Automatic Content Generation AI and Copyright

Introduction
Automatic content (image) generation AI services, such as Midjourney, Stable Diffusion, and mimic, are certainly a hot topic. Although there is no need to mention the details of these services, Midjourney and Stable Diffusion are “automatic image generation AI services that can automatically generate an image when a sentence (a prompt) is input” and mimic is “a service that can create AI capable of automatically generating illustrations that reflect the individuality of the artist by learning the illustrations of a specific artist”.(However, soon after the service was released, there was a backlash and it was shut down.)
So, since almost the same issues are generally discussed with this kind of automatic content generation AI, such as the automatic image generation AI, from the perspective of the Copyright Act, taking [these] automatic image generation AI as an example, there are three issues below. 1 To be precise, Issue 1 is not only about automatic content generation AI, but also about AI in general. The issues specific to automatic content generation AI are issues 2 and 3.
Whether the collection and use, without permission, of copyrighted works, such as texts and images owned by third parties, to generate AI software 2Here, AI software refers to those developed using statistical machine learning technology. In this article, I sometimes simply call it “AI”. is allowed (Issue 1);
Whether a copyright arises for autogenerated images(Issue 2); and
Whether an image constitutes a copyright infringement if an image identical to the image used in the learning is “coincidentally” autogenerated by AI(Issue 3).
Since I received responses from many people when I tweeted on Twitter about “whether a copyright arises for autogenerated images”, I would like to explain these three issues in detail in this article.
Section 1. Overview of the Issues
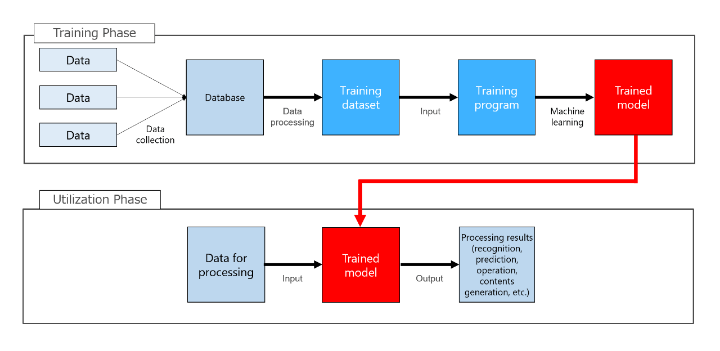
In my work, I am often asked to provide advice and to do presentations relating to the utilization of AI software and the development (learning and training) of AI software. On these occasions, I use this diagram for explanation purposes.
Of the three issues introduced above, the first issue of “whether the collection and use, without permission, of copyrighted works, such as texts and images owned by third parties, to generate AI software is allowed” relates to the learning (training) phase, and is an issue that primarily pertains to service providers of AI software and development.
Next, the second issue of “whether a copyright arises for autogenerated images” (Issue 2) relates to the utilization phase, and is an issue that pertains exclusively to users who use AI software to autogenerate images.
The final issue of “whether an image constitutes a copyright infringement if an image identical to the image used in the learning is “coincidentally” autogenerated by AI” (Issue 3) is also an issue that relates to the utilization phase. This issue pertains to both service providers and users alike.
This is attributable to an automatic content (image) generation AI tool provided by the service provider and the user using the same tool to autogenerate images. Therefore, the issues are both whether the use of images automatically generated by a user using an automatic image generation AI constitutes copyright infringement(Issue 3(2)) and whether, if the user has committed copyright infringement, not only the user but also the service provider who provided such automatic image generation AI is liable (Issue 3(1)).
Since only Issue 3 may be a bit difficult to visualize, the diagram below illustrates this issue more clearly.
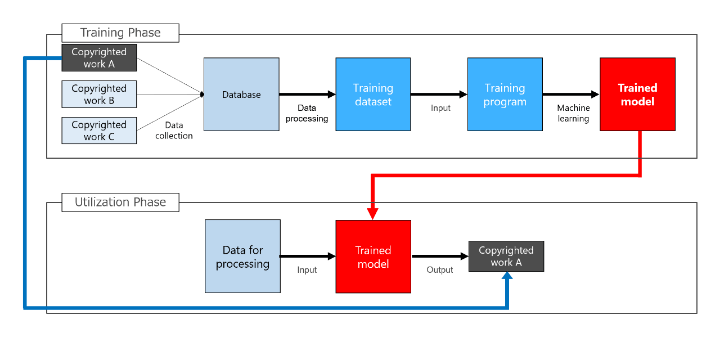
This issue involves the case of whether Image A constitutes a copyright infringement if Image A identical to the existing image A used in the learning is “coincidentally” autogenerated.
Section 2. Whether the Collection and Use, Without Permission, of Copyrighted works, such as Texts and Images Owned by Third Parties, to Generate AI Software is allowed (Issue 1)
When collecting copyrighted works owned by third parties without permission to generate AI software using machine learning techniques, there are several patterns in the collections of the copyrighted works to be used as the “raw material”. This section will focus on the collection of data from the internet.
Actually, in this case, there are two issues.
The issues are “whether there is a problem under the Copyright Act (i.e.,whether it infringes a copyright)” and “whether there is a breach of contract (i.e., the terms of use)”.
The latter issue poses a question with respect to mimic of whether it is actually possible to prohibit the use of illustrations for learning by means of a representation that “the use of the illustration that I drew for AI learning is prohibited”.
Since these are separate issues, I will explain them separately below.
1. Whether the collection and use, without permission, of copyrighted works, such as texts and images owned by third parties, to generate AI software poses any problems under the Copyright Act
(1) Japan’s Copyright Act, Article 30-4, Item (ii)
For example, suppose that you collect a large number of photos and illustrations that exist on the web, and then, after generating a training dataset, create automatic content generation AI software.
In such cases, although the copyrights to these photos and illustrations are usually held by their respective creators, in order to create AI software, the permission of the copyright holder of such photos is required, in principle, to download such photos (i.e.,reproduction), process them into a form suitable for AI learning(i.e.,adaptation), and use them in AI learning.
However, Japan’s Copyright Act contains a provision for limitations of copyrights, which, in principle, makes it possible to engage in acts using copyrighted works (i.e., reproduction and adaptation of data) required for the generation of AI software without the consent of the copyright holder.
This provision is Article 30-4, Item (ii) of [Japan’s] Copyright Act, which was adopted by the Act Partially Amending the Copyright Act of 2018.
(Exploitation without the Purpose of Enjoying the Thoughts or Sentiments Expressed in a Work )
Article 30-4 It is permissible to exploit a work, in any way and to the extent considered necessary, in any of the following cases, or in any other case in which it is not a person’s purpose to personally enjoy or cause another person to enjoy the thoughts or sentiments expressed in that work; provided, however, that this does not apply if the action would unreasonably prejudice the interests of the copyright owner in light of the nature or purpose of the work or the circumstances of its exploitation.
(i) Omitted
(ii) if it is done for use in data analysis (meaning the extraction, comparison, classification, or other statistical analysis of the constituent language, sounds, images, or other elemental data from a large number of works or a large volume of other such data; the same applies in Article 47-5, paragraph 1, item (ii);
(iii) Omitted
Although the text is as shown above, it is essentially a provision whose contents limit rights in that “in principle, works may be freely used to the extent necessary for ‘data analysis’”.
Since the development of AI software falls under such “data analysis”, as a result, copyrighted works can, in principle, be freely used to the extent necessary to generate AI software.
More particularly, since the introductory text of Article 30-4 stipulates that “it is permissible to exploit [a work], in any way and to the extent considered necessary”, it is possible to engage in “acts of collecting, reproducing, modifying, etc. copyrighted works to develop AI software on your own” as well as “acts of generating and providing training dataset for other companies that are developing AI software by collecting or modifying copyrighted works.”