人工知能(AI)、ビッグデータ法務
渋谷の牛タン屋で横にいたカップルとAI開発における演繹と帰納について

ある日のお昼時、渋谷の牛タン屋さんで、メニュー写真よりずいぶん小さい牛タンを食べていたところ、横にいた若い男女の会話が聞くともなく聞こえてきた。
「ねえ、どんな芸能人が好きなの?」
と女性。
言葉遣いや雰囲気からして同じ会社の同僚同士のようだ。
特に興味を引かれるやりとりではなかったので、私は景表法違反のことなどを考えながら牛タンを食べていた。
男女はその後もとりとめのない話を続けている。
最近見たドラマの話や、メルカリで買った洋服が気に入ったことなどなど。
ふと思い出したように女性が
「私さ、友達からよく言われることがあって。」
「どんなこと?」
「自分がこれまで好きになった芸能人って、自分では分からないんだけど、友達からは『・・ちゃんの好きな芸能人って、みんな唇が肉厚だよね』って言われるんだよね~。で、たしかにそう言われて考えてみると、確かにそうだなって思って。」
「ふうん、そうなんだ」
彼は興味があるのかないのか分からないが、聞き流している模様。
その後も会話は、社内の共通の友人や上司の話題に流れた。
で、しばらく当たり障りのない会話が続いたあと、彼女がこれまたふと思いついたように
「そういえば、あなたの唇って肉厚だよね?」
「は?おれ?(照)」
この男女のやりとりからは、AI開発における重要概念、「帰納」と「演繹」が見事に浮かび上がる。
Contents
■ AI開発におけるベンダとユーザの間の溝
AI開発契約の締結に際して、私がベンダあるいはユーザから非常に多く受ける質問として「AI開発契約においては『性能保証』『検収』『瑕疵担保』についてはどのように定めればいいのでしょうか。」というものがあります。
ユーザは「開発したシステムを現場に投入した際の性能を保証してもらえなければ現場で使いものにならない」と言い、AIベンダは「未知データを入力した際に確実な挙動を保証することはAIの場合そもそも不可能」と言います。
あるいはユーザは「AIを組み込んだシステムが想定どおり動かない場合はベンダに瑕疵担保責任を負って欲しい」といい、AIベンダは「『想定どおり動かない』と言ってもその理由は、AI生成の際に用いたユーザ提供データに偏りがあったのかもしれないし、組み込んだAIの外側のシステムの問題かもしれないし、そもそもAIの内部でどのような処理が行われているかがブラックボックスなので瑕疵担保責任負うのは無理」と言います。
このようなやりとりはAIの開発に際して日常的に発生しているのですが、その原因の一つとして、「AI開発が通常のシステム開発と違うことについての共通認識がない」というものがあります。
AI開発と、通常のシステム開発の違いは、簡単に整理するとこのように整理できます。
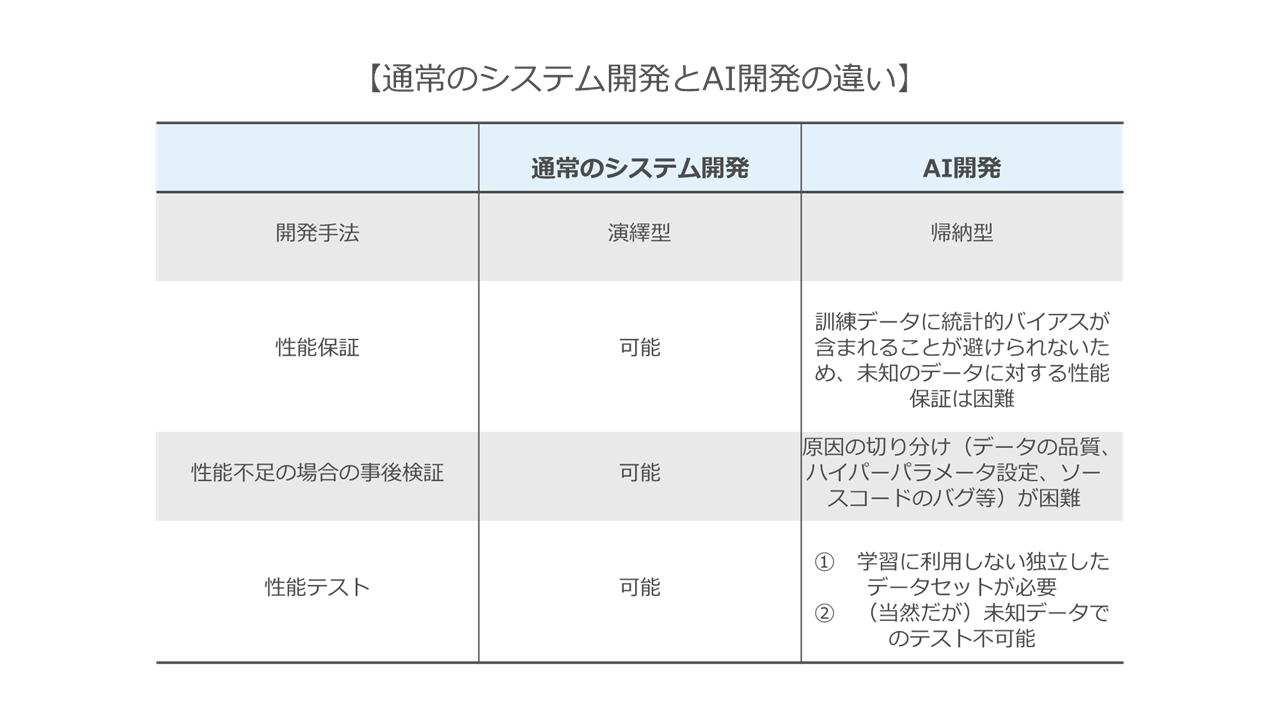
人間がアルゴリズムを考案して当該アルゴリズムどおりにプログラムを記述する通常のシステム開発と、大量のデータを用いて学習を行い当該データに共通する法則を抽出するAI開発とでは、システム開発の発想がかなり違います。
先ほどの表の冒頭に「開発手法」として「演繹型」と「帰納型」と記載しているのはそれを表しています。
人工知能学会誌33巻2号(2018年3月)に株式会社プリファードネットワークの丸山宏氏と城戸隆氏による「機械学習工学のいざない」という論稿が掲載されています。
一部引用します。
「機械学習は、プログラミングの方法論という観点からすると、本特集のテーマであるデータに基づく帰納的なシステム開発手法と位置づけることができる。今までの演繹的なシステム開発、すなわちシステムの仕様を定義し、先験的な知識に基づいてそれをモデル化し、段階的に詳細化していく方法論に対して、機械学習に基づく帰納的なシステム開発は、仕様を訓練データの形で表現し、実装は訓練(training)によって行うという形をとる。帰納的なシステム開発においては、仕様定義の方法、実装の方法、テストの方法、運用の方法などが今までのシステム開発と大きく異なり、そのため演繹システム開発を前提としたソフトウェア工学の方法論の多くがそのままでは適用できない。」
このような「演繹的開発」(通常のシステム開発)と、「帰納的開発」(AI開発)の違いが冒頭のユーザとAIベンダの溝につながっていくのです。
■ 「演繹」と「帰納」
では「演繹」と「帰納」の違いは何でしょうか。
一般的に「演繹」とは、一般的な前提やルールから結論を得る考え方です。三段論法はその典型例とされており、「A=B」「B=C」「よってA=C」という三段論法は法学部生であればおそらく最初の授業で習うはずです。
一方「帰納」とは、複数の個別事例や経験則などの前提を集めて、そこから普遍的な法則を見いだす考え方です。
通常のシステム開発は演繹的な開発手法、すなわち、まず仕様を確定したうえで、その仕様を実現するためにはこうする必要がある、ということを積み重ねてシステムを開発する手法をとります。
一方、AI開発は帰納的な開発手法、すなわち開発目的との関係で意味のあると思われる大量のデータを集めてきて、それを用いて学習をさせ、当該データに共通する法則・特徴を見つけ出そうという手法をとります。
したがって、このような帰納的な開発手法により開発されたAIは、「未知のデータでの性能保証は困難」ですし(理屈を積み上げて開発したわけではないので、訓練に使っていないデータを入力した場合、どのような挙動をするかが予測困難)、「なにをもって『瑕疵』というかはっきりしない」ということになります。
■ ベンダとユーザの溝を埋めるためには
このような開発手法の差がら生じるベンダとユーザの溝を埋めるためには、以下の3点が必要ではないかと考えています。
1 AI開発の特性をユーザとベンダが理解すること
具体的には、経産省が出しているAI・データ契約ガイドラインを活用してユーザ・ベンダがAI開発の特性について共通の理解基盤を持つこと。このガイドライン策定には私も関わっていますが、AI開発における基礎概念、AIの技術的特性、利点と限界について詳細に記載してありますので、共通基盤の形成に大いに役立てて頂きたいです。
2 開発プロセス及び契約の分割
AI開発の特徴を一言で言い表すと「開発を進めてみないと、うまくいくかどうかわからない」という点に尽きます。そして、この特徴はユーザのみならずベンダにとっても大きなリスクなのです(今後きちんとビジネスをしようと考えているベンダにとっては特に。)
そして、ユーザ・ベンダお互いのリスクヘッジのための一つの方法は、開発プロセスと契約を複数の段階に区切って、徐々に開発を進めていくというものです。
ガイドラインでは、このような開発プロセスを「探索型段階型開発方式」と名付けています。詳細はガイドラインをご参照下さい。
3 契約内容の工夫
最後に契約内容の工夫です。AI開発の特質を踏まえてどのような契約条項にするかという点です。
ガイドラインにはモデル契約書も添付されていますので、参照して頂ければと思います。
【参照】
AI・データ契約ガイドライン(現在パブコメ募集中です)
■ 再び牛タン屋さん
で、冒頭の牛タン屋さんの話に戻るわけです。
まず女性は「自分では気づいていなかったが、好きな芸能人の共通点を探してみると唇が肉厚だという特徴がある」という話をします。
これは帰納的な発想です。
多数の事例を集めてきて、その共通ルールを探しているためです。
一方、この女性が「女性は初恋の人をいつまでも忘れられない」「私の初恋の人は唇が肉厚だった」「なので私は唇が肉厚な人が好きである」という説明をした場合(牛タン食べながらこんな説明されたら怖いですが)演繹的な発想だということになります。
さらに女性は帰納法によって導いた「私は唇が肉厚な人が好きである」という布石を打った後、演繹法で相手を仕留めにかかります。
もうおわかりですね。
そう
「私は唇が肉厚な人が好きである」
「あなたは唇が肉厚である。」
「は?おれ?照」
です。
このやりとりを聞いて私は席を後にしたので、この後どうなったかは分かりませんが、この二人に幸多からんことを。
(弁護士柿沼太一)












