Automatic Content Generation AI and Copyright
2. If a copyright arises for an automatically generated image, who will be the copyright holder?
So, if a copyright arises for an automatically generated image, who will be the copyright holder? Under the Copyright Act, “author” is defined as “a person who creates a work” (Copyright Act, Article 2, Paragraph 1,Item 2).
Incidentally, whether a copyright arises for certain content and who the author is are determined under the Copyright Act, and private individuals cannot arbitrarily decide whether or not a copyright has arisen or whether or not authorship (i.e., the primary original source of the copyright) exists.
Therefore, even if the terms of use of image generation AI software stipulates that “a copyright will arise for images generated by this software” or “the service provider is the author of images generated by this software”, it would be meaningless (however, it is possible to stipulate “copyrights derived from the user are transferred to the service provider free of charge”).
The reason for this is, first of all, as for the creator of the image generation AI software, there is no doubt that he or she is the author of the image generation AI software itself (which is a copyrighted program work); however, no copyrights can be obtained with respect to the automatically generated image since there was no act of creation for the automatically generated images using such AI software.
For the same reason, neither the person who generated and provided the image for the creation of the automatic image generation AI software nor the person who generated and provided the dataset can acquire a copyright on the autogenerated images.
On the other hand, as explained earlier, I think that copyrights would arise for “a person who generated along, detailed text (prompt), and used it to generate an image”; “a person who chooses the desired image after multiple attempts to determine the length and components of text (prompt)”; “a person who chooses the desired image from among numerous images generated by using the same text (prompt) over and over again”; and “a person who has creatively processed an image automatically generated by AI.”
Complications arise when the “person who created the detailed and lengthy spell” and the “person who used said spell to generate the image” are different people.
Let’s assume that A is “the person who generated a long, detailed text(prompt) X”; B is “the person who used the text (prompt) X to generate an image”; and Y is “the image automatically generated by B on the very firsttry using the X text (prompt).”
In this case, it seems to me that A cannot hold the copyright to the Y image since it is not a derivative work of the X text (prompt). On the other hand, since B automatically generated the Y image on the very firsttry using the X text (prompt) created by A, who is a totally different person, there is no “creative contribution”from B. Therefore, B cannot become the author of the Y image either.
Then, that would mean that no one holds the copyright for the Y image. However, if “the creation of the X text(prompt)” itself is a “creative contribution with respect to the creation of Y”, then it seems to me that A might hold the copyright to the Y image. However, I think that would contradict the fact that the Y image is not a derivative work of the X text(prompt). I will consider this a bit more.
Incidentally, there is also an argument that, as a legislative theory, it may be acceptable to recognize the individuality of “AI itself” and to consider “AI itself” as the author. Alternatively, it may be acceptable to consider the person who created the AI as the author by adopting a concept similar to that of a work made in the course of duty under the Copyright Act (Copyright Act, Article 15) or a copyright on a cinematographic work(Copyright Act, Article 29, Paragraph 1).
Section 4. Whether an image constitutes a copyright infringement if an image identical to the image used in the learning is “coincidentally” autogenerated by AI (Issue 3)
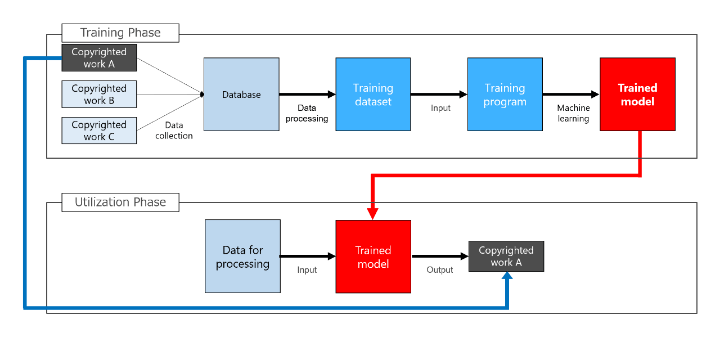
1. Before anything else, does this constitute a copyright infringement?
For example, suppose that an existing image A exists and this existing copyrighted work A is used as a training dataset, which then automatically generating an image A that is identical or similar to the existing image A.
For copyright infringement (infringement of the reproduction rights or adaptation rights) to be established, the following are required: (i) the copyrighted work must be identical or similar to an existing copyrighted work (similarity) and (ii) there must be reliance on the copyrighted work.
(1) When only the workmanship or style is similar
First, the problem in relation to the similarity [in (i) in the preceding paragraph], is when an output image A is only similar in terms of the “workmanship” or “style” of the existing image A.
For “similarity” to be affirmed, the “essential expressive characteristics of the existing copyrighted work must be directly recognizable”. If the copyright works are similar only in “style” or “workmanship”, they do not satisfy the similarity requirement and do not constitute copyright infringement.
This is because copyright is only a right to protect concrete “expressions” and the “style” or “workmanship” of a certain author belongs to the realm of abstract “ideas”, which are not subject to copyright protection(the idea-expression dichotomy). 1Tatsuhiro Ueno, “Issues Concerning Artificial Intelligence and Machine Learning under the Copyright Act – Recent Trends in Japan and Europe” (Legal Times, Vol. 91, No. 8, Page 38).
However, the distinction between similarity at the “expression” level and similarity at the “style” or “workmanship” level is an often-disputed difficult point, since it is not always clear, not only with respect to AI-generated works.
(2) Whether or not reliance exists
Relying is defined as “coming into contact with another person’s copyrighted work and using it in one’s own work”. 2Nobuhiro Nakayama, Copyright Law (3rd edition), Page 709 In short, even if a certain creation happens to resemble the copyrighted work of another person, if it is an original creation that did not rely on the copyrighted work of others, then there is no reliance and therefore [such creation] is non-infringing.
Therefore, in this case, the question becomes whether “reliance”, one of the elements of copyright infringement, exists (or not). 3In fact, unlike the case described in the main text, there may be a “case where a work A identical or similar to an existing work A that is not used as training data is automatically generated”. In this case, the question is whether or not the user/service provider has accessed the existing work A. If he/she has not accessed the existing work A, reliance would be denied.
On this point, there is a theory whose idea is that reliance should be recognized if there is access to an existing copyrighted work, such as existing copyrighted work A being included in a training dataset (affirmative theory) 4Hisayoshi Yokoyama, “Issues related to AI under the Copyright Act and the Patent Act”, Legal Times, Vol. 91, No. 8, Pages 53-54. In this study, Yokoyama states, “if the original work contributed to the creation of a set of parameters, and if a product is created based on that set of parameters, the AI product can be said to have been created using the original work, even though the form of expression has been transformed, and thus reliance should be affirmed”. Yasuyuki Echi, “AI Products, Machine Learning and the Copyright Act”, Patent, Vol. 73, No. 8, Page 143. and another theory whose idea is that since the parameter (coefficient generated by machine learning) itself is an idea, reliance should not be recognized when an existing copyrighted work is parameterized(negative theory).5Koji Okumura, “The Mobius Strip of Technological Innovation and Copyright Legality”, Copyright, No. 702, Vol. 59, Page 10. However, there is no consensus about this point.