【スタートアップ資本政策連載・第3回】 株式の取り扱い
【スタートアップ資本政策連載・第3回】 株式の取り扱い

【スタートアップ資本政策連載・第2回】何のために法人化するのか

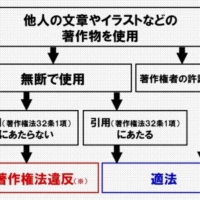
【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~第6回
【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~第4回
【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~第5回
【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~第3回
【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~第2回
【連載】生成AIと著作権~文化審議会著作権分科会法制度小委員会「考え方」を踏まえて~第1回

2024年4月1日改正個情法規則の施行で生じるプライバシーポリシーへの影響

文化庁「AIと著作権に関する考え方について(素案)令和6年1月15日時点版」の検討