8 Points about AI Development Agreements that can be learned from the “Contract Guidance on Utilization of AI and Data
2. Dividing the development process from the contract
The next important matter is dividing the development process and the contract.
Very roughly speaking, the characteristic of AI software development is that “it is difficult for both the
user and the vendor to predict in advance what will be produced”; in short, until you actually
start the development process, you will not know whether it will go well or not.
This “not knowing whether [it] will go well or not” is not a matter of asymmetric information where the
“vendor knows, but the user does not know”; rather, it means that neither the vendor nor the user knows.
This kind of characteristic poses a serious risk for both the user and the vendor.
As one measure to control this risk, the AI Guidelines advocate the “Exploratory Multi-phased AI development processes” development methodology that divides the development process and the contract. More specifically, this is a development methodology that divides the development of AI software into four phases: (i) the assessment phase, (ii) the PoC phase, (iii) the development phase, and (iv) the retraining phase.
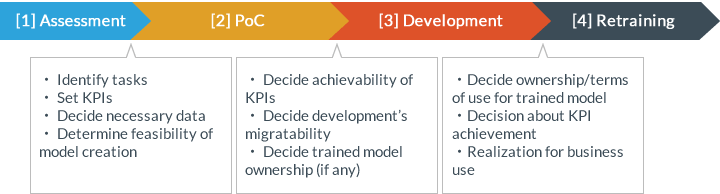
AIガイドラインより
A summary of each phase’s goal, deliverables, and contract is below.
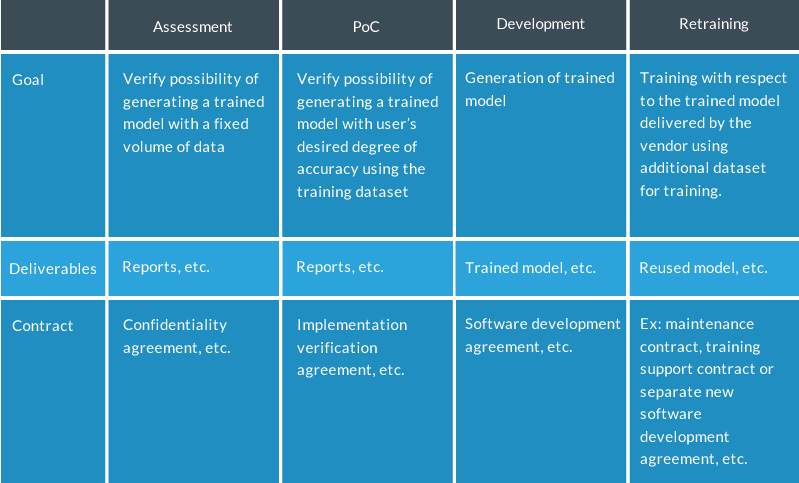
Quoted from the AI Guidelines (partially revised)
Incidentally, the phrase “dividing into four phases” itself is not important. The essential point is to
“proceed gradually because whether the [development] will go well or not is unknown, proceeding to the next
phase if it looks as though it might be successful, and stopping when it seems impossible, thereby enabling
both the vendor and the user to control the risk”.
Because it is not of course essential to divide into the four phases above, depending on the scale of
development, the (i) assessment phase and the (ii) PoC phase can be combined and the (ii) PoC phase can be
further divided into numerous phases.
3. Crafting the contents of a development agreement
Finally, there is crafting the contents of a development agreement.
If we contrast the contents of contracts for conventional system development and for AI software development,
it is as below.
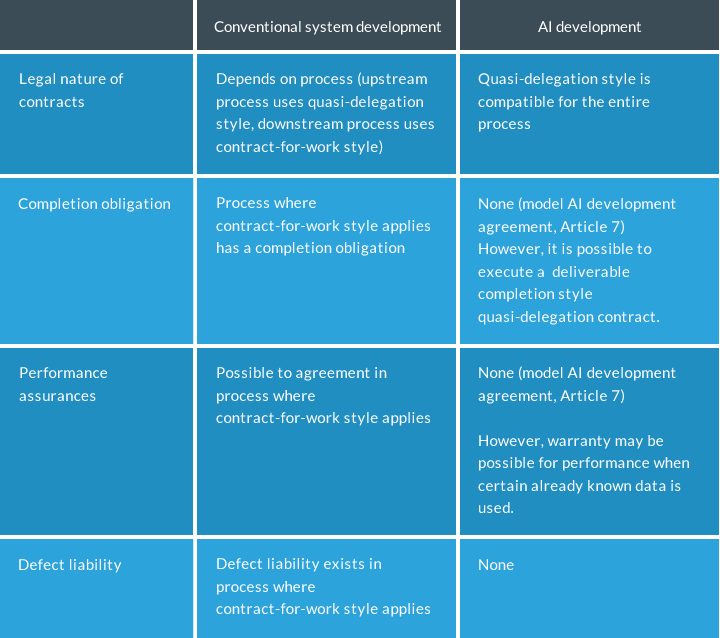
I often use this diagram for explanatory purposes at seminars and the like where the most frequently asked
question is: “I understand the logic behind the lack of performance assurances when AI software is
introduced at the workplace and unknown data is entered. However, in the end it is difficult for the user to
accept that there are no performance assurances whatsoever for AI software, the development of which the
user has paid a large sum of money. Is there any way that the contents of a development agreement can be
devised to resolve this issue?
The methods presented in the Guidelines on this point are the method where performance is assured when
certain already known evaluation data, not used in training, is entered and the method of selecting the
completed results type in a quasi-delegation contract.
Even if assurances are difficult with respect to the former [method] in the case of input of unknown data,
assurances are technologically possible in the case of entry of already known evaluation data. Understandably,
in this case, it is necessary for such data used for evaluation to sufficiently reflect the actual nature of
the unknown data when AI is introduced at the workplace.
It is thought that there are two types in a quasi-delegation contract; the “completed results type” for the
promise to pay remuneration for results obtained through performance of the entrusted business or the
“performance proportion type” for payment of remuneration to be made in proportion to entrusted handled. The
latter [method] refers to the choice of the “completed results type”.
For a “completed results type” quasi-delegation contract, the user and the vendor agree to pay a fixed amount for results depending on the progress (for example, a certain performance for already known data) and it will reduce the vendor’s risk in the case of uncompleted results.
Who owns what rights to generated training datasets, trained models, and trained parameters? (rights/intellectual property)
Next is the problem concerning rights and intellectual property.
When developing AI software, how to provide for rights/intellectual property concerning deliverables and the
like in a contract is a matter of serious concern for the user and the vendor.
A typical consultation is as follows: “When we, as an AI vendor, launch a joint project with a business
partner, the business partner and the AI vendor are often not sure about how to address intellectual
and legal issues (how to include provisions in a contract) at the beginning, and once there are actual
profits, there is a concern about possible disputes.”
Why are negotiations so difficult?
Below are two reasons why the positions of both parties are often more contentious with respect to the rights and intellectual property concerning deliverables in AI software development than in conventional system development.
- Unlike the conventional system development, AI software development involves various materials, interim deliverables, as well as deliverables.
- The materials required in development, interim deliverables, and deliverables have high values and therefore there is a demand from both users and vendors to monopolize/re-use them.
First, if the development process for conventional system development is stripped to its bare essentials, it becomes the development of deliverables in the form of a program and documentation by introducing materials such as the vendor’s labor and know-how as shown below.

On the other hand, one of the major features of the AI software system development’s development process is that, as shown below, the introduction of materials such as raw data, training programs, labor and know-how results in the development of deliverables such as trained models and trained parameters, while generating interim deliverables, such as training datasets as well as inventions and know-how during the development process.
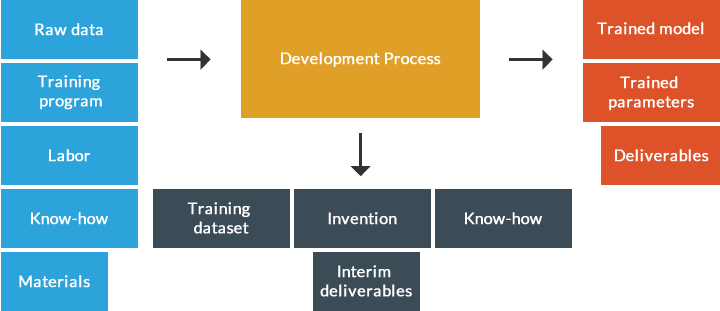
(Incidentally, the term “deliverable” as used here refers to items whose delivery and creation support are agreed to contractually. Therefore, since the distinction between a “deliverable” and an “interim deliverable” is a relative matter, depending on the contents of a contract, “training dataset” may also be agreed to being a “deliverable”.)