人工知能(AI)、ビッグデータ法務 知的財産 裁判例
freee vs マネーフォワードの特許権侵害訴訟第1審判決はAIの観点からも興味深い
株式会社マネーフォワード(以下「MF社))の「MFクラウド会計」が自社の特許を侵害しているとして、フリー株式会社(以下「freee」)が2016年10月に東京地方裁判所に提起した特許権侵害訴訟ですが、第1審判決が2017年7月27日に出ました。
結果は特許権者であるfreeeの敗訴です。
【参考】
自動仕訳で特許侵害なし、マネーフォワードがfreeeに勝訴会計の仕訳項目を機械的に判定するアルゴリズムを巡ってfreeeとマネーフォワードの間で争われた特許訴訟が9カ月という比較的短期で終結した。東京地裁が先ほど(7月27日午後に)出した判決は、freee側の請求を棄却するもので、特許侵害は認められないという結論だった。
この裁判は、ベンチャー同士の特許権侵害訴訟ということでも注目を集めたのですが、AI(正確には機械学習)を利用した技術と特許侵害という面からも、なかなか面白い判決です。
ちなみに私は,freeeは事務所の会計管理で、マネーフォワードは家計管理でいずれもお世話になっています。いずれも非常に優秀なサービスです。
今回は、この裁判を題材に、「特許権侵害とはどのような行為のことをいうのか」「特許権侵害訴訟とはどのような訴訟なのか」「なぜfreeeが敗訴したのか」「MFアルゴリズムを巡るもう1つの攻防」についてできるだけわかりやすく説明をします。
以下freeeのソフトウェア特許(第5503795号)を「freee特許」、freee特許で用いられているアルゴリズムを「freeeアルゴリズム」、MFクラウド会計で用いられているアルゴリズムを「MFアルゴリズム」と呼びます。
Contents
1 双方の主張の概要
freeeは「MFクラウドはfreee特許を侵害している」と主張しましたが、このfreee特許はいわゆる自動仕訳に関する特許であり、MFクラウドも自動仕訳の機能を有しています。
しかし、MFは「MFは自動仕訳機能を有しているが、freee特許に記載されているような自動仕訳ルールではなく、機械学習を用いて自動仕訳を行っているからfreee特許を侵害していない」と主張しました。
要するに自動仕訳を実現する仕組み(アルゴリズム)が異なると主張したわけですが、1審ではこのMF側の主張が認められ、freee特許を侵害していないという判断が下されました。
この判断がどのような内容だったかを説明する前に、特許権侵害や特許権侵害訴訟のことについて簡単に説明をします。
2 どのような場合に特許権侵害になるか
特許権侵害が認められた場合、製品の生産・使用の差止請求や損害賠償請求をすることができますが、そもそも「相手が自分の特許権を侵害している」といえるためには以下の3つの要件を満たすことが必要です。
1) 原告が特許権を保有していること
2) 被告が、ある製品を製造・販売、使用していること
3) 被告の製造販売している製品(あるいは使用している方法)が原告の特許権を侵害していること
このうち最も問題になることが多いのは3)の要件です(「権利侵害の要件」といいます)。
この「権利侵害の要件」を満たしているかどうかは、以下のような方法で判定します。
1 特許発明における「特許請求の範囲」を複数の要素に分解する
2 対象製品(または方法)をこれと比較
3 の要素を全て満たしているかどうかを判断
図にするとこのようなイメージです。

たとえば、今回のfreee特許の特許公報を見ると1頁目に「特許請求の範囲」という部分があるのが分かりますが、この「特許請求の範囲」を分解していくことになるわけです。

ちなみに、今回のようなソフトウェア特許の場合は、相手方が販売・使用しているソフトウェアのアルゴリズムがいわばブラックボックス状態なので、原告において②③の作業を行うことが非常に難しいと言われています。
実際、今回の訴訟でもfreeeはその点に非常に苦戦しています。
3 freee特許はどのような内容か
■ freee特許の「特許請求の範囲」を複数の要素に分解すると
先ほど説明したように、まずfreee特許の「特許請求の範囲」を複数の要素に分解する必要があります。
裁判所が整理した内容は以下のとおりとなります(以下の要素は、freee特許のうち「方法の発明」の請求項13のものです)。
A ウェブサーバが提供するクラウドコンピューティングによる会計処理を行うための会計処理方法であって、
B 前記ウェブサーバが、ウェブ明細データを取引ごとに識別するステップと、
C 前記ウェブサーバが、各取引を、前記各取引の取引内容の記載に基づいて、前記取引内容の記載に含まれうるキーワードと勘定科目との対応づけを保持する対応テーブルを参照して、特定の勘定科目に自動的に仕訳するステップと、
D 前記ウェブサーバが、日付、取引内容、金額及び勘定科目を少なくとも含む仕訳データを作成するステップとを含み、作成された前記仕訳データは、ユーザーが前記ウェブサーバにアクセスするコンピュータに送信され、前記コンピュータのウェブブラウザに、仕訳処理画面として表示され、前記仕訳処理画面は、勘定科目を変更するためのメニューを有し、
E 前記対応テーブルを参照した自動仕訳は、前記各取引の取引内容の記載に対して、複数のキーワードが含まれる場合にキーワードの優先ルールを適用し、優先順位の最も高いキーワードにより、前記対応テーブルの参照を行う
F ことを特徴とする会計処理方法。
このうち特に問題となった(MFクラウドが同じ方法を利用しているかどうかが問題となった)要素は、自動仕訳に関するCとEです。
■ freeeアルゴリズムの内容の解釈が裁判の勝敗を決した
freeeとしては、MFアルゴリズムが、このCとEを満たしていると言いたいわけですから当然CとEについてはなるべく広く解釈をし、freeeアルゴリズムが機械学習によるアルゴリズムも含むような主張をしています。
一方、MF社としては逆に狭く解釈する方向での主張をすることとなる訳ですが、結果的には、この部分における攻防が本件での勝敗を決したように思います。
裁判所が最終的に認定したfreee特許に含まれるfreeeアルゴリズムは以下のとおりでした。
まず、「取引内容に含まれるキーワードに対応する勘定科目を1対1で対応づけた対応テーブル(対応表)」と「キーワードの優先ルール」を用意します(これは別々ではなく1つのテーブルとして存在していても良いでしょう)。
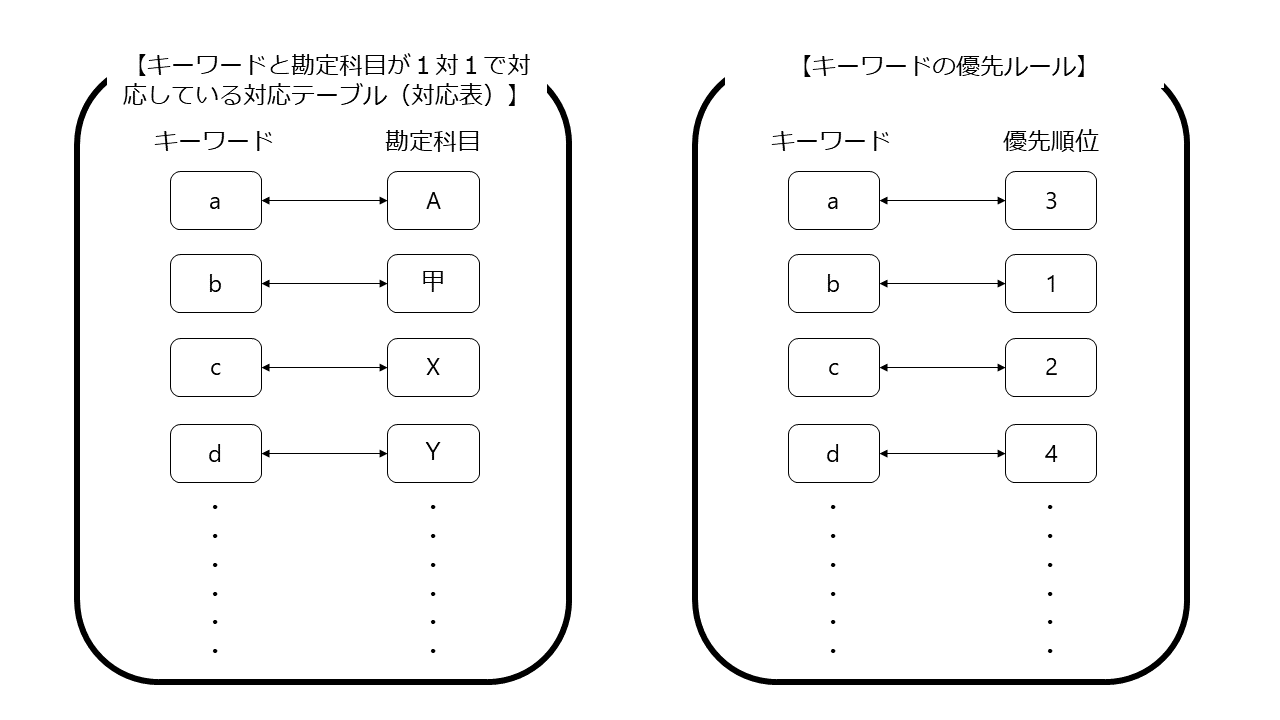
その上で、取引内容の記載に複数のキーワードが含まれる場合には、まず「キーワードの優先ルール」を適用して、優先順位の最も高いキーワードを選定し、選定されたキーワードを「取引内容に含まれるキーワードに対応する勘定科目を1対1で対応づけた対応テーブル(対応表)」と照合して、特定の勘定科目を選択する、という仕組みです。
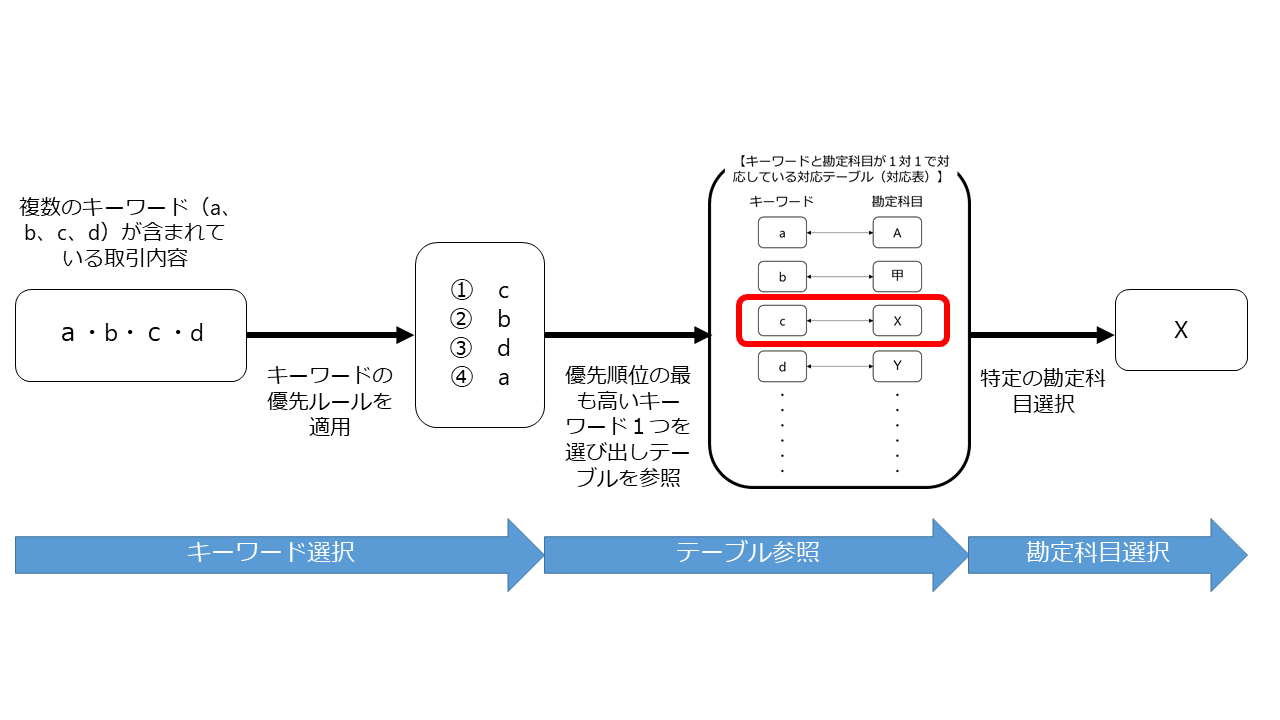
簡単にいうと「キーワードを1つに絞り込んで」「絞り込んだキーワードでテーブルを参照して勘定科目を選択する」というアルゴリズムですね。
freee特許の明細の中にある例(「モロゾフ JR大阪三越伊勢丹店」という取引内容を仕訳する例)で考えると以下のようになると思われます。
まずは「取引内容に含まれるキーワードに対応する勘定科目を1対1で対応づけた対応テーブル(対応表)」と「キーワードの優先ルール」を用意します。
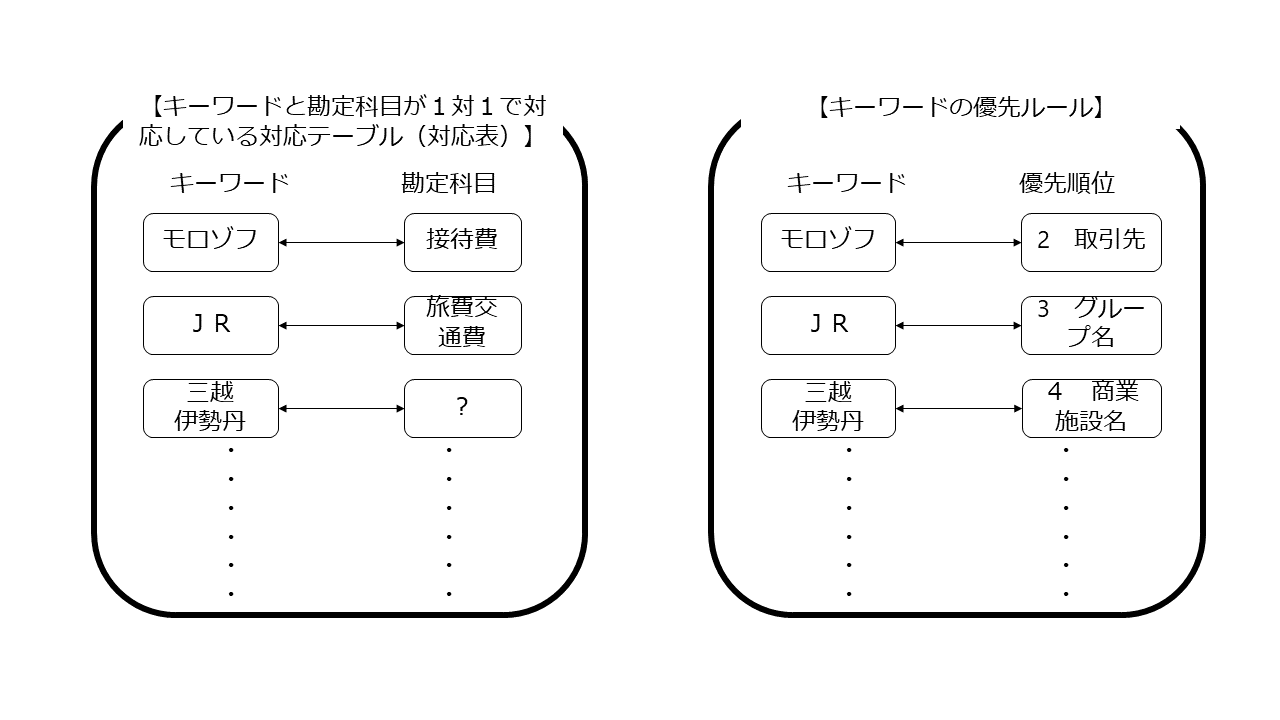
次に「キーワードの優先ルール」を適用して、優先順位の最も高いキーワードを選定し、選定されたキーワードを「取引内容に含まれるキーワードに対応する勘定科目を1対1で対応づけた対応テーブル(対応表)」と照合して、特定の勘定科目を選択します。

freeeアルゴリズムを、このようにいわば「1キーワード選択+テーブル参照方式」と裁判所に認定されたことにより、この裁判の勝負はほぼ決していた、といえるように思います。詳しくは後述します。
4 MFアルゴリズムはどのような内容か
このようにfreeeアルゴリズムの内容が特定されました。
それでは、MFアルゴリズムの内容はどのようなものだったのでしょうか。
これは一言で言うと「機械学習を利用したアルゴリズム」というものでした。
MF社は訴訟でMFアルゴリズムについて以下のとおり主張しています。
「被告は、これまでのサービスの提供を通じて自らが保有する莫大な数の実際の仕訳情報の中から抽出した膨大なデータを、学習データとして利用することで(すなわち、すでに正解が判明している大量の取引データをコンピューターに入力して学習させることで),新たな取引いについても、より高い確率で適切な勘定科目に仕訳することができるようなアルゴリズムをコンピューターに自律的に生成させ、これを本件機能に用いているのである。」
つまり、MFアルゴリズムは、教師ありデータを用いた機械学習により自動的に生成された予測モデルである、ということですね。
とすると、先ほど裁判所が認定したfreeeアルゴリズムの内容(テーブル参照方式)とはかなり違うように思えます。
現にMF社はこのように主張しています。
「このアルゴリズムは、極めて複雑な多数の数式の組み合わせから構成されるものであって、キーワードと勘定科目の「対応テーブル」を参照するなどというものではないし、そもそもキーワードと勘定科目が対応づけられたテーブルなど保持していない」「(MFアルゴリズムは)取引の内容の記載に複数のキーワードが含まれている場合にはそれら全てのキーワードと、さらにサービスカテゴリや金額も、機械学習により自律的に生成されたアルゴリズムに入力して、勘定科目を選択している」
このMF社の主張を図で示すと以下のとおりとなります。

5 MF社の興味深い訴訟戦術
■ MF社の戦術
では、MF社は、具体的にどうやって「freeeアルゴリズムとMFアルゴリズムが違うこと」を明らかにしようとしたのでしょうか。
まず、MFクラウドにおける自動仕訳のアルゴリズムを開示することで、直接「freee特許におけるアルゴリズムと異なること」を立証するという方法も考えられます。
しかし、これはすぐに分かるように「MF社にとって極めて重要なアルゴリズムをライバルであるfreeeに開示してしまうこと」を意味しています。
できません。
そこで「MFアルゴリズムを使うと、freeeアルゴリズムでは説明の付かない自動仕訳結果が出ること」を証明することで「MFアルゴリズムとfreeeアルゴリズムは異なる」ということを証明しようとしたのです。
これは、「ライバルにアルゴリズムを開示せずに、アルゴリズムの違いを証明する」という点で非常に興味深い戦術です。
結果的にこの戦術は成功を収め、裁判所はこの点に関するMFクラウドの主張を認めました。
これは、ソフトウェアの特許権侵害訴訟においては、「アルゴリズムが違う」ということだけ明らかになれば被告は勝てるのであって、被告であるMF社としては「自社のアルゴリズムがこのような内容である」ということを具体的に明らかにしなくてもよいことから可能になった戦術と言えるかもしれません。
■ MFアルゴリズムを使うと、freeeアルゴリズムでは説明の付かない自動仕訳結果が出ること
裁判所が認定した「MFアルゴリズムを使うと、freeeアルゴリズムでは説明の付かない自動仕訳結果が出る」とした点は具体的には3点あります。
1 摘要に含まれる取引内容が複数の要素に分解できる場合、各要素を入力し出力される勘定科目の推定結果と、要素を適宜組み合わせて複合語を入力して出力される勘定科目の推定結果が合致しないこと
判決が認定しているのは以下の例です。

つまり「店舗チケット」の語を入力すると「旅費交通費」が出力されるのですが、それを分解した「店舗」のみを入力すると「福利厚生費」、「チケット」のみを入力すると「短期借入金」が出力され「旅費交通費」とは合致しません(ま、「チケット」を入力するとなぜ「短期借入金」が出力されるのか、仕訳的にはよく意味が分かりません。「チケット」を入力すると「旅費交通費」が出力されるのが普通のような気がしますが・・・)。
2 摘要の入力が同一であっても、出金額やサービスカテゴリーを変更すると異なる勘定科目の推定結果が出力されること
判決が認定しているのは以下の例です。

最初の「東京」「5040円」「カード」「旅費交通費」以外の仕訳は、なぜこうなるのかよく分からない仕訳ですが、とにかく判決の言うように「摘要の入力が同一であっても、出金額やサービスカテゴリーを変更すると異なる勘定科目の推定結果が出力されている」ことは間違いありませんね。
3 「鴻働葡賃」のような通常の日本語には存在しない語を入力した場合でも、何らかの勘定科目の推定結果が出力されること
判決が認定しているのは以下の例です。

これも判決の言うとおりですね。
4 まとめ
判決は、仮にMFクラウド会計がfreeeアルゴリズムのようなキーワード対照方式を利用しているのであれば、上記のような出力がなされるとは考えにくいとして「かえって、被告が主張するように、いわゆる機械学習を利用して生成されたアルゴリズムを適用して、入力された取引内容に対応する勘定科目を推測していることが窺われる」としました。
もちろんfreee側は、上記のような出力がなされたことについて「未知のキーワードの一部に勘定科目と対応づけられているものがあるかもしれない」「未知のキーワードについては一律に金額に応じた勘定科目を付与する例外処理があるかもしれない」などと主張しましたが、いずれも「そのような証拠は一切ない」として退けられています。
6 MFアルゴリズムを巡るもう1つの攻防
■ freeeによる文書提出命令申立
もちろん、freeeも訴訟の中で手をこまねいていたわけではありません。
「freeeアルゴリズム=MFアルゴリズム」であることを証明するために、「MF社が勘定科目提案機能に関して行った特許出願にかかる提出書類一式」について平成29年4月14日に文書提出命令を申し立てました。
え?「MF社が勘定科目提案機能に関して行った特許出願」?
そんな特許出願があったことは知りませんでした。
INPITのデータベースを検索しましたが、MF社の出願としては以下で紹介する出願しか掲載されていないようです。
ネットをざっと調べた限りではMF社による自動仕訳に関する特許出願に関する情報はありませんでした。
MF社は2015年2月17日のプレスリリースで特許出願を行ったことを明らかにしているのですが、この時に出願している特許(特願2015-26999)は、金融機関などから定期的に取引明細を自動取得して一括表示するシステム(アカウントアグリゲーションシステム)に関するものであり、勘定科目提案機能とは無関係のように見えます。
もしかしたら、MF社は、上記出願とは別に自動仕訳に関する出願をしており、それをfreee社が何かのきっかけで知ったことから、このような文書提出命令申立を行ったのかもしれません。
「文書提出命令」というのは、ある文書を所持している者に対して、当該文書の提出をするようにとの命令を裁判所が出すことです。
この「文書提出命令」というのは、特許権侵害訴訟に限らず一般の民事事件の裁判でももちろん利用できるのですが、特許法には特別の規定(特許法105条)があります。
(書類の提出等)
第百五条 裁判所は、特許権又は専用実施権の侵害に係る訴訟においては、当事者の申立てにより、当事者に対し、当該侵害行為について立証するため、又は当該侵害の行為による損害の計算をするため必要な書類の提出を命ずることができる。ただし、その書類の所持者においてその提出を拒むことについて正当な理由があるときは、この限りでない。
今回、freeeはこの特許法105条を使って文書提出命令の申立をしました。この条文にあるように「提出を拒むことについて正当な理由」がある場合は提出命令の対象にはならないのですが、そもそもその文書の内容を裁判所が見なければ「正当な理由」があるかどうかを判断できません。
そこで、特許法105条2項は「正当な理由があるかどうか」の判断をするために、裁判所は当該文書の内容を見ることができる、としました(これを「インカメラ手続」といいます)。
2 裁判所は、前項ただし書に規定する正当な理由があるかどうかの判断をするため必要があると認めるときは、書類の所持者にその提示をさせることができる。この場合においては、何人も、その提示された書類の開示を求めることができない。
■ インカメラ手続の結果・・・・・
そして、本件でもこのインカメラ手続が実施されました。
その結果「対象文書には、被告製品及び被告方法がfreee特許の構成要件に相当又は関連する構成を備えていることを窺わせる記載はなかった」として、MF社には文書提出を拒む「正当な理由」ありと判断し、結果的に裁判所はfreeeの文書提出命令申立を却下しました。
■ 文書提出命令の申立をすべきだったかは難しい判断
この「MF社が勘定科目提案機能に関して行った特許出願にかかる提出書類一式」の内容がよく分かりません。
ただ、もしMFアルゴリズムの内容が記載されている書類だったとすると、freeeの文書提出命令の申立がなければ、裁判所が「MF社が勘定科目提案機能に関して行った特許出願にかかる提出書類一式」を見る機会はなかった、つまりMFアルゴリズムの具体的内容を把握する機会がなかったはずです。
しかし、実際には、freeeの文書提出命令の申立があったことにより、特許法105条2項の「正当な理由」の判断を行う過程で、裁判所はMFアルゴリズムの詳細な内容を把握できた(というか把握してしまった)のです。
その結果、裁判所は「対象文書には、被告製品及び被告方法がfreee特許の構成要件に相当又は関連する構成を備えていることを窺わせる記載はなかった」と判断しているわけですから、結局、裁判所がMFアルゴリズムの内容を把握したのは、freeeにとってはマイナスだったように思います。
裁判所がMFアルゴリズムの内容を見たのは、あくまで「正当な理由」があるかどうかの判断のためですから、そこで見てしまったMFアルゴリズムの内容を根拠に勝ち負けを決するわけにはいかないのですが、事実上影響はなかったとは言い切れません。
もちろん、freeeとしては、このようなリスクは十分に把握した上での文書提出命令申立だったのだと思われます。
それは、申立が審理終結日(平成29年5月12日)の直前である平成29年4月14日であったことからも窺われます。ギリギリまで申立をするかどうかを迷っていたのかもしれません。
7 残された謎
また本件では、1つよく分からない点があります。
それは「なぜfreeeは機械学習の特許権侵害を主張しなかったのか」という点です。
実は、freeeは今回の訴訟で侵害を主張した特許権(第5503795)とは別に、機械学習を利用した自動仕訳に関する特許権(特許第5936284号)を2016年5月20日に取得済みです。
【参考】
freee が自動仕訳に関する人工知能(AI)技術の特許を取得。 バックオフィス業務効率化の支援をAIで加速することを目指した 「スモールビジネスAIラボ」 を創設。freee は、創業当初より人工知能による経理効率化に注力し開発を進めており、2016年5月20日付で、クラウド会計ソフトの特徴である自動仕訳機能に関して、人工知能技術を活用した基本特許を取得しました(特許第5936284号)。これを皮切りに、 freee だからこそ実現できる高度な自動仕訳機能、自動消込機能など、人工知能を活用したバックオフィス効率化の機能開発を進めてまいります。
この特許の内容は詳しくは紹介しませんが、この特許に含まれているアルゴリズムは以下のようなもののようです。
1 取引内容の記載を形態素(意味を持つ最小の言語単位)に分節する
2 機械学習による学習済みDBを参照して「各形態素に対応づけられた1又は複数の勘定科目の出現確率」を読み出す
3 2の出現確率をスコアとして合計して最も高いスコアの勘定科目に自動的に仕訳をする
4 2の学習済みDBは、サービスを利用する複数のユーザーが推測結果を修正することによってさらに学習を継続し、推定精度が高まっていく
MFアルゴリズムと同じアルゴリズムかどうかは不明ですが、機械学習を利用していることは明らかですから、少なくとも今回の裁判で主張したテーブル参照方式の特許権(第5503795)におけるアルゴリズムよりは、MFアルゴリズムに近いように思えます。
では、なぜこの裁判においてfreeeは機械学習の方の特許権侵害を主張しなかったのでしょうか。
判決の翌日!にfreee代表取締役の佐々木大輔氏と、同社法務本部長の桑名直樹氏がインタビューに応じています(敗訴当事者が判決翌日にきちんとインタビューに応じて、訴訟の内容について説明していることに非常に驚きました。もちろんいい意味で。)
【参考】
マネーフォワード勝訴に対してfreeeは何を思うのか–佐々木代表に聞く(質問)機械学習に関する特許を主張しなかったのはなぜでしょうか。
桑名氏 マネーフォワードの動作を調査し、2つのうちどちらのパターンに近いかを分析したところ、機械学習よりは自動仕訳が近いと判断したこと、またそちらのほうが裁判所にも理解してもらいやすいだろうということで、自動仕訳に関する特許を主張しました。
すると、マネーフォワード側は対応テーブルではなく機械学習だと主張してきましたので、機械学習に関する特許を主張しようとしました。ところが、マネーフォワード側が裁判を急いでいる事情があり、ある程度時間が経った後で反論してきたことから、我々の再反論が遅くなってしまいました。そのため、もう一つの特許に関しては、裁判の手続きに乗りませんでした。裁判は、いつでも主張できるものではないのです。
桑名氏のこの回答が事実なのかどうか、判決文からは分かりませんが、いずれにしても「なぜfreeeは機械学習の特許侵害を主張しなかったのか」という謎は残ります。
ちなみに、freeeの現在のサービスは、テーブル参照方式と機械学習方式の両方を実装しているそうです。
8 まとめ
■ 特許権侵害訴訟においては原告の特許の構成要素と被告製品・サービスの構成要素を比較する。
■ 今回の裁判では、freeeアルゴリズムが「1キーワード選択+テーブル参照方式」と裁判所に認定されたことにより裁判の勝負はほぼ決していたのではないか。
■ MF社の訴訟戦術は「ライバルにアルゴリズムを開示せずに、アルゴリズムの違いを証明する」という点で非常に興味深いものだった。
■ 「文書提出命令」と「インカメラ手続」というもう1つの攻防があった
■ freee社が機械学習の特許侵害を今回の裁判で主張しなかった理由は謎である。










