人工知能(AI)、ビッグデータ法務
AIにおける学習済モデルを守る3つの方法(基礎編)
Contents
■ はじめに
深層学習(DL)によりAIを生成する際には、大量の生データを用いて学習用データセットを生成し、当該学習用データセットを用いてDLを行って学習済みモデルを生成します。
学習済みモデル生成のためには質の良いデータセットと強力な計算資源が必要であるため、AIの中核的価値は学習済みモデルにあると言っていいでしょう。
したがって自ら、あるいは外注して生成した学習済みモデルをどのように保護するかはビジネスにおいて非常に重要な課題となります。
私どもはAIに関する相談を多数受けていますが、その中で非常に良く聞かれるのがこの「どのように学習済みモデルを保護するか」という点です。
たとえば以下のような相談を受けることがあります。
【設例】
工場用ロボット操業用の学習済モデルを生成したうえでロボットに組み込んでメーカーX社に納品したが、X社の担当役員によりモデルごとロボットが持ち出されてZ社に持ち込まれ、Z社により同じモデルを組み込んだロボットが販売された。どのように対処したら良いか。
この点について検討するためには、「学習済みモデルを保護する3つの方法」「特許権、著作権、営業秘密それぞれによる保護の特徴」などの一般論を知って頂く必要があります。今回の記事ではこの一般論についてご説明をし、次回以降の記事でその一般論を前提として、実際に学習済みモデルを保護する実践的な方法についてご紹介したいと思います。
■ 学習済みモデルを保護する3つの方法
学習済みモデルを保護する方法は大きく分けて以下の3つがあります。
1 技術(アーキテクチャー)
2 契約
3 法律
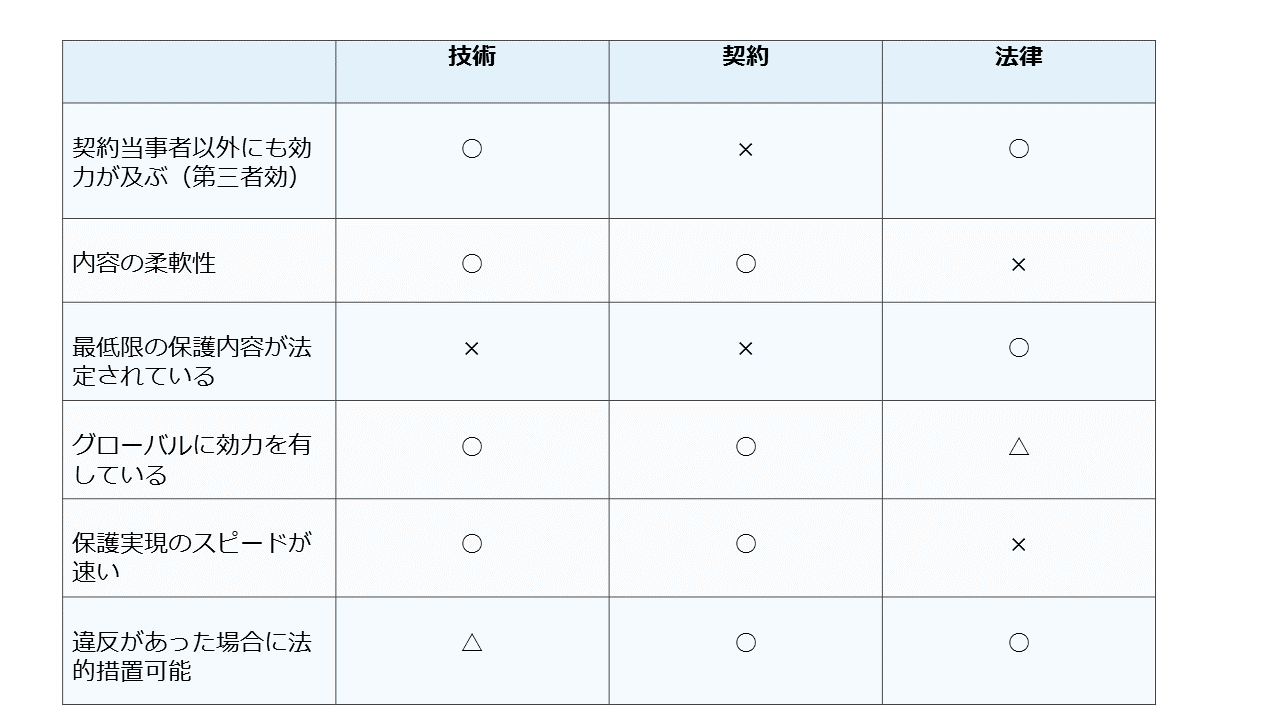
1の「技術」は要するに学習済みモデルが簡単にコピーできないように技術的な工夫を行うというものです。
たとえば、学習済みモデルそのものを納品するのではなく、モデルをクラウド上に置いて、出力のみをサービスとして提供するようなサービスモデルを採用する方法などです。ただ、自動運転用AIや工場ロボット用AIの場合はモデルそのものを自動車やロボットに組み込まなければなりませんから、そのようなサービスモデルを採用することができず、無断コピーされる危険性が高いという限界があります。
2の「契約」は、何らかの契約に基づいて学習済みモデルを提供する場合に,さまざまな利用条件を付したり条件違反の場合の賠償責任を定めたりすることで学習済みモデルを保護する方法です。
3の「法律」と違って「契約の相手方しか拘束できない」という限界はありますが、柔軟な条件を定めたり、法律の制定を待たずに保護が開始できる、さらにはグローバルに効く、という点が大きなメリットです。
また、次回以降の記事でご説明しますが、実は3の「法律」での保護の実効性を高めるためにはこの「契約」がきちんとしているかどうかが非常に重要となります。
3の「法律」とは、知的財産を保護する法律(特許法、著作権法、不正競争防止法)などによって、学習済みモデルを「知的財産(権)」として保護するという方法です。
もっとも、学習済みモデルの場合、派生モデルや蒸留モデルを生成することが可能であることから、現行の知的財産制度による保護にはなかなか高いハードルがあります(詳細は後述します)。
これら3つの手段をまとめたのが以下の表です。
■ 特許権、著作権、営業秘密(不正競争防止法)による保護
さきほど述べた3つの保護方法(技術、契約、法律)のうち、「法律による保護」について、もう少し掘り下げて検討します。
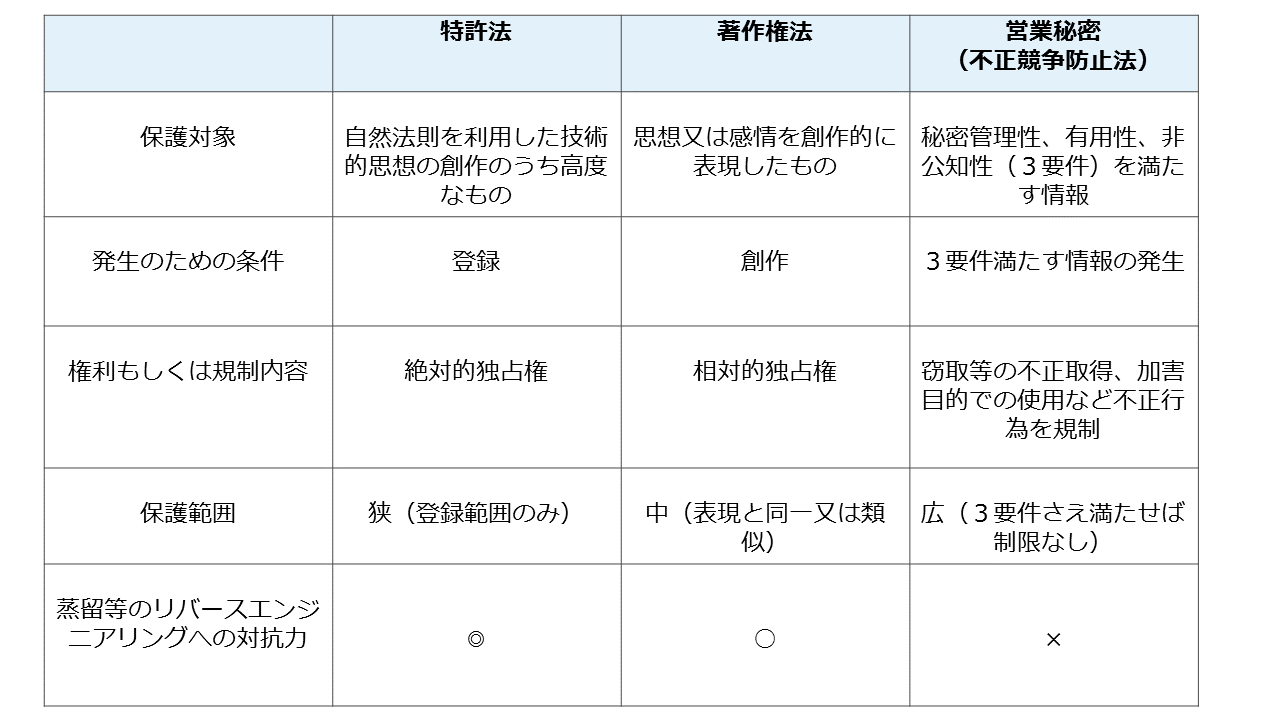
学習済みモデルを現行の知財制度によって保護しようとする場合、特許権、著作権、営業秘密(不正競争防止法)が考えられます(他にも新しい権利による保護なども考えられますが、AIは技術的なスピードが非常に速い分野ですし、我が国だけで独自の権利を創設してもあまり意味がないことから、政府でも積極的な検討はされていません)。
私の個人的な意見としては、学習済みモデルに関しては、現時点では営業秘密による保護が実務的には一番使えるのではないかと考えています。
営業秘密の特徴としては、「秘密管理性」「有用性」「非公知性」の3要件さえ満たせばあらゆるデータ、情報が保護の対象となるという点です。
ここが、「発明」のみ保護する特許権や、「創作」のみ保護する著作権とは大きく違うところです。また、特定の技術に依存していないという点も営業秘密による保護の強みです。
その一方で、営業秘密自体に何らかの権利が発生するわけではなく、データを窃取したり、正当に取得したデータを不正利益を得る目的で開示する場合など、「不正行為」が規制されているに過ぎません。なので、「不正行為」に該当しないリバースエンジニアリングには弱い、という限界があります。
詳細は次回以降の記事で説明いたします。
■ 特許権と著作権の違い
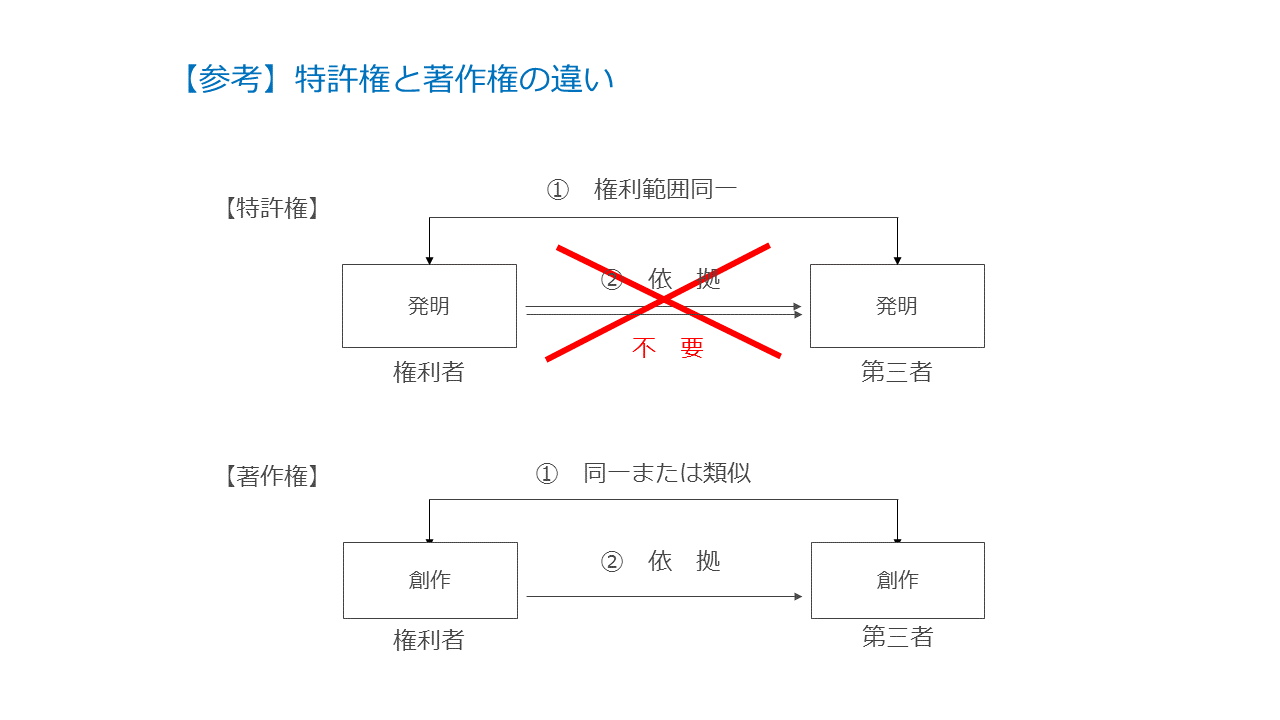
先ほどの表で特許権について「絶対独占権」、著作権について「相対的独占権」という表現が出て来ましたので、少し説明をします。
「絶対的独占権」とは、客観的内容を同じくするものに対して排他的に支配できる権利で、「相対的独占権」とは、客観的な内容が同じであっても、他人が独自に創作したものには及ばない、という権利です。
言い換えれば、偶然似てしまった場合には権利行使できないのが相対的独占権(著作権)で、偶然似てしまったとしても内容が同一であれば権利行使できるのが絶対的独占権(特許権)ということになります。
つまり、権利者が権利行使するには「内容同一」+「依拠」が必要なのが相対的独占権(著作権)で、「内容同一」でありさえすれば権利行使が可能なのが絶対的独占権(特許権)です。
図で示すとこのような感じです。
■ 派生モデルと蒸留
もう少し一般論におつきあいください。
先ほど説明したように、学習済みモデルの特殊性は、派生モデルや蒸留モデルを生成することが可能であるという点です。
▼ 派生モデルとは
派生モデルというのは、ある学習済モデルに対して新しいデータを利用して再学習させた結果できたモデルのことです。
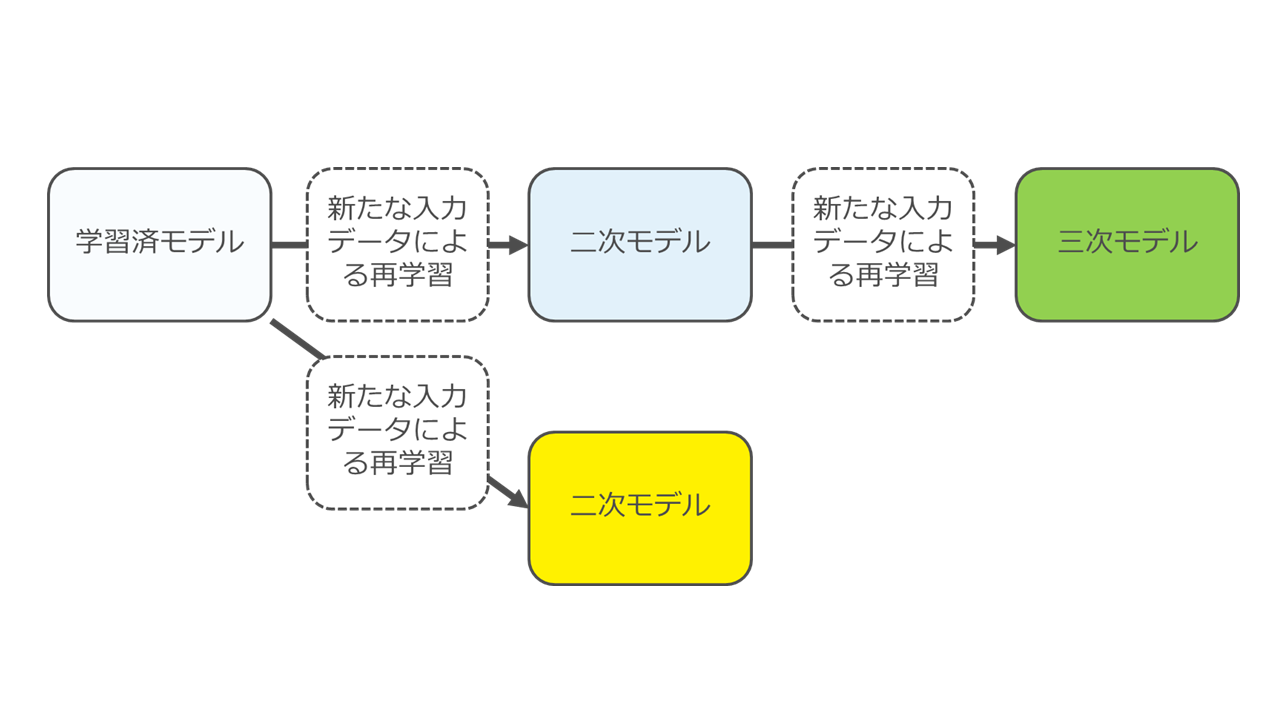
元のモデルより、より精度の高いものができますが、再学習により重み付けデータが更新されるため、元のモデルと全く異なる形になっている、つまり元のモデルとの関連性が存在しない点が、モデルの保護の際に大きな問題となります。
▼ 蒸留モデルとは
蒸留とはこういう行為です。
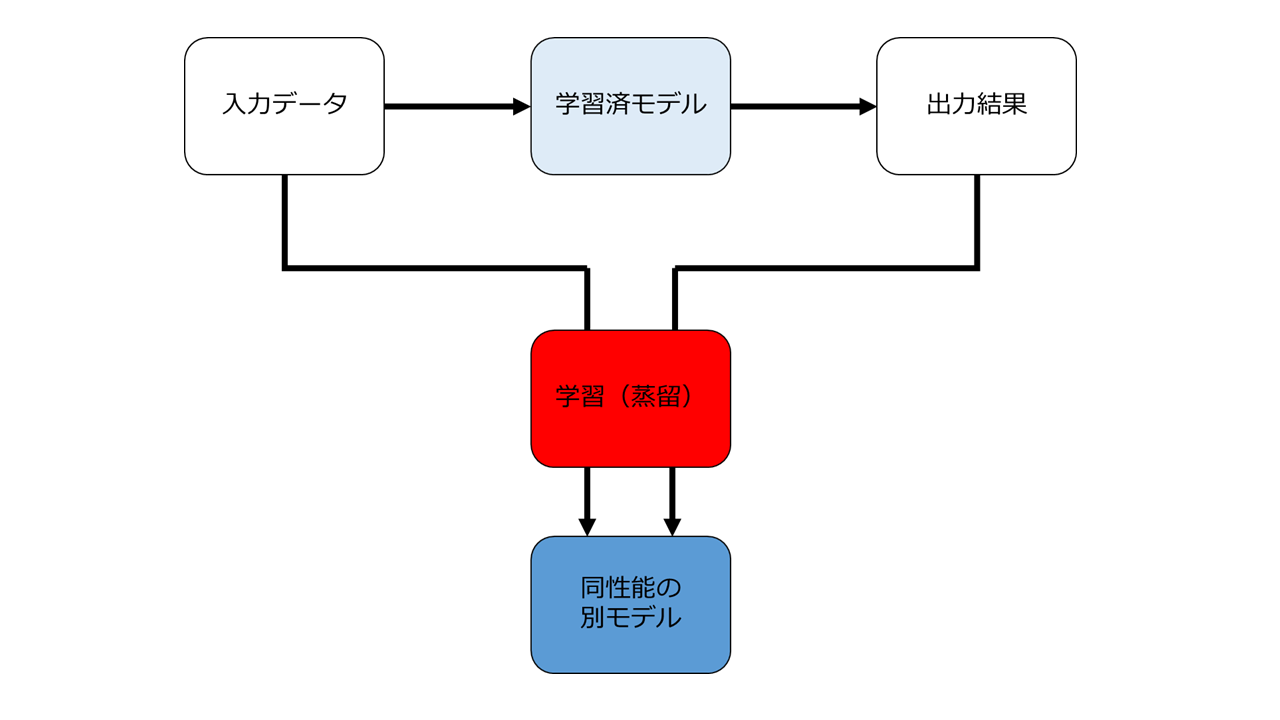
要するに学習済モデルを直接コピーしなくても、入力データと出力データを用いて別途学習をすることで全く異なるモデルを生成できる、という行為です。
これにより、性能がほとんど変わらず、かつ軽量なモデルができると言われています。
しかも、この蒸留行為は、学習済モデルが外から見えない状況(ブラックボックス化された状況)になっていても可能です。
「蒸留」行為の問題点は、 派生モデルと同様、元のモデルと全く異なる形になっている、つまり元のモデルとの関連性が存在しないことです。
▼ 何が問題なのか
知的財産制度は、ものすごく単純にいうと、ある知的財産を独占することができ、かつ他人が当該知的財産と「同一・類似の」知的財産を利用することを禁じることができる、という点に本質があります。
たとえば、特許で言えば、特許権者は、特許発明を独占的に実施する権利を有し、他人が無断で特許発明を実施した場合には、特許権者はこのような侵害行為を停止させ(差止請求権)、特許権侵害によって被った損害を賠償させることができます(損害賠償請求権)。
しかし、学習済みモデルの場合、元のモデルに新たなデータを用いて更に学習することで得られる「派生モデル」や、元のモデルの入力と出力のみを用いて生成される「蒸留モデル」は元のモデルとは全く違う形式になっており、元のモデルの痕跡は残っていません。
つまり、ある学習済みモデルを知的財産として保護したとしても、当該モデルを元に派生モデルや蒸留モデルが生成されてしまった場合、元のモデルとの同一性・関連性が立証できず、権利行使(差し止めや損害賠償請求)ができないという問題があるのです。
ここに、知的財産制度によって学習済みモデルを保護する場合の最大の難しさがあります。
■ まとめ
▼ 学習済みモデルを保護する方法は、「技術」「契約」「法律」の3つがあり、それぞれ一長一短がある。
▼ 法律による保護には「特許権」「著作権」「営業秘密(不正競争防止法)」によるものがあり、保護の範囲の広狭や蒸留(リバースエンジニアリング)に強いか弱いかという違いがある。
▼ 学習済みモデルを法律(知的財産制度)で保護するのが難しいのは、派生モデルや蒸留モデルの場合、元のモデルとの同一性、関連性が存在しないためである。
次回は具体的な設例を元に、学習済みモデルを保護する実践的な方法について検討します。










