人工知能(AI)、ビッグデータ法務
そのファイル、実はクラウドに送られています ― AIエージェントを使うと、あなたのデータはどこに送られ、どう処理されているのか

ビジネスレポートや書類を生成するAIエージェント。文章を解析し、要約を作成する生成人工知能。オフィスのデスクでノートパソコンを使ってAIに指示を出すビジネスマン。
Contents
1 AIエージェント、使っていますか
最近、ユーザーのPC上でファイルを読み取り、コードを書き、WordやExcelを操作してレポートなどを作成してくれる「AIエージェント」と呼ばれるツールが急速に普及しています1本稿で扱うのは、ユーザーのPC上で動くホストプログラムが、クラウド上のLLM(Claude、GPT等)と通信しながら処理を進めるタイプのAIエージェントです。Claude Codeのようなツールが典型例です。これに対し、ローカルLLMやオンプレミス構成など、データがクラウドに送信されない構成は本稿の射程外とします。。
AIエージェントについて、最近クライアント企業から「AIエージェントはPCの中で動いているんだから、データはPCの外に出ていないですよね?」というご質問を立て続けにいただきました。
結論から言えば、この理解は正確ではありません。
たしかに、AIエージェントの処理の一部はローカルPC上で実行されます。ですが、クラウド上のLLMに判断をさせるために、ユーザーの指示や、必要に応じてPC内のデータがインターネット経由でLLMに送信される構成になっています。
AIチャット(ブラウザで使うChatGPTやClaude)なら「ファイルをアップロードしている」という動作がある分、データを外部に送っている自覚があるのですが、AIエージェントの場合はその自覚が生まれにくい構造になっています。
本記事では、AIエージェントの技術的な仕組みをできるだけわかりやすく解説した上で、そこから生じる法的リスクと実務上の対策について整理します。なお、GmailやSlackなどの外部サービスとAIを接続した場合のリスクについては、論点が別になるため本記事では扱いません。こちらは次回の記事で取り上げる予定です。
2 AIチャットとAIエージェント ― 見え方の違い
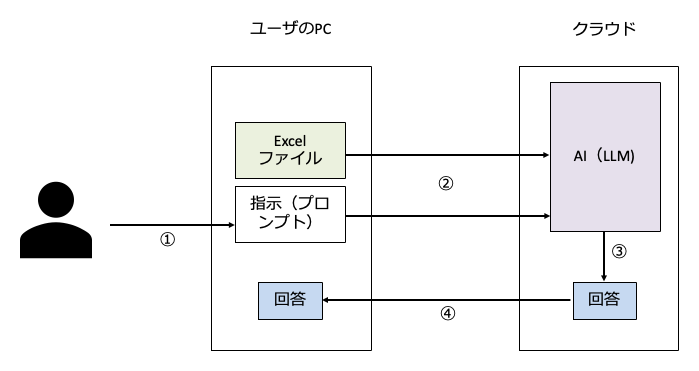
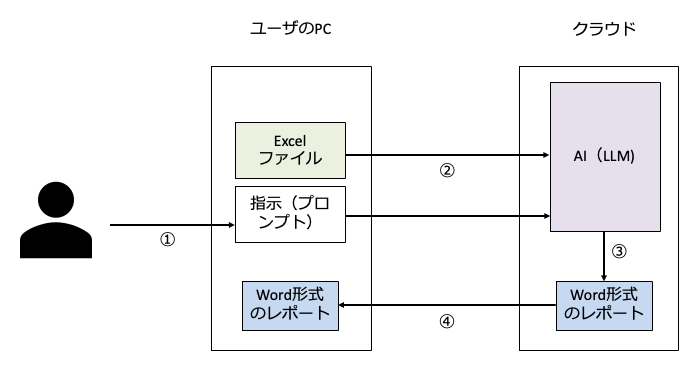
まず、AIチャットとAIエージェントの「見え方」の違いを確認しましょう。たとえば「ユーザーのPC内のExcelファイルをアップロードして解析してもらって解析結果をチャットで返信してもらう」作業を考えましょう。
AIチャット(Claude.aiやChatGPTのブラウザ版など)の場合、ユーザーはプロンプト入力(①)とともに、自分の手でファイルをアップロードします(②)。ブラウザ上でドラッグ&ドロップする、あるいは「ファイルを選択」ボタンを押す。この操作があるので、「自分のPC内のデータをクラウドに送っている」ということが直感的にわかります。わかりやすいですよね。そして、AI内でプロンプトとデータを解析して回答が作成され(③)ユーザに送信されます(④)
一方、AIエージェントの場合はどうでしょうか。
ユーザーはExcelファイルが入っているフォルダを指定してAIエージェントに「このフォルダ内のExcelファイルを分析して」と指示するだけです。するとAIエージェントが自動的にファイルを読み取り、分析し、レポートを生成してくれます。操作はすべてユーザーのPC内で完結しているように見えます。
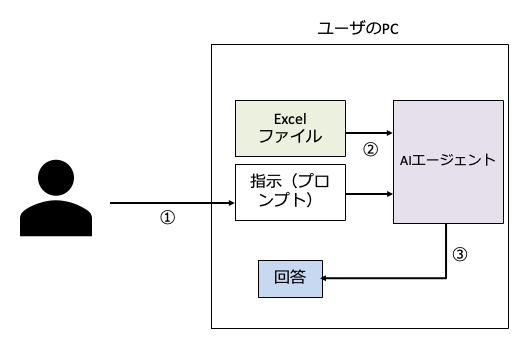
こんなイメージですよね。「AIエージェント」という賢い奴がPC内にいて、そいつがファイルを読んだり回答を作成しており、PC内のデータはクラウドに送られていない、というイメージです。
でも、これは大きな誤解です。
3 AIエージェントの仕組み
では、AIエージェントを利用する場合、具体的には何が起きているのでしょうか。
(1)AIエージェントの構成要素
AIエージェントにはいろいろなタイプがありますが、ここでは「ユーザーのPC内のデータを読み取って何らかの具体的な成果物(Word形式のレポートなど)を作成する」タイプのAIエージェントを例に取って説明します。
この場合、ざっくり言うと、AIエージェントを構成するパーツは3つだけです。
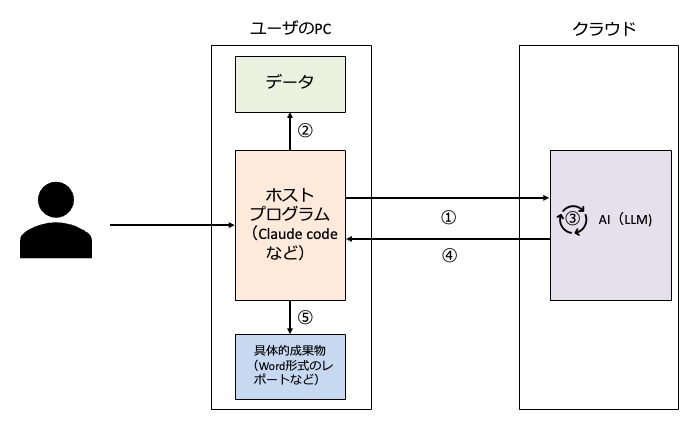
(ⅰ) ホストプログラム
ユーザーのPC上で動いているプログラムです(Claude Codeなど)。このプログラムは、ユーザーとLLMの間に立つ「仲介者」のような存在で、以下の2つの機能を持っています。
ア LLMとの通信
ユーザーの指示やデータをクラウド上のLLMに送信し、LLMからの判断(次に何をすべきか)を受け取る(①)。
イ LLMの判断に基づく実行
LLMからの判断を受け取って、データの取得(ファイルの読み取り、外部サービスからのデータ取得)(②)、ファイルの作成・加工・移動、外部サービスへのデータ送信(メール送信、メッセージ投稿など)を行う(⑤)。このとき、ホストプログラムは自分でファイル操作を行うこともあれば、PC内の別のプログラム(Python等)を呼び出して処理させることもあります。
ここが重要なのですが、ホストプログラム自身には「判断」する能力はありません。何をすべきかを考える力は持っておらず、LLMから送信されてきた「判断」を忠実に「実行」するだけです。
(ⅱ)データ
ホストプログラムがアクセスするデータです。PC内のファイル(ExcelやWord等)のこともあれば、外部サービス上のデータ(SlackのメッセージやGmailのメール等)のこともあります。
(ⅲ)LLM(大規模言語モデル)
クラウド上のサーバーで動いているAIの本体です(Anthropicのサーバー上のClaude、OpenAIのサーバー上のGPTなど)。
「何をすべきか」の判断はすべてこのLLMが行います(③)。
重要なのは、ホストプログラムはローカルPC上にあるのに対し、LLMはクラウド上にあるという点です(データはローカルPCにある場合も、クラウド(クラウドストレージや別のSaaS上のデータなど)上にある場合もあります)。
そして、「判断」は常にクラウド上のLLMが行い、その「判断」がホストプログラムに送信され(④)、「判断」に基づく「実行」はローカルPC上のホストプログラムが行うという役割分担になっています。
(2)具体例:ローカルのExcelファイルを分析する場合
少し具体例を見てみましょう。
ユーザーがAIエージェントで「PC内のフォルダにあるsales.xlsxを分析してWord形式の売上レポートを作って」と指示した場合を考えてみます。
この場合、以下のような処理が行われます。
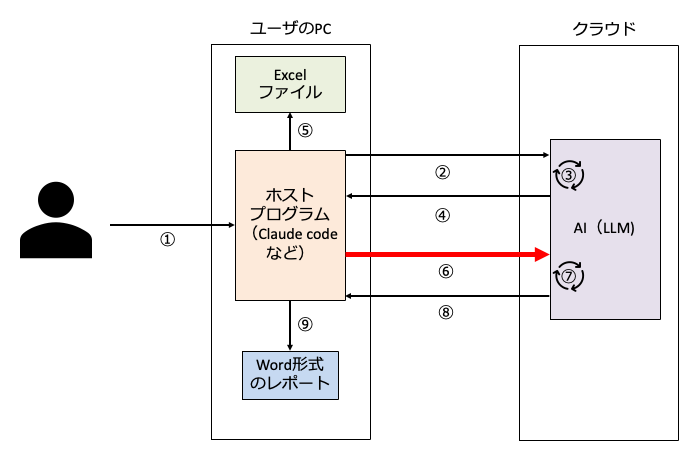
① ユーザーの指示
ユーザーの「PC内のフォルダにあるsales.xlsxを分析してWord形式で売上レポートを作って」という指示です。
② ホストプログラムによるLLMへの指示の送信
ユーザーが入力した①の指示テキスト(プロンプト)を、ホストプログラムがインターネット経由でクラウド上のLLMに送信します。この時点で送られるのはファイルの「パス(保存場所のアドレス)」を含むテキストだけです。Excelファイルの中身はまだ送られていません。
③ LLMによる判断
②の指示の送信を受けたLLMは「まずPythonでExcelファイルを読み込もう」と判断します。
④ LLMの判断の送信
LLMは「PythonでExcelファイルを読み込め」という指示をホストプログラムに返します。
⑤ ホストプログラムによる実行(ファイル読み込み)
ホストプログラムはLLMからの指示を受け取り、ユーザーに「このコマンドを実行していいですか?」と確認した上で、ローカルPC上のPython(ホストプログラムとは別のプログラム)を呼び出してExcelファイルを読み取ります。ここで初めてExcelファイルが開かれますが、この時点ではまだローカルPC内で完結しています。
ここからが重要なポイントです。
⑥ ホストプログラムによるLLMへのデータの送信
ホストプログラムは、Excelファイルの読み取り結果(テキスト化されたデータ)をクラウド上のLLMに送信します。「読み取った結果はこうでした。次はどうしますか?」と報告するわけです。つまり、Excelファイルの中身が、テキストデータとしてクラウドに送信されているということになります。
⑦ LLMによる判断
LLMは送信されてきたデータの構造を把握し、「月別・地域別に集計分析してWordでレポートを作成しよう」と判断します。
⑧ LLMの判断の送信
LLMは「月別・地域別に集計分析してWordでレポートを作成せよ」という指示をホストプログラムに返します。
⑨ ホストプログラムによる実行と完了
ホストプログラムはPC内でPythonを呼び出して集計分析を実行し、Wordでレポートファイルを作成します。完了を報告して終了です。
もうおわかりですね。
AIエージェントが一部「ローカルで動いている」のは事実ですが、それは「実行」の部分だけです。「判断」のためにデータがクラウドに送信されているという部分は、AIチャットでファイルをアップロードする場合と何も変わりません。
ちなみに、AIチャット(Claude.aiなど)でも、Word形式のレポートのような具体的な成果物を作成できますよね。
その場合は以下のような流れになります。
ユーザーのPC内ではWord形式のレポートの作成などの具体的な作業は行われておらず、クラウド上で作成されたWord形式のレポートをユーザーがダウンロードする形式になります。
4 AIの情報系リスクの本質
ここからは法務の観点で整理します。
生成AIツールを利用する場合の情報系リスクの本質は、自らが管理している個人情報(個人データ)や、他社から受領した秘密情報、自社の秘密情報を、生成AIサービス提供者という外部の第三者に送信(入力)することから生じます。
この構造はAIチャットでもAIエージェントでも同じです。
具体的には以下のような法的論点が生じます。
(1)個人データの第三者提供規制
顧客リストや従業員データなど、個人データを生成AIに入力することが個人情報保護法上の第三者提供(法27条)に該当するかが問題となります。また、AIサービス提供者が外国法人(Anthropic、OpenAIなど)である場合、個人データの越境移転規制も問題となります。
もっとも、通常は、個人データを生成AIに入力することは、生成AIの学習機能がオフになっていれば「委託」(法27条5項1号)に該当して本人同意なく可能です。また、越境移転規制についてもメジャーな生成AIサービスについては、基準適合体制の整備(法28条1項、施行規則16条)により本人同意なく入力可能であることが多いでしょう(ただし同スキームを採用する場合のさまざまな義務や外的環境の把握が必要な点には注意が必要です)。
(2)他者の秘密情報との関係
NDAを締結した上でクライアントから受領した秘密情報をAIに入力した場合、NDA上の「第三者への開示」に該当するかが問題となります。該当する場合、何らかの理屈がないと秘密情報のAIへの入力はNDA違反となります。もっとも、この点については弊所としては「一定の条件を満たした生成AIサービスへの秘密情報の入力については、開示者の黙示の承諾がある」と認定できる場合があると考えています。
詳細は弊所杉浦弁護士のブログ記事をご参照ください。
(3)営業秘密の秘密管理性
不正競争防止法上、営業秘密として保護されるためには「秘密管理性」が要件の一つとされています。自社の秘密情報をAIサービス提供者のクラウドに送信することで、この秘密管理性が損なわれ、「営業秘密として保護されなくなってしまう」というリスクがあります。ただ、AIサービス提供者における秘密保持義務が利用規約上明記されており、かつ生成AIを利用する従業員の認識可能性がきちんと担保されていれば、AIへの入力によって直ちに秘密管理性が失われるとは考えにくいところです(この論点は面白い論点なので、別記事にしたいと思います)。
(4)まとめ
これらのリスクは、すべて「社内のデータが第三者(クラウド)に提供される」ことから生じています。
したがって結局のところ、AIチャットだろうとAIエージェントだろうと、情報系リスクの本質は変わりません。
そして、上で見たとおり、これらのリスクは、学習機能のオフ(API利用やオプトアウト設定)や、利用規約・DPAの確認、NDAへのAI利用条項の整備といった対応を適切に行うことで、相当程度コントロール可能です。AIチャットについては、この整理がすでに広く認知されており、多くの企業で実務対応が進んでいます。
ただし、これらの対応はすべて、「どのデータがAIに送信されているかをユーザーが把握していること」が大前提です。AIエージェントを利用すると、その部分の認識が曖昧になることがあるので注意しましょう、というのが本記事でお伝えしたいことです。
5 AIエージェント固有のリスク ― 無自覚な大量データ提供
また、法的論点の本質は同じでも、リスクの規模や管理の難しさはAIエージェントのほうが大きいと言わざるを得ません。
AIチャットの場合、ユーザーは自分の手でファイルをアップロードします。
何を送信しているかを意識的に選択しているので、送信範囲は限定されます。「この契約書をレビューして」と1つのファイルをアップロードする行為は、ユーザーにとって自覚的な行動です。
一方、AIエージェントの場合はどうでしょうか。AIエージェントは、ユーザーの指示に基づいて自律的にファイルを読み取ります。先ほど見たように「判断→実行→結果を見て次の判断」をループで繰り返す構造ですので、このループの中で、エージェントが次々とファイルを読み取り、その内容をクラウドに送信していくことになります。
結局のところ、AIエージェントではユーザーが送信範囲を把握しにくいのです。
具体的に起こりうるシナリオを挙げてみます。
▼ プロジェクトフォルダ内にある.envファイル(APIキーやパスワードが記載されている設定ファイル)をエージェントが読み取って送信してしまう
▼ 作業対象のフォルダに隣接するディレクトリにある、別のクライアントの機密情報をエージェントが「参考になる」と判断して読み取って送信してしまう
▼ ループの中で関連ファイルを次々と読み取り、当初の想定を超えた範囲のデータがクラウドに送信される
▼ 営業秘密として管理されていた社内の機密情報が、ユーザが気づかないうちにクラウドに送信されて機密情報を含む処理結果がユーザに表示され、当該処理結果に機密情報が含まれていることを知らずに社外に提供してしまった。
これらはいずれも、ユーザーが明示的に「このファイルを送れ」と指示したわけではなく、エージェントが自律的に判断した結果として起きうる事態です。
この「無自覚な大量データ提供」こそが、AIエージェント固有のリスクということになります。
なお、ここで「エージェントが自律的に判断」と書きましたが、正確には判断しているのはクラウド上のLLMです。LLMが「このファイルも読んだほうがいい」と判断し、ホストプログラムがその判断に従ってファイルを読み取り、読み取った内容をまたLLMに送信する、というループが回っています。この構造を理解しておくと、なぜユーザーの意図しないファイルまで読み取られてしまうのかがわかると思います。
6 企業のAI利用者が押さえるべき実務ポイント
以上を踏まえ、情報系リスクへの対応という観点から、企業がAIエージェントを利用する際に押さえるべき実務ポイントを整理します。
(1)AIエージェントがアクセスできるデータの範囲を制限する
AIエージェント(ホストプログラム)がアクセスできるデータの範囲を明確に制限してください。たとえば、AIエージェントに作業させるフォルダと機密ファイルの保管場所を分離する、ホストプログラムの設定でアクセス可能なフォルダを限定する、といった方法があります。エージェントがアクセスできる範囲を制限することが、最もシンプルで効果的な対策です。
(2)送信前確認を安易にスキップしない
Claude Codeなどのツールは、コマンド実行前に「このコマンドを実行していいですか?」と確認を求めてきます。この確認を面倒だからと一括許可(自動承認)にしてしまうと、無自覚なデータ送信のリスクが大幅に高まります。確かに毎回の確認は煩わしいのですが、ここは安全と効率のトレードオフです。少なくとも、機密性の高いファイルがあるディレクトリで作業する場合は、確認を省略しないことをお勧めします。
(3)「AIエージェントはPC内で動いており安全」ではないことの社内教育
本記事で解説したとおり、AIエージェントがローカルで動いているように見えても、データはクラウドに送信されています。この点を社内の研修やガイドラインで明確に周知してください。「PCの中で動いているから大丈夫」という誤解は、想像以上に広まっています。
7 最後に
AIエージェントは強力なツールであり、その生産性向上の効果は計り知れません。
もっとも、その便利さの裏側にあるデータの流れを正しく理解した上で、適切なルール整備を行うことが重要です。「ローカルで動いているように見えるから安全」という思い込みだけは、今日この記事を読んだ時点で捨てていただければと思います。
なお、本記事ではAIエージェントのローカルファイル操作に焦点を絞りましたが、GmailやSlackなどの外部サービスとAIを接続した場合(いわゆるMCP連携)には、データの経由地がさらに増えるという別のリスクが生じます。
この点については、次回の記事で解説する予定です。お楽しみに!












