人工知能(AI)、ビッグデータ法務
「AI・データの利用に関する契約ガイドライン」に学ぶAI開発契約の8つのポイント

Contents
- 1 ■ はじめに
- 2 ■ AI開発契約において「性能保証」「検収」「瑕疵担保」についてはどのように定めればいいのか(性能保証、検収、瑕疵担保)
- 3 ■ 生成された学習用データセット、学習済みモデル、学習済みパラメータは誰がどのような権利を持っているのか(権利・知財)
- 3.1 なぜ交渉が難航するのか
- 3.2 ではどうしたらよいのか
- 3.3 「1 材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく」「2 1についてデフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく」
- 3.4 「3 契約条項をどのようにして自社に有利にデザインするかを知っておく(「権利帰属」にこだわらず「利用条件」で「実」をとる)」
- 3.5 「4 契約の限界を知っておく」
- 4 ■ AI開発・利用に際して生じる可能性のある損害についてAI開発契約ではどのように定めたら良いか(責任)
- 5 ■ まとめ~「AI・データの利用に関する契約ガイドライン」に学ぶAI開発契約の8つのポイント~
■ はじめに
最近、AI開発契約に関するご相談やご依頼を頂くことが急速に増えています。
AI開発をベンダに発注しようとするユーザや、ユーザからデータの提供を受けてAI開発を受託しようとするAIベンダ双方の立場からご相談を頂くのですが、相談内容は
・ ユーザから学習済みモデルを用いた出力の精度について一定の保証をするようにと強く要請された場合、AIベンダはどのように対応すべきか
・ AI開発契約において検収基準や瑕疵担保についてどのように定めたら良いか
・ 開発成果に関する権利や知的財産権に関してどのようなポイントに着目して交渉し、どのような契約条項に落とし込んだら良いのか
・ ユーザの提供データを用いてベンダが開発したAIを組み込んだシステムが誤作動をしてユーザや第三者に損害を与えた場合、誰が責任を負うのか。
・ AIの誤作動に備えて、AI開発契約においてはどのような定めをすべきか。
など様々です。
これらAI開発契約に関する相談を分類すると、ほぼ以下の3つの領域に収まります。
1 AI開発契約において「性能保証」「検収」「瑕疵担保」についてはどのように定めればいいのか(性能保証、検収、瑕疵担保)
2 生成された学習用データセット、学習済みモデル、学習済みパラメータは誰がどのような権利を持っているのか(権利・知財)
3 AI開発・利用に際して生じる可能性のある損害についてAI開発契約ではどのように定めたら良いか(責任)
これら現場の悩みは一言で言うと「AIソフトウェア開発と通常のルールベースのソフトウェア開発との相違」に由来するのですが、特に2の「権利・知財」に関してはユーザ・ベンダ双方の主張が激しく対立することもあります。
そのため、開発契約の締結交渉に非常に長い時間がかかり、結局破談になったり他社に遅れを取って競争力を失うケースなどがあります。
つまり、AI開発契約において、上記3領域についての交渉がうまくいかないということは、個々の企業の不利益に直結しますし、ひいては日本のAI開発にとっても大きな障害となるということです。
そこで、AI開発契約締結に際しての一定の指針が必要となるのですが、この点、非常に参考になるのが経済産業省が2018年6月15日に策定した「AI・データの利用に関する契約ガイドライン」です。
このガイドラインは「データ編」と「AI編」に分かれており、私はこのガイドラインのうちAI編の検討委員・作業部会委員を務めました。もっとも、ガイドラインはAI編だけでも180ページ以上あるため、ガイドラインをわかりやすく説明してほしいという声を多数お聞きします。
そこで、私の個人的な見解に基づいて、「AI・データの利用に関する契約ガイドライン(AI編)」(以下AIガイドラインといいます)をもとに「『AI・データの利用に関する契約ガイドライン』に学ぶAI開発契約の8つのポイント」を整理してみました。
なお、これらの記事はAIガイドラインを題材にした私個人の見解であって、「ガイドラインの概要」や「ガイドラインのエッセンス」ではないですし、ましてやガイドラインの公的な解釈ではないことを、あらかじめお断りいたします。
正確なガイドラインの内容は是非ガイドライン本文を参照して頂ければと思います。
また、「AI」という用語の意味は多義的ですが、AIガイドラインでは「AI技術」のことを「『機械学習』、またはそれに関連する一連のソフトウェア技術のいずれか」という意味で使っていますので、本記事では「AI」という用語を「(統計的」機械学習」という意味で使っています。
「『AI・データの利用に関する契約ガイドライン』に学ぶAI開発契約の8つのポイント」の全体像は以下のとおりです。
「AI・データの利用に関する契約ガイドライン」に学ぶAI開発契約の8つのポイント
1 性能保証、検収、瑕疵担保
(1)AIの特性と限界の相互理解
(2)プロセス・契約を分割する
(3)開発契約の内容を工夫する2 権利・知財
(1)材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく
(2)(1)についてデフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく
(3)契約条項をどのようにして自社に有利にデザインするかを知っておく(「権利帰属」にこだわらず「利用条件」で「実」をとる)
(4)契約の限界を知っておく3 責任
AI開発における「責任」の種類を知り、契約でコントロールする
■ AI開発契約において「性能保証」「検収」「瑕疵担保」についてはどのように定めればいいのか(性能保証、検収、瑕疵担保)
なぜ問題になるのか
【よくある質問】
・ ユーザから学習済みモデルを用いた出力の精度について一定の保証をするようにと強く要請された場合、AIベンダはどのように対応すべきか
・ AI開発契約において検収基準や瑕疵担保についてどのように定めたら良いか
「性能保証、検収、瑕疵担保」は、AI開発契約の契約交渉で問題となることが非常に多い領域です。
AI技術を用いない通常のシステム開発契約においては、成果物の性能についてベンダが一定の性能を保証したり、成果物について一定の検収基準に従った検収を行って合否の判定を行ったり、成果物について瑕疵が存在した場合の瑕疵担保責任を定めるのが通常です。
そのため、AI開発契約においても、ユーザはベンダに対して一定の性能保証、検収規定や瑕疵担保条項を盛り込むように要求することが多いのです。
しかしAIソフトウェアの場合は、その技術的特性から「訓練データに統計的バイアスが含まれることが避けられないため、未知のデータに対する性能保証は原理的に困難」「何か不具合が生じた場合でも、その原因(データの品質、ハイパーパラメータ設定、ソースコードのバグ等)が複数存在し問題の切り分けが困難」「成果物の検収に際して学習に利用しない独立したデータセットが必要であり、かつ当然のことだが未知データでのテストが不可能」という特徴を有しています。
そのため、ベンダはユーザの上記要求に対して応じられないとして拒絶することが多いのですが、そこでベンダとユーザの歩み寄りが不可能となってしまうケースがあるのです。
この通常のシステム開発とAIソフトウェア開発とで「性能保証、検収、瑕疵担保」に関する双方の意見が対立する原因は、開発手法が、通常のシステム開発が「演繹的」であるのに対して、AIソフトウェアが「帰納的」である点に起因します。
「演繹的」と「帰納的」についての詳細はこちらの記事をご覧ください。
【参考記事】
渋谷の牛タン屋で横にいたカップルとAI開発における演繹と帰納について
ちなみに、AIソフトウェア開発案件において、当初ユーザーサイドのビジネス部門や技術部門とベンダとが非常に盛り上がり「ぜひこの案件やりましょう!」となって、その話がユーザサイドの法務・知財部門に上がった瞬間にストップがかかるケースは非常に多いです。それは、このような「性能保証・検収・瑕疵担保」が通常のシステム開発とはかなり違うためです。
ではどうすればいいのか
問題はこのような「通常のシステム開発とAIソフトウェア開発の違い」があったとして、AI開発契約締結に際して、それをどのように乗り越えるか、という点です。
先程の「渋谷の牛タン屋で横にいたカップルとAI開発における演繹と帰納について」にも少し書きましたが、私は以下の3点がポイントだと考えています。
1 AI開発の特性をユーザとベンダが理解すること
2 開発プロセス及び契約の分割
3 契約内容の工夫
1 AI開発の特性をユーザとベンダが理解すること
先程書いたように通常のシステム開発とAIソフトウェア開発においてはそもそもの開発手法の発想が異なるわけです。その点についてユーザ・ベンダが共通認識を持つというのがとても重要です。
実はAIガイドラインも、この点を非常に意識して作られました。
このガイドラインが、かなりの分量を割いてA技術について記述している(「第2 AI技術の解説」)のはそのためです。
AI開発に関しては技術者向けの書籍や情報は多数存在していますが、企業の法務・知財部門の方がAIソフトウェアの技術的特性やAI開発と通常のシステム開発の相違を学べるような平易な書籍類はこれまでなかったように思います。
AIガイドラインにおいては、「第2 AI技術の解説」として「1 基本的概念の説明」「2 対象とするAI技術」「3 想定するAI技術の実用化の過程」「4 AI技術を利用したソフトウェア開発の特徴」の各項目に分けてAI開発における基礎概念、AIの技術的特性、利点と限界について詳細かつできる限りわかりやすく記載しています。
ぜひ、ユーザとベンダの契約交渉が煮詰まったとき、ユーザの技術部門が社内で知財・法務部門あるいは経営トップの理解を得たいときに、このAIガイドラインを利用してください(宣伝)。
2 開発プロセス及び契約の分割
次に重要なのが「開発プロセス及び契約の分割」です。
AIソフトウェアの開発の特徴を非常に乱暴に言ってしまうと「どのようなものができあがるか事前に予測することがユーザ・ベンダ双方にとって困難であること」、要するに「開発を進めてみないと、うまくいくかどうかわからない」という点にあります。
この「うまくいくかどうかわからない」というのは「ベンダはわかっているけどユーザはわからない」という情報の非対称性の話ではなく、「ベンダもユーザもわからない」ということを意味しています。
このような特徴はユーザ・ベンダに双方にとって大きなリスクとなります。
このリスクをコントロールするための一つの方法としてAIガイドラインで提唱しているのが開発プロセス及び契約を分割する「探索的段階型」の開発手法です。具体的には、AIソフトウェアの開発を、①アセスメント段階、②PoC段階、③開発段階、④追加学習段階の4段階に分けた開発手法です。
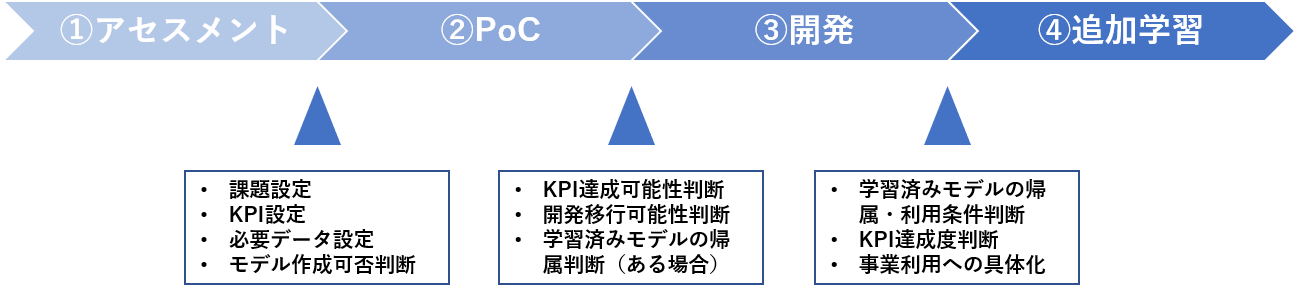
AIガイドラインより
各段階の目的・成果物・契約内容の概要は以下のとおりです。

AIガイドラインより一部変更の上引用
ちなみに「4つの段階に分ける」こと自体が重要なのではなく、「うまくいくかどうかわからないから少しつずつ進めていって、うまくいきそうなら次のステップに行き、無理そうなら中止する。それによってユーザ・ベンダ双方のリスクをコントロールする」という点が本質です。
ですので、上記4つの段階に分割することが必須というわけではもちろんなく、開発規模によっては、①アセスメント段階、②PoC段階が一体となることもあるし、②PoC段階を更に複数に分割することもあります。
3 契約内容の工夫
最後に契約内容の工夫です。
通常のシステム開発とAIソフトウェアの開発における契約内容を対比すると以下のようになります。
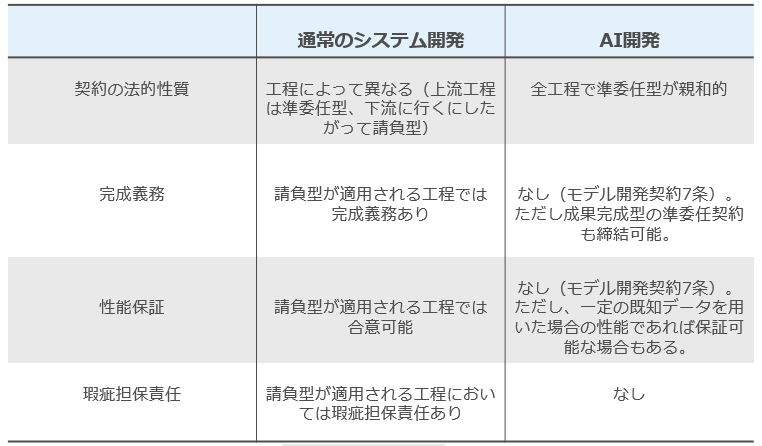
私はセミナーなどでこの図を使って説明することが多いのですが、そこで一番聞かれる質問は「現場にAIソフトウェアを投入し、未知のデータが入力された場合に性能保証ができないのは理屈としてはわかった。しかし多額のお金を支払って開発したAIソフトウェアが一切性能保証できない、というのはやはりユーザとしては納得し難い。契約上の工夫でそこについてなんとかできないのか」というものです。
この点についてガイドラインで提示されている方法は「学習に利用しない一定の既知の評価用データを入力した場合の性能保証行う方法」と「準委任契約における成果完成型を選択する方法」です。
前者については未知データ入力の場合の保証は難しいとしても、既知の評価用データ入力の場合の保証は技術的には可能だからです。もっとも、この場合、当該評価用データが、AIを現場に投入した場合の実際の未知データの性質を十分に反映している必要があります。
後者については、準委任型契約には、委任事務の履行により得られる成果に対して報酬を支払うことを約する「成果完成型」と、委任事務の処理の割合に応じて報酬を支払う「履行割合型」があると言われており、そのうち「成果完成型」を選択するという意味です。
この「成果完成型」の準委任契約であれば、進捗に応じた成果(たとえば既知データに対する一定の性能など)に対して固定金額を支払うという合意をすることになり、成果未達成の場合のベンダのリスクを下げることができると考えられます。
■ 生成された学習用データセット、学習済みモデル、学習済みパラメータは誰がどのような権利を持っているのか(権利・知財)
次に権利・知財に関する問題です。
AIソフトウェアの開発に際して、成果物等に関する権利・知財について契約上どのように定めるかはユーザ・ベンダにとって非常に大きな関心事です。
典型的に寄せられる相談は「AIベンダとして、事業会社との共同プロジェクトを立ち上げる際の、知財・法務に対する最初のニギリ方 (契約書への文言の入れ方) が事業会社側、AIベンダ側とも曖昧なケースが多く、実際に売り上げが発生した際にモメそうな不安があります。」というようなものです。
なぜ交渉が難航するのか
AIソフトウェアの開発においては、通常のシステム開発以上に成果物の権利・知財に関する当事者双方の主張の対立が先鋭化することが多いのですが、その理由は以下の2点にあると思われます。
1 通常のシステム開発と異なり、AIソフトウェア開発においては複数の材料、中間成果物、成果物が存在する
2 開発に要する材料、中間成果物、成果物が高い価値を持ち、ユーザ・ベンダ共にそれらを独占/再利用したいという需要が存在する
まず、通常のシステム開発の開発工程をごくごく単純化すると以下のように、「『ベンダの労力やノウハウ』という材料を投入して『プログラムや文書類』という成果物を開発する」ということになります。

一方、AIソフトウェアシステム開発の開発工程は、以下のように「『生データ、学習用プログラム、労力、ノウハウ』という材料を投入することで『学習済みモデル』や「学習済みパラメータ』という成果物を開発するし、開発の過程で『学習用データセット』や『発明、ノウハウ』といった中間的な成果物が生じる」という点が大きな特徴です。
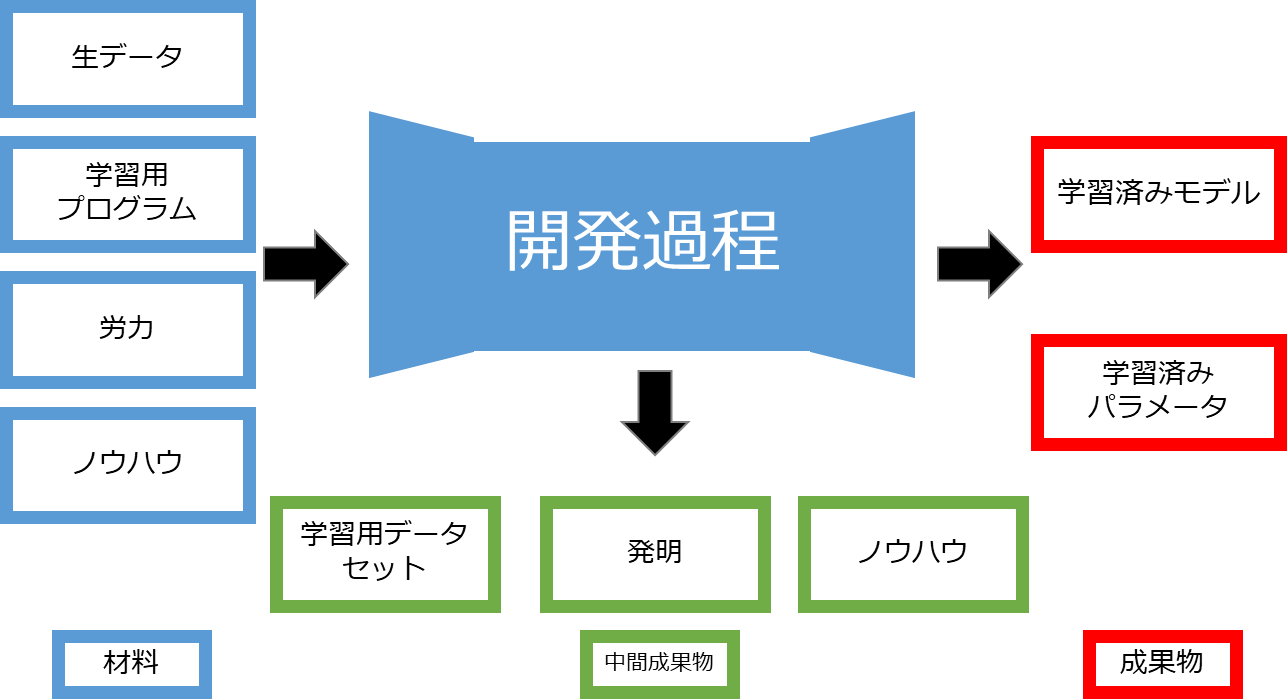
(ちなみに、ここでいう「成果物」とは契約上、納品や作成支援が合意されているものを指します。したがって「成果物」と「中間成果物」の区別は相対的なものでして、契約内容によっては学習用データセットが成果物として合意されることもあります。)
さらに、これらの材料、中間成果物、成果物が高い価値を持ち、ユーザ・ベンダ共にそれらを独占/再利用したいという意向を強く持ちます。
たとえばユーザが提供した生データを用いてベンダが学習済みモデルを生成するという典型的なケースを前提とすると、ユーザとベンダの成果物に関する意向は以下のように対立することになります。
▼ ユーザ
学習用データセット、学習済みモデルは自社のノウハウや機密が詰まった生データを用いて生成されたものであり、開発に際して委託料も支払っていることから、自社で独占したい。
▼ ベンダ
生データを用いて学習用データセットを生成する過程、学習済みモデルの生成過程いずれにおいても自社の高度のノウハウ及び多大な労力を用いていること、学習用データセットや学習済みモデルは再利用が可能であることから、委託を受けた本開発案件以外にも横展開したい。
そこで、この相反する2つの意向を調整する枠組みが必要となるのです。
ではどうしたらよいのか
この点について、私は以下のような枠組みで整理すればよいのではないかと考えています。
1 材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく
2 1についてデフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく
3 契約条項をどのようにして自社に有利にデザインするかを知っておく(「権利帰属」にこだわらず「利用条件」で「実」をとる)
4 契約の限界を知っておく
▼ まずは一般論
まず、これらについて説明する前に「法律と契約の関係」についての一般論について説明をします。
セミナーなどで「法律と契約の関係について知っていますか」と質問をすると、大抵の方は「法律に書いてあることでも、契約で法律とは別の約束をすれば原則として契約の方が優先する。」ということはご存知です。
一方「契約に定めていないことがある場合には、その点についての法律の規定があれば自動的に法律に従う。」ということについては案外ご存じない方も多いです。
2つ目の点についてはイメージはこんな感じです。
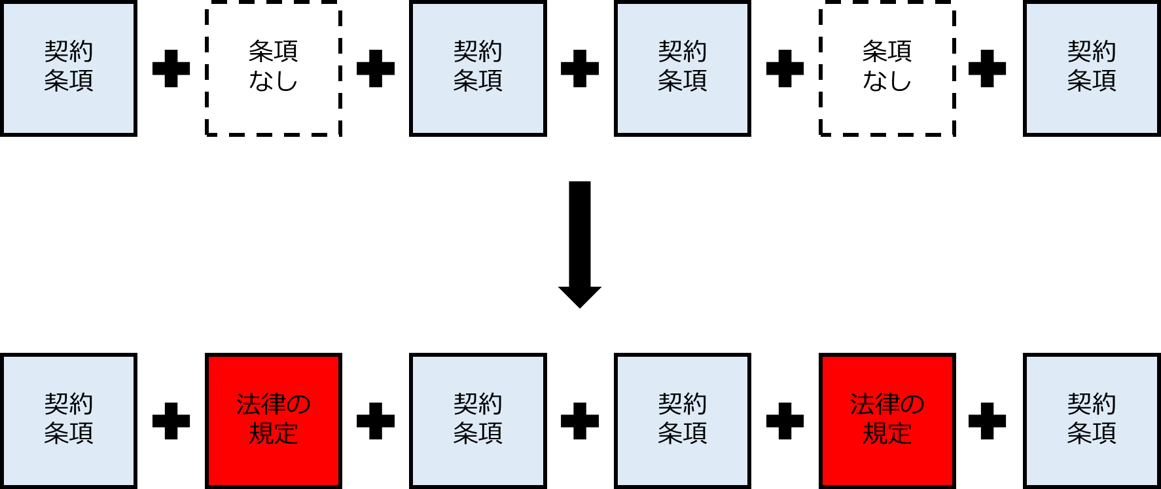
契約に定めていないことがある場合には、自動的に法律の規定が挿入されるイメージですね。
そして、この「法律と契約の関係」を簡単にマトリクスにまとめるとこのような関係になります。
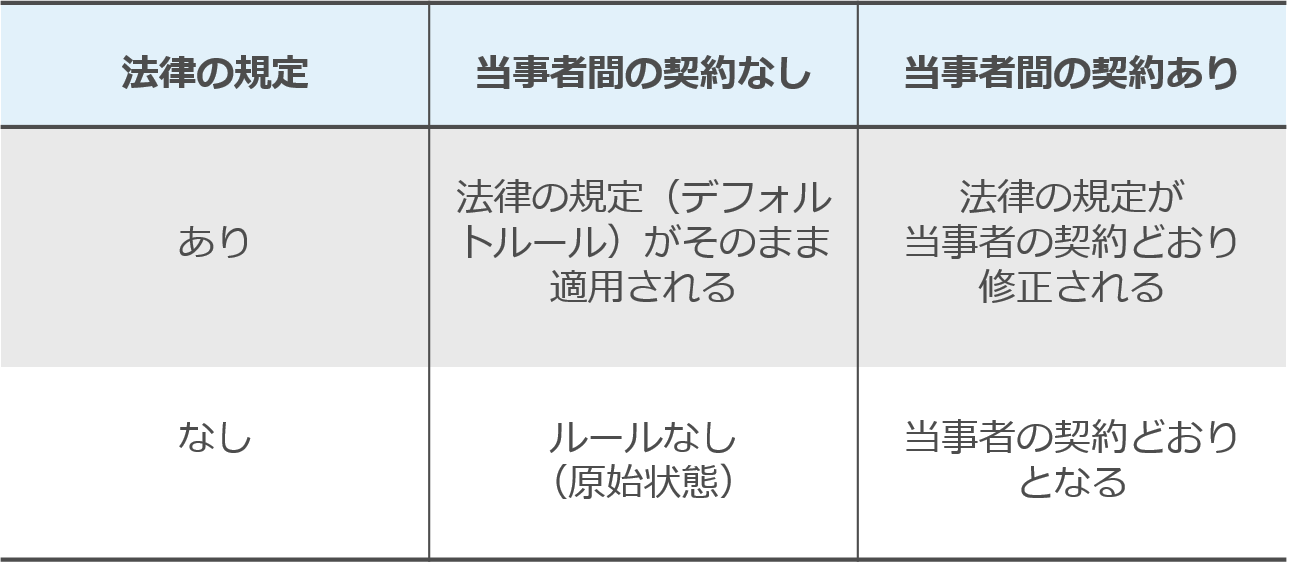
少し具体例を挙げます。
たとえば「委任契約において損害賠償に関して契約上特別の条項がある場合と、ない場合」を考えてみます。
債務不履行に関する損害賠償の範囲については民法416条に規定がありますが、それと別の契約上の条項(たとえば損害賠償の額を増額するなど)があった場合、その条項が法律に優先します。
逆に、損害賠償の範囲に関する条項が、契約上存在しなかった場合には、法律の規定通りとなります。
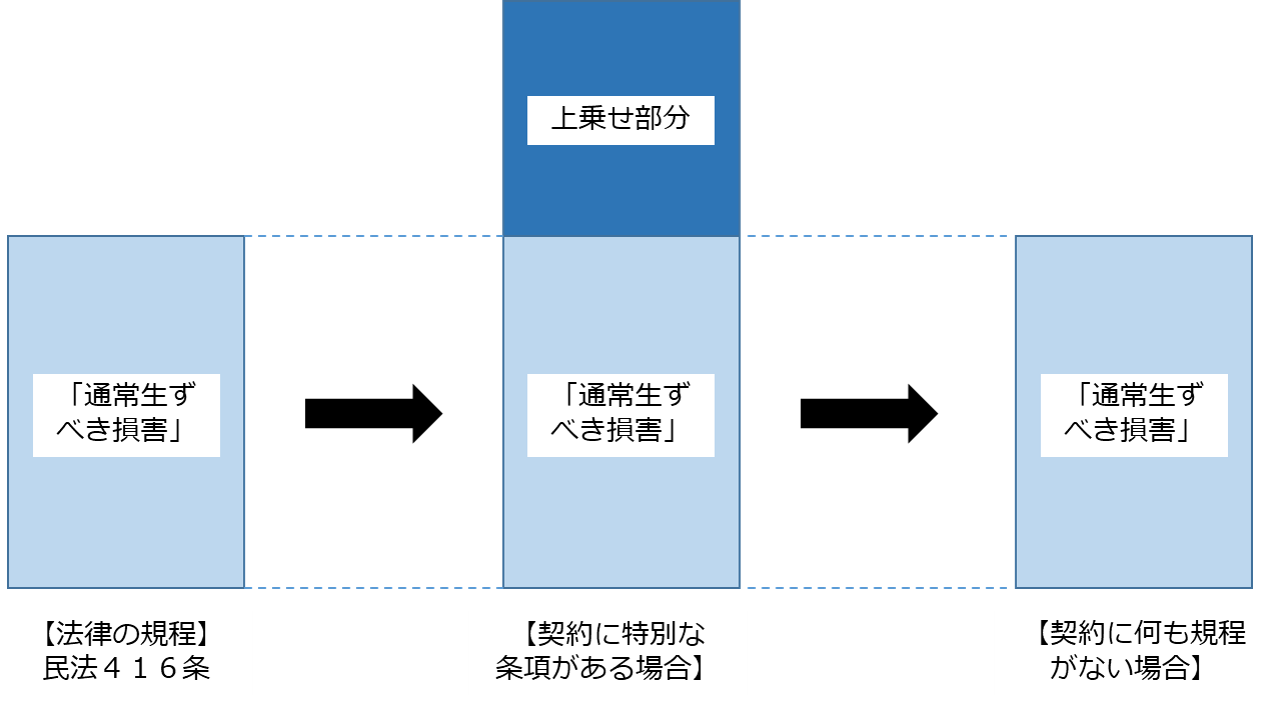
もう1つ事例を。
「ハードウェアベンダーが、ユーザの工場に納入した機器から生じるセンサデータを、ユーザからの同意を得てハードウェアベンダーに送信した場合、当該センサデータをベンダーはどの範囲で利用できるか」を考えてみます。
まず、センサデータについては、著作権などの知的財産権の対象ではありませんので、現行法上、誰が権利を持っているかや、誰が利用できるかの法律の規定が存在しません。
先ほどのマトリクスでいうと「法律の規定がない」という領域の話になります。
したがって、データの利用条件について、当事者間の合意が全くなかった場合には、法律上も、契約上も全くルールがない、つまり「原始状態」ということになります。
「原始状態」とは、つまり「持っている人が自由に使える」という意味であり、この例でいうと、ベンダはデータを自由に利用できるしユーザはベンダにデータの利用制限を課したり、データの引渡請求する権利はないということを意味します。
もちろん、データの利用条件について当事者の合意がある場合は、当該合意に従います。たとえば「機器の保守管理目的のため」という合意があればその範囲でのみベンダは利用できますし、それに加えて「ベンダのサービス・機器の改善のため」という合意があれば、その範囲でもベンダは利用可能ということになります。
▼ AI開発ではどうなるか
そしてこの一般的なルールをAI開発にあてはめるとこうなります。
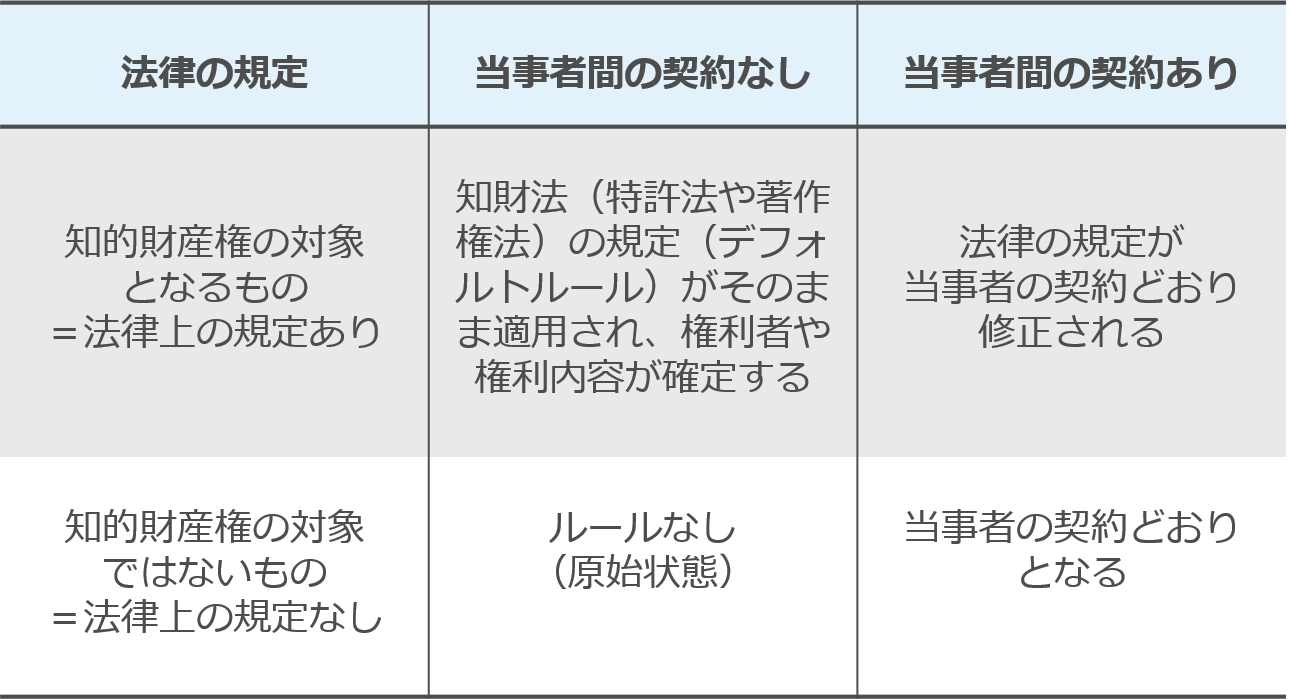
まず「1 材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく」という点です。
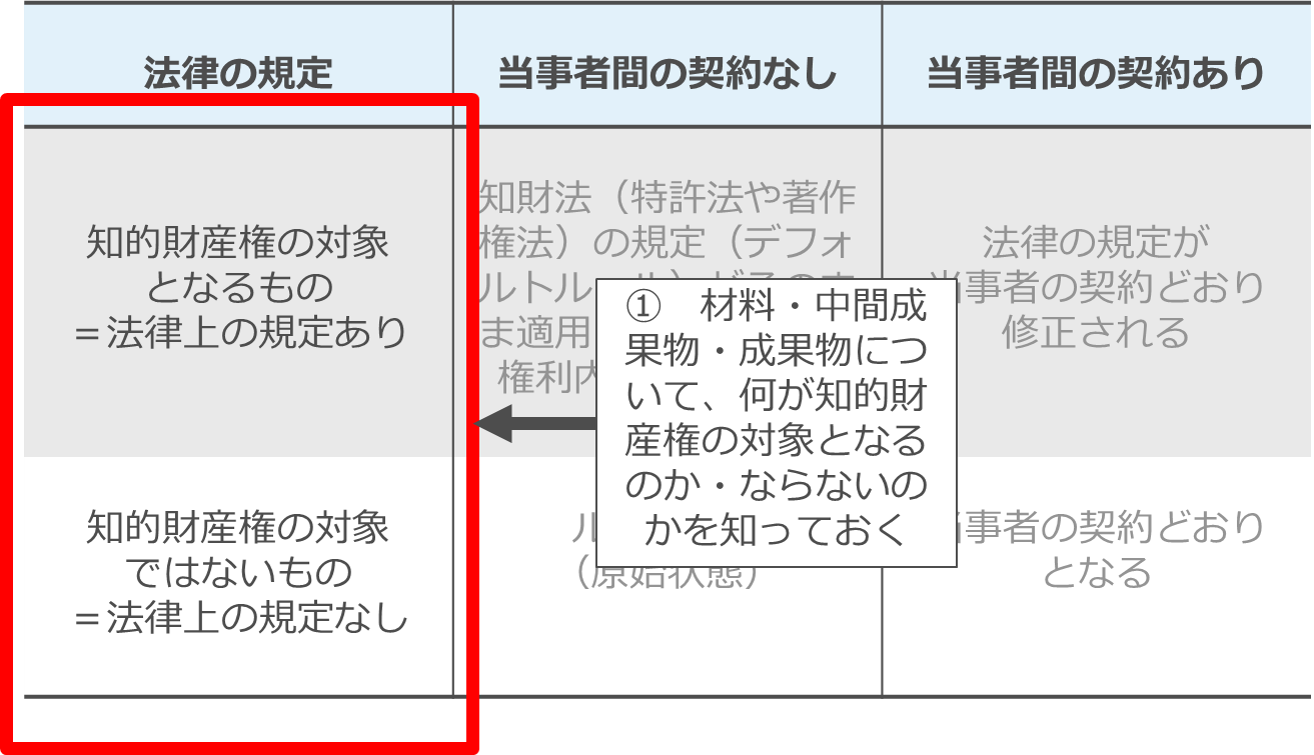
これは、知的財産権の対象となるかならないかで、その帰属や利用条件についてデフォルトルール(=法律上のルール)があるかないかが異なるためです。
次に「2 1についてデフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく」です。
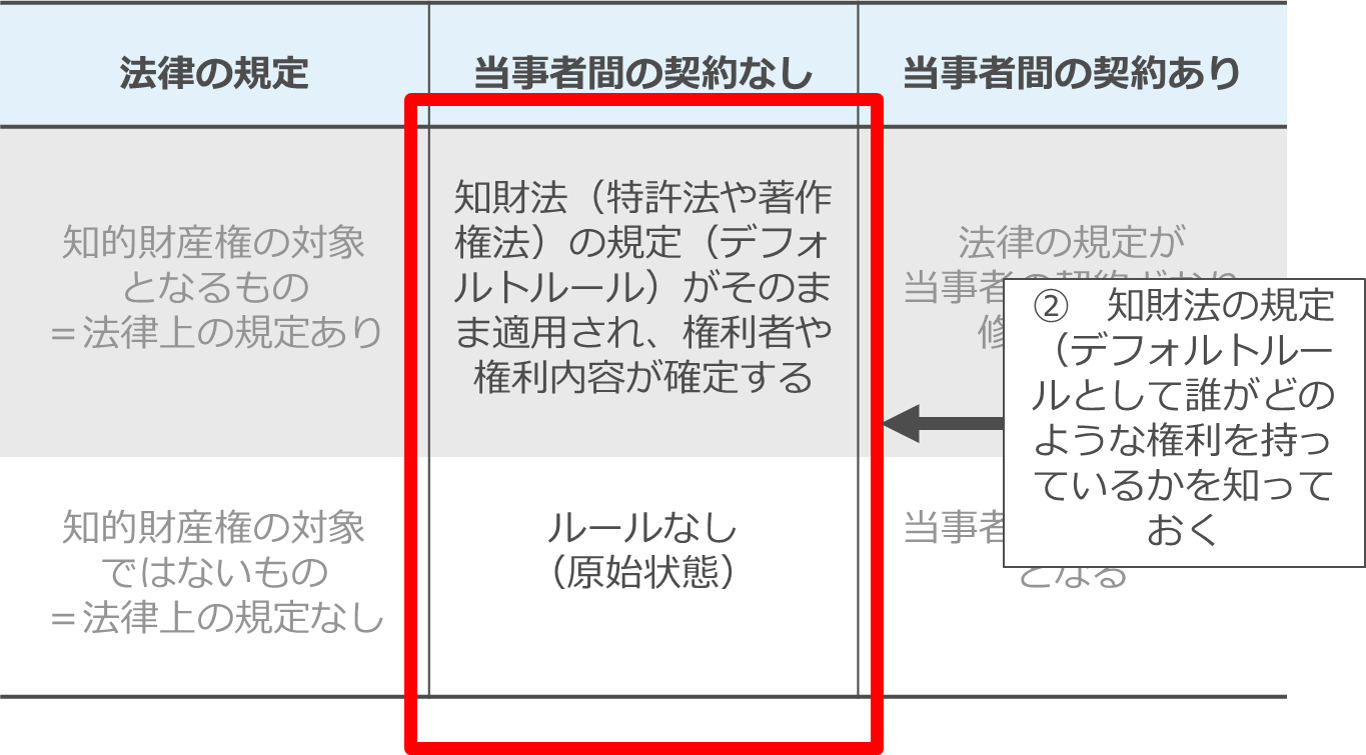
まず1で何が知的財産権の対象になるかを知ったうえで、2で対象となるものについての法律(特許法、著作権法など)上のルールを知っておくということです。
そのうえで「3 契約条項をどのようにして自社に有利にデザインするかを知っておく(「権利帰属」にこだわらず「利用条件」で「実」をとる)」です。

2の法律上のデフォルトルール、あるいは「原始状態」を、契約でどのようにデザインするかの問題です。
詳細は後述しますが、ここでのデザインの仕方が、AI開発契約における「権利と知財」に関する考え方の肝であり、AIガイドラインにおける非常に大きなポイントの1つです。
最後に「4 契約の限界を知っておく」です。
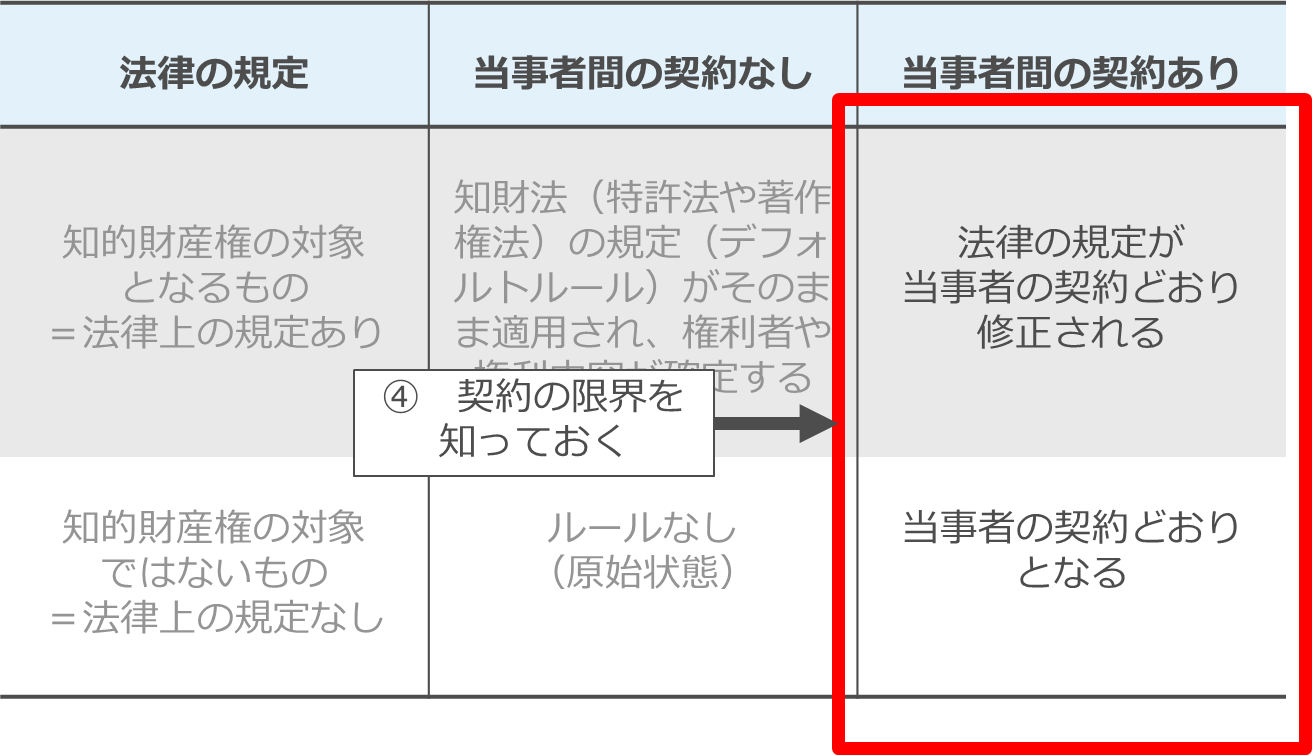
AIソフトウェアの場合、成果物等の権利帰属や利用条件を契約で定めていても、学習済みモデルに別のデータを用いて学習させた派生モデルや、入出力データのみを用いて別の学習済みモデルを生成する、いわゆる蒸留により生成された蒸留モデルに対して契約の効力が及ばない可能性があります。
それは契約の限界ではあるわけですが、その限界を知ることも重要です。
「1 材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく」「2 1についてデフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく」
この2点はまとめて説明したほうがわかりやすいのでまとめます。
ここで検討する必要がある対象物(材料・中間成果物・成果物)は、以下の6つです。
1 生データ
2 学習用データセット
3 学習用プログラム
4 学習済みモデル
5 学習済みパラメータ
6 ノウハウ
これら6つの対象物を現行の知財法で保護しようとすると、実際には特許法、著作権法、不正競争防止法(営業秘密等)の3つが考えられます。なお、不正競争防止法は「知的財産権」に関する法律ではありませんが、対象物が営業秘密や限定提供データに該当する場合には、その不正取得行為等が不正競争行為として差し止めや損害賠償請求の対象となりますので、同じように扱っています。
したがって、以下の表のブランク部分を埋めることが、ここでの目標になります。
1 生データ
(1) 知的財産権の対象となるのか・ならないのか
生データの種類によりますが、例えば機械の操業データ、センサデータや事実を示すデータなどについては知的財産権は発生しませんので、「営業秘密」(不競法2条6項) 「限定提供データ」(改正不競法2条7項)に該当する限りにおいて、保護されることになります。
営業秘密等にも該当しない生データについては、法律上のデフォルトルールがないということになります。
(2) デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
営業秘密等にも該当しない生データについては、知的財産権の対象ではないため誰も権利を持っていません。したがって、そのような場合において生データを誰がどのように利用出来るかについては、ユーザ・ベンダ双方の契約によって定めるしかないことになります。
2 学習用データセット
「学習用データセット」とは、生データに対して、変換・加工処理を施すことによって、学習作業を容易にするために生成された二次的な加工データのことを言います。
(1) 知的財産権の対象となるのか・ならないのか
学習用データセットは、情報の単なる提示に過ぎないため、「発明」に該当せず特許を受ける権利の対象とはならないことがほとんどだと思われます。
もっとも、個々のデータに著作物性がない場合でも、学習用データセットが「データベースの著作物」(著作権法12条の2)に該当すれば著作権が発生します。
「データベースの著作物」とは「その情報の選択又は体系的な構成によつて創作性を有するもの」を言いますが、効率的な機械学習・深層学習のために、生データを取捨選択したり、体系的な構成で整理した学習用データセットは「データベースの著作物」に該当する場合も多いと思われます。
また、「営業秘密」(不競法2条6項) 「限定提供データ」(改正不競法2条7項)に該当すれば保護されます。
(2) デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
学習用データセットが「データベースの著作物」に該当する場合、創作的な「情報の選択」又は「体系的な構成」を行った者が著作権者となります。
したがって、ベンダのノウハウのみを利用して加工行為を行ったのであればベンダが著作権者となりますし、ユーザとベンダが共同して創作的な行為を行ったのであればユーザ・ベンダの共同著作物となって双方が著作権を共有するということもありえます。
3 学習用プログラム
(1) 学習用プログラムとは
「学習用プログラム」とは、学習用データセットを利用して学習を行い、学習済みモデルを生成するためのプログラムを言います。
学習用プログラムは、ベンダが既に保有しているものを利用する場合や、具体的開発案件に即して一から開発する場合など様々なケースがありますが、実際には、OSS(オープン・ソース・ソフトウェア)が利用されることも多々あります。
(2) 知的財産権の対象となるのか・ならないのか
学習用プログラムは「プログラム」なので、通常のプログラムが知的財産権の対象となるかどうかと全く同じ話になります。
つまり、アルゴリズム部分は、特許法上の要件を充足すれば「物(プログラム)の発明」等として、特許法の保護を受けますし、ソースコード部分は著作権法による「プログラムの著作物」として著作権法上の保護を受けます(なお、オブジェクトコードに変換されても同様です。著作権法 10 条 1 項 9 号)
また、「営業秘密」(不競法2条6項) に該当すれば不正競争防止法で保護されます。
(3) デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
法律上、特許を受ける権利を取得するのは発明者(作成者)であり、著作権を取得するのは創作者(作成者)ですから、当該プログラムを発明・創作した者が特許を受ける権利・著作権を取得することになります。
したがって、学習用プログラムをベンダが一から開発したのであれば法律のデフォルトルールとしてはベンダが、特許を受ける権利も著作権も取得することになります。
なお、OSSとして提供されている学習用プログラムを利用する場合には、ベンダ・ユーザ共にそのライセンス内容に注意する必要があります。OSSのライセンス内容によっては、ソースコードの開示義務などがあるためです。
4 学習済みモデル
(1) 学習済みモデルとは
学習済みモデルは、学習用データセット同様、再利用可能であり、契約当事者の関心が非常に高い成果物です。
ただし、学習済みモデルに関しては、契約上・交渉上『学習済みモデル』という言葉が何を意味しているのかについて、慎重に見極める必要があります。
というのは、学習済みモデルは、「関数」「数理モデル」「アルゴリズム」「ネットワーク構造」「推論プログラム」「パラメータ」「それら各概念の組み合わせ」等多義的な意味を持っており、当事者が異なる意味で使うと大きなトラブルの原因となるからです。
ここでは、AIガイドラインと同様、学習済みモデルとは「『学習済みパラメータ』が組み込まれた『推論プログラム』」を指すものとします。
(2) 知的財産権の対象となるのか・ならないのか
学習済みモデルのうち「推論プログラム」部分については、学習用プログラムと同様に考えればOKです。
つまり、アルゴリズム部分は、特許法上の要件を充足すれば「物(プログラム)の発明」等として、特許法の保護を受けますし、ソースコード部分は著作権法による「プログラムの著作物」として著作権法上の保護を受けます。
たとえば、特定の開発課題の関係で非常に高い精度を持つ独自性の高いネットワーク構造を発見した場合、そのネットワーク構造については「物(プログラム)の発明」として特許出願が可能となる可能性があります。
また、「営業秘密」(不競法2条6項) に該当すれば不正競争防止法で保護されます。
学習済みモデルのうち「学習済みパラメータ」部分については後述しますが、結論的には知的財産権の対象にはならないものと思われます。
(3) デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
これも、「推論プログラム」部分については、学習済みプログラムと同様、ベンダが一から開発したのであれば法律のデフォルトルールとしてはベンダが特許を受ける権利も著作権も取得することになります。
5 学習済みパラメータ
(1) 学習済みパラメータとは
「学習済みパラメータ」とは、学習用データセットと学習用プログラムを用いた学習の結果、得られたパラメータ(係数)をいいます。
「学習用プログラムで自動的に生成される」「大量の数値の列」であり、ディープラーニングの場合で言うと、学習済みパラメータの中で主要なものとしては、各ノード間のリンクの重み付けに用いられるパラメータ等がこれに該当します。
(2) 知的財産権の対象となるのか・ならないのか
先ほど説明したように、学習済みパラメータは、「学習用プログラムで自動的に生成される」「大量の数値の列」であって創作性がないことから「発明」にも「著作物」にも該当しないものと思われます。
もっとも「営業秘密」(不競法2条6項) 「限定提供データ」(改正不競法2条7項)に該当すれば保護されます。
(3) デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
営業秘密等にも該当しない学習済みパラメータについては、知的財産権の対象ではないため誰も権利を持っていません。したがって、学習済みパラメータを誰がどのように利用出来るかについては、ユーザ・ベンダ双方の契約によって定めるしかないことになります。
6 ノウハウ
AIソフトウェアの開発に際しては様々なノウハウが必要となります。たとえば、「生データの取得・選択方法」「学習用データセットへの加工方法」「学習用プログラムを用いた効率的な学習方法」「学習済みモデルの本番環境における調製」などに関するノウハウです。
(1) 知的財産権の対象となるのか・ならないのか
ノウハウについては、無形の情報ですので、著作権の対象にはなりませんが、「発明」の要件を満たすノウハウであれば特許を受ける権利の対象になりえます。「営業秘密」(不競法2条6項) 「限定提供データ」(改正不競法2条7項)に該当すれば保護されます。
(2) デフォルトルール(=法律上のルール)として誰がどのような権利を持っているか
営業秘密等や発明に該当しないノウハウについては、知的財産権の対象ではないため誰も権利を持っていません。したがって、ノウハウを誰がどのように利用出来るかについては、ユーザ・ベンダ双方の契約によって定めるしかないことになります。
7 まとめ
以上をまとめると以下の表のように整理できます(追記あり)。
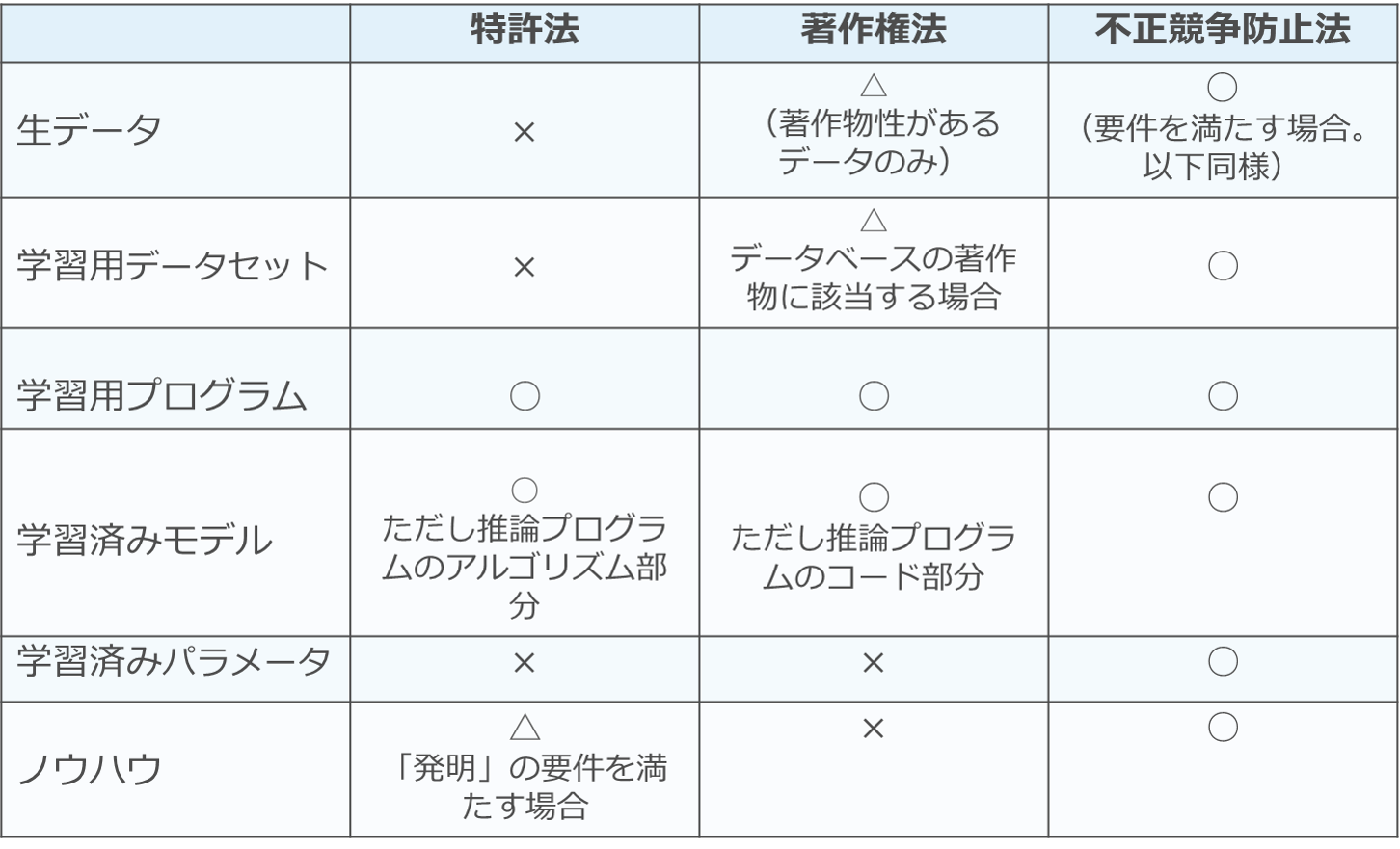
【追記】
なお、AIに関する知的財産権デフォルトルールについては、経産省の「オープンなデータ流通構造に向けた環境整備」(平成28年8月29日・経済産業省)にも類似の表が掲載されています(P82、以下「環境整備表」と言います。)ので、上記の「まとめ表」と「環境整備表」との関係について簡単に説明します(Takuji Hashizumeさん、ご指摘ありがとうございます!)。
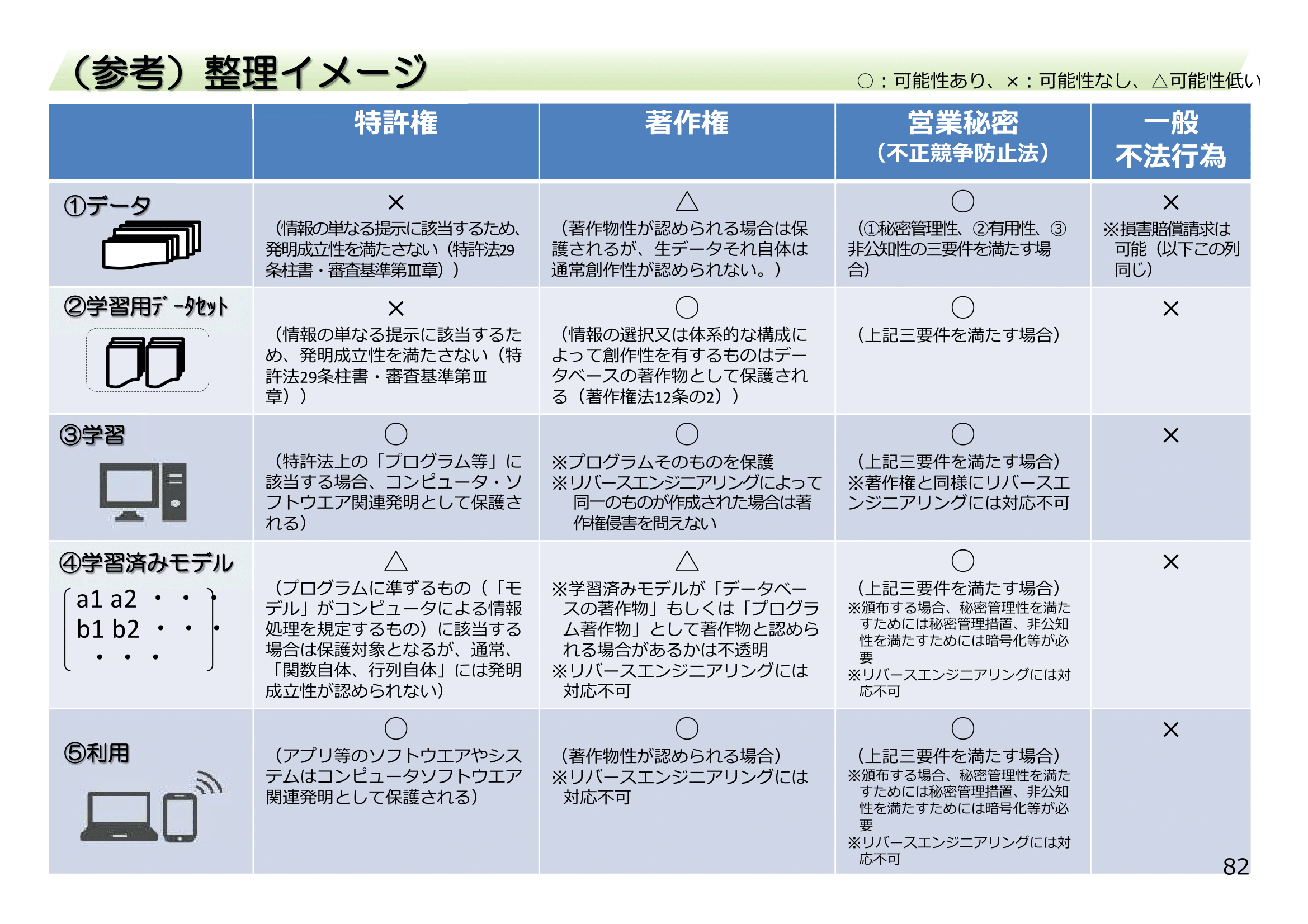
「オープンなデータ流通構造に向けた環境整備」(平成28年8月29日・経済産業省)より抜粋
まず、「(生)データ」については、生データの種類によりますが、例えば機械の操業データ、センサデータや事実を示すデータなどについては知的財産権は発生しませんが、著作物性があるデータ(写真、音声、映像、小説等)であれば著作権が発生いたしますので、その点について初出のまとめ表を修正し、環境整備表と合わせました。
次に「学習用データセット」については、まとめ表と環境整備表はほぼ同一のことを述べています。
また、境整備表の「学習」というのは、当該資料の78頁を見るとおそらく、まとめ表の「学習用プログラム」と同じ意味だと思われます。
さらに、環境整備表の「学習済みモデル」は、当該資料の79頁に「学習済みモデルは、計算機が計算した数字の羅列(行列等)・・・・・」とあることからすると、まとめ表の「学習済みパラメータ」のことだと思われます(もちろん、これはまとめ表と環境整備表のどちらが正しいということではなく、先程説明したように単なる学習済みモデルの定義付けの問題です)。
なお、環境整備表では、「学習済みモデル」(まとめ表で言うところの「学習済みパラメータ」)について特許法や著作権法で保護される可能性があると記載されていますが、私見では、先ほど説明した理由(「学習用プログラムで自動的に生成される」「大量の数値の列」であるという点)により、かなり難しいと思っています。
最後に、環境整備表の「利用」というのは、当該資料の75頁の「モデルをアプリに入れてソフトウェアとして利用」という説明からすると、おそらくまとめ表で言うところの「学習済みモデル」(「『学習済みパラメータ』が組み込まれた『推論プログラム』」)のことを指しているのではないかと思います(ややこしいですね。。。)。
【参考】
「オープンなデータ流通構造に向けた環境整備」(平成28年8月29日・経済産業省)
「3 契約条項をどのようにして自社に有利にデザインするかを知っておく(「権利帰属」にこだわらず「利用条件」で「実」をとる)」
これで、AI開発における6つの対象物についての法律上のデフォルトルールが分かりました。
次に重要なのは、そのデフォルトルールを前提として、契約条項をどのようにして自社に有利にデザインするかです。
▼ 典型的な暗礁乗り上げパターン
AI開発契約における、権利・知財に関する典型的な暗礁乗り上げパターンは以下のようなものです。
【ユーザ】
学習用データセットや学習済みモデルは、うちのノウハウや機密が詰まった生データを用いて生成されたものですし、開発に際して委託料も支払っています。うちに権利がありますよね?
【ベンダ】
いやいや、生データだけでは学習済みモデルは生成できません。高性能なモデルができるのは、データの前処理やモデルの訓練過程いずれにおいてもうちの高度のノウハウと多大な労力あってこそです。うちに権利がありますよね?
▼ どう考えたら良いのか
このような対立は、ユーザ・ベンダいずれもが「成果物等は自社のものである」、言い換えると「成果物の権利を自己に帰属させる」ことに双方が固執することに主として起因しています。
そして、このように「どちらが権利を持っているか」(権利の帰属)に双方がこだわっている限り永久に双方の溝は埋まらず、交渉に多大な労力と時間がかかり結局双方が競争力を失うことになります。
本来、データ提供者(ユーザ)と学習済みモデル生成者(ベンダ)のビジネス構造は異なりますから、双方のニーズを同時に満たしうる契約条件は当事者双方が思うよりももっと多いはずです。
そこで、AIガイドラインにおいて提案しているのが「権利帰属」と「利用条件」を分離して柔軟な条件設定をすることです。
たとえば学習済みモデルにつき、「1 ベンダに権利を帰属させた上で(「権利帰属」)、「2 開発後、ベンダは一定期間の目的外利用や競業的利用は禁止される一方でユーザは当該学習済みモデルを自由に利用できる(「利用条件」)」等の対応をすることによって、当事者双方の利益に合致する契約を締結できる場合もあるでしょう。
言い換えれば
「双方が対象物の『権利帰属』ではなく『利用条件』で『実』をとることを目指す」
という発想です。
極端な言い方をすれば、自社が学習済みモデルに関する権利を保有しておらず、相手に権利が全て帰属していても、交渉の結果「モデルの第三者提供を含め、何の制限もなくモデルを自由に利用できる」という利用条件を設定できれば、実質的にはモデルの権利を保有していることとほとんど同じ、ということです(もちろん、権利の譲渡の可否や権利者が移転した際の対抗力の問題など、「モデルの権利を保有しているのと完全に同じ」というわけではありませんが)。
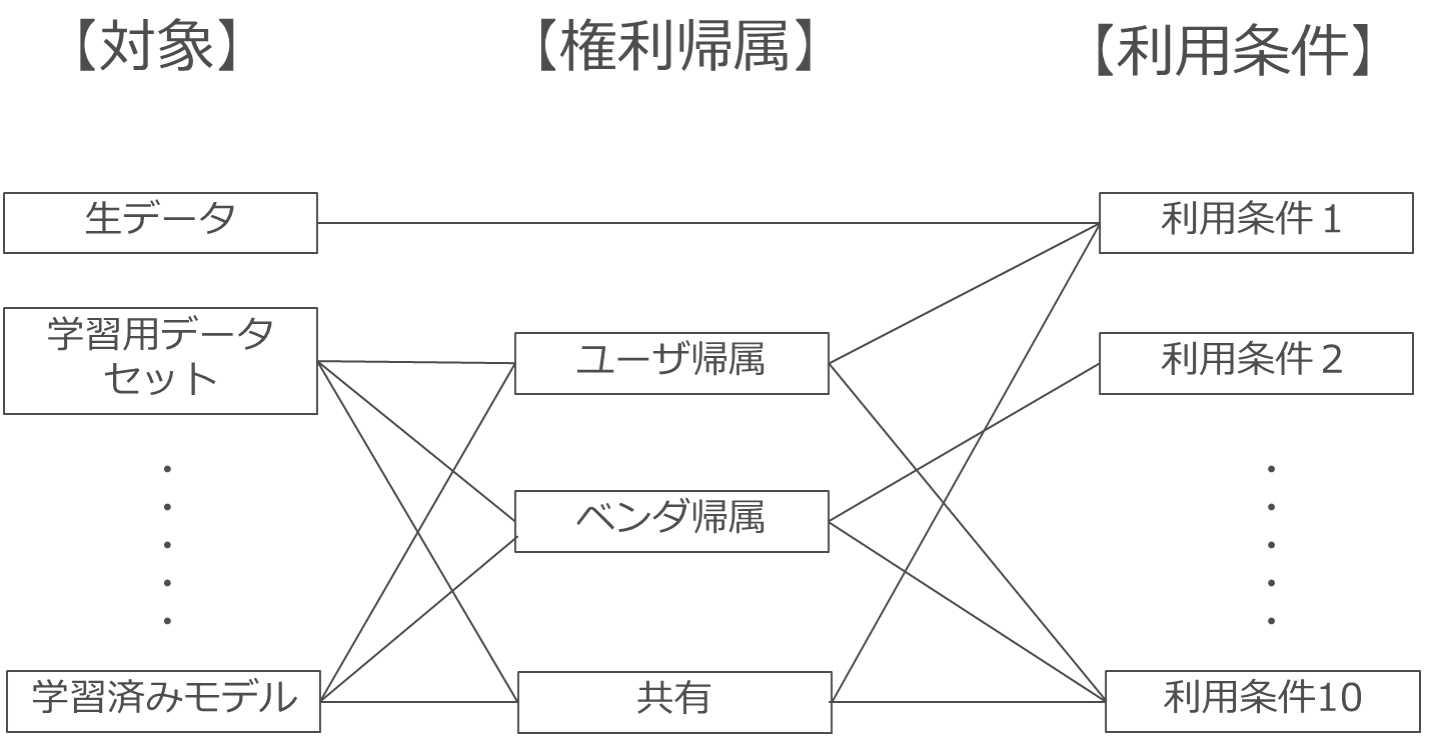
▼ 具体的な検討方法
このように「権利帰属」と「利用条件」を分けて考えるという発想に立つと、理屈としては、例の6つの対象物全てについて「権利帰属」と「利用条件」を設定するということになります(なお、以下の図で生データについて「権利帰属」を定めていないのは、生データについては現行法上知的財産権が発生しないため、直接「利用条件」を定めれば足りるためです(もちろん、著作物など知的財産権が発生するデータについては「権利帰属」が問題となります))。
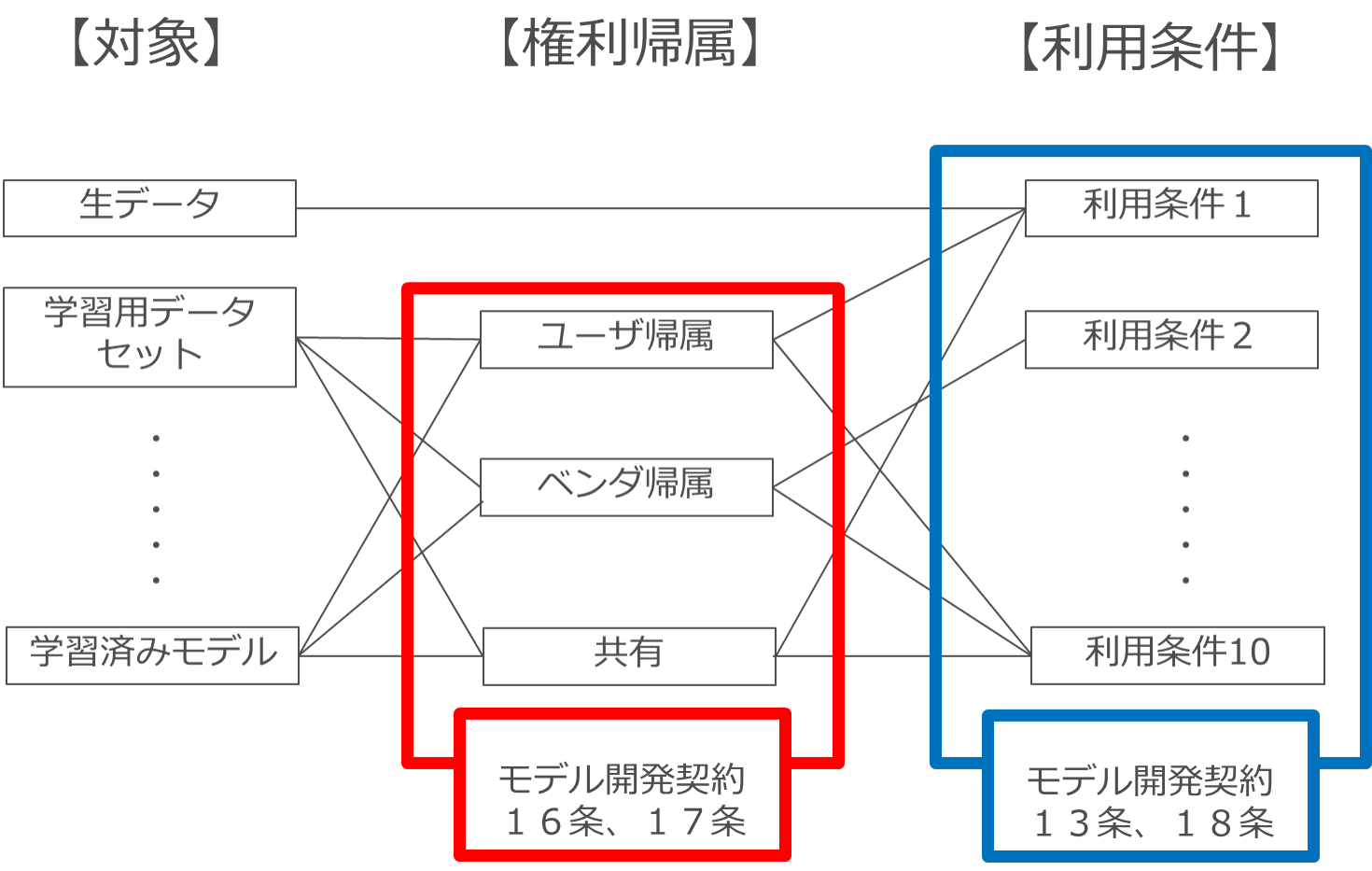
もっとも、実際にはもっとシンプルなパターンも多いはずで、AIガイドラインに附属している「 開発段階のソフトウェア開発契約書(モデル契約書)」では、「権利帰属」については第16条と第17条に、「利用条件」については第13条と第18条に定めています。
▼ 権利帰属について
権利帰属については、誰に権利帰属するかを合意するとすれば3パターンしかありません。
1 ベンダ全部帰属
2 ユーザ全部帰属
3 ユーザ・ベンダ共有
です。
AIガイドラインのモデル開発契約においては、成果物等のうち著作権の対象となるものは第16条に、著作権以外の知的財産権の対象となるものは第17条に定めています。
このように分けているのは、成果物等のうち「著作権の対象となるもの」(学習用データセットや学習済みモデルの推論プログラムのコード部分など)については、契約締結時点において、ユーザ・ベンダどちらに権利帰属するかを明確にしておきたいというニーズが強いと思われるためです。
一方、成果物のうち「著作権以外の知的財産権の対象となるもの」については、17条で「本件成果物等を創出した者が属する当事者に帰属するものとする」(発明者主義)としています。
これは、「著作権以外の知的財産権の対象となるもの」については、どのようなものが発生するか契約締結時点では不明確なことも多いため、予め権利帰属について定めないこととしているのですが、もちろん「著作権の対象となるもの」と同様、「ベンダ全部帰属」「ユーザ全部帰属」「ユーザ・ベンダ共有」のいずれかとしても問題ありません。
なお、2007年に公表された経済産業省のモデル取引・契約書(第一版)(モデル契約2007)でも同じように「著作権」と「著作権以外」の条項が分けられており、今回のモデル開発契約もこれと同じ発想に基いています。
モデル開発契約の関係条項をまとめたのが以下の表です。

▼ 利用条件について
利用条件については、ユーザ、ベンダそれぞれが、材料・中間成果物・成果物を、自社のビジネスにおいてどのように利用したいかをよく検討しなければなりません。
たとえば、学習済みモデルの利用条件であれば、ユーザ・ベンダそれぞれがどのように自己のビジネスに利用するかは様々な方法が考えられます。
1 自己の業務遂行に必要な範囲で、開発対象となった学習済みモデルを利用するだけなのか
2 学習済みモデルに新たなデータによる学習を行い、派生モデル(AIガイドラインでは「再利用モデル」と呼んでいます)を生成するのか
3 学習済みモデルや派生モデルを第三者へ開示、利用許諾、提供等することがあるのか。
4 2,3の場合の相手方に対する利益配分(ライセンスフィー、プロフィットシェア)が必要かどうか
などを検討する必要があります。
個人的には、実際の契約締結交渉においては「権利帰属」より、ここの「利用条件」をいかに自分のビジネスモデルに適合した形で設定できるか、ということのほうがよっぽど大事ではないかと感じています。
AIガイドラインのモデル開発契約では、3つの具体的なケースを挙げ、それぞれのケースにおいて契約で利用条件をどのように定めたらよいかを例示していますので、是非参考にしてください。
「4 契約の限界を知っておく」
これまで見てきたように、成果物等については、その権利帰属と利用条件をAI開発契約で定めることによって、ユーザ・ベンダそれぞれが、自分のビジネスに必要な範囲で利用できるように設定することができます。
ただ、実際には、成果物等そのものに関して権利帰属と利用条件を定めるだけでは、ユーザ・ベンダの権利を十分守れないことがありえます。
特に学習済みモデルについては、派生モデルや蒸留モデルの生成が可能であることからその危険性が顕著です。
▼ 派生モデルとは
派生モデルというのは、ある学習済モデルに対して新しいデータを利用して再学習させた結果できたモデルのことです。
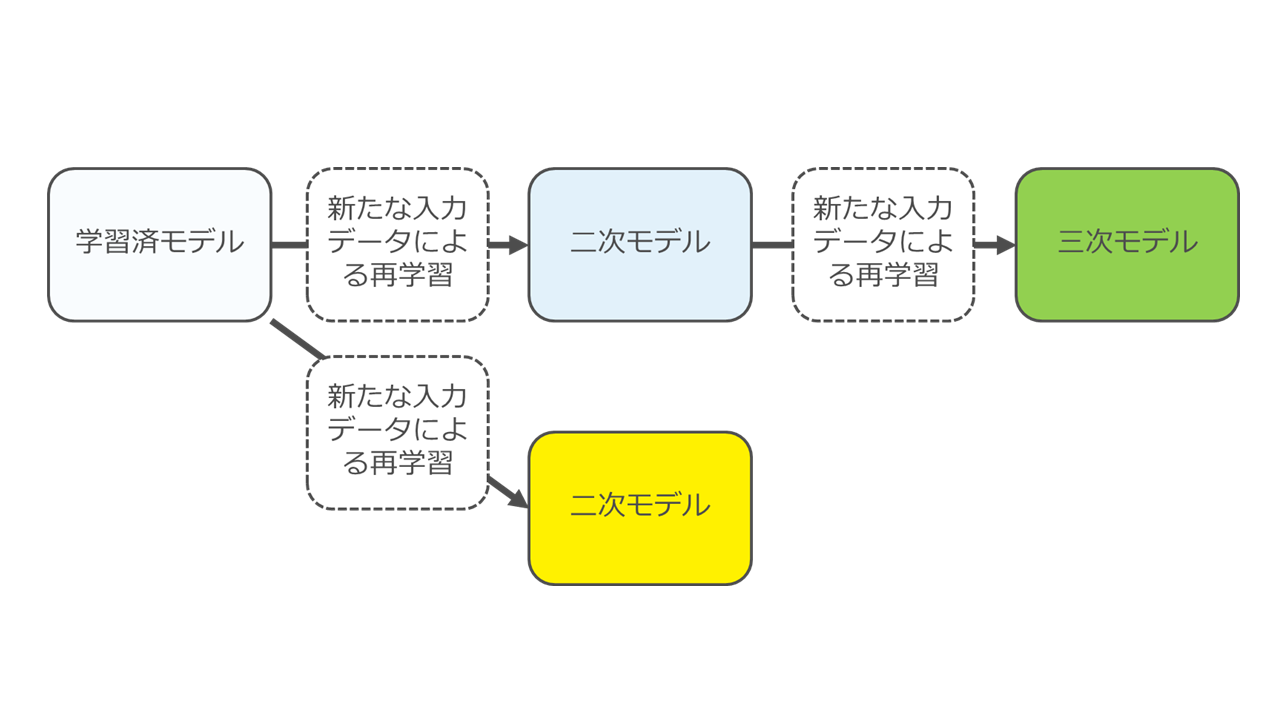
元のモデルより、より精度の高いものができますが、再学習によりパラメータが更新されるため、少なくともパラメータ部分については元のモデルと全く異なる形になっていますし、フレームワークの種類によってはネットワーク構造も元モデルと異なる形になります。
▼ 蒸留モデルとは
蒸留とはこういう行為です。
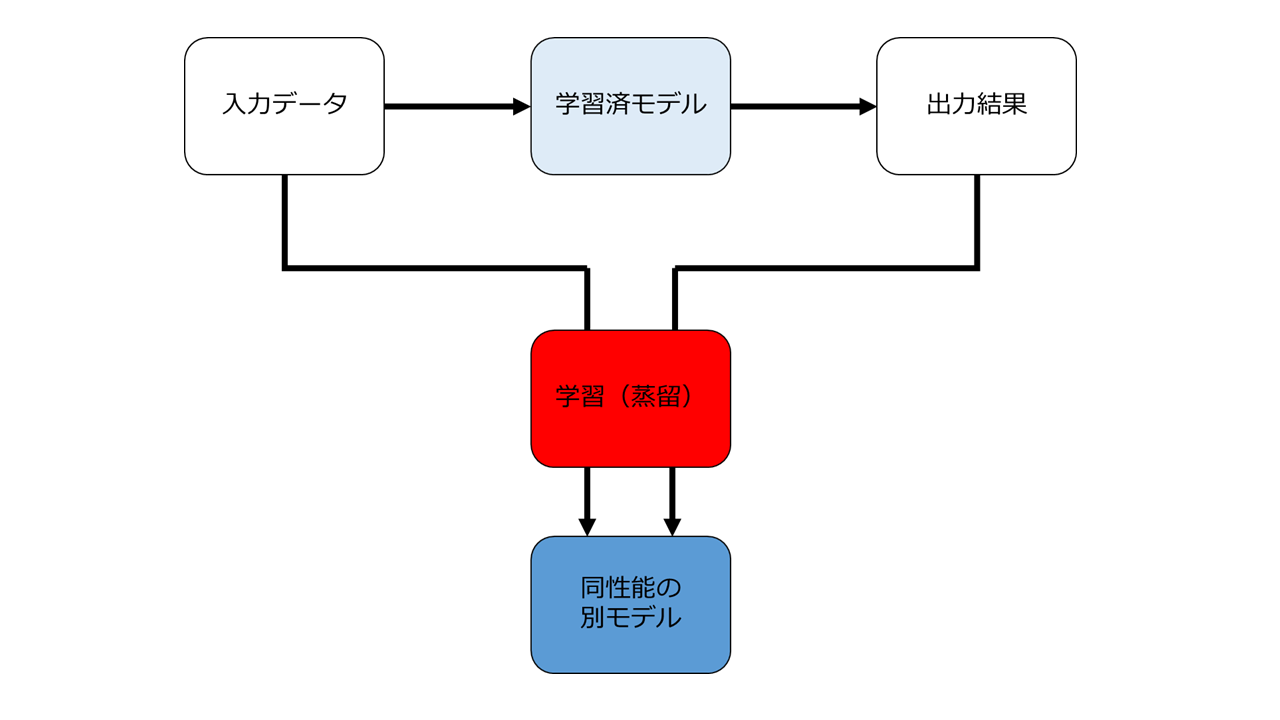
要するに学習済モデルを直接コピーしなくても、入力データと出力データを用いて別途学習をすることで全く異なるモデルを生成できる、という行為です。
これにより、性能がほとんど変わらず、かつ軽量なモデルができると言われています。
しかも、この蒸留行為は、学習済モデルが外から見えない状況(ブラックボックス化された状況)になっていても可能です。
「蒸留」行為の問題点は、 派生モデルと同様、元のモデルと全く異なる形になっている、つまり元のモデルとの関連性が存在しない点です。
▼ ではどうすればよいのか
派生モデル・蒸留モデルはこのように元のモデルとの関連性が存在しないことから、AI開発契約において、開発対象となった学習済みモデルの権利帰属・利用条件を定めた条項を設置していても、その条項の効力が及ばない可能性があることになります。
そこで、AI開発契約において
1 リバースエンジニアリング、派生モデル生成、蒸留行為を明示的に禁止する(モデル開発契約19条)
2 同等または類似した機能を持つ学習済みモデルを用いることで行うことができる事業を一定の時期や範囲で制限する
という条項を設置することが考えられます。
なお、2については独占禁止法への抵触に注意する必要があります。
■ AI開発・利用に際して生じる可能性のある損害についてAI開発契約ではどのように定めたら良いか(責任)
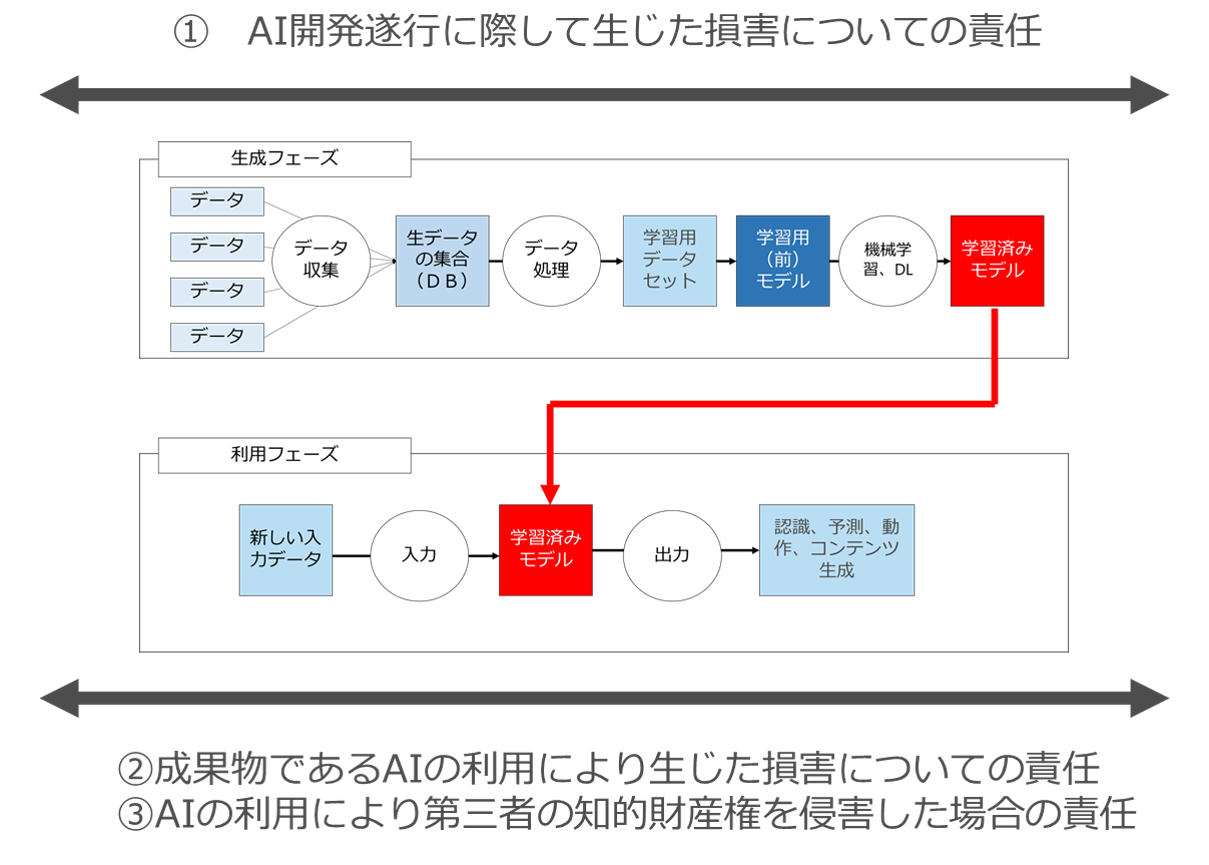
AI開発・利用に関する3種類の責任
AIの開発・利用に関してベンダがユーザに対して負担する可能性がある責任は以下の3つに分類できるのではないかと思います。
1 AI開発遂行に際してユーザに生じた損害についての責任
2 成果物であるAIソフトウェアの利用によりユーザに生じた損害についての責任
3 成果物であるAIソフトウェアをユーザが利用したことによりユーザが第三者の知的財産権を侵害した場合の責任
AIソフトウェアの生成フェーズ(学習フェーズ)と利用フェーズ(推論フェーズ)に分けて図示するとこのようなイメージです。
1 AI開発遂行に際してユーザに生じた損害についての責任
【具体例】
ベンダが、通常の技術レベルを持つAIベンダであればやらないレベルのミスを犯したことにより、学習に通常では考えられない期間を要したため、納期に間に合わなかった。
まず、当然のことですが、AI開発契約の法的性質を準委任契約としたからといって、受任者であるベンダが一切責任を負わないということではありません。
準委任契約においても、ベンダは「善管注意義務」(民法644条。委任の本旨に従い、善良な管理者の注意をもって、委任事務を処理する義務)を負っています。
したがって、この「開発遂行に際して生じた責任」についてはAI開発と通常のシステム開発を区別する合理性がないことになります。
そこで、モデル開発契約第22条1項では以下のように定めています。
【第22条1項】
「ユーザおよびベンダは、本契約の履行に関し、相手方の責めに帰すべき事由により損害を被った場合、相手方に対して、損害賠償(ただし直接かつ現実に生じた通常の損害に限る。)を請求することができる。ただし、この請求は、業務の終了確認日から●か月が経過した後は行うことができない。」
2 成果物であるAIソフトウェアの利用によりユーザに生じた損害についての責任
【具体例】
工場における半製品の異常検知検出AIをベンダが開発してユーザに納品、ユーザが自社の工場において当該AIを利用したところ、AIソフトウェアが異常を見落としてユーザが不良品を顧客に出荷してしまい大きな損害を被った。
1の「AI開発遂行に際してユーザに生じた損害についての責任」と異なり、「AIソフトウェアの利用によりユーザに生じた損害についての責任」については、ベンダにその責任を問うことがかなり難しいのではないかと思われます。
これは冒頭に紹介した、通常のシステム開発とAIソフトウェア開発との相違点に由来するものであり、「未知の入力(データ)に対する学習済みモデルの事前の性能保証が技術上難しい。」というのが大きな理由です。
さらに、AIガイドラインでは「因果関係等につき事後的な検証等が技術上困難である」「学習済みモデルの性能等が学習用データセットに依存する」「AI生成物の性質等が利用段階の入力データの品質に依存する」という点を指摘しています。
したがって、AI開発契約においては、この「AIソフトウェアの利用によりユーザに生じた損害についての責任」については、ベンダは責任を負わないとするか、負うとしても一定の損害額の上限を設けるのが合理的ではないかと思われます。
モデル開発契約第20条では、学習済みモデルなど成果物等の使用等による責任をベンダは原則として負わないと定めています。
【第20条】
ユーザによる本件成果物等の使用、複製および改変、並びに当該、複製および改変等により生じた生成物の使用(以下「本件成果物等の使用等」という。)は、ユーザの負担と責任により行われるものとする。ベンダはユーザに対して、本契約で別段の定めがある場合またはベンダの責に帰すべき事由がある場合を除いて、ユーザによる本件成果物等の使用等によりユーザに生じた損害を賠償する責任を負わない。
もちろん、当事者のニーズや力関係によっては、学習済みモデルの利用によって生じた損害についてもベンダに責任を負って欲しいということはあり得ると思います。
ただ、その場合でも、賠償の対象となる損害額については一定の上限を設けることが合理的であることが多いと思われます。
上限を設ける場合、モデル開発契約第22条2項「ベンダがユーザに対して負担する損害賠償は、債務不履行、法律上の瑕疵担保責任、知的財産権の侵害、不当利得、不法行為その他請求原因の如何にかかわらず、本契約の委託料を限度とする。」と同様の条項を設けることになります。
3 成果物であるAIソフトウェアをユーザが利用したことによりユーザが第三者の知的財産権を侵害した場合の責任
【具体例】
ある学習方法についてのA社により特許登録がなされていた。ベンダが当該特許をA社に無許諾で実施して学習済みモデルを生成してユーザに提供し、ユーザが不特定多数の第三者に当該モデルを提供し始めたところ、A社から特許権侵害であるとの警告書が届いた
この「成果物であるAIソフトウェアをユーザが利用したことによりユーザが第三者の知的財産権を侵害した場合の責任」は「AIソフトウェアの利用によりユーザに生じた損害」の一種ですが、知的財産権侵害についてはユーザの関心が非常に高いため別に検討する必要があります。
ユーザとしては、ベンダに対して、知財の非侵害保証(第三者の知的財産権を侵害しないことの保証)を行ってほしいと要請することも多いのですが、一般論としては、ベンダにおいて海外特許を含め侵害の有無を完全に調査検証することは費用面から非常に困難であることも少なくありません。
大まかな考え方としては、以下の3つがありえます。
1 一切保証をしないパターン
2 著作権非侵害のみ保証するパターン
3 すべての知的財産権の非侵害を保証するパターン
2で著作権の非侵害のみ保証するパターンがあるのは、著作権(たとえばプログラムの著作権)については、侵害成立の要件として依拠性(平たくいえば「パクリだとわかりつつパクった」こと)が必要とされるため、ベンダにおいて侵害がないことを保証できる場合が多いと思われるためです。
モデル開発契約においては、上記2(第21条B案)と3(第21条A案)を提案しています。
■ まとめ~「AI・データの利用に関する契約ガイドライン」に学ぶAI開発契約の8つのポイント~
1 性能保証、検収、瑕疵担保
(1)AIの特性と限界の相互理解
(2)プロセス・契約を分割する
(3)開発契約の内容を工夫する
2 権利・知財
(1)材料・中間成果物・成果物について、何が知的財産権の対象となるのか・ならないのかを知っておく
(2)(1)についてデフォルトルール(=法律上のルール)として誰がどのような権利を持っているかを知っておく
(3)契約条項をどのようにして自社に有利にデザインするかを知っておく(「権利帰属」にこだわらず「利用条件」で「実」をとる)
(4)契約の限界を知っておく
3 責任
AI開発における「責任」の種類を知り、契約でコントロールする
【2018年8月8日追記】
知的財産権デフォルトルールの〇×表と経産省「オープンなデータ流通構造に向けた環境整備」に掲載されている類似の表との関係について追記しました。
【2018年8月10日追記】
本記事における「AI」の用語の意味を明確にしました。
(弁護士柿沼太一)












