのであれば、生成AIの普及に大きな影響があることから、かなり大きな問題です。
5 まとめ
以上大変長くなりましたが、まとめです。
本記事では「1 議論の前提」でまず前提を抑えた上で「2 生成AIを作ること(機械学習)と著作権侵害」「3 生成AIを利用してAI生成物を生成・利用することと著作権侵害」「4 機械学習×生成・利用と著作権侵害」の順番で検討しました。
(1) 生成AIを作ること(機械学習)と著作権侵害
– 生成AIを作ること(機械学習)のために既存著作物を利用することは著作権法30条の4第2号により原則として適法だが、2つ例外がある。
– 1つは、「学習対象著作物の「享受目的」が併存している場合」。ただし、ただし、そのような「享受目的」を安易に認めるべきではない。
– もう1つの例外は30条の4の但書が適用される場合。「情報解析を行う者の用に供するために作成されたデータベースの著作物の利用行為」は但書に該当するが、それ以外のケースは議論中。
(2) 生成AIを利用してAI生成物を生成・利用することと著作権侵害
– 生成・利用段階を検討する際には、「著作物の入力行為」「AI生成物の生成行為」「AI生成物の送信行為」の3段階に分けて検討することが必要。
– 具体的には5つのパターンがあり、各パターンにおいて、著作物の利用行為ごとに①類似性と依拠性、②権利制限規定(情報解析、私的利用、検討目的利用等)適用有無を検討する必要がある。
– 「著作物の入力行為」「AI生成物の生成行為」「AI生成物の送信行為」は独立した利用行為であるため、基本的には、個別に適法性を検討すればよいが、それらの行為が連続して行われた場合には、特に「著作物の入力行為」の「享受目的」の併存有無を判断する際に各行為を完全に切り離して検討することができない。すなわち、パターン1、パターン2,パターン3それぞれにおいて、「著作物の入力行為」の「享受目的」の併存有無の判断は異なる。
(3) 機械学習×生成・利用と著作権侵害
– 学習にも生成・利用にも既存著作物が利用されているパターン
– 基本的にはを抑えた上で「2 生成AIを作ること(機械学習)と著作権侵害」「3 生成AIを利用してAI生成物を生成・利用することと著作権侵害」で述べたことがそのまま当てはまるが、「学習用データに既存著作物が利用されているが、ユーザーがそれを知らずに非著作物を入力指示し、結果的に既存著作物の類似著作物が出力された」パターンは依拠性が問題となり、難問。
【告知】
STORIA法律事務所では7月、8月に生成AI関連のオンラインセミナーを開催いたします。詳細は以下のとおりです。
▼ Day1(2023年7月21日(金)13:00~16:00)
生成AIを企業内の業務で活用するための法務・知財戦略▼ Day2(2023年7月24日 (月) 13:00 – 16:00)
生成AIサービス提供事業者のための法務・知財・契約戦略▼ Day3(2023年8月10日 (木) 13:00 – 16:00)
AIと著作権法~生成AIを中心に~各セミナーは、ざっくり言うとDay1は、生成AIサービスを業務で「利用する」事業者向けのセミナー、Day2は生成サービスを「開発・提供する」事業者向けのセミナーです。そして、Day3は、AI(主として生成AI)と著作権について広く深く検討する、(ややマニアックな)セミナーです。
ご興味がある方は是非お申し込み下さい!












