人工知能(AI)、ビッグデータ法務
AIが偶然に「アナゴさん」を生み出した場合、サザエさんの著作権者に怒られるのか?(キャラクター生成AIと著作権問題)
AIを利用して結果的に第三者に何らかの損害を与えてしまった場合、その責任を誰がどの範囲で負うのかというのは、AIの利活用にとって非常にシビアな問題です。
たとえば、
・ AIを利用した自動運転車を運転していたが、何らかの理由により交通事故を起こしてしまった場合
・ 医師が医療用AIを利用して診断を行ったが、医療用AIが示した診療方針が医療水準に満たないものだっため患者が死傷した場合
などです。
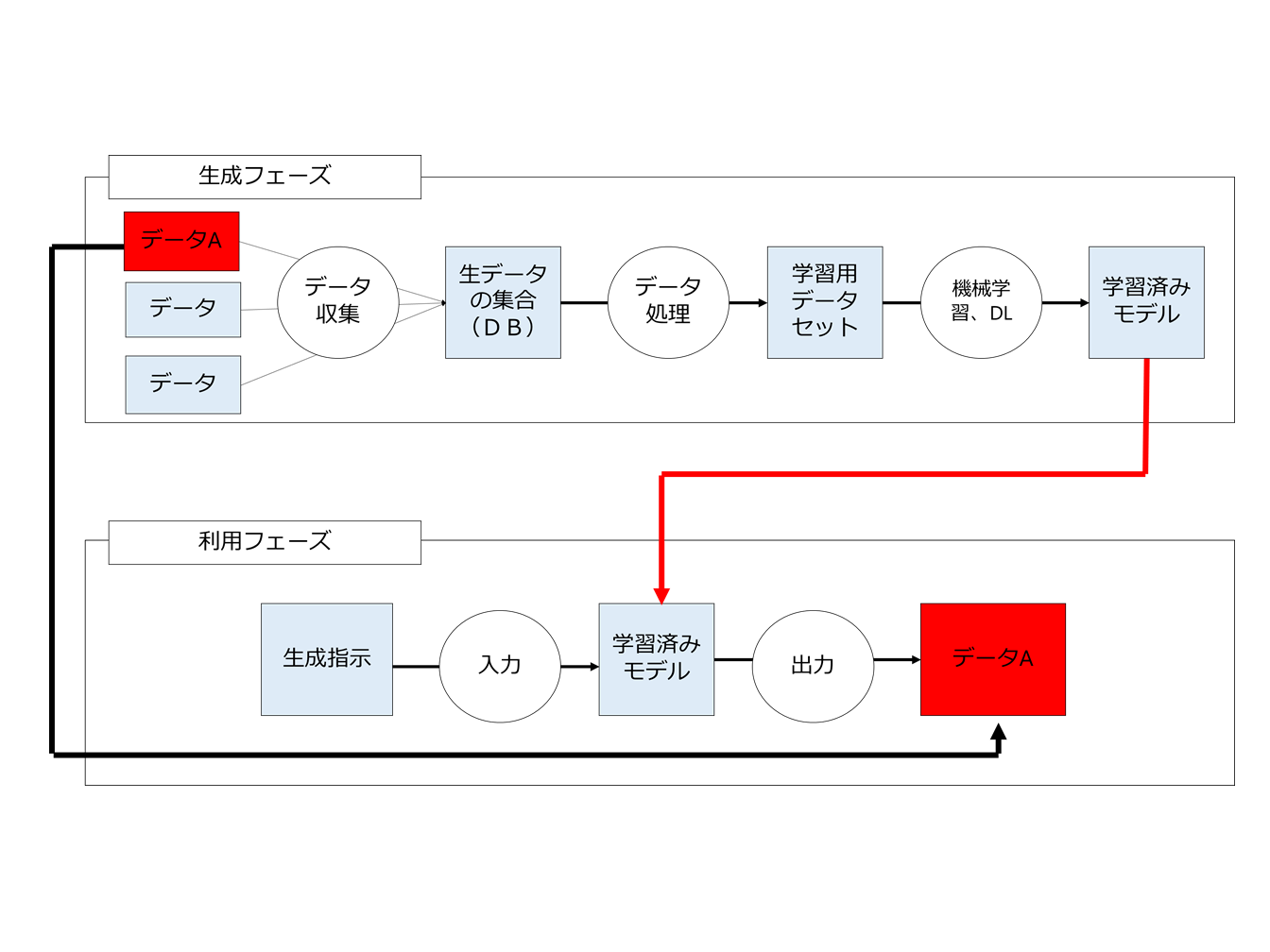
このような問題領域の中に、「ある学習用データを利用して適法に学習済みモデルを生成したのに、当該学習済みモデルに何らかの指示を行ったところ、元の学習用データの一部又は全部と同一又は類似する結果が出て来てしまった場合著作権侵害になるのか」という問題があります。
たとえば、私はサザエさんが非常に好きです。
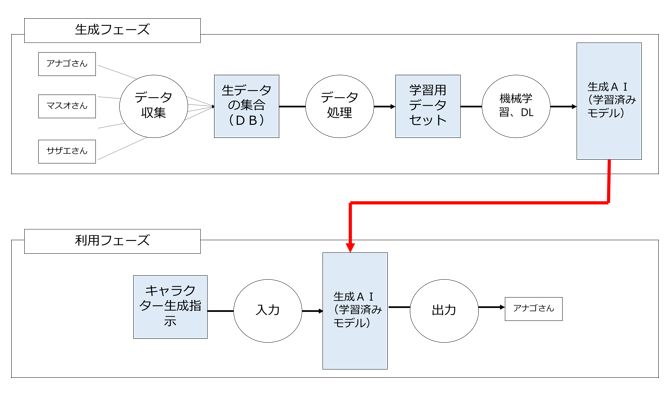
そのストーリーだけではなく、あの心安らぐ独特のタッチのキャラクター全部が好きなのですが、そんな私が、「その日の気分にあったサザエさん風キャラクターを自由自在に生成したい」と思い、サザエさんの漫画作品やアニメ作品などを学習用データとして「サザエさん風キャラクター生成AI(学習済みモデル)」を生成したとします。
生成のために用いた学習用データには、ありとあらゆるサザエさんのキャラクターが入っていますが、このAI生成行為は、著作権法47条の7に基づいて適法に行うことができます。
さて、このAIに私が「今日は裁判官に嫌味を言われ、部下に責められさんざんな一日だった。黙ってそばにいて愚痴を聞いてくれる、そんなサザエさん風キャラクターを生成して欲しい」と指示をしたところ、「アナゴさん」とそっくりなキャラクターがたまたま生成されてしまった場合、著作権侵害となるのか、ということです(私的利用ではないか、という点はひとまず置いておきます)。
「ある学習用データを利用して適法に学習済みモデルを生成したのに、当該学習済みモデルに何らかの指示を行ったところ、元の学習用データの一部又は全部と同一又は類似する結果が出て来てしまった場合著作権侵害になるのか」問題、ではあまりに長すぎるので、以後「アナゴさん問題」と呼びますが、この問題は、2017年3月に知的財産戦略本部 検証・評価・企画委員会・新たな情報財検討委員会によって公表された「新たな情報財検討委員会報告書」においても論じられている論点です。
コンテンツ業界がAIを利活用する場合に、かなりシビアな問題になります。
今回はこの点について検討をしてみようと思います。
Contents
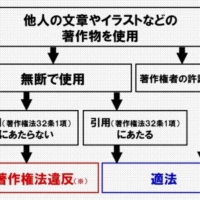
■ 著作権侵害となるには「類似性」+「依拠」が必要
まずは基本知識からですが、今回は「学習用データ(著作物)と同じ著作物が生成された場合に著作権侵害の問題が生じるか」という問題です。
では、そもそもどのような場合に著作権侵害が認められるのでしょうか。
著作権侵害(複製権・翻案権侵害)となるためには、「(既存の著作物との)類似性」+「依拠」が必要です。
逆に言えば、「類似性がなければ(似ていなければ)」著作権侵害は認められないし、「類似性があっても依拠がなければ」著作権侵害は認められない、ということです。つまり「たまたま似てしまった場合(独自に創作した場合)には著作権侵害にはならない」ということですね。

この「依拠」という要件は著作権法に明記されているわけではありませんが、当然必要と考えられています。
■ 単に「作風」が似ているだけでは著作権侵害にならない
さて、先ほど述べたように、著作権侵害が認められるためには「類似性+依拠」が必要です。
そして、ここでいう「類似性」はあくまで「表現」に類似性があることが必要であって、表現ではない「作風」や「スタイル」が類似していたとしても、「類似性」が肯定されることはありません。
たとえば、有名な「The Next Rembrandt」プロジェクトでは、レンブラントが描いた全346作品の3Dスキャンデータを基に絵画の主題や構図、服装の特徴、性別・年齢などを学習して生成された人工知能が用いられ、レンブラントの「画風」「スタイル」を模倣してレンブラントの「新作」を生成しました。

https://www.nextrembrandt.com/より
したがって、この「新作」は、レンブラントの従来作品と類似するものではなく、この「新作」は著作権侵害にはならないということになります(これは、AIが生成しようが人間が生成しようが同じことです。)
ここでまず「作風」や「スタイル」が類似していたとしても著作権侵害にはならない、ということを押さえてください。
もっとも、実際には「作風」「スタイル」の類似なのか、「表現」の類似なのかという区別はなかなか難しいものがあります。
例えば、新たな情報財検討委員会の委員でもある清水亮氏が書いた記事「AI生成物に著作権はあるか?田中圭一AI出現の可能性とAI専用デジタル国会図書館」では田中圭一氏の漫画について紹介されています。
田中圭一氏は、手塚治虫などの巨匠の作風を利用した作品を発表していることで有名な方ですが、これもあくまで「作風」の模倣にとどまる限り著作権侵害には該当しません。

しかし、一歩踏み越えると。。。。。

https://note.mu/keiichisennsei/n/n4ab1d789295cより
左の奴は、「作風」を踏み越えて明らかに某キャラクターの「表現」を模倣しているように思えます。これはほぼアウトでしょう。
■ 同一・類似の著作物が生成された場合には「依拠」があるかどうかが問題となるが、AIにおける元データの利用方法によって分けて考える必要がある。
次に、AIに食わせた元データと「表現」が類似している著作物がAIによって生成されたとします。
その場合は「類似性」はクリアしていることになりますので「依拠」があるか否かが著作権侵害となるか否かの分かれ目ということになります。
ただ、これは元データがどのように利用されているのかで場合を分けて考える必要があります。
▼ 元データをそのまま利用しているニセAI
以前ネット上で話題になった「Everfilter」というフィルターソフトがあります。これは、ある写真を入力するとアニメ風にしてくれるという話で非常に人気が出ましたが、よく見ると、「アニメ風」であるはずのEverfilterの出力は、実際には新海誠さんの作品の完全コピーであった、というものです。
【参考記事】
盗用問題の「君の名は。」風加工アプリ「Everfilter」が配信を一時停止
これはAIであろうがなかろうが、単に著作物をそのまま利用しているだけですので、明らかに著作権侵害となります。
▼ 元データをそのまま利用しているリコメンド型AI
次に、元データをそのまま利用しているAIを考えてみます。
これは、例えば元データをそのまま保持しつつ、レコメンド部分にAIを使っているというものです。
「サザエさん風キャラ生成AI」の場合、私が「今日は検察官にいびられ、部下に責められ(以下略)キャラクターを生成して欲しい」とAIに指示すると、「そんな気分のときには『アナゴさん』がぴったりだ」と判断して、もともと保持している「アナゴさん」を出力するようなAIです(なので、このAIはキャラクターの「生成」はしていないことになります)。
このようなAIは、元データをそのまま利用していますので、当然依拠は認められる、ということになります。
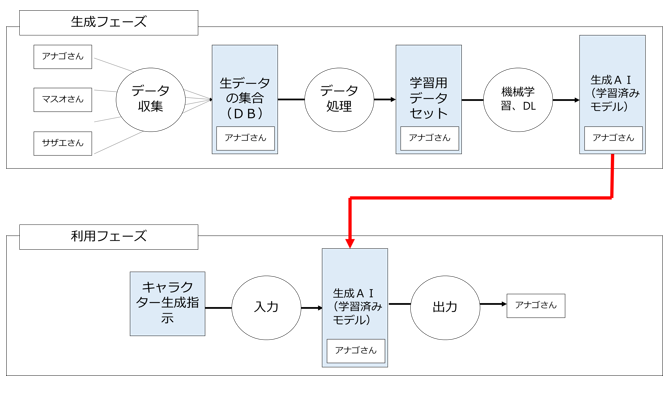
▼ 元データを特徴ベクトル・パラメーターに変換しているため元データの痕跡が学習済みモデルに残っていないAI
次に、「元データを特徴ベクトル・パラメーターに変換しているため元データの痕跡が学習済みモデルに残っていないAI」です。
つまり、先ほどのリコメンド型AIと異なり、学習済みモデルの中に元データの痕跡が一切残っておらず、出力指示があるたびに新たな著作物を生成するAIです。
「依拠」があるかないかが非常に問題になるのは、このタイプのAIです。
考え方としては2つあります。
▼ 依拠を認めない考え方もありうる
1つは、いったん元データの痕跡が残らない形に抽象化しているのだから、元データではなくアイデアを利用しているに過ぎないのであって依拠はない、という考え方です。
この考え方は、「このタイプのAIにおいて元データとなった著作物と同一・類似の著作物が生成されることは、本当に「偶然」にすぎず、極めて出現可能性が低いのだから、この場合に依拠を否定しても(著作権侵害を否定しても)著作権者の利益を不当に害することはないだろう」という価値判断が背景にあるように思えます。
さらに、人間の場合、過去に知覚した表現等を無意識のうちに利用してしまった場合には依拠なしとする学説が多数説とされています。
AIはいったん読み込んだ元データを忘れないのだから「無意識のうちに利用」ということはありえないのではないかとも思われますが、元データを増やせば増やすほど、個々の元データの影響力は薄まっていくことからすれば、AIであっても「無意識のうちに利用」ということはありえると思います。(清水委員はこれを第三回委員会で「私の考えではAIは物を忘れることがあります。しかも結構頻繁に。」と文学的に表現しています)
▼ 現在の通説に従えば依拠は認められる
しかし、現在の、通説的な著作権法に関する理解では、「(既存の著作物に対する)アクセスがあれば依拠を認めるべき」とされています。
したがって、元データの中に含まれている著作物と類似の著作物が生成された場合には当然「アクセス」はありますので「依拠」もありということになります。
新たな情報財検討委員会の議論も大勢はそうなっています。
現行法の解釈としては、そのように理解せざるを得ないかもしれません。
したがって、仮にAIが元データに含まれる著作物と類似の著作物を生成したケースの著作権侵害訴訟においては、「依拠」は肯定され、勝負は「類似性の有無」一本になる、ということになるのではないかと思われます。
そして、元データに含まれる著作物と、AIが生成した著作物が完全に一致すると言うことはおそらくないでしょうから、結局のところ、「(著作物ではない)作風だけが一致している」か「表現の本質的特徴を直接感得できる」かが争われることになると思われます。
これは、なにもAI特有の問題ではなく、通常の裁判でもよく争われる争点ですね。
■ 関与している当事者が複数の場合さらに問題は複雑に
さて、これまで見てきたように、AIが元データに含まれる著作物と表現が類似した著作物を生成した場合は著作権侵害になるとして、関与している当事者が複数の場合、さらに複雑になります。
たとえば、学習用データを収集した人、データ処理をした人、学習を行った人、出力指示を行った人、それぞれが異なることは十分にありうるのであって、その場合に誰が責任を負うか、ということです。
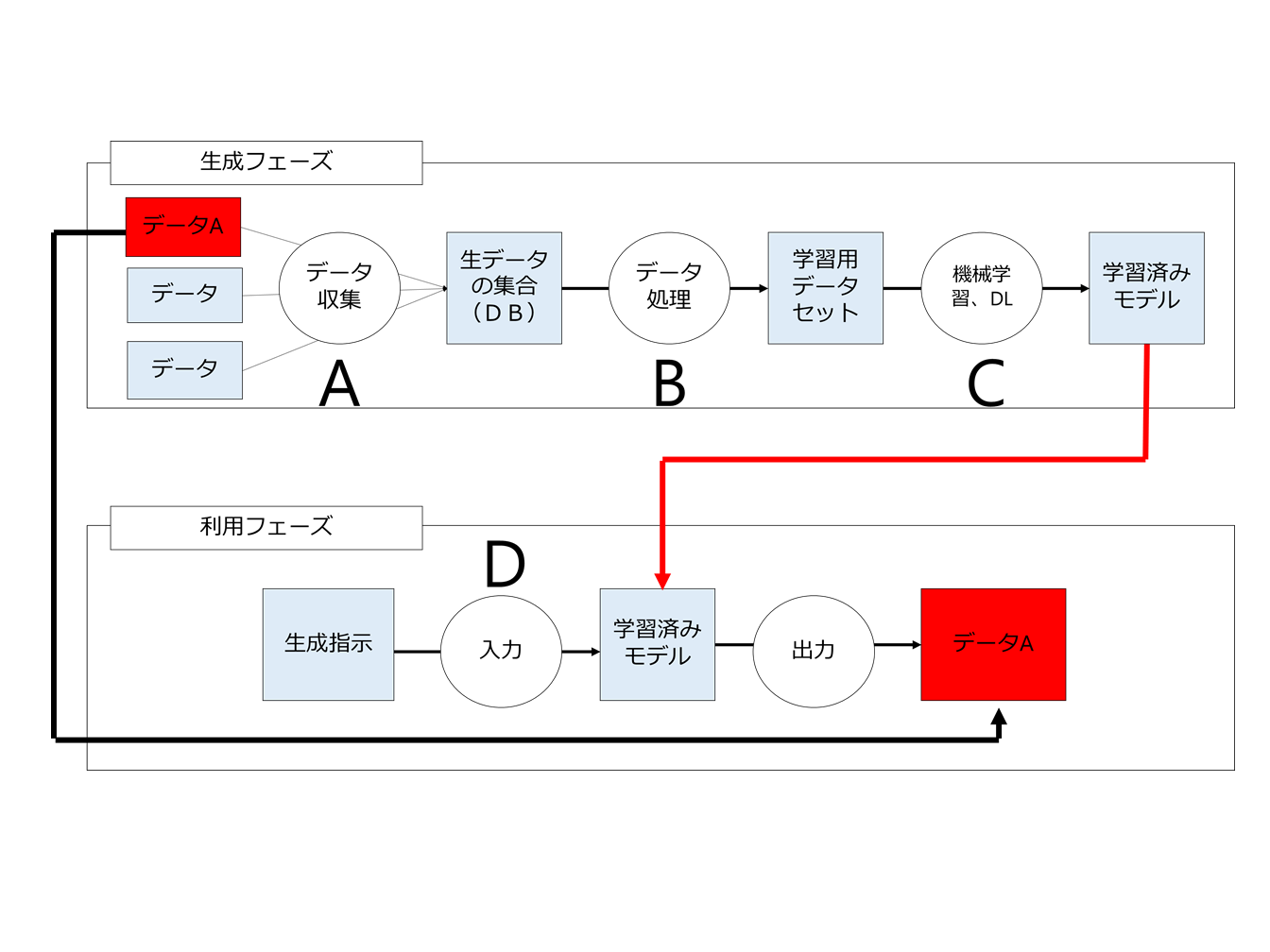
学習用データを収集した人(A)、データ処理をした人(B)、学習を行った人(C)、出力指示を行った人(D)のうちだれが責任を負うのか、あるいは全員が責任を負うのか、という問題です。
この点についてはまだ確立した見解はありませんが、1つのポイントとなるのは「行為者の内心ごとに依拠の有無を判断するのか」という点です。
実は、「依拠」については「既存の著作物の表現内容の認識と、その自己の作品への利用の意思が必要」とする考え方と「他人の著作物を自己の作品に利用する事実で足りる」という考え方の2つがあります。
前者は「個々の利用者の内心を問題にする考え方」、後者は「利用者の内心を問題とせず、客観的な事実のみを問題にする考え方」と言えるでしょう。
前者の立場に立った場合、A、B、C、Dそれぞれの内心を元に「依拠」の有無を判断することになります。
例えば、どのようにしてAIが生成されたかを全く知らないD(AIに生成指示をした人)については、依拠が否定されるケースも多くなると思われます。
一方で、他人の著作物を自己の作品に利用する事実で足りる」という考え方に立つと、個々の行為者の内心は問題となりませんので、Dについても依拠が肯定される、ということになりそうです。
新たな情報財検討委員会報告書でも、この点について明確な結論は出していません。
■ まとめ
▼ AI利用に伴う法的責任として、「ある学習用データを利用して適法に学習済みモデルを生成したのに、当該学習済みモデルに何らかの入力を行ったところ、元の学習用データの一部又は類似する結果が出て来てしまった場合著作権侵害になるのか」という問題がある。
▼ 著作権侵害となるには「類似性」+「依拠」が必要
▼ 「類似性」については、単に「作風」が似ているだけでは著作権侵害にならない
▼ 「依拠」については元データをそのまま利用しているニセAIはもちろん、元データをそのまま利用しているリコメンド型AIについても当然「依拠」は肯定される。
▼ 難しいのは、元データを特徴ベクトル・パラメーターに変換しているため元データの痕跡が学習済みモデルに残っていないAIだが、これも現在の通説にしたがえば、元データへのアクセスがあるため「依拠」は肯定され著作権侵害となる。
▼ 結局のところ問題は、元データの著作物と出力された著作物との間に「類似性」があるか否かとなる。
▼ 関与している当事者が複数の場合さらに問題は複雑に
(弁護士柿沼太一)
(2023年6月3日一部編集)
→STORIAへのお問い合わせやご相談はこちらから